 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Primal-Dual Mesh Convolutional Neural Networks
Oct 23, 2020
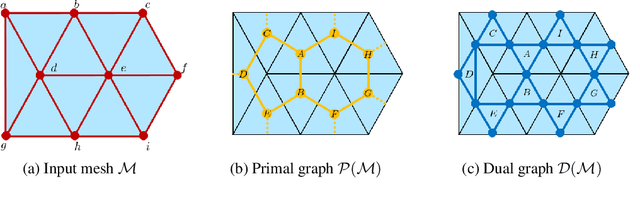
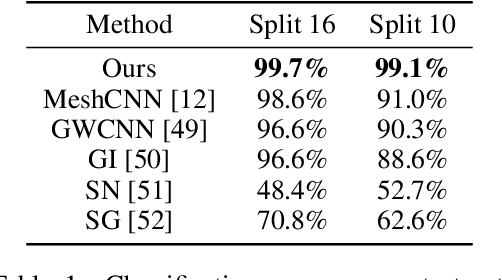

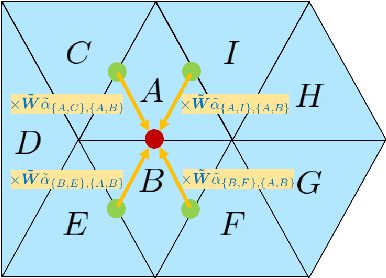
Recent works in geometric deep learning have introduced neural networks that allow performing inference tasks on three-dimensional geometric data by defining convolution, and sometimes pooling, operations on triangle meshes. These methods, however, either consider the input mesh as a graph, and do not exploit specific geometric properties of meshes for feature aggregation and downsampling, or are specialized for meshes, but rely on a rigid definition of convolution that does not properly capture the local topology of the mesh. We propose a method that combines the advantages of both types of approaches, while addressing their limitations: we extend a primal-dual framework drawn from the graph-neural-network literature to triangle meshes, and define convolutions on two types of graphs constructed from an input mesh. Our method takes features for both edges and faces of a 3D mesh as input and dynamically aggregates them using an attention mechanism. At the same time, we introduce a pooling operation with a precise geometric interpretation, that allows handling variations in the mesh connectivity by clustering mesh faces in a task-driven fashion. We provide theoretical insights of our approach using tools from the mesh-simplification literature. In addition, we validate experimentally our method in the tasks of shape classification and shape segmentation, where we obtain comparable or superior performance to the state of the art.
* Accepted to the 34th Conference on Neural Information Processing Systems (NeurIPS 2020), Vancouver, Canada. Code available at: https://github.com/MIT-SPARK/PD-MeshNet
Adaptive Shape Servoing of Elastic Rods using Parameterized Regression Features and Auto-Tuning Motion Controls
Aug 16, 2020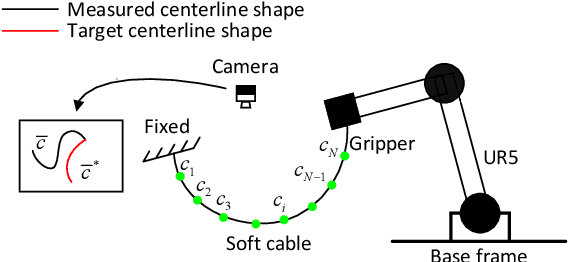
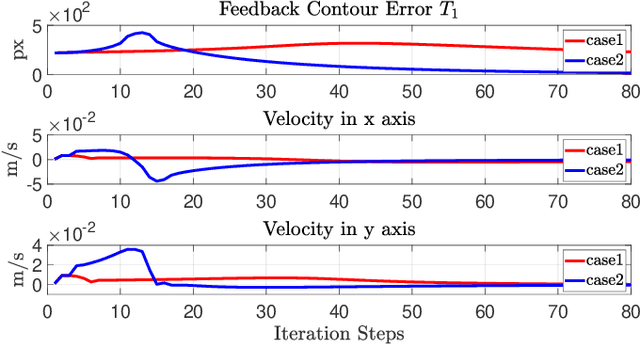
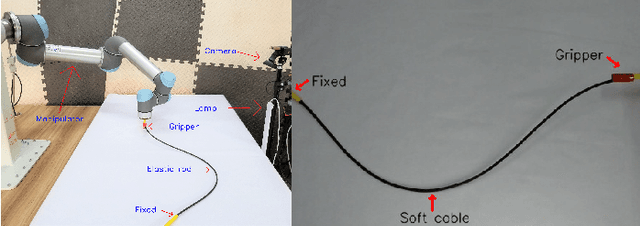

In this paper, we present a new vision-based method to control the shape of elastic rods with robot manipulators. Our new method computes parameterized regression features from online sensor measurements that enable to automatically quantify the object's configuration and establish an explicit shape servo-loop. To automatically deform the rod into a desired shape, our adaptive controller iteratively estimates the differential transformation between the robot's motion and the relative shape changes; This valuable capability allows to effectively manipulate objects with unknown mechanical models. An auto-tuning algorithm is introduced to adjust the robot's shaping motion in real-time based on optimal performance criteria. To validate the proposed theory, we present a detailed numerical and experimental study with vision-guided robotic manipulators.
Optimal target assignment for massive spectroscopic surveys
May 18, 2020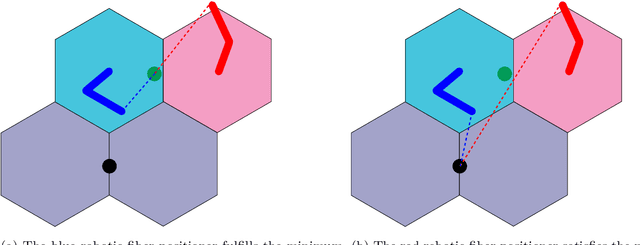

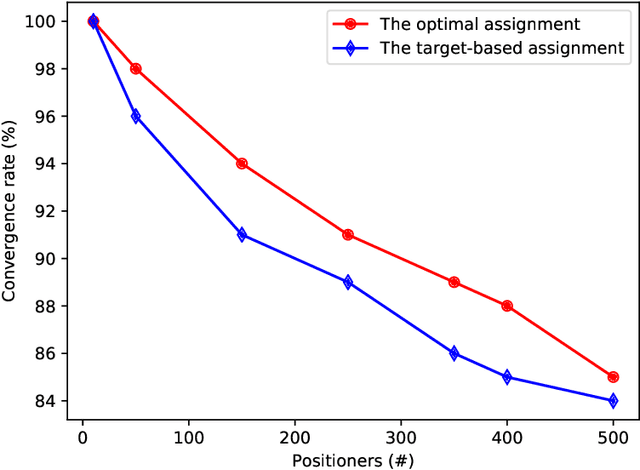
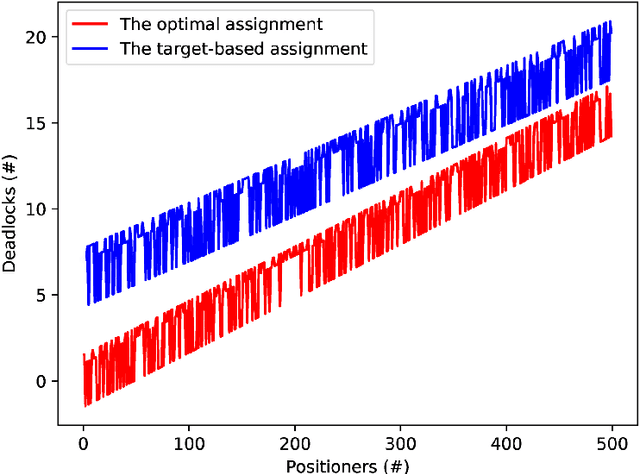
Robotics have recently contributed to cosmological spectroscopy to automatically obtain the map of the observable universe using robotic fiber positioners. For this purpose, an assignment algorithm is required to assign each robotic fiber positioner to a target associated with a particular observation. The assignment process directly impacts on the coordination of robotic fiber positioners to reach their assigned targets. In this paper, we establish an optimal target assignment scheme which simultaneously provides the fastest coordination accompanied with the minimum of colliding scenarios between robotic fiber positioners. In particular, we propose a cost function by whose minimization both of the cited requirements are taken into account in the course of a target assignment process. The applied simulations manifest the improvement of convergence rates using our optimal approach. We show that our algorithm scales the solution in quadratic time in the case of full observations. Additionally, the convergence time and the percentage of the colliding scenarios are also decreased in both supervisory and hybrid coordination strategies.
Event-based Stereo Visual Odometry
Jul 30, 2020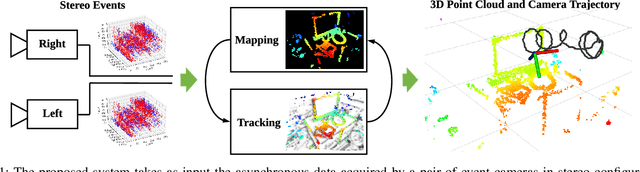


Event-based cameras are bio-inspired vision sensors whose pixels work independently from each other and respond asynchronously to brightness changes, with microsecond resolution. Their advantages make it possible to tackle challenging scenarios in robotics, such as high-speed and high dynamic range scenes. We present a solution to the problem of visual odometry from the data acquired by a stereo event-based camera rig. Our system follows a parallel tracking-and-mapping approach, where novel solutions to each subproblem (3D reconstruction and camera pose estimation) are developed with two objectives in mind: being principled and efficient, for real-time operation with commodity hardware. To this end, we seek to maximize the spatio-temporal consistency of stereo event-based data while using a simple and efficient representation. Specifically, the mapping module builds a semi-dense 3D map of the scene by fusing depth estimates from multiple local viewpoints (obtained by spatio-temporal consistency) in a probabilistic fashion. The tracking module recovers the pose of the stereo rig by solving a registration problem that naturally arises due to the chosen map and event data representation. Experiments on publicly available datasets and on our own recordings demonstrate the versatility of the proposed method in natural scenes with general 6-DoF motion. The system successfully leverages the advantages of event-based cameras to perform visual odometry in challenging illumination conditions, such as low-light and high dynamic range, while running in real-time on a standard CPU. We release the software and dataset under an open source licence to foster research in the emerging topic of event-based SLAM.
An Asymptotically Optimal Primal-Dual Incremental Algorithm for Contextual Linear Bandits
Oct 23, 2020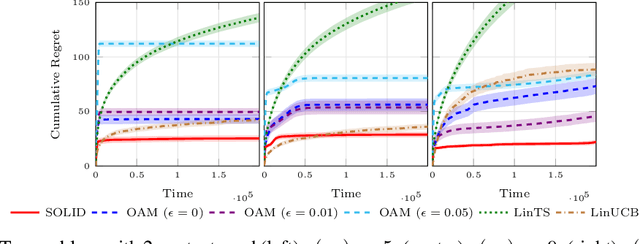

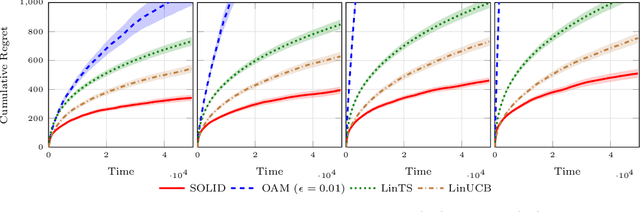
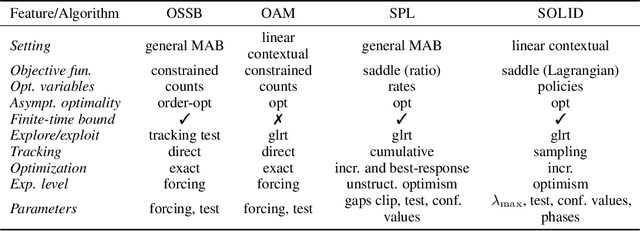
In the contextual linear bandit setting, algorithms built on the optimism principle fail to exploit the structure of the problem and have been shown to be asymptotically suboptimal. In this paper, we follow recent approaches of deriving asymptotically optimal algorithms from problem-dependent regret lower bounds and we introduce a novel algorithm improving over the state-of-the-art along multiple dimensions. We build on a reformulation of the lower bound, where context distribution and exploration policy are decoupled, and we obtain an algorithm robust to unbalanced context distributions. Then, using an incremental primal-dual approach to solve the Lagrangian relaxation of the lower bound, we obtain a scalable and computationally efficient algorithm. Finally, we remove forced exploration and build on confidence intervals of the optimization problem to encourage a minimum level of exploration that is better adapted to the problem structure. We demonstrate the asymptotic optimality of our algorithm, while providing both problem-dependent and worst-case finite-time regret guarantees. Our bounds scale with the logarithm of the number of arms, thus avoiding the linear dependence common in all related prior works. Notably, we establish minimax optimality for any learning horizon in the special case of non-contextual linear bandits. Finally, we verify that our algorithm obtains better empirical performance than state-of-the-art baselines.
Some Experiments with Real-Time Decision Algorithms
Feb 13, 2013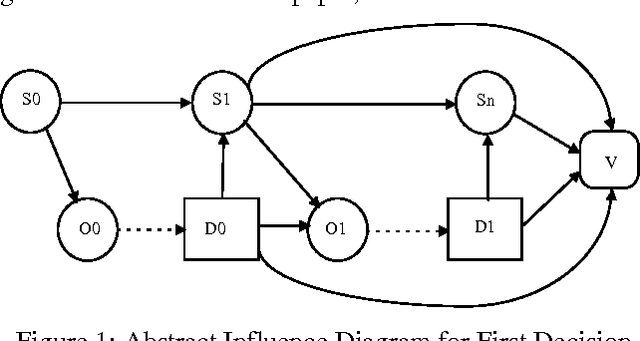
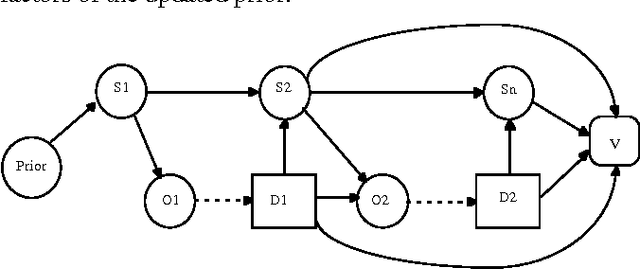
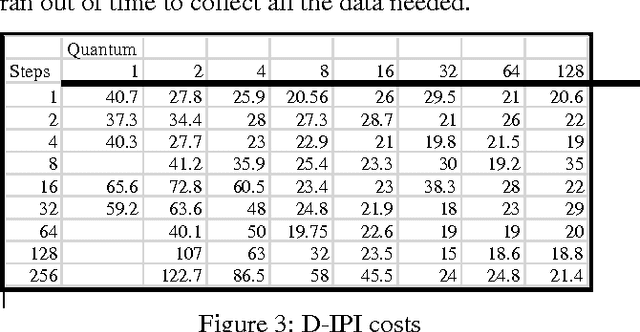
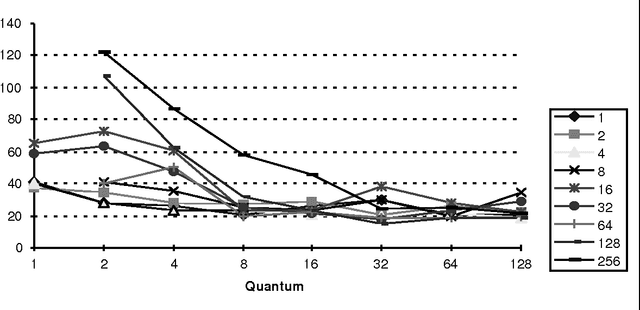
Real-time Decision algorithms are a class of incremental resource-bounded [Horvitz, 89] or anytime [Dean, 93] algorithms for evaluating influence diagrams. We present a test domain for real-time decision algorithms, and the results of experiments with several Real-time Decision Algorithms in this domain. The results demonstrate high performance for two algorithms, a decision-evaluation variant of Incremental Probabilisitic Inference [D'Ambrosio 93] and a variant of an algorithm suggested by Goldszmidt, [Goldszmidt, 95], PK-reduced. We discuss the implications of these experimental results and explore the broader applicability of these algorithms.
OT-Flow: Fast and Accurate Continuous Normalizing Flows via Optimal Transport
Jun 22, 2020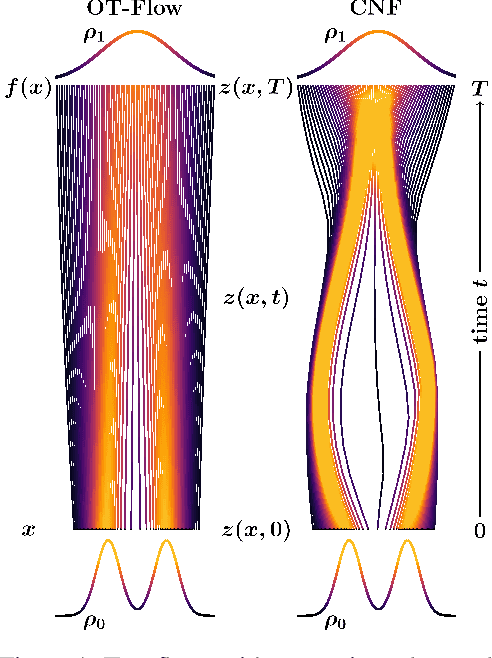

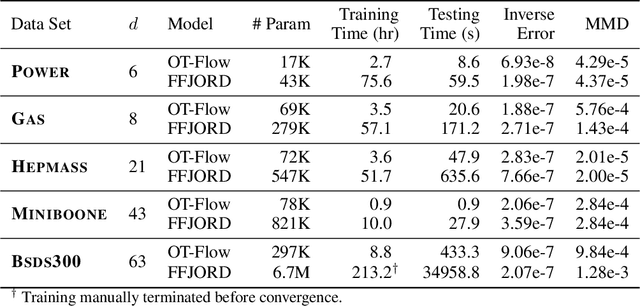
A normalizing flow is an invertible mapping between an arbitrary probability distribution and a standard normal distribution; it can be used for density estimation and statistical inference. Computing the flow follows the change of variables formula and thus requires invertibility of the mapping and an efficient way to compute the determinant of its Jacobian. To satisfy these requirements, normalizing flows typically consist of carefully chosen components. Continuous normalizing flows (CNFs) are mappings obtained by solving a neural ordinary differential equation (ODE). The neural ODE's dynamics can be chosen almost arbitrarily while ensuring invertibility. Moreover, the log-determinant of the flow's Jacobian can be obtained by integrating the trace of the dynamics' Jacobian along the flow. Our proposed OT-Flow approach tackles two critical computational challenges that limit a more widespread use of CNFs. First, OT-Flow leverages optimal transport (OT) theory to regularize the CNF and enforce straight trajectories that are easier to integrate. Second, OT-Flow features exact trace computation with time complexity equal to trace estimators used in existing CNFs. On five high-dimensional density estimation and generative modeling tasks, OT-Flow performs competitively to a state-of-the-art CNF while on average requiring one-fourth of the number of weights with 19x speedup in training time and 28x speedup in inference.
PowerPlanningDL: Reliability-Aware Framework for On-Chip Power Grid Design using Deep Learning
May 04, 2020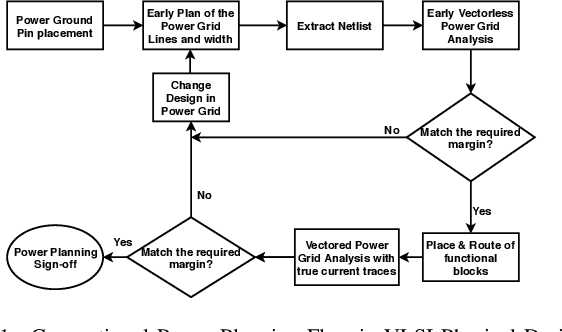
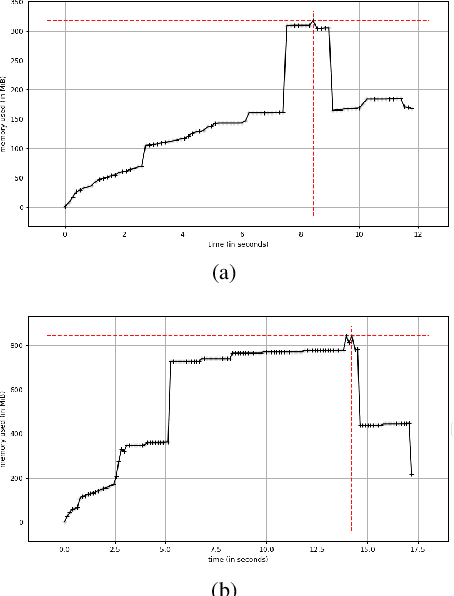
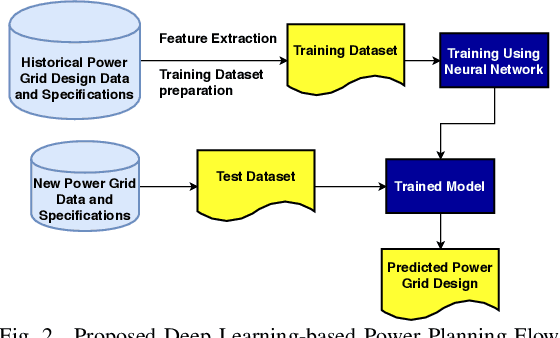
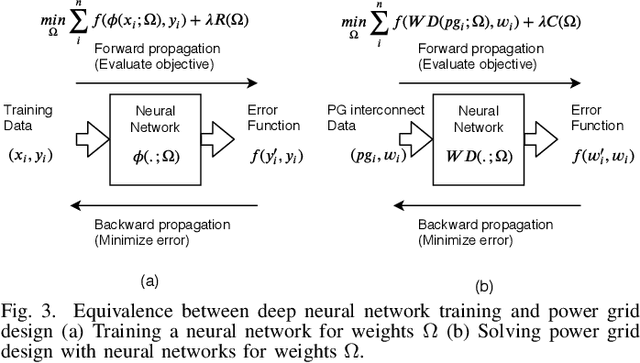
With the increase in the complexity of chip designs, VLSI physical design has become a time-consuming task, which is an iterative design process. Power planning is that part of the floorplanning in VLSI physical design where power grid networks are designed in order to provide adequate power to all the underlying functional blocks. Power planning also requires multiple iterative steps to create the power grid network while satisfying the allowed worst-case IR drop and Electromigration (EM) margin. For the first time, this paper introduces Deep learning (DL)-based framework to approximately predict the initial design of the power grid network, considering different reliability constraints. The proposed framework reduces many iterative design steps and speeds up the total design cycle. Neural Network-based multi-target regression technique is used to create the DL model. Feature extraction is done, and the training dataset is generated from the floorplans of some of the power grid designs extracted from the IBM processor. The DL model is trained using the generated dataset. The proposed DL-based framework is validated using a new set of power grid specifications (obtained by perturbing the designs used in the training phase). The results show that the predicted power grid design is closer to the original design with minimal prediction error (~2%). The proposed DL-based approach also improves the design cycle time with a speedup of ~6X for standard power grid benchmarks.
Convolutional neural network based deep-learning architecture for intraprostatic tumour contouring on PSMA PET images in patients with primary prostate cancer
Aug 07, 2020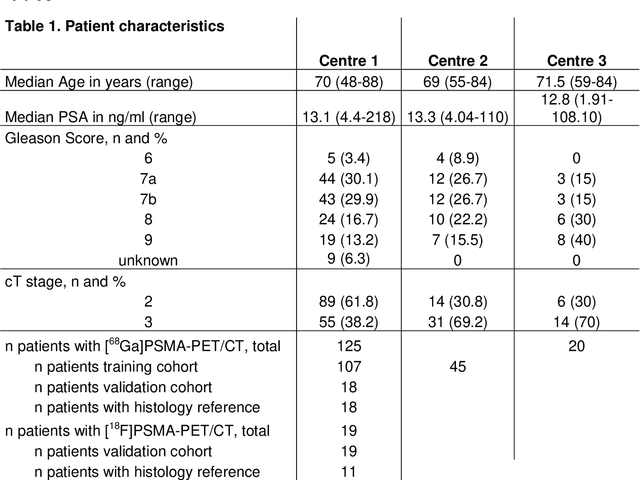
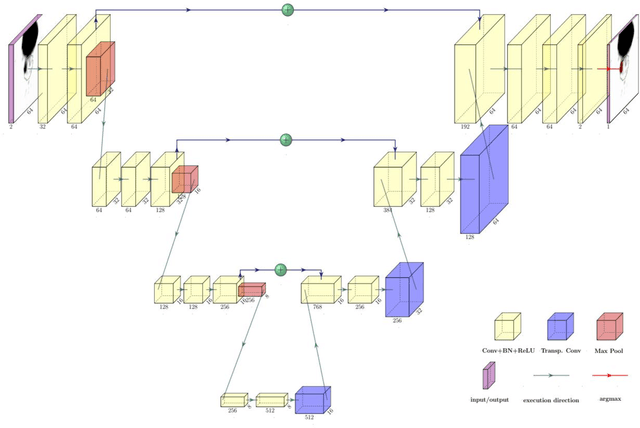
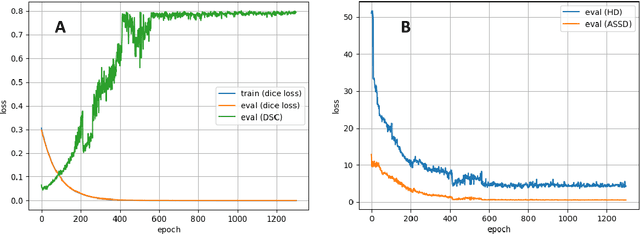

Accurate delineation of the intraprostatic gross tumour volume (GTV) is a prerequisite for treatment approaches in patients with primary prostate cancer (PCa). Prostate-specific membrane antigen positron emission tomography (PSMA-PET) may outperform MRI in GTV detection. However, visual GTV delineation underlies interobserver heterogeneity and is time consuming. The aim of this study was to develop a convolutional neural network (CNN) for automated segmentation of intraprostatic tumour (GTV-CNN) in PSMA-PET. Methods: The CNN (3D U-Net) was trained on [68Ga]PSMA-PET images of 152 patients from two different institutions and the training labels were generated manually using a validated technique. The CNN was tested on two independent internal (cohort 1: [68Ga]PSMA-PET, n=18 and cohort 2: [18F]PSMA-PET, n=19) and one external (cohort 3: [68Ga]PSMA-PET, n=20) test-datasets. Accordance between manual contours and GTV-CNN was assessed with Dice-S{\o}rensen coefficient (DSC). Sensitivity and specificity were calculated for the two internal test-datasets by using whole-mount histology. Results: Median DSCs for cohorts 1-3 were 0.84 (range: 0.32-0.95), 0.81 (range: 0.28-0.93) and 0.83 (range: 0.32-0.93), respectively. Sensitivities and specificities for GTV-CNN were comparable with manual expert contours: 0.98 and 0.76 (cohort 1) and 1 and 0.57 (cohort 2), respectively. Computation time was around 6 seconds for a standard dataset. Conclusion: The application of a CNN for automated contouring of intraprostatic GTV in [68Ga]PSMA- and [18F]PSMA-PET images resulted in a high concordance with expert contours and in high sensitivities and specificities in comparison with histology reference. This robust, accurate and fast technique may be implemented for treatment concepts in primary PCa. The trained model and the study's source code are available in an open source repository.
Deep learning for video game genre classification
Nov 21, 2020

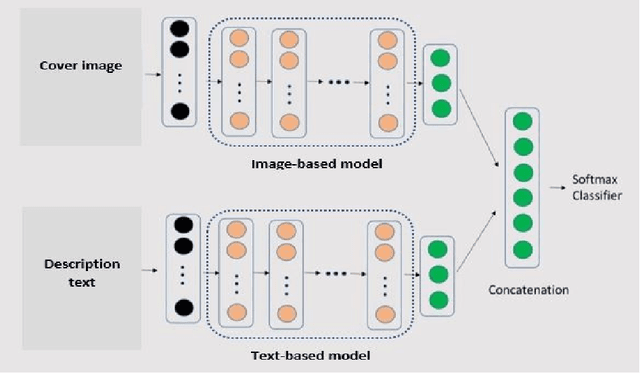
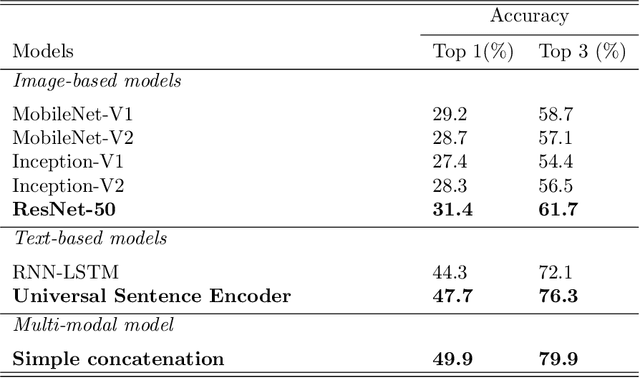
Video game genre classification based on its cover and textual description would be utterly beneficial to many modern identification, collocation, and retrieval systems. At the same time, it is also an extremely challenging task due to the following reasons: First, there exists a wide variety of video game genres, many of which are not concretely defined. Second, video game covers vary in many different ways such as colors, styles, textual information, etc, even for games of the same genre. Third, cover designs and textual descriptions may vary due to many external factors such as country, culture, target reader populations, etc. With the growing competitiveness in the video game industry, the cover designers and typographers push the cover designs to its limit in the hope of attracting sales. The computer-based automatic video game genre classification systems become a particularly exciting research topic in recent years. In this paper, we propose a multi-modal deep learning framework to solve this problem. The contribution of this paper is four-fold. First, we compiles a large dataset consisting of 50,000 video games from 21 genres made of cover images, description text, and title text and the genre information. Second, image-based and text-based, state-of-the-art models are evaluated thoroughly for the task of genre classification for video games. Third, we developed an efficient and salable multi-modal framework based on both images and texts. Fourth, a thorough analysis of the experimental results is given and future works to improve the performance is suggested. The results show that the multi-modal framework outperforms the current state-of-the-art image-based or text-based models. Several challenges are outlined for this task. More efforts and resources are needed for this classification task in order to reach a satisfactory level.