 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Bidirectional Sampling Based Search Without Two Point Boundary Value Solution
Oct 28, 2020
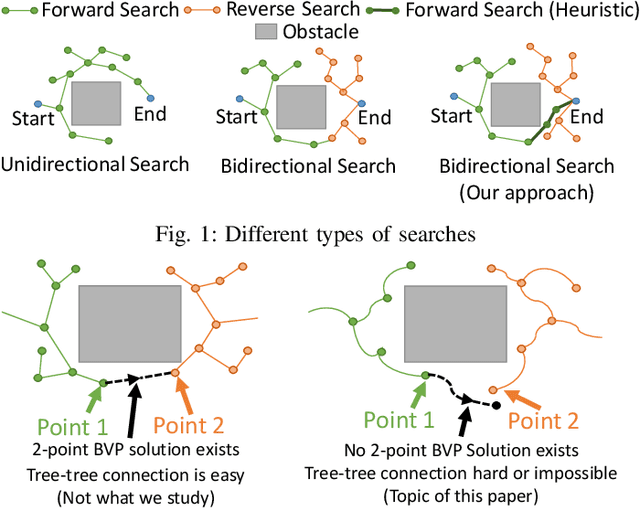
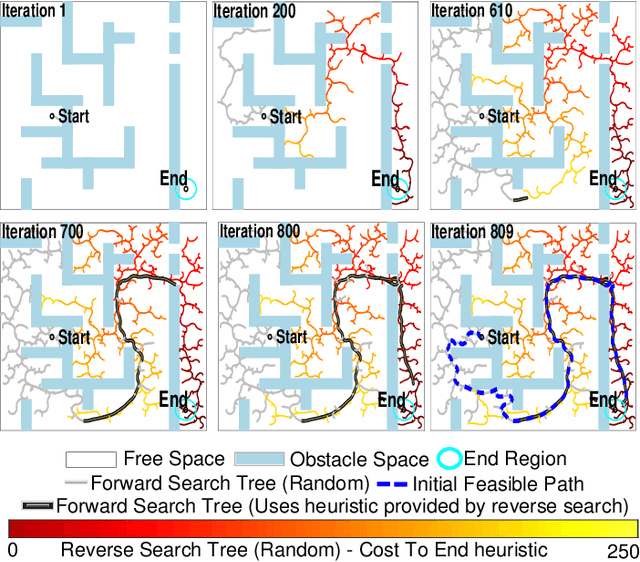

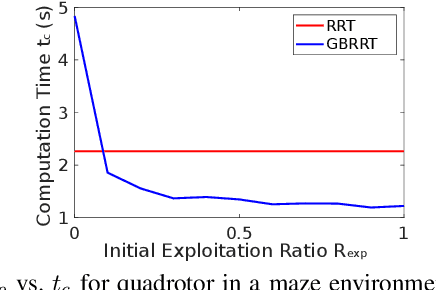
Bidirectional path and motion planning approaches decrease planning time, on average, compared to their unidirectional counterparts. In the context of single-query feasible motion planning, using bidirectional search to find a continuous motion plan requires an explicit connection between the forward search tree and the reverse search tree. Such a tree-tree connection requires solving a two-point Boundary Value Problem (BVP). However, two-point BVP solution can be difficult or impossible to calculate for many types of vehicles (using numerical methods to find a solution, such as shooting approaches may be computationally expensive and is sometimes numerically unstable). To overcome this challenge, we present a generalized bidirectional search algorithm that does not require solving two-point BVP. Instead of connecting the two trees directly, our algorithm uses the cost information of the reverse tree as a guiding heuristic for forward search. This enables the forward search to quickly converge to a full feasible solution without an explicit tree-tree connection and without the solution to a two-point BVP. We run multiple software simulations in different environments and using dynamics of different vehicles along with real-world hardware experiments to show that our approach performs very close or better than existing state of the art approaches in terms of quickly converging to an initial feasible solution.
Economy Statistical Recurrent Units For Inferring Nonlinear Granger Causality
Jan 14, 2020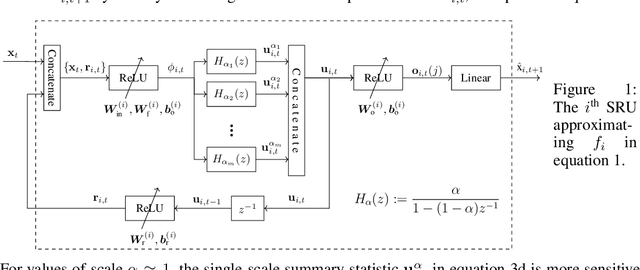

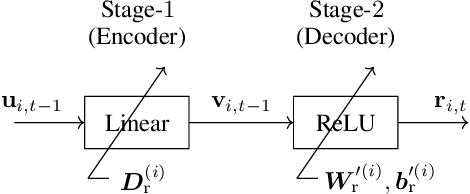
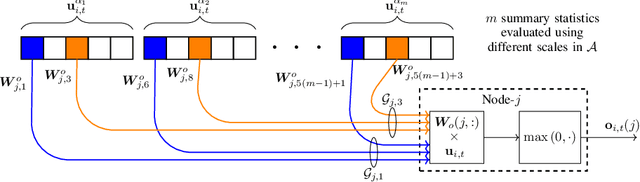
Granger causality is a widely-used criterion for analyzing interactions in large-scale networks. As most physical interactions are inherently nonlinear, we consider the problem of inferring the existence of pairwise Granger causality between nonlinearly interacting stochastic processes from their time series measurements. Our proposed approach relies on modeling the embedded nonlinearities in the measurements using a component-wise time series prediction model based on Statistical Recurrent Units (SRUs). We make a case that the network topology of Granger causal relations is directly inferrable from a structured sparse estimate of the internal parameters of the SRU networks trained to predict the processes$'$ time series measurements. We propose a variant of SRU, called economy-SRU, which, by design has considerably fewer trainable parameters, and therefore less prone to overfitting. The economy-SRU computes a low-dimensional sketch of its high-dimensional hidden state in the form of random projections to generate the feedback for its recurrent processing. Additionally, the internal weight parameters of the economy-SRU are strategically regularized in a group-wise manner to facilitate the proposed network in extracting meaningful predictive features that are highly time-localized to mimic real-world causal events. Extensive experiments are carried out to demonstrate that the proposed economy-SRU based time series prediction model outperforms the MLP, LSTM and attention-gated CNN-based time series models considered previously for inferring Granger causality.
Streaming Submodular Maximization with Fairness Constraints
Oct 09, 2020We study the problem of extracting a small subset of representative items from a large data stream. Following the convention in many data mining and machine learning applications such as data summarization, recommender systems, and social network analysis, the problem is formulated as maximizing a monotone submodular function subject to a cardinality constraint -- i.e., the size of the selected subset is restricted to be smaller than or equal to an input integer $k$. In this paper, we consider the problem with additional \emph{fairness constraints}, which takes into account the group membership of data items and limits the number of items selected from each group to a given number. We propose efficient algorithms for this fairness-aware variant of the streaming submodular maximization problem. In particular, we first provide a $(\frac{1}{2}-\varepsilon)$-approximation algorithm that requires $O(\frac{1}{\varepsilon} \cdot \log \frac{k}{\varepsilon})$ passes over the stream for any constant $ \varepsilon>0 $. In addition, we design a single-pass streaming algorithm that has the same $(\frac{1}{2}-\varepsilon)$ approximation ratio when unlimited buffer size and post-processing time is permitted.
Time and Activity Sequence Prediction of Business Process Instances
Feb 24, 2016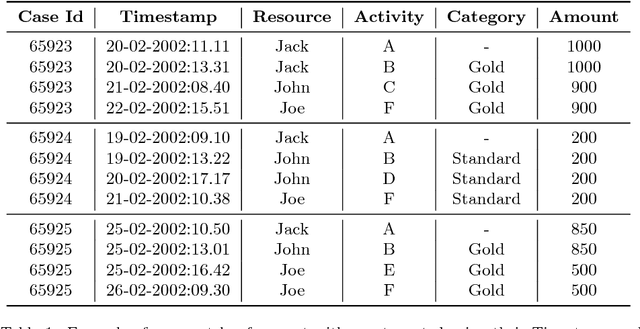
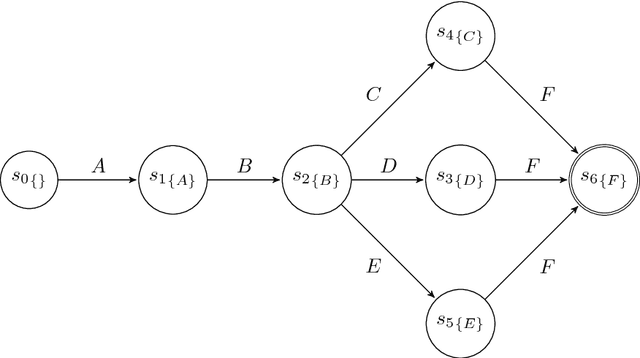

The ability to know in advance the trend of running process instances, with respect to different features, such as the expected completion time, would allow business managers to timely counteract to undesired situations, in order to prevent losses. Therefore, the ability to accurately predict future features of running business process instances would be a very helpful aid when managing processes, especially under service level agreement constraints. However, making such accurate forecasts is not easy: many factors may influence the predicted features. Many approaches have been proposed to cope with this problem but all of them assume that the underling process is stationary. However, in real cases this assumption is not always true. In this work we present new methods for predicting the remaining time of running cases. In particular we propose a method, assuming process stationarity, which outperforms the state-of-the-art and two other methods which are able to make predictions even with non-stationary processes. We also describe an approach able to predict the full sequence of activities that a running case is going to take. All these methods are extensively evaluated on two real case studies.
APMSqueeze: A Communication Efficient Adam-Preconditioned Momentum SGD Algorithm
Aug 28, 2020
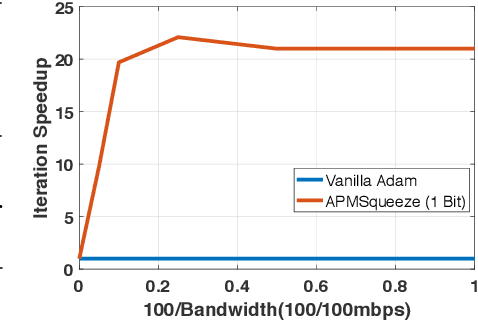
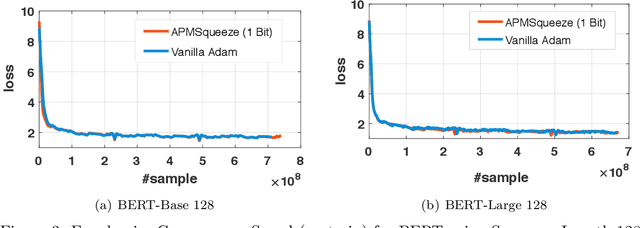
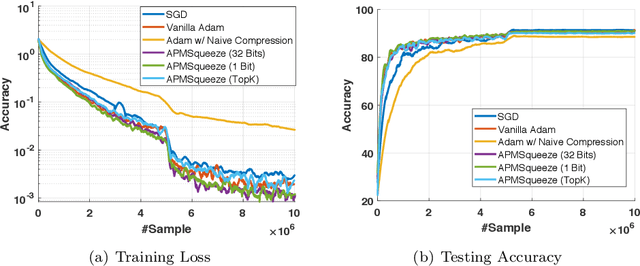
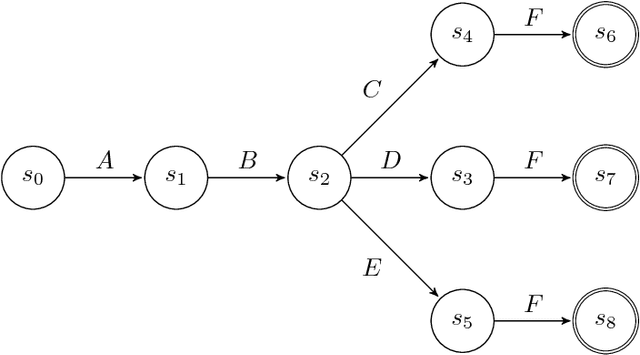
Adam is the important optimization algorithm to guarantee efficiency and accuracy for training many important tasks such as BERT and ImageNet. However, Adam is generally not compatible with information (gradient) compression technology. Therefore, the communication usually becomes the bottleneck for parallelizing Adam. In this paper, we propose a communication efficient {\bf A}DAM {\bf p}reconditioned {\bf M}omentum SGD algorithm-- named APMSqueeze-- through an error compensated method compressing gradients. The proposed algorithm achieves a similar convergence efficiency to Adam in term of epochs, but significantly reduces the running time per epoch. In terms of end-to-end performance (including the full-precision pre-condition step), APMSqueeze is able to provide {sometimes by up to $2-10\times$ speed-up depending on network bandwidth.} We also conduct theoretical analysis on the convergence and efficiency.
Some Experiments with Real-Time Decision Algorithms
Feb 13, 2013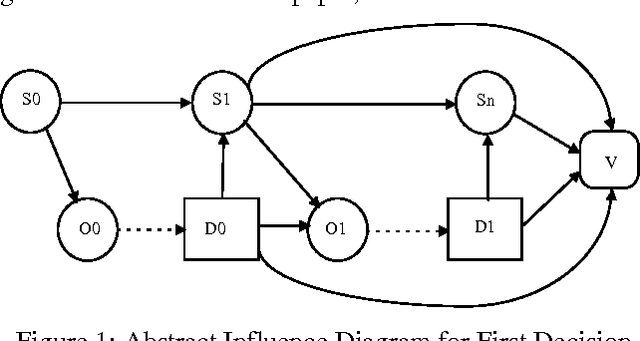
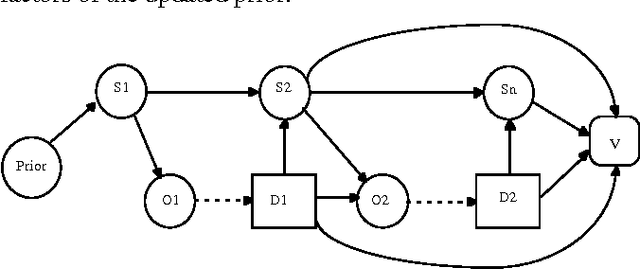
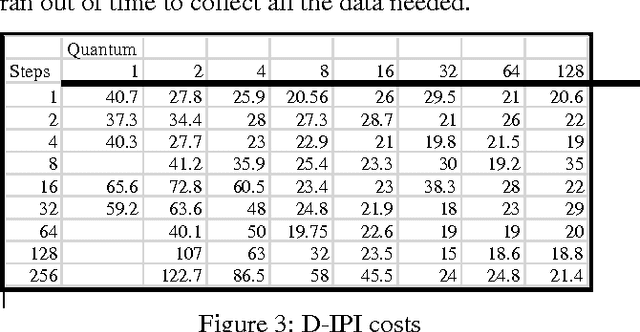
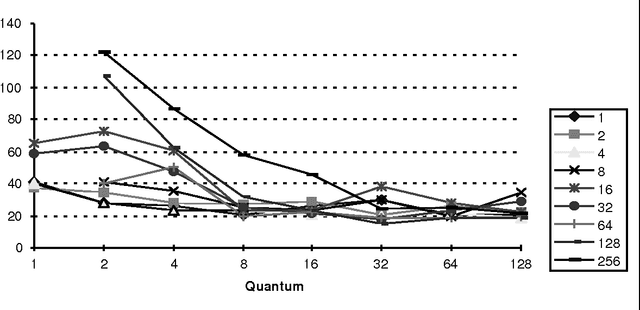
Real-time Decision algorithms are a class of incremental resource-bounded [Horvitz, 89] or anytime [Dean, 93] algorithms for evaluating influence diagrams. We present a test domain for real-time decision algorithms, and the results of experiments with several Real-time Decision Algorithms in this domain. The results demonstrate high performance for two algorithms, a decision-evaluation variant of Incremental Probabilisitic Inference [D'Ambrosio 93] and a variant of an algorithm suggested by Goldszmidt, [Goldszmidt, 95], PK-reduced. We discuss the implications of these experimental results and explore the broader applicability of these algorithms.
Constrained Reinforcement Learning for Dynamic Optimization under Uncertainty
Jun 04, 2020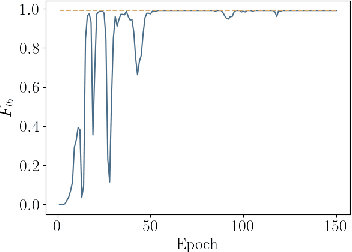
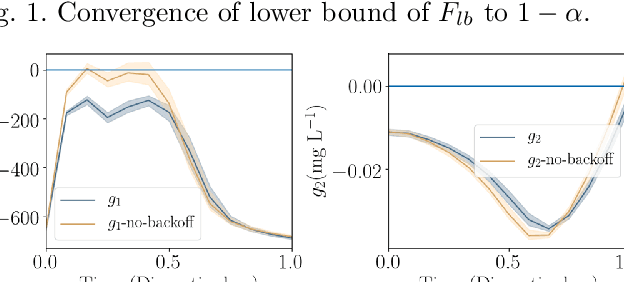
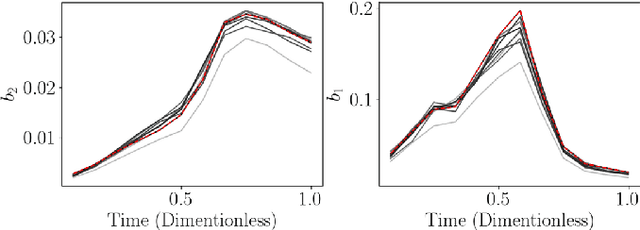
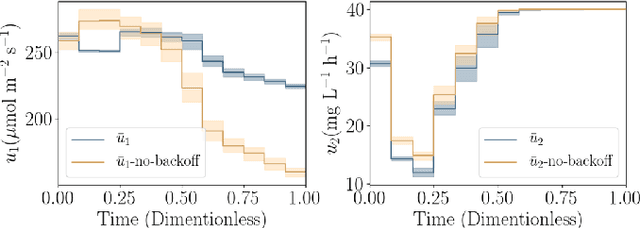
Dynamic real-time optimization (DRTO) is a challenging task due to the fact that optimal operating conditions must be computed in real time. The main bottleneck in the industrial application of DRTO is the presence of uncertainty. Many stochastic systems present the following obstacles: 1) plant-model mismatch, 2) process disturbances, 3) risks in violation of process constraints. To accommodate these difficulties, we present a constrained reinforcement learning (RL) based approach. RL naturally handles the process uncertainty by computing an optimal feedback policy. However, no state constraints can be introduced intuitively. To address this problem, we present a chance-constrained RL methodology. We use chance constraints to guarantee the probabilistic satisfaction of process constraints, which is accomplished by introducing backoffs, such that the optimal policy and backoffs are computed simultaneously. Backoffs are adjusted using the empirical cumulative distribution function to guarantee the satisfaction of a joint chance constraint. The advantage and performance of this strategy are illustrated through a stochastic dynamic bioprocess optimization problem, to produce sustainable high-value bioproducts.
Robust Learning under Strong Noise via SQs
Oct 18, 2020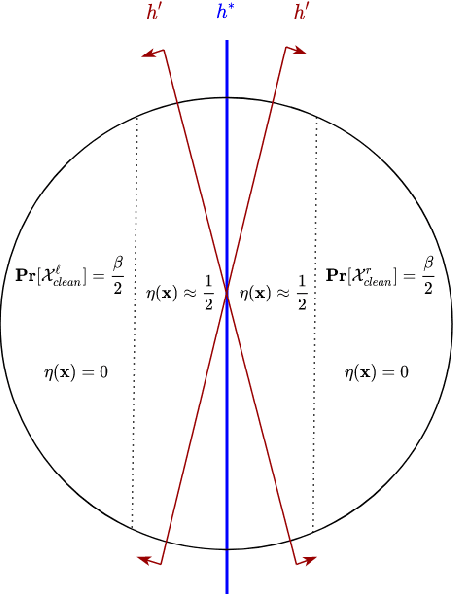
This work provides several new insights on the robustness of Kearns' statistical query framework against challenging label-noise models. First, we build on a recent result by \cite{DBLP:journals/corr/abs-2006-04787} that showed noise tolerance of distribution-independently evolvable concept classes under Massart noise. Specifically, we extend their characterization to more general noise models, including the Tsybakov model which considerably generalizes the Massart condition by allowing the flipping probability to be arbitrarily close to $\frac{1}{2}$ for a subset of the domain. As a corollary, we employ an evolutionary algorithm by \cite{DBLP:conf/colt/KanadeVV10} to obtain the first polynomial time algorithm with arbitrarily small excess error for learning linear threshold functions over any spherically symmetric distribution in the presence of spherically symmetric Tsybakov noise. Moreover, we posit access to a stronger oracle, in which for every labeled example we additionally obtain its flipping probability. In this model, we show that every SQ learnable class admits an efficient learning algorithm with OPT + $\epsilon$ misclassification error for a broad class of noise models. This setting substantially generalizes the widely-studied problem of classification under RCN with known noise rate, and corresponds to a non-convex optimization problem even when the noise function -- i.e. the flipping probabilities of all points -- is known in advance.
Denmark's Participation in the Search Engine TREC COVID-19 Challenge: Lessons Learned about Searching for Precise Biomedical Scientific Information on COVID-19
Nov 26, 2020
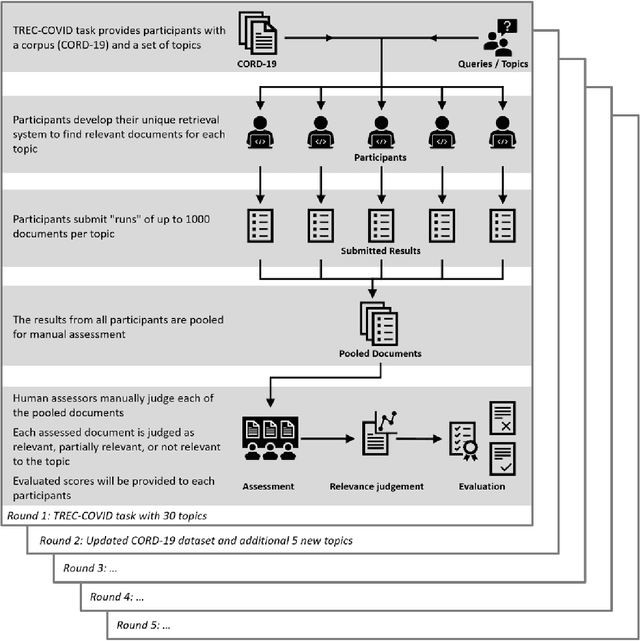
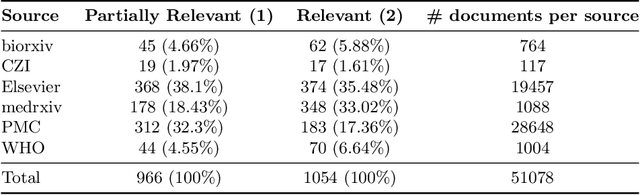
This report describes the participation of two Danish universities, University of Copenhagen and Aalborg University, in the international search engine competition on COVID-19 (the 2020 TREC-COVID Challenge) organised by the U.S. National Institute of Standards and Technology (NIST) and its Text Retrieval Conference (TREC) division. The aim of the competition was to find the best search engine strategy for retrieving precise biomedical scientific information on COVID-19 from the largest, at that point in time, dataset of curated scientific literature on COVID-19 -- the COVID-19 Open Research Dataset (CORD-19). CORD-19 was the result of a call to action to the tech community by the U.S. White House in March 2020, and was shortly thereafter posted on Kaggle as an AI competition by the Allen Institute for AI, the Chan Zuckerberg Initiative, Georgetown University's Center for Security and Emerging Technology, Microsoft, and the National Library of Medicine at the US National Institutes of Health. CORD-19 contained over 200,000 scholarly articles (of which more than 100,000 were with full text) about COVID-19, SARS-CoV-2, and related coronaviruses, gathered from curated biomedical sources. The TREC-COVID challenge asked for the best way to (a) retrieve accurate and precise scientific information, in response to some queries formulated by biomedical experts, and (b) rank this information decreasingly by its relevance to the query. In this document, we describe the TREC-COVID competition setup, our participation to it, and our resulting reflections and lessons learned about the state-of-art technology when faced with the acute task of retrieving precise scientific information from a rapidly growing corpus of literature, in response to highly specialised queries, in the middle of a pandemic.
HydroDeep -- A Knowledge Guided Deep Neural Network for Geo-Spatiotemporal Data Analysis
Oct 09, 2020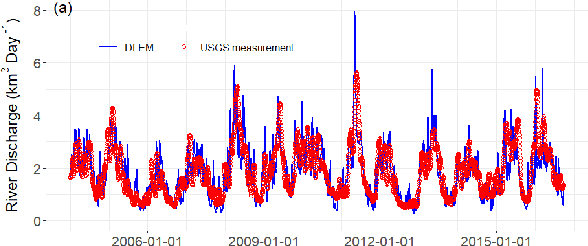

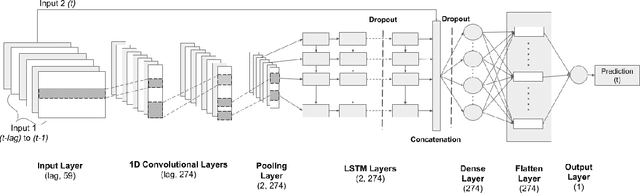
Floods are one of the major climate-related disasters, leading to substantial economic loss and social safety issue. However, the confidence in predicting changes in fluvial floods remains low due to limited evidence and complex causes of regional climate change. The recent development in machine learning techniques has the potential to improve traditional hydrological models by using monitoring data. Although Recurrent Neural Networks (RNN) perform remarkably with multivariate time series data, these models are blinded to the underlying mechanisms represented in a process-based model for flood prediction. While both process-based models and deep learning networks have their strength, understanding the fundamental mechanisms intrinsic to geo-spatiotemporal information is crucial to improve the prediction accuracy of flood occurrence. This paper demonstrates a neural network architecture (HydroDeep) that couples a process-based hydro-ecological model with a combination of Deep Convolutional Neural Network (CNN) and Long Short-Term Memory (LSTM) Network to build a hybrid baseline model. HydroDeep outperforms the performance of both the independent networks by 4.8% and 31.8% respectively in Nash-Sutcliffe efficiency. A trained HydroDeep can transfer its knowledge and can learn the Geo-spatiotemporal features of any new region in minimal training iterations.