 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Communicate to Learn at the Edge
Sep 28, 2020
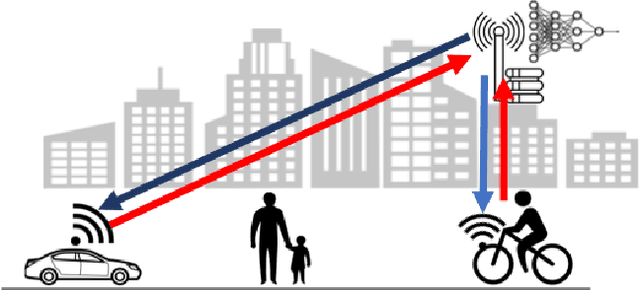
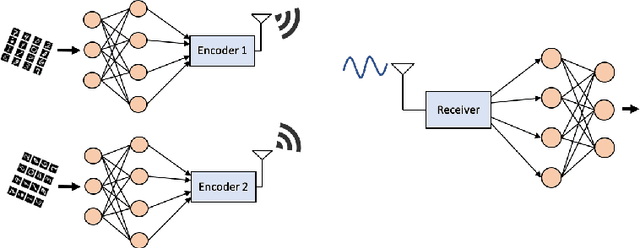
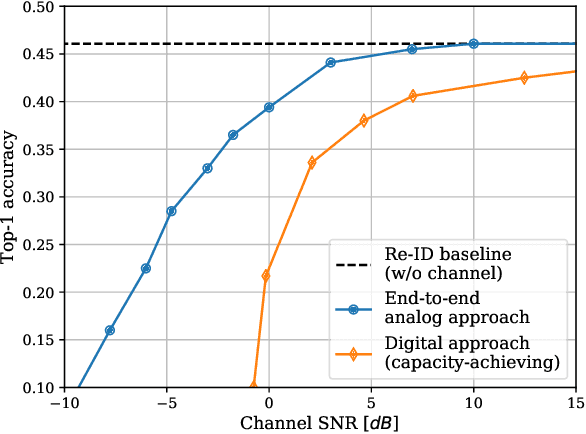
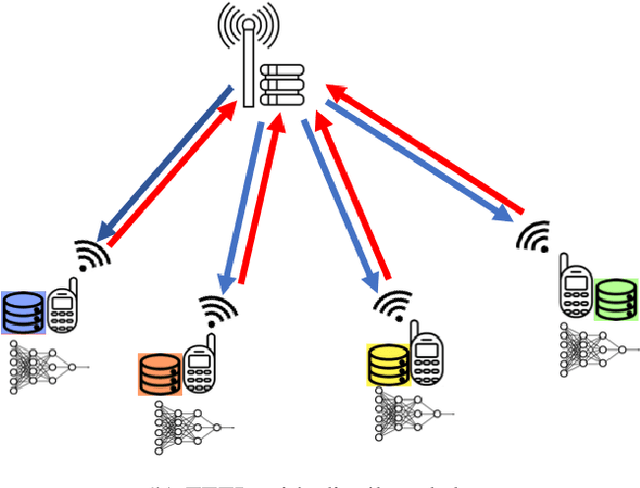
Bringing the success of modern machine learning (ML) techniques to mobile devices can enable many new services and businesses, but also poses significant technical and research challenges. Two factors that are critical for the success of ML algorithms are massive amounts of data and processing power, both of which are plentiful, yet highly distributed at the network edge. Moreover, edge devices are connected through bandwidth- and power-limited wireless links that suffer from noise, time-variations, and interference. Information and coding theory have laid the foundations of reliable and efficient communications in the presence of channel imperfections, whose application in modern wireless networks have been a tremendous success. However, there is a clear disconnect between the current coding and communication schemes, and the ML algorithms deployed at the network edge. In this paper, we challenge the current approach that treats these problems separately, and argue for a joint communication and learning paradigm for both the training and inference stages of edge learning.
DARE: AI-based Diver Action Recognition System using Multi-Channel CNNs for AUV Supervision
Nov 16, 2020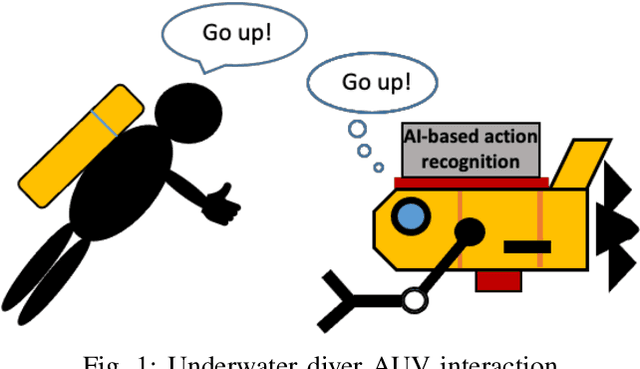
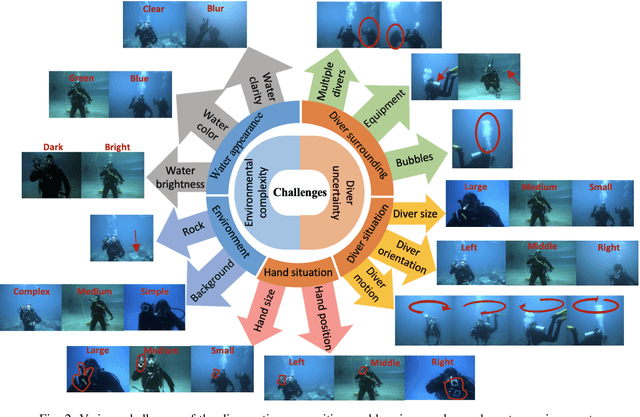
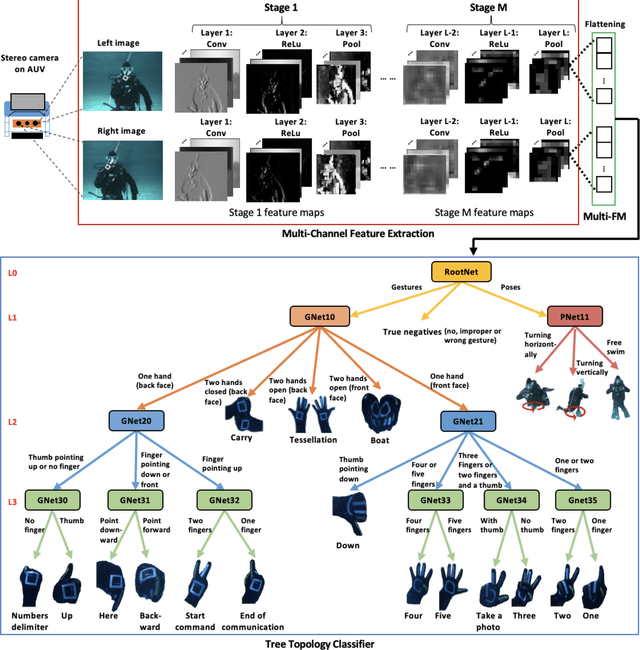

With the growth of sensing, control and robotic technologies, autonomous underwater vehicles (AUVs) have become useful assistants to human divers for performing various underwater operations. In the current practice, the divers are required to carry expensive, bulky, and waterproof keyboards or joystick-based controllers for supervision and control of AUVs. Therefore, diver action-based supervision is becoming increasingly popular because it is convenient, easier to use, faster, and cost effective. However, the various environmental, diver and sensing uncertainties present underwater makes it challenging to train a robust and reliable diver action recognition system. In this regard, this paper presents DARE, a diver action recognition system, that is trained based on Cognitive Autonomous Driving Buddy (CADDY) dataset, which is a rich set of data containing images of different diver gestures and poses in several different and realistic underwater environments. DARE is based on fusion of stereo-pairs of camera images using a multi-channel convolutional neural network supported with a systematically trained tree-topological deep neural network classifier to enhance the classification performance. DARE is fast and requires only a few milliseconds to classify one stereo-pair, thus making it suitable for real-time underwater implementation. DARE is comparatively evaluated against several existing classifier architectures and the results show that DARE supersedes the performance of all classifiers for diver action recognition in terms of overall as well as individual class accuracies and F1-scores.
Deep Hurdle Networks for Zero-Inflated Multi-Target Regression: Application to Multiple Species Abundance Estimation
Oct 30, 2020
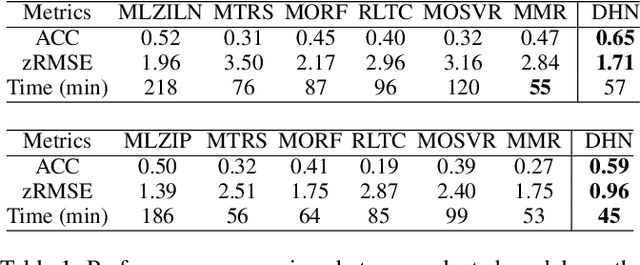
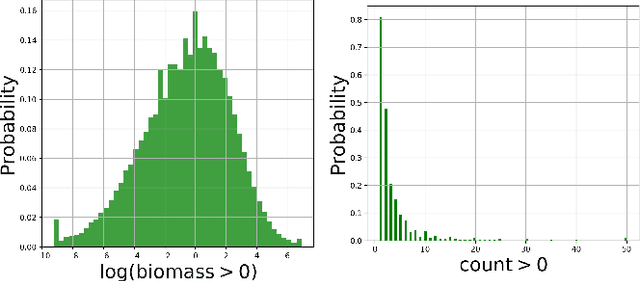
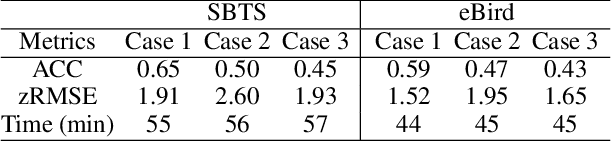
A key problem in computational sustainability is to understand the distribution of species across landscapes over time. This question gives rise to challenging large-scale prediction problems since (i) hundreds of species have to be simultaneously modeled and (ii) the survey data are usually inflated with zeros due to the absence of species for a large number of sites. The problem of tackling both issues simultaneously, which we refer to as the zero-inflated multi-target regression problem, has not been addressed by previous methods in statistics and machine learning. In this paper, we propose a novel deep model for the zero-inflated multi-target regression problem. To this end, we first model the joint distribution of multiple response variables as a multivariate probit model and then couple the positive outcomes with a multivariate log-normal distribution. By penalizing the difference between the two distributions' covariance matrices, a link between both distributions is established. The whole model is cast as an end-to-end learning framework and we provide an efficient learning algorithm for our model that can be fully implemented on GPUs. We show that our model outperforms the existing state-of-the-art baselines on two challenging real-world species distribution datasets concerning bird and fish populations.
Planar 3D Transfer Learning for End to End Unimodal MRI Unbalanced Data Segmentation
Nov 23, 2020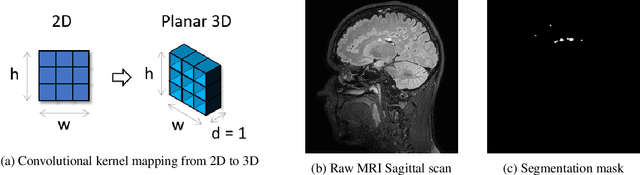
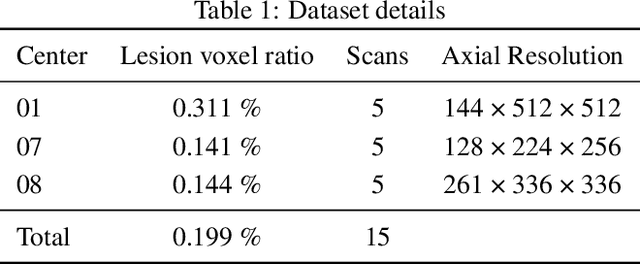
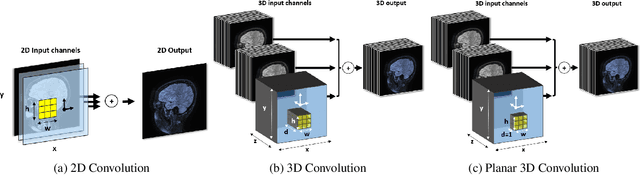

We present a novel approach of 2D to 3D transfer learning based on mapping pre-trained 2D convolutional neural network weights into planar 3D kernels. The method is validated by the proposed planar 3D res-u-net network with encoder transferred from the 2D VGG-16, which is applied for a single-stage unbalanced 3D image data segmentation. In particular, we evaluate the method on the MICCAI 2016 MS lesion segmentation challenge dataset utilizing solely fluid-attenuated inversion recovery (FLAIR) sequence without brain extraction for training and inference to simulate real medical praxis. The planar 3D res-u-net network performed the best both in sensitivity and Dice score amongst end to end methods processing raw MRI scans and achieved comparable Dice score to a state-of-the-art unimodal not end to end approach. Complete source code was released under the open-source license, and this paper complies with the Machine learning reproducibility checklist. By implementing practical transfer learning for 3D data representation, we could segment heavily unbalanced data without selective sampling and achieved more reliable results using less training data in a single modality. From a medical perspective, the unimodal approach gives an advantage in real praxis as it does not require co-registration nor additional scanning time during an examination. Although modern medical imaging methods capture high-resolution 3D anatomy scans suitable for computer-aided detection system processing, deployment of automatic systems for interpretation of radiology imaging is still rather theoretical in many medical areas. Our work aims to bridge the gap by offering a solution for partial research questions.
Scalable Synthesis of Minimum-Information Linear-Gaussian Control by Distributed Optimization
Apr 11, 2020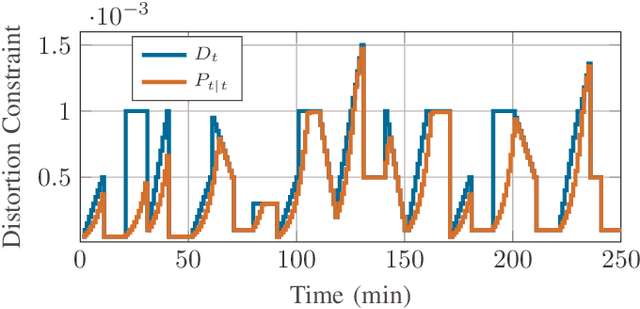
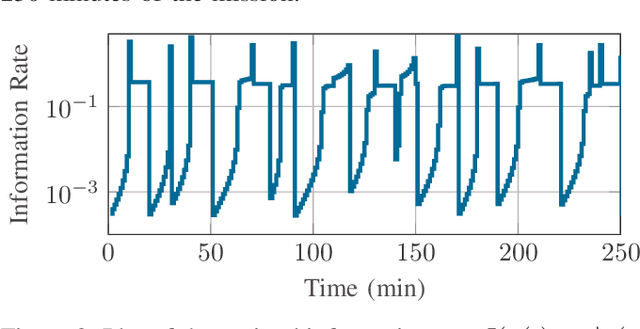
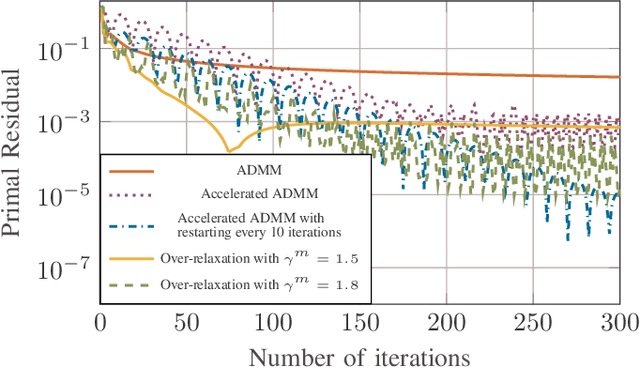
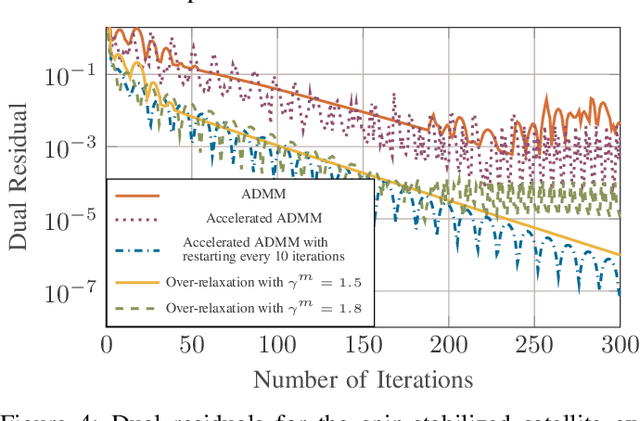
We consider a discrete-time linear-quadratic Gaussian control problem in which we minimize a weighted sum of the directed information from the state of the system to the control input and the control cost. The optimal control and sensing policies can be synthesized jointly by solving a semidefinite programming problem. However, the existing solutions typically scale cubic with the horizon length. We leverage the structure in the problem to develop a distributed algorithm that decomposes the synthesis problem into a set of smaller problems, one for each time step. We prove that the algorithm runs in time linear in the horizon length. As an application of the algorithm, we consider a path-planning problem in a state space with obstacles under the presence of stochastic disturbances. The algorithm computes a locally optimal solution that jointly minimizes the perception and control cost while ensuring the safety of the path. The numerical examples show that the algorithm can scale to thousands of horizon length and compute locally optimal solutions.
Generative Adversarial Simulator
Nov 23, 2020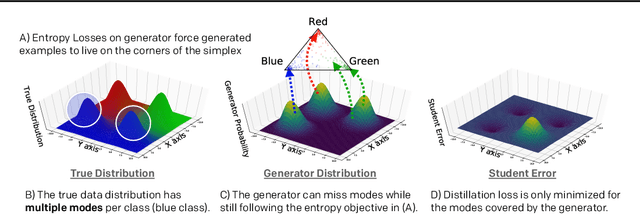
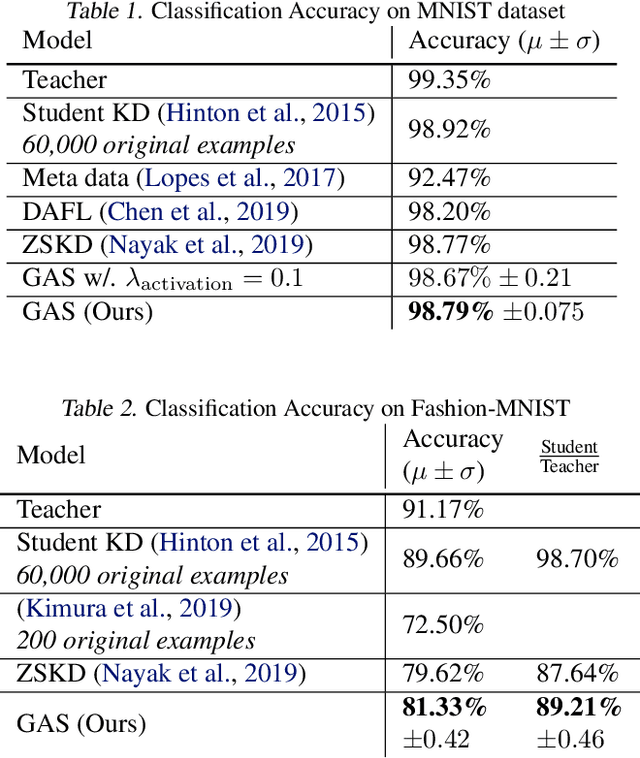
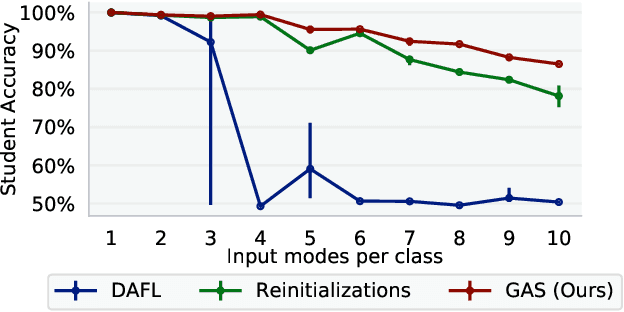
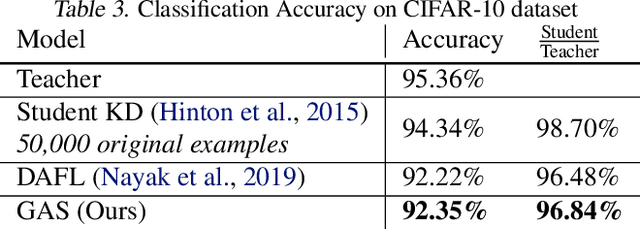
Knowledge distillation between machine learning models has opened many new avenues for parameter count reduction, performance improvements, or amortizing training time when changing architectures between the teacher and student network. In the case of reinforcement learning, this technique has also been applied to distill teacher policies to students. Until now, policy distillation required access to a simulator or real world trajectories. In this paper we introduce a simulator-free approach to knowledge distillation in the context of reinforcement learning. A key challenge is having the student learn the multiplicity of cases that correspond to a given action. While prior work has shown that data-free knowledge distillation is possible with supervised learning models by generating synthetic examples, these approaches to are vulnerable to only producing a single prototype example for each class. We propose an extension to explicitly handle multiple observations per output class that seeks to find as many exemplars as possible for a given output class by reinitializing our data generator and making use of an adversarial loss. To the best of our knowledge, this is the first demonstration of simulator-free knowledge distillation between a teacher and a student policy. This new approach improves over the state of the art on data-free learning of student networks on benchmark datasets (MNIST, Fashion-MNIST, CIFAR-10), and we also demonstrate that it specifically tackles issues with multiple input modes. We also identify open problems when distilling agents trained in high dimensional environments such as Pong, Breakout, or Seaquest.
POMO: Policy Optimization with Multiple Optima for Reinforcement Learning
Oct 30, 2020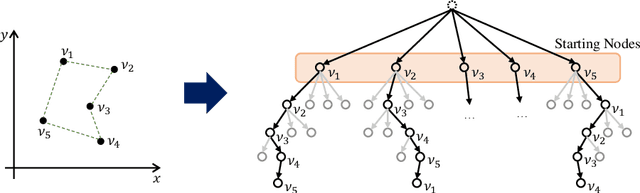

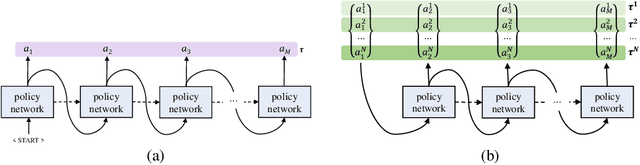
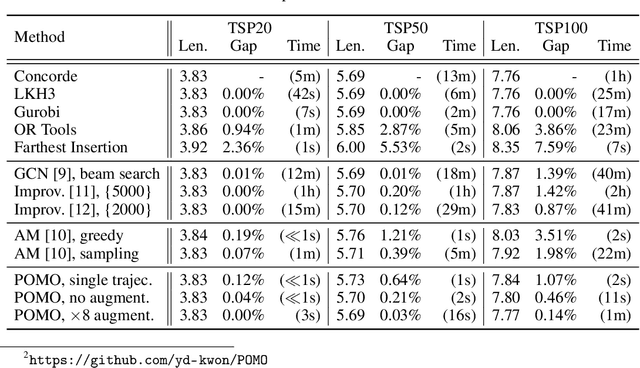
In neural combinatorial optimization (CO), reinforcement learning (RL) can turn a deep neural net into a fast, powerful heuristic solver of NP-hard problems. This approach has a great potential in practical applications because it allows near-optimal solutions to be found without expert guides armed with substantial domain knowledge. We introduce Policy Optimization with Multiple Optima (POMO), an end-to-end approach for building such a heuristic solver. POMO is applicable to a wide range of CO problems. It is designed to exploit the symmetries in the representation of a CO solution. POMO uses a modified REINFORCE algorithm that forces diverse rollouts towards all optimal solutions. Empirically, the low-variance baseline of POMO makes RL training fast and stable, and it is more resistant to local minima compared to previous approaches. We also introduce a new augmentation-based inference method, which accompanies POMO nicely. We demonstrate the effectiveness of POMO by solving three popular NP-hard problems, namely, traveling salesman (TSP), capacitated vehicle routing (CVRP), and 0-1 knapsack (KP). For all three, our solver based on POMO shows a significant improvement in performance over all recent learned heuristics. In particular, we achieve the optimality gap of 0.14% with TSP100 while reducing inference time by more than an order of magnitude.
Recurrent Neural Networks for Time Series Forecasting: Current Status and Future Directions
Sep 02, 2019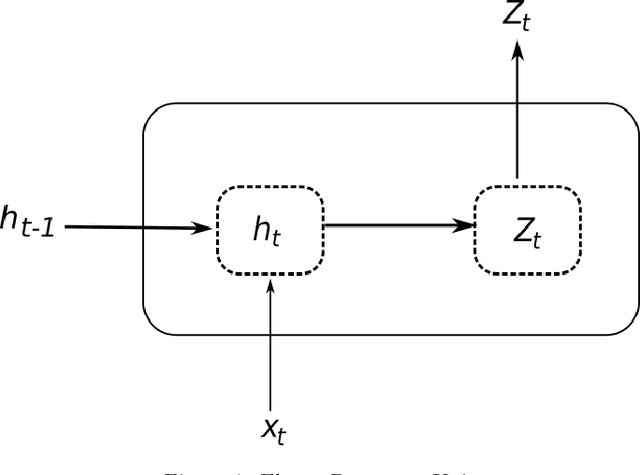

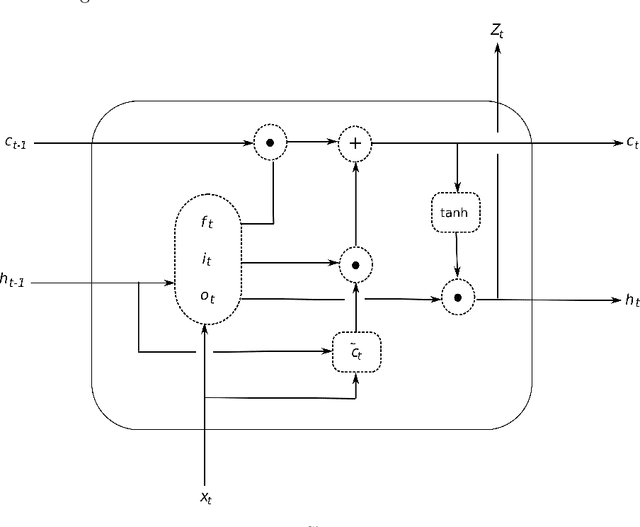

Recurrent Neural Networks (RNN) have become competitive forecasting methods, as most notably shown in the winning method of the recent M4 competition. However, established statistical models such as ETS and ARIMA gain their popularity not only from their high accuracy, but they are also suitable for non-expert users as they are robust, efficient, and automatic. In these areas, RNNs have still a long way to go. We present an extensive empirical study and an open-source software framework of existing RNN architectures for forecasting, that allow us to develop guidelines and best practices for their use. For example, we conclude that RNNs are capable of modelling seasonality directly if the series in the dataset possess homogeneous seasonal patterns, otherwise we recommend a deseasonalization step. Comparisons against ETS and ARIMA demonstrate that the implemented (semi-)automatic RNN models are no silver bullets, but they are competitive alternatives in many situations.
Identification of deep breath while moving forward based on multiple body regions and graph signal analysis
Oct 20, 2020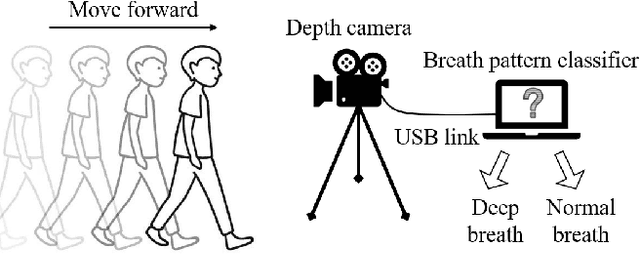
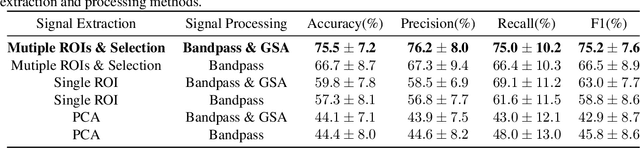
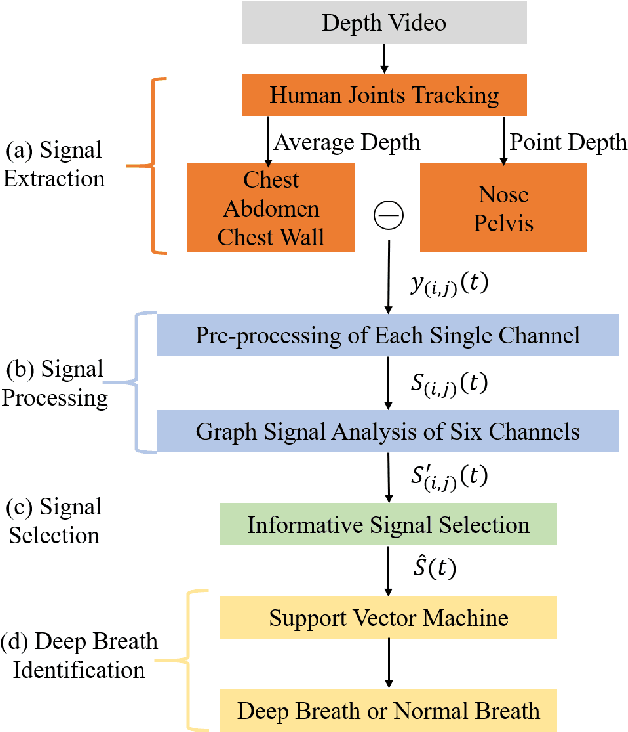
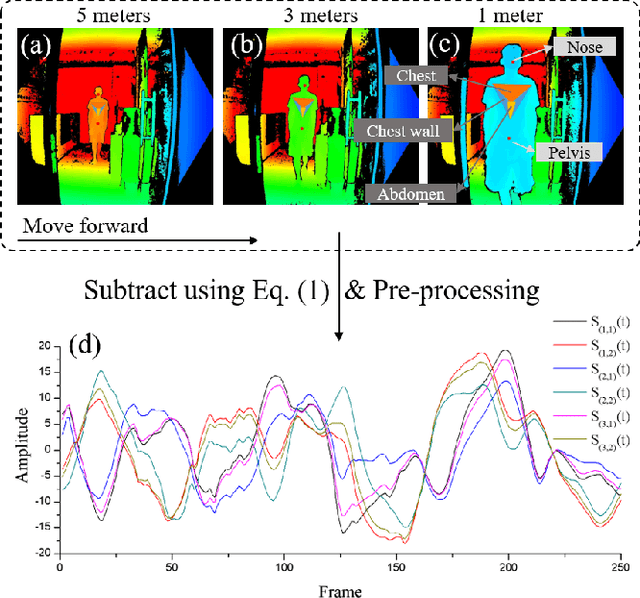
This paper presents an unobtrusive solution that can automatically identify deep breath when a person is walking past the global depth camera. Existing non-contact breath assessments achieve satisfactory results under restricted conditions when human body stays relatively still. When someone moves forward, the breath signals detected by depth camera are hidden within signals of trunk displacement and deformation, and the signal length is short due to the short stay time, posing great challenges for us to establish models. To overcome these challenges, multiple region of interests (ROIs) based signal extraction and selection method is proposed to automatically obtain the signal informative to breath from depth video. Subsequently, graph signal analysis (GSA) is adopted as a spatial-temporal filter to wipe the components unrelated to breath. Finally, a classifier for identifying deep breath is established based on the selected breath-informative signal. In validation experiments, the proposed approach outperforms the comparative methods with the accuracy, precision, recall and F1 of 75.5%, 76.2%, 75.0% and 75.2%, respectively. This system can be extended to public places to provide timely and ubiquitous help for those who may have or are going through physical or mental trouble.
Behavioral analysis of support vector machine classifier with Gaussian kernel and imbalanced data
Jul 09, 2020

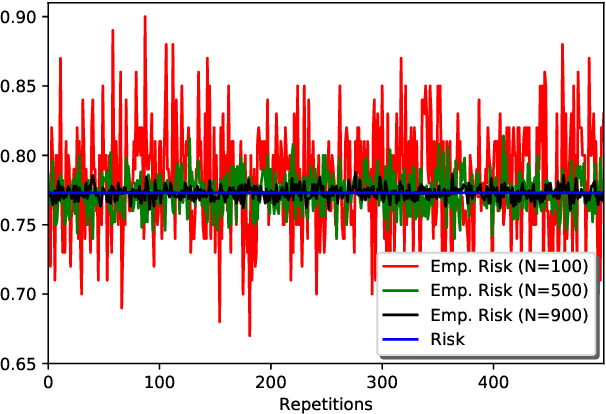
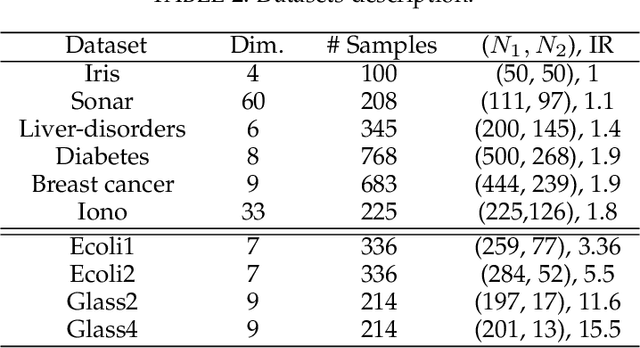
The parameters of support vector machines (SVMs) such as the penalty parameter and the kernel parameters have a great impact on the classification accuracy and the complexity of the SVM model. Therefore, the model selection in SVM involves the tuning of these parameters. However, these parameters are usually tuned and used as a black box, without understanding the mathematical background or internal details. In this paper, the behavior of the SVM classification model is analyzed when these parameters take different values with balanced and imbalanced data. This analysis including visualization, mathematical and geometrical interpretations and illustrative numerical examples with the aim of providing the basics of the Gaussian and linear kernel functions with SVM. From this analysis, we proposed a novel search algorithm. In this algorithm, we search for the optimal SVM parameters into two one-dimensional spaces instead of searching into one two-dimensional space. This reduces the computational time significantly. Moreover, in our algorithm, from the analysis of the data, the range of kernel function can be expected. This also reduces the search space and hence reduces the required computational time. Different experiments were conducted to evaluate our search algorithm using different balanced and imbalanced datasets. The results demonstrated how the proposed strategy is fast and effective than other searching strategies.