 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DartMinHash: Fast Sketching for Weighted Sets
May 23, 2020
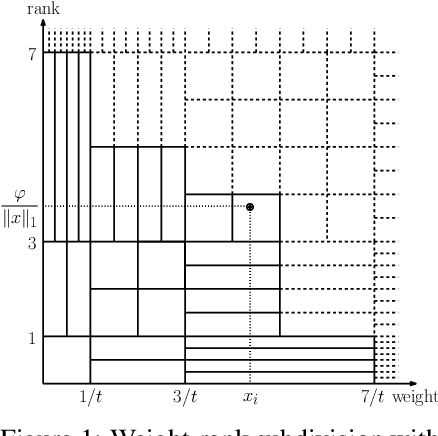
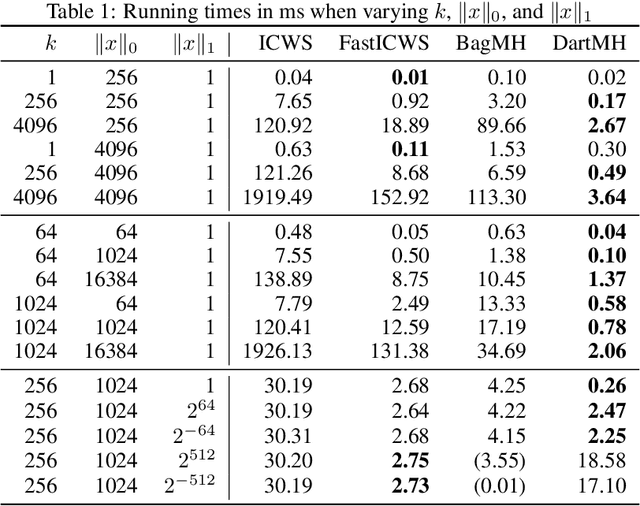
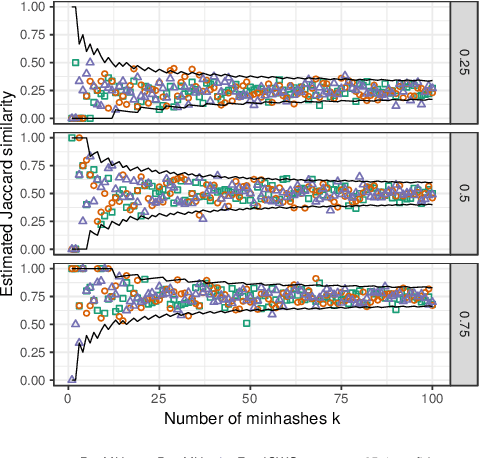
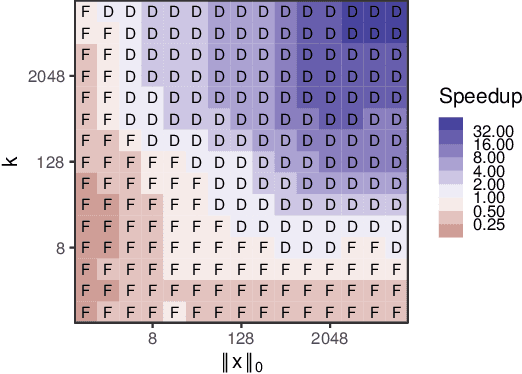
Weighted minwise hashing is a standard dimensionality reduction technique with applications to similarity search and large-scale kernel machines. We introduce a simple algorithm that takes a weighted set $x \in \mathbb{R}_{\geq 0}^{d}$ and computes $k$ independent minhashes in expected time $O(k \log k + \Vert x \Vert_{0}\log( \Vert x \Vert_1 + 1/\Vert x \Vert_1))$, improving upon the state-of-the-art BagMinHash algorithm (KDD '18) and representing the fastest weighted minhash algorithm for sparse data. Our experiments show running times that scale better with $k$ and $\Vert x \Vert_0$ compared to ICWS (ICDM '10) and BagMinhash, obtaining $10$x speedups in common use cases. Our approach also gives rise to a technique for computing fully independent locality-sensitive hash values for $(L, K)$-parameterized approximate near neighbor search under weighted Jaccard similarity in optimal expected time $O(LK + \Vert x \Vert_0)$, improving on prior work even in the case of unweighted sets.
Parameter-based Value Functions
Jun 16, 2020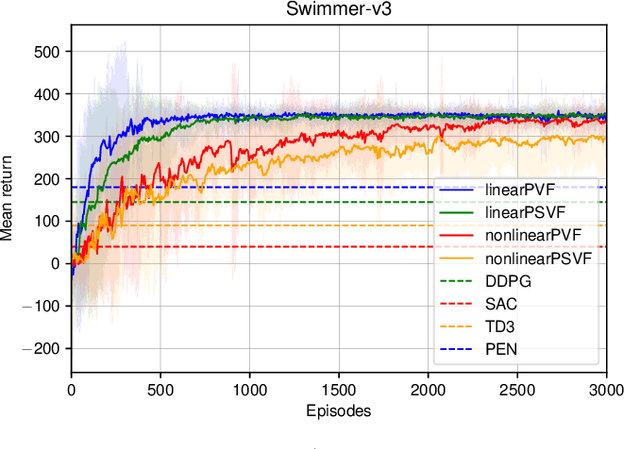
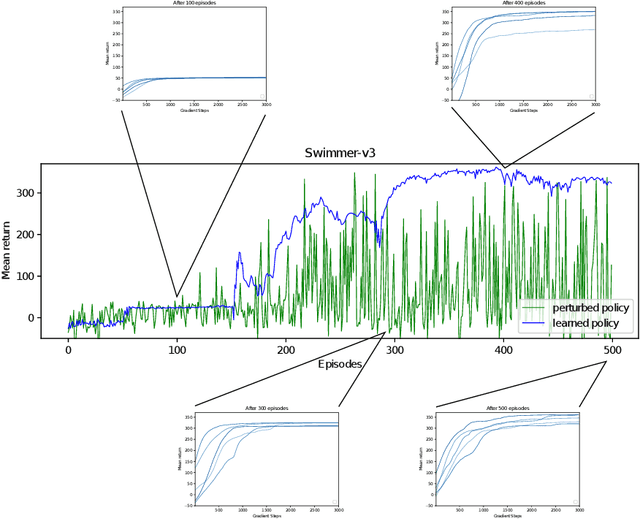
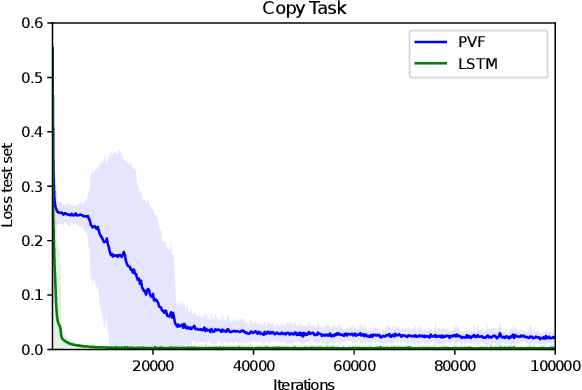
Learning value functions off-policy is at the core of modern Reinforcement Learning (RL). Traditional off-policy actor-critic algorithms, however, only approximate the true policy gradient, since the gradient $\nabla_{\theta} Q^{\pi_{\theta}}(s,a)$ of the action-value function with respect to the policy parameters is often ignored. We introduce a class of value functions called Parameter-based Value Functions (PVFs) whose inputs include the policy parameters. PVFs can evaluate the performance of any policy given a state, a state-action pair, or a distribution over the RL agent's initial states. We show how PVFs yield exact policy gradient theorems. We derive off-policy actor-critic algorithms based on PVFs trained using Monte Carlo or Temporal Difference methods. Preliminary experimental results indicate that PVFs can effectively evaluate deterministic linear and nonlinear policies, outperforming state-of-the-art algorithms in the continuous control environment Swimmer-v3. Finally, we show how recurrent neural networks can be trained through PVFs to solve supervised and RL problems involving partial observability and long time lags between relevant events. This provides an alternative to backpropagation through time.
FinRL: A Deep Reinforcement Learning Library for Automated Stock Trading in Quantitative Finance
Nov 19, 2020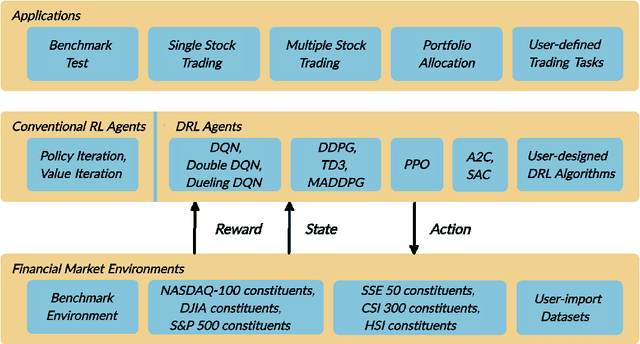
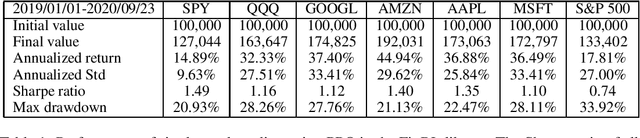
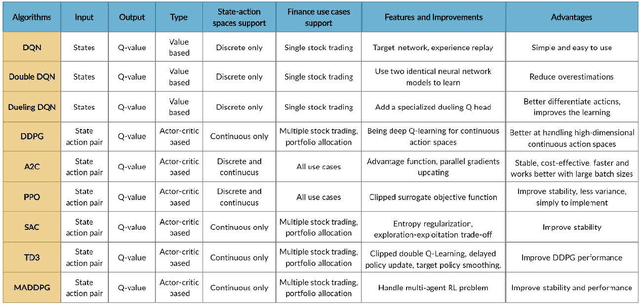
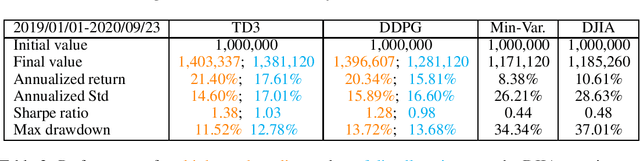
As deep reinforcement learning (DRL) has been recognized as an effective approach in quantitative finance, getting hands-on experiences is attractive to beginners. However, to train a practical DRL trading agent that decides where to trade, at what price, and what quantity involves error-prone and arduous development and debugging. In this paper, we introduce a DRL library FinRL that facilitates beginners to expose themselves to quantitative finance and to develop their own stock trading strategies. Along with easily-reproducible tutorials, FinRL library allows users to streamline their own developments and to compare with existing schemes easily. Within FinRL, virtual environments are configured with stock market datasets, trading agents are trained with neural networks, and extensive backtesting is analyzed via trading performance. Moreover, it incorporates important trading constraints such as transaction cost, market liquidity and the investor's degree of risk-aversion. FinRL is featured with completeness, hands-on tutorial and reproducibility that favors beginners: (i) at multiple levels of time granularity, FinRL simulates trading environments across various stock markets, including NASDAQ-100, DJIA, S&P 500, HSI, SSE 50, and CSI 300; (ii) organized in a layered architecture with modular structure, FinRL provides fine-tuned state-of-the-art DRL algorithms (DQN, DDPG, PPO, SAC, A2C, TD3, etc.), commonly-used reward functions and standard evaluation baselines to alleviate the debugging workloads and promote the reproducibility, and (iii) being highly extendable, FinRL reserves a complete set of user-import interfaces. Furthermore, we incorporated three application demonstrations, namely single stock trading, multiple stock trading, and portfolio allocation. The FinRL library will be available on Github at link https://github.com/AI4Finance-LLC/FinRL-Library.
The Slow Deterioration of the Generalization Error of the Random Feature Model
Aug 13, 2020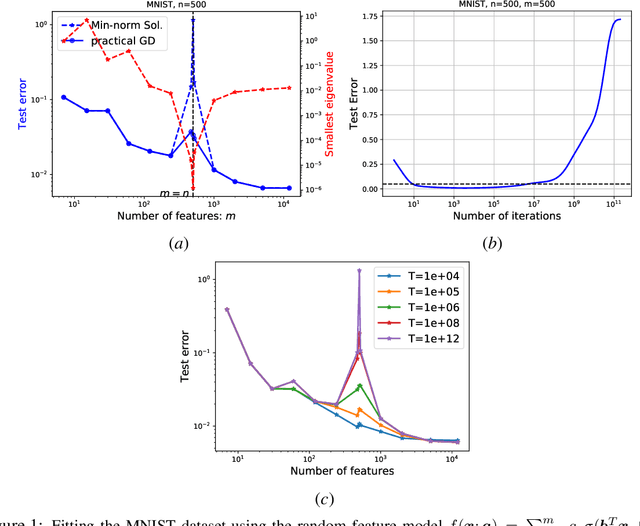
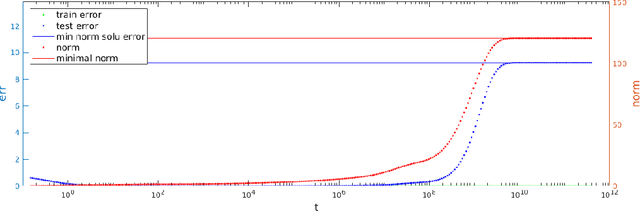
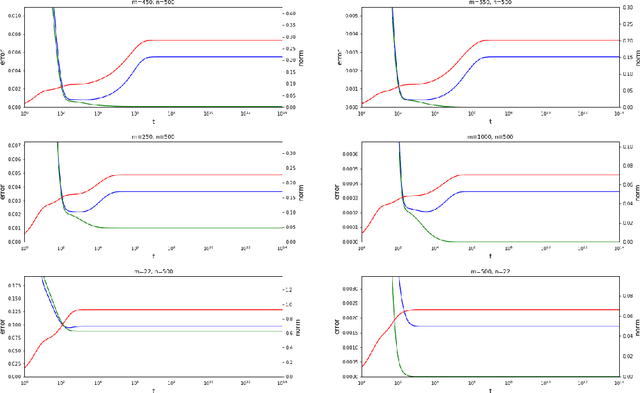
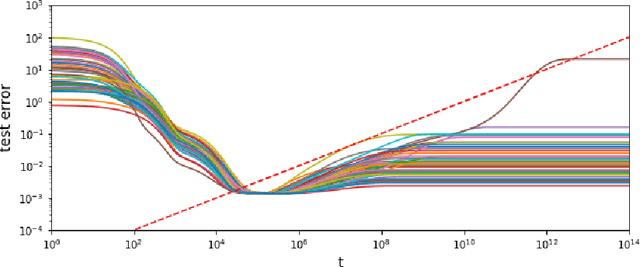
The random feature model exhibits a kind of resonance behavior when the number of parameters is close to the training sample size. This behavior is characterized by the appearance of large generalization gap, and is due to the occurrence of very small eigenvalues for the associated Gram matrix. In this paper, we examine the dynamic behavior of the gradient descent algorithm in this regime. We show, both theoretically and experimentally, that there is a dynamic self-correction mechanism at work: The larger the eventual generalization gap, the slower it develops, both because of the small eigenvalues. This gives us ample time to stop the training process and obtain solutions with good generalization property.
Industrial Forecasting with Exponentially Smoothed Recurrent Neural Networks
Apr 09, 2020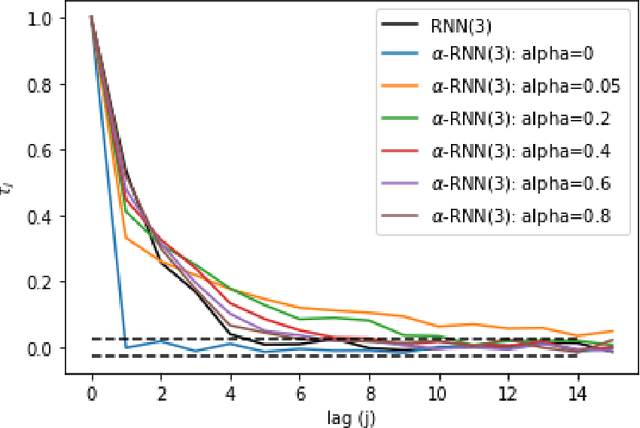
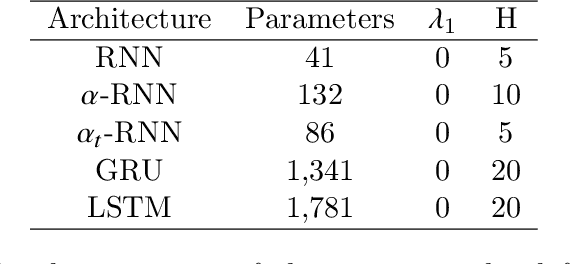
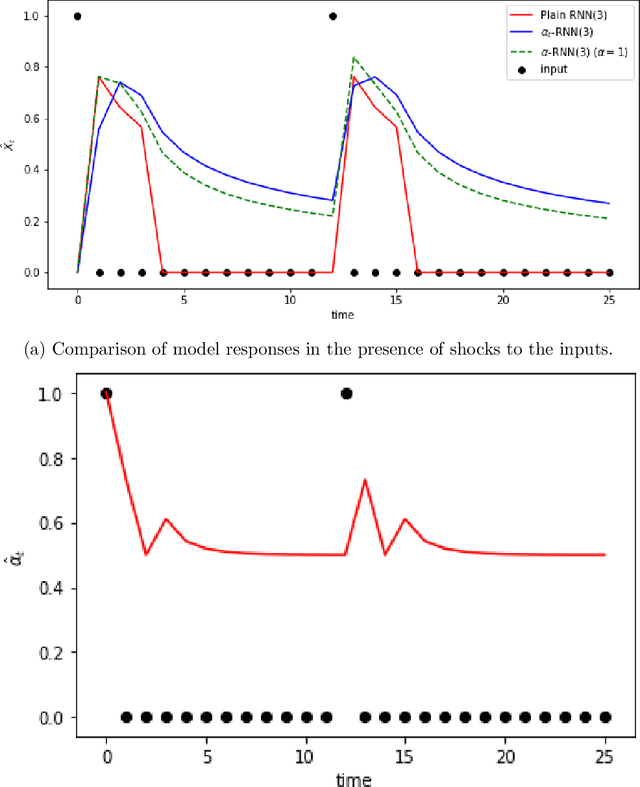
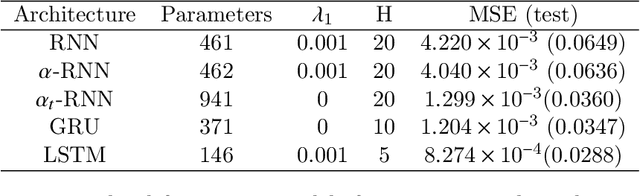
Industrial forecasting has entered an era of unprecedented growth in the size and complexity of data which require new modeling methodologies. While many new general purpose machine learning approaches have emerged, they remain poorly understand and irreconcilable with more traditional statistical modeling approaches. We present a general class of exponential smoothed recurrent neural networks (RNNs) which are well suited to modeling non-stationary dynamical systems arising in industrial applications such as electricity load management and financial risk and trading. In particular, we analyze their capacity to characterize the non-linear partial autocorrelation structure of time series and directly capture dynamic effects such as seasonality and regime changes. Application of exponentially smoothed RNNs to electricity load forecasting, weather data and financial time series, such as minute level Bitcoin prices and CME futures tick data, highlight the efficacy of exponential smoothing for multi-step time series forecasting. The results also suggest that popular, but more complicated neural network architectures originally designed for speech processing, such as LSTMs and GRUs, are likely over-engineered for industrial forecasting and light-weight exponentially smoothed architectures capture the salient features while being superior and more robust than simple RNNs.
DENS-ECG: A Deep Learning Approach for ECG Signal Delineation
May 18, 2020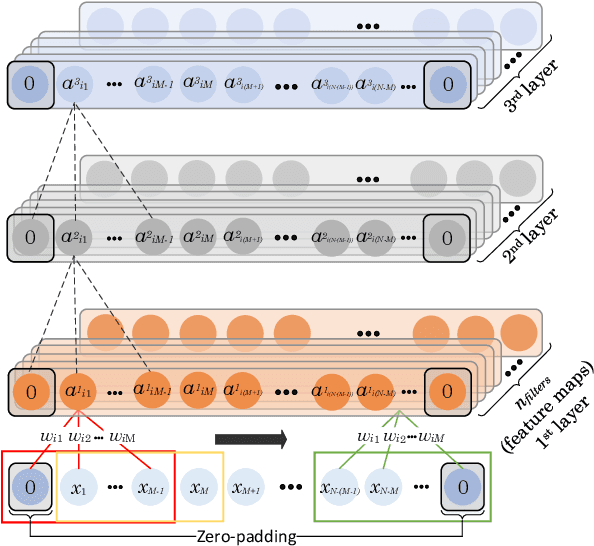

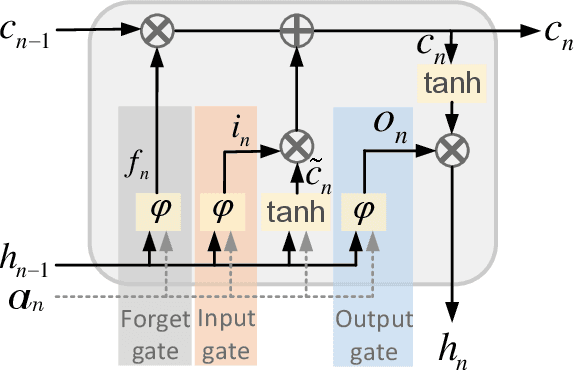
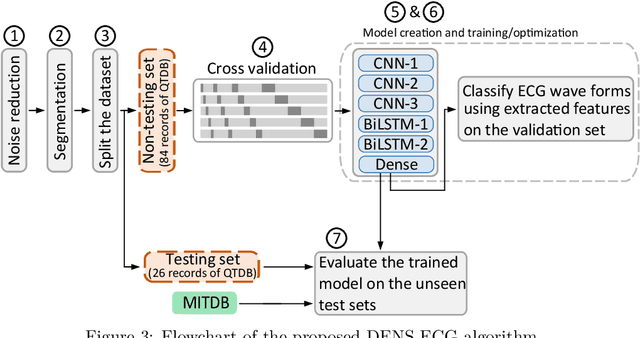
Objectives: With the technological advancements in the field of tele-health monitoring, it is now possible to gather huge amounts of electro-physiological signals such as electrocardiogram (ECG). It is therefore necessary to develop models/algorithms that are capable of analysing these massive amounts of data in real-time. This paper proposes a deep learning model for real-time segmentation of heartbeats. Methods: The proposed algorithm, named as the DENS-ECG algorithm, combines convolutional neural network (CNN) and long short-term memory (LSTM) model to detect onset, peak, and offset of different heartbeat waveforms such as the P-wave, QRS complex, T-wave, and No wave (NW). Using ECG as the inputs, the model learns to extract high level features through the training process, which, unlike other classical machine learning based methods, eliminates the feature engineering step. Results: The proposed DENS-ECG model was trained and validated on a dataset with 105 ECGs of length 15 minutes each and achieved an average sensitivity and precision of 97.95% and 95.68%, respectively, using a 5-fold cross validation. Additionally, the model was evaluated on an unseen dataset to examine its robustness in QRS detection, which resulted in a sensitivity of 99.61% and precision of 99.52%. Conclusion: The empirical results show the flexibility and accuracy of the combined CNN-LSTM model for ECG signal delineation. Significance: This paper proposes an efficient and easy to use approach using deep learning for heartbeat segmentation, which could potentially be used in real-time tele-health monitoring systems.
A Computationally Efficient Approach to Black-box Optimization using Gaussian Process Models
Oct 27, 2020
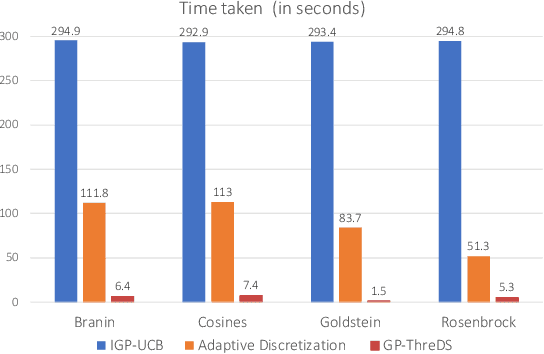
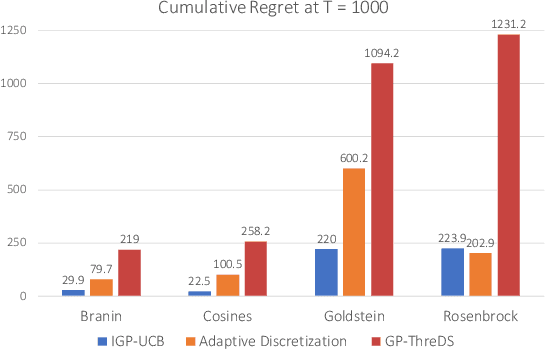
We consider the sequential optimization of an unknown function from noisy feedback using Gaussian process modeling. A prevailing approach to this problem involves choosing query points based on finding the maximum of an upper confidence bound (UCB) score over the entire domain of the function. Due to the multi-modal nature of the UCB, this maximization can only be approximated, usually using an increasingly fine sequence of discretizations of the entire domain, making such methods computationally prohibitive. We propose a general approach that reduces the computational complexity of this class of algorithms by a factor of $O(T^{2d-1})$ (where $T$ is the time horizon and $d$ the dimension of the function domain), while preserving the same regret order. The significant reduction in computational complexity results from two key features of the proposed approach: (i) a tree-based localized search strategy rooted in the methodology of domain shrinking to achieve increasing accuracy with a constant-size discretization; (ii) a localized optimization with the objective relaxed from a global maximizer to any point with value exceeding a given threshold, where the threshold is updated iteratively to approach the maximum as the search deepens. More succinctly, the proposed optimization strategy is a sequence of localized searches in the domain of the function guided by an iterative search in the range of the function to approach the maximum.
Planning to Chronicle
Nov 04, 2020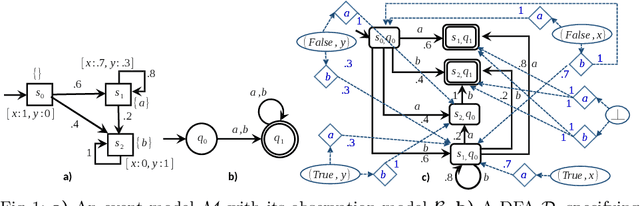
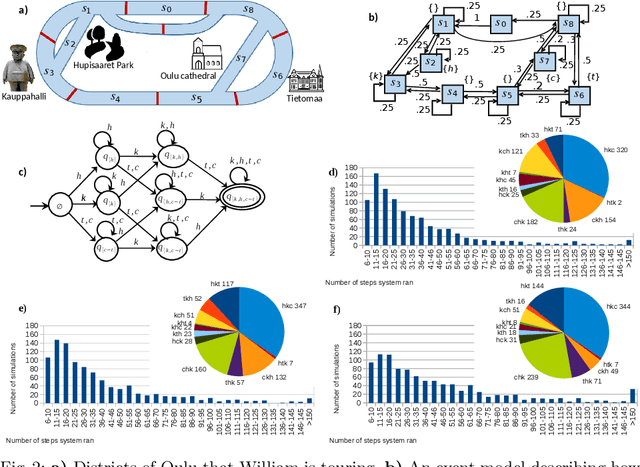
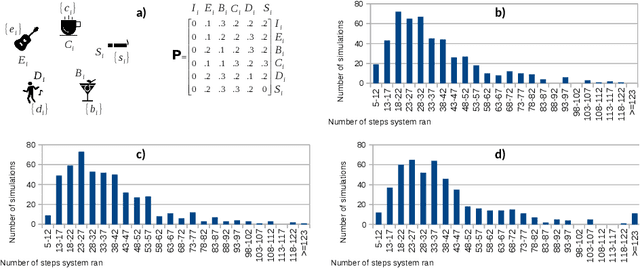
An important class of applications entails a robot monitoring, scrutinizing, or recording the evolution of an uncertain time-extended process. This sort of situation leads an interesting family of planning problems in which the robot is limited in what it sees and must, thus, choose what to pay attention to. The distinguishing characteristic of this setting is that the robot has influence over what it captures via its sensors, but exercises no causal authority over the evolving process. As such, the robot's objective is to observe the underlying process and to produce a `chronicle' of occurrent events, subject to a goal specification of the sorts of event sequences that may be of interest. This paper examines variants of such problems when the robot aims to collect sets of observations to meet a rich specification of their sequential structure. We study this class of problems by modeling a stochastic process via a variant of a hidden Markov model, and specify the event sequences of interest as a regular language, developing a vocabulary of `mutators' that enable sophisticated requirements to be expressed. Under different suppositions about the information gleaned about the Markov model, we formulate and solve different planning problems. The core underlying idea is the construction of a product between the event model and a specification automaton. The paper reports and compares performance metrics by drawing on some small case studies analyzed in depth in simulation.
Forecasting with sktime: Designing sktime's New Forecasting API and Applying It to Replicate and Extend the M4 Study
May 16, 2020
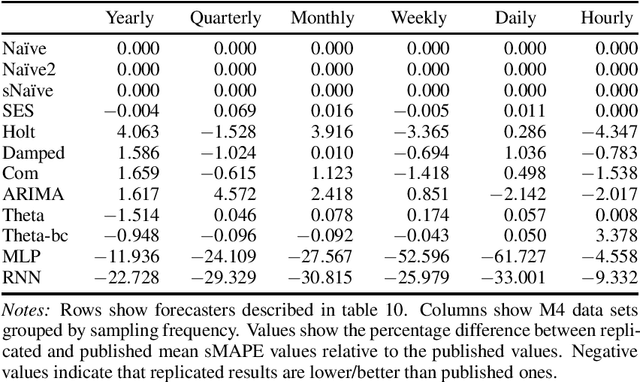
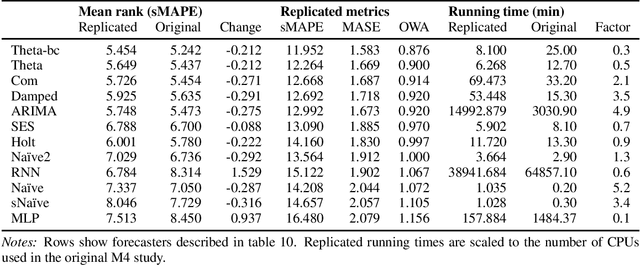

We present a new open-source framework for forecasting in Python. Our framework forms part of sktime, a machine learning toolbox with a unified interface for different time series learning tasks, like forecasting, but also time series classification and regression. We provide a dedicated forecasting interface, common statistical algorithms, and scikit-learn compatible tools for building composite machine learning models. We use sktime to both replicate key results from the M4 forecasting study and to extend it. sktime allows to easily build, tune and evaluate new models. We investigate the potential of common machine learning techniques for univariate forecasting, including reduction, boosting, ensembling, pipelining and tuning. We find that simple hybrid models can boost the performance of statistical models, and that pure machine learning models can achieve competitive forecasting performance on the hourly data sets, outperforming the statistical algorithms and coming close to the M4 winner model.
Exploiting the Nonlinear Stiffness of TMP Origami Folding to Enhance Robotic Jumping Performance
Oct 26, 2020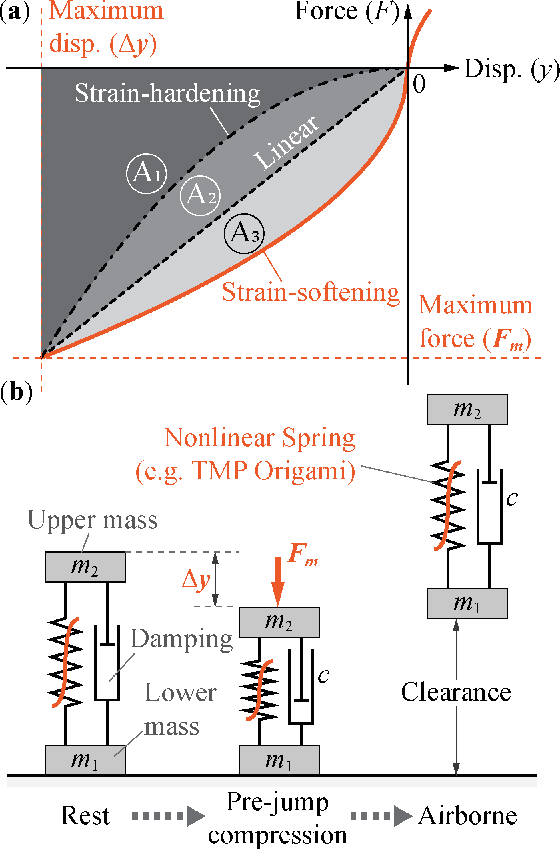

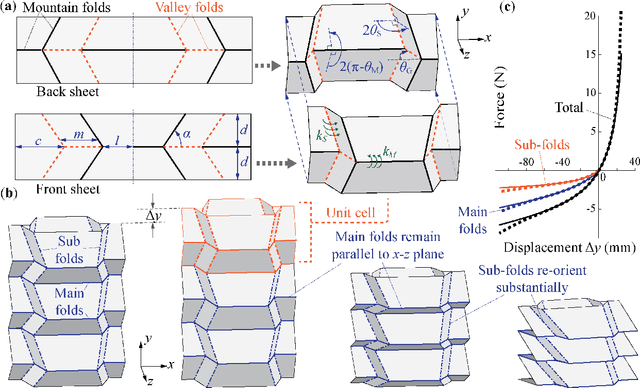

Via numerical simulation and experimental assessment, this study examines the use of origami folding to develop robotic jumping mechanisms with tailored nonlinear stiffness to improve dynamic performance. Specifically, we use Tachi-Miura Polyhedron (TMP) bellow origami -- which exhibits a nonlinear "strain-softening" force-displacement curve -- as a jumping robotic skeleton with embedded energy storage. TMP's nonlinear stiffness allows it to store more energy than a linear spring and offers improved jumping height and airtime. Moreover, the nonlinearity can be tailored by directly changing the underlying TMP crease geometry. A critical challenge is to minimize the TMP's hysteresis and energy loss during its compression stage right before jumping. So we used the plastically annealed lamina emergent origami (PALEO) concept to modify the TMP creases. PALEO increases the folding limit before plastic deformation occurs, thus improving the overall strain energy retention. Jumping experiments confirmed that a nonlinear TMP mechanism achieved roughly 9% improvement in air time and a 13% improvement in jumping height compared to a "control" TMP sample with a relatively linear stiffness. This study's results validate the advantages of using origami in robotic jumping mechanisms and demonstrate the benefits of utilizing nonlinear spring elements for improving jumping performance. Therefore, they could foster a new family of energetically efficient jumping mechanisms with optimized performance in the future.