 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
GOAT: GPU Outsourcing of Deep Learning Training With Asynchronous Probabilistic Integrity Verification Inside Trusted Execution Environment
Oct 17, 2020
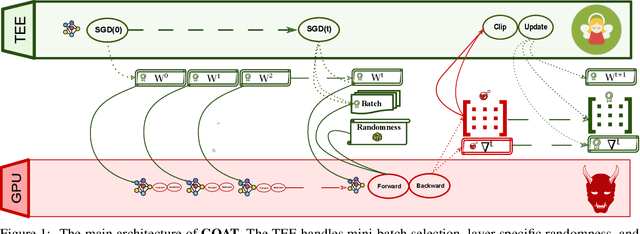

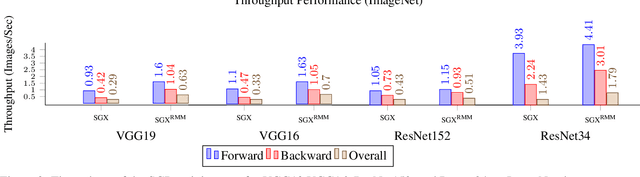
Machine learning models based on Deep Neural Networks (DNNs) are increasingly deployed in a wide range of applications ranging from self-driving cars to COVID-19 treatment discovery. To support the computational power necessary to learn a DNN, cloud environments with dedicated hardware support have emerged as critical infrastructure. However, there are many integrity challenges associated with outsourcing computation. Various approaches have been developed to address these challenges, building on trusted execution environments (TEE). Yet, no existing approach scales up to support realistic integrity-preserving DNN model training for heavy workloads (deep architectures and millions of training examples) without sustaining a significant performance hit. To mitigate the time gap between pure TEE (full integrity) and pure GPU (no integrity), we combine random verification of selected computation steps with systematic adjustments of DNN hyper-parameters (e.g., a narrow gradient clipping range), hence limiting the attacker's ability to shift the model parameters significantly provided that the step is not selected for verification during its training phase. Experimental results show the new approach achieves 2X to 20X performance improvement over pure TEE based solution while guaranteeing a very high probability of integrity (e.g., 0.999) with respect to state-of-the-art DNN backdoor attacks.
Multi-span Style Extraction for Generative Reading Comprehension
Sep 15, 2020
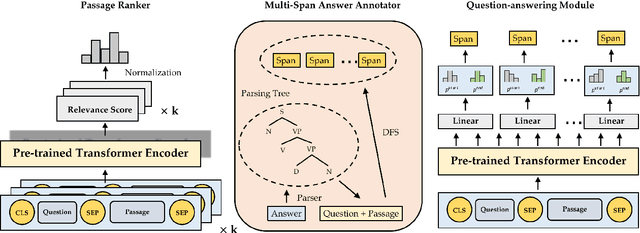
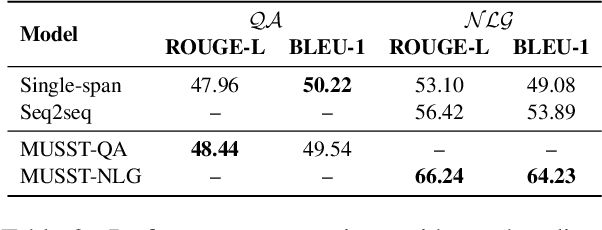
Generative machine reading comprehension (MRC) requires a model to generate well-formed answers. For this type of MRC, answer generation method is crucial to the model performance. However, generative models, which are supposed to be the right model for the task, in generally perform poorly. At the same time, single-span extraction models have been proven effective for extractive MRC, where the answer is constrained to a single span in the passage. Nevertheless, they generally suffer from generating incomplete answers or introducing redundant words when applied to the generative MRC. Thus, we extend the single-span extraction method to multi-span, proposing a new framework which enables generative MRC to be smoothly solved as multi-span extraction. Thorough experiments demonstrate that this novel approach can alleviate the dilemma between generative models and single-span models and produce answers with better-formed syntax and semantics. We will open-source our code for the research community.
Learning Interpretable Flight's 4D Landing Parameters Using Tunnel Gaussian Process
Nov 18, 2020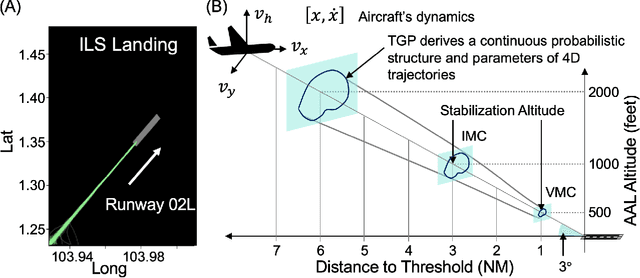
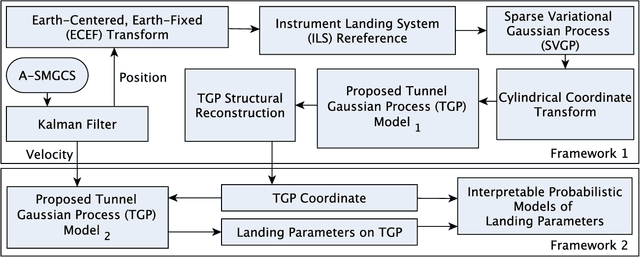
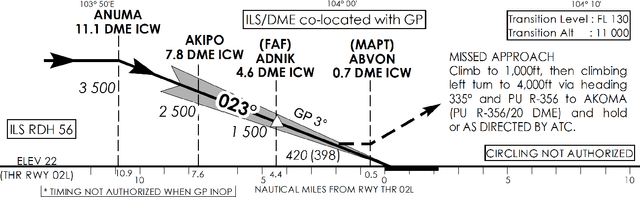
Approach and landing accidents (ALAs) have resulted in a significant number of hull losses worldwide, aside from runway excursion, hard landing, landing short. Technologies (e.g., instrument landing system) and procedures (e.g., stabilized approach criteria) have been developed to reduce ALA risks. In this paper, we propose a data-driven method to learn and interpret flight's 4D approach and landing parameters to facilitate comprehensible and actionable insights of landing dynamics for aircrew and air traffic controller (ATCO) in real-time. Specifically, we develop a tunnel Gaussian process (TGP) model to gain an insight into the landing dynamics of aircraft using advanced surface movement guidance and control system (A-SMGCS) data, which then indicates the stability of flight. TGP hybridizes the strengths of sparse variational Gaussian process and polar Gaussian process to learn from a large amount of data in cylindrical coordinates. We examine TGP qualitatively and quantitatively by synthesizing two complex trajectory datasets. Empirically, TGP reconstructed the structure of the synthesized trajectories. When applied to operational A-SMGCS data, TGP provides the probabilistic description of landing dynamics and interpretable 4D tunnel views of approach and landing parameters. The 4D tunnel views can facilitate the analysis of procedure adherence and augment existing aircrew and ATCO's display during the approach and landing procedures, enabling necessary corrective actions. The proposed TGP model can also provide insights and aid the design of landing procedures in complex runway configurations such as parallel approach. Moreover, the extension of TGP model to the next generation of landing systems (e.g., GNSS landing system) is straight-forward. The interactive visualization of our findings are available at https://simkuangoh.github.io/TunnelGP/.
Don't Parse, Insert: Multilingual Semantic Parsing with Insertion Based Decoding
Oct 08, 2020
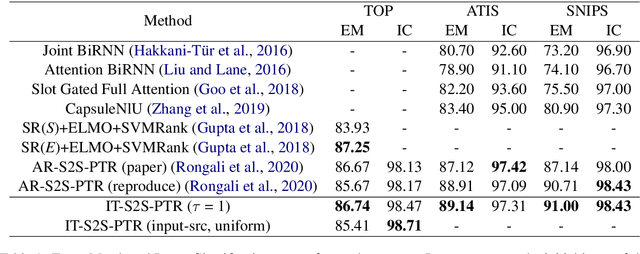


Semantic parsing is one of the key components of natural language understanding systems. A successful parse transforms an input utterance to an action that is easily understood by the system. Many algorithms have been proposed to solve this problem, from conventional rulebased or statistical slot-filling systems to shiftreduce based neural parsers. For complex parsing tasks, the state-of-the-art method is based on autoregressive sequence to sequence models to generate the parse directly. This model is slow at inference time, generating parses in O(n) decoding steps (n is the length of the target sequence). In addition, we demonstrate that this method performs poorly in zero-shot cross-lingual transfer learning settings. In this paper, we propose a non-autoregressive parser which is based on the insertion transformer to overcome these two issues. Our approach 1) speeds up decoding by 3x while outperforming the autoregressive model and 2) significantly improves cross-lingual transfer in the low-resource setting by 37% compared to autoregressive baseline. We test our approach on three well-known monolingual datasets: ATIS, SNIPS and TOP. For cross lingual semantic parsing, we use the MultiATIS++ and the multilingual TOP datasets.
Detecting Anomalies from Video-Sequences: a Novel Descriptor
Oct 17, 2020
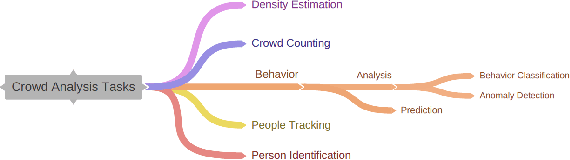

We present a novel descriptor for crowd behavior analysis and anomaly detection. The goal is to measure by appropriate patterns the speed of formation and disintegration of groups in the crowd. This descriptor is inspired by the concept of one-dimensional local binary patterns: in our case, such patterns depend on the number of group observed in a time window. An appropriate measurement unit, named "trit" (trinary digit), represents three possible dynamic states of groups on a certain frame. Our hypothesis is that abrupt variations of the groups' number may be due to an anomalous event that can be accordingly detected, by translating these variations on temporal trit-based sequence of strings which are significantly different from the one describing the "no-anomaly" one. Due to the peculiarity of the rationale behind this work, relying on the number of groups, three different methods of people group's extraction are compared. Experiments are carried out on the Motion-Emotion benchmark data set. Reported results point out in which cases the trit-based measurement of group dynamics allows us to detect the anomaly. Besides the promising performance of our approach, we show how it is correlated with the anomaly typology and the camera's perspective to the crowd's flow (frontal, lateral).
Multitask Learning and Benchmarking with Clinical Time Series Data
Mar 22, 2017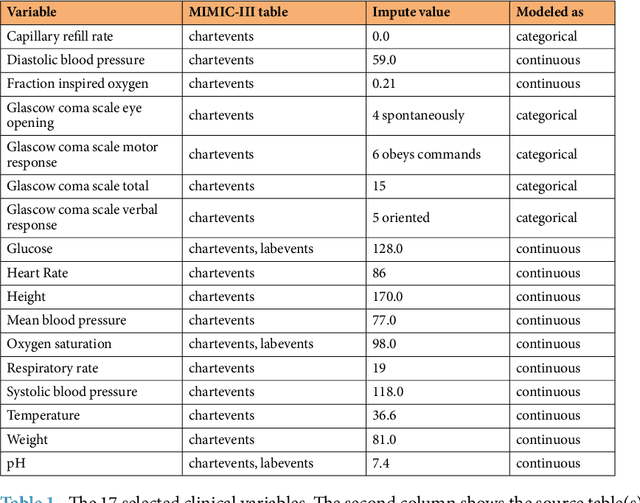
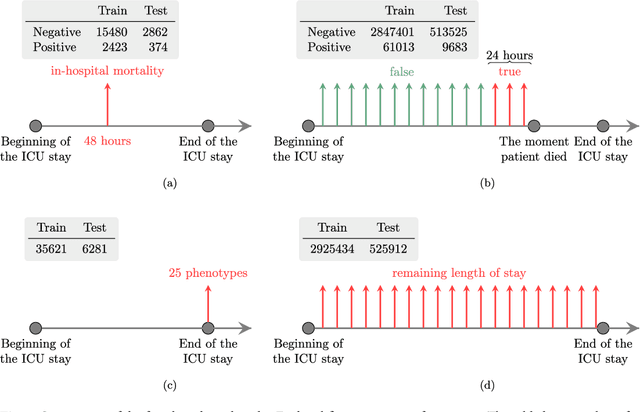
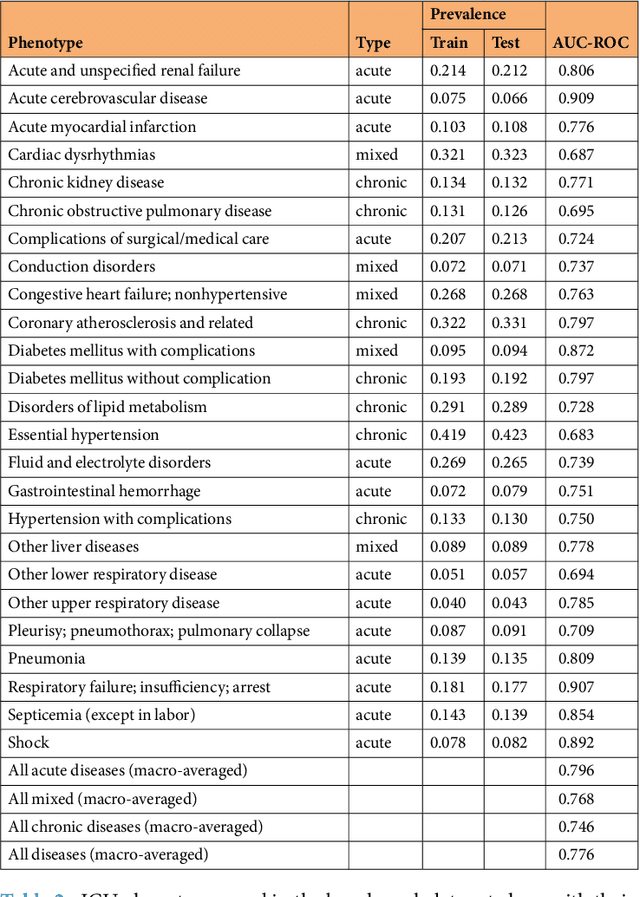
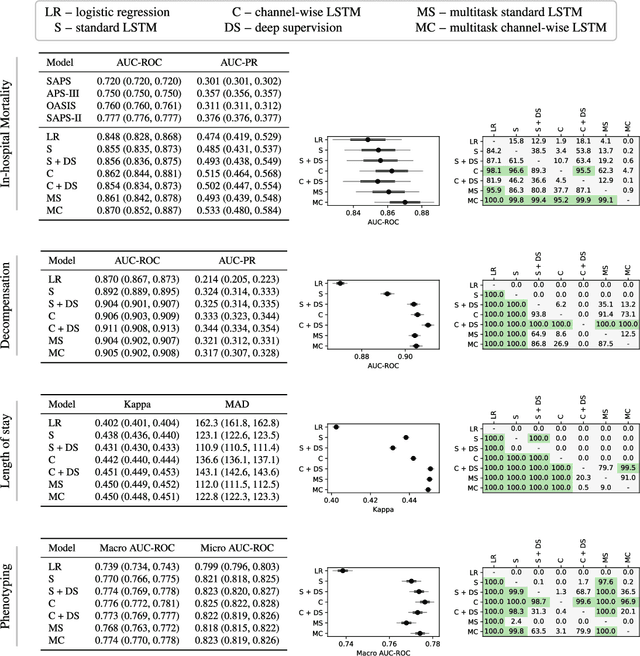
Health care is one of the most exciting frontiers in data mining and machine learning. Successful adoption of electronic health records (EHRs) created an explosion in digital clinical data available for analysis, but progress in machine learning for healthcare research has been difficult to measure because of the absence of publicly available benchmark data sets. To address this problem, we propose four clinical prediction benchmarks using data derived from the publicly available Medical Information Mart for Intensive Care (MIMIC-III) database. These tasks cover a range of clinical problems including modeling risk of mortality, forecasting length of stay, detecting physiologic decline, and phenotype classification. We formulate a heterogeneous multitask problem where the goal is to jointly learn multiple clinically relevant prediction tasks based on the same time series data. To address this problem, we propose a novel recurrent neural network (RNN) architecture that leverages the correlations between the various tasks to learn a better predictive model. We validate the proposed neural architecture on this benchmark, and demonstrate that it outperforms strong baselines, including single task RNNs.
Learning the Latent State Space of Time-Varying Graphs
Mar 14, 2014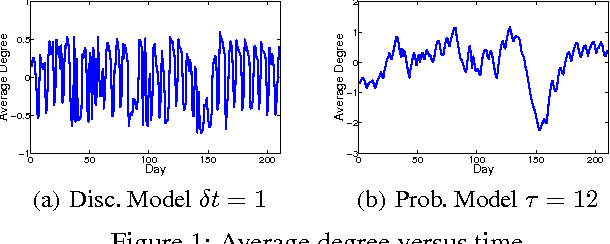
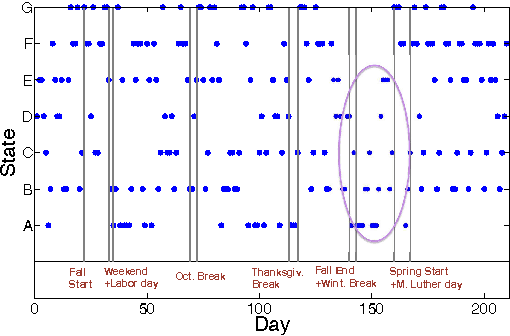
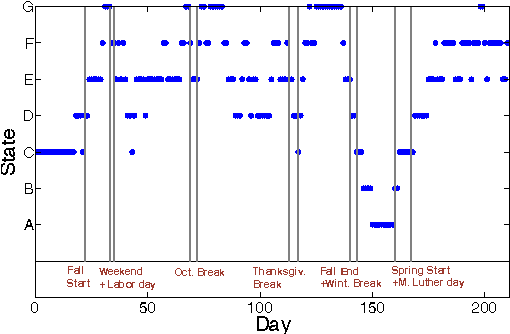
From social networks to Internet applications, a wide variety of electronic communication tools are producing streams of graph data; where the nodes represent users and the edges represent the contacts between them over time. This has led to an increased interest in mechanisms to model the dynamic structure of time-varying graphs. In this work, we develop a framework for learning the latent state space of a time-varying email graph. We show how the framework can be used to find subsequences that correspond to global real-time events in the Email graph (e.g. vacations, breaks, ...etc.). These events impact the underlying graph process to make its characteristics non-stationary. Within the framework, we compare two different representations of the temporal relationships; discrete vs. probabilistic. We use the two representations as inputs to a mixture model to learn the latent state transitions that correspond to important changes in the Email graph structure over time.
Online Safety Assurance for Deep Reinforcement Learning
Oct 07, 2020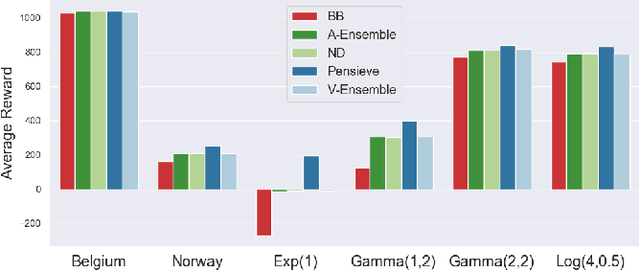
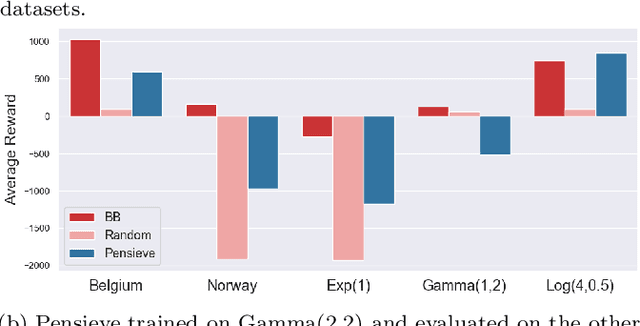
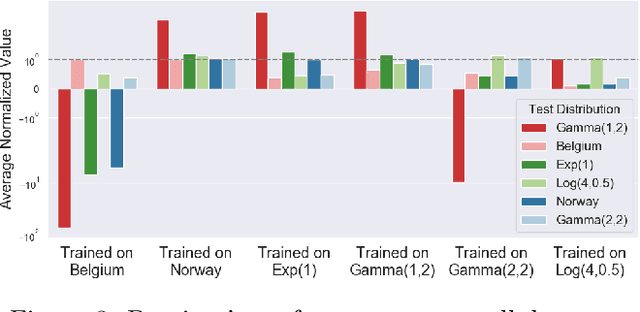
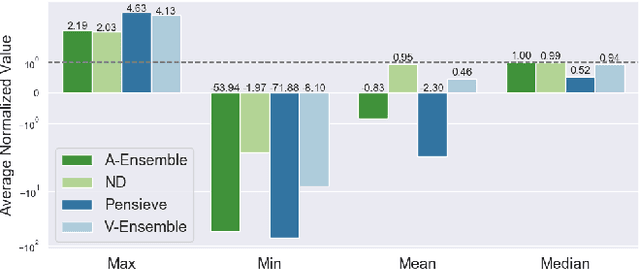
Recently, deep learning has been successfully applied to a variety of networking problems. A fundamental challenge is that when the operational environment for a learning-augmented system differs from its training environment, such systems often make badly informed decisions, leading to bad performance. We argue that safely deploying learning-driven systems requires being able to determine, in real time, whether system behavior is coherent, for the purpose of defaulting to a reasonable heuristic when this is not so. We term this the online safety assurance problem (OSAP). We present three approaches to quantifying decision uncertainty that differ in terms of the signal used to infer uncertainty. We illustrate the usefulness of online safety assurance in the context of the proposed deep reinforcement learning (RL) approach to video streaming. While deep RL for video streaming bests other approaches when the operational and training environments match, it is dominated by simple heuristics when the two differ. Our preliminary findings suggest that transitioning to a default policy when decision uncertainty is detected is key to enjoying the performance benefits afforded by leveraging ML without compromising on safety.
Tile Tensors: A versatile data structure with descriptive shapes for homomorphic encryption
Nov 03, 2020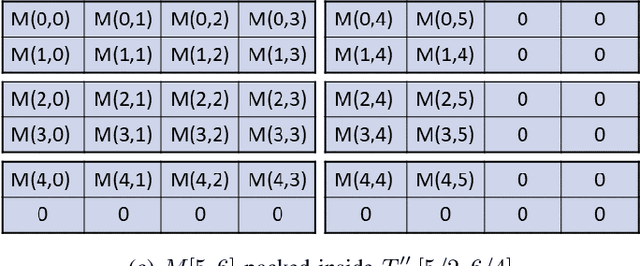

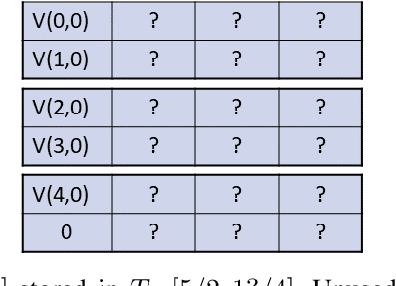
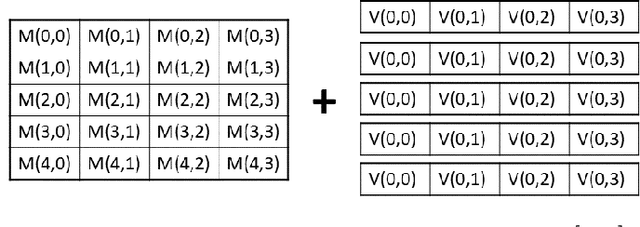
Moving from the theoretical promise of Fully Homomorphic Encryption (FHE) to real-world applications with realistic and acceptable time and memory figures is an on-going challenge. After choosing an appropriate FHE scheme, and before implementing privacy-preserving analytics, one needs an efficient packing method that will optimize use of the ciphertext slots, trading-off size, latency, and throughput. We propose a solution to this challenge. We describe a method for efficiently working with tensors (multi-dimensional arrays) in a system that imposes tiles, i.e., fixed-size vectors. The tensors are packed into tiles and then manipulated via operations on those tiles. We further show a novel and concise notation for describing packing details. Our method reinterprets the tiles as multi-dimensional arrays, and combines them to cover enough space to hold the tensor. An efficient summation algorithm can then sum over any dimension of this construct. We propose a descriptive notation for the shape of this data structure that describes both the original tensor and how it is packed inside the tiles. Our solution can be used to optimize the performance of various algorithms such as consecutive matrix multiplications or neural network inference with varying batch sizes. It can also serve to enhance optimizations done by homomorphic encryption compilers. We describe different applications that take advantage of this data structure through the proposed notation, experiment to evaluate the advantages through different applications, and share our conclusions.
Demand Forecasting of individual Probability Density Functions with Machine Learning
Sep 15, 2020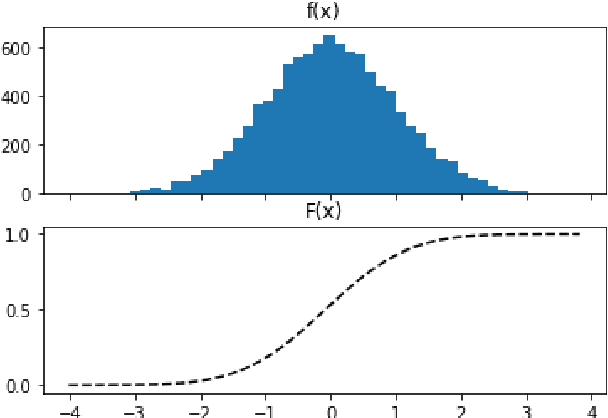
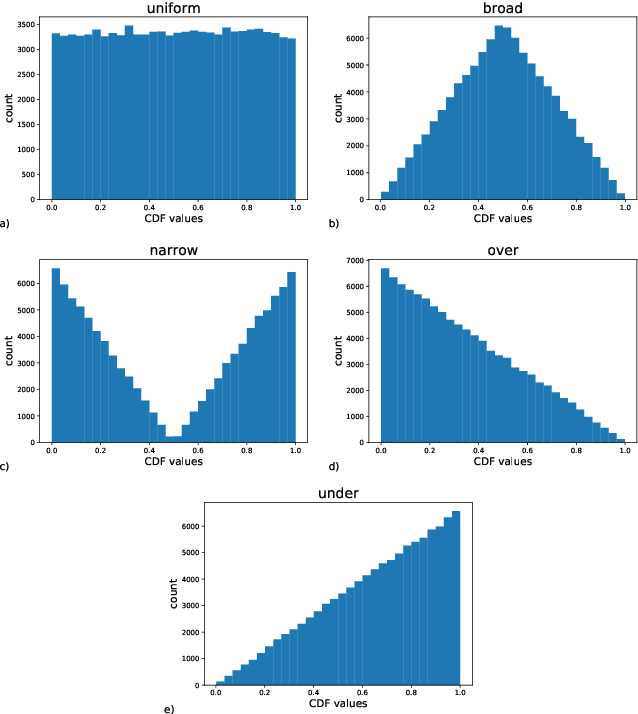
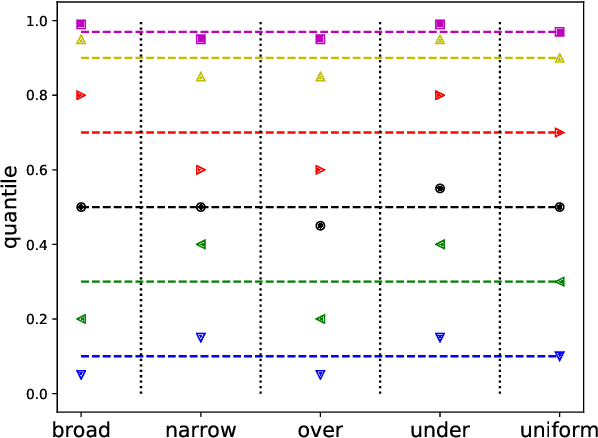
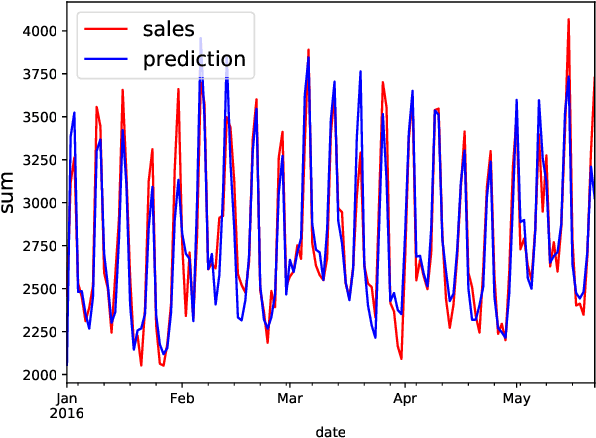
Demand forecasting is a central component for many aspects of supply chain operations, as it provides crucial input for subsequent decision making like ordering processes. While machine learning methods can significantly improve prediction accuracy over traditional time series forecasting, the calculated predictions are often just point estimations for the conditional mean of the underlying probability distribution, and the most powerful approaches, like deep learning, are usually opaque in terms of how its individual predictions can be interpreted. Using the novel supervised machine learning method "Cyclic Boosting", complete individual probability density functions can be predicted instead of single numbers. While metrics evaluating point estimates are widely used, methods for assessing the accuracy of predicted distributions are rare and this work proposes new techniques for both qualitative and quantitative evaluation methods. Additionally, each single prediction obtained with this framework is explainable. This is a major benefit in particular for practitioners, as this allows them to avoid "black-box" models and understand the contributing factors for each individual prediction.