 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Intraoperative Liver Surface Completion with Graph Convolutional VAE
Sep 08, 2020
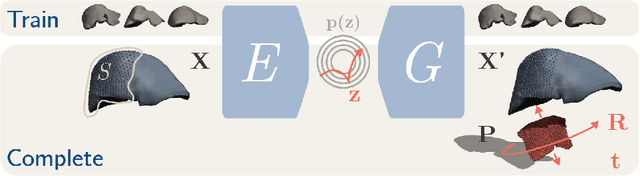

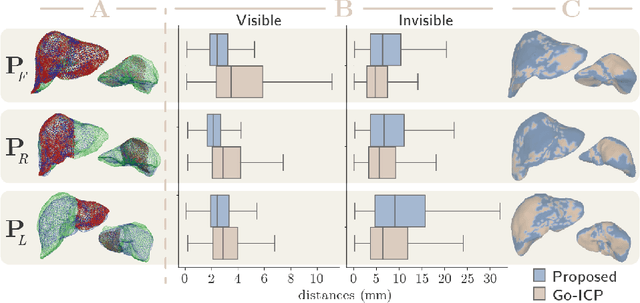
In this work we propose a method based on geometric deep learning to predict the complete surface of the liver, given a partial point cloud of the organ obtained during the surgical laparoscopic procedure. We introduce a new data augmentation technique that randomly perturbs shapes in their frequency domain to compensate the limited size of our dataset. The core of our method is a variational autoencoder (VAE) that is trained to learn a latent space for complete shapes of the liver. At inference time, the generative part of the model is embedded in an optimisation procedure where the latent representation is iteratively updated to generate a model that matches the intraoperative partial point cloud. The effect of this optimisation is a progressive non-rigid deformation of the initially generated shape. Our method is qualitatively evaluated on real data and quantitatively evaluated on synthetic data. We compared with a state-of-the-art rigid registration algorithm, that our method outperformed in visible areas.
Every Pixel Matters: Center-aware Feature Alignment for Domain Adaptive Object Detector
Aug 19, 2020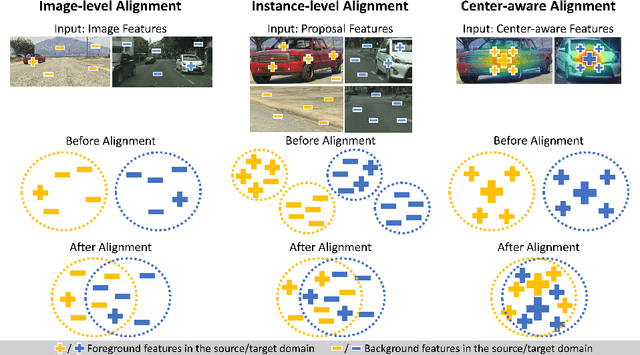
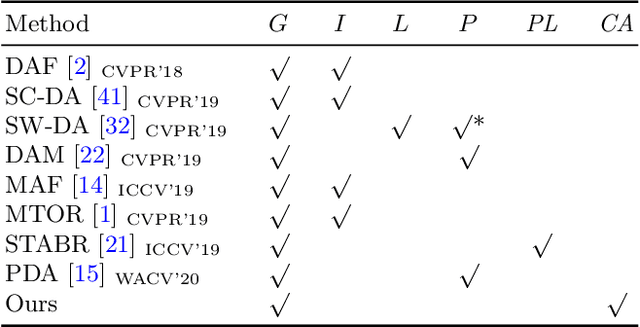
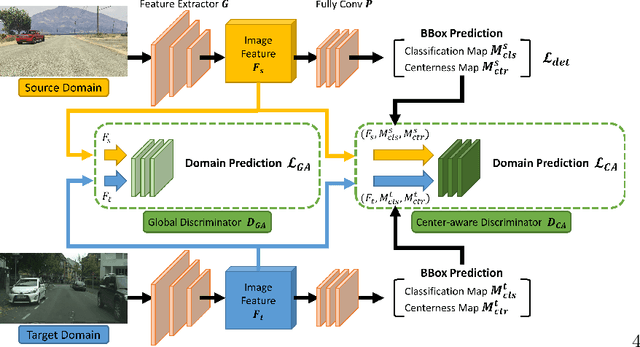
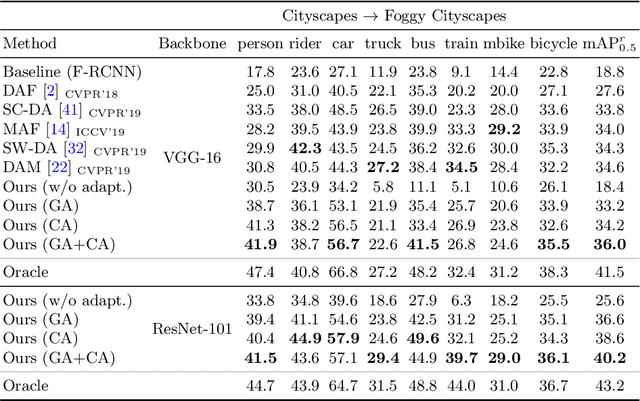
A domain adaptive object detector aims to adapt itself to unseen domains that may contain variations of object appearance, viewpoints or backgrounds. Most existing methods adopt feature alignment either on the image level or instance level. However, image-level alignment on global features may tangle foreground/background pixels at the same time, while instance-level alignment using proposals may suffer from the background noise. Different from existing solutions, we propose a domain adaptation framework that accounts for each pixel via predicting pixel-wise objectness and centerness. Specifically, the proposed method carries out center-aware alignment by paying more attention to foreground pixels, hence achieving better adaptation across domains. We demonstrate our method on numerous adaptation settings with extensive experimental results and show favorable performance against existing state-of-the-art algorithms.
ivadomed: A Medical Imaging Deep Learning Toolbox
Oct 20, 2020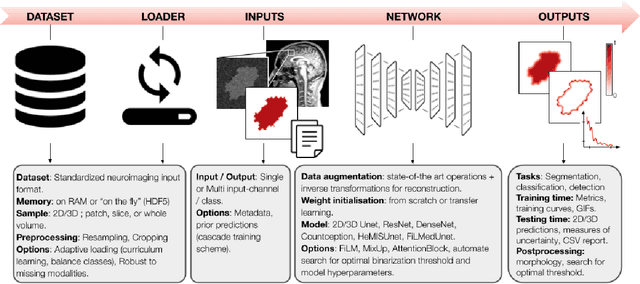
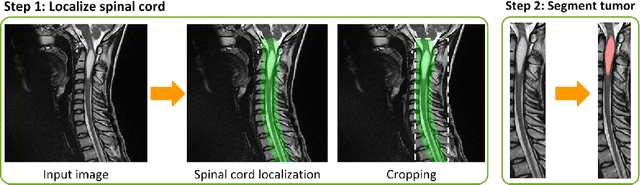
ivadomed is an open-source Python package for designing, end-to-end training, and evaluating deep learning models applied to medical imaging data. The package includes APIs, command-line tools, documentation, and tutorials. ivadomed also includes pre-trained models such as spinal tumor segmentation and vertebral labeling. Original features of ivadomed include a data loader that can parse image metadata (e.g., acquisition parameters, image contrast, resolution) and subject metadata (e.g., pathology, age, sex) for custom data splitting or extra information during training and evaluation. Any dataset following the Brain Imaging Data Structure (BIDS) convention will be compatible with ivadomed without the need to manually organize the data, which is typically a tedious task. Beyond the traditional deep learning methods, ivadomed features cutting-edge architectures, such as FiLM and HeMis, as well as various uncertainty estimation methods (aleatoric and epistemic), and losses adapted to imbalanced classes and non-binary predictions. Each step is conveniently configurable via a single file. At the same time, the code is highly modular to allow addition/modification of an architecture or pre/post-processing steps. Example applications of ivadomed include MRI object detection, segmentation, and labeling of anatomical and pathological structures. Overall, ivadomed enables easy and quick exploration of the latest advances in deep learning for medical imaging applications. ivadomed's main project page is available at https://ivadomed.org.
Improving Vietnamese Named Entity Recognition from Speech Using Word Capitalization and Punctuation Recovery Models
Oct 01, 2020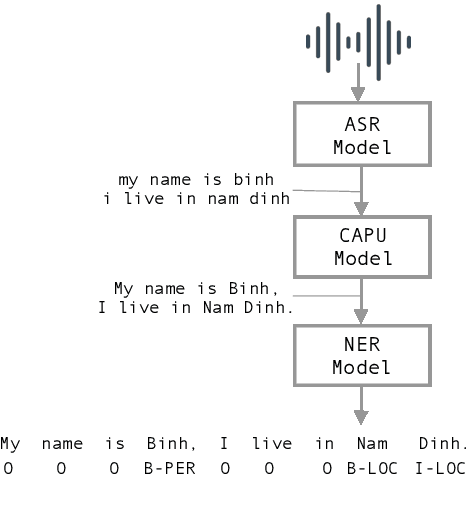

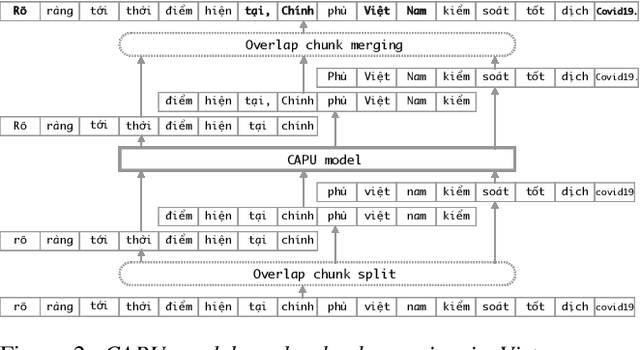
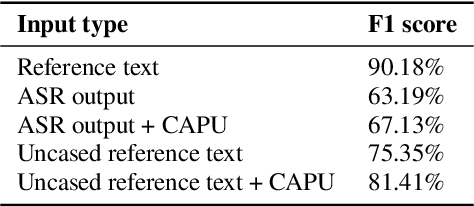
Studies on the Named Entity Recognition (NER) task have shown outstanding results that reach human parity on input texts with correct text formattings, such as with proper punctuation and capitalization. However, such conditions are not available in applications where the input is speech, because the text is generated from a speech recognition system (ASR), and that the system does not consider the text formatting. In this paper, we (1) presented the first Vietnamese speech dataset for NER task, and (2) the first pre-trained public large-scale monolingual language model for Vietnamese that achieved the new state-of-the-art for the Vietnamese NER task by 1.3% absolute F1 score comparing to the latest study. And finally, (3) we proposed a new pipeline for NER task from speech that overcomes the text formatting problem by introducing a text capitalization and punctuation recovery model (CaPu) into the pipeline. The model takes input text from an ASR system and performs two tasks at the same time, producing proper text formatting that helps to improve NER performance. Experimental results indicated that the CaPu model helps to improve by nearly 4% of F1-score.
ADABOOK & MULTIBOOK: Adaptive Boosting with Chance Correction
Oct 11, 2020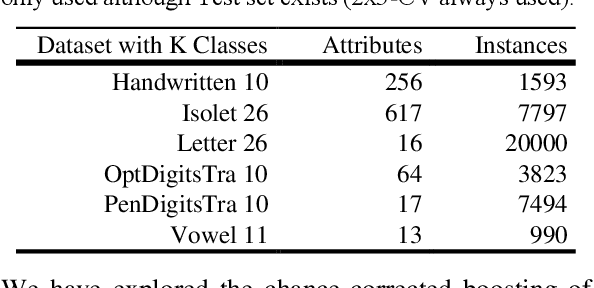
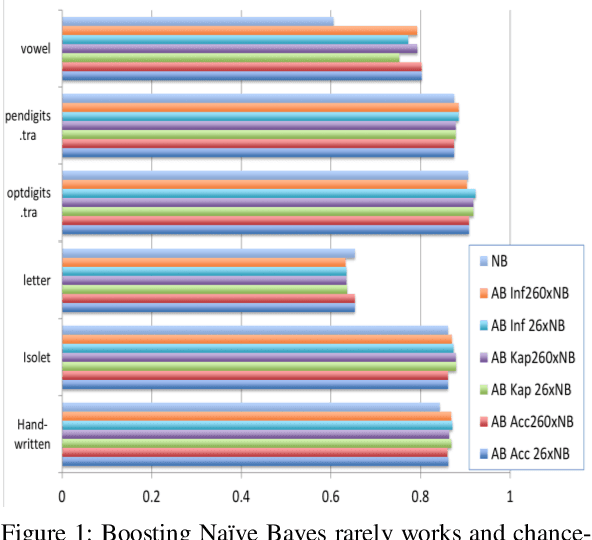
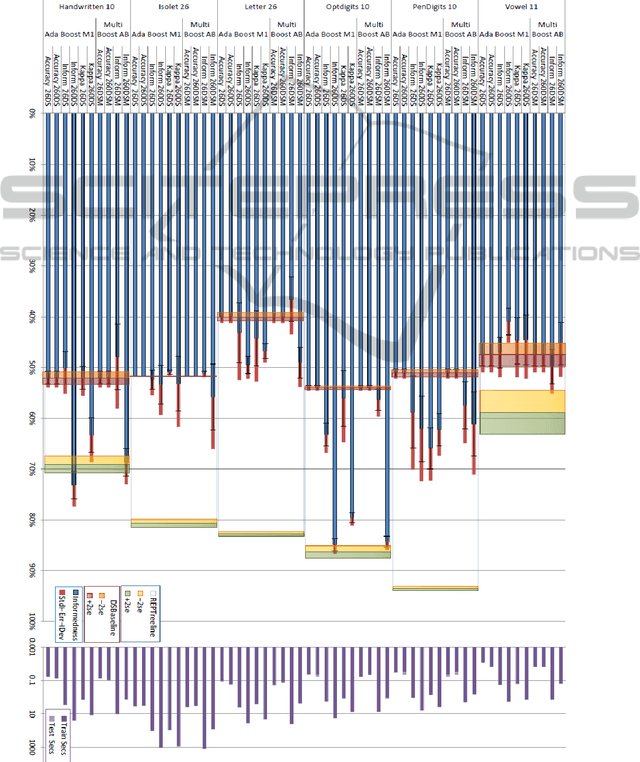
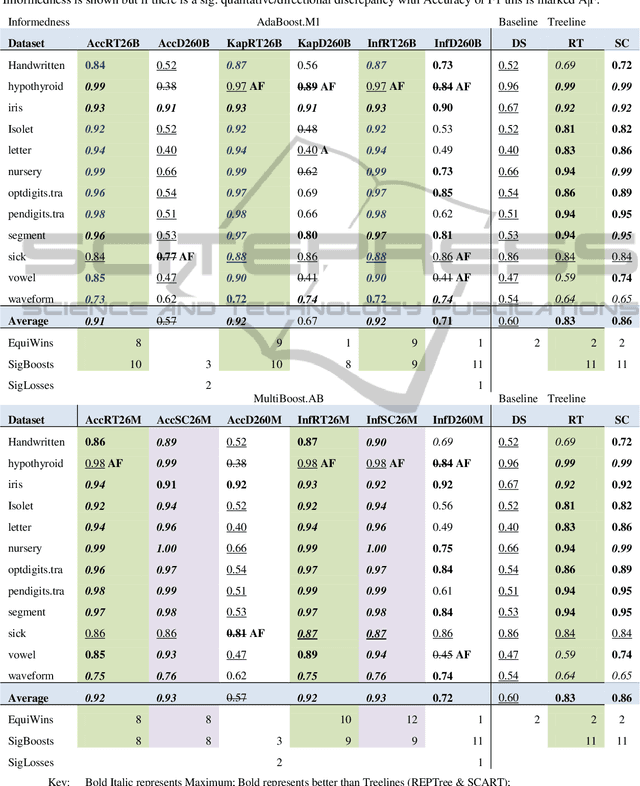
There has been considerable interest in boosting and bagging, including the combination of the adaptive techniques of AdaBoost with the random selection with replacement techniques of Bagging. At the same time there has been a revisiting of the way we evaluate, with chance-corrected measures like Kappa, Informedness, Correlation or ROC AUC being advocated. This leads to the question of whether learning algorithms can do better by optimizing an appropriate chance corrected measure. Indeed, it is possible for a weak learner to optimize Accuracy to the detriment of the more reaslistic chance-corrected measures, and when this happens the booster can give up too early. This phenomenon is known to occur with conventional Accuracy-based AdaBoost, and the MultiBoost algorithm has been developed to overcome such problems using restart techniques based on bagging. This paper thus complements the theoretical work showing the necessity of using chance-corrected measures for evaluation, with empirical work showing how use of a chance-corrected measure can improve boosting. We show that the early surrender problem occurs in MultiBoost too, in multiclass situations, so that chance-corrected AdaBook and Multibook can beat standard Multiboost or AdaBoost, and we further identify which chance-corrected measures to use when.
* 10 pages, 3 figures. This is an updated preprint of a paper presented at ICINCO2013
Stochastic Optimization Forests
Sep 08, 2020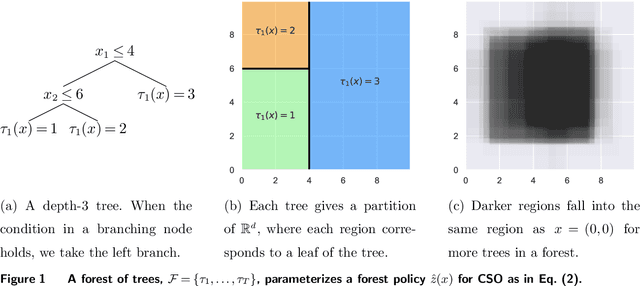

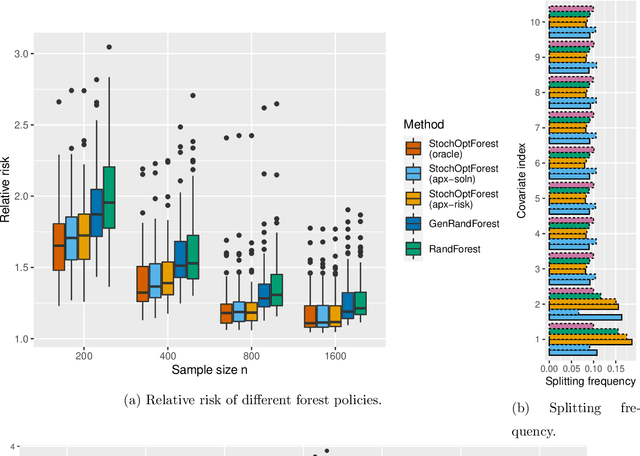
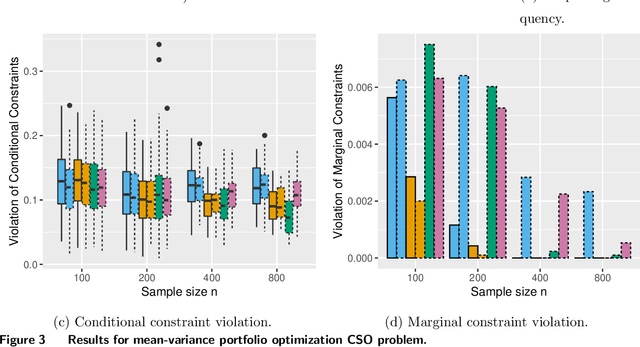
We study conditional stochastic optimization problems, where we leverage rich auxiliary observations (e.g., customer characteristics) to improve decision-making with uncertain variables (e.g., demand). We show how to train forest decision policies for this problem by growing trees that choose splits to directly optimize the downstream decision quality, rather than splitting to improve prediction accuracy as in the standard random forest algorithm. We realize this seemingly computationally intractable problem by developing approximate splitting criteria that utilize optimization perturbation analysis to eschew burdensome re-optimization for every candidate split, so that our method scales to large-scale problems. Our method can accommodate both deterministic and stochastic constraints. We prove that our splitting criteria consistently approximate the true risk. We extensively validate its efficacy empirically, demonstrating the value of optimization-aware construction of forests and the success of our efficient approximations. We show that our approximate splitting criteria can reduce running time hundredfold, while achieving performance close to forest algorithms that exactly re-optimize for every candidate split.
Dynamically Feasible Deep Reinforcement Learning Policy for Robot Navigation in Dense Mobile Crowds
Oct 28, 2020
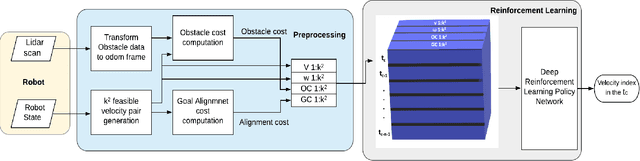
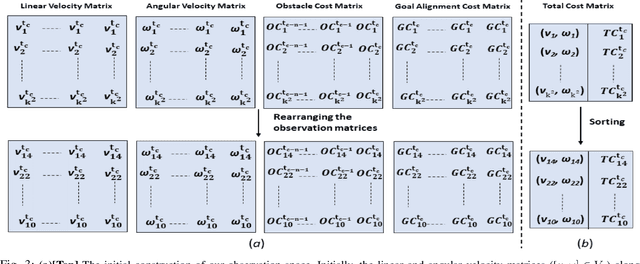
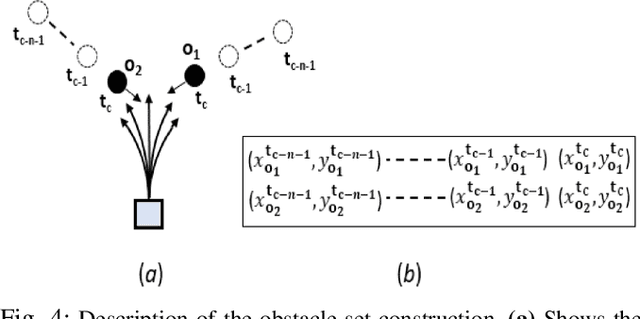
We present a novel Deep Reinforcement Learning (DRL) based policy for mobile robot navigation in dynamic environments that computes dynamically feasible and spatially aware robot velocities. Our method addresses two primary issues associated with the Dynamic Window Approach (DWA) and DRL-based navigation policies and solves them by using the benefits of one method to fix the issues of the other. The issues are: 1. DWA not utilizing the time evolution of the environment while choosing velocities from the dynamically feasible velocity set leading to sub-optimal dynamic collision avoidance behaviors, and 2. DRL-based navigation policies computing velocities that often violate the dynamics constraints such as the non-holonomic and acceleration constraints of the robot. Our DRL-based method generates velocities that are dynamically feasible while accounting for the motion of the obstacles in the environment. This is done by embedding the changes in the environment's state in a novel observation space and a reward function formulation that reinforces spatially aware obstacle avoidance maneuvers. We evaluate our method in realistic 3-D simulation and on a real differential drive robot in challenging indoor scenarios with crowds of varying densities. We make comparisons with traditional and current state-of-the-art collision avoidance methods and observe significant improvements in terms of collision rate, number of dynamics constraint violations and smoothness. We also conduct ablation studies to highlight the advantages and explain the rationale behind our observation space construction, reward structure and network architecture.
Automated Model Compression by Jointly Applied Pruning and Quantization
Nov 12, 2020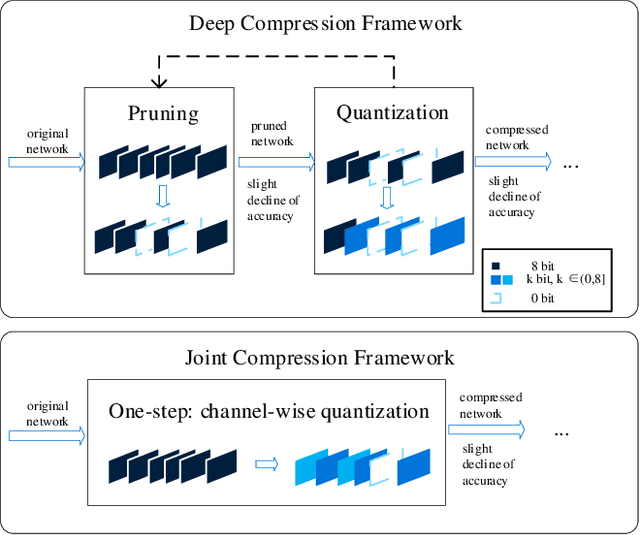
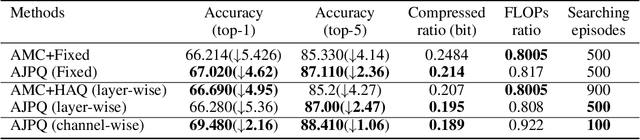
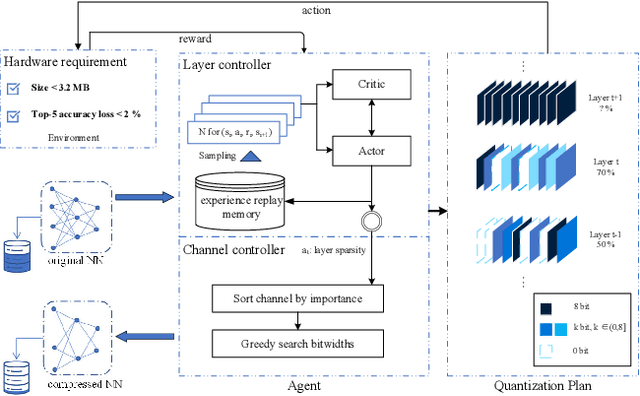
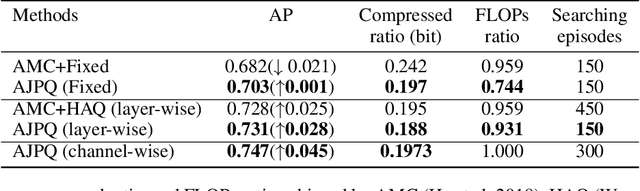
In the traditional deep compression framework, iteratively performing network pruning and quantization can reduce the model size and computation cost to meet the deployment requirements. However, such a step-wise application of pruning and quantization may lead to suboptimal solutions and unnecessary time consumption. In this paper, we tackle this issue by integrating network pruning and quantization as a unified joint compression problem and then use AutoML to automatically solve it. We find the pruning process can be regarded as the channel-wise quantization with 0 bit. Thus, the separate two-step pruning and quantization can be simplified as the one-step quantization with mixed precision. This unification not only simplifies the compression pipeline but also avoids the compression divergence. To implement this idea, we propose the automated model compression by jointly applied pruning and quantization (AJPQ). AJPQ is designed with a hierarchical architecture: the layer controller controls the layer sparsity, and the channel controller decides the bit-width for each kernel. Following the same importance criterion, the layer controller and the channel controller collaboratively decide the compression strategy. With the help of reinforcement learning, our one-step compression is automatically achieved. Compared with the state-of-the-art automated compression methods, our method obtains a better accuracy while reducing the storage considerably. For fixed precision quantization, AJPQ can reduce more than five times model size and two times computation with a slight performance increase for Skynet in remote sensing object detection. When mixed-precision is allowed, AJPQ can reduce five times model size with only 1.06% top-5 accuracy decline for MobileNet in the classification task.
Planning a Sequence of Base Positions for a Mobile Manipulator to Perform Multiple Pick-and-Place Tasks
Oct 01, 2020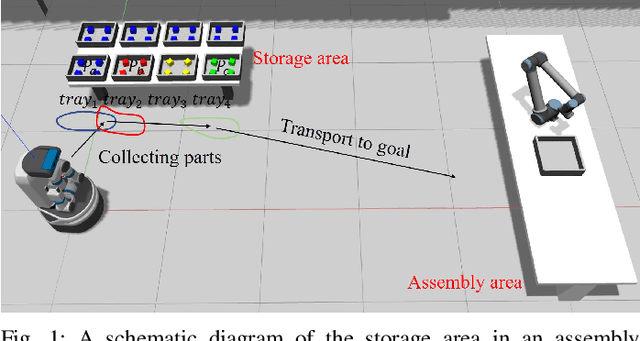
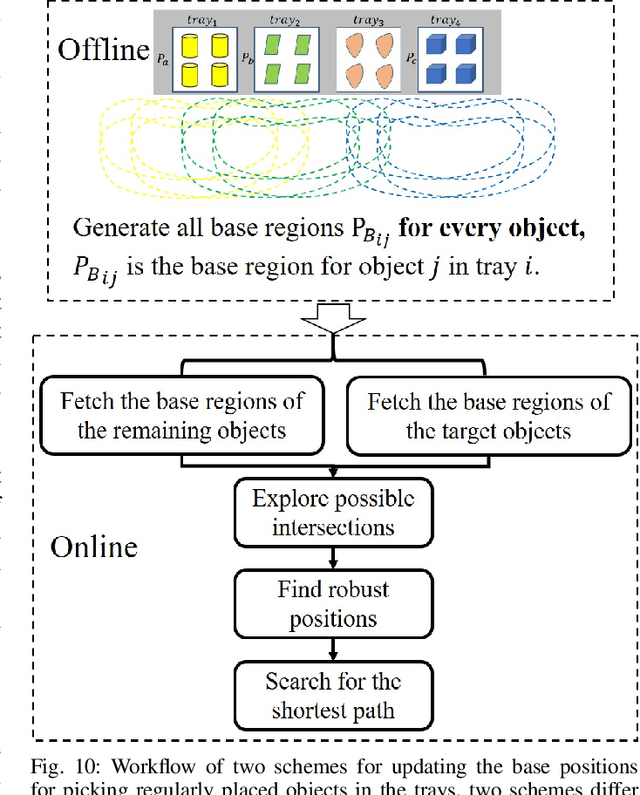
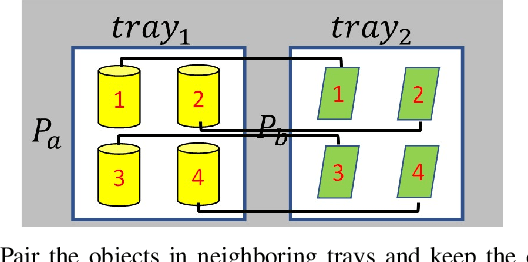
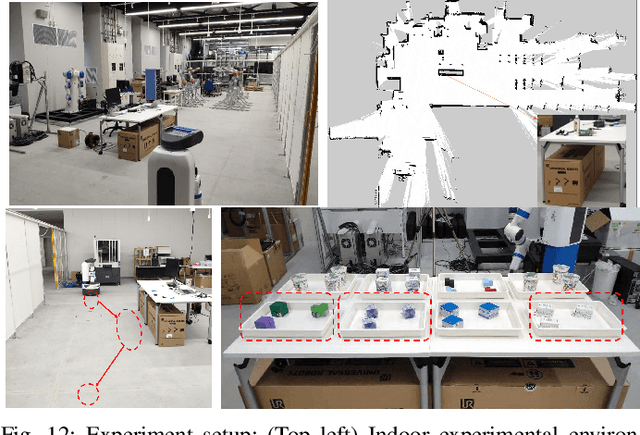
In this paper, we present a planner that plans a sequence of base positions for a mobile manipulator to efficiently and robustly collect objects stored in distinct trays. We achieve high efficiency by exploring the common areas where a mobile manipulator can grasp objects stored in multiple trays simultaneously and move the mobile manipulator to the common areas to reduce the time needed for moving the mobile base. We ensure robustness by optimizing the base position with the best clearance to positioning uncertainty so that a mobile manipulator can complete the task even if there is a certain deviation from the planned base positions. Besides, considering different styles of object placement in the tray, we analyze feasible schemes for dynamically updating the base positions based on either the remaining objects or the target objects to be picked in one round of the tasks. In the experiment part, we examine our planner on various scenarios, including different object placement: (1) Regularly placed toy objects; (2) Randomly placed industrial parts; and different schemes for online execution: (1) Apply globally static base positions; (2) Dynamically update the base positions. The experiment results demonstrate the efficiency, robustness and feasibility of the proposed method.
The More the Merrier?! Evaluating the Effect of Landmark Extraction Algorithms on Landmark-Based Goal Recognition
May 06, 2020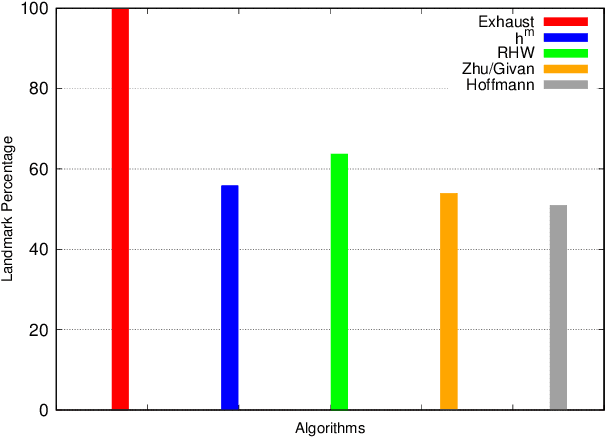
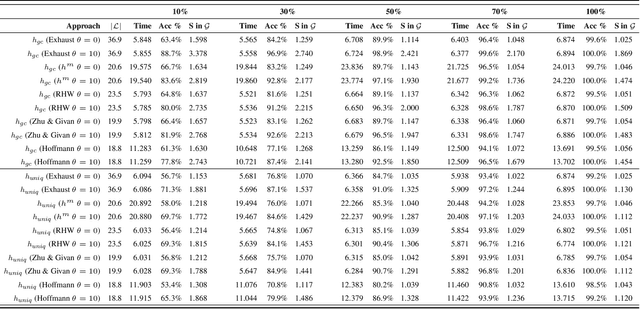
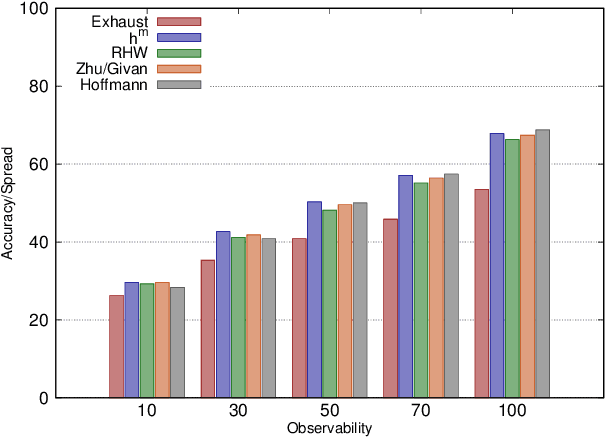
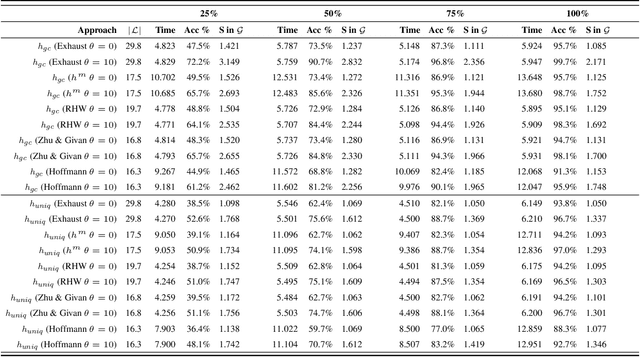
Recent approaches to goal and plan recognition using classical planning domains have achieved state of the art results in terms of both recognition time and accuracy by using heuristics based on planning landmarks. To achieve such fast recognition time these approaches use efficient, but incomplete, algorithms to extract only a subset of landmarks for planning domains and problems, at the cost of some accuracy. In this paper, we investigate the impact and effect of using various landmark extraction algorithms capable of extracting a larger proportion of the landmarks for each given planning problem, up to exhaustive landmark extraction. We perform an extensive empirical evaluation of various landmark-based heuristics when using different percentages of the full set of landmarks. Results show that having more landmarks does not necessarily mean achieving higher accuracy and lower spread, as the additional extracted landmarks may not necessarily increase be helpful towards the goal recognition task.