 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Read what you need: Controllable Aspect-based Opinion Summarization of Tourist Reviews
Jun 09, 2020
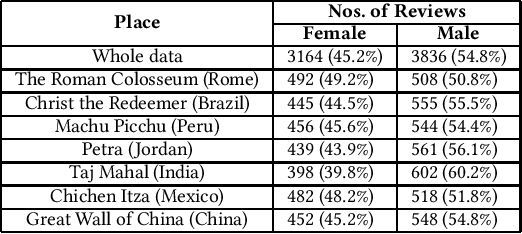
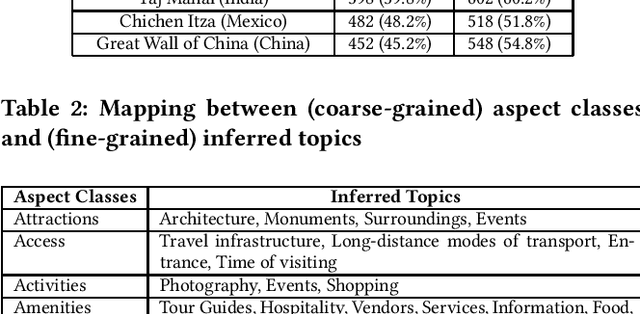
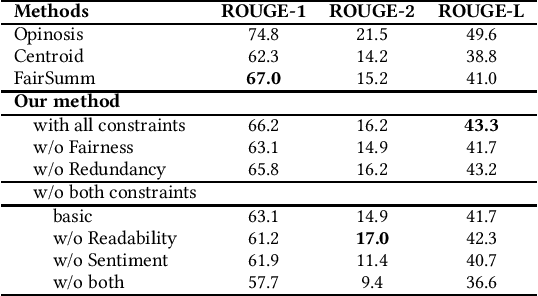
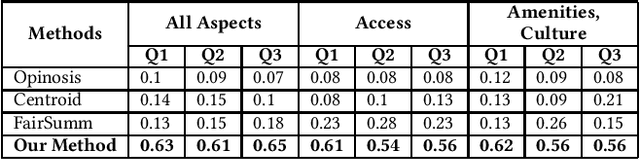
Manually extracting relevant aspects and opinions from large volumes of user-generated text is a time-consuming process. Summaries, on the other hand, help readers with limited time budgets to quickly consume the key ideas from the data. State-of-the-art approaches for multi-document summarization, however, do not consider user preferences while generating summaries. In this work, we argue the need and propose a solution for generating personalized aspect-based opinion summaries from large collections of online tourist reviews. We let our readers decide and control several attributes of the summary such as the length and specific aspects of interest among others. Specifically, we take an unsupervised approach to extract coherent aspects from tourist reviews posted on TripAdvisor. We then propose an Integer Linear Programming (ILP) based extractive technique to select an informative subset of opinions around the identified aspects while respecting the user-specified values for various control parameters. Finally, we evaluate and compare our summaries using crowdsourcing and ROUGE-based metrics and obtain competitive results.
Accelerating Deep Learning Applications in Space
Jul 21, 2020
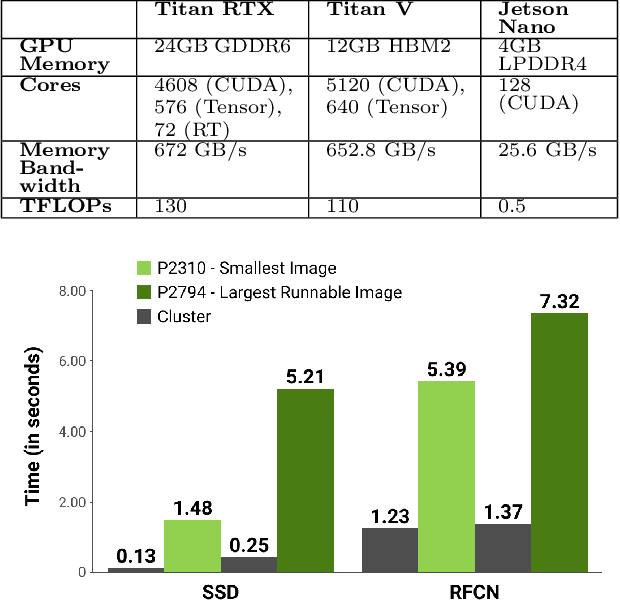

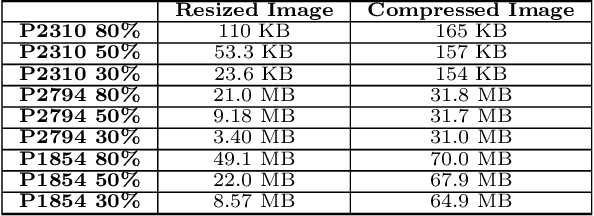
Computing at the edge offers intriguing possibilities for the development of autonomy and artificial intelligence. The advancements in autonomous technologies and the resurgence of computer vision have led to a rise in demand for fast and reliable deep learning applications. In recent years, the industry has introduced devices with impressive processing power to perform various object detection tasks. However, with real-time detection, devices are constrained in memory, computational capacity, and power, which may compromise the overall performance. This could be solved either by optimizing the object detector or modifying the images. In this paper, we investigate the performance of CNN-based object detectors on constrained devices when applying different image compression techniques. We examine the capabilities of a NVIDIA Jetson Nano; a low-power, high-performance computer, with an integrated GPU, small enough to fit on-board a CubeSat. We take a closer look at the Single Shot MultiBox Detector (SSD) and Region-based Fully Convolutional Network (R-FCN) that are pre-trained on DOTA - a Large Scale Dataset for Object Detection in Aerial Images. The performance is measured in terms of inference time, memory consumption, and accuracy. By applying image compression techniques, we are able to optimize performance. The two techniques applied, lossless compression and image scaling, improves speed and memory consumption with no or little change in accuracy. The image scaling technique achieves a 100% runnable dataset and we suggest combining both techniques in order to optimize the speed/memory/accuracy trade-off.
Stochastic embeddings of dynamical phenomena through variational autoencoders
Oct 13, 2020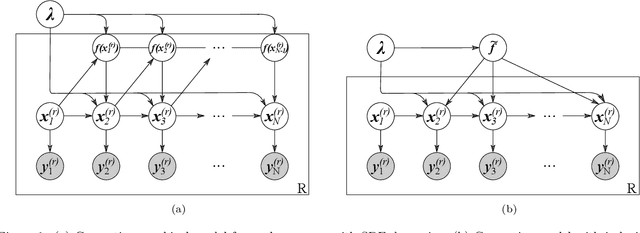
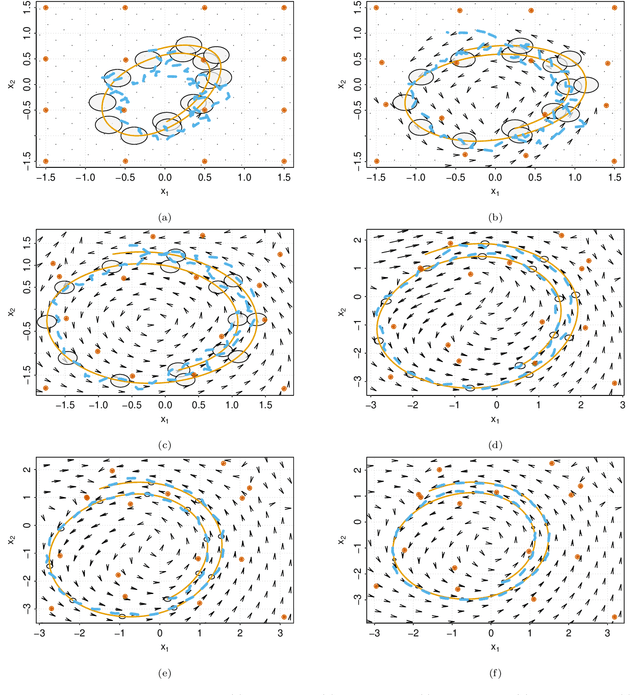
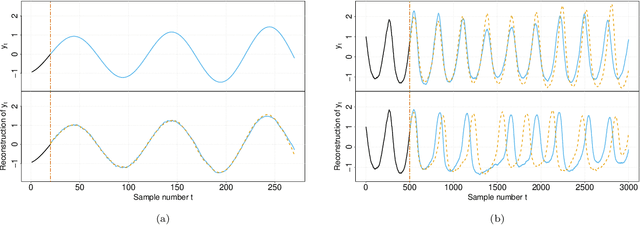
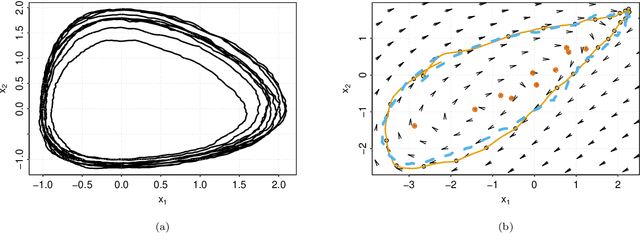
System identification in scenarios where the observed number of variables is less than the degrees of freedom in the dynamics is an important challenge. In this work we tackle this problem by using a recognition network to increase the observed space dimensionality during the reconstruction of the phase space. The phase space is forced to have approximately Markovian dynamics described by a Stochastic Differential Equation (SDE), which is also to be discovered. To enable robust learning from stochastic data we use the Bayesian paradigm and place priors on the drift and diffusion terms. To handle the complexity of learning the posteriors, a set of mean field variational approximations to the true posteriors are introduced, enabling efficient statistical inference. Finally, a decoder network is used to obtain plausible reconstructions of the experimental data. The main advantage of this approach is that the resulting model is interpretable within the paradigm of statistical physics. Our validation shows that this approach not only recovers a state space that resembles the original one, but it is also able to synthetize new time series capturing the main properties of the experimental data.
ConFoc: Content-Focus Protection Against Trojan Attacks on Neural Networks
Jul 01, 2020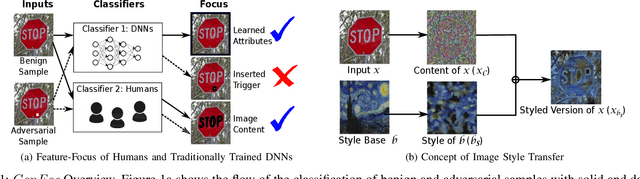
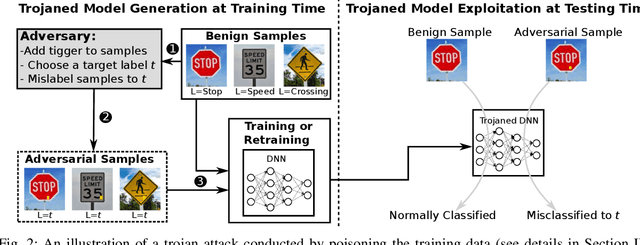
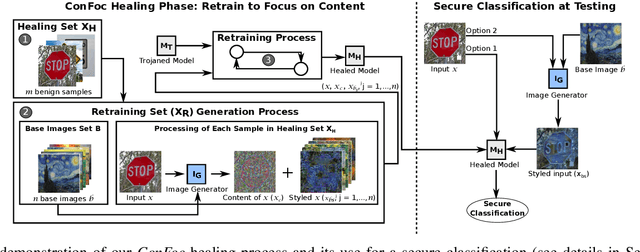
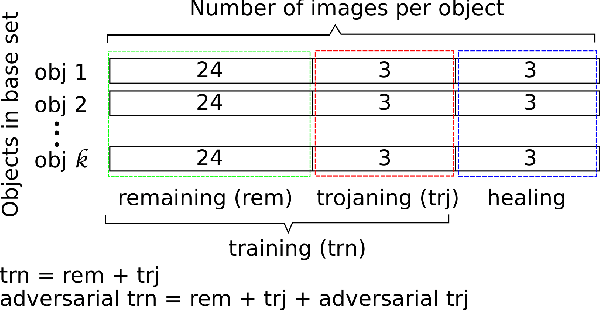
Deep Neural Networks (DNNs) have been applied successfully in computer vision. However, their wide adoption in image-related applications is threatened by their vulnerability to trojan attacks. These attacks insert some misbehavior at training using samples with a mark or trigger, which is exploited at inference or testing time. In this work, we analyze the composition of the features learned by DNNs at training. We identify that they, including those related to the inserted triggers, contain both content (semantic information) and style (texture information), which are recognized as a whole by DNNs at testing time. We then propose a novel defensive technique against trojan attacks, in which DNNs are taught to disregard the styles of inputs and focus on their content only to mitigate the effect of triggers during the classification. The generic applicability of the approach is demonstrated in the context of a traffic sign and a face recognition application. Each of them is exposed to a different attack with a variety of triggers. Results show that the method reduces the attack success rate significantly to values < 1% in all the tested attacks while keeping as well as improving the initial accuracy of the models when processing both benign and adversarial data.
MCMC-Interactive Variational Inference
Oct 02, 2020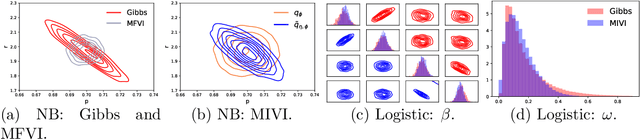

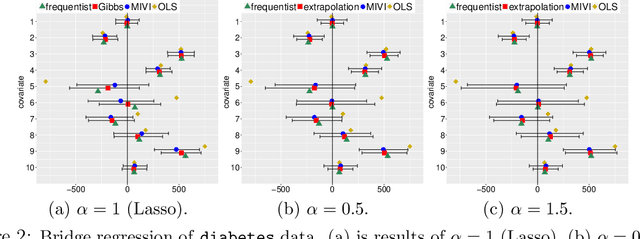
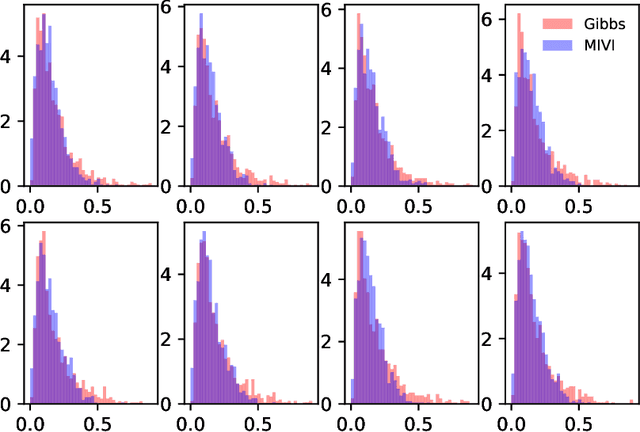
Leveraging well-established MCMC strategies, we propose MCMC-interactive variational inference (MIVI) to not only estimate the posterior in a time constrained manner, but also facilitate the design of MCMC transitions. Constructing a variational distribution followed by a short Markov chain that has parameters to learn, MIVI takes advantage of the complementary properties of variational inference and MCMC to encourage mutual improvement. On one hand, with the variational distribution locating high posterior density regions, the Markov chain is optimized within the variational inference framework to efficiently target the posterior despite a small number of transitions. On the other hand, the optimized Markov chain with considerable flexibility guides the variational distribution towards the posterior and alleviates its underestimation of uncertainty. Furthermore, we prove the optimized Markov chain in MIVI admits extrapolation, which means its marginal distribution gets closer to the true posterior as the chain grows. Therefore, the Markov chain can be used separately as an efficient MCMC scheme. Experiments show that MIVI not only accurately and efficiently approximates the posteriors but also facilitates designs of stochastic gradient MCMC and Gibbs sampling transitions.
Experimental Quantum Generative Adversarial Networks for Image Generation
Oct 13, 2020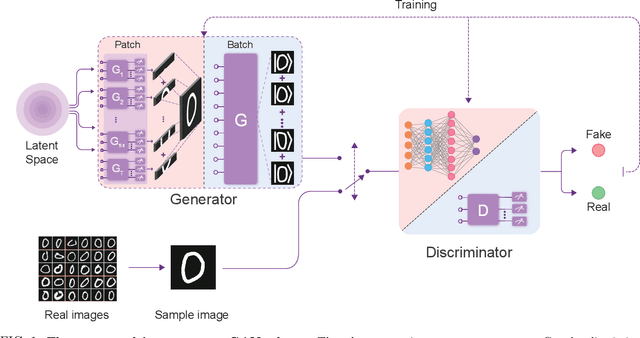

Quantum machine learning is expected to be one of the first practical applications of near-term quantum devices. Pioneer theoretical works suggest that quantum generative adversarial networks (GANs) may exhibit a potential exponential advantage over classical GANs, thus attracting widespread attention. However, it remains elusive whether quantum GANs implemented on near-term quantum devices can actually solve real-world learning tasks. Here, we devise a flexible quantum GAN scheme to narrow this knowledge gap, which could accomplish image generation with arbitrarily high-dimensional features, and could also take advantage of quantum superposition to train multiple examples in parallel. For the first time, we experimentally achieve the learning and generation of real-world hand-written digit images on a superconducting quantum processor. Moreover, we utilize a gray-scale bar dataset to exhibit the competitive performance between quantum GANs and the classical GANs based on multilayer perceptron and convolutional neural network architectures, respectively, benchmarked by the Fr\'echet Distance score. Our work provides guidance for developing advanced quantum generative models on near-term quantum devices and opens up an avenue for exploring quantum advantages in various GAN-related learning tasks.
Neighbourhood-Insensitive Point Cloud Normal Estimation Network
Aug 25, 2020
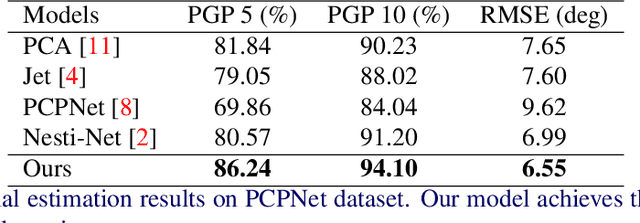
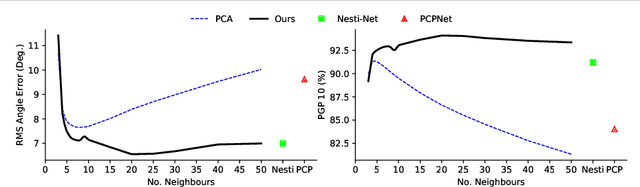
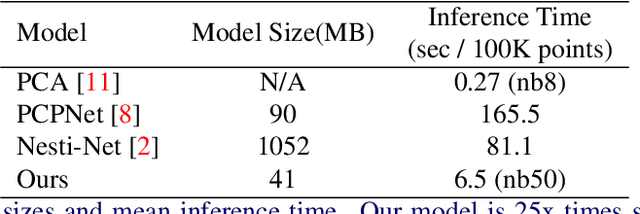
We introduce a novel self-attention-based normal estimation network that is able to focus softly on relevant points and adjust the softness by learning a temperature parameter, making it able to work naturally and effectively within a large neighbourhood range. As a result, our model outperforms all existing normal estimation algorithms by a large margin, achieving 94.1% accuracy in comparison with the previous state of the art of 91.2%, with a 25x smaller model and 12x faster inference time. We also use point-to-plane Iterative Closest Point (ICP) as an application case to show that our normal estimations lead to faster convergence than normal estimations from other methods, without manually fine-tuning neighbourhood range parameters. Code available at https://code.active.vision.
Deep Actor-Critic Learning for Distributed Power Control in Wireless Mobile Networks
Sep 14, 2020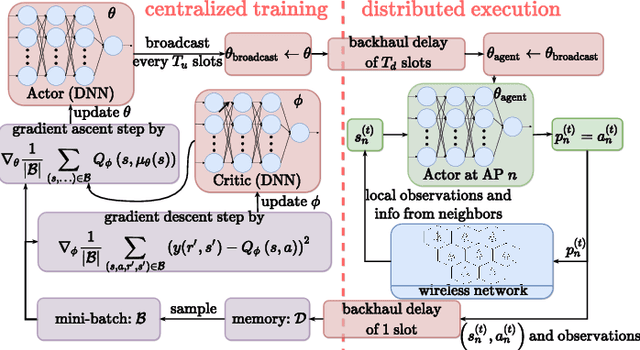
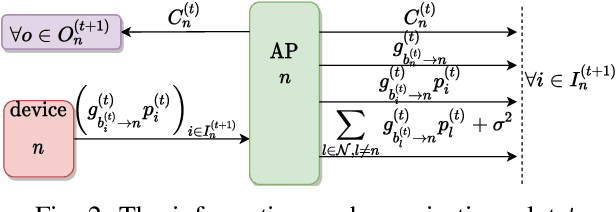
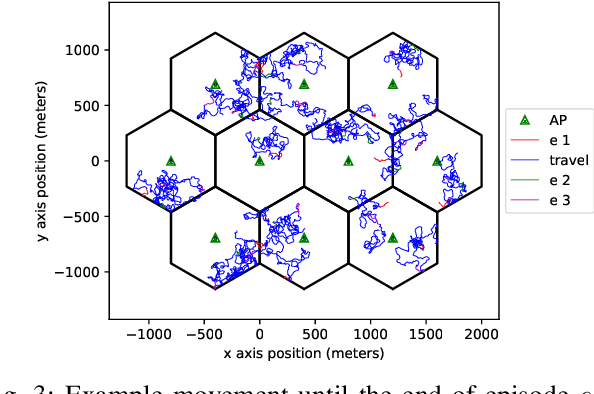
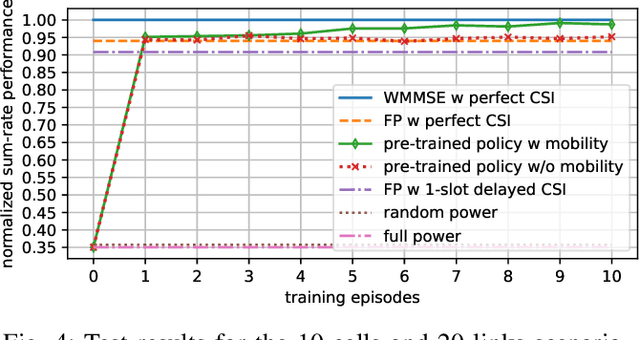
Deep reinforcement learning offers a model-free alternative to supervised deep learning and classical optimization for solving the transmit power control problem in wireless networks. The multi-agent deep reinforcement learning approach considers each transmitter as an individual learning agent that determines its transmit power level by observing the local wireless environment. Following a certain policy, these agents learn to collaboratively maximize a global objective, e.g., a sum-rate utility function. This multi-agent scheme is easily scalable and practically applicable to large-scale cellular networks. In this work, we present a distributively executed continuous power control algorithm with the help of deep actor-critic learning, and more specifically, by adapting deep deterministic policy gradient. Furthermore, we integrate the proposed power control algorithm to a time-slotted system where devices are mobile and channel conditions change rapidly. We demonstrate the functionality of the proposed algorithm using simulation results.
Modeling Future Cost for Neural Machine Translation
Feb 28, 2020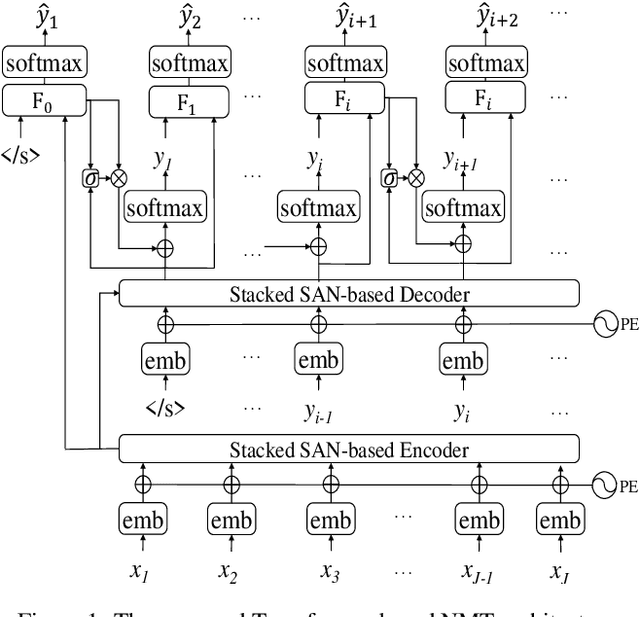
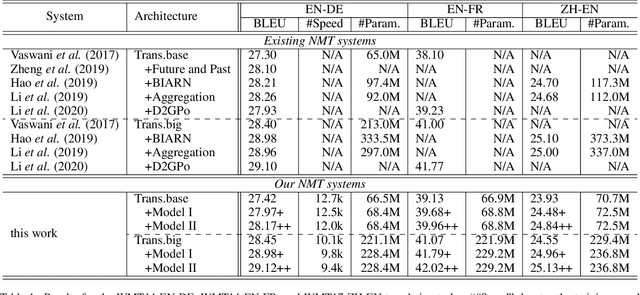
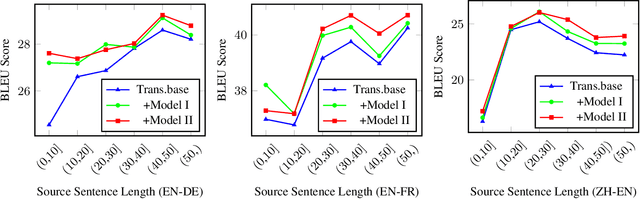
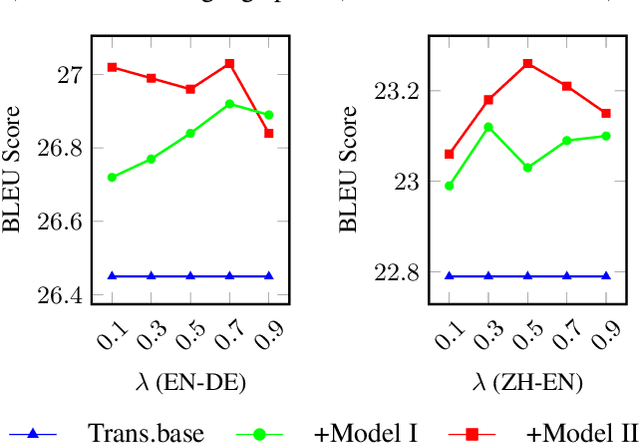
Existing neural machine translation (NMT) systems utilize sequence-to-sequence neural networks to generate target translation word by word, and then make the generated word at each time-step and the counterpart in the references as consistent as possible. However, the trained translation model tends to focus on ensuring the accuracy of the generated target word at the current time-step and does not consider its future cost which means the expected cost of generating the subsequent target translation (i.e., the next target word). To respond to this issue, we propose a simple and effective method to model the future cost of each target word for NMT systems. In detail, a time-dependent future cost is estimated based on the current generated target word and its contextual information to boost the training of the NMT model. Furthermore, the learned future context representation at the current time-step is used to help the generation of the next target word in the decoding. Experimental results on three widely-used translation datasets, including the WMT14 German-to-English, WMT14 English-to-French, and WMT17 Chinese-to-English, show that the proposed approach achieves significant improvements over strong Transformer-based NMT baseline.
PAN: Towards Fast Action Recognition via Learning Persistence of Appearance
Aug 08, 2020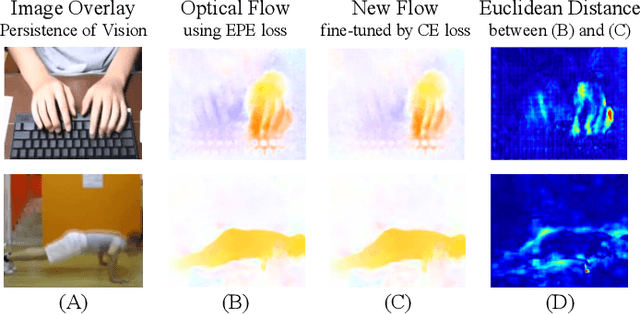
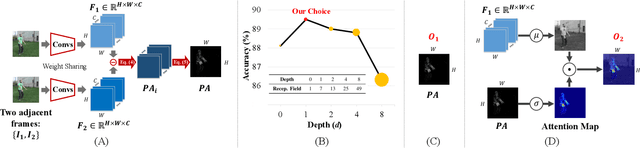
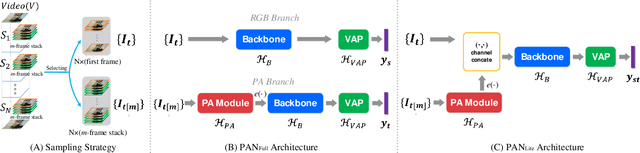
Efficiently modeling dynamic motion information in videos is crucial for action recognition task. Most state-of-the-art methods heavily rely on dense optical flow as motion representation. Although combining optical flow with RGB frames as input can achieve excellent recognition performance, the optical flow extraction is very time-consuming. This undoubtably will count against real-time action recognition. In this paper, we shed light on fast action recognition by lifting the reliance on optical flow. Our motivation lies in the observation that small displacements of motion boundaries are the most critical ingredients for distinguishing actions, so we design a novel motion cue called Persistence of Appearance (PA). In contrast to optical flow, our PA focuses more on distilling the motion information at boundaries. Also, it is more efficient by only accumulating pixel-wise differences in feature space, instead of using exhaustive patch-wise search of all the possible motion vectors. Our PA is over 1000x faster (8196fps vs. 8fps) than conventional optical flow in terms of motion modeling speed. To further aggregate the short-term dynamics in PA to long-term dynamics, we also devise a global temporal fusion strategy called Various-timescale Aggregation Pooling (VAP) that can adaptively model long-range temporal relationships across various timescales. We finally incorporate the proposed PA and VAP to form a unified framework called Persistent Appearance Network (PAN) with strong temporal modeling ability. Extensive experiments on six challenging action recognition benchmarks verify that our PAN outperforms recent state-of-the-art methods at low FLOPs. Codes and models are available at: https://github.com/zhang-can/PAN-PyTorch.