 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Is the space complexity of planted clique recovery the same as that of detection?
Aug 28, 2020
We study the planted clique problem in which a clique of size k is planted in an Erd\H{o}s-R\'enyi graph G(n, 1/2), and one is interested in either detecting or recovering this planted clique. This problem is interesting because it is widely believed to show a statistical-computational gap at clique size k=sqrt{n}, and has emerged as the prototypical problem with such a gap from which average-case hardness of other statistical problems can be deduced. It also displays a tight computational connection between the detection and recovery variants, unlike other problems of a similar nature. This wide investigation into the computational complexity of the planted clique problem has, however, mostly focused on its time complexity. In this work, we ask- Do the statistical-computational phenomena that make the planted clique an interesting problem also hold when we use `space efficiency' as our notion of computational efficiency? It is relatively easy to show that a positive answer to this question depends on the existence of a O(log n) space algorithm that can recover planted cliques of size k = Omega(sqrt{n}). Our main result comes very close to designing such an algorithm. We show that for k=Omega(sqrt{n}), the recovery problem can be solved in O((log*{n}-log*{k/sqrt{n}}) log n) bits of space. 1. If k = omega(sqrt{n}log^{(l)}n) for any constant integer l > 0, the space usage is O(log n) bits. 2.If k = Theta(sqrt{n}), the space usage is O(log*{n} log n) bits. Our result suggests that there does exist an O(log n) space algorithm to recover cliques of size k = Omega(sqrt{n}), since we come very close to achieving such parameters. This provides evidence that the statistical-computational phenomena that (conjecturally) hold for planted clique time complexity also (conjecturally) hold for space complexity.
Optimal estimates for short horizon travel time prediction in urban areas
Aug 10, 2015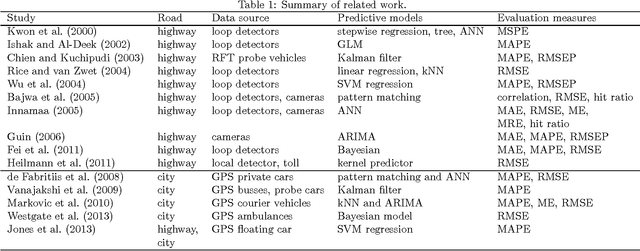
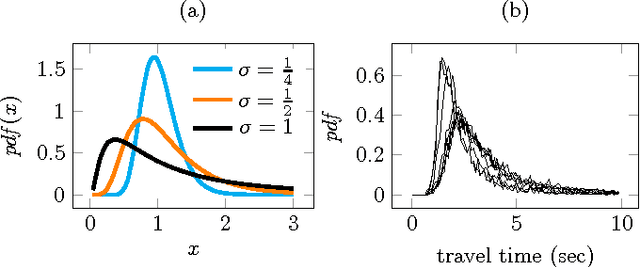
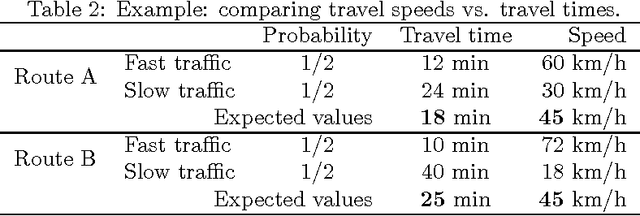
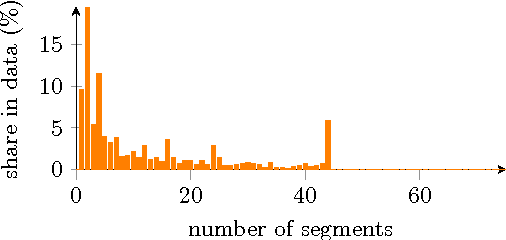
Increasing popularity of mobile route planning applications based on GPS technology provides opportunities for collecting traffic data in urban environments. One of the main challenges for travel time estimation and prediction in such a setting is how to aggregate data from vehicles that have followed different routes, and predict travel time for other routes of interest. One approach is to predict travel times for route segments, and sum those estimates to obtain a prediction for the whole route. We study how to obtain optimal predictions in this scenario. It appears that the optimal estimate, minimizing the expected mean absolute error, is a combination of the mean and the median travel times on each segment, where the combination function depends on the number of segments in the route of interest. We present a methodology for obtaining such predictions, and demonstrate its effectiveness with a case study using travel time data from a district of St. Petersburg collected over one year. The proposed methodology can be applied for real-time prediction of expected travel times in an urban road network.
Learning by Repetition: Stochastic Multi-armed Bandits under Priming Effect
Jun 18, 2020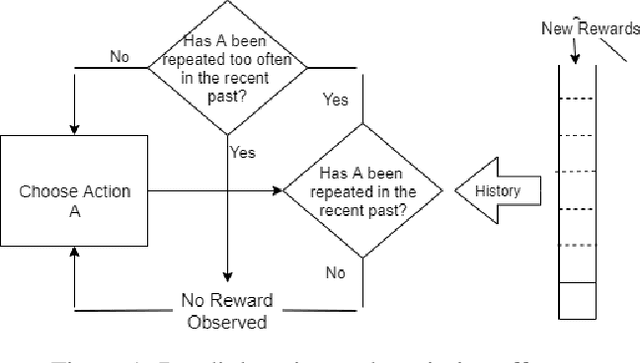

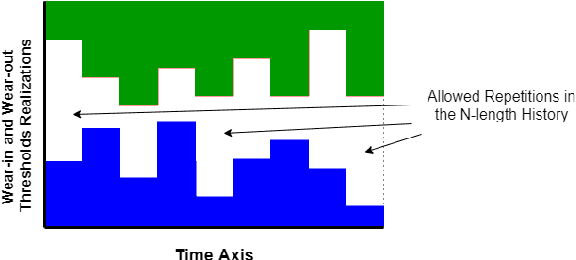
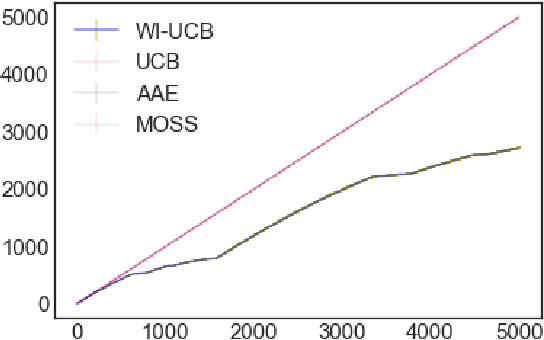
We study the effect of persistence of engagement on learning in a stochastic multi-armed bandit setting. In advertising and recommendation systems, repetition effect includes a wear-in period, where the user's propensity to reward the platform via a click or purchase depends on how frequently they see the recommendation in the recent past. It also includes a counteracting wear-out period, where the user's propensity to respond positively is dampened if the recommendation was shown too many times recently. Priming effect can be naturally modelled as a temporal constraint on the strategy space, since the reward for the current action depends on historical actions taken by the platform. We provide novel algorithms that achieves sublinear regret in time and the relevant wear-in/wear-out parameters. The effect of priming on the regret upper bound is also additive, and we get back a guarantee that matches popular algorithms such as the UCB1 and Thompson sampling when there is no priming effect. Our work complements recent work on modeling time varying rewards, delays and corruptions in bandits, and extends the usage of rich behavior models in sequential decision making settings.
Large-Scale Cargo Distribution
Sep 29, 2020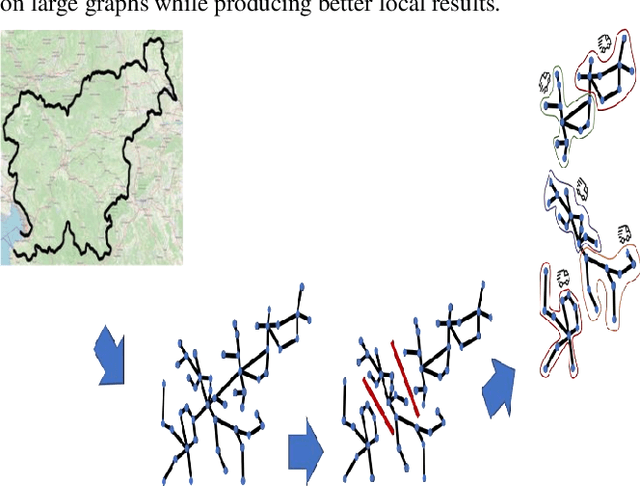
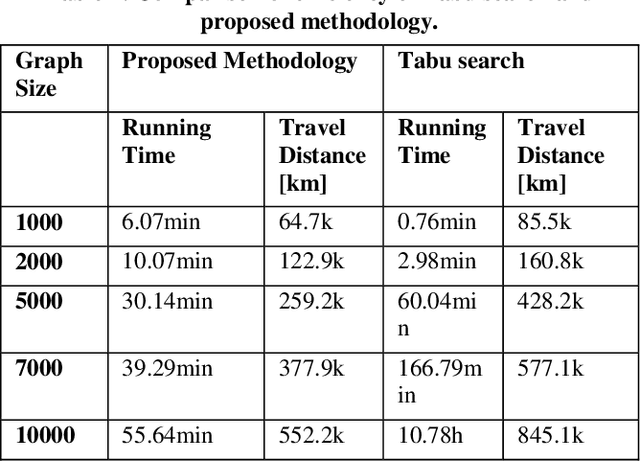
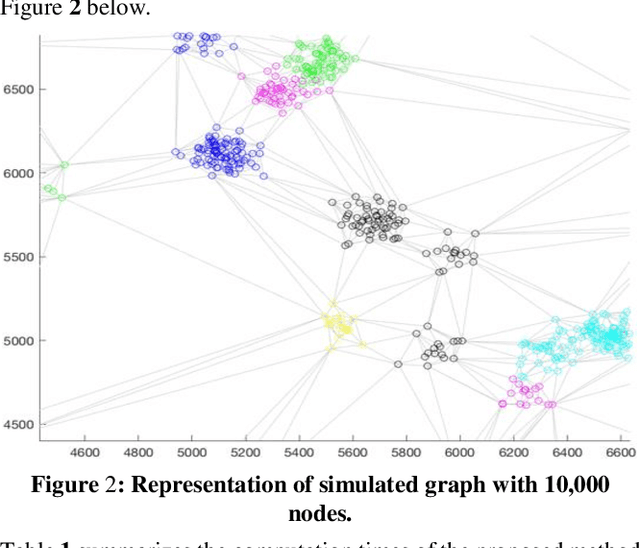

This study focuses on the design and development of methods for generating cargo distribution plans for large-scale logistics networks. It uses data from three large logistics operators while focusing on cross border logistics operations using one large graph. The approach uses a three-step methodology to first represent the logistic infrastructure as a graph, then partition the graph into smaller size regions, and finally generate cargo distribution plans for each individual region. The initial graph representation has been extracted from regional graphs by spectral clustering and is then further used for computing the distribution plan. The approach introduces methods for each of the modelling steps. The proposed approach on using regionalization of large logistics infrastructure for generating partial plans, enables scaling to thousands of drop-off locations. Results also show that the proposed approach scales better than the state-of-the-art, while preserving the quality of the solution. Our methodology is suited to address the main challenge in transforming rigid large logistics infrastructure into dynamic, just-in-time, and point-to-point delivery-oriented logistics operations.
Towards Full-line Code Completion with Neural Language Models
Sep 18, 2020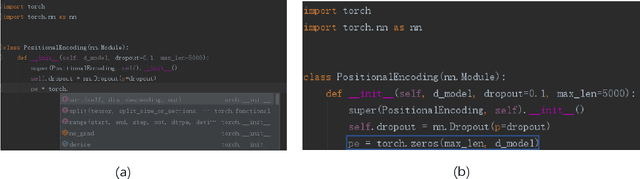



A code completion system suggests future code elements to developers given a partially-complete code snippet. Code completion is one of the most useful features in Integrated Development Environments (IDEs). Currently, most code completion techniques predict a single token at a time. In this paper, we take a further step and discuss the probability of directly completing a whole line of code instead of a single token. We believe suggesting longer code sequences can further improve the efficiency of developers. Recently neural language models have been adopted as a preferred approach for code completion, and we believe these models can still be applied to full-line code completion with a few improvements. We conduct our experiments on two real-world python corpora and evaluate existing neural models based on source code tokens or syntactical actions. The results show that neural language models can achieve acceptable results on our tasks, with significant room for improvements.
Online learning of both state and dynamics using ensemble Kalman filters
Jun 06, 2020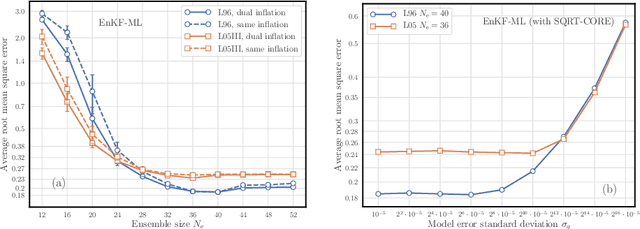
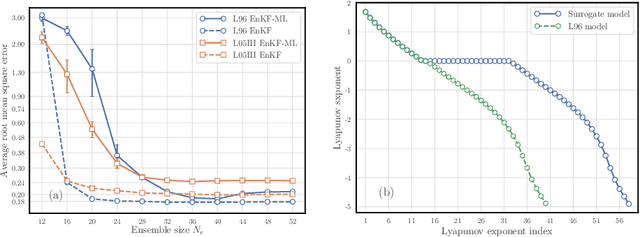
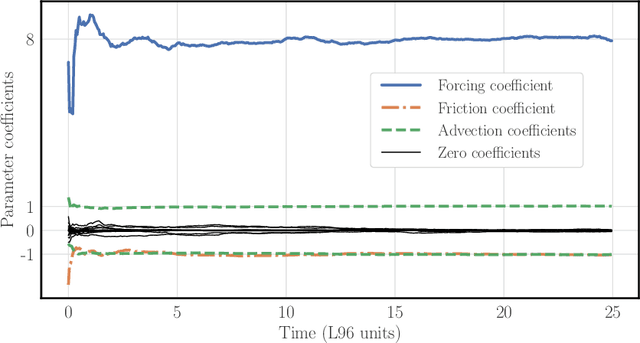
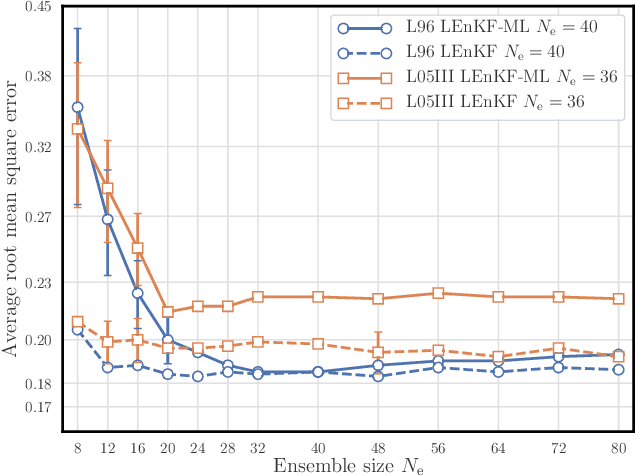
The reconstruction of the dynamics of an observed physical system as a surrogate model has been brought to the fore by recent advances in machine learning. To deal with partial and noisy observations in that endeavor, machine learning representations of the surrogate model can be used within a Bayesian data assimilation framework. However, these approaches require to consider long time series of observational data, meant to be assimilated all together. This paper investigates the possibility to learn both the dynamics and the state online, i.e. to update their estimates at any time, in particular when new observations are acquired. The estimation is based on the ensemble Kalman filter (EnKF) family of algorithms using a rather simple representation for the surrogate model and state augmentation. We consider the implication of learning dynamics online through (i) a global EnKF, (i) a local EnKF and (iii) an iterative EnKF and we discuss in each case issues and algorithmic solutions. We then demonstrate numerically the efficiency and assess the accuracy of these methods using one-dimensional, one-scale and two-scale chaotic Lorenz models.
Semi-Autonomous Teleoperation of Mobile Manipulators for Safely and Efficiently Executing Machine Tending Tasks Human-Supervised Semi-Autonomous Mobile Manipulators for Safely and Efficiently Executing Machine Tending Tasks
Oct 10, 2020
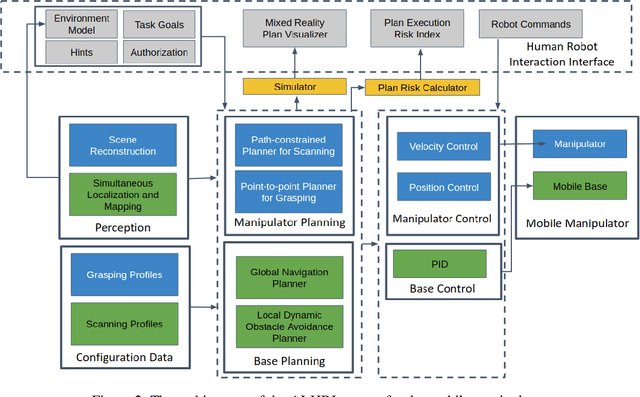
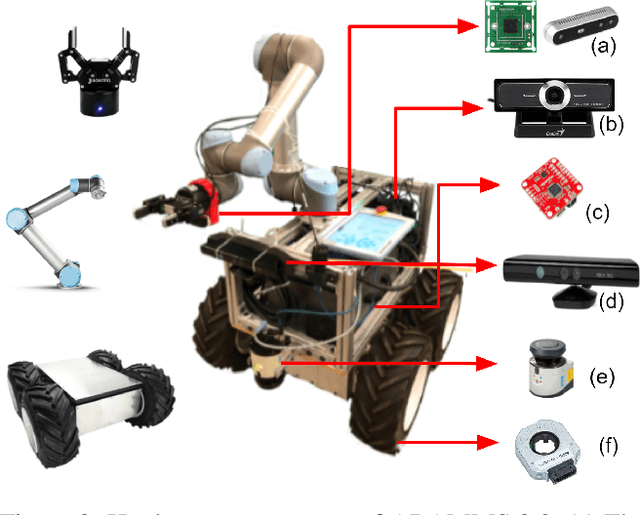
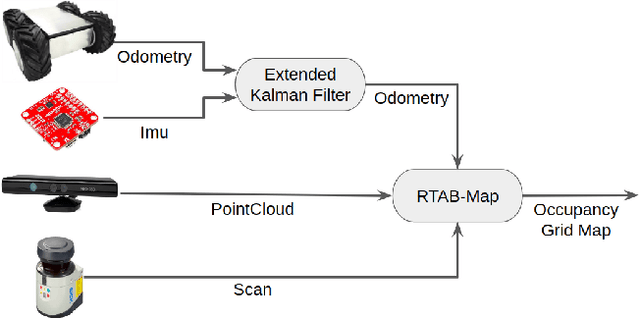
Mobile manipulators can be used for machine tending and material handling tasks in small volume manufacturing applications. These applications usually have semi-structured work environment. The use of a fully autonomous mobile manipulator for such applications can be risky, as an inaccurate model of the workspace may result in damage to expensive equipment. On the other hand, the use of a fully teleoperated mobile manipulator may require a significant amount of operator time. In this paper, a semi-autonomous mobile manipulator is developed for safely and efficiently carrying out machine tending tasks under human supervision. The robot is capable of generating motion plans from the high-level task description and presenting simulation results to the human for approval. The human operator can authorize the robot to execute the automatically generated plan or provide additional input to the planner to refine the plan. If the level of uncertainty in some parts of the workspace model is high, then the human can decide to perform teleoperation to safely execute the task. Our preliminary user trials show that non-expert operators can quickly learn to use the system and perform machine tending tasks.
Variational Autoencoder for Anti-Cancer Drug Response Prediction
Sep 29, 2020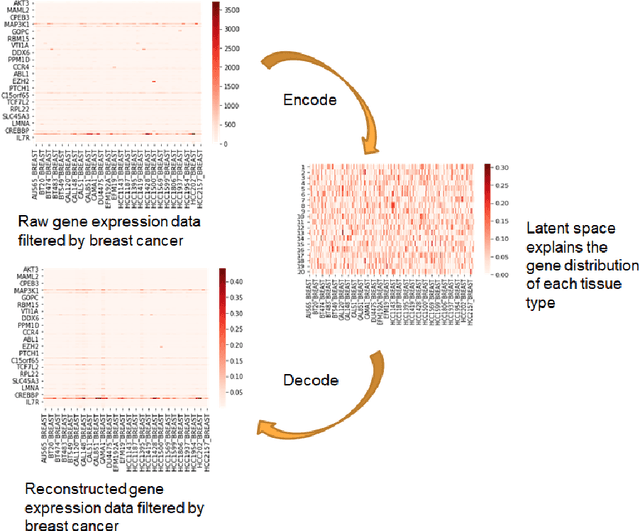
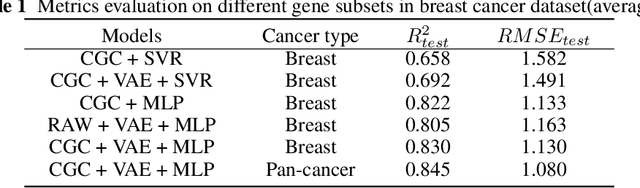
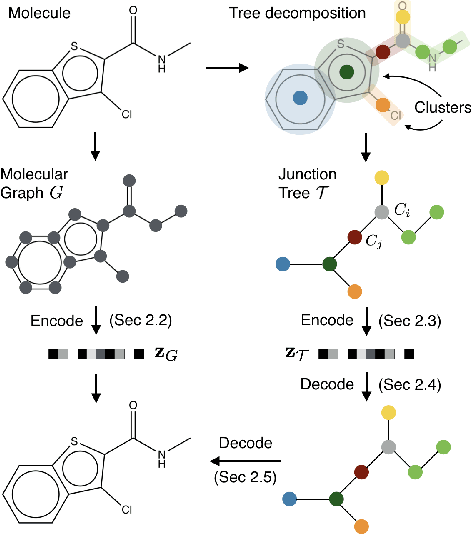
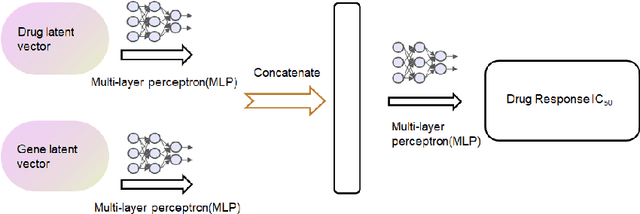
Cancer has long been a main cause of human death, and the discovery of new drugs and the customization of cancer therapy have puzzled people for a long time. In order to facilitate the discovery of new anti-cancer drugs and the customization of treatment strategy, we seek to predict the response of different anti-cancer drugs with variational autoencoders (VAE) and multi-layer perceptron (MLP).Our model takes as input gene expression data of cancer cell lines and anti-cancer drug molecular data, and encode these data with {\sc {GeneVae}} model, which is an ordinary VAE, and rectified junction tree variational autoencoder ({\sc JtVae}) (\cite{jin2018junction}) model, respectively. Encoded features are processes by a Multi-layer Perceptron (MLP) model to produce a final prediction. We reach an average coefficient of determination ($R^{2} = 0.83$) in predicting drug response on breast cancer cell lines and an average $R^{2} > 0.84$ on pan-cancer cell lines. Additionally, we show that our model can generate unseen effective drug compounds for specific cancer cell lines.
Dynamic Nonparametric Edge-Clustering Model for Time-Evolving Sparse Networks
May 28, 2019
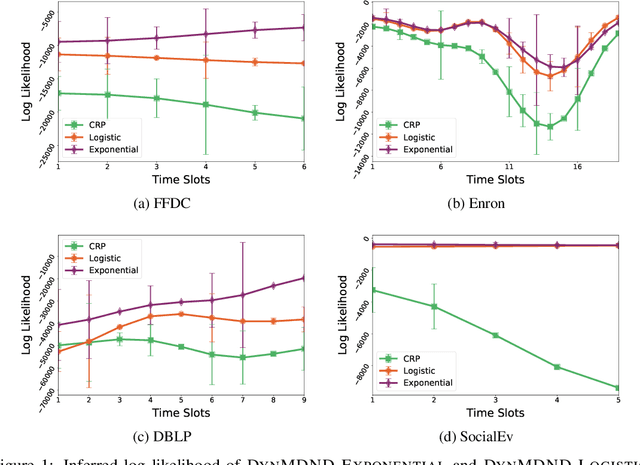
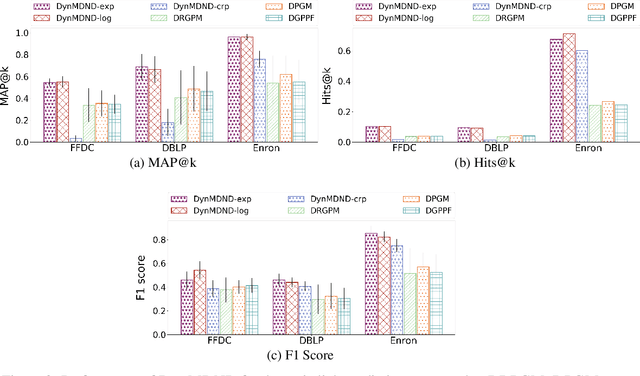
Interaction graphs, such as those recording emails between individuals or transactions between institutions, tend to be sparse yet structured, and often grow in an unbounded manner. Such behavior can be well-captured by structured, nonparametric edge-exchangeable graphs. However, such exchangeable models necessarily ignore temporal dynamics in the network. We propose a dynamic nonparametric model for interaction graphs that combine the sparsity of the exchangeable models with dynamic clustering patterns that tend to reinforce recent behavioral patterns. We show that our method yields improved held-out likelihood over stationary variants, and impressive predictive performance against a range of state-of-the-art dynamic interaction graph models.
Privacy Preserving Set-Based Estimation Using Partially Homomorphic Encryption
Oct 19, 2020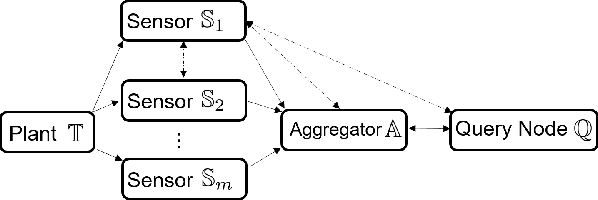
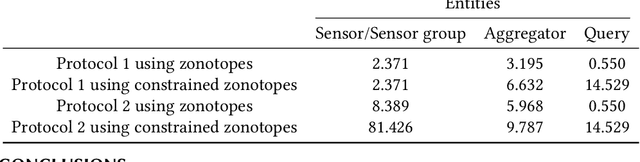
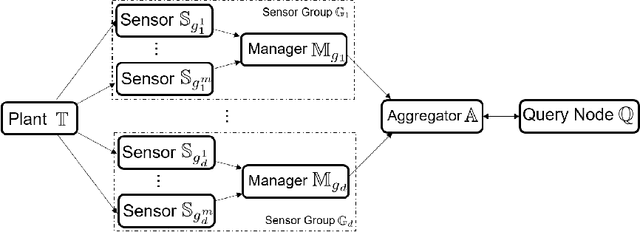
Set-based estimation has gained a lot of attention due to its ability to guarantee state enclosures for safety-critical systems. However, it requires computationally expensive operations, which in turn often requires outsourcing of these operations to cloud-computing platforms. Consequently, this raises some concerns with regard to sharing sensitive information and measurements. This paper presents the first privacy-preserving set-based estimation protocols using partially homomorphic encryption in which we preserve the privacy of the set of all possible estimates and the measurements. We consider a linear discrete-time dynamical system with bounded modeling and measurement uncertainties without any other statistical assumptions. We represent sets by zonotopes and constrained zonotopes as they can compactly represent high-dimensional sets and are closed under linear maps and Minkowski addition. By selectively encrypting some parameters of the used set representations, we are able to intersect sets in the encrypted domain, which enables guaranteed state estimation while ensuring the privacy goals. In particular, we show that our protocols achieve computational privacy using formal cryptographic definitions of computational indistinguishability. We demonstrate the efficiency of our approach by localizing a mobile quadcopter using custom ultra-wideband wireless devices. Our code and data are available online.