 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
FSGS: Real-Time Few-shot View Synthesis using Gaussian Splatting
Dec 01, 2023
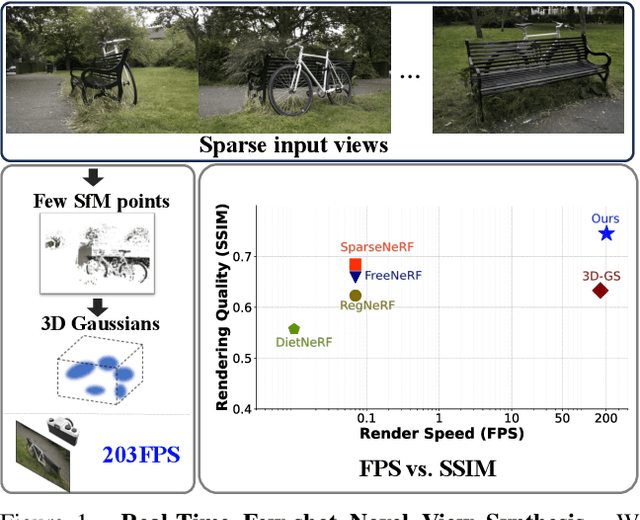
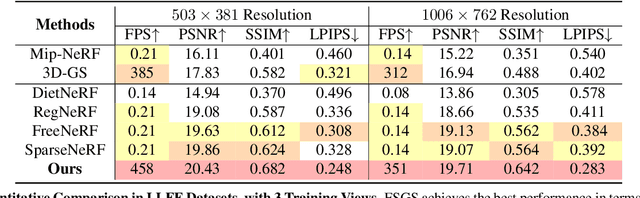
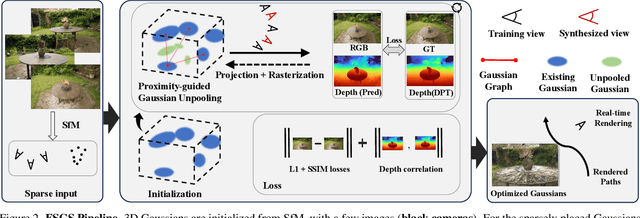
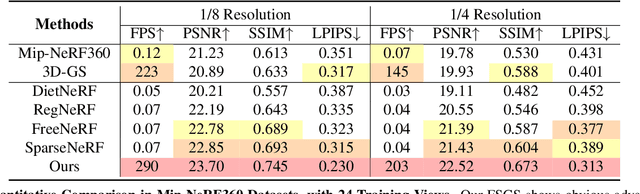
Novel view synthesis from limited observations remains an important and persistent task. However, high efficiency in existing NeRF-based few-shot view synthesis is often compromised to obtain an accurate 3D representation. To address this challenge, we propose a few-shot view synthesis framework based on 3D Gaussian Splatting that enables real-time and photo-realistic view synthesis with as few as three training views. The proposed method, dubbed FSGS, handles the extremely sparse initialized SfM points with a thoughtfully designed Gaussian Unpooling process. Our method iteratively distributes new Gaussians around the most representative locations, subsequently infilling local details in vacant areas. We also integrate a large-scale pre-trained monocular depth estimator within the Gaussians optimization process, leveraging online augmented views to guide the geometric optimization towards an optimal solution. Starting from sparse points observed from limited input viewpoints, our FSGS can accurately grow into unseen regions, comprehensively covering the scene and boosting the rendering quality of novel views. Overall, FSGS achieves state-of-the-art performance in both accuracy and rendering efficiency across diverse datasets, including LLFF, Mip-NeRF360, and Blender. Project website: https://zehaozhu.github.io/FSGS/.
Object Location Prediction in Real-time using LSTM Neural Network and Polynomial Regression
Nov 23, 2023This paper details the design and implementation of a system for predicting and interpolating object location coordinates. Our solution is based on processing inertial measurements and global positioning system data through a Long Short-Term Memory (LSTM) neural network and polynomial regression. LSTM is a type of recurrent neural network (RNN) particularly suited for processing data sequences and avoiding the long-term dependency problem. We employed data from real-world vehicles and the global positioning system (GPS) sensors. A critical pre-processing step was developed to address varying sensor frequencies and inconsistent GPS time steps and dropouts. The LSTM-based system's performance was compared with the Kalman Filter. The system was tuned to work in real-time with low latency and high precision. We tested our system on roads under various driving conditions, including acceleration, turns, deceleration, and straight paths. We tested our proposed solution's accuracy and inference time and showed that it could perform in real-time. Our LSTM-based system yielded an average error of 0.11 meters with an inference time of 2 ms. This represents a 76\% reduction in error compared to the traditional Kalman filter method, which has an average error of 0.46 meters with a similar inference time to the LSTM-based system.
A Generalization of the Convolution Theorem and its Connections to Non-Stationarity and the Graph Frequency Domain
Dec 28, 2023In this paper, we present a novel convolution theorem which encompasses the well known convolution theorem in (graph) signal processing as well as the one related to time-varying filters. Specifically, we show how a node-wise convolution for signals supported on a graph can be expressed as another node-wise convolution in a frequency domain graph, different from the original graph. This is achieved through a parameterization of the filter coefficients following a basis expansion model. After showing how the presented theorem is consistent with the already existing body of literature, we discuss its implications in terms of non-stationarity. Finally, we propose a data-driven algorithm based on subspace fitting to learn the frequency domain graph, which is then corroborated by experimental results on synthetic and real data.
Matching of Users and Creators in Two-Sided Markets with Departures
Dec 30, 2023Many online platforms of today, including social media sites, are two-sided markets bridging content creators and users. Most of the existing literature on platform recommendation algorithms largely focuses on user preferences and decisions, and does not simultaneously address creator incentives. We propose a model of content recommendation that explicitly focuses on the dynamics of user-content matching, with the novel property that both users and creators may leave the platform permanently if they do not experience sufficient engagement. In our model, each player decides to participate at each time step based on utilities derived from the current match: users based on alignment of the recommended content with their preferences, and creators based on their audience size. We show that a user-centric greedy algorithm that does not consider creator departures can result in arbitrarily poor total engagement, relative to an algorithm that maximizes total engagement while accounting for two-sided departures. Moreover, in stark contrast to the case where only users or only creators leave the platform, we prove that with two-sided departures, approximating maximum total engagement within any constant factor is NP-hard. We present two practical algorithms, one with performance guarantees under mild assumptions on user preferences, and another that tends to outperform algorithms that ignore two-sided departures in practice.
Contrastive learning-based agent modeling for deep reinforcement learning
Dec 30, 2023Multi-agent systems often require agents to collaborate with or compete against other agents with diverse goals, behaviors, or strategies. Agent modeling is essential when designing adaptive policies for intelligent machine agents in multiagent systems, as this is the means by which the ego agent understands other agents' behavior and extracts their meaningful policy representations. These representations can be used to enhance the ego agent's adaptive policy which is trained by reinforcement learning. However, existing agent modeling approaches typically assume the availability of local observations from other agents (modeled agents) during training or a long observation trajectory for policy adaption. To remove these constrictive assumptions and improve agent modeling performance, we devised a Contrastive Learning-based Agent Modeling (CLAM) method that relies only on the local observations from the ego agent during training and execution. With these observations, CLAM is capable of generating consistent high-quality policy representations in real-time right from the beginning of each episode. We evaluated the efficacy of our approach in both cooperative and competitive multi-agent environments. Our experiments demonstrate that our approach achieves state-of-the-art on both cooperative and competitive tasks, highlighting the potential of contrastive learning-based agent modeling for enhancing reinforcement learning.
GAN-GA: A Generative Model based on Genetic Algorithm for Medical Image Generation
Dec 30, 2023Medical imaging is an essential tool for diagnosing and treating diseases. However, lacking medical images can lead to inaccurate diagnoses and ineffective treatments. Generative models offer a promising solution for addressing medical image shortage problems due to their ability to generate new data from existing datasets and detect anomalies in this data. Data augmentation with position augmentation methods like scaling, cropping, flipping, padding, rotation, and translation could lead to more overfitting in domains with little data, such as medical image data. This paper proposes the GAN-GA, a generative model optimized by embedding a genetic algorithm. The proposed model enhances image fidelity and diversity while preserving distinctive features. The proposed medical image synthesis approach improves the quality and fidelity of medical images, an essential aspect of image interpretation. To evaluate synthesized images: Frechet Inception Distance (FID) is used. The proposed GAN-GA model is tested by generating Acute lymphoblastic leukemia (ALL) medical images, an image dataset, and is the first time to be used in generative models. Our results were compared to those of InfoGAN as a baseline model. The experimental results show that the proposed optimized GAN-GA enhances FID scores by about 6.8\%, especially in earlier training epochs. The source code and dataset will be available at: https://github.com/Mustafa-AbdulRazek/InfoGAN-GA.
* 10 pages, 2 figures. Abstract published in Frontiers in Medical Technology, presented at the 27th Conference on Medical Image Understanding and Analysis 2023. DOI: 10.3389/978-2-8325-1231-9. URL: https://doi.org/10.3389/978-2-8325-1231-9
Deep Generative Symbolic Regression
Dec 30, 2023Symbolic regression (SR) aims to discover concise closed-form mathematical equations from data, a task fundamental to scientific discovery. However, the problem is highly challenging because closed-form equations lie in a complex combinatorial search space. Existing methods, ranging from heuristic search to reinforcement learning, fail to scale with the number of input variables. We make the observation that closed-form equations often have structural characteristics and invariances (e.g., the commutative law) that could be further exploited to build more effective symbolic regression solutions. Motivated by this observation, our key contribution is to leverage pre-trained deep generative models to capture the intrinsic regularities of equations, thereby providing a solid foundation for subsequent optimization steps. We show that our novel formalism unifies several prominent approaches of symbolic regression and offers a new perspective to justify and improve on the previous ad hoc designs, such as the usage of cross-entropy loss during pre-training. Specifically, we propose an instantiation of our framework, Deep Generative Symbolic Regression (DGSR). In our experiments, we show that DGSR achieves a higher recovery rate of true equations in the setting of a larger number of input variables, and it is more computationally efficient at inference time than state-of-the-art RL symbolic regression solutions.
* In the proceedings of the Eleventh International Conference on Learning Representations (ICLR 2023). https://iclr.cc/virtual/2023/poster/11782
C2FAR: Coarse-to-Fine Autoregressive Networks for Precise Probabilistic Forecasting
Dec 22, 2023We present coarse-to-fine autoregressive networks (C2FAR), a method for modeling the probability distribution of univariate, numeric random variables. C2FAR generates a hierarchical, coarse-to-fine discretization of a variable autoregressively; progressively finer intervals of support are generated from a sequence of binned distributions, where each distribution is conditioned on previously-generated coarser intervals. Unlike prior (flat) binned distributions, C2FAR can represent values with exponentially higher precision, for only a linear increase in complexity. We use C2FAR for probabilistic forecasting via a recurrent neural network, thus modeling time series autoregressively in both space and time. C2FAR is the first method to simultaneously handle discrete and continuous series of arbitrary scale and distribution shape. This flexibility enables a variety of time series use cases, including anomaly detection, interpolation, and compression. C2FAR achieves improvements over the state-of-the-art on several benchmark forecasting datasets.
Simplicity bias, algorithmic probability, and the random logistic map
Dec 31, 2023Simplicity bias is an intriguing phenomenon prevalent in various input-output maps, characterized by a preference for simpler, more regular, or symmetric outputs. Notably, these maps typically feature high-probability outputs with simple patterns, whereas complex patterns are exponentially less probable. This bias has been extensively examined and attributed to principles derived from algorithmic information theory and algorithmic probability. In a significant advancement, it has been demonstrated that the renowned logistic map $x_{k+1}=\mu x_k(1-x_k)$, and other one-dimensional maps exhibit simplicity bias when conceptualized as input-output systems. Building upon this foundational work, our research delves into the manifestations of simplicity bias within the random logistic map, specifically focusing on scenarios involving additive noise. This investigation is driven by the overarching goal of formulating a comprehensive theory for the prediction and analysis of time series.Our primary contributions are multifaceted. We discover that simplicity bias is observable in the random logistic map for specific ranges of $\mu$ and noise magnitudes. Additionally, we find that this bias persists even with the introduction of small measurement noise, though it diminishes as noise levels increase. Our studies also revisit the phenomenon of noise-induced chaos, particularly when $\mu=3.83$, revealing its characteristics through complexity-probability plots. Intriguingly, we employ the logistic map to underscore a paradoxical aspect of data analysis: more data adhering to a consistent trend can occasionally lead to reduced confidence in extrapolation predictions, challenging conventional wisdom.We propose that adopting a probability-complexity perspective in analyzing dynamical systems could significantly enrich statistical learning theories related to series prediction.
AllSpark: a multimodal spatiotemporal general model
Dec 31, 2023For a long time, due to the high heterogeneity in structure and semantics among various spatiotemporal modal data, the joint interpretation of multimodal spatiotemporal data has been an extremely challenging problem. The primary challenge resides in striking a trade-off between the cohesion and autonomy of diverse modalities, and this trade-off exhibits a progressively nonlinear nature as the number of modalities expands. We introduce the Language as Reference Framework (LaRF), a fundamental principle for constructing a multimodal unified model, aiming to strike a trade-off between the cohesion and autonomy among different modalities. We propose a multimodal spatiotemporal general artificial intelligence model, called AllSpark. Our model integrates thirteen different modalities into a unified framework, including 1D (text, code), 2D (RGB, infrared, SAR, multispectral, hyperspectral, tables, graphs, trajectory, oblique photography), and 3D (point clouds, videos) modalities. To achieve modal cohesion, AllSpark uniformly maps diverse modal features to the language modality. In addition, we design modality-specific prompts to guide multi-modal large language models in accurately perceiving multimodal data. To maintain modality autonomy, AllSpark introduces modality-specific encoders to extract the tokens of various spatiotemporal modalities. And modal bridge is employed to achieve dimensional projection from each modality to the language modality. Finally, observing a gap between the model's interpretation and downstream tasks, we designed task heads to enhance the model's generalization capability on specific downstream tasks. Experiments indicate that AllSpark achieves competitive accuracy in modalities such as RGB and trajectory compared to state-of-the-art models.