 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Online Influence Maximization under Linear Threshold Model
Nov 12, 2020
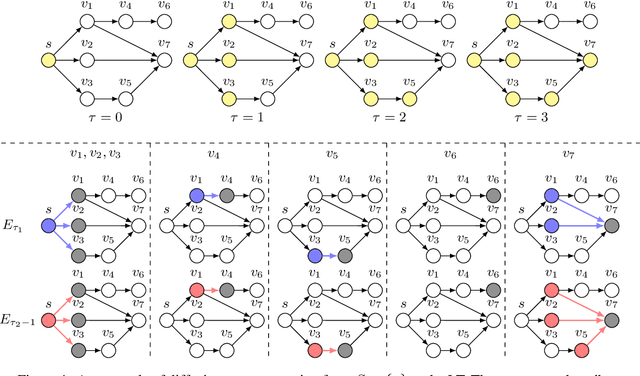
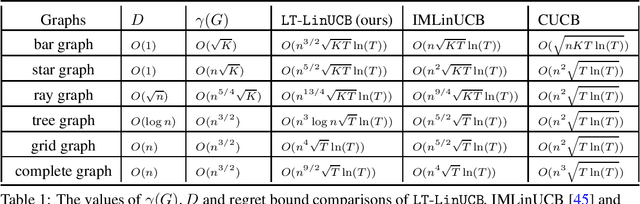
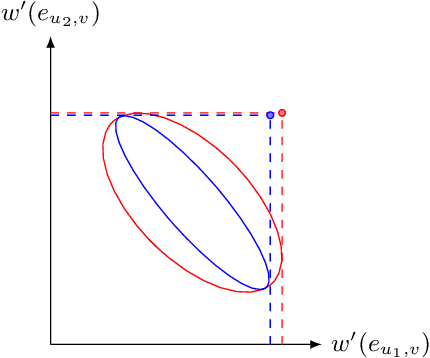

Online influence maximization (OIM) is a popular problem in social networks to learn influence propagation model parameters and maximize the influence spread at the same time. Most previous studies focus on the independent cascade (IC) model under the edge-level feedback. In this paper, we address OIM in the linear threshold (LT) model. Because node activations in the LT model are due to the aggregated effect of all active neighbors, it is more natural to model OIM with the node-level feedback. And this brings new challenge in online learning since we only observe aggregated effect from groups of nodes and the groups are also random. Based on the linear structure in node activations, we incorporate ideas from linear bandits and design an algorithm LT-LinUCB that is consistent with the observed feedback. By proving group observation modulated (GOM) bounded smoothness property, a novel result of the influence difference in terms of the random observations, we provide a regret of order $\tilde{O}(\mathrm{poly}(m)\sqrt{T})$, where $m$ is the number of edges and $T$ is the number of rounds. This is the first theoretical result in such order for OIM under the LT model. In the end, we also provide an algorithm OIM-ETC with regret bound $O(\mathrm{poly}(m)\ T^{2/3})$, which is model-independent, simple and has less requirement on online feedback and offline computation.
Data-Driven Distributed State Estimation and Behavior Modeling in Sensor Networks
Sep 24, 2020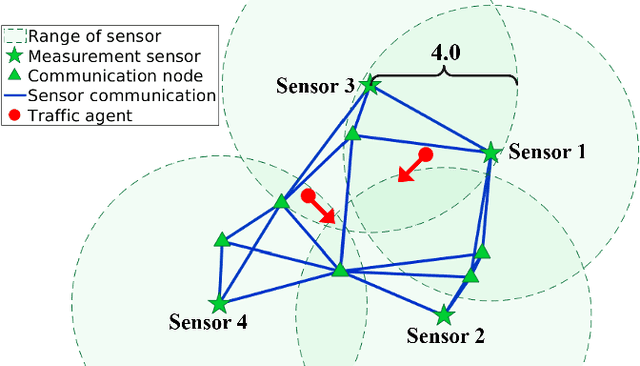
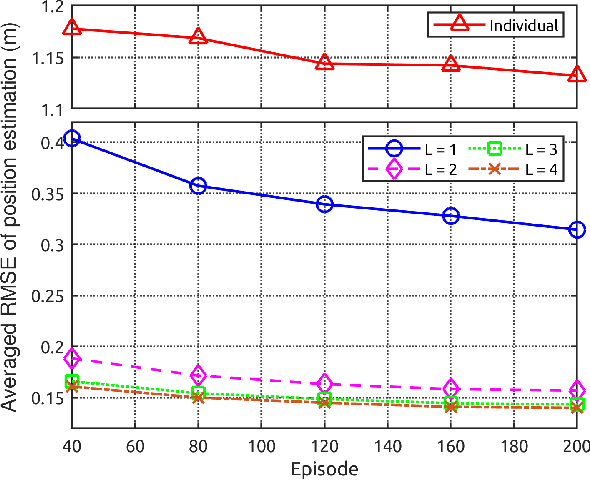
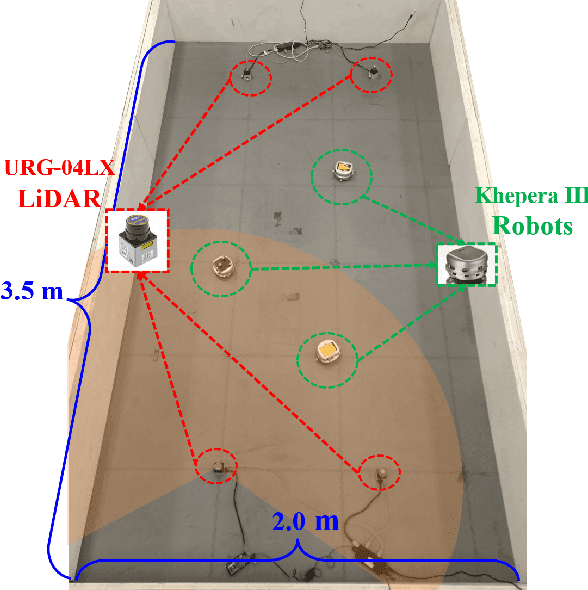
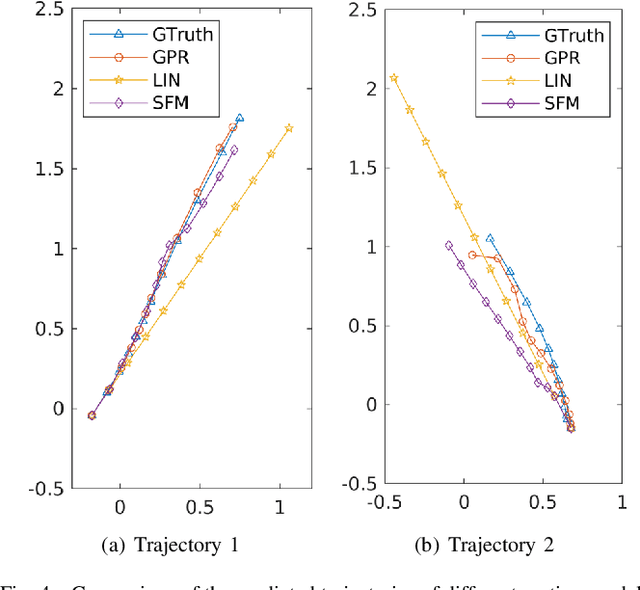
Nowadays, the prevalence of sensor networks has enabled tracking of the states of dynamic objects for a wide spectrum of applications from autonomous driving to environmental monitoring and urban planning. However, tracking real-world objects often faces two key challenges: First, due to the limitation of individual sensors, state estimation needs to be solved in a collaborative and distributed manner. Second, the objects' movement behavior is unknown, and needs to be learned using sensor observations. In this work, for the first time, we formally formulate the problem of simultaneous state estimation and behavior learning in a sensor network. We then propose a simple yet effective solution to this new problem by extending the Gaussian process-based Bayes filters (GP-BayesFilters) to an online, distributed setting. The effectiveness of the proposed method is evaluated on tracking objects with unknown movement behaviors using both synthetic data and data collected from a multi-robot platform.
A Note on the Linear Convergence of Policy Gradient Methods
Jul 21, 2020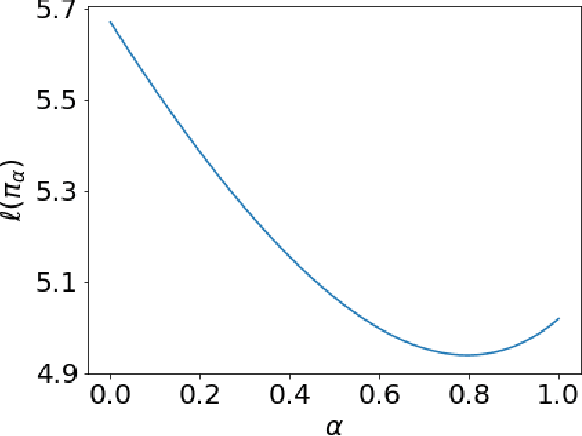
We revisit the finite time analysis of policy gradient methods in the simplest setting: finite state and action problems with a policy class consisting of all stochastic policies and with exact gradient evaluations. Some recent works have viewed these problems as instances of smooth nonlinear optimization problems, suggesting suggest small stepsizes and showing sublinear convergence rates. This note instead takes a policy iteration perspective and highlights that many versions of policy gradient succeed with extremely large stepsizes and attain a linear rate of convergence.
Labeled Optimal Partitioning
Jun 24, 2020
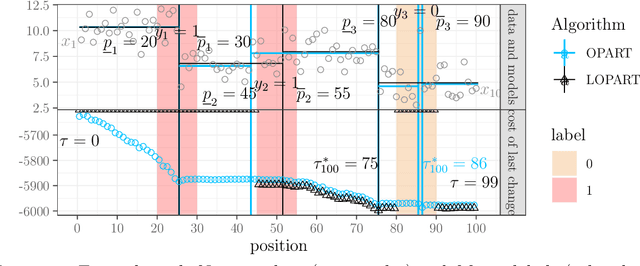
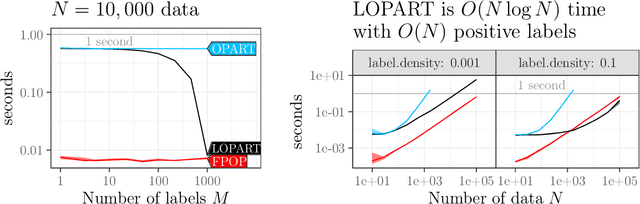
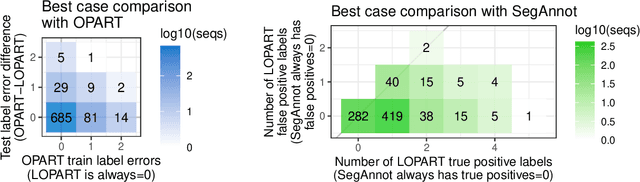
In data sequences measured over space or time, an important problem is accurate detection of abrupt changes. In partially labeled data, it is important to correctly predict presence/absence of changes in positive/negative labeled regions, in both the train and test sets. One existing dynamic programming algorithm is designed for prediction in unlabeled test regions (and ignores the labels in the train set); another is for accurate fitting of train labels (but does not predict changepoints in unlabeled test regions). We resolve these issues by proposing a new optimal changepoint detection model that is guaranteed to fit the labels in the train data, and can also provide predictions of unlabeled changepoints in test data. We propose a new dynamic programming algorithm, Labeled Optimal Partitioning (LOPART), and we provide a formal proof that it solves the resulting non-convex optimization problem. We provide theoretical and empirical analysis of the time complexity of our algorithm, in terms of the number of labels and the size of the data sequence to segment. Finally, we provide empirical evidence that our algorithm is more accurate than the existing baselines, in terms of train and test label error.
On Embodied Visual Navigation in Real Environments Through Habitat
Oct 26, 2020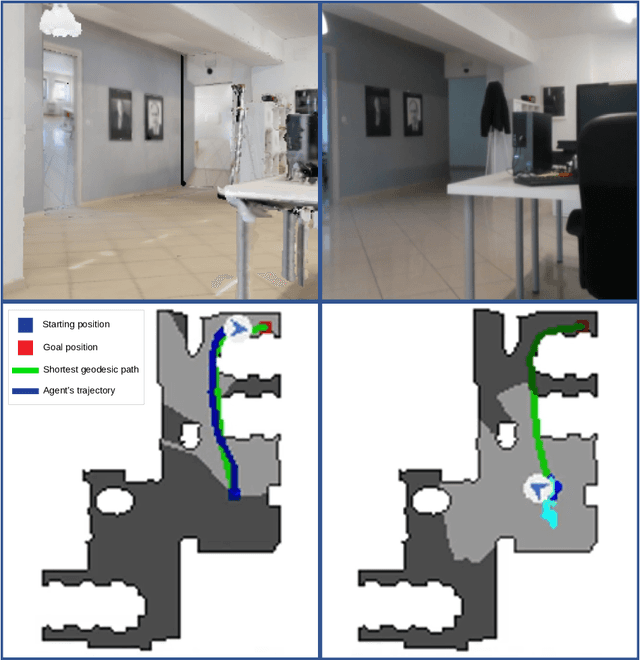
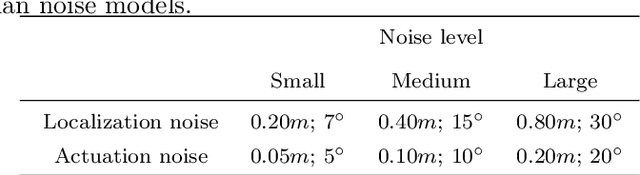
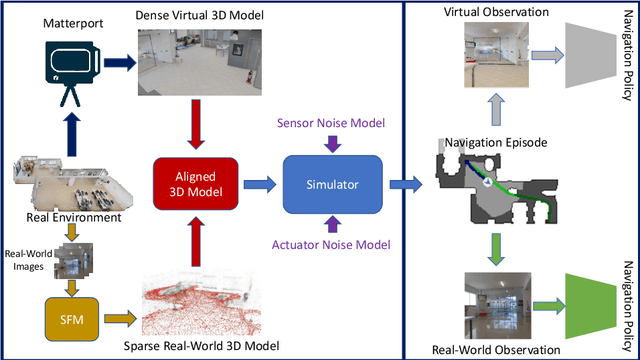
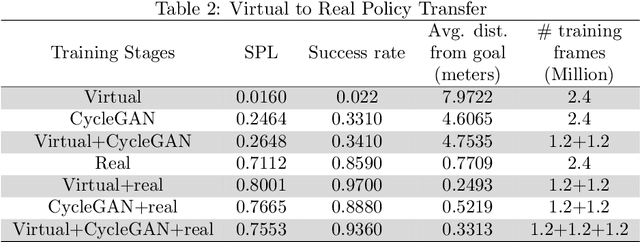
Visual navigation models based on deep learning can learn effective policies when trained on large amounts of visual observations through reinforcement learning. Unfortunately, collecting the required experience in the real world requires the deployment of a robotic platform, which is expensive and time-consuming. To deal with this limitation, several simulation platforms have been proposed in order to train visual navigation policies on virtual environments efficiently. Despite the advantages they offer, simulators present a limited realism in terms of appearance and physical dynamics, leading to navigation policies that do not generalize in the real world. In this paper, we propose a tool based on the Habitat simulator which exploits real world images of the environment, together with sensor and actuator noise models, to produce more realistic navigation episodes. We perform a range of experiments to assess the ability of such policies to generalize using virtual and real-world images, as well as observations transformed with unsupervised domain adaptation approaches. We also assess the impact of sensor and actuation noise on the navigation performance and investigate whether it allows to learn more robust navigation policies. We show that our tool can effectively help to train and evaluate navigation policies on real-world observations without running navigation pisodes in the real world.
Time-Aware Gated Recurrent Unit Networks for Road Surface Friction Prediction Using Historical Data
Nov 01, 2019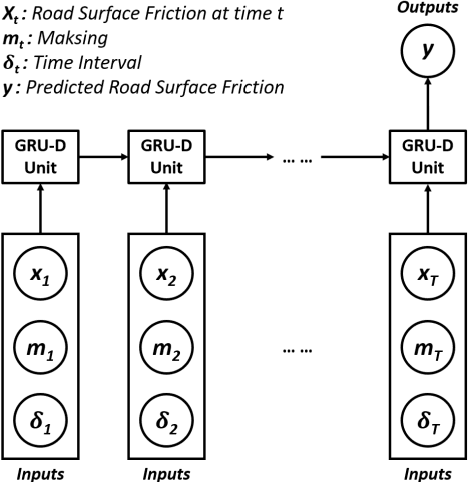
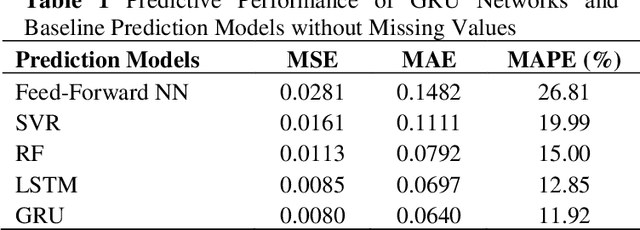


An accurate road surface friction prediction algorithm can enable intelligent transportation systems to share timely road surface condition to the public for increasing the safety of the road users. Previously, scholars developed multiple prediction models for forecasting road surface conditions using historical data. However, road surface condition data cannot be perfectly collected at every timestamp, e.g. the data collected by on-vehicle sensors may be influenced when vehicles cannot travel due to economic cost issue or weather issues. Such resulted missing values in the collected data can damage the effectiveness and accuracy of the existing prediction methods since they are assumed to have the input data with a fixed temporal resolution. This study proposed a road surface friction prediction model employing a Gated Recurrent Unit network-based decay mechanism (GRU-D) to handle the missing values. The evaluation results present that the proposed GRU-D networks outperform all baseline models. The impact of missing rate on predictive accuracy, learning efficiency and learned decay rate are analyzed as well. The findings can help improve the prediction accuracy and efficiency of forecasting road surface friction using historical data sets with missing values, therefore mitigating the impact of wet or icy road conditions on traffic safety.
Generating 3D Molecular Structures Conditional on a Receptor Binding Site with Deep Generative Models
Oct 16, 2020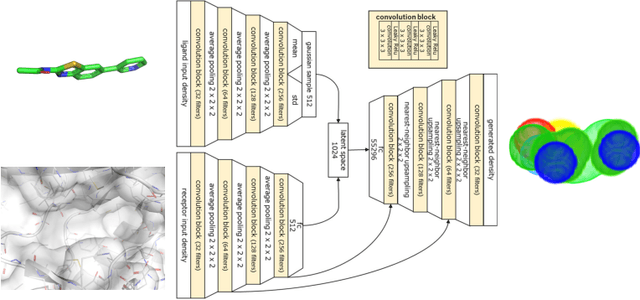
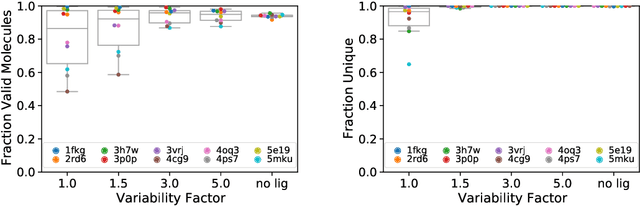
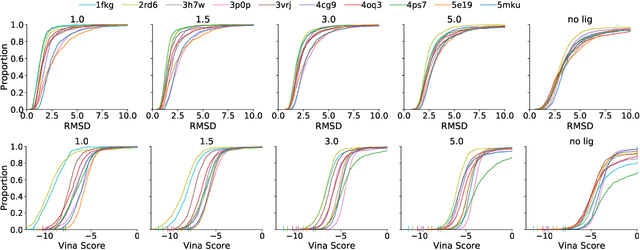
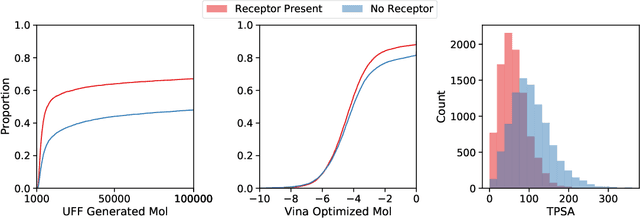
Deep generative models have been applied with increasing success to the generation of two dimensional molecules as SMILES strings and molecular graphs. In this work we describe for the first time a deep generative model that can generate 3D molecular structures conditioned on a three-dimensional (3D) binding pocket. Using convolutional neural networks, we encode atomic density grids into separate receptor and ligand latent spaces. The ligand latent space is variational to support sampling of new molecules. A decoder network generates atomic densities of novel ligands conditioned on the receptor. Discrete atoms are then fit to these continuous densities to create molecular structures. We show that valid and unique molecules can be readily sampled from the variational latent space defined by a reference `seed' structure and generated structures have reasonable interactions with the binding site. As structures are sampled farther in latent space from the seed structure, the novelty of the generated structures increases, but the predicted binding affinity decreases. Overall, we demonstrate the feasibility of conditional 3D molecular structure generation and provide a starting point for methods that also explicitly optimize for desired molecular properties, such as high binding affinity.
m-TSNE: A Framework for Visualizing High-Dimensional Multivariate Time Series
Aug 26, 2017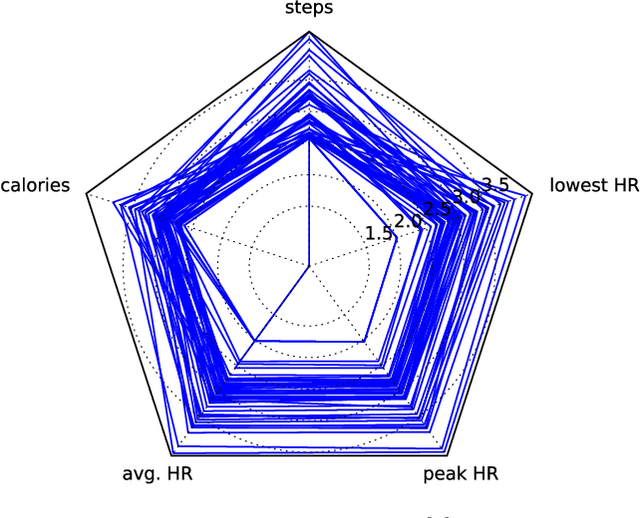
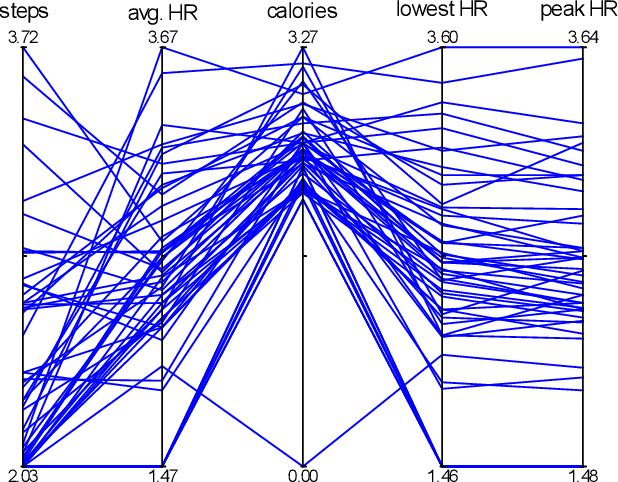

Multivariate time series (MTS) have become increasingly common in healthcare domains where human vital signs and laboratory results are collected for predictive diagnosis. Recently, there have been increasing efforts to visualize healthcare MTS data based on star charts or parallel coordinates. However, such techniques might not be ideal for visualizing a large MTS dataset, since it is difficult to obtain insights or interpretations due to the inherent high dimensionality of MTS. In this paper, we propose 'm-TSNE': a simple and novel framework to visualize high-dimensional MTS data by projecting them into a low-dimensional (2-D or 3-D) space while capturing the underlying data properties. Our framework is easy to use and provides interpretable insights for healthcare professionals to understand MTS data. We evaluate our visualization framework on two real-world datasets and demonstrate that the results of our m-TSNE show patterns that are easy to understand while the other methods' visualization may have limitations in interpretability.
Clustering Based on Graph of Density Topology
Sep 24, 2020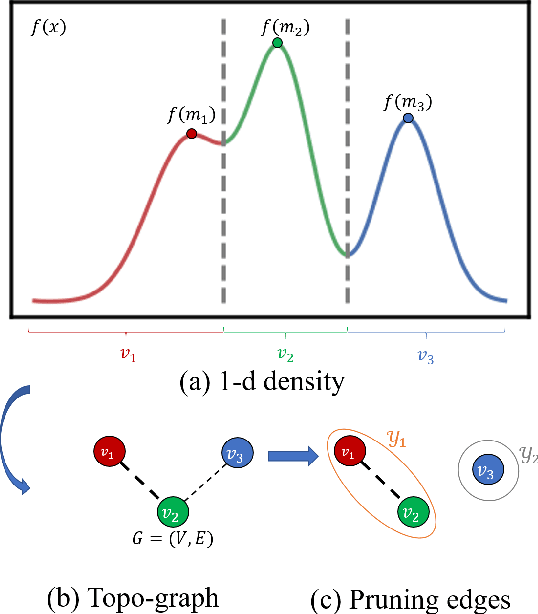

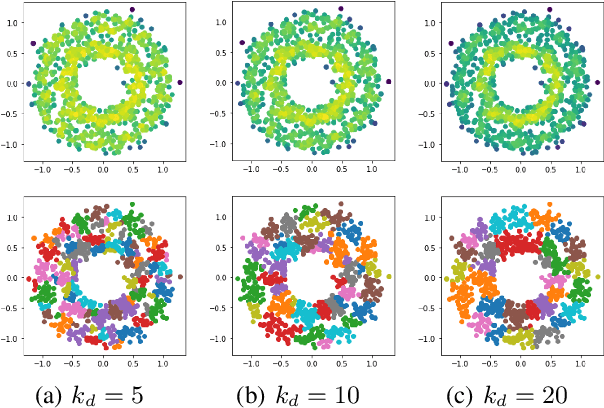
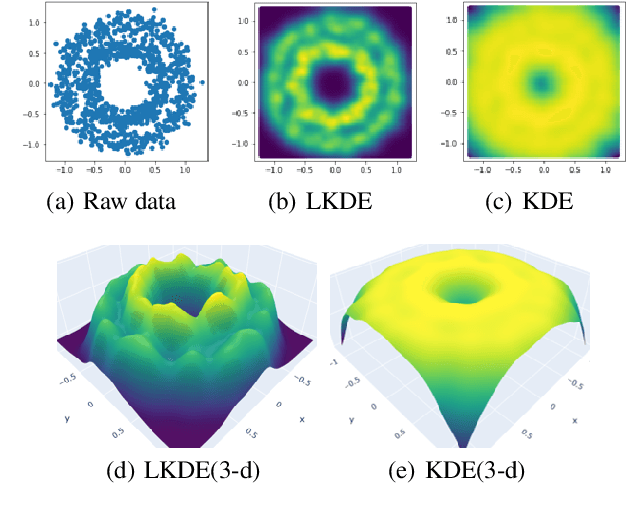
Data clustering with uneven distribution in high level noise is challenging. Currently, HDBSCAN is considered as the SOTA algorithm for this problem. In this paper, we propose a novel clustering algorithm based on what we call graph of density topology (GDT). GDT jointly considers the local and global structures of data samples: firstly forming local clusters based on a density growing process with a strategy for properly noise handling as well as cluster boundary detection; and then estimating a GDT from relationship between local clusters in terms of a connectivity measure, givingglobal topological graph. The connectivity, measuring similarity between neighboring local clusters, is based on local clusters rather than individual points, ensuring its robustness to even very large noise. Evaluation results on both toy and real-world datasets show that GDT achieves the SOTA performance by far on almost all the popular datasets, and has a low time complexity of O(nlogn). The code is available at https://github.com/gaozhangyang/DGC.git.
Analysing Long Short Term Memory Models for Cricket Match Outcome Prediction
Nov 04, 2020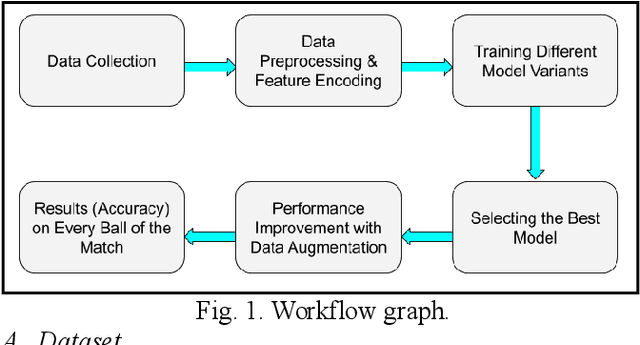
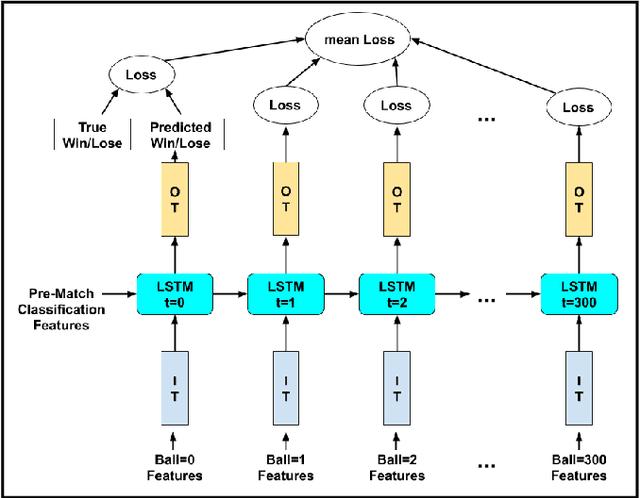
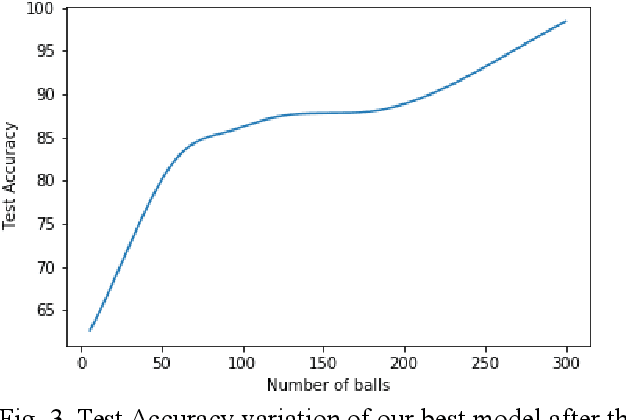
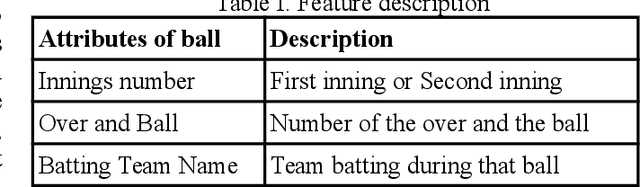
As the technology advances, an ample amount of data is collected in sports with the help of advanced sensors. Sports Analytics is the study of this data to provide a constructive advantage to the team and its players. The game of international cricket is popular all across the globe. Recently, various machine learning techniques have been used to analyse the cricket match data and predict the match outcome as win or lose. Generally these models make use of the overall match level statistics such as teams, venue, average run rate, win margin, etc to predict the match results before the beginning of the match. However, very few works provide insights based on the ball-by-ball level statistics. Here we propose a novel Recurrent Neural Network model which can predict the win probability of a match at regular intervals given the ball-by-ball statistics. The Long Short Term Memory (LSTM) Model takes as input the ball wise features as well as the match level details available from the training dataset. It gives a prediction of winning the match at any time stamp during the match. This level of insight will help the team to predict the probability of them winning the match after every ball and help them determine the critical in-game changes they should make in their game strategies.