 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Back to the Future: Unsupervised Backprop-based Decoding for Counterfactual and Abductive Commonsense Reasoning
Oct 12, 2020
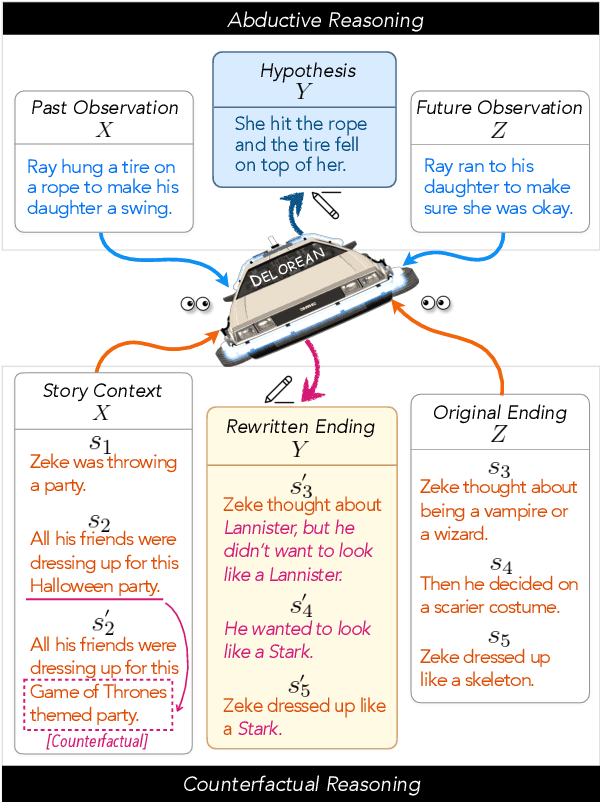
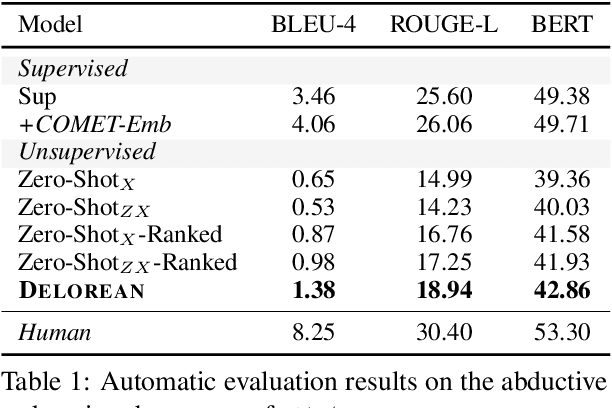
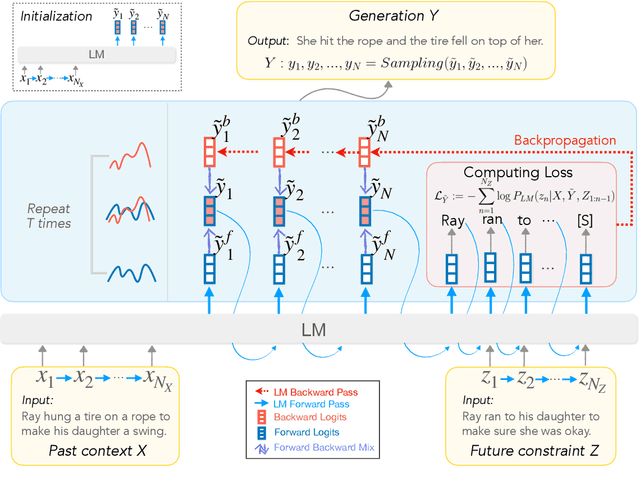
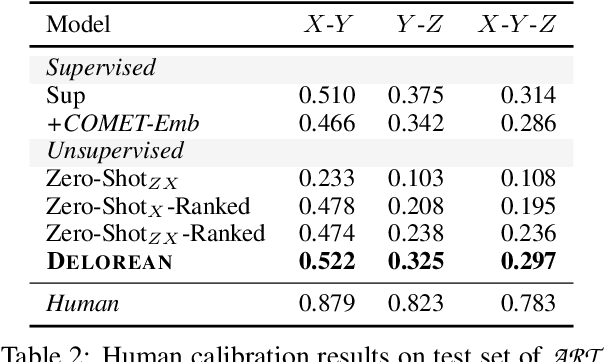
Abductive and counterfactual reasoning, core abilities of everyday human cognition, require reasoning about what might have happened at time t, while conditioning on multiple contexts from the relative past and future. However, simultaneous incorporation of past and future contexts using generative language models (LMs) can be challenging, as they are trained either to condition only on the past context or to perform narrowly scoped text-infilling. In this paper, we propose DeLorean, a new unsupervised decoding algorithm that can flexibly incorporate both the past and future contexts using only off-the-shelf, left-to-right language models and no supervision. The key intuition of our algorithm is incorporating the future through back-propagation, during which, we only update the internal representation of the output while fixing the model parameters. By alternating between forward and backward propagation, DeLorean can decode the output representation that reflects both the left and right contexts. We demonstrate that our approach is general and applicable to two nonmonotonic reasoning tasks: abductive text generation and counterfactual story revision, where DeLorean outperforms a range of unsupervised and some supervised methods, based on automatic and human evaluation.
MicroRec: Accelerating Deep Recommendation Systems to Microseconds by Hardware and Data Structure Solutions
Oct 12, 2020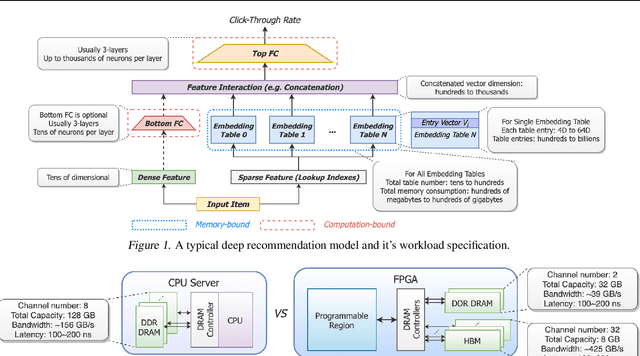
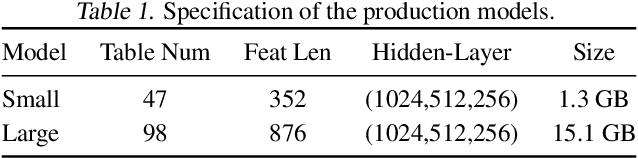
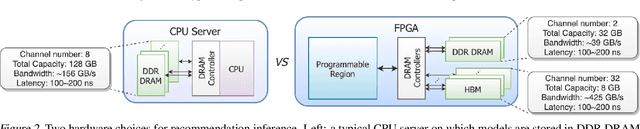
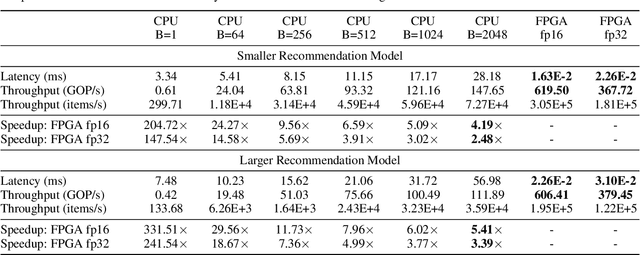
Deep neural networks are widely used in personalized recommendation systems. Unlike regular DNN inference workloads, recommendation inference is memory-bound due to the many random memory accesses needed to lookup the embedding tables. The inference is also heavily constrained in terms of latency because producing a recommendation for a user must be done in about tens of milliseconds. In this paper, we propose MicroRec, a high-performance inference engine for recommendation systems. MicroRec accelerates recommendation inference by (1) redesigning the data structures involved in the embeddings to reduce the number of lookups needed and (2) taking advantage of the availability of High-Bandwidth Memory (HBM) in FPGA accelerators to tackle the latency by enabling parallel lookups. We have implemented the resulting design on an FPGA board including the embedding lookup step as well as the complete inference process. Compared to the optimized CPU baseline (16 vCPU, AVX2-enabled), MicroRec achieves 13.8~14.7x speedup on embedding lookup alone and 2.5$~5.4x speedup for the entire recommendation inference in terms of throughput. As for latency, CPU-based engines needs milliseconds for inferring a recommendation while MicroRec only takes microseconds, a significant advantage in real-time recommendation systems.
A Vertical Federated Learning Method for Interpretable Scorecard and Its Application in Credit Scoring
Sep 14, 2020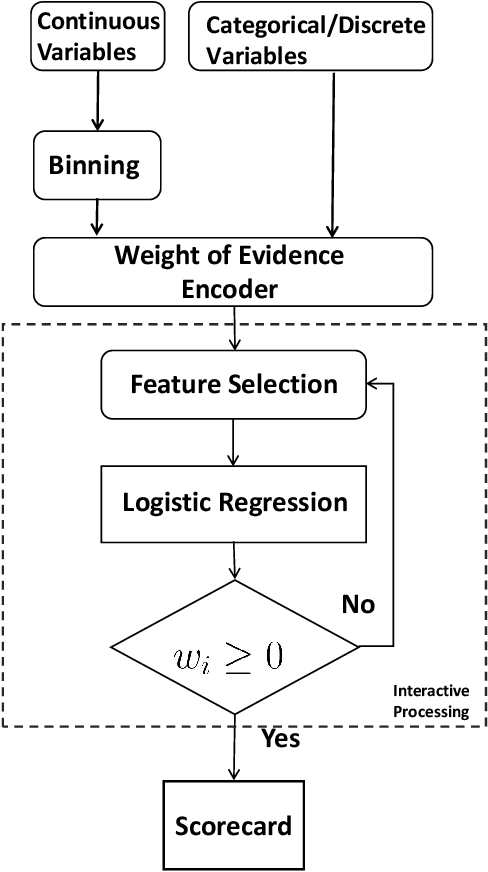
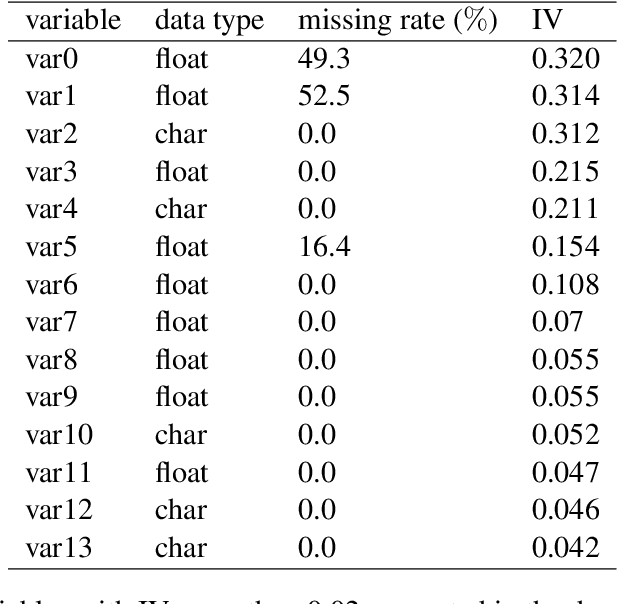
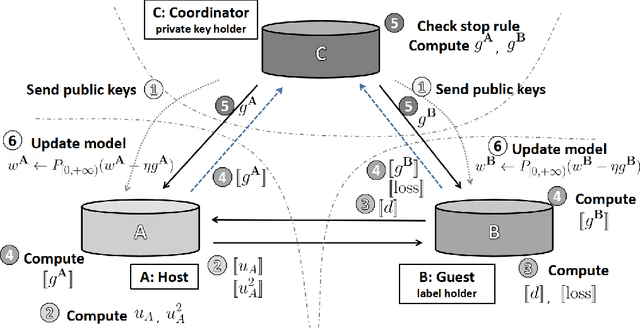

With the success of big data and artificial intelligence in many fields, the applications of big data driven models are expected in financial risk management especially credit scoring and rating. Under the premise of data privacy protection, we propose a projected gradient-based method in the vertical federated learning framework for the traditional scorecard, which is based on logistic regression with bounded constraints, namely FL-LRBC. The latter enables multiple agencies to jointly train an optimized scorecard model in a single training session. It leads to the formation of the model with positive coefficients, while the time-consuming parameter-tuning process can be avoided. Moreover, the performance in terms of both AUC and the Kolmogorov-Smirnov (KS) statistics is significantly improved due to data enrichment using FL-LRBC. At present, FL-LRBC has already been applied to credit business in a China nation-wide financial holdings group.
Budgeted Online Selection of Candidate IoT Clients to Participate in Federated Learning
Nov 16, 2020
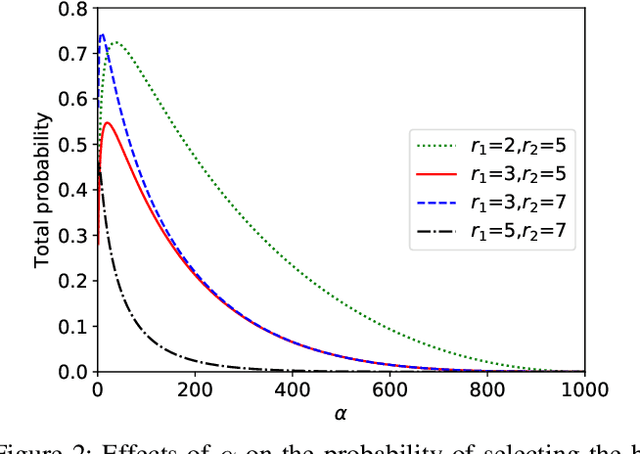
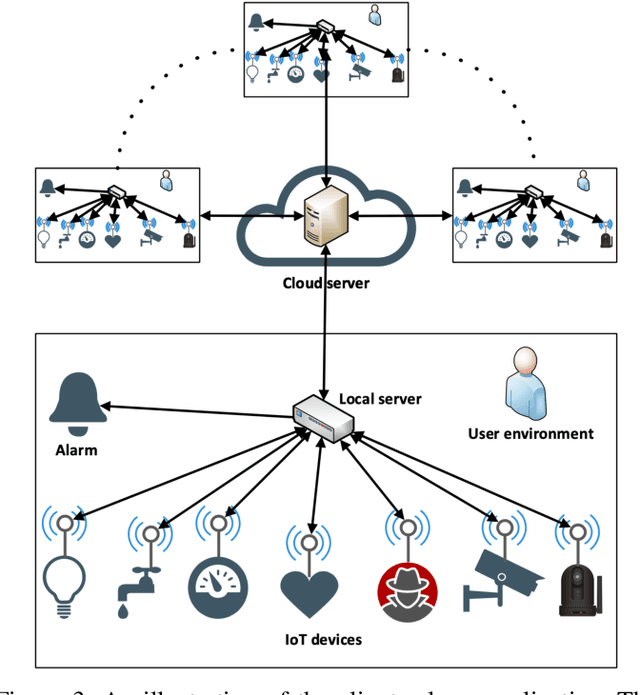

Machine Learning (ML), and Deep Learning (DL) in particular, play a vital role in providing smart services to the industry. These techniques however suffer from privacy and security concerns since data is collected from clients and then stored and processed at a central location. Federated Learning (FL), an architecture in which model parameters are exchanged instead of client data, has been proposed as a solution to these concerns. Nevertheless, FL trains a global model by communicating with clients over communication rounds, which introduces more traffic on the network and increases the convergence time to the target accuracy. In this work, we solve the problem of optimizing accuracy in stateful FL with a budgeted number of candidate clients by selecting the best candidate clients in terms of test accuracy to participate in the training process. Next, we propose an online stateful FL heuristic to find the best candidate clients. Additionally, we propose an IoT client alarm application that utilizes the proposed heuristic in training a stateful FL global model based on IoT device type classification to alert clients about unauthorized IoT devices in their environment. To test the efficiency of the proposed online heuristic, we conduct several experiments using a real dataset and compare the results against state-of-the-art algorithms. Our results indicate that the proposed heuristic outperforms the online random algorithm with up to 27% gain in accuracy. Additionally, the performance of the proposed online heuristic is comparable to the performance of the best offline algorithm.
Fractional Deep Neural Network via Constrained Optimization
Apr 01, 2020
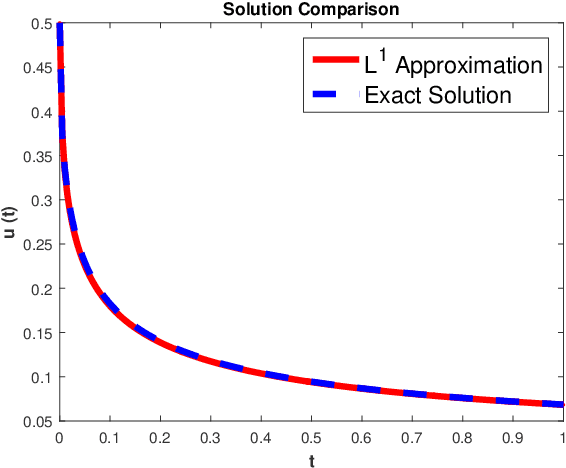
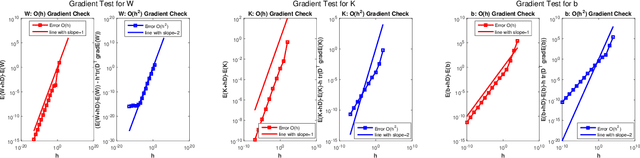
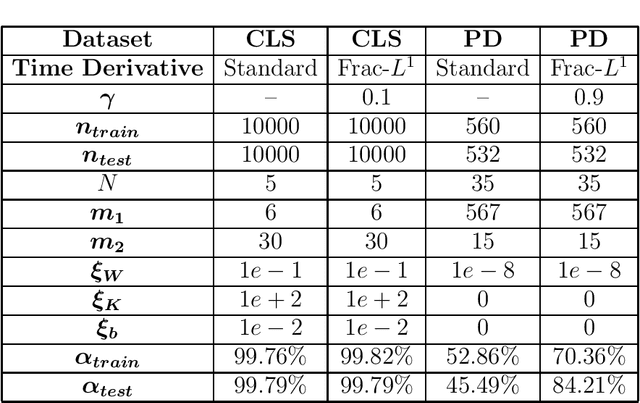
This paper introduces a novel algorithmic framework for a deep neural network (DNN), which in a mathematically rigorous manner, allows us to incorporate history (or memory) into the network -- it ensures all layers are connected to one another. This DNN, called Fractional-DNN, can be viewed as a time-discretization of a fractional in time nonlinear ordinary differential equation (ODE). The learning problem then is a minimization problem subject to that fractional ODE as constraints. We emphasize that an analogy between the existing DNN and ODEs, with standard time derivative, is well-known by now. The focus of our work is the Fractional-DNN. Using the Lagrangian approach, we provide a derivation of the backward propagation and the design equations. We test our network on several datasets for classification problems. Fractional-DNN offers various advantages over the existing DNN. The key benefits are a significant improvement to the vanishing gradient issue due to the memory effect, and better handling of nonsmooth data due to the network's ability to approximate non-smooth functions.
Dynamic Nonparametric Edge-Clustering Model for Time-Evolving Sparse Networks
May 28, 2019
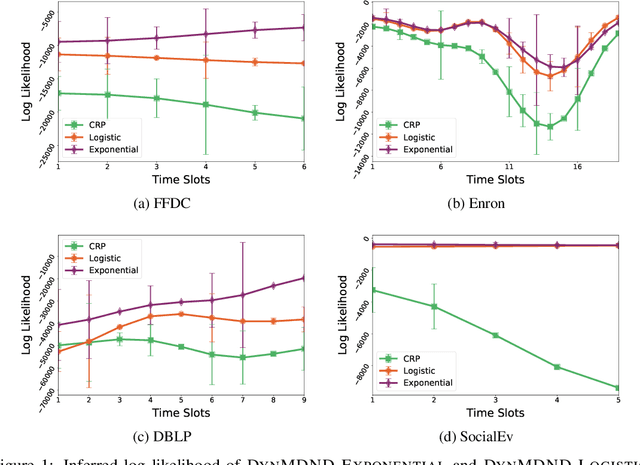
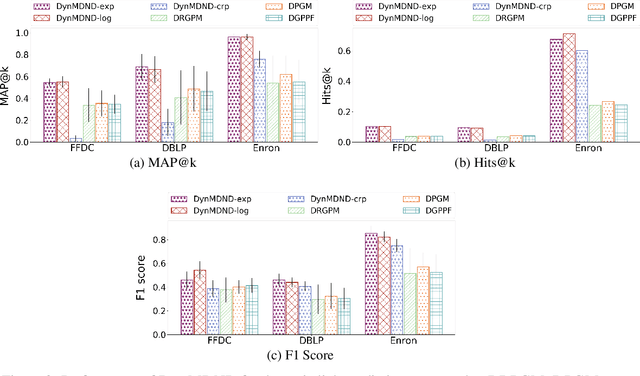
Interaction graphs, such as those recording emails between individuals or transactions between institutions, tend to be sparse yet structured, and often grow in an unbounded manner. Such behavior can be well-captured by structured, nonparametric edge-exchangeable graphs. However, such exchangeable models necessarily ignore temporal dynamics in the network. We propose a dynamic nonparametric model for interaction graphs that combine the sparsity of the exchangeable models with dynamic clustering patterns that tend to reinforce recent behavioral patterns. We show that our method yields improved held-out likelihood over stationary variants, and impressive predictive performance against a range of state-of-the-art dynamic interaction graph models.
Geometry-Aware Hamiltonian Variational Auto-Encoder
Oct 22, 2020

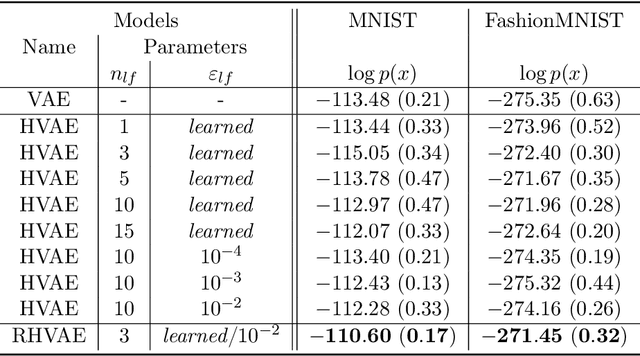
Variational auto-encoders (VAEs) have proven to be a well suited tool for performing dimensionality reduction by extracting latent variables lying in a potentially much smaller dimensional space than the data. Their ability to capture meaningful information from the data can be easily apprehended when considering their capability to generate new realistic samples or perform potentially meaningful interpolations in a much smaller space. However, such generative models may perform poorly when trained on small data sets which are abundant in many real-life fields such as medicine. This may, among others, come from the lack of structure of the latent space, the geometry of which is often under-considered. We thus propose in this paper to see the latent space as a Riemannian manifold endowed with a parametrized metric learned at the same time as the encoder and decoder networks. This metric is then used in what we called the Riemannian Hamiltonian VAE which extends the Hamiltonian VAE introduced by arXiv:1805.11328 to better exploit the underlying geometry of the latent space. We argue that such latent space modelling provides useful information about its underlying structure leading to far more meaningful interpolations, more realistic data-generation and more reliable clustering.
Prediction of Homicides in Urban Centers: A Machine Learning Approach
Aug 16, 2020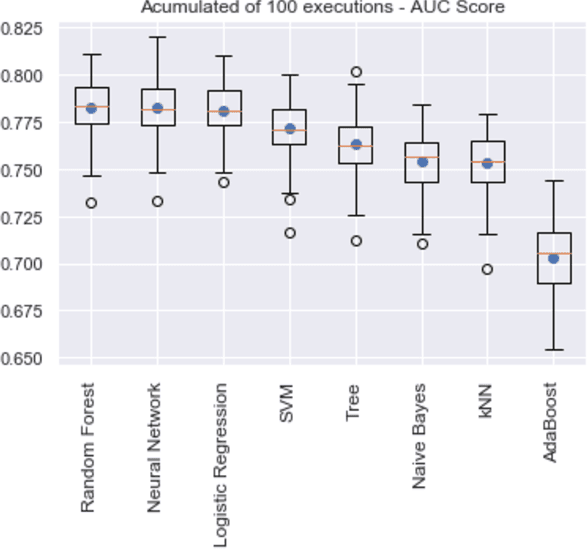
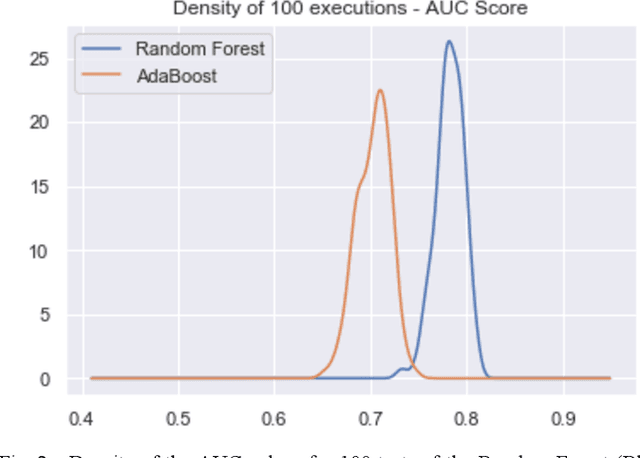
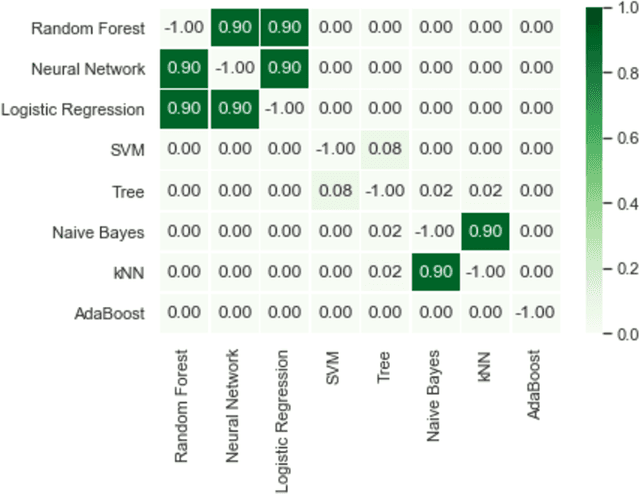
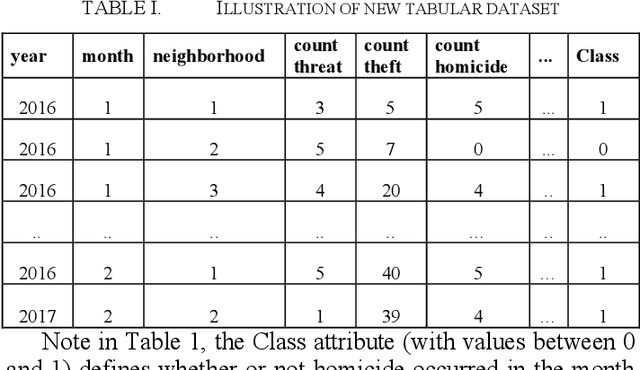
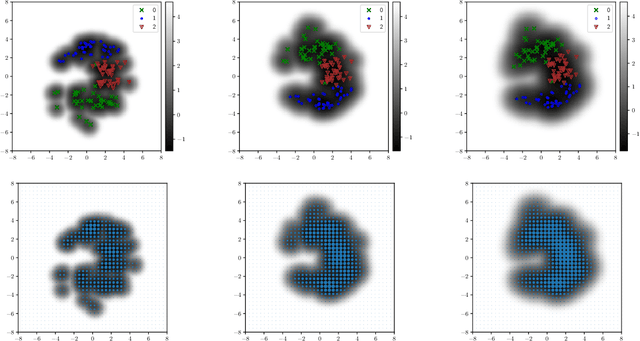
Relevant research has been standing out in the computing community aiming to develop computational models capable of predicting occurrence of crimes, analyzing contexts of crimes, extracting profiles of individuals linked to crimes, and analyzing crimes according to time. This, due to the social impact and also the complex origin of the data, thus showing itself as an interesting computational challenge. This research presents a computational model for the prediction of homicide crimes, based on tabular data of crimes registered in the city of Bel\'em - Par\'a, Brazil. Statistical tests were performed with 8 different classification methods, both Random Forest, Logistic Regression, and Neural Network presented best results, AUC ~ 0.8. Results considered as a baseline for the proposed problem.
Probabilistic solution of chaotic dynamical system inverse problems using Bayesian Artificial Neural Networks
May 26, 2020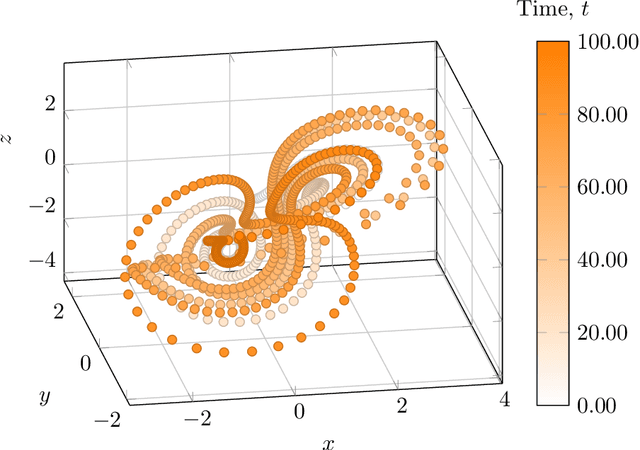
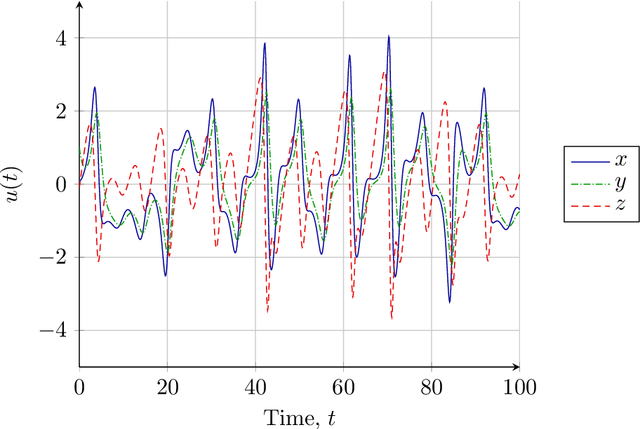
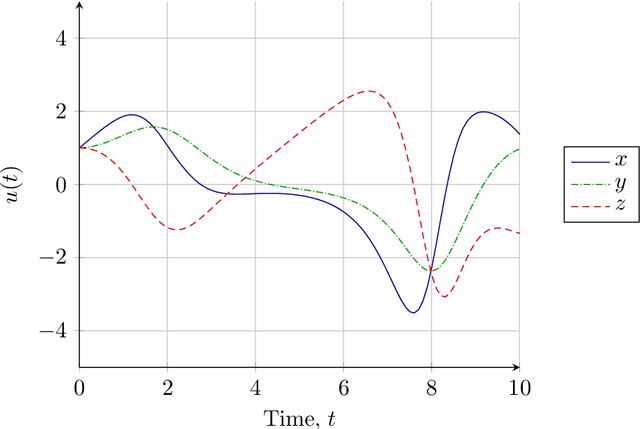
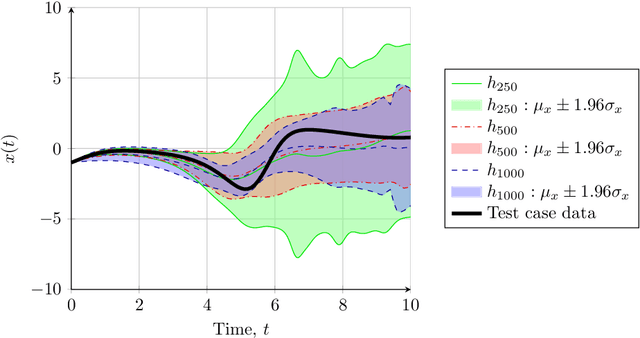
This paper demonstrates the application of Bayesian Artificial Neural Networks to Ordinary Differential Equation (ODE) inverse problems. We consider the case of estimating an unknown chaotic dynamical system transition model from state observation data. Inverse problems for chaotic systems are numerically challenging as small perturbations in model parameters can cause very large changes in estimated forward trajectories. Bayesian Artificial Neural Networks can be used to simultaneously fit a model and estimate model parameter uncertainty. Knowledge of model parameter uncertainty can then be incorporated into the probabilistic estimates of the inferred system's forward time evolution. The method is demonstrated numerically by analysing the chaotic Sprott B system. Observations of the system are used to estimate a posterior predictive distribution over the weights of a parametric polynomial kernel Artificial Neural Network. It is shown that the proposed method is able to perform accurate time predictions. Further, the proposed method is able to correctly account for model uncertainties and provide useful prediction uncertainty bounds.
Nearest Neighbor Machine Translation
Oct 01, 2020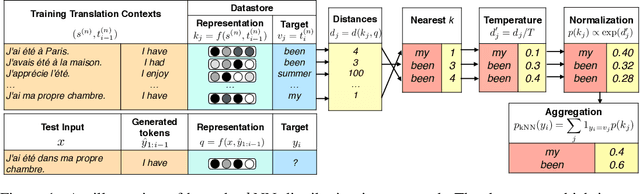
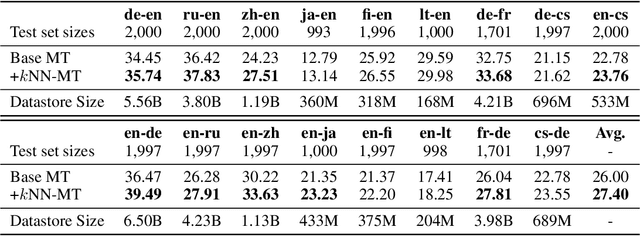
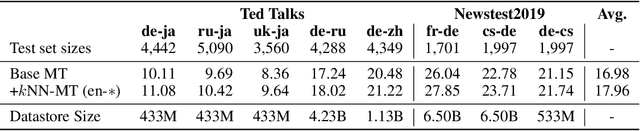
We introduce $k$-nearest-neighbor machine translation ($k$NN-MT), which predicts tokens with a nearest neighbor classifier over a large datastore of cached examples, using representations from a neural translation model for similarity search. This approach requires no additional training and scales to give the decoder direct access to billions of examples at test time, resulting in a highly expressive model that consistently improves performance across many settings. Simply adding nearest neighbor search improves a state-of-the-art German-English translation model by 1.5 BLEU. $k$NN-MT allows a single model to be adapted to diverse domains by using a domain-specific datastore, improving results by an average of 9.2 BLEU over zero-shot transfer, and achieving new state-of-the-art results---without training on these domains. A massively multilingual model can also be specialized for particular language pairs, with improvements of 3 BLEU for translating from English into German and Chinese. Qualitatively, $k$NN-MT is easily interpretable; it combines source and target context to retrieve highly relevant examples.