 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Sequential Subspace Search for Functional Bayesian Optimization Incorporating Experimenter Intuition
Sep 08, 2020

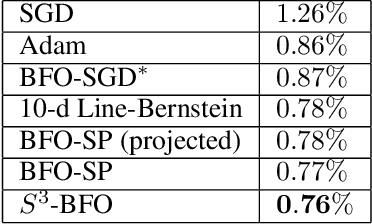

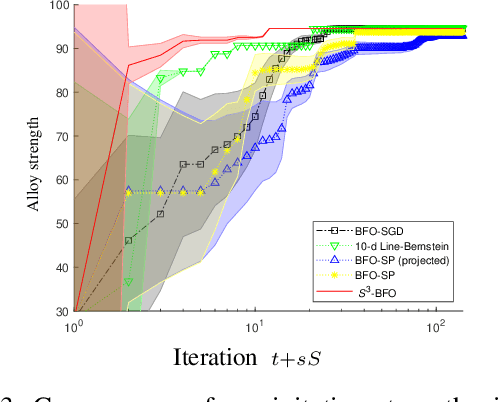
We propose an algorithm for Bayesian functional optimisation - that is, finding the function to optimise a process - guided by experimenter beliefs and intuitions regarding the expected characteristics (length-scale, smoothness, cyclicity etc.) of the optimal solution encoded into the covariance function of a Gaussian Process. Our algorithm generates a sequence of finite-dimensional random subspaces of functional space spanned by a set of draws from the experimenter's Gaussian Process. Standard Bayesian optimisation is applied on each subspace, and the best solution found used as a starting point (origin) for the next subspace. Using the concept of effective dimensionality, we analyse the convergence of our algorithm and provide a regret bound to show that our algorithm converges in sub-linear time provided a finite effective dimension exists. We test our algorithm in simulated and real-world experiments, namely blind function matching, finding the optimal precipitation-strengthening function for an aluminium alloy, and learning rate schedule optimisation for deep networks.
Continual Reinforcement Learning with Multi-Timescale Replay
Apr 16, 2020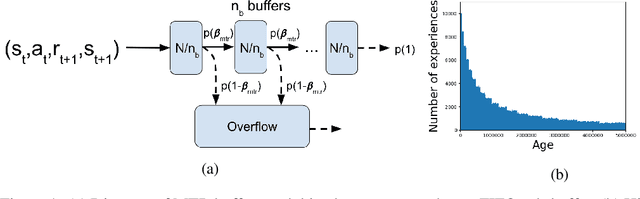

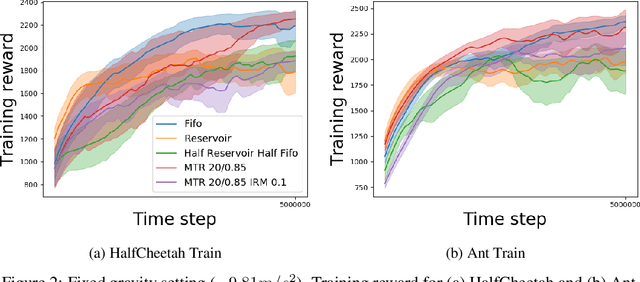
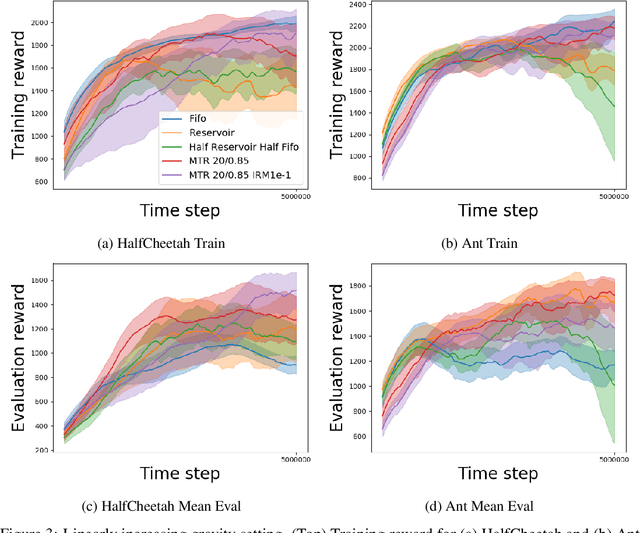
In this paper, we propose a multi-timescale replay (MTR) buffer for improving continual learning in RL agents faced with environments that are changing continuously over time at timescales that are unknown to the agent. The basic MTR buffer comprises a cascade of sub-buffers that accumulate experiences at different timescales, enabling the agent to improve the trade-off between adaptation to new data and retention of old knowledge. We also combine the MTR framework with invariant risk minimization, with the idea of encouraging the agent to learn a policy that is robust across the various environments it encounters over time. The MTR methods are evaluated in three different continual learning settings on two continuous control tasks and, in many cases, show improvement over the baselines.
MixML: A Unified Analysis of Weakly Consistent Parallel Learning
May 14, 2020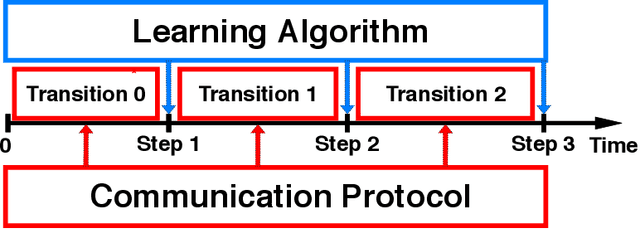
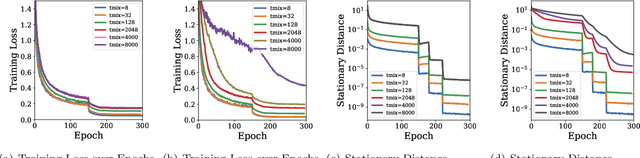
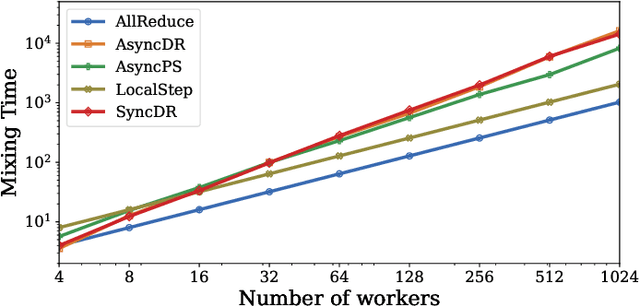
Parallelism is a ubiquitous method for accelerating machine learning algorithms. However, theoretical analysis of parallel learning is usually done in an algorithm- and protocol-specific setting, giving little insight about how changes in the structure of communication could affect convergence. In this paper we propose MixML, a general framework for analyzing convergence of weakly consistent parallel machine learning. Our framework includes: (1) a unified way of modeling the communication process among parallel workers; (2) a new parameter, the mixing time tmix, that quantifies how the communication process affects convergence; and (3) a principled way of converting a convergence proof for a sequential algorithm into one for a parallel version that depends only on tmix. We show MixML recovers and improves on known convergence bounds for asynchronous and/or decentralized versions of many algorithms, includingSGD and AMSGrad. Our experiments substantiate the theory and show the dependency of convergence on the underlying mixing time.
An Autonomous Path Planning Method for Unmanned Aerial Vehicle based on A Tangent Intersection and Target Guidance Strategy
Jun 07, 2020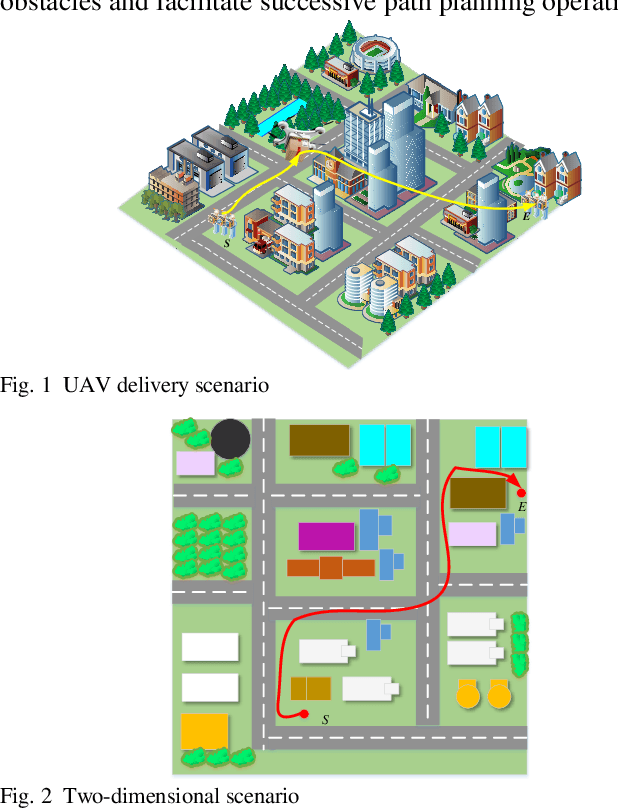
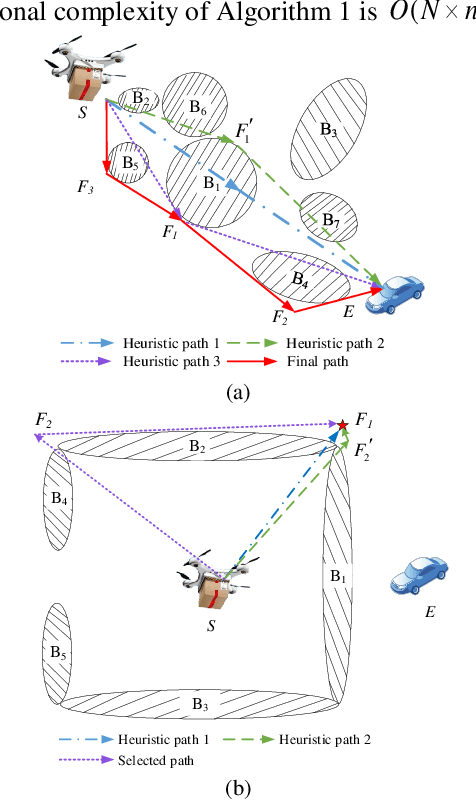
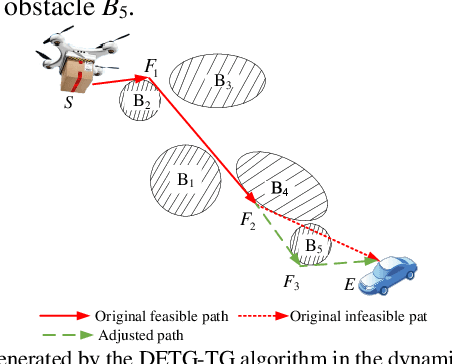
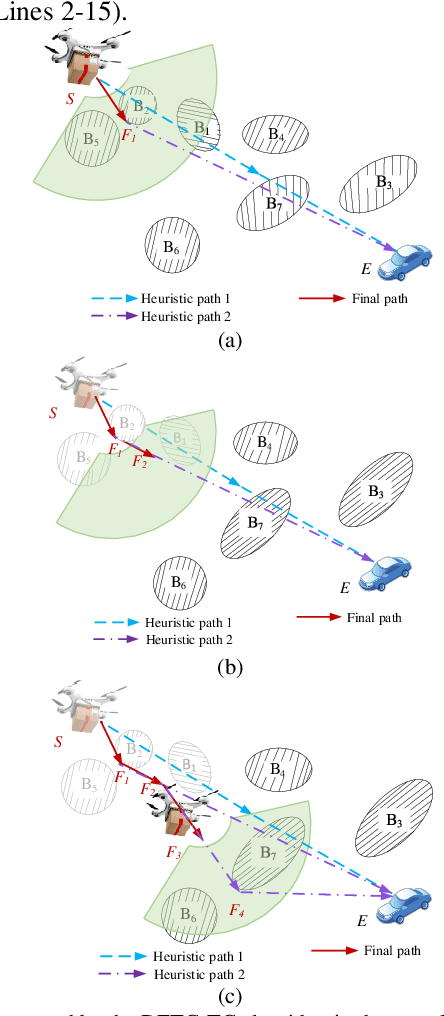
Unmanned aerial vehicle (UAV) path planning enables UAVs to avoid obstacles and reach the target efficiently. To generate high-quality paths without obstacle collision for UAVs, this paper proposes a novel autonomous path planning algorithm based on a tangent intersection and target guidance strategy (APPATT). Guided by a target, the elliptic tangent graph method is used to generate two sub-paths, one of which is selected based on heuristic rules when confronting an obstacle. The UAV flies along the selected sub-path and repeatedly adjusts its flight path to avoid obstacles through this way until the collision-free path extends to the target. Considering the UAV kinematic constraints, the cubic B-spline curve is employed to smooth the waypoints for obtaining a feasible path. Compared with A*, PRM, RRT and VFH, the experimental results show that APPATT can generate the shortest collision-free path within 0.05 seconds for each instance under static environments. Moreover, compared with VFH and RRTRW, APPATT can generate satisfactory collision-free paths under uncertain environments in a nearly real-time manner. It is worth noting that APPATT has the capability of escaping from simple traps within a reasonable time.
The Role of Isomorphism Classes in Multi-Relational Datasets
Sep 30, 2020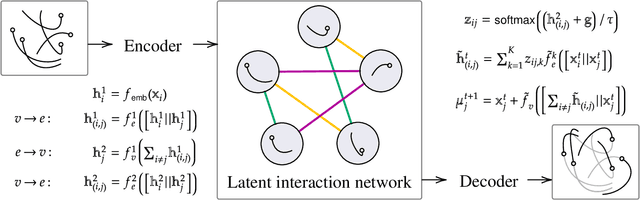

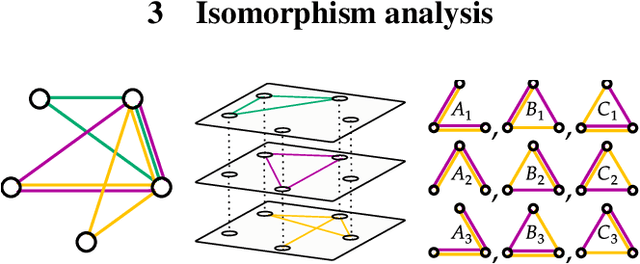
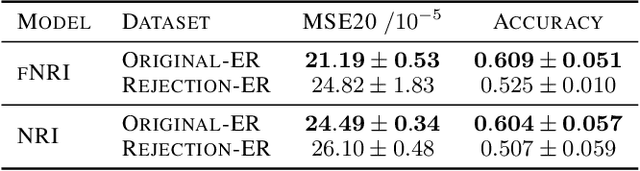
Multi-interaction systems abound in nature, from colloidal suspensions to gene regulatory circuits. These systems can produce complex dynamics and graph neural networks have been proposed as a method to extract underlying interactions and predict how systems will evolve. The current training and evaluation procedures for these models through the use of synthetic multi-relational datasets however are agnostic to interaction network isomorphism classes, which produce identical dynamics up to initial conditions. We extensively analyse how isomorphism class awareness affects these models, focusing on neural relational inference (NRI) models, which are unique in explicitly inferring interactions to predict dynamics in the unsupervised setting. Specifically, we demonstrate that isomorphism leakage overestimates performance in multi-relational inference and that sampling biases present in the multi-interaction network generation process can impair generalisation. To remedy this, we propose isomorphism-aware synthetic benchmarks for model evaluation. We use these benchmarks to test generalisation abilities and demonstrate the existence of a threshold sampling frequency of isomorphism classes for successful learning. In addition, we demonstrate that isomorphism classes can be utilised through a simple prioritisation scheme to improve model performance, stability during training and reduce training time.
Can questions summarize a corpus? Using question generation for characterizing COVID-19 research
Sep 19, 2020

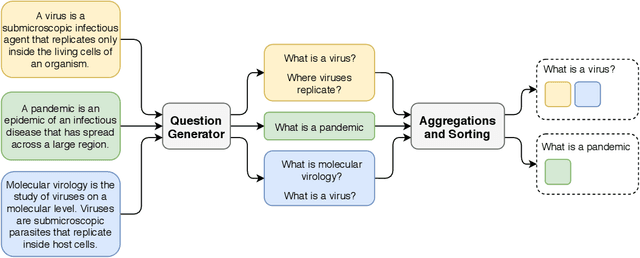
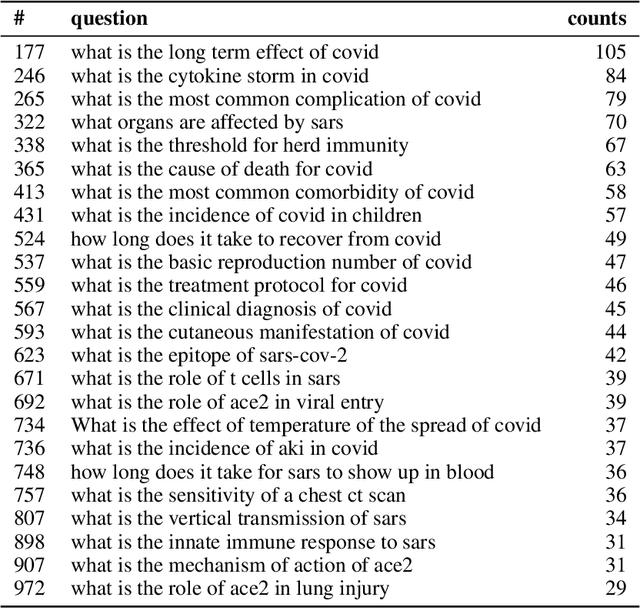
What are the latent questions on some textual data? In this work, we investigate using question generation models for exploring a collection of documents. Our method, dubbed corpus2question, consists of applying a pre-trained question generation model over a corpus and aggregating the resulting questions by frequency and time. This technique is an alternative to methods such as topic modelling and word cloud for summarizing large amounts of textual data. Results show that applying corpus2question on a corpus of scientific articles related to COVID-19 yields relevant questions about the topic. The most frequent questions are "what is covid 19" and "what is the treatment for covid". Among the 1000 most frequent questions are "what is the threshold for herd immunity" and "what is the role of ace2 in viral entry". We show that the proposed method generated similar questions for 13 of the 27 expert-made questions from the CovidQA question answering dataset. The code to reproduce our experiments and the generated questions are available at: https://github.com/unicamp-dl/corpus2question
W-Cell-Net: Multi-frame Interpolation of Cellular Microscopy Videos
May 14, 2020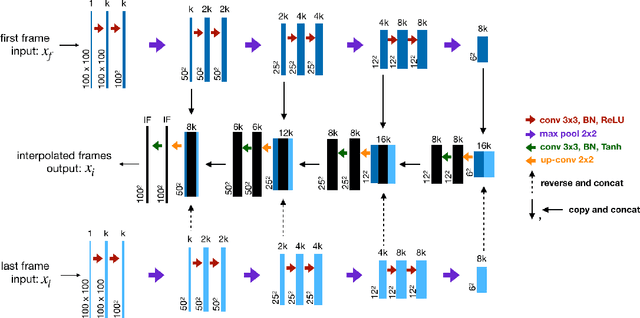
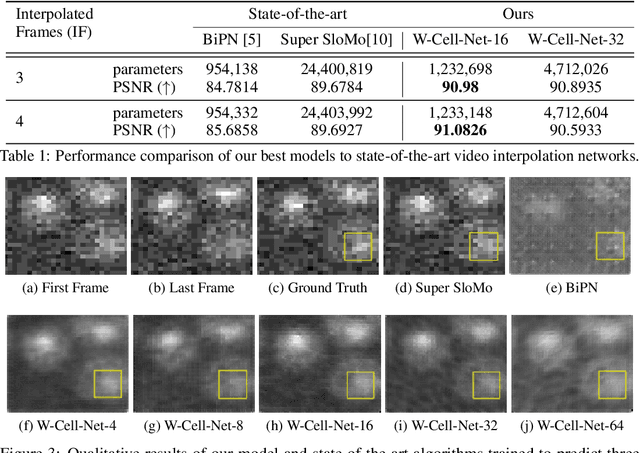
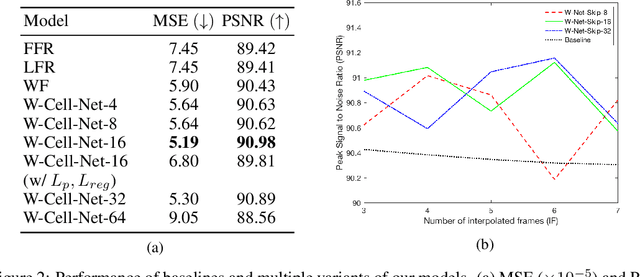
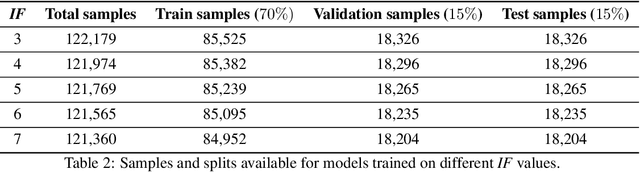
Deep Neural Networks are increasingly used in video frame interpolation tasks such as frame rate changes as well as generating fake face videos. Our project aims to apply recent advances in Deep video interpolation to increase the temporal resolution of fluorescent microscopy time-lapse movies. To our knowledge, there is no previous work that uses Convolutional Neural Networks (CNN) to generate frames between two consecutive microscopy images. We propose a fully convolutional autoencoder network that takes as input two images and generates upto seven intermediate images. Our architecture has two encoders each with a skip connection to a single decoder. We evaluate the performance of several variants of our model that differ in network architecture and loss function. Our best model out-performs state of the art video frame interpolation algorithms. We also show qualitative and quantitative comparisons with state-of-the-art video frame interpolation algorithms. We believe deep video interpolation represents a new approach to improve the time-resolution of fluorescent microscopy.
Detecting Autism Spectrum Disorder using Machine Learning
Sep 30, 2020
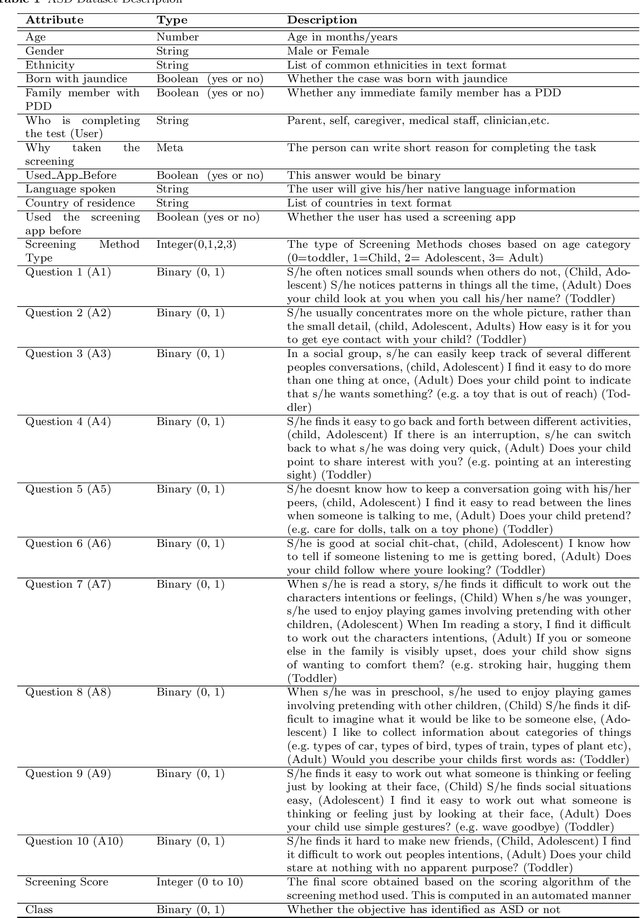
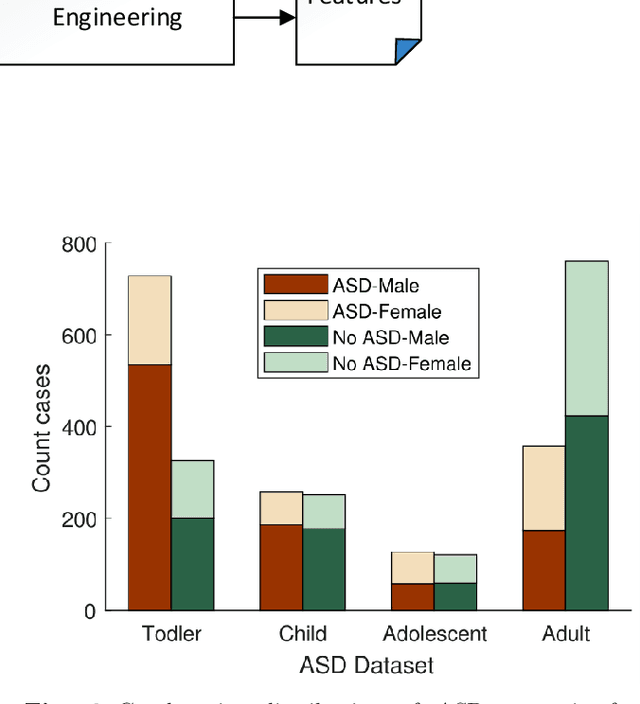
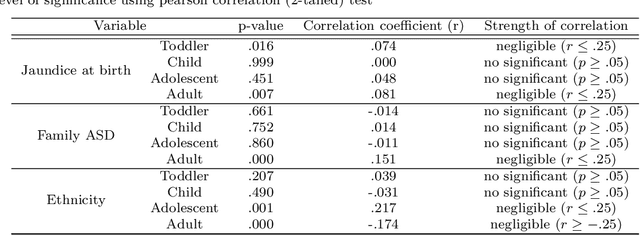
Autism Spectrum Disorder (ASD), which is a neuro development disorder, is often accompanied by sensory issues such an over sensitivity or under sensitivity to sounds and smells or touch. Although its main cause is genetics in nature, early detection and treatment can help to improve the conditions. In recent years, machine learning based intelligent diagnosis has been evolved to complement the traditional clinical methods which can be time consuming and expensive. The focus of this paper is to find out the most significant traits and automate the diagnosis process using available classification techniques for improved diagnosis purpose. We have analyzed ASD datasets of Toddler, Child, Adolescent and Adult. We determine the best performing classifier for these binary datasets using the evaluation metrics recall, precision, F-measures and classification errors. Our finding shows that Sequential minimal optimization (SMO) based Support Vector Machines (SVM) classifier outperforms all other benchmark machine learning algorithms in terms of accuracy during the detection of ASD cases and produces less classification errors compared to other algorithms. Also, we find that Relief Attributes algorithm is the best to identify the most significant attributes in ASD datasets.
Spoken Language Interaction with Robots: Research Issues and Recommendations, Report from the NSF Future Directions Workshop
Nov 11, 2020
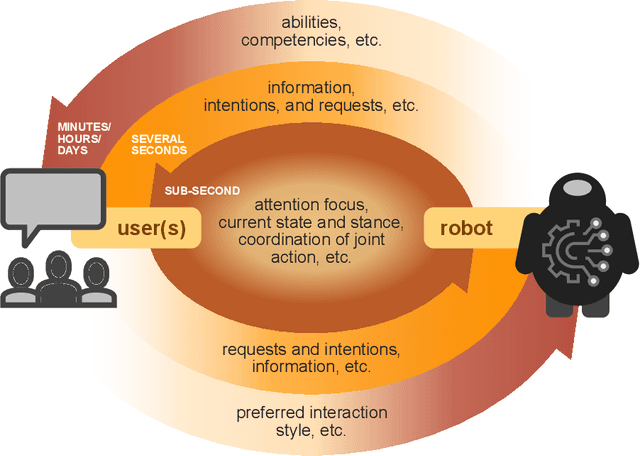
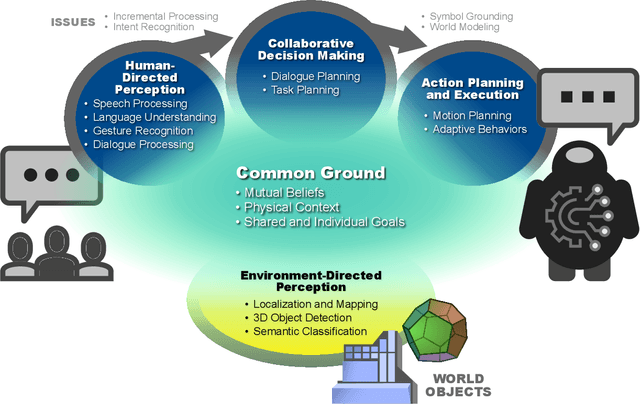
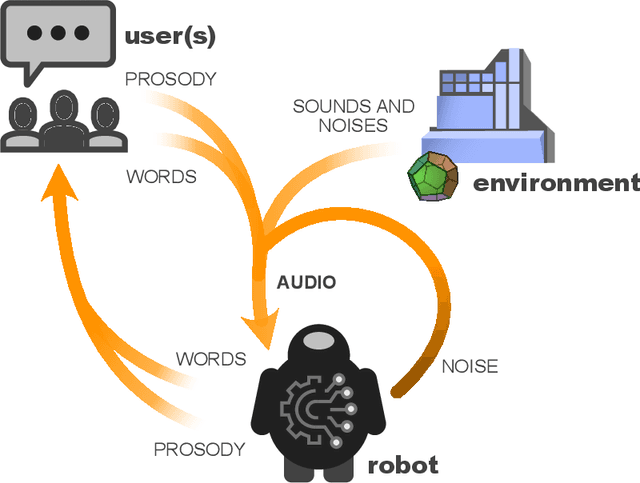
With robotics rapidly advancing, more effective human-robot interaction is increasingly needed to realize the full potential of robots for society. While spoken language must be part of the solution, our ability to provide spoken language interaction capabilities is still very limited. The National Science Foundation accordingly convened a workshop, bringing together speech, language, and robotics researchers to discuss what needs to be done. The result is this report, in which we identify key scientific and engineering advances needed. Our recommendations broadly relate to eight general themes. First, meeting human needs requires addressing new challenges in speech technology and user experience design. Second, this requires better models of the social and interactive aspects of language use. Third, for robustness, robots need higher-bandwidth communication with users and better handling of uncertainty, including simultaneous consideration of multiple hypotheses and goals. Fourth, more powerful adaptation methods are needed, to enable robots to communicate in new environments, for new tasks, and with diverse user populations, without extensive re-engineering or the collection of massive training data. Fifth, since robots are embodied, speech should function together with other communication modalities, such as gaze, gesture, posture, and motion. Sixth, since robots operate in complex environments, speech components need access to rich yet efficient representations of what the robot knows about objects, locations, noise sources, the user, and other humans. Seventh, since robots operate in real time, their speech and language processing components must also. Eighth, in addition to more research, we need more work on infrastructure and resources, including shareable software modules and internal interfaces, inexpensive hardware, baseline systems, and diverse corpora.
Stochastic Graph Recurrent Neural Network
Sep 01, 2020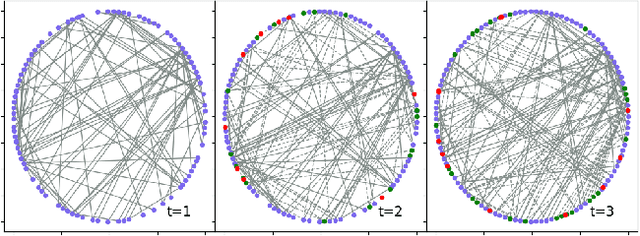
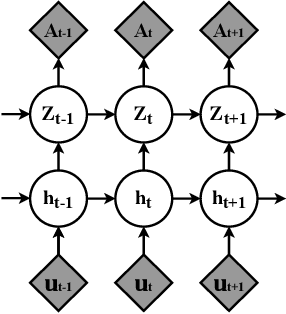
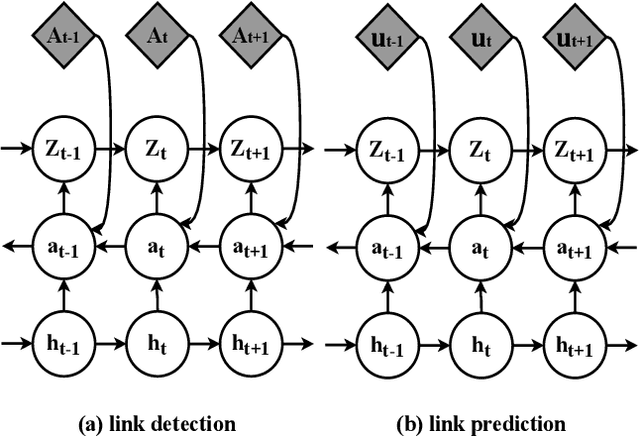
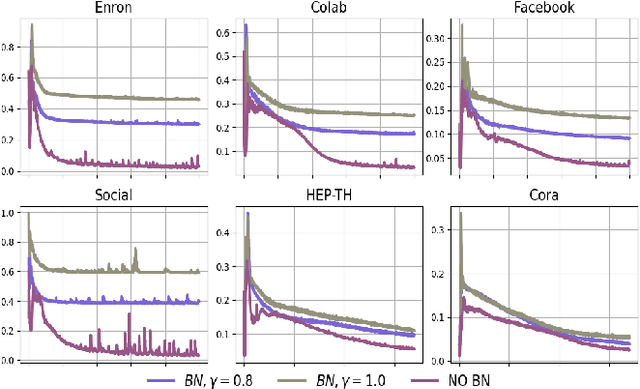
Representation learning over graph structure data has been widely studied due to its wide application prospects. However, previous methods mainly focus on static graphs while many real-world graphs evolve over time. Modeling such evolution is important for predicting properties of unseen networks. To resolve this challenge, we propose SGRNN, a novel neural architecture that applies stochastic latent variables to simultaneously capture the evolution in node attributes and topology. Specifically, deterministic states are separated from stochastic states in the iterative process to suppress mutual interference. With semi-implicit variational inference integrated to SGRNN, a non-Gaussian variational distribution is proposed to help further improve the performance. In addition, to alleviate KL-vanishing problem in SGRNN, a simple and interpretable structure is proposed based on the lower bound of KL-divergence. Extensive experiments on real-world datasets demonstrate the effectiveness of the proposed model. Code is available at https://github.com/StochasticGRNN/SGRNN.