 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Subword Segmentation and a Single Bridge Language Affect Zero-Shot Neural Machine Translation
Nov 03, 2020
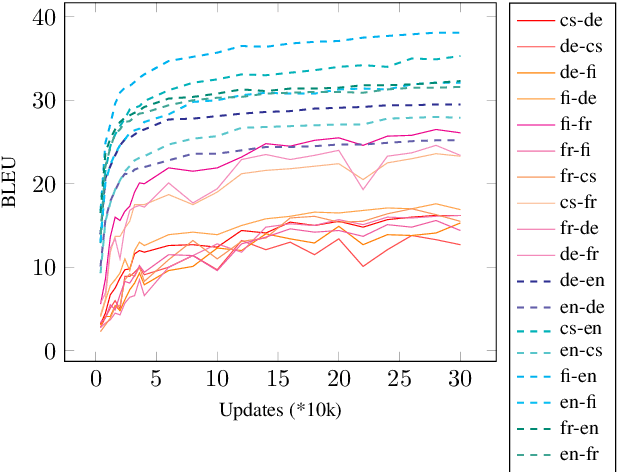
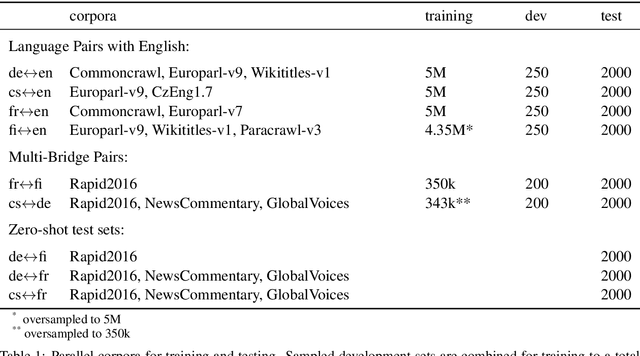
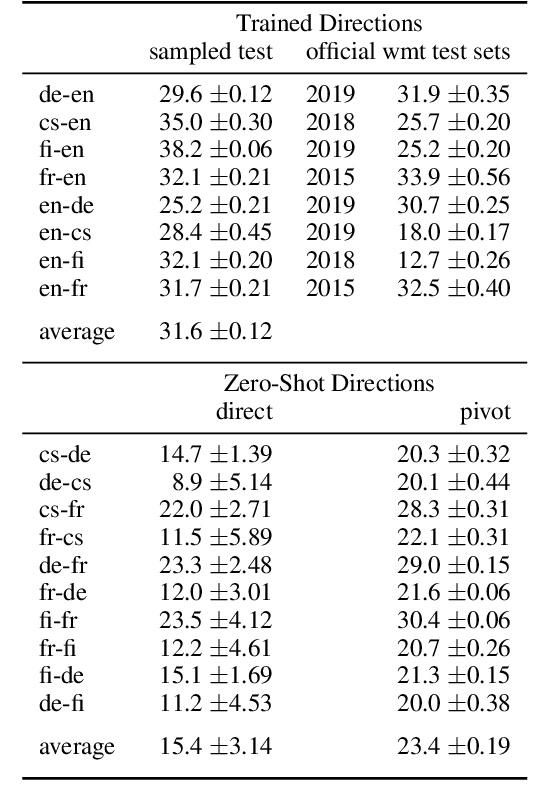
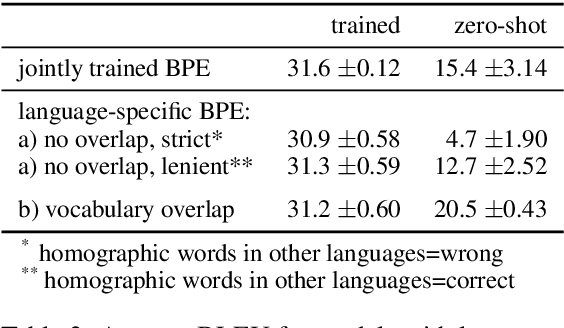
Zero-shot neural machine translation is an attractive goal because of the high cost of obtaining data and building translation systems for new translation directions. However, previous papers have reported mixed success in zero-shot translation. It is hard to predict in which settings it will be effective, and what limits performance compared to a fully supervised system. In this paper, we investigate zero-shot performance of a multilingual EN$\leftrightarrow${FR,CS,DE,FI} system trained on WMT data. We find that zero-shot performance is highly unstable and can vary by more than 6 BLEU between training runs, making it difficult to reliably track improvements. We observe a bias towards copying the source in zero-shot translation, and investigate how the choice of subword segmentation affects this bias. We find that language-specific subword segmentation results in less subword copying at training time, and leads to better zero-shot performance compared to jointly trained segmentation. A recent trend in multilingual models is to not train on parallel data between all language pairs, but have a single bridge language, e.g. English. We find that this negatively affects zero-shot translation and leads to a failure mode where the model ignores the language tag and instead produces English output in zero-shot directions. We show that this bias towards English can be effectively reduced with even a small amount of parallel data in some of the non-English pairs.
Theory-Oriented Deep Leakage from Gradients via Linear Equation Solver
Oct 26, 2020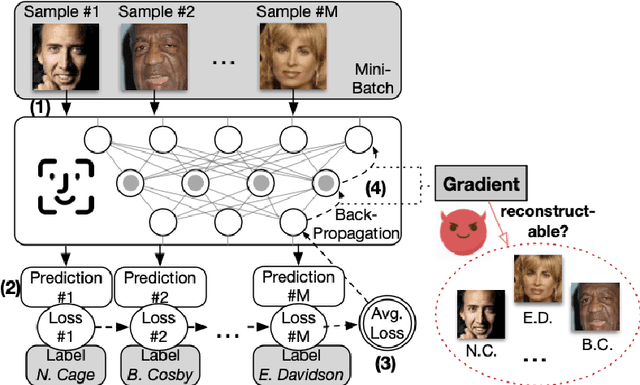
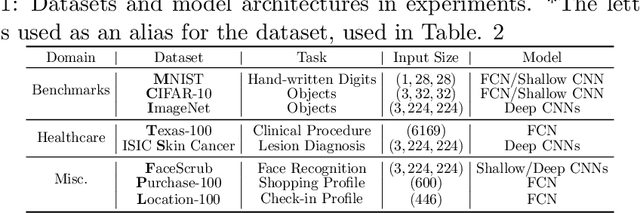
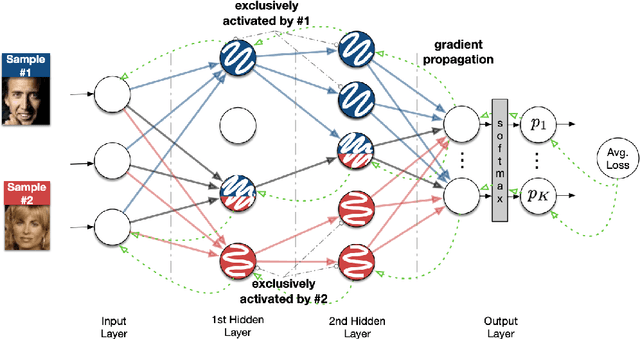
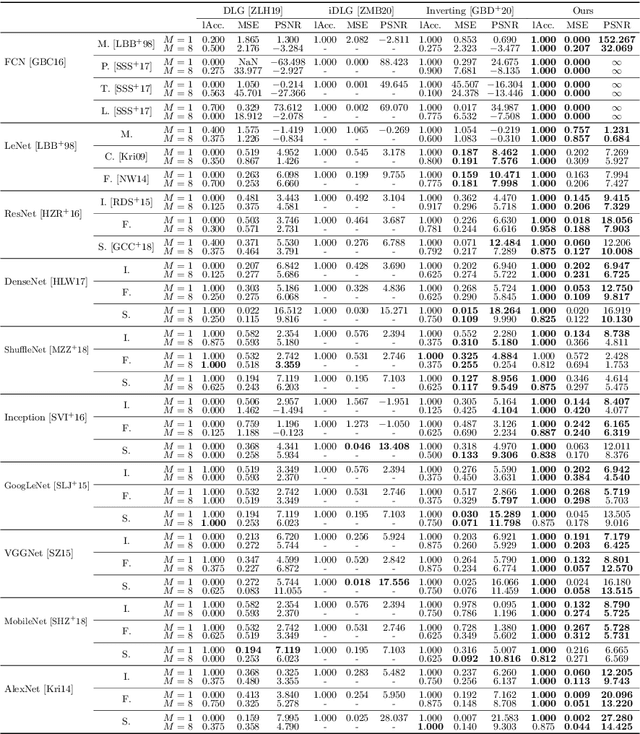
In this paper, we take a theory-oriented approach to systematically study the privacy properties of gradients from a broad class of neural networks with rectified linear units (ReLU), probably the most popular activation function used in current deep learning practices. By utilizing some intrinsic properties of neural networks with ReLU, we prove the existence of exclusively activated neurons is critical to the separability of the activation patterns of different samples. Intuitively, an activation pattern is like the fingerprint of the corresponding sample during the training process. With the separated activation patterns, we for the first time show the equivalence of data reconstruction attacks with a sparse linear equation system. In practice, we propose a novel data reconstruction attack on fully-connected neural networks and extend the attack to more commercial convolutional neural network architectures. Our systematic evaluations cover more than $10$ representative neural network architectures (e.g., GoogLeNet, VGGNet and $6$ more), on various real-world scenarios related with healthcare, medical imaging, location, face recognition and shopping behaviors. In the majority of test cases, our proposed attack is able to infer ground-truth labels in the training batch with near $100\%$ accuracy, reconstruct the input data to fully-connected neural networks with lower than $10^{-6}$ MSE error, and provide better reconstruction results on both shallow and deep convolutional neural networks than previous attacks.
Multi-scale Transformer Language Models
May 01, 2020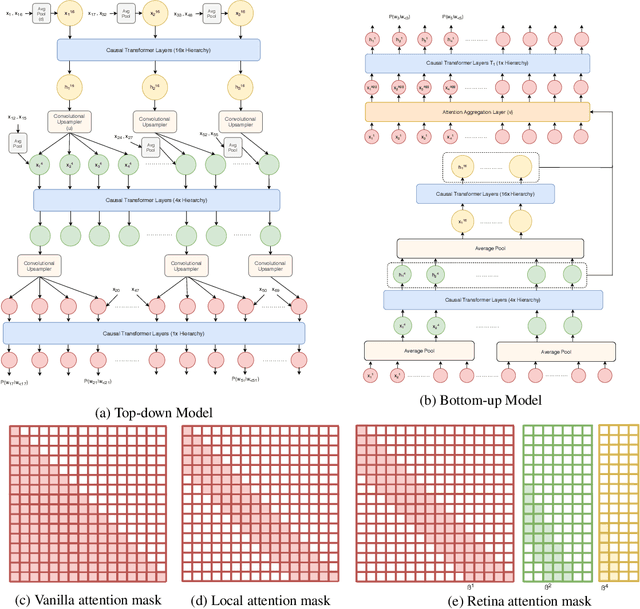
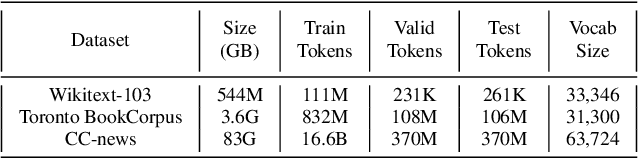
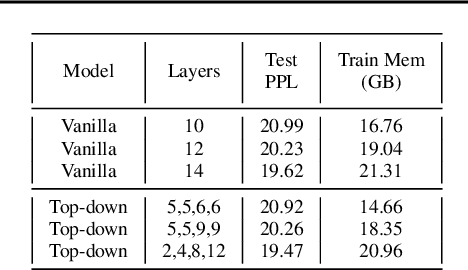
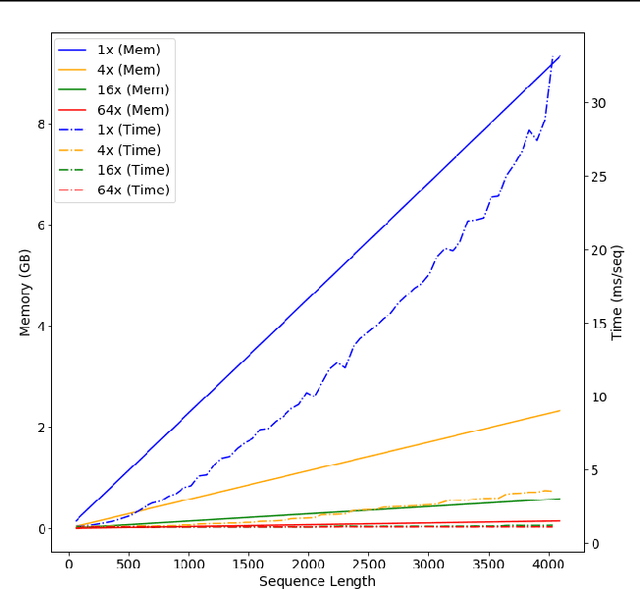
We investigate multi-scale transformer language models that learn representations of text at multiple scales, and present three different architectures that have an inductive bias to handle the hierarchical nature of language. Experiments on large-scale language modeling benchmarks empirically demonstrate favorable likelihood vs memory footprint trade-offs, e.g. we show that it is possible to train a hierarchical variant with 30 layers that has 23% smaller memory footprint and better perplexity, compared to a vanilla transformer with less than half the number of layers, on the Toronto BookCorpus. We analyze the advantages of learned representations at multiple scales in terms of memory footprint, compute time, and perplexity, which are particularly appealing given the quadratic scaling of transformers' run time and memory usage with respect to sequence length.
PSF-LO: Parameterized Semantic Features Based Lidar Odometry
Oct 26, 2020
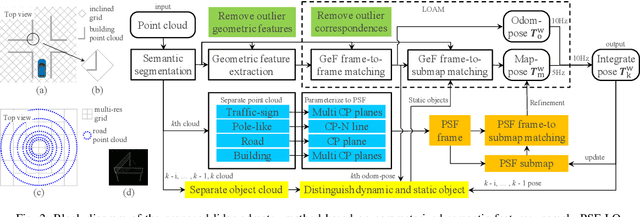
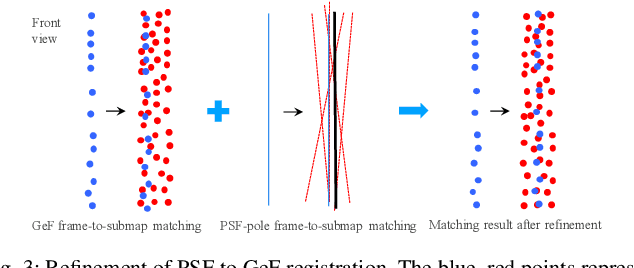
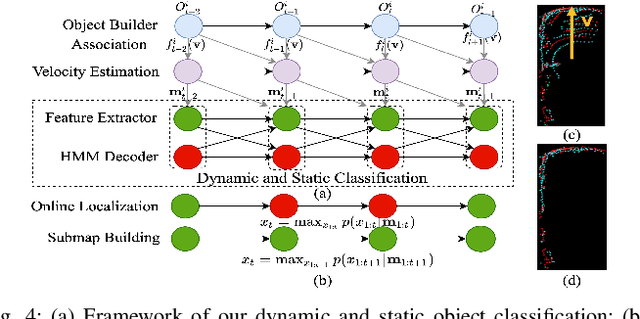
Lidar odometry (LO) is a key technology in numerous reliable and accurate localization and mapping systems of autonomous driving. The state-of-the-art LO methods generally leverage geometric information to perform point cloud registration. Furthermore, obtaining point cloud semantic information which can describe the environment more abundantly will help for the registration. We present a novel semantic lidar odometry method based on self-designed parameterized semantic features (PSFs) to achieve low-drift ego-motion estimation for autonomous vehicle in realtime. We first use a convolutional neural network-based algorithm to obtain point-wise semantics from the input laser point cloud, and then use semantic labels to separate the road, building, traffic sign and pole-like point cloud and fit them separately to obtain corresponding PSFs. A fast PSF-based matching enable us to refine geometric features (GeFs) registration, reducing the impact of blurred submap surface on the accuracy of GeFs matching. Besides, we design an efficient method to accurately recognize and remove the dynamic objects while retaining static ones in the semantic point cloud, which are beneficial to further improve the accuracy of LO. We evaluated our method, namely PSF-LO, on the public dataset KITTI Odometry Benchmark and ranked #1 among semantic lidar methods with an average translation error of 0.82% in the test dataset at the time of writing.
Learning Mesh-Based Simulation with Graph Networks
Oct 07, 2020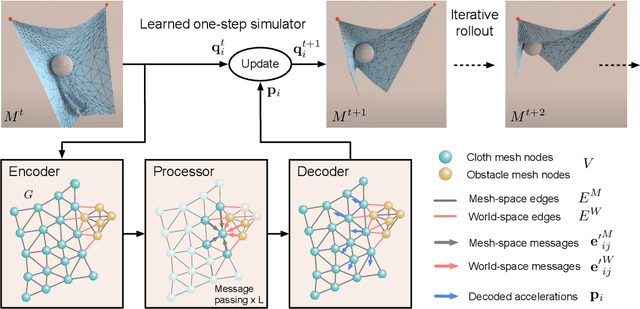
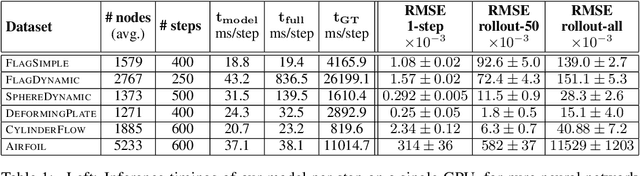
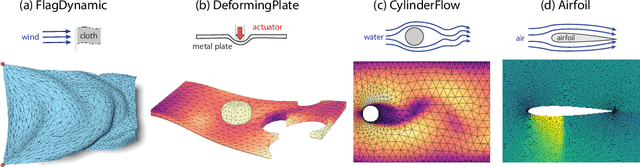
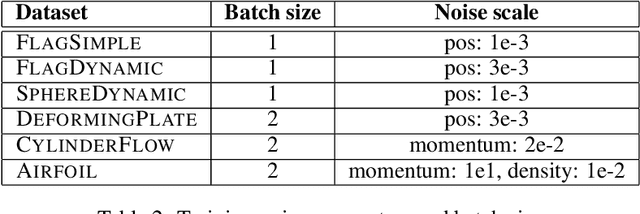
Mesh-based simulations are central to modeling complex physical systems in many disciplines across science and engineering. Mesh representations support powerful numerical integration methods and their resolution can be adapted to strike favorable trade-offs between accuracy and efficiency. However, high-dimensional scientific simulations are very expensive to run, and solvers and parameters must often be tuned individually to each system studied. Here we introduce MeshGraphNets, a framework for learning mesh-based simulations using graph neural networks. Our model can be trained to pass messages on a mesh graph and to adapt the mesh discretization during forward simulation. Our results show it can accurately predict the dynamics of a wide range of physical systems, including aerodynamics, structural mechanics, and cloth. The model's adaptivity supports learning resolution-independent dynamics and can scale to more complex state spaces at test time. Our method is also highly efficient, running 1-2 orders of magnitude faster than the simulation on which it is trained. Our approach broadens the range of problems on which neural network simulators can operate and promises to improve the efficiency of complex, scientific modeling tasks.
Economy Statistical Recurrent Units For Inferring Nonlinear Granger Causality
Jan 14, 2020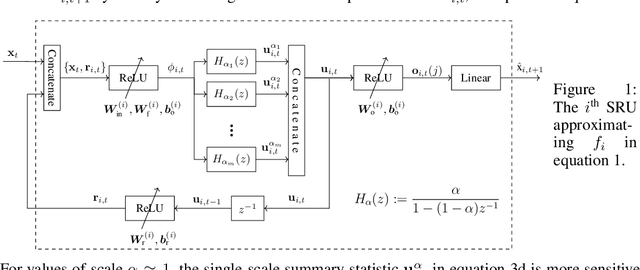

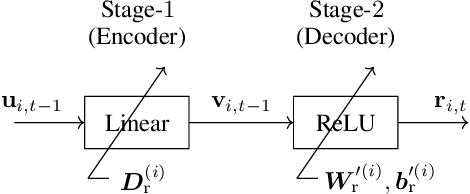
Granger causality is a widely-used criterion for analyzing interactions in large-scale networks. As most physical interactions are inherently nonlinear, we consider the problem of inferring the existence of pairwise Granger causality between nonlinearly interacting stochastic processes from their time series measurements. Our proposed approach relies on modeling the embedded nonlinearities in the measurements using a component-wise time series prediction model based on Statistical Recurrent Units (SRUs). We make a case that the network topology of Granger causal relations is directly inferrable from a structured sparse estimate of the internal parameters of the SRU networks trained to predict the processes$'$ time series measurements. We propose a variant of SRU, called economy-SRU, which, by design has considerably fewer trainable parameters, and therefore less prone to overfitting. The economy-SRU computes a low-dimensional sketch of its high-dimensional hidden state in the form of random projections to generate the feedback for its recurrent processing. Additionally, the internal weight parameters of the economy-SRU are strategically regularized in a group-wise manner to facilitate the proposed network in extracting meaningful predictive features that are highly time-localized to mimic real-world causal events. Extensive experiments are carried out to demonstrate that the proposed economy-SRU based time series prediction model outperforms the MLP, LSTM and attention-gated CNN-based time series models considered previously for inferring Granger causality.
Automatic Data Augmentation for 3D Medical Image Segmentation
Oct 07, 2020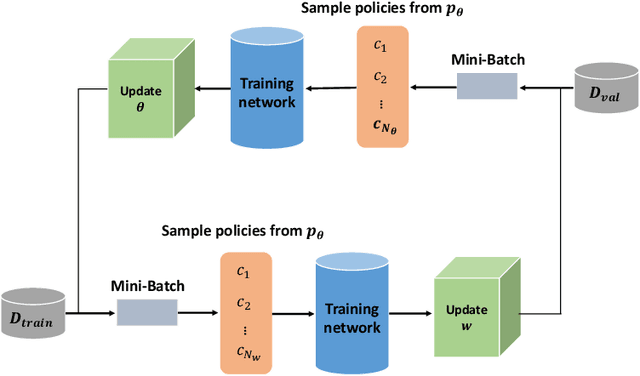
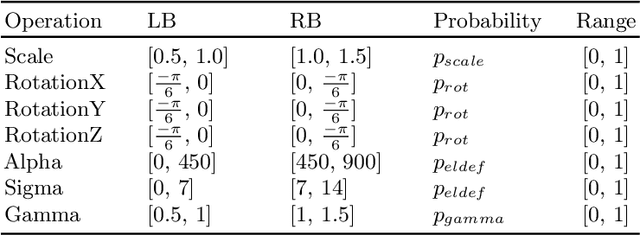
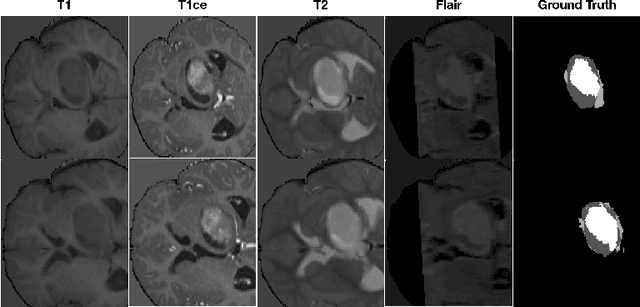
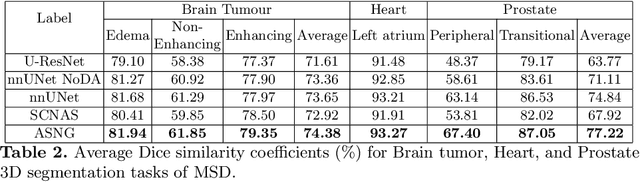
Data augmentation is an effective and universal technique for improving generalization performance of deep neural networks. It could enrich diversity of training samples that is essential in medical image segmentation tasks because 1) the scale of medical image dataset is typically smaller, which may increase the risk of overfitting; 2) the shape and modality of different objects such as organs or tumors are unique, thus requiring customized data augmentation policy. However, most data augmentation implementations are hand-crafted and suboptimal in medical image processing. To fully exploit the potential of data augmentation, we propose an efficient algorithm to automatically search for the optimal augmentation strategies. We formulate the coupled optimization w.r.t. network weights and augmentation parameters into a differentiable form by means of stochastic relaxation. This formulation allows us to apply alternative gradient-based methods to solve it, i.e. stochastic natural gradient method with adaptive step-size. To the best of our knowledge, it is the first time that differentiable automatic data augmentation is employed in medical image segmentation tasks. Our numerical experiments demonstrate that the proposed approach significantly outperforms existing build-in data augmentation of state-of-the-art models.
Robust Face Alignment by Multi-order High-precision Hourglass Network
Oct 17, 2020
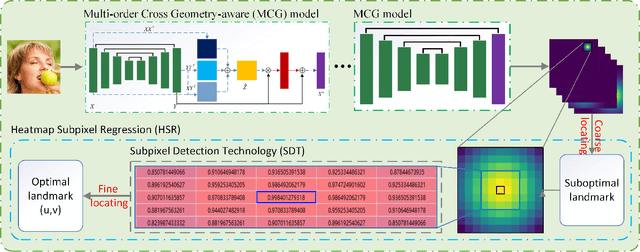
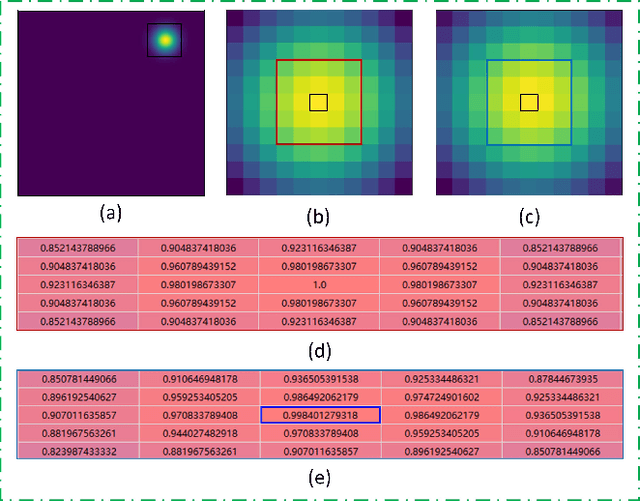
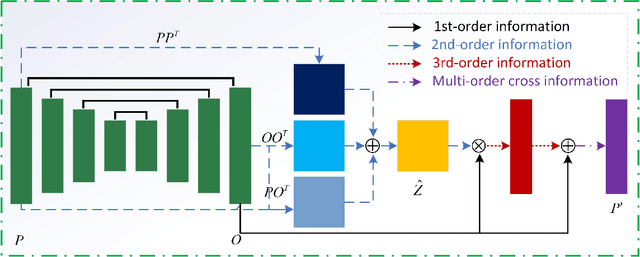
Heatmap regression (HR) has become one of the mainstream approaches for face alignment and has obtained promising results under constrained environments. However, when a face image suffers from large pose variations, heavy occlusions and complicated illuminations, the performances of HR methods degrade greatly due to the low resolutions of the generated landmark heatmaps and the exclusion of important high-order information that can be used to learn more discriminative features. To address the alignment problem for faces with extremely large poses and heavy occlusions, this paper proposes a heatmap subpixel regression (HSR) method and a multi-order cross geometry-aware (MCG) model, which are seamlessly integrated into a novel multi-order high-precision hourglass network (MHHN). The HSR method is proposed to achieve high-precision landmark detection by a well-designed subpixel detection loss (SDL) and subpixel detection technology (SDT). At the same time, the MCG model is able to use the proposed multi-order cross information to learn more discriminative representations for enhancing facial geometric constraints and context information. To the best of our knowledge, this is the first study to explore heatmap subpixel regression for robust and high-precision face alignment. The experimental results from challenging benchmark datasets demonstrate that our approach outperforms state-of-the-art methods in the literature.
Adaptive Reinforcement Learning through Evolving Self-Modifying Neural Networks
May 22, 2020
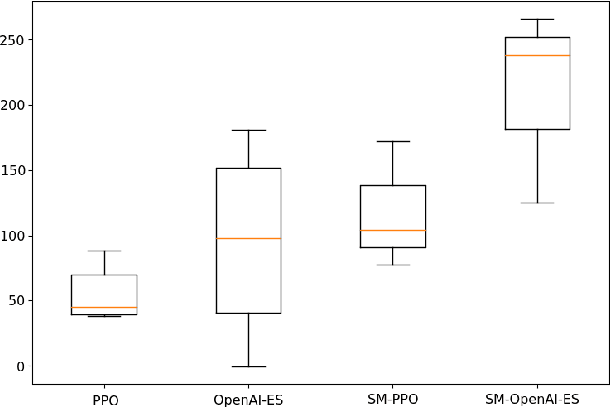
The adaptive learning capabilities seen in biological neural networks are largely a product of the self-modifying behavior emerging from online plastic changes in synaptic connectivity. Current methods in Reinforcement Learning (RL) only adjust to new interactions after reflection over a specified time interval, preventing the emergence of online adaptivity. Recent work addressing this by endowing artificial neural networks with neuromodulated plasticity have been shown to improve performance on simple RL tasks trained using backpropagation, but have yet to scale up to larger problems. Here we study the problem of meta-learning in a challenging quadruped domain, where each leg of the quadruped has a chance of becoming unusable, requiring the agent to adapt by continuing locomotion with the remaining limbs. Results demonstrate that agents evolved using self-modifying plastic networks are more capable of adapting to complex meta-learning learning tasks, even outperforming the same network updated using gradient-based algorithms while taking less time to train.
* GECCO'2020 Poster: Submitted and accepted
Towards Efficient Scheduling of Federated Mobile Devices under Computational and Statistical Heterogeneity
May 25, 2020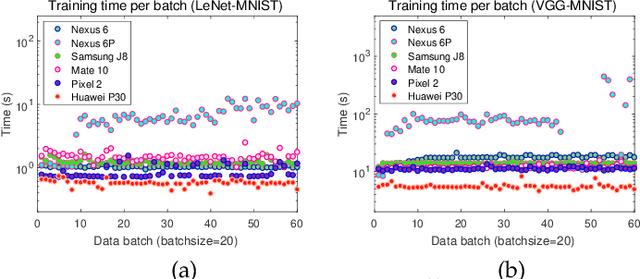
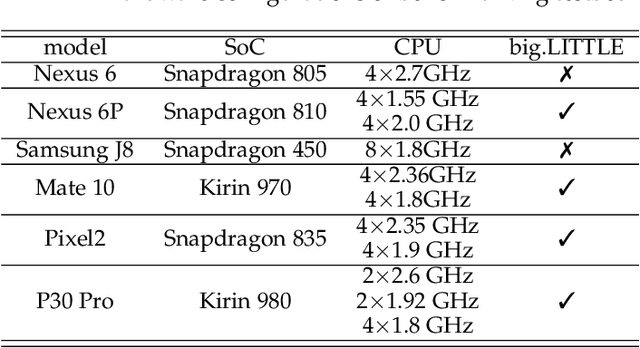
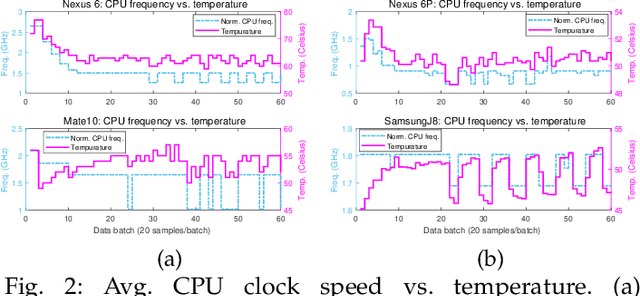

Originated from distributed learning, federated learning enables privacy-preserved collaboration on a new abstracted level by sharing the model parameters only. While the current research mainly focuses on optimizing learning algorithms and minimizing communication overhead left by distributed learning, there is still a considerable gap when it comes to the real implementation on mobile devices. In this paper, we start with an empirical experiment to demonstrate computation heterogeneity is a more pronounced bottleneck than communication on the current generation of battery-powered mobile devices, and the existing methods are haunted by mobile stragglers. Further, non-identically distributed data across the mobile users makes the selection of participants critical to the accuracy and convergence. To tackle the computational and statistical heterogeneity, we utilize data as a tunable knob and propose two efficient polynomial-time algorithms to schedule different workloads on various mobile devices, when data is identically or non-identically distributed. For identically distributed data, we combine partitioning and linear bottleneck assignment to achieve near-optimal training time without accuracy loss. For non-identically distributed data, we convert it into an average cost minimization problem and propose a greedy algorithm to find a reasonable balance between computation time and accuracy. We also establish an offline profiler to quantify the runtime behavior of different devices, which serves as the input to the scheduling algorithms. We conduct extensive experiments on a mobile testbed with two datasets and up to 20 devices. Compared with the common benchmarks, the proposed algorithms achieve 2-100x speedup epoch-wise, 2-7% accuracy gain and boost the convergence rate by more than 100% on CIFAR10.