 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Transformer-Based Multi-Object Smoothing with Decoupled Data Association and Smoothing
Dec 22, 2023
Multi-object tracking (MOT) is the task of estimating the state trajectories of an unknown and time-varying number of objects over a certain time window. Several algorithms have been proposed to tackle the multi-object smoothing task, where object detections can be conditioned on all the measurements in the time window. However, the best-performing methods suffer from intractable computational complexity and require approximations, performing suboptimally in complex settings. Deep learning based algorithms are a possible venue for tackling this issue but have not been applied extensively in settings where accurate multi-object models are available and measurements are low-dimensional. We propose a novel DL architecture specifically tailored for this setting that decouples the data association task from the smoothing task. We compare the performance of the proposed smoother to the state-of-the-art in different tasks of varying difficulty and provide, to the best of our knowledge, the first comparison between traditional Bayesian trackers and DL trackers in the smoothing problem setting.
Simplicity bias, algorithmic probability, and the random logistic map
Dec 31, 2023Simplicity bias is an intriguing phenomenon prevalent in various input-output maps, characterized by a preference for simpler, more regular, or symmetric outputs. Notably, these maps typically feature high-probability outputs with simple patterns, whereas complex patterns are exponentially less probable. This bias has been extensively examined and attributed to principles derived from algorithmic information theory and algorithmic probability. In a significant advancement, it has been demonstrated that the renowned logistic map $x_{k+1}=\mu x_k(1-x_k)$, and other one-dimensional maps exhibit simplicity bias when conceptualized as input-output systems. Building upon this foundational work, our research delves into the manifestations of simplicity bias within the random logistic map, specifically focusing on scenarios involving additive noise. This investigation is driven by the overarching goal of formulating a comprehensive theory for the prediction and analysis of time series.Our primary contributions are multifaceted. We discover that simplicity bias is observable in the random logistic map for specific ranges of $\mu$ and noise magnitudes. Additionally, we find that this bias persists even with the introduction of small measurement noise, though it diminishes as noise levels increase. Our studies also revisit the phenomenon of noise-induced chaos, particularly when $\mu=3.83$, revealing its characteristics through complexity-probability plots. Intriguingly, we employ the logistic map to underscore a paradoxical aspect of data analysis: more data adhering to a consistent trend can occasionally lead to reduced confidence in extrapolation predictions, challenging conventional wisdom.We propose that adopting a probability-complexity perspective in analyzing dynamical systems could significantly enrich statistical learning theories related to series prediction.
AllSpark: a multimodal spatiotemporal general model
Dec 31, 2023For a long time, due to the high heterogeneity in structure and semantics among various spatiotemporal modal data, the joint interpretation of multimodal spatiotemporal data has been an extremely challenging problem. The primary challenge resides in striking a trade-off between the cohesion and autonomy of diverse modalities, and this trade-off exhibits a progressively nonlinear nature as the number of modalities expands. We introduce the Language as Reference Framework (LaRF), a fundamental principle for constructing a multimodal unified model, aiming to strike a trade-off between the cohesion and autonomy among different modalities. We propose a multimodal spatiotemporal general artificial intelligence model, called AllSpark. Our model integrates thirteen different modalities into a unified framework, including 1D (text, code), 2D (RGB, infrared, SAR, multispectral, hyperspectral, tables, graphs, trajectory, oblique photography), and 3D (point clouds, videos) modalities. To achieve modal cohesion, AllSpark uniformly maps diverse modal features to the language modality. In addition, we design modality-specific prompts to guide multi-modal large language models in accurately perceiving multimodal data. To maintain modality autonomy, AllSpark introduces modality-specific encoders to extract the tokens of various spatiotemporal modalities. And modal bridge is employed to achieve dimensional projection from each modality to the language modality. Finally, observing a gap between the model's interpretation and downstream tasks, we designed task heads to enhance the model's generalization capability on specific downstream tasks. Experiments indicate that AllSpark achieves competitive accuracy in modalities such as RGB and trajectory compared to state-of-the-art models.
EVI-SAM: Robust, Real-time, Tightly-coupled Event-Visual-Inertial State Estimation and 3D Dense Mapping
Dec 19, 2023Event cameras are bio-inspired, motion-activated sensors that demonstrate substantial potential in handling challenging situations, such as motion blur and high-dynamic range. In this paper, we proposed EVI-SAM to tackle the problem of 6 DoF pose tracking and 3D reconstruction using monocular event camera. A novel event-based hybrid tracking framework is designed to estimate the pose, leveraging the robustness of feature matching and the precision of direct alignment. Specifically, we develop an event-based 2D-2D alignment to construct the photometric constraint, and tightly integrate it with the event-based reprojection constraint. The mapping module recovers the dense and colorful depth of the scene through the image-guided event-based mapping method. Subsequently, the appearance, texture, and surface mesh of the 3D scene can be reconstructed by fusing the dense depth map from multiple viewpoints using truncated signed distance function (TSDF) fusion. To the best of our knowledge, this is the first non-learning work to realize event-based dense mapping. Numerical evaluations are performed on both publicly available and self-collected datasets, which qualitatively and quantitatively demonstrate the superior performance of our method. Our EVI-SAM effectively balances accuracy and robustness while maintaining computational efficiency, showcasing superior pose tracking and dense mapping performance in challenging scenarios. Video Demo: https://youtu.be/Nn40U4e5Si8.
Real-Time Surface-to-Air Missile Engagement Zone Prediction Using Simulation and Machine Learning
Dec 05, 2023Surface-to-Air Missiles (SAMs) are crucial in modern air defense systems. A critical aspect of their effectiveness is the Engagement Zone (EZ), the spatial region within which a SAM can effectively engage and neutralize a target. Notably, the EZ is intrinsically related to the missile's maximum range; it defines the furthest distance at which a missile can intercept a target. The accurate computation of this EZ is essential but challenging due to the dynamic and complex factors involved, which often lead to high computational costs and extended processing times when using conventional simulation methods. In light of these challenges, our study investigates the potential of machine learning techniques, proposing an approach that integrates machine learning with a custom-designed simulation tool to train supervised algorithms. We leverage a comprehensive dataset of pre-computed SAM EZ simulations, enabling our model to accurately predict the SAM EZ for new input parameters. It accelerates SAM EZ simulations, enhances air defense strategic planning, and provides real-time insights, improving SAM system performance. The study also includes a comparative analysis of machine learning algorithms, illuminating their capabilities and performance metrics and suggesting areas for future research, highlighting the transformative potential of machine learning in SAM EZ simulations.
LEFL: Low Entropy Client Sampling in Federated Learning
Dec 29, 2023Federated learning (FL) is a machine learning paradigm where multiple clients collaborate to optimize a single global model using their private data. The global model is maintained by a central server that orchestrates the FL training process through a series of training rounds. In each round, the server samples clients from a client pool before sending them its latest global model parameters for further optimization. Naive sampling strategies implement random client sampling and fail to factor client data distributions for privacy reasons. Hence we proposes an alternative sampling strategy by performing a one-time clustering of clients based on their model's learned high-level features while respecting data privacy. This enables the server to perform stratified client sampling across clusters in every round. We show datasets of sampled clients selected with this approach yield a low relative entropy with respect to the global data distribution. Consequently, the FL training becomes less noisy and significantly improves the convergence of the global model by as much as 7.4% in some experiments. Furthermore, it also significantly reduces the communication rounds required to achieve a target accuracy.
Exploring Time Granularity on Temporal Graphs for Dynamic Link Prediction in Real-world Networks
Nov 22, 2023Dynamic Graph Neural Networks (DGNNs) have emerged as the predominant approach for processing dynamic graph-structured data. However, the influence of temporal information on model performance and robustness remains insufficiently explored, particularly regarding how models address prediction tasks with different time granularities. In this paper, we explore the impact of time granularity when training DGNNs on dynamic graphs through extensive experiments. We examine graphs derived from various domains and compare three different DGNNs to the baseline model across four varied time granularities. We mainly consider the interplay between time granularities, model architectures, and negative sampling strategies to obtain general conclusions. Our results reveal that a sophisticated memory mechanism and proper time granularity are crucial for a DGNN to deliver competitive and robust performance in the dynamic link prediction task. We also discuss drawbacks in considered models and datasets and propose promising directions for future research on the time granularity of temporal graphs.
SANIA: Polyak-type Optimization Framework Leads to Scale Invariant Stochastic Algorithms
Dec 28, 2023Adaptive optimization methods are widely recognized as among the most popular approaches for training Deep Neural Networks (DNNs). Techniques such as Adam, AdaGrad, and AdaHessian utilize a preconditioner that modifies the search direction by incorporating information about the curvature of the objective function. However, despite their adaptive characteristics, these methods still require manual fine-tuning of the step-size. This, in turn, impacts the time required to solve a particular problem. This paper presents an optimization framework named SANIA to tackle these challenges. Beyond eliminating the need for manual step-size hyperparameter settings, SANIA incorporates techniques to address poorly scaled or ill-conditioned problems. We also explore several preconditioning methods, including Hutchinson's method, which approximates the Hessian diagonal of the loss function. We conclude with an extensive empirical examination of the proposed techniques across classification tasks, covering both convex and non-convex contexts.
A Two-stream Hybrid CNN-Transformer Network for Skeleton-based Human Interaction Recognition
Dec 31, 2023Human Interaction Recognition is the process of identifying interactive actions between multiple participants in a specific situation. The aim is to recognise the action interactions between multiple entities and their meaning. Many single Convolutional Neural Network has issues, such as the inability to capture global instance interaction features or difficulty in training, leading to ambiguity in action semantics. In addition, the computational complexity of the Transformer cannot be ignored, and its ability to capture local information and motion features in the image is poor. In this work, we propose a Two-stream Hybrid CNN-Transformer Network (THCT-Net), which exploits the local specificity of CNN and models global dependencies through the Transformer. CNN and Transformer simultaneously model the entity, time and space relationships between interactive entities respectively. Specifically, Transformer-based stream integrates 3D convolutions with multi-head self-attention to learn inter-token correlations; We propose a new multi-branch CNN framework for CNN-based streams that automatically learns joint spatio-temporal features from skeleton sequences. The convolutional layer independently learns the local features of each joint neighborhood and aggregates the features of all joints. And the raw skeleton coordinates as well as their temporal difference are integrated with a dual-branch paradigm to fuse the motion features of the skeleton. Besides, a residual structure is added to speed up training convergence. Finally, the recognition results of the two branches are fused using parallel splicing. Experimental results on diverse and challenging datasets, demonstrate that the proposed method can better comprehend and infer the meaning and context of various actions, outperforming state-of-the-art methods.
Hierarchical Joint Graph Learning and Multivariate Time Series Forecasting
Nov 21, 2023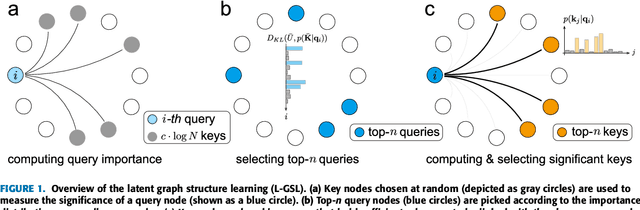

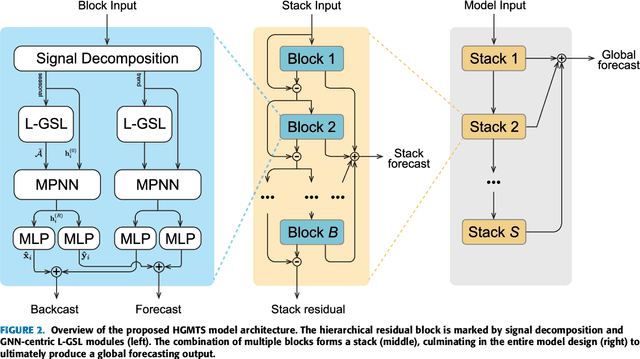
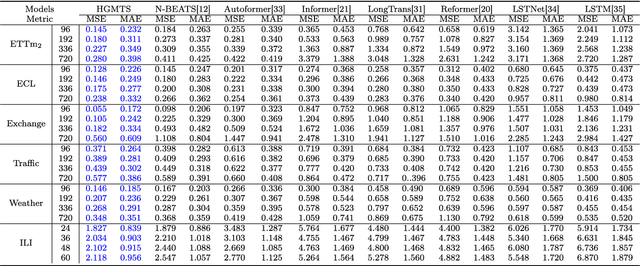
Multivariate time series is prevalent in many scientific and industrial domains. Modeling multivariate signals is challenging due to their long-range temporal dependencies and intricate interactions--both direct and indirect. To confront these complexities, we introduce a method of representing multivariate signals as nodes in a graph with edges indicating interdependency between them. Specifically, we leverage graph neural networks (GNN) and attention mechanisms to efficiently learn the underlying relationships within the time series data. Moreover, we suggest employing hierarchical signal decompositions running over the graphs to capture multiple spatial dependencies. The effectiveness of our proposed model is evaluated across various real-world benchmark datasets designed for long-term forecasting tasks. The results consistently showcase the superiority of our model, achieving an average 23\% reduction in mean squared error (MSE) compared to existing models.