 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Reconfigurable Behavior Trees: Towards an Executive Framework Meeting High-level Decision Making and Control Layer Features
Aug 31, 2020
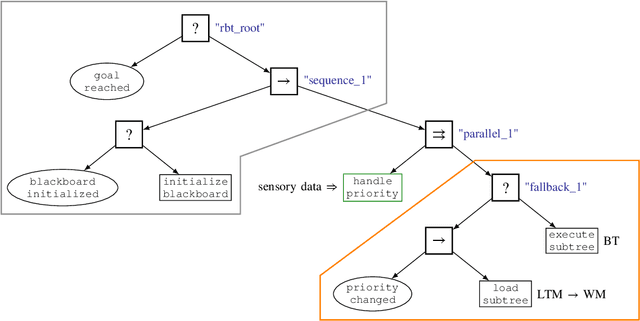
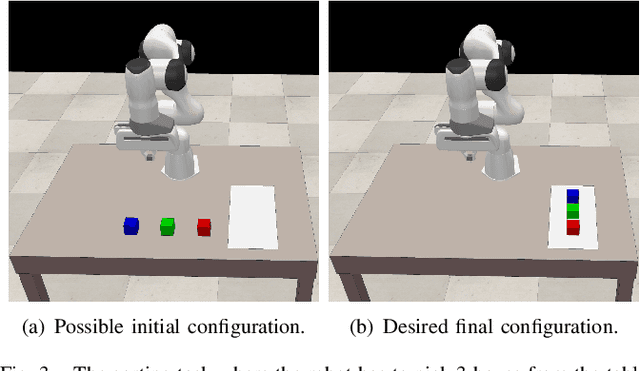
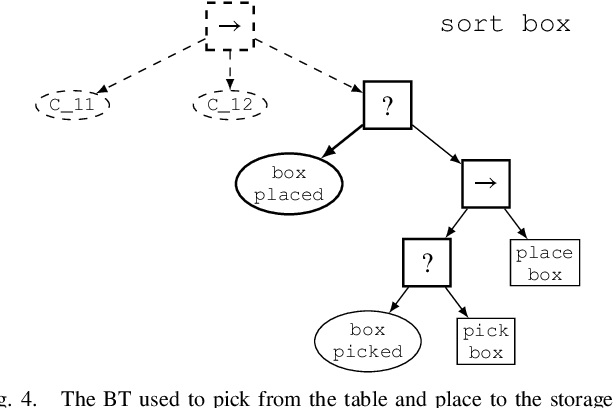
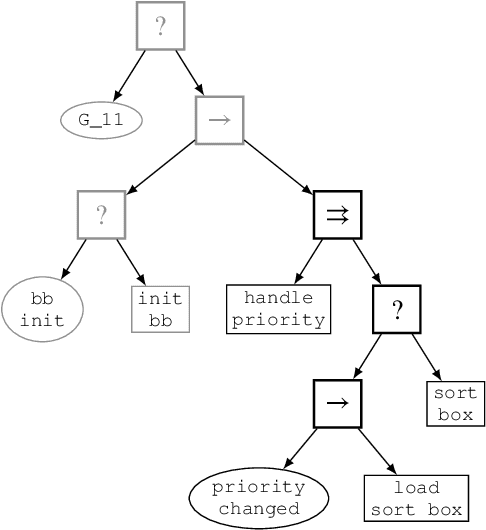
Behavior Trees constitute a widespread AI tool which has been successfully spun out in robotics. Their advantages include simplicity, modularity, and reusability of code. However, Behavior Trees remain a high-level decision making engine; control features cannot be easily integrated. This paper proposes the Reconfigurable Behavior Trees (RBTs), an extension of the traditional BTs that considers physical constraints from the robotic environment in the decision making process. We endow RBTs with continuous sensory information that permits the online monitoring of the task execution. The resulting stimulus-driven architecture is capable of dynamically handling changes in the executive context while keeping the execution time low. The proposed framework is evaluated on a set of robotic experiments. The results show that RBTs are a promising approach for robotic task representation, monitoring, and execution.
Repulsive Attention: Rethinking Multi-head Attention as Bayesian Inference
Sep 20, 2020
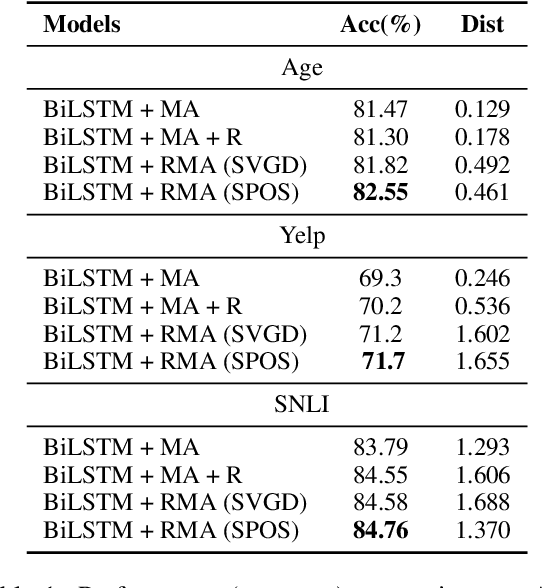
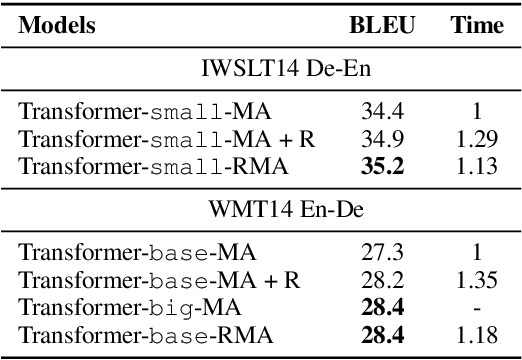
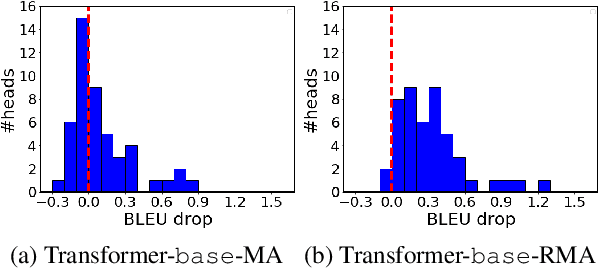
The neural attention mechanism plays an important role in many natural language processing applications. In particular, the use of multi-head attention extends single-head attention by allowing a model to jointly attend information from different perspectives. Without explicit constraining, however, multi-head attention may suffer from attention collapse, an issue that makes different heads extract similar attentive features, thus limiting the model's representation power. In this paper, for the first time, we provide a novel understanding of multi-head attention from a Bayesian perspective. Based on the recently developed particle-optimization sampling techniques, we propose a non-parametric approach that explicitly improves the repulsiveness in multi-head attention and consequently strengthens model's expressiveness. Remarkably, our Bayesian interpretation provides theoretical inspirations on the not-well-understood questions: why and how one uses multi-head attention. Extensive experiments on various attention models and applications demonstrate that the proposed repulsive attention can improve the learned feature diversity, leading to more informative representations with consistent performance improvement on various tasks.
A comparison of Vietnamese Statistical Parametric Speech Synthesis Systems
May 26, 2020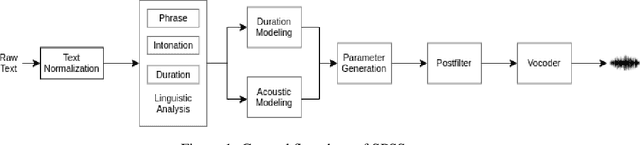
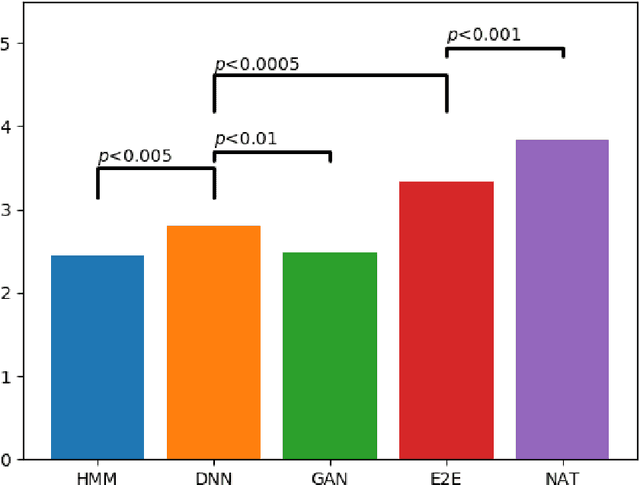
In recent years, statistical parametric speech synthesis (SPSS) systems have been widely utilized in many interactive speech-based systems (e.g.~Amazon's Alexa, Bose's headphones). To select a suitable SPSS system, both speech quality and performance efficiency (e.g.~decoding time) must be taken into account. In the paper, we compared four popular Vietnamese SPSS techniques using: 1) hidden Markov models (HMM), 2) deep neural networks (DNN), 3) generative adversarial networks (GAN), and 4) end-to-end (E2E) architectures, which consists of Tacontron~2 and WaveGlow vocoder in terms of speech quality and performance efficiency. We showed that the E2E systems accomplished the best quality, but required the power of GPU to achieve real-time performance. We also showed that the HMM-based system had inferior speech quality, but it was the most efficient system. Surprisingly, the E2E systems were more efficient than the DNN and GAN in inference on GPU. Surprisingly, the GAN-based system did not outperform the DNN in term of quality.
Modeling emotion in complex stories: the Stanford Emotional Narratives Dataset
Nov 22, 2019
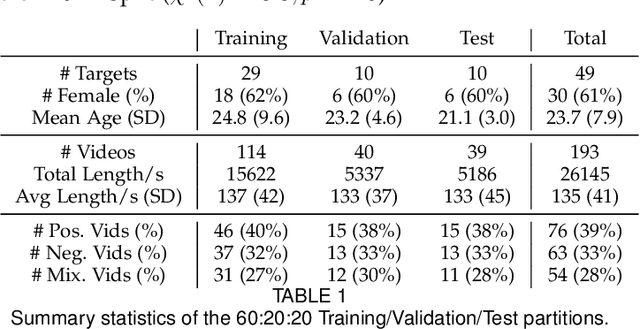
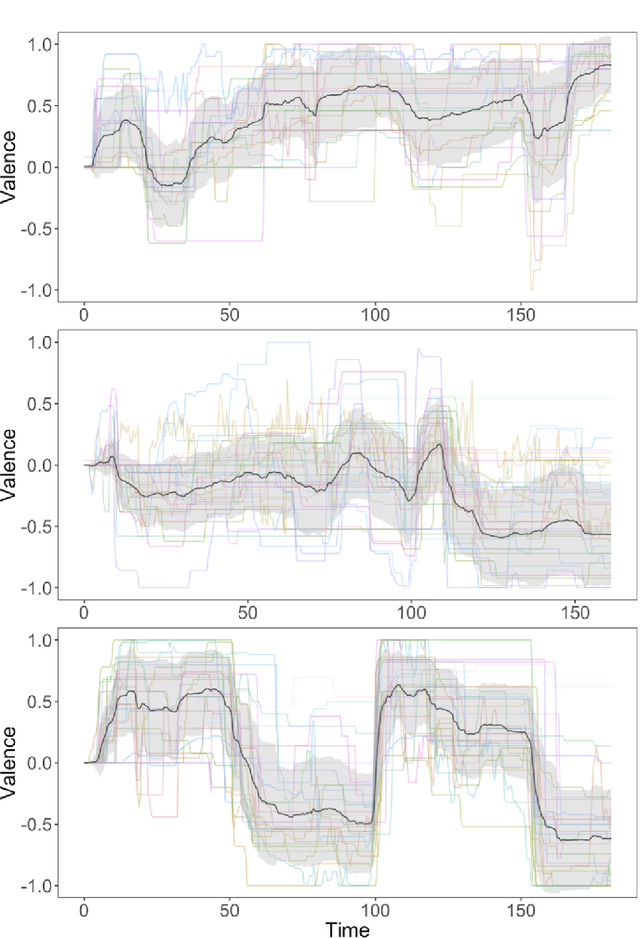
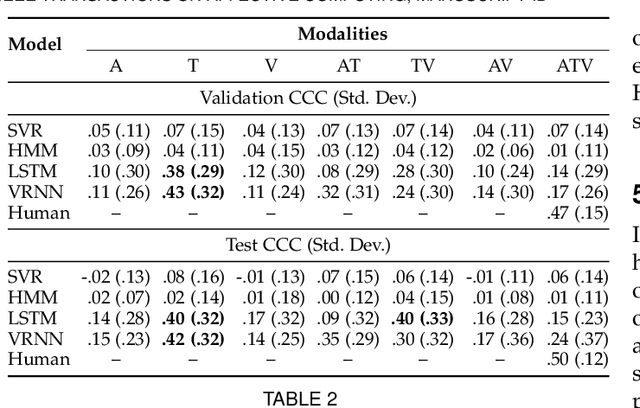
Human emotions unfold over time, and more affective computing research has to prioritize capturing this crucial component of real-world affect. Modeling dynamic emotional stimuli requires solving the twin challenges of time-series modeling and of collecting high-quality time-series datasets. We begin by assessing the state-of-the-art in time-series emotion recognition, and we review contemporary time-series approaches in affective computing, including discriminative and generative models. We then introduce the first version of the Stanford Emotional Narratives Dataset (SENDv1): a set of rich, multimodal videos of self-paced, unscripted emotional narratives, annotated for emotional valence over time. The complex narratives and naturalistic expressions in this dataset provide a challenging test for contemporary time-series emotion recognition models. We demonstrate several baseline and state-of-the-art modeling approaches on the SEND, including a Long Short-Term Memory model and a multimodal Variational Recurrent Neural Network, which perform comparably to the human-benchmark. We end by discussing the implications for future research in time-series affective computing.
COV-ELM classifier: An Extreme Learning Machine based identification of COVID-19 using Chest X-Ray Images
Aug 15, 2020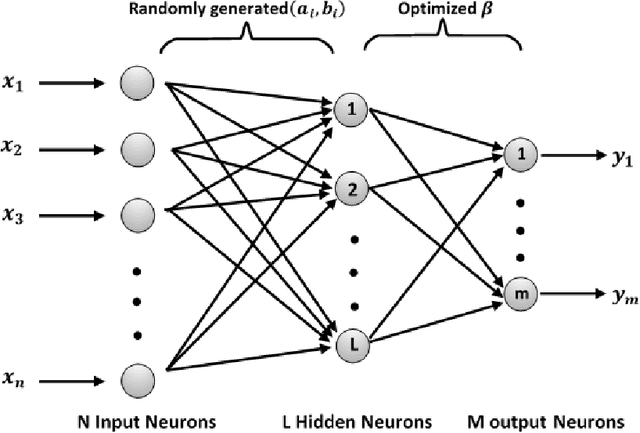
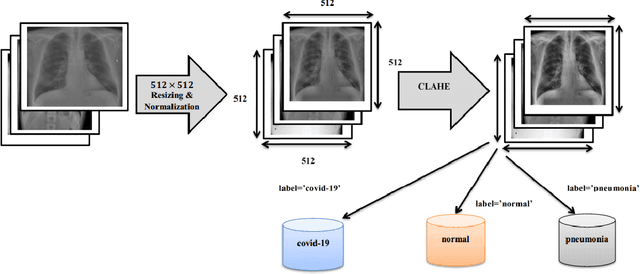
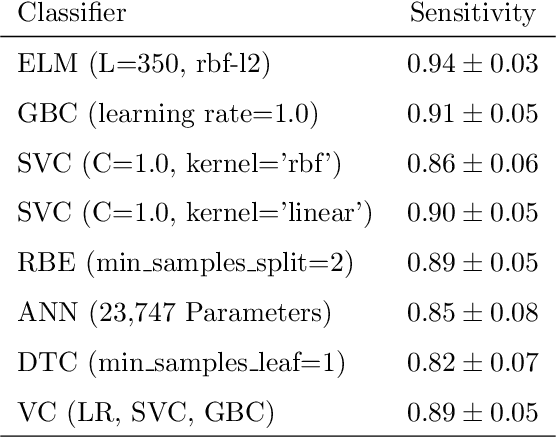
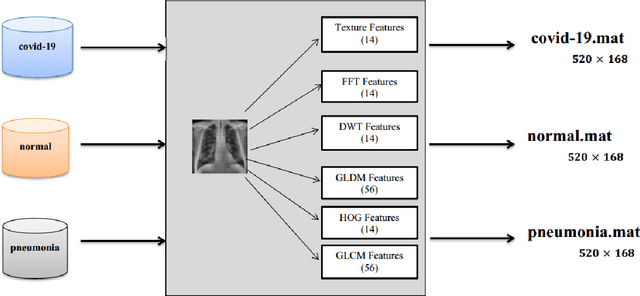
Coronaviruses constitute a family of virus that gives rise to respiratory diseases. Coronavirus disease 2019 (COVID-19) is an infectious disease caused by a newly discovered coronavirus also termed as Severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2). Due to its rapid spread, WHO has declared COVID-19 outbreak a pandemic on 11th March 2020. Reverse transcription-polymerase chain reaction (RT-PCR) test is popularly used worldwide for the detection of COVID-19. However, due to the high false-negative rate of RT-PCR test, chest X-ray (CXR) imaging is emerging as a feasible alternative for the detection of COVID-19. In this work, we propose a multiclass classification model COV-ELM, based on the extreme learning machine which classifies the CXR images into one of the three classes, namely COVID-19, normal, and pneumonia. The choice of ELM in this work has been motivated by its significantly short training time as compared to conventional gradient-based learning algorithms. After some preprocessing, we extract a pool of features based on texture and frequency. This pool of features serves as an input to the ELM and a 10-fold cross-validation method is employed to evaluate the proposed model. For experimentation, we use chest X-ray (CXR) images from three publicly available sources. The results of applying COV-ELM on test data are quite promising. The COV-ELM achieved a macro average F1-score of 0.95 and the overall sensitivity of ${0.94 \pm 0.02}$ at 95% confidence interval. When compared to state-of-the-art machine learning algorithms, the COV-ELM is found to outperform in a three-class classification scenario. The main advantage of COV-ELM is that its training time being quite low, as bigger and diverse datasets become available, it can be quickly retrained as compared to its gradient-based competitor models.
Pair the Dots: Jointly Examining Training History and Test Stimuli for Model Interpretability
Oct 31, 2020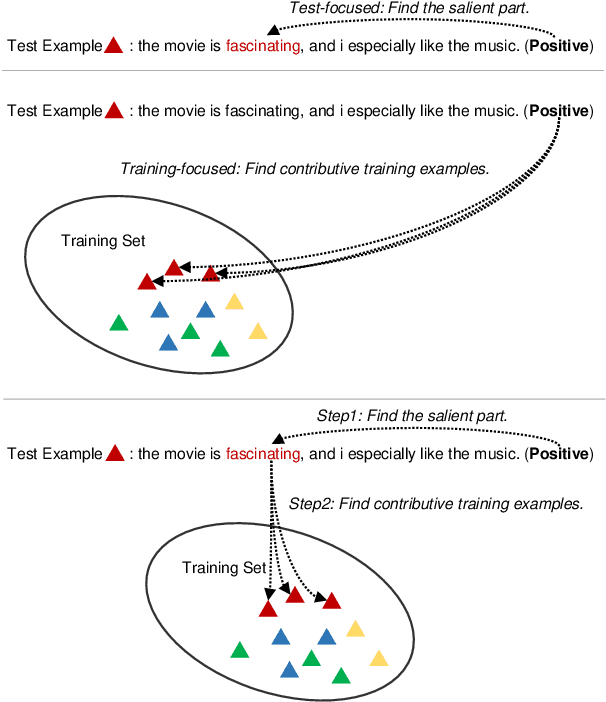
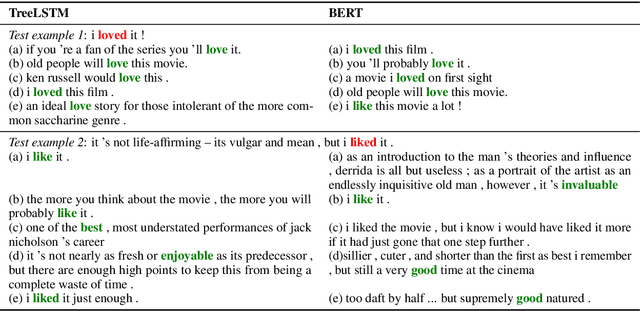

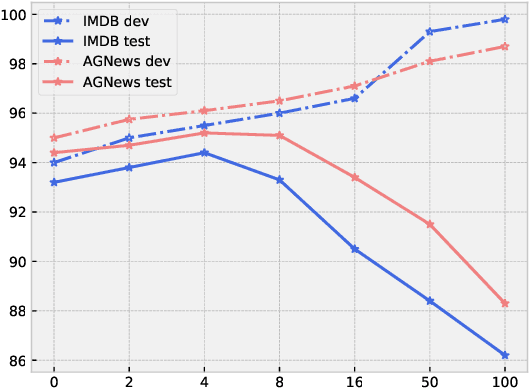
Any prediction from a model is made by a combination of learning history and test stimuli. This provides significant insights for improving model interpretability: {\it because of which part(s) of which training example(s), the model attends to which part(s) of a test example}. Unfortunately, existing methods to interpret a model's predictions are only able to capture a single aspect of either test stimuli or learning history, and evidences from both are never combined or integrated. In this paper, we propose an efficient and differentiable approach to make it feasible to interpret a model's prediction by jointly examining training history and test stimuli. Test stimuli is first identified by gradient-based methods, signifying {\it the part of a test example that the model attends to}. The gradient-based saliency scores are then propagated to training examples using influence functions to identify {\it which part(s) of which training example(s)} make the model attends to the test stimuli. The system is differentiable and time efficient: the adoption of saliency scores from gradient-based methods allows us to efficiently trace a model's prediction through test stimuli, and then back to training examples through influence functions. We demonstrate that the proposed methodology offers clear explanations about neural model decisions, along with being useful for performing error analysis, crafting adversarial examples and fixing erroneously classified examples.
ECOC as a Method of Constructing Deep Convolutional Neural Network Ensembles
Sep 07, 2020
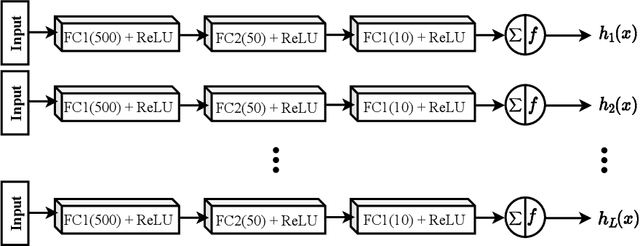
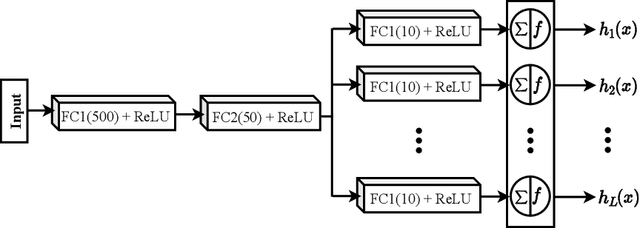
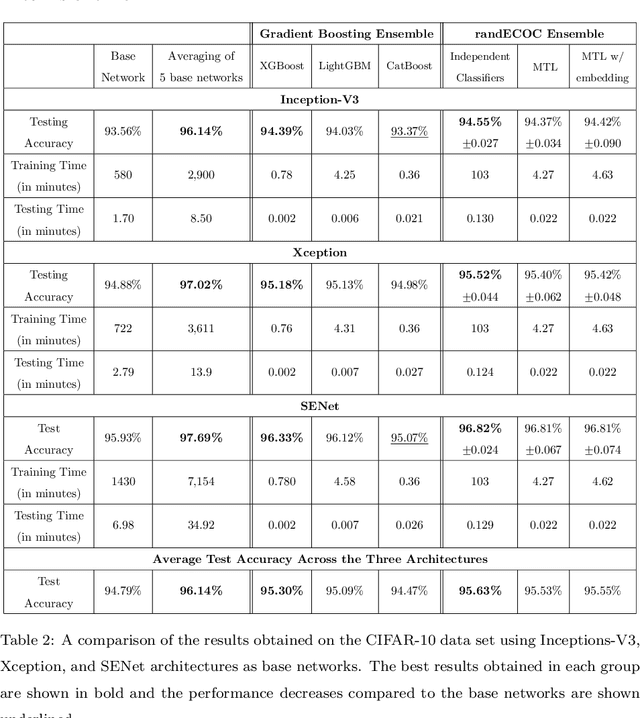
Deep neural networks have enhanced the performance of decision making systems in many applications including image understanding, and further gains can be achieved by constructing ensembles. However, designing an ensemble of deep networks is often not very beneficial since the time needed to train the constituent networks is very high or the performance gain obtained is not very significant. In this paper, we analyse error correcting output coding (ECOC) framework to be used as an ensemble technique for deep networks and propose different design strategies to address the accuracy-complexity trade-off. We carry out an extensive comparative study between the introduced ECOC designs and the state-of-the-art ensemble techniques such as ensemble averaging and gradient boosting decision trees. Furthermore, we propose a combinatory technique which is shown to reveal the highest classification performance amongst all.
Multiscale Detection of Cancerous Tissue in High Resolution Slide Scans
Oct 01, 2020
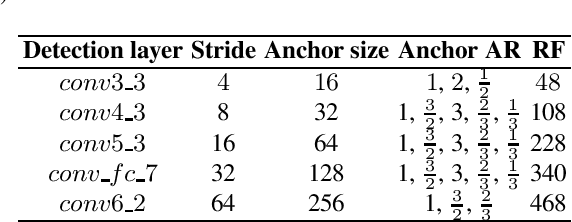


We present an algorithm for multi-scale tumor (chimeric cell) detection in high resolution slide scans. The broad range of tumor sizes in our dataset pose a challenge for current Convolutional Neural Networks (CNN) which often fail when image features are very small (8 pixels). Our approach modifies the effective receptive field at different layers in a CNN so that objects with a broad range of varying scales can be detected in a single forward pass. We define rules for computing adaptive prior anchor boxes which we show are solvable under the equal proportion interval principle. Two mechanisms in our CNN architecture alleviate the effects of non-discriminative features prevalent in our data - a foveal detection algorithm that incorporates a cascade residual-inception module and a deconvolution module with additional context information. When integrated into a Single Shot MultiBox Detector (SSD), these additions permit more accurate detection of small-scale objects. The results permit efficient real-time analysis of medical images in pathology and related biomedical research fields.
Learning Occupancy Function from Point Clouds for Surface Reconstruction
Oct 22, 2020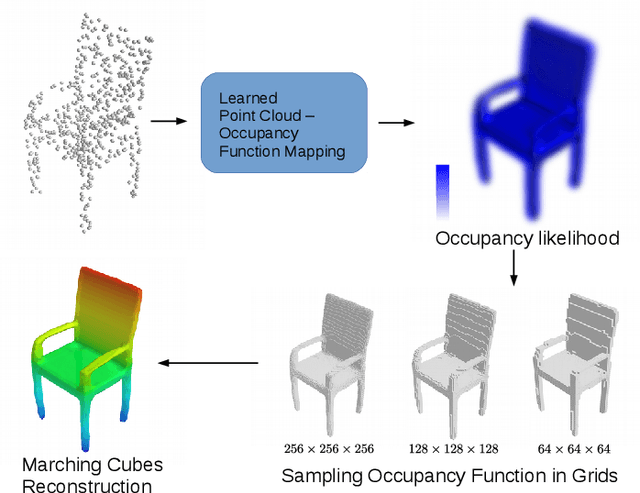
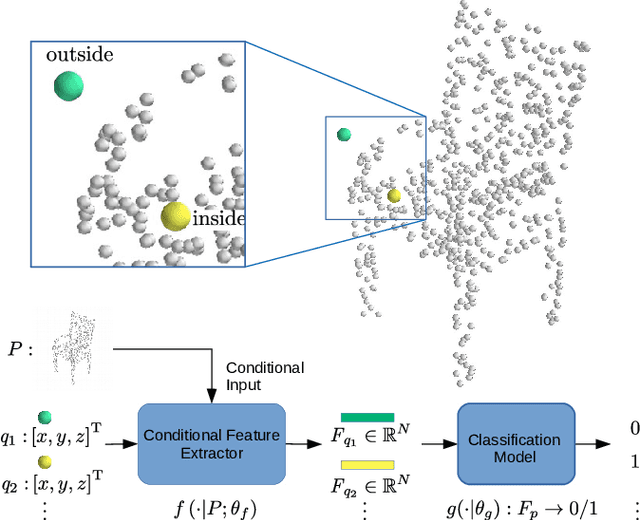
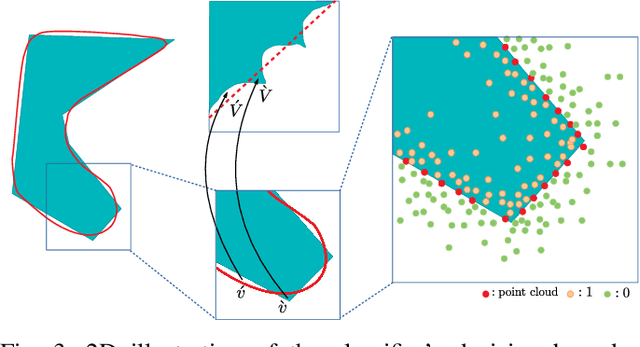
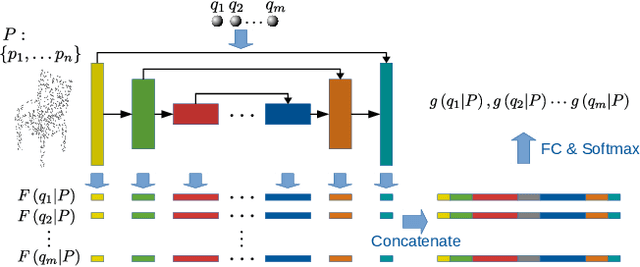
Implicit function based surface reconstruction has been studied for a long time to recover 3D shapes from point clouds sampled from surfaces. Recently, Signed Distance Functions (SDFs) and Occupany Functions are adopted in learning-based shape reconstruction methods as implicit 3D shape representation. This paper proposes a novel method for learning occupancy functions from sparse point clouds and achieves better performance on challenging surface reconstruction tasks. Unlike the previous methods, which predict point occupancy with fully-connected multi-layer networks, we adapt the point cloud deep learning architecture, Point Convolution Neural Network (PCNN), to build our learning model. Specifically, we create a sampling operator and insert it into PCNN to continuously sample the feature space at the points where occupancy states need to be predicted. This method natively obtains point cloud data's geometric nature, and it's invariant to point permutation. Our occupancy function learning can be easily fit into procedures of point cloud up-sampling and surface reconstruction. Our experiments show state-of-the-art performance for reconstructing With ShapeNet dataset and demonstrate this method's well-generalization by testing it with McGill 3D dataset \cite{siddiqi2008retrieving}. Moreover, we find the learned occupancy function is relatively more rotation invariant than previous shape learning methods.
Deep Learning for Distinguishing Normal versus Abnormal Chest Radiographs and Generalization to Unseen Diseases
Oct 22, 2020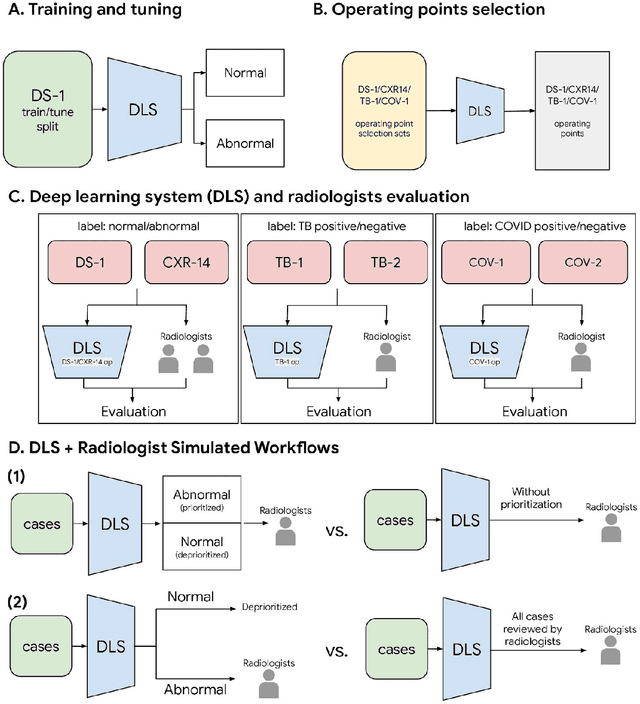
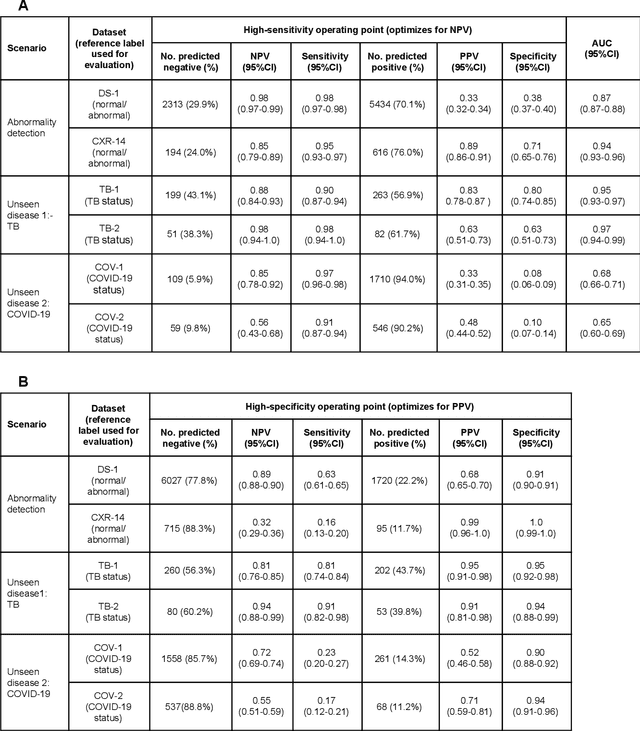
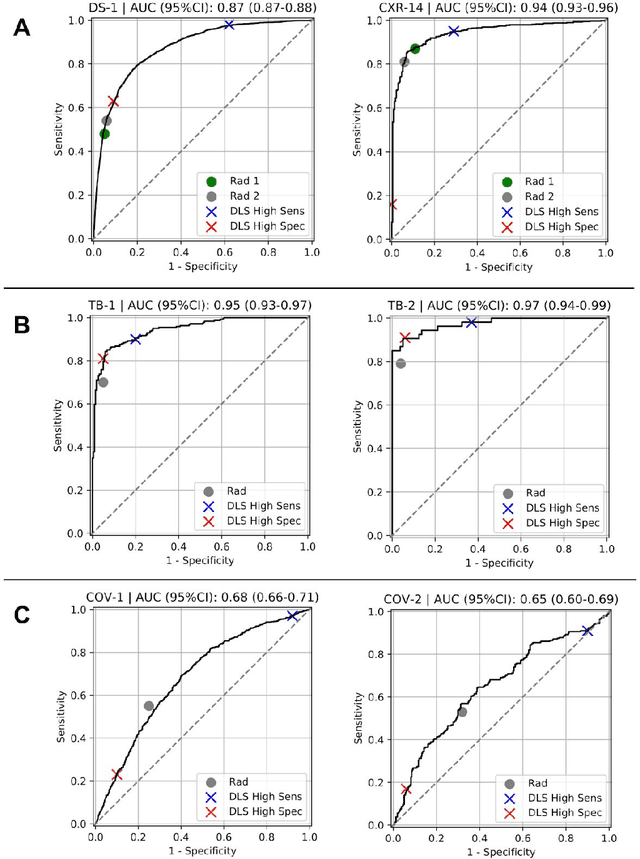
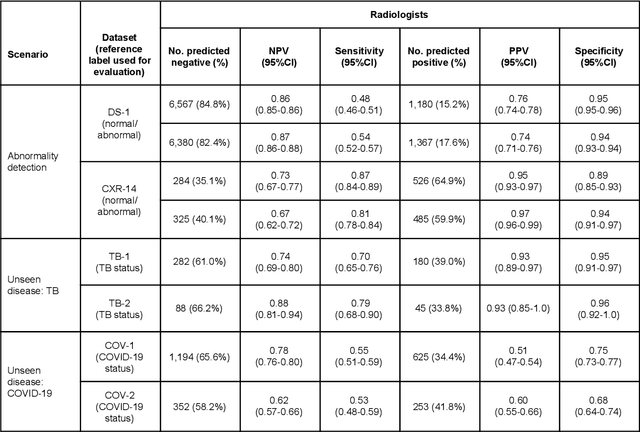
Chest radiography (CXR) is the most widely-used thoracic clinical imaging modality and is crucial for guiding the management of cardiothoracic conditions. The detection of specific CXR findings has been the main focus of several artificial intelligence (AI) systems. However, the wide range of possible CXR abnormalities makes it impractical to build specific systems to detect every possible condition. In this work, we developed and evaluated an AI system to classify CXRs as normal or abnormal. For development, we used a de-identified dataset of 248,445 patients from a multi-city hospital network in India. To assess generalizability, we evaluated our system using 6 international datasets from India, China, and the United States. Of these datasets, 4 focused on diseases that the AI was not trained to detect: 2 datasets with tuberculosis and 2 datasets with coronavirus disease 2019. Our results suggest that the AI system generalizes to new patient populations and abnormalities. In a simulated workflow where the AI system prioritized abnormal cases, the turnaround time for abnormal cases reduced by 7-28%. These results represent an important step towards evaluating whether AI can be safely used to flag cases in a general setting where previously unseen abnormalities exist.