 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Spatio-temporal encoding improves neuromorphic tactile texture classification
Oct 27, 2020
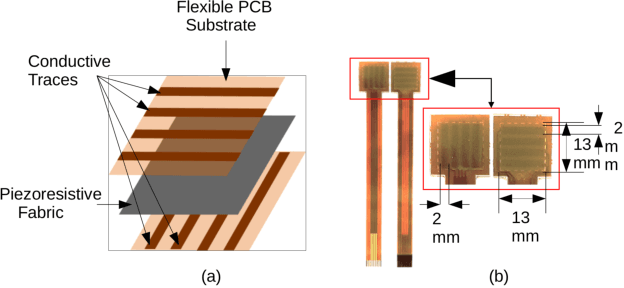


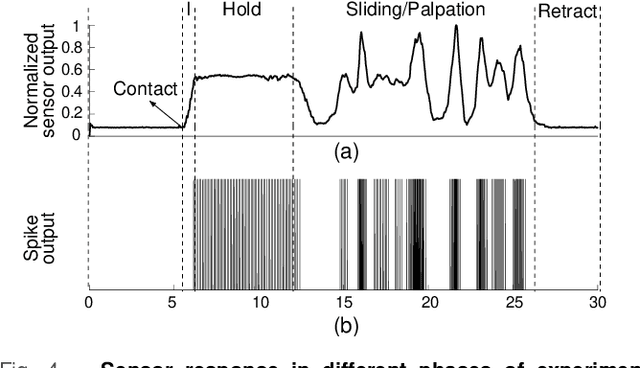
With the increase in interest in deployment of robots in unstructured environments to work alongside humans, the development of human-like sense of touch for robots becomes important. In this work, we implement a multi-channel neuromorphic tactile system that encodes contact events as discrete spike events that mimic the behavior of slow adapting mechanoreceptors. We study the impact of information pooling across artificial mechanoreceptors on classification performance of spatially non-uniform naturalistic textures. We encoded the spatio-temporal activation patterns of mechanoreceptors through gray-level co-occurrence matrix computed from time-varying mean spiking rate-based tactile response volume. We found that this approach greatly improved texture classification in comparison to use of individual mechanoreceptor response alone. In addition, the performance was also more robust to changes in sliding velocity. The importance of exploiting precise spatial and temporal correlations between sensory channels is evident from the fact that on either removal of precise temporal information or altering of spatial structure of response pattern, a significant performance drop was observed. This study thus demonstrates the superiority of population coding approaches that can exploit the precise spatio-temporal information encoded in activation patterns of mechanoreceptor populations. It, therefore, makes an advance in the direction of development of bio-inspired tactile systems required for realistic touch applications in robotics and prostheses.
Performance of Bounded-Rational Agents With the Ability to Self-Modify
Nov 12, 2020Self-modification of agents embedded in complex environments is hard to avoid, whether it happens via direct means (e.g. own code modification) or indirectly (e.g. influencing the operator, exploiting bugs or the environment). While it has been argued that intelligent agents have an incentive to avoid modifying their utility function so that their future instances will work towards the same goals, it is not clear whether this also applies in non-dualistic scenarios, where the agent is embedded in the environment. The problem of self-modification safety is raised by Bostrom in Superintelligence (2014) in the context of safe AGI deployment. In contrast to Everitt et al. (2016), who formally show that providing an option to self-modify is harmless for perfectly rational agents, we show that for agents with bounded rationality, self-modification may cause exponential deterioration in performance and gradual misalignment of a previously aligned agent. We investigate how the size of this effect depends on the type and magnitude of imperfections in the agent's rationality (1-4 below). We also discuss model assumptions and the wider problem and framing space. Specifically, we introduce several types of a bounded-rational agent, which either (1) doesn't always choose the optimal action, (2) is not perfectly aligned with human values, (3) has an innacurate model of the environment, or (4) uses the wrong temporal discounting factor. We show that while in the cases (2)-(4) the misalignment caused by the agent's imperfection does not worsen over time, with (1) the misalignment may grow exponentially.
A Follow-the-Leader Strategy using Hierarchical Deep Neural Networks with Grouped Convolutions
Nov 04, 2020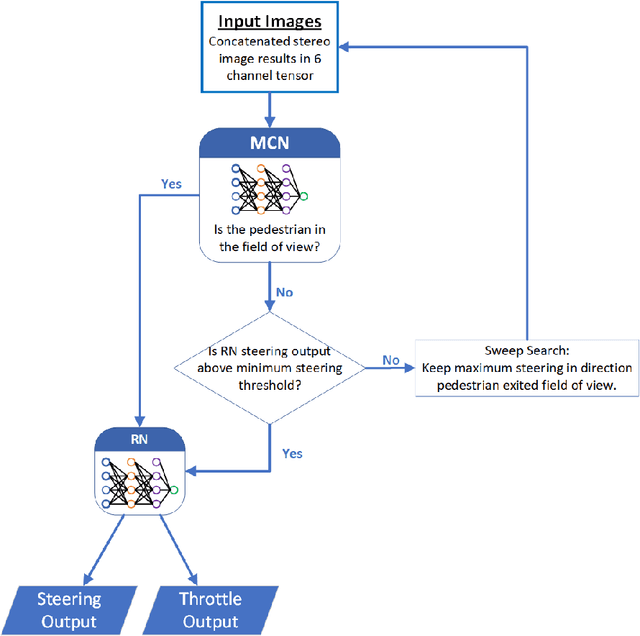
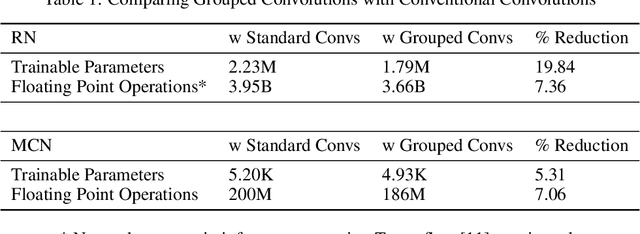
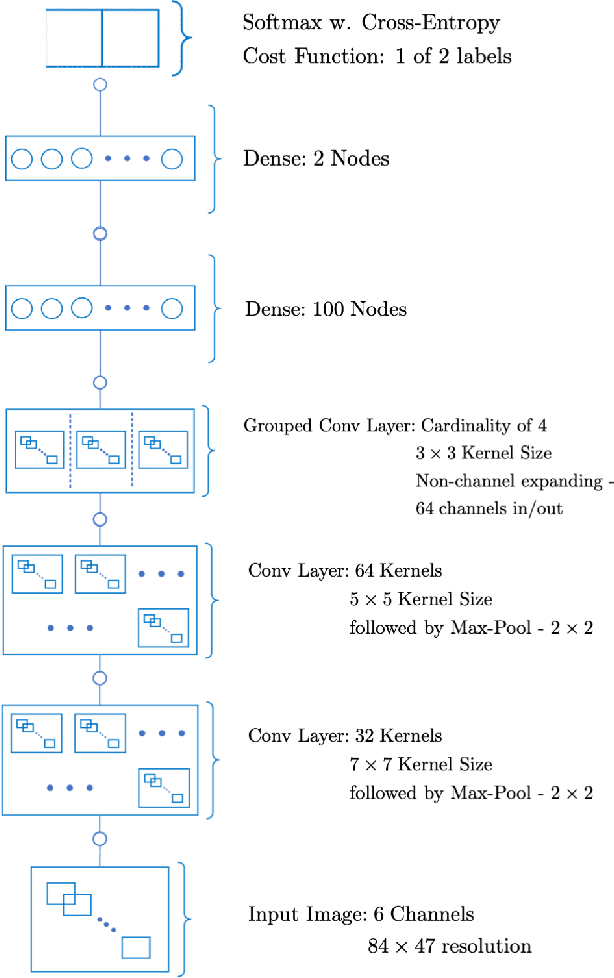

The task of following-the-leader is implemented using a hierarchical Deep Neural Network (DNN) end-to-end driving model to match the direction and speed of a target pedestrian. The model uses a classifier DNN to determine if the pedestrian is within the field of view of the camera sensor. If the pedestrian is present, the image stream from the camera is fed to a regression DNN which simultaneously adjusts the autonomous vehicle's steering and throttle to keep cadence with the pedestrian. If the pedestrian is not visible, the vehicle uses a straightforward exploratory search strategy to reacquire the tracking objective. The classifier and regression DNNs incorporate grouped convolutions to boost model performance as well as to significantly reduce parameter count and compute latency. The models are trained on the Intelligence Processing Unit (IPU) to leverage its fine-grain compute capabilities in order to minimize time-to-train. The results indicate very robust tracking behavior on the part of the autonomous vehicle in terms of its steering and throttle profiles, which required minimal data collection to produce. The throughput in terms of processing training samples has been boosted by the use of the IPU in conjunction with grouped convolutions by a factor ${\sim}3.5$ for training of the classifier and a factor of ${\sim}7$ for the regression network. A recording of the vehicle tracking a pedestrian has been produced and is available on the web.
Investigating Class-level Difficulty Factors in Multi-label Classification Problems
May 01, 2020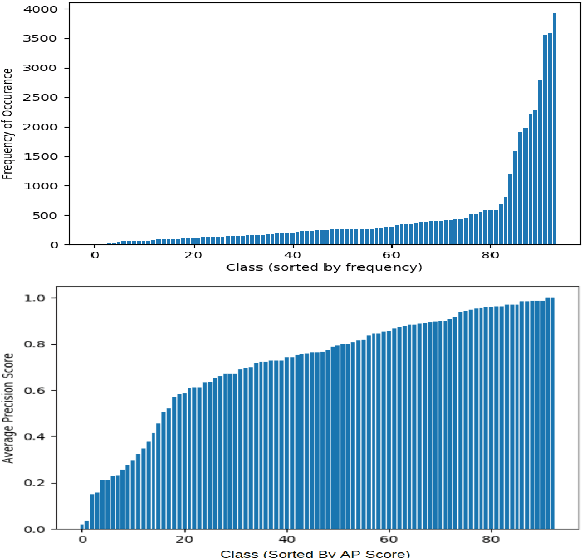

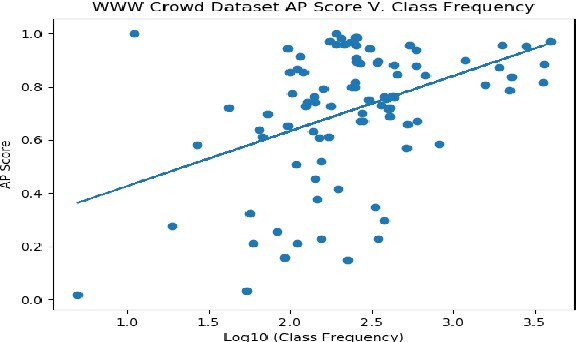

This work investigates the use of class-level difficulty factors in multi-label classification problems for the first time. Four class-level difficulty factors are proposed: frequency, visual variation, semantic abstraction, and class co-occurrence. Once computed for a given multi-label classification dataset, these difficulty factors are shown to have several potential applications including the prediction of class-level performance across datasets and the improvement of predictive performance through difficulty weighted optimisation. Significant improvements to mAP and AUC performance are observed for two challenging multi-label datasets (WWW Crowd and Visual Genome) with the inclusion of difficulty weighted optimisation. The proposed technique does not require any additional computational complexity during training or inference and can be extended over time with inclusion of other class-level difficulty factors.
Hybrid quantum-classical optimization for financial index tracking
Aug 27, 2020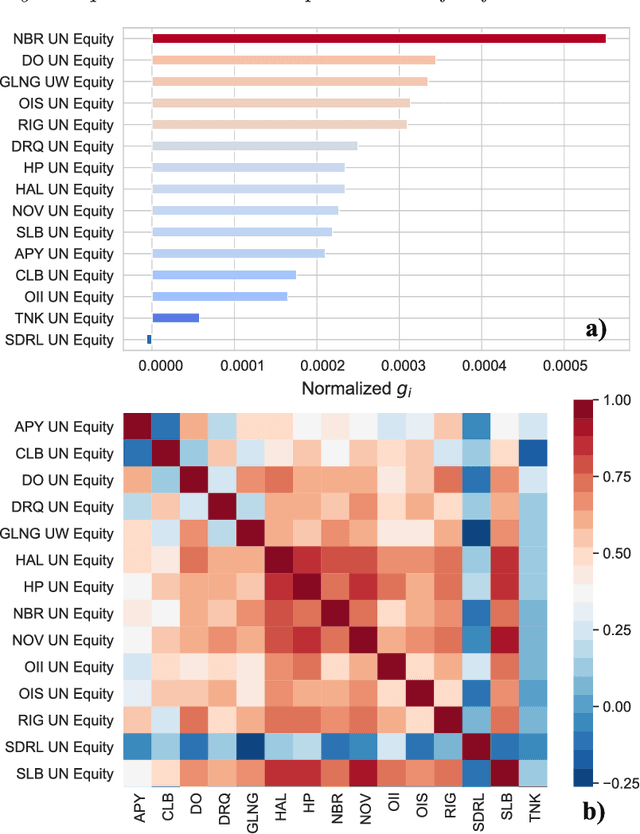
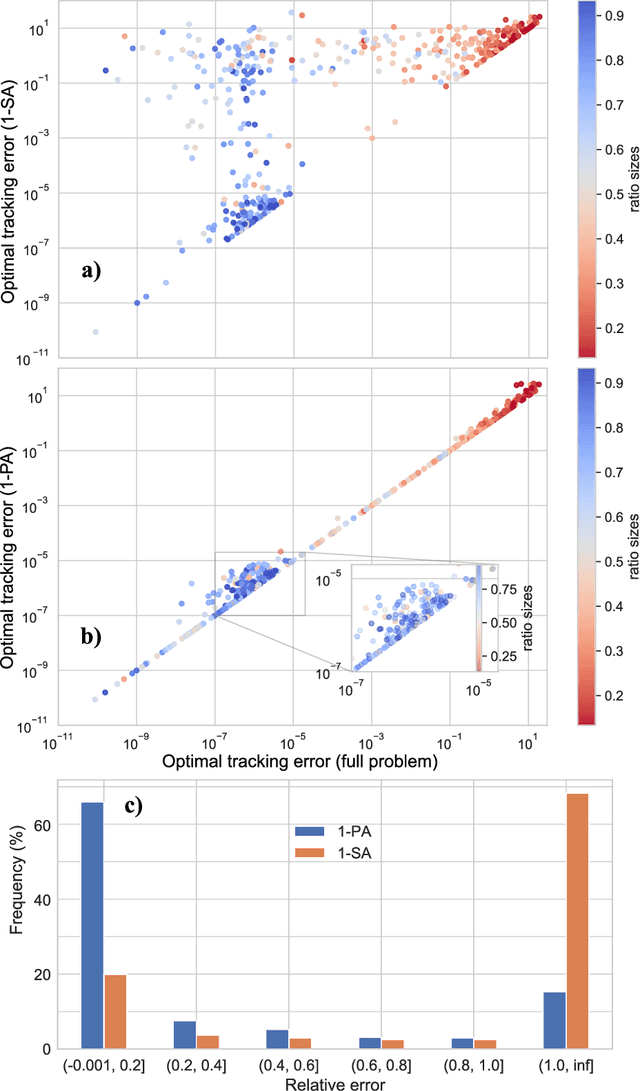
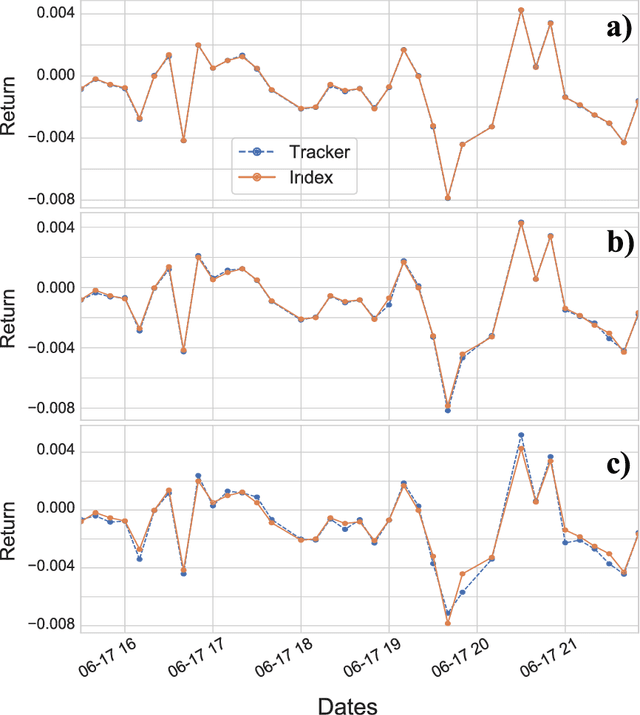
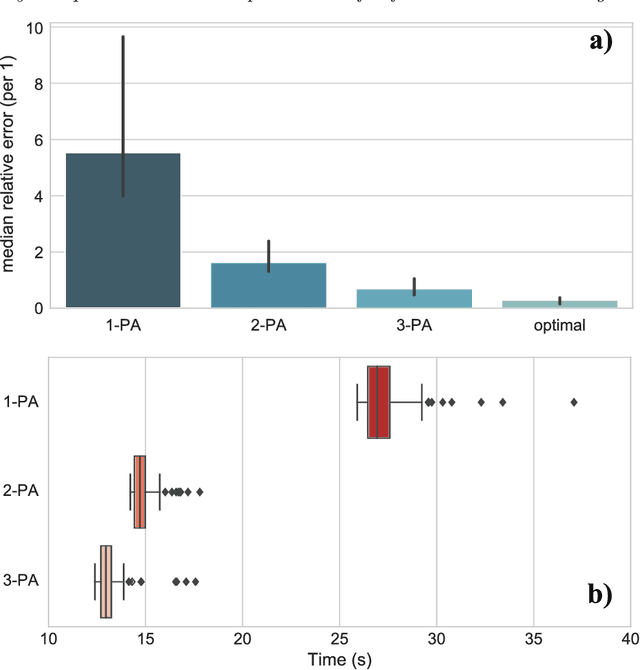
Tracking a financial index boils down to replicating its trajectory of returns for a well-defined time span by investing in a weighted subset of the securities included in the benchmark. Picking the optimal combination of assets becomes a challenging NP-hard problem even for moderately large indices consisting of dozens or hundreds of assets, thereby requiring heuristic methods to find approximate solutions. Hybrid quantum-classical optimization with variational gate-based quantum circuits arises as a plausible method to improve performance of current schemes. In this work we introduce a heuristic pruning algorithm to find weighted combinations of assets subject to cardinality constraints. We further consider different strategies to respect such constraints and compare the performance of relevant quantum ans\"{a}tze and classical optimizers through numerical simulations.
Extremely Low Bit Transformer Quantization for On-Device Neural Machine Translation
Sep 16, 2020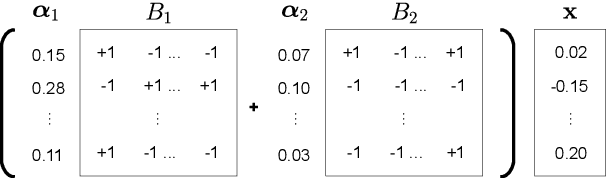
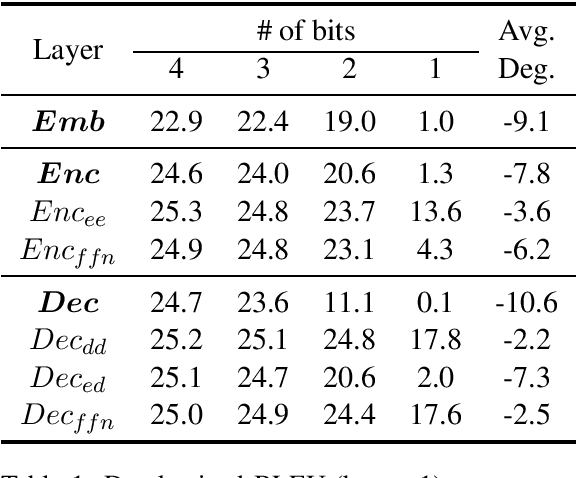
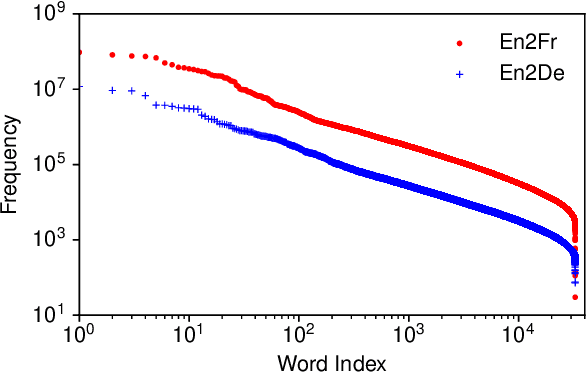
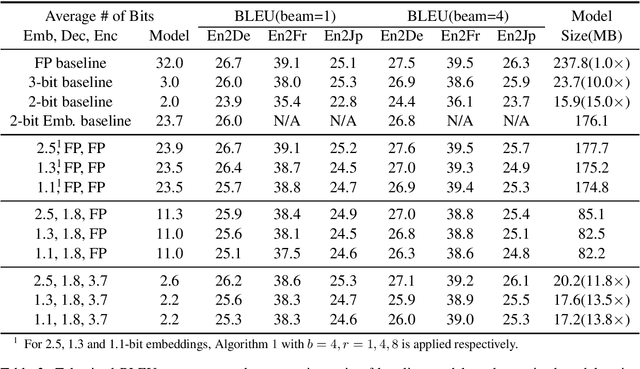
Transformer is being widely used in Neural Machine Translation (NMT). Deploying Transformer models to mobile or edge devices with limited resources is challenging because of heavy computation and memory overhead during inference. Quantization is an effective technique to address such challenges. Our analysis shows that for a given number of quantization bits, each block of Transformer contributes to translation accuracy and inference computations in different manners. Moreover, even inside an embedding block, each word presents vastly different contributions. Correspondingly, we propose a mixed precision quantization strategy to represent Transformer weights with lower bits (e.g. under 3 bits). For example, for each word in an embedding block, we assign different quantization bits based on statistical property. Our quantized Transformer model achieves 11.8x smaller model size than the baseline model, with less than -0.5 BLEU. We achieve 8.3x reduction in run-time memory footprints and 3.5x speed up (Galaxy N10+) such that our proposed compression strategy enables efficient implementation for on-device NMT.
Adaptive Reinforcement Learning through Evolving Self-Modifying Neural Networks
May 22, 2020
The adaptive learning capabilities seen in biological neural networks are largely a product of the self-modifying behavior emerging from online plastic changes in synaptic connectivity. Current methods in Reinforcement Learning (RL) only adjust to new interactions after reflection over a specified time interval, preventing the emergence of online adaptivity. Recent work addressing this by endowing artificial neural networks with neuromodulated plasticity have been shown to improve performance on simple RL tasks trained using backpropagation, but have yet to scale up to larger problems. Here we study the problem of meta-learning in a challenging quadruped domain, where each leg of the quadruped has a chance of becoming unusable, requiring the agent to adapt by continuing locomotion with the remaining limbs. Results demonstrate that agents evolved using self-modifying plastic networks are more capable of adapting to complex meta-learning learning tasks, even outperforming the same network updated using gradient-based algorithms while taking less time to train.
* GECCO'2020 Poster: Submitted and accepted
Towards Efficient Scheduling of Federated Mobile Devices under Computational and Statistical Heterogeneity
May 25, 2020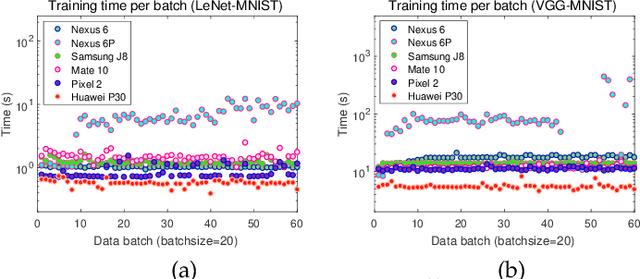
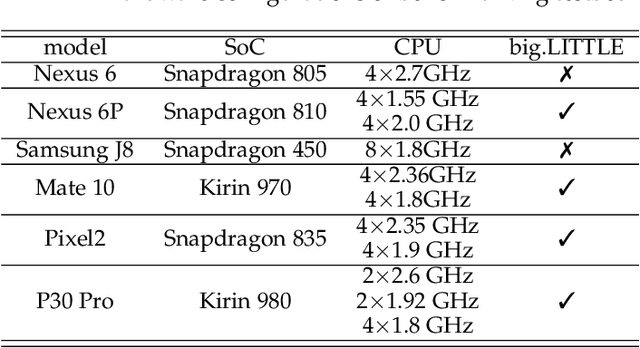
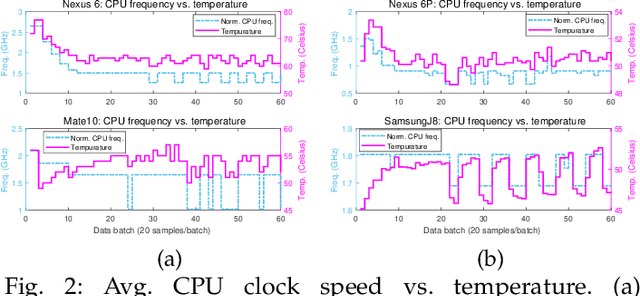

Originated from distributed learning, federated learning enables privacy-preserved collaboration on a new abstracted level by sharing the model parameters only. While the current research mainly focuses on optimizing learning algorithms and minimizing communication overhead left by distributed learning, there is still a considerable gap when it comes to the real implementation on mobile devices. In this paper, we start with an empirical experiment to demonstrate computation heterogeneity is a more pronounced bottleneck than communication on the current generation of battery-powered mobile devices, and the existing methods are haunted by mobile stragglers. Further, non-identically distributed data across the mobile users makes the selection of participants critical to the accuracy and convergence. To tackle the computational and statistical heterogeneity, we utilize data as a tunable knob and propose two efficient polynomial-time algorithms to schedule different workloads on various mobile devices, when data is identically or non-identically distributed. For identically distributed data, we combine partitioning and linear bottleneck assignment to achieve near-optimal training time without accuracy loss. For non-identically distributed data, we convert it into an average cost minimization problem and propose a greedy algorithm to find a reasonable balance between computation time and accuracy. We also establish an offline profiler to quantify the runtime behavior of different devices, which serves as the input to the scheduling algorithms. We conduct extensive experiments on a mobile testbed with two datasets and up to 20 devices. Compared with the common benchmarks, the proposed algorithms achieve 2-100x speedup epoch-wise, 2-7% accuracy gain and boost the convergence rate by more than 100% on CIFAR10.
Self-Supervised Scale Recovery for Monocular Depth and Egomotion Estimation
Sep 09, 2020

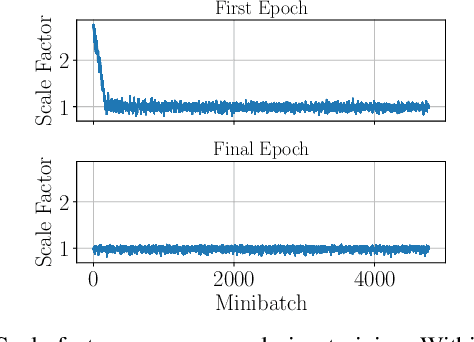
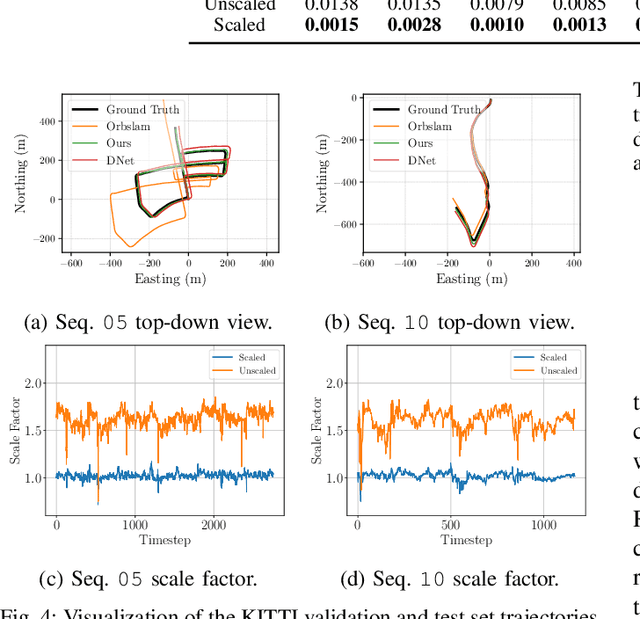
The self-supervised loss formulation for jointly training depth and egomotion neural networks with monocular images is well studied and has demonstrated state-of-the-art accuracy. One of the main limitations of this approach, however, is that the depth and egomotion estimates are only determined up to an unknown scale. In this paper, we present a novel scale recovery loss that enforces consistency between a known camera height and the estimated camera height, generating metric (scaled) depth and egomotion predictions. We show that our proposed method is competitive with other scale recovery techniques (i.e., pose supervision and stereo left/right consistency constraints). Further, we demonstrate how our method facilitates network retraining within new environments, whereas other scale-resolving approaches are incapable of doing so. Notably, our egomotion network is able to produce more accurate estimates than a similar method that only recovers scale at test time.
A Computationally Efficient Approach to Black-box Optimization using Gaussian Process Models
Oct 27, 2020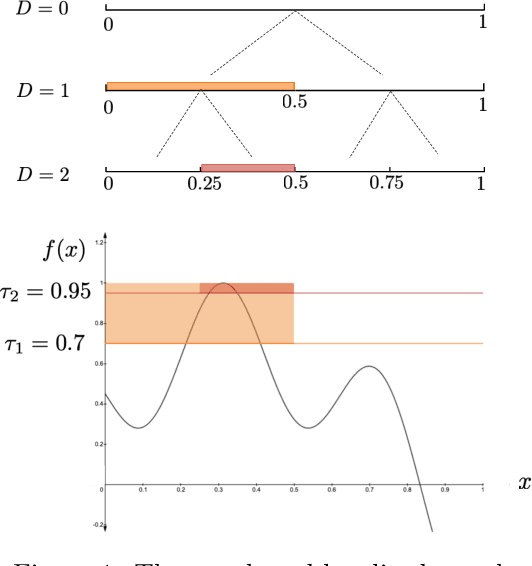
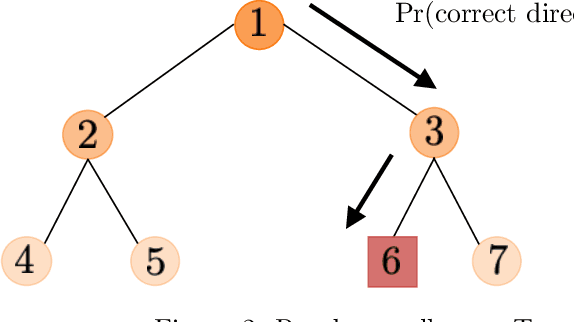
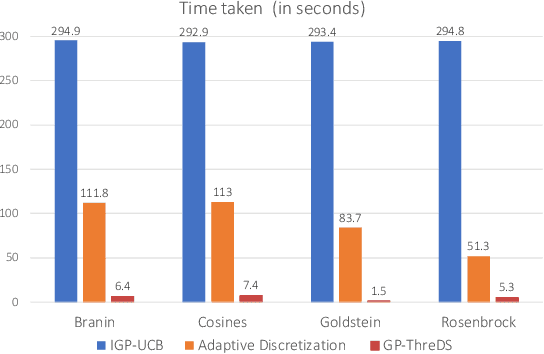
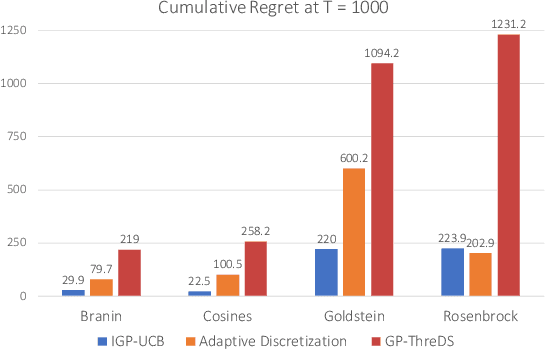
We consider the sequential optimization of an unknown function from noisy feedback using Gaussian process modeling. A prevailing approach to this problem involves choosing query points based on finding the maximum of an upper confidence bound (UCB) score over the entire domain of the function. Due to the multi-modal nature of the UCB, this maximization can only be approximated, usually using an increasingly fine sequence of discretizations of the entire domain, making such methods computationally prohibitive. We propose a general approach that reduces the computational complexity of this class of algorithms by a factor of $O(T^{2d-1})$ (where $T$ is the time horizon and $d$ the dimension of the function domain), while preserving the same regret order. The significant reduction in computational complexity results from two key features of the proposed approach: (i) a tree-based localized search strategy rooted in the methodology of domain shrinking to achieve increasing accuracy with a constant-size discretization; (ii) a localized optimization with the objective relaxed from a global maximizer to any point with value exceeding a given threshold, where the threshold is updated iteratively to approach the maximum as the search deepens. More succinctly, the proposed optimization strategy is a sequence of localized searches in the domain of the function guided by an iterative search in the range of the function to approach the maximum.