 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ALPS: Active Learning via Perturbations
Apr 20, 2020
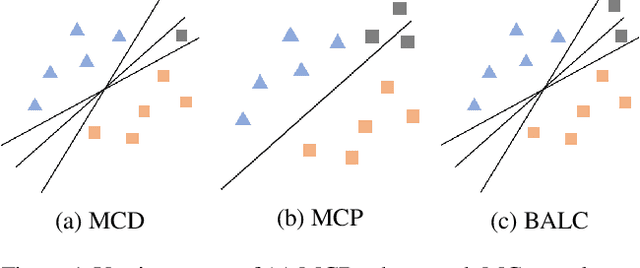
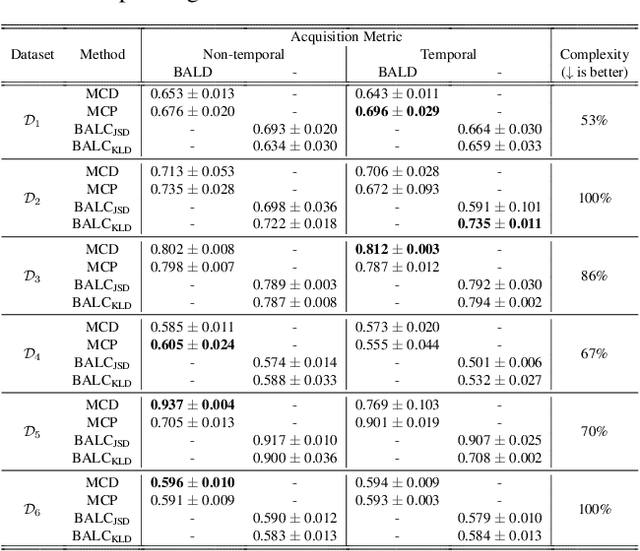
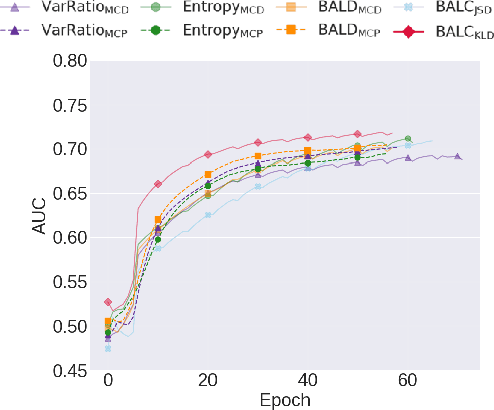
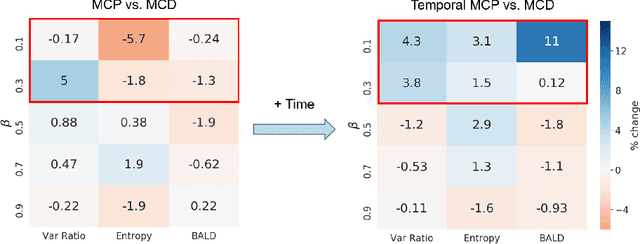
Small, labelled datasets in the presence of larger, unlabelled datasets pose challenges to data-hungry deep learning algorithms. Such scenarios are prevalent in healthcare where labelling is expensive, time-consuming, and requires expert medical professionals. To tackle this challenge, we propose a family of active learning methodologies and acquisition functions dependent upon input and parameter perturbations which we call Active Learning via Perturbations (ALPS). We test our methods on six diverse time-series and image datasets and illustrate their benefit in the presence and absence of an oracle. We also show that acquisition functions that incorporate temporal information have the potential to predict the ability of networks to generalize.
Multi-Target Tracking with Time-Varying Clutter Rate and Detection Profile: Application to Time-lapse Cell Microscopy Sequences
Jul 23, 2015
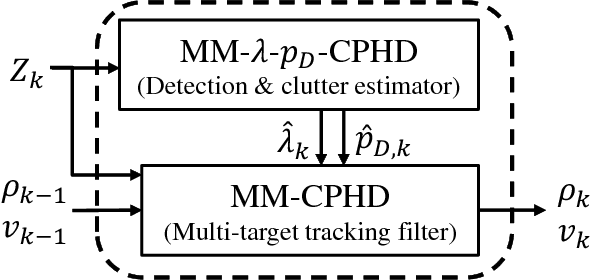
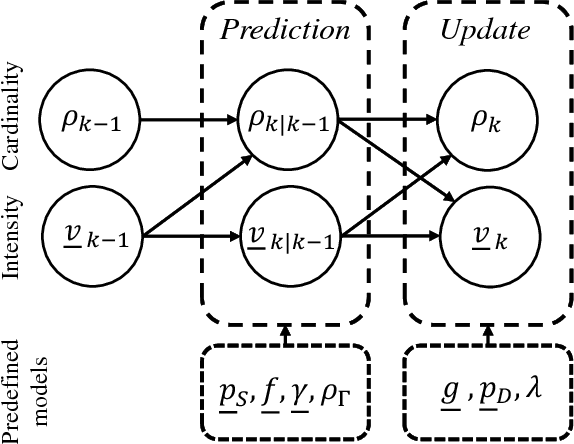
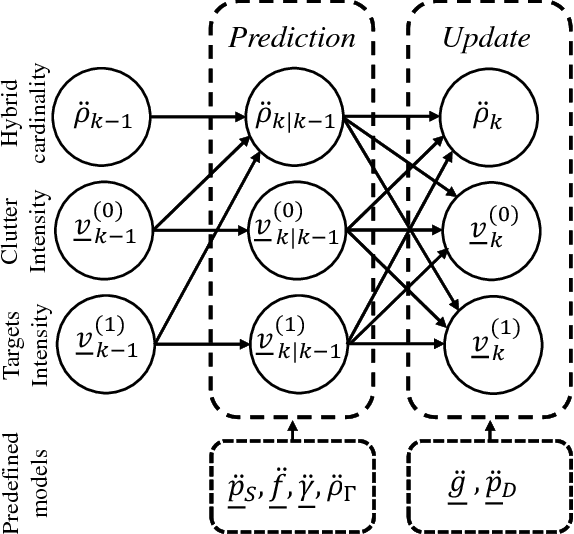
Quantitative analysis of the dynamics of tiny cellular and sub-cellular structures, known as particles, in time-lapse cell microscopy sequences requires the development of a reliable multi-target tracking method capable of tracking numerous similar targets in the presence of high levels of noise, high target density, complex motion patterns and intricate interactions. In this paper, we propose a framework for tracking these structures based on the random finite set Bayesian filtering framework. We focus on challenging biological applications where image characteristics such as noise and background intensity change during the acquisition process. Under these conditions, detection methods usually fail to detect all particles and are often followed by missed detections and many spurious measurements with unknown and time-varying rates. To deal with this, we propose a bootstrap filter composed of an estimator and a tracker. The estimator adaptively estimates the required meta parameters for the tracker such as clutter rate and the detection probability of the targets, while the tracker estimates the state of the targets. Our results show that the proposed approach can outperform state-of-the-art particle trackers on both synthetic and real data in this regime.
EdinburghNLP at WNUT-2020 Task 2: Leveraging Transformers with Generalized Augmentation for Identifying Informativeness in COVID-19 Tweets
Sep 06, 2020
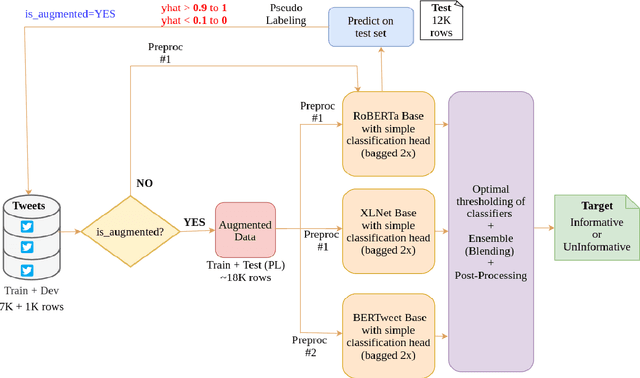
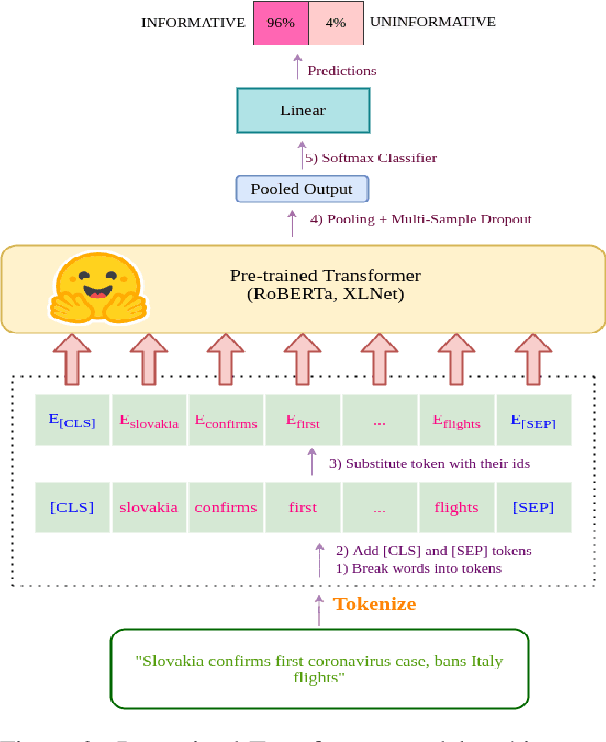
Twitter has become an important communication channel in times of emergency. The ubiquitousness of smartphones enables people to announce an emergency they're observing in real-time. Because of this, more agencies are interested in programatically monitoring Twitter (disaster relief organizations and news agencies) and therefore recognizing the informativeness of a tweet can help filter noise from large volumes of data. In this paper, we present our submission for WNUT-2020 Task 2: Identification of informative COVID-19 English Tweets. Our most successful model is an ensemble of transformers including RoBERTa, XLNet, and BERTweet trained in a semi-supervised experimental setting. The proposed system achieves a F1 score of 0.9011 on the test set (ranking 7th on the leaderboard), and shows significant gains in performance compared to a baseline system using fasttext embeddings.
Batch-Augmented Multi-Agent Reinforcement Learning for Efficient Traffic Signal Optimization
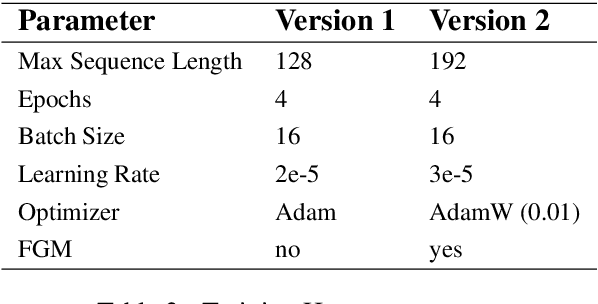
May 19, 2020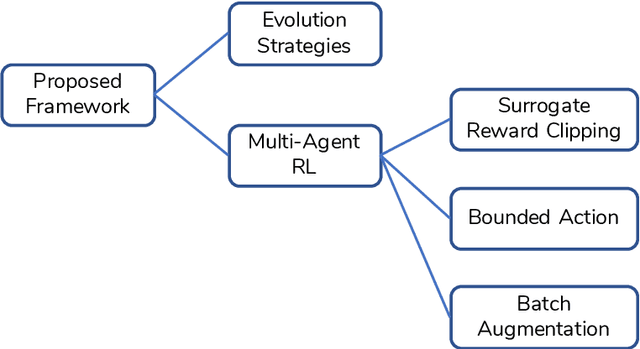
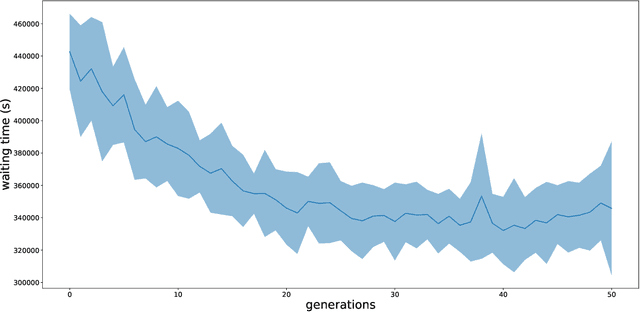
The goal of this work is to provide a viable solution based on reinforcement learning for traffic signal control problems. Although the state-of-the-art reinforcement learning approaches have yielded great success in a variety of domains, directly applying it to alleviate traffic congestion can be challenging, considering the requirement of high sample efficiency and how training data is gathered. In this work, we address several challenges that we encountered when we attempted to mitigate serious traffic congestion occurring in a metropolitan area. Specifically, we are required to provide a solution that is able to (1) handle the traffic signal control when certain surveillance cameras that retrieve information for reinforcement learning are down, (2) learn from batch data without a traffic simulator, and (3) make control decisions without shared information across intersections. We present a two-stage framework to deal with the above-mentioned situations. The framework can be decomposed into an Evolution Strategies approach that gives a fixed-time traffic signal control schedule and a multi-agent off-policy reinforcement learning that is capable of learning from batch data with the aid of three proposed components, bounded action, batch augmentation, and surrogate reward clipping. Our experiments show that the proposed framework reduces traffic congestion by 36% in terms of waiting time compared with the currently used fixed-time traffic signal plan. Furthermore, the framework requires only 600 queries to a simulator to achieve the result.
CPR: Understanding and Improving Failure Tolerant Training for Deep Learning Recommendation with Partial Recovery
Nov 05, 2020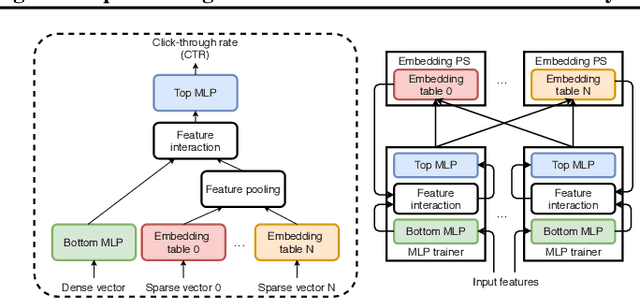
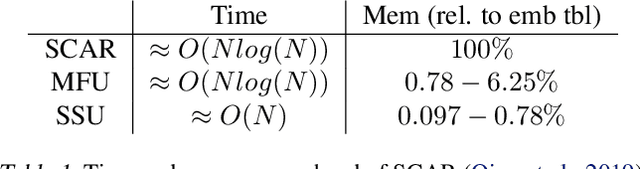
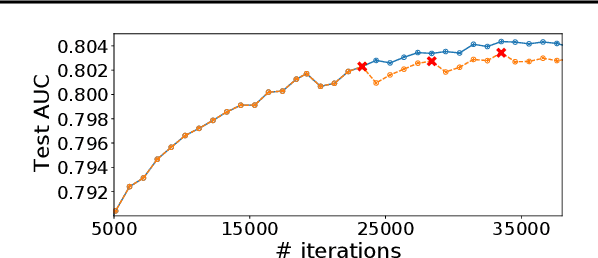
The paper proposes and optimizes a partial recovery training system, CPR, for recommendation models. CPR relaxes the consistency requirement by enabling non-failed nodes to proceed without loading checkpoints when a node fails during training, improving failure-related overheads. The paper is the first to the extent of our knowledge to perform a data-driven, in-depth analysis of applying partial recovery to recommendation models and identified a trade-off between accuracy and performance. Motivated by the analysis, we present CPR, a partial recovery training system that can reduce the training time and maintain the desired level of model accuracy by (1) estimating the benefit of partial recovery, (2) selecting an appropriate checkpoint saving interval, and (3) prioritizing to save updates of more frequently accessed parameters. Two variants of CPR, CPR-MFU and CPR-SSU, reduce the checkpoint-related overhead from 8.2-8.5% to 0.53-0.68% compared to full recovery, on a configuration emulating the failure pattern and overhead of a production-scale cluster. While reducing overhead significantly, CPR achieves model quality on par with the more expensive full recovery scheme, training the state-of-the-art recommendation model using Criteo's Ads CTR dataset. Our preliminary results also suggest that CPR can speed up training on a real production-scale cluster, without notably degrading the accuracy.
Real-time Quasi-Optimal Trajectory Planning for Autonomous Underwater Docking
May 03, 2016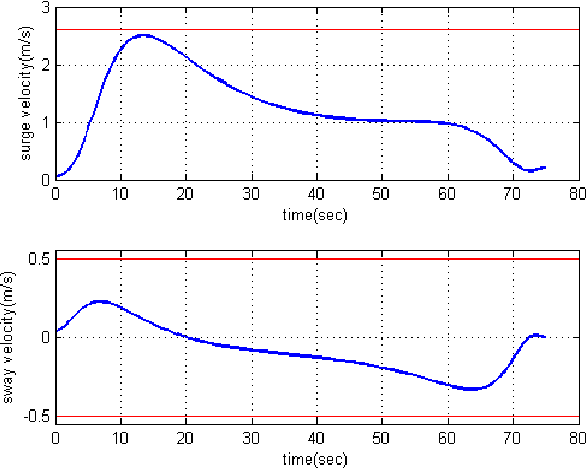
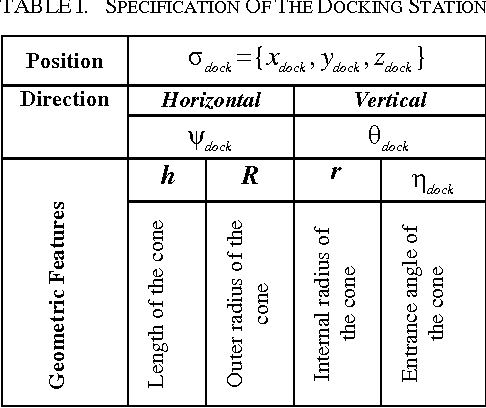
In this paper, a real-time quasi-optimal trajectory planning scheme is employed to guide an autonomous underwater vehicle (AUV) safely into a funnel-shape stationary docking station. By taking advantage of the direct method of calculus of variation and inverse dynamics optimization, the proposed trajectory planner provides a computationally efficient framework for autonomous underwater docking in a 3D cluttered undersea environment. Vehicular constraints, such as constraints on AUV states and actuators; boundary conditions, including initial and final vehicle poses; and environmental constraints, for instance no-fly zones and current disturbances, are all modelled and considered in the problem formulation. The performance of the proposed planner algorithm is analyzed through simulation studies. To show the reliability and robustness of the method in dealing with uncertainty, Monte Carlo runs and statistical analysis are carried out. The results of the simulations indicate that the proposed planner is well suited for real-time implementation in a dynamic and uncertain environment.
MACER: A Modular Framework for Accelerated Compilation Error Repair
May 28, 2020



Automated compilation error repair, the problem of suggesting fixes to buggy programs that fail to compile, has generated significant interest in recent years. Apart from being a tool of general convenience, automated code repair has significant pedagogical applications for novice programmers who find compiler error messages cryptic and unhelpful. Existing approaches largely solve this problem using a blackbox-application of a heavy-duty generative learning technique, such as sequence-to-sequence prediction (TRACER) or reinforcement learning (RLAssist). Although convenient, such black-box application of learning techniques makes existing approaches bulky in terms of training time, as well as inefficient at targeting specific error types. We present MACER, a novel technique for accelerated error repair based on a modular segregation of the repair process into repair identification and repair application. MACER uses powerful yet inexpensive discriminative learning techniques such as multi-label classifiers and rankers to first identify the type of repair required and then apply the suggested repair. Experiments indicate that the fine-grained approach adopted by MACER offers not only superior error correction, but also much faster training and prediction. On a benchmark dataset of 4K buggy programs collected from actual student submissions, MACER outperforms existing methods by 20% at suggesting fixes for popular errors that exactly match the fix desired by the student. MACER is also competitive or better than existing methods at all error types -- whether popular or rare. MACER offers a training time speedup of 2x over TRACER and 800x over RLAssist, and a test time speedup of 2-4x over both.
Comparison of Recurrent Neural Network Architectures for Wildfire Spread Modelling
May 26, 2020
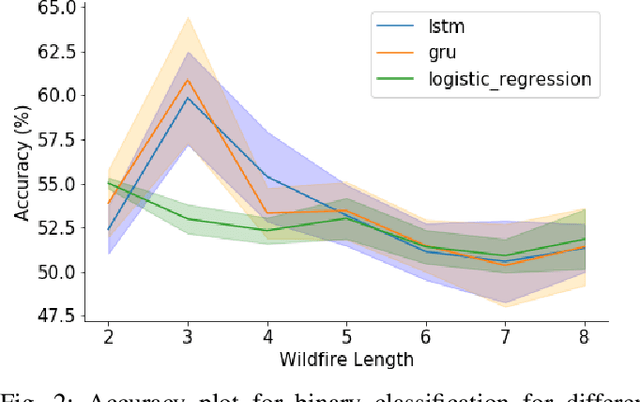
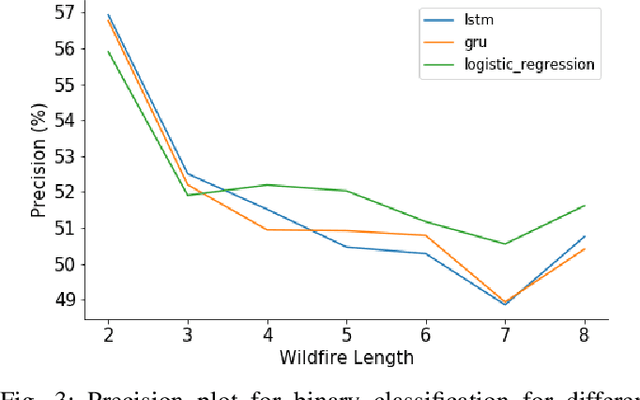
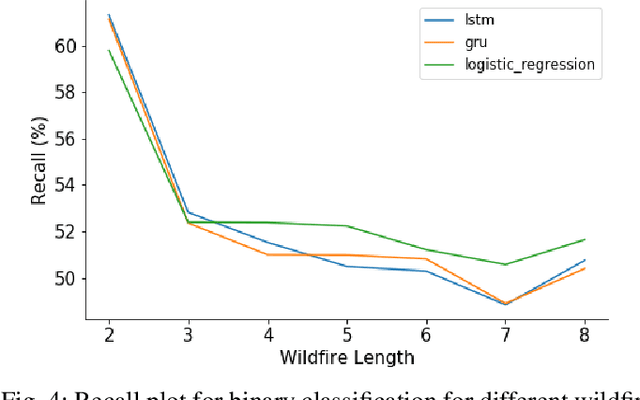
Wildfire modelling is an attempt to reproduce fire behaviour. Through active fire analysis, it is possible to reproduce a dynamical process, such as wildfires, with limited duration time series data. Recurrent neural networks (RNNs) can model dynamic temporal behaviour due to their ability to remember their internal input. In this paper, we compare the Gated Recurrent Unit (GRU) and the Long Short-Term Memory (LSTM) network. We try to determine whether a wildfire continues to burn and given that it does, we aim to predict which one of the 8 cardinal directions the wildfire will spread in. Overall the GRU performs better for longer time series than the LSTM. We have shown that although we are reasonable at predicting the direction in which the wildfire will spread, we are not able to asses if the wildfire continues to burn due to the lack of auxiliary data.
Experience Augmentation: Boosting and Accelerating Off-Policy Multi-Agent Reinforcement Learning
May 20, 2020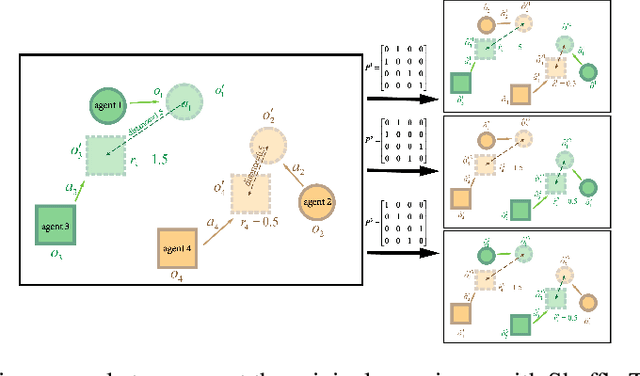

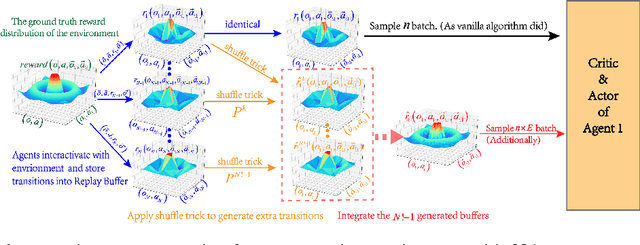

Exploration of the high-dimensional state action space is one of the biggest challenges in Reinforcement Learning (RL), especially in multi-agent domain. We present a novel technique called Experience Augmentation, which enables a time-efficient and boosted learning based on a fast, fair and thorough exploration to the environment. It can be combined with arbitrary off-policy MARL algorithms and is applicable to either homogeneous or heterogeneous environments. We demonstrate our approach by combining it with MADDPG and verifing the performance in two homogeneous and one heterogeneous environments. In the best performing scenario, the MADDPG with experience augmentation reaches to the convergence reward of vanilla MADDPG with 1/4 realistic time, and its convergence beats the original model by a significant margin. Our ablation studies show that experience augmentation is a crucial ingredient which accelerates the training process and boosts the convergence.
Democratizing Artificial Intelligence in Healthcare: A Study of Model Development Across Two Institutions Incorporating Transfer Learning
Sep 25, 2020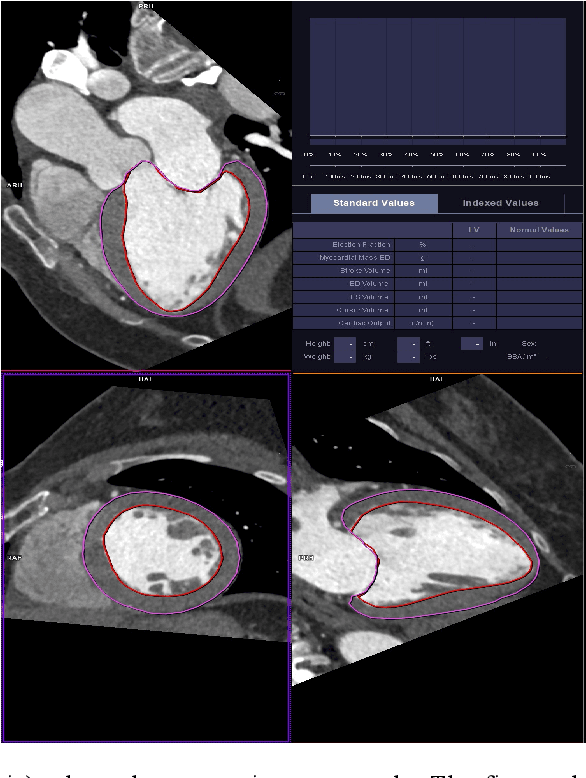
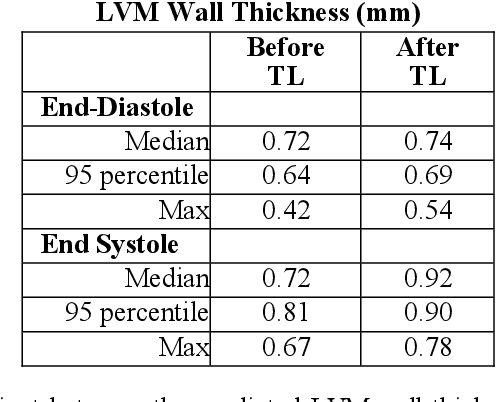
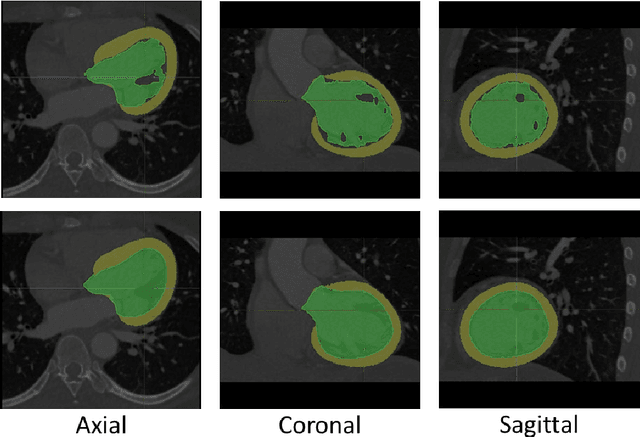
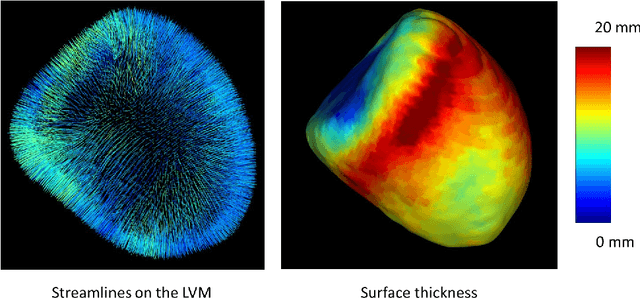
The training of deep learning models typically requires extensive data, which are not readily available as large well-curated medical-image datasets for development of artificial intelligence (AI) models applied in Radiology. Recognizing the potential for transfer learning (TL) to allow a fully trained model from one institution to be fine-tuned by another institution using a much small local dataset, this report describes the challenges, methodology, and benefits of TL within the context of developing an AI model for a basic use-case, segmentation of Left Ventricular Myocardium (LVM) on images from 4-dimensional coronary computed tomography angiography. Ultimately, our results from comparisons of LVM segmentation predicted by a model locally trained using random initialization, versus one training-enhanced by TL, showed that a use-case model initiated by TL can be developed with sparse labels with acceptable performance. This process reduces the time required to build a new model in the clinical environment at a different institution.