 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multi-Task Temporal Shift Attention Networks for On-Device Contactless Vitals Measurement
Jun 06, 2020
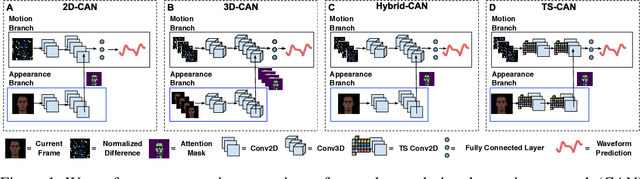
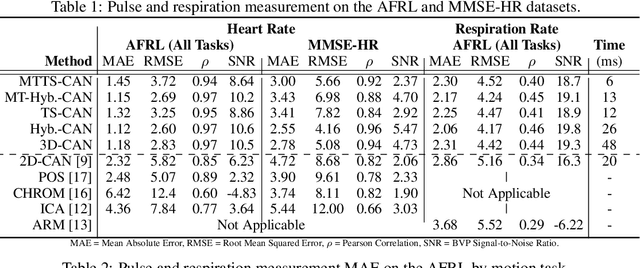
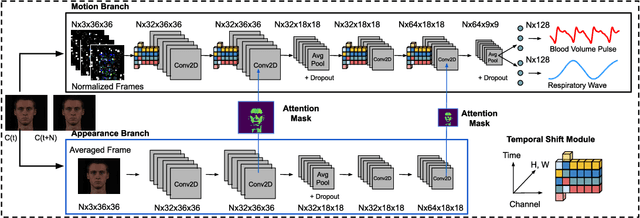
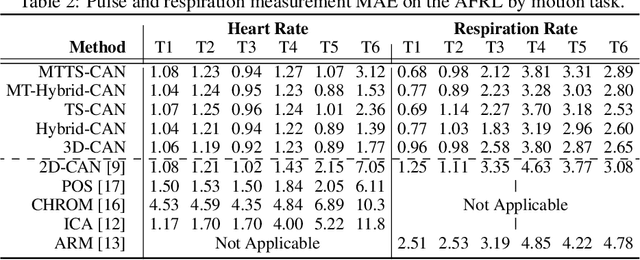
Telehealth and remote health monitoring have become increasingly important during the SARS-CoV-2 pandemic and it is widely expected that this will have a lasting impact on healthcare practices. These tools can help reduce the risk of exposing patients and medical staff to infection, make healthcare services more accessible, and allow providers to see more patients. However, objective measurement of vital signs is challenging without direct contact with a patient. We present a video-based and on-device optical cardiopulmonary vital sign measurement approach. It leverages a novel multi-task temporal shift convolutional attention network (MTTS-CAN) and enables real-time cardiovascular and respiratory measurements on mobile platforms. We evaluate our system on an ARM CPU and achieve state-of-the-art accuracy while running at over 150 frames per second which enables real-time applications. Systematic experimentation on large benchmark datasets reveals that our approach leads to substantial (20%-50%) reductions in error and generalizes well across datasets.
Posterior Sampling for Anytime Motion Planning on Graphs with Expensive-to-Evaluate Edges
Mar 20, 2020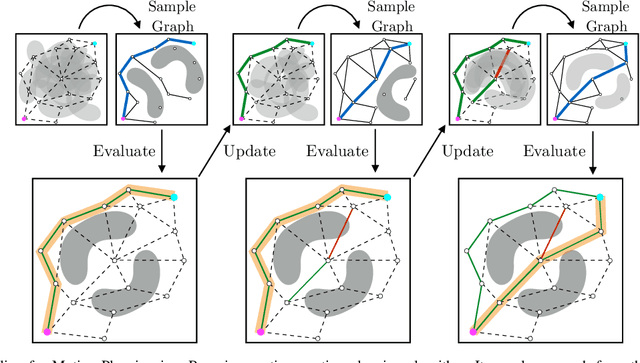

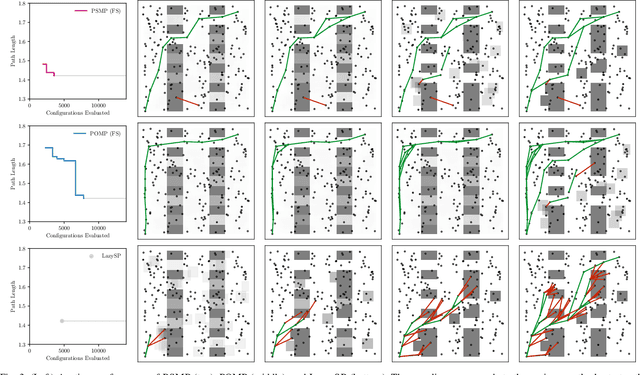
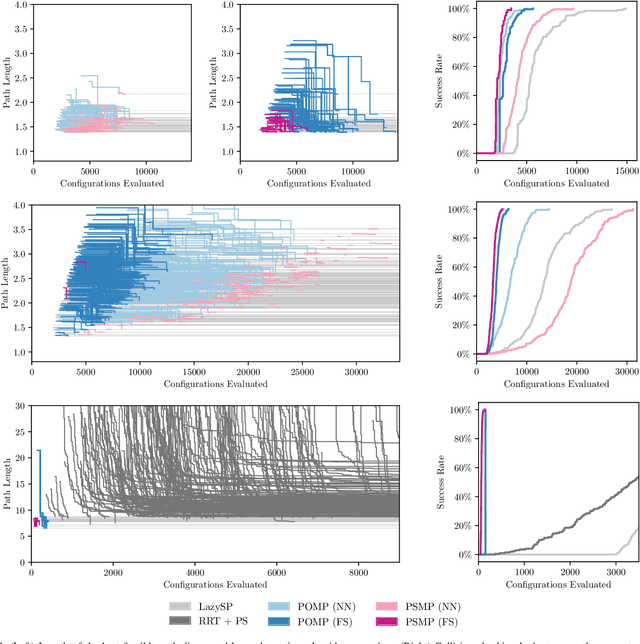
Collision checking is a computational bottleneck in motion planning, requiring lazy algorithms that explicitly reason about when to perform this computation. Optimism in the face of collision uncertainty minimizes the number of checks before finding the shortest path. However, this may take a prohibitively long time to compute, with no other feasible paths discovered during this period. For many real-time applications, we instead demand strong anytime performance, defined as minimizing the cumulative lengths of the feasible paths yielded over time. We introduce Posterior Sampling for Motion Planning (PSMP), an anytime lazy motion planning algorithm that leverages learned posteriors on edge collisions to quickly discover an initial feasible path and progressively yield shorter paths. PSMP obtains an expected regret bound of $\tilde{O}(\sqrt{\mathcal{S} \mathcal{A} T})$ and outperforms comparative baselines on a set of 2D and 7D planning problems.
A Fully Bayesian Gradient-Free Supervised Dimension Reduction Method using Gaussian Processes
Aug 08, 2020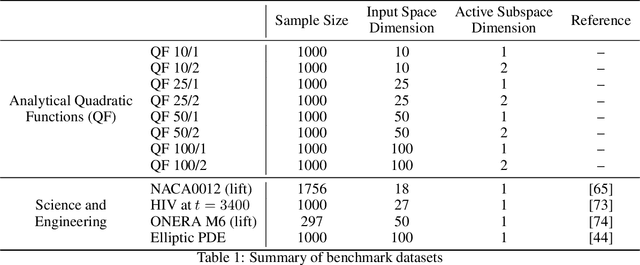
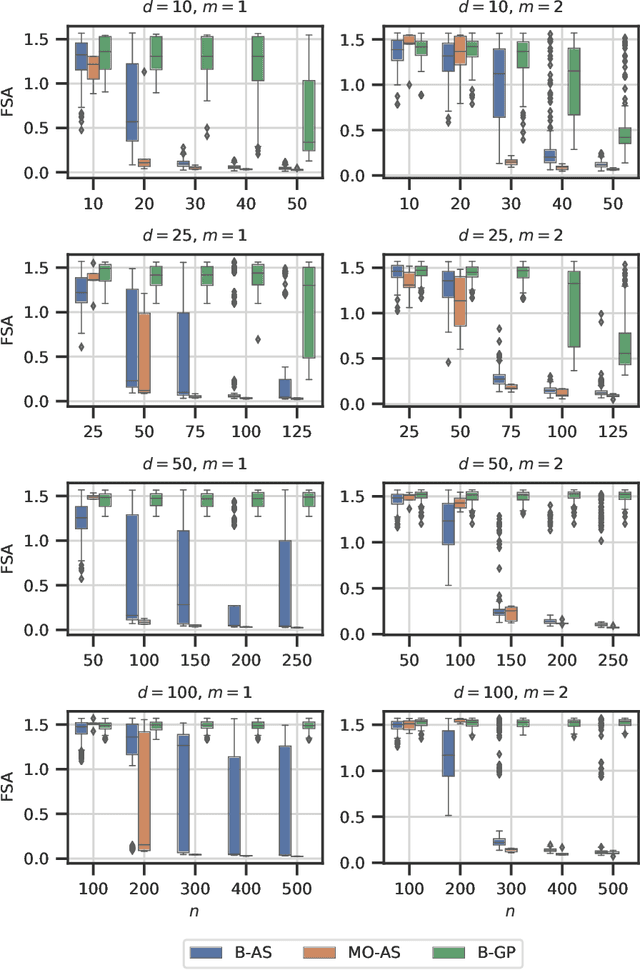
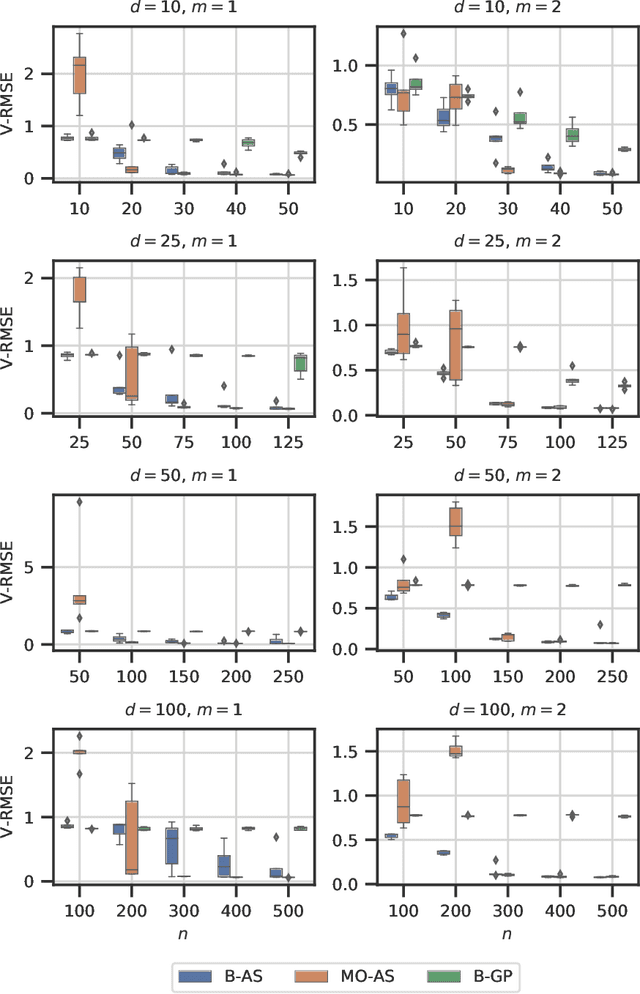
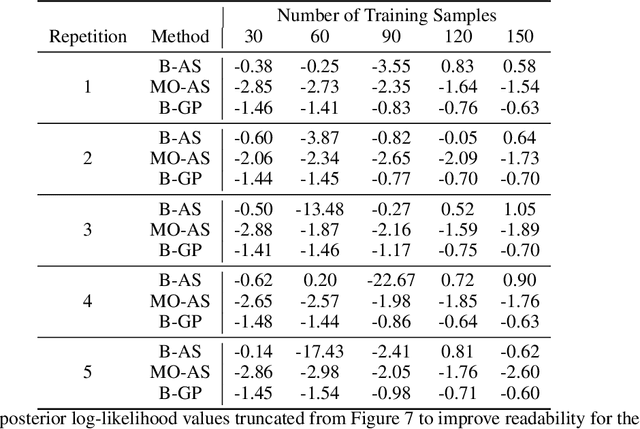
Modern day engineering problems are ubiquitously characterized by sophisticated computer codes that map parameters or inputs to an underlying physical process. In other situations, experimental setups are used to model the physical process in a laboratory, ensuring high precision while being costly in materials and logistics. In both scenarios, only limited amount of data can be generated by querying the expensive information source at a finite number of inputs or designs. This problem is compounded further in the presence of a high-dimensional input space. State-of-the-art parameter space dimension reduction methods, such as active subspace, aim to identify a subspace of the original input space that is sufficient to explain the output response. These methods are restricted by their reliance on gradient evaluations or copious data, making them inadequate to expensive problems without direct access to gradients. The proposed methodology is gradient-free and fully Bayesian, as it quantifies uncertainty in both the low-dimensional subspace and the surrogate model parameters. This enables a full quantification of epistemic uncertainty and robustness to limited data availability. It is validated on multiple datasets from engineering and science and compared to two other state-of-the-art methods based on four aspects: a) recovery of the active subspace, b) deterministic prediction accuracy, c) probabilistic prediction accuracy, and d) training time. The comparison shows that the proposed method improves the active subspace recovery and predictive accuracy, in both the deterministic and probabilistic sense, when only few model observations are available for training, at the cost of increased training time.
A Probabilistic Approach in Historical Linguistics Word Order Change in Infinitival Clauses: from Latin to Old French
Nov 16, 2020
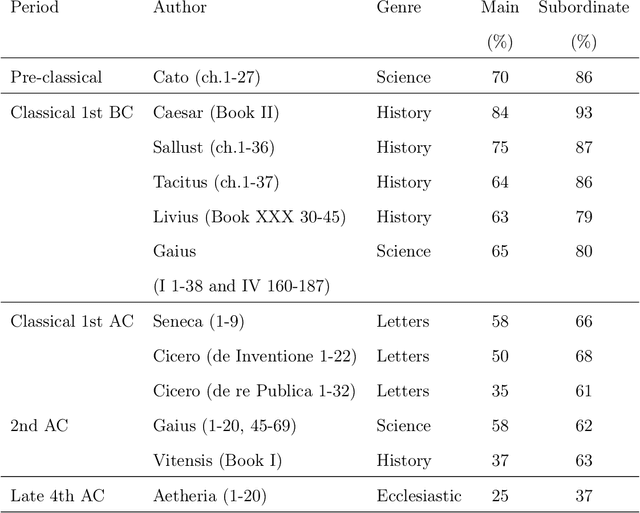
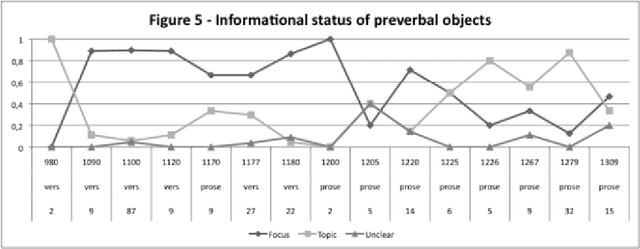

This research offers a new interdisciplinary approach to the field of Linguistics by using Computational Linguistics, NLP, Bayesian Statistics and Sociolinguistics methods. This thesis investigates word order change in infinitival clauses from Object-Verb (OV) to Verb-Object (VO) in the history of Latin and Old French. By applying a variationist approach, I examine a synchronic word order variation in each stage of language change, from which I infer the character, periodization and constraints of diachronic variation. I also show that in discourse-configurational languages, such as Latin and Early Old French, it is possible to identify pragmatically neutral contexts by using information structure annotation. I further argue that by mapping pragmatic categories into a syntactic structure, we can detect how word order change unfolds. For this investigation, the data are extracted from annotated corpora spanning several centuries of Latin and Old French and from additional resources created by using computational linguistic methods. The data are then further codified for various pragmatic, semantic, syntactic and sociolinguistic factors. This study also evaluates previous factors proposed to account for word order alternation and change. I show how information structure and syntactic constraints change over time and propose a method that allows researchers to differentiate a stable word order alternation from alternation indicating a change. Finally, I present a three-stage probabilistic model of word order change, which also conforms to traditional language change patterns.
Demand Responsive Dynamic Pricing Framework for Prosumer Dominated Microgrids using Multiagent Reinforcement Learning
Sep 23, 2020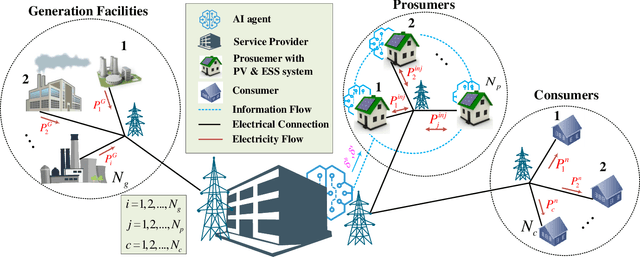
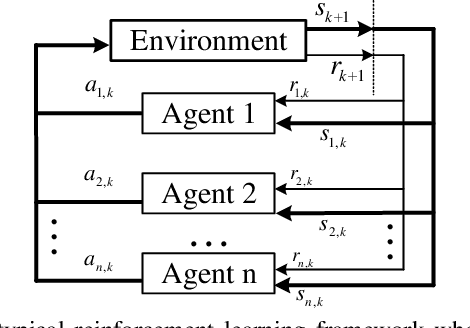
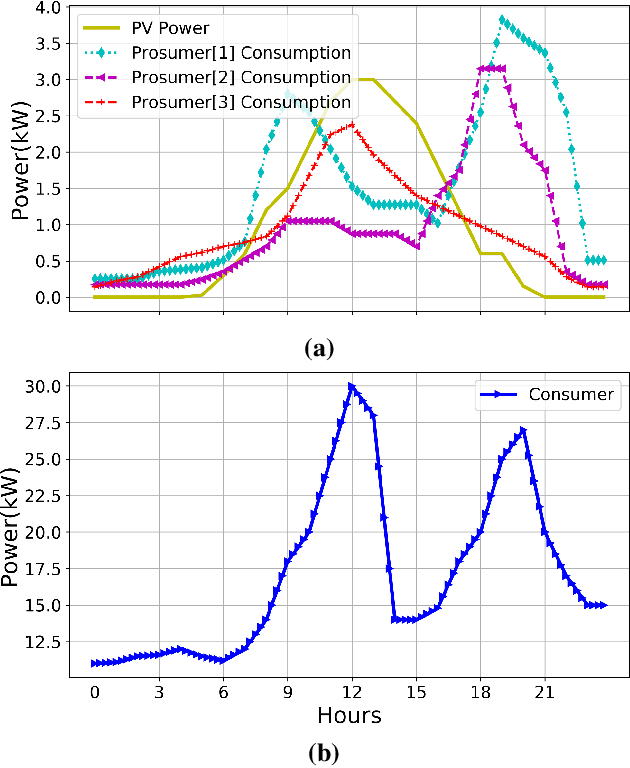
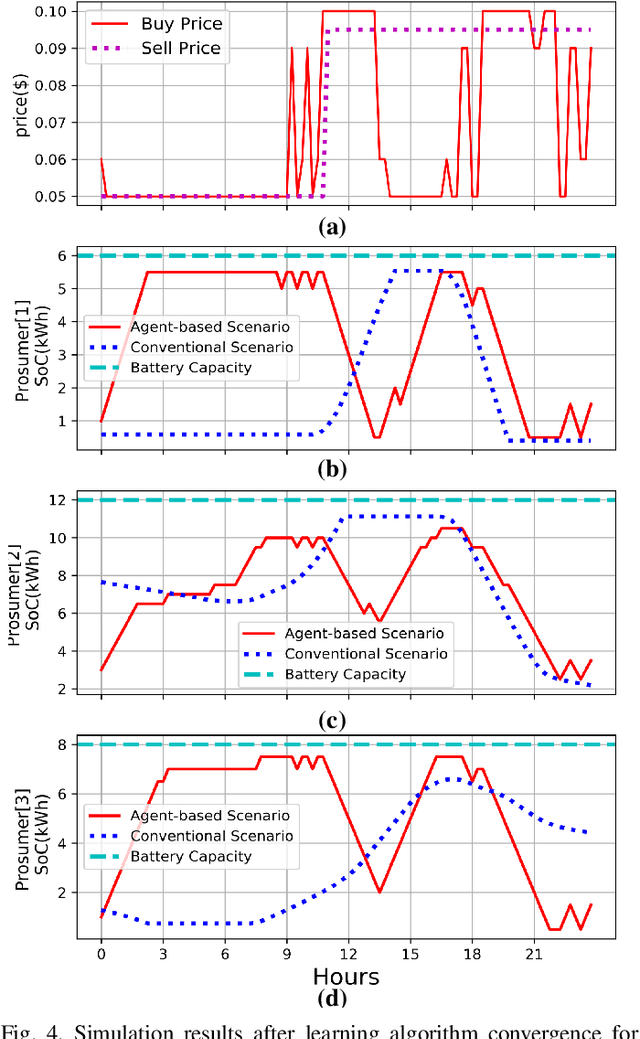
Demand Response (DR) has a widely recognized potential for improving grid stability and reliability while reducing customers energy bills. However, the conventional DR techniques come with several shortcomings, such as inability to handle operational uncertainties and incurring customer disutility, impeding their wide spread adoption in real-world applications. This paper proposes a new multiagent Reinforcement Learning (RL) based decision-making environment for implementing a Real-Time Pricing (RTP) DR technique in a prosumer dominated microgrid. The proposed technique addresses several shortcomings common to traditional DR methods and provides significant economic benefits to the grid operator and prosumers. To show its better efficacy, the proposed DR method is compared to a baseline traditional operation scenario in a small-scale microgrid system. Finally, investigations on the use of prosumers energy storage capacity in this microgrid highlight the advantages of the proposed method in establishing a balanced market setup.
Dialog Simulation with Realistic Variations for Training Goal-Oriented Conversational Systems
Nov 16, 2020
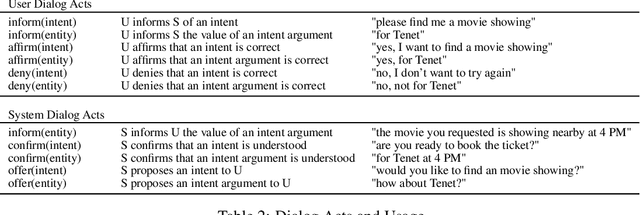
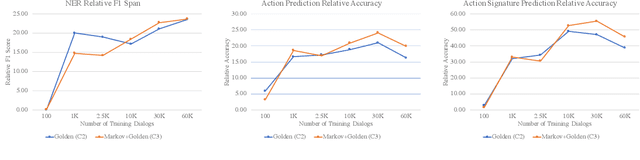
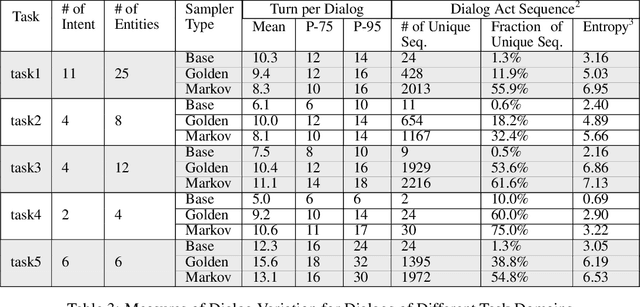
Goal-oriented dialog systems enable users to complete specific goals like requesting information about a movie or booking a ticket. Typically the dialog system pipeline contains multiple ML models, including natural language understanding, state tracking and action prediction (policy learning). These models are trained through a combination of supervised or reinforcement learning methods and therefore require collection of labeled domain specific datasets. However, collecting annotated datasets with language and dialog-flow variations is expensive, time-consuming and scales poorly due to human involvement. In this paper, we propose an approach for automatically creating a large corpus of annotated dialogs from a few thoroughly annotated sample dialogs and the dialog schema. Our approach includes a novel goal-sampling technique for sampling plausible user goals and a dialog simulation technique that uses heuristic interplay between the user and the system (Alexa), where the user tries to achieve the sampled goal. We validate our approach by generating data and training three different downstream conversational ML models. We achieve 18 ? 50% relative accuracy improvements on a held-out test set compared to a baseline dialog generation approach that only samples natural language and entity value variations from existing catalogs but does not generate any novel dialog flow variations. We also qualitatively establish that the proposed approach is better than the baseline. Moreover, several different conversational experiences have been built using this method, which enables customers to have a wide variety of conversations with Alexa.
Hierarchical Large-scale Graph Similarity Computation via Graph Coarsening and Matching
Jun 09, 2020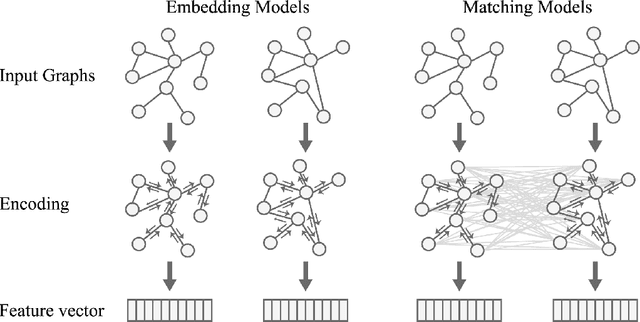
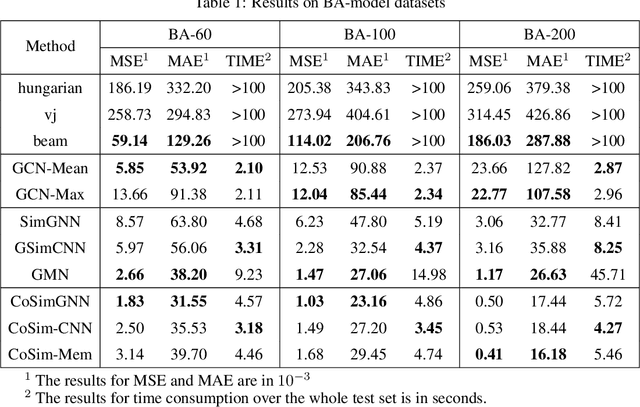
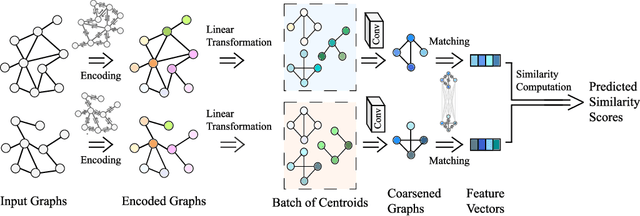
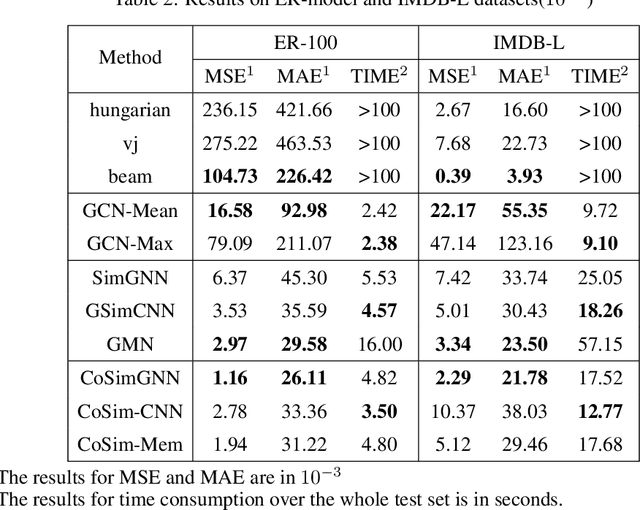
In this work, we focus on large graph similarity computation problem and propose a novel ``embedding-coarsening-matching'' learning framework, which outperforms state-of-the-art methods in this task and has significant improvement in time efficiency. Graph similarity computation for metrics such as Graph Edit Distance (GED) is typically NP-hard, and existing heuristics-based algorithms usually achieves a unsatisfactory trade-off between accuracy and efficiency. Recently the development of deep learning techniques provides a promising solution for this problem by a data-driven approach which trains a network to encode graphs to their own feature vectors and computes similarity based on feature vectors. These deep-learning methods can be classified to two categories, embedding models and matching models. Embedding models such as GCN-Mean and GCN-Max, which directly map graphs to respective feature vectors, run faster but the performance is usually poor due to the lack of interactions across graphs. Matching models such as GMN, whose encoding process involves interaction across the two graphs, are more accurate but interaction between whole graphs brings a significant increase in time consumption (at least quadratic time complexity over number of nodes). Inspired by large biological molecular identification where the whole molecular is first mapped to functional groups and then identified based on these functional groups, our ``embedding-coarsening-matching'' learning framework first embeds and coarsens large graphs to coarsened graphs with denser local topology and then matching mechanism is deployed on the coarsened graphs for the final similarity scores. Detailed experiments have been conducted and the results demonstrate the efficiency and effectiveness of our proposed framework.
Experimental Quantum Generative Adversarial Networks for Image Generation
Oct 21, 2020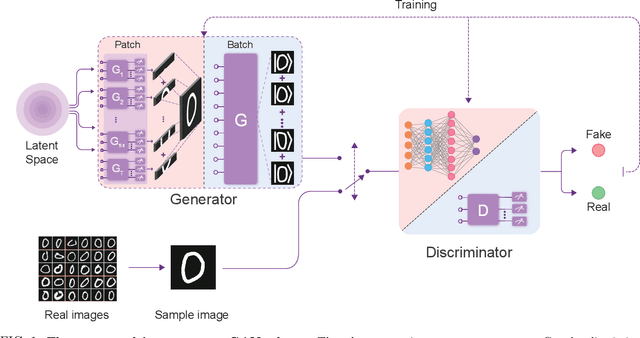

Quantum machine learning is expected to be one of the first practical applications of near-term quantum devices. Pioneer theoretical works suggest that quantum generative adversarial networks (GANs) may exhibit a potential exponential advantage over classical GANs, thus attracting widespread attention. However, it remains elusive whether quantum GANs implemented on near-term quantum devices can actually solve real-world learning tasks. Here, we devise a flexible quantum GAN scheme to narrow this knowledge gap, which could accomplish image generation with arbitrarily high-dimensional features, and could also take advantage of quantum superposition to train multiple examples in parallel. For the first time, we experimentally achieve the learning and generation of real-world hand-written digit images on a superconducting quantum processor. Moreover, we utilize a gray-scale bar dataset to exhibit the competitive performance between quantum GANs and the classical GANs based on multilayer perceptron and convolutional neural network architectures, respectively, benchmarked by the Fr\'echet Distance score. Our work provides guidance for developing advanced quantum generative models on near-term quantum devices and opens up an avenue for exploring quantum advantages in various GAN-related learning tasks.
Machine-Learning the Sato--Tate Conjecture
Oct 30, 2020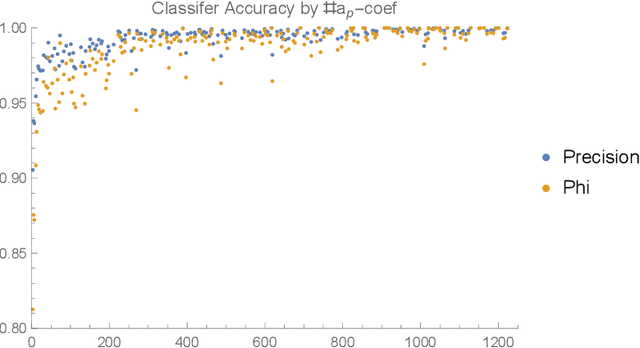
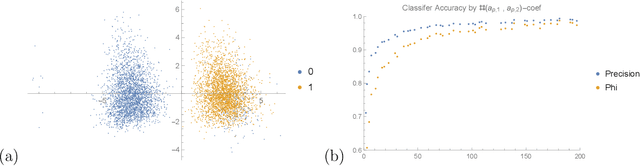
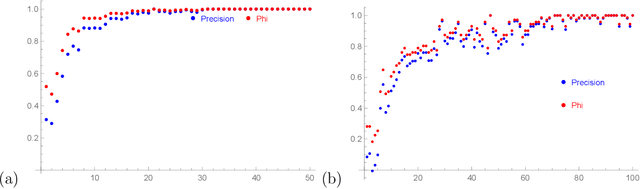
We apply some of the latest techniques from machine-learning to the arithmetic of hyperelliptic curves. More precisely we show that, with impressive accuracy and confidence (between 99 and 100 percent precision), and in very short time (matter of seconds on an ordinary laptop), a Bayesian classifier can distinguish between Sato-Tate groups given a small number of Euler factors for the L-function. Our observations are in keeping with the Sato-Tate conjecture for curves of low genus. For elliptic curves, this amounts to distinguishing generic curves (with Sato-Tate group SU(2)) from those with complex multiplication. In genus 2, a principal component analysis is observed to separate the generic Sato-Tate group USp(4) from the non-generic groups. Furthermore in this case, for which there are many more non-generic possibilities than in the case of elliptic curves, we demonstrate an accurate characterisation of several Sato-Tate groups with the same identity component. Throughout, our observations are verified using known results from the literature and the data available in the LMFDB. The results in this paper suggest that a machine can be trained to learn the Sato-Tate distributions and may be able to classify curves much more efficiently than the methods available in the literature.
A Comprehensive Survey of Machine Learning Applied to Radar Signal Processing
Sep 29, 2020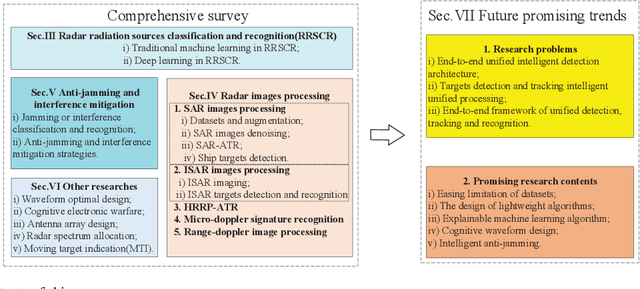
Modern radar systems have high requirements in terms of accuracy, robustness and real-time capability when operating on increasingly complex electromagnetic environments. Traditional radar signal processing (RSP) methods have shown some limitations when meeting such requirements, particularly in matters of target classification. With the rapid development of machine learning (ML), especially deep learning, radar researchers have started integrating these new methods when solving RSP-related problems. This paper aims at helping researchers and practitioners to better understand the application of ML techniques to RSP-related problems by providing a comprehensive, structured and reasoned literature overview of ML-based RSP techniques. This work is amply introduced by providing general elements of ML-based RSP and by stating the motivations behind them. The main applications of ML-based RSP are then analysed and structured based on the application field. This paper then concludes with a series of open questions and proposed research directions, in order to indicate current gaps and potential future solutions and trends.