 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Quadtree Driven Lossy Event Compression
May 03, 2020


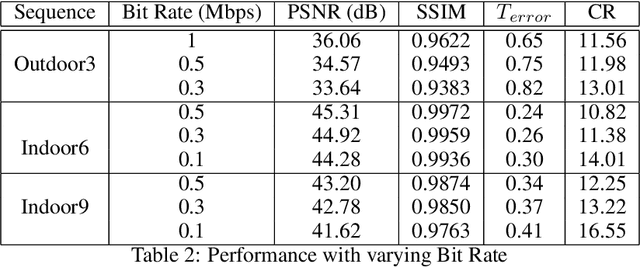
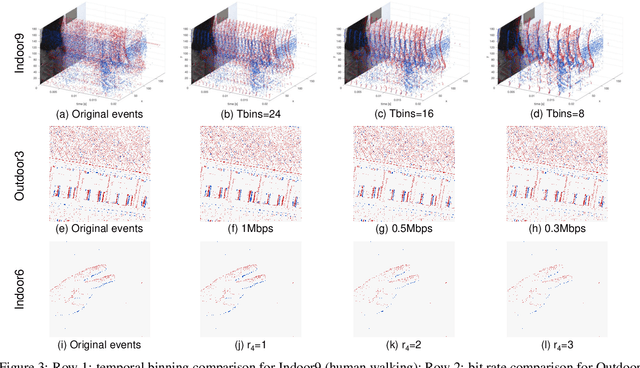
Event cameras are emerging bio-inspired sensors that offer salient benefits over traditional cameras. With high speed, high dynamic range, and low power consumption, event cameras have been increasingly employed to solve existing as well as novel visual and robotics tasks. Despite rapid advancement in event-based vision, event data compression is facing growing demand, yet remains elusively challenging and not effectively addressed. The major challenge is the unique data form, \emph{i.e.}, a stream of four-attribute events, encoding the spatial locations and the timestamp of each event, with a polarity representing the brightness increase/decrease. While events encode temporal variations at high speed, they omit rich spatial information, which is critical for image/video compression. In this paper, we perform lossy event compression (LEC) based on a quadtree (QT) segmentation map derived from an adjacent image. The QT structure provides a priority map for the 3D space-time volume, albeit in a 2D manner. LEC is performed by first quantizing the events over time, and then variably compressing the events within each QT block via Poisson Disk Sampling in 2D space for each quantized time. Our QT-LEC has flexibility in accordance with the bit-rate requirement. Experimentally, we show results with state-of-the-art coding performance. We further evaluate the performance in event-based applications such as image reconstruction and corner detection.
Simulated Chats for Task-oriented Dialog: Learning to Generate Conversations from Instructions
Oct 20, 2020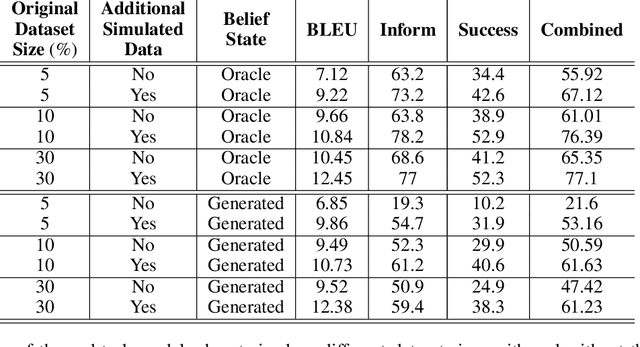
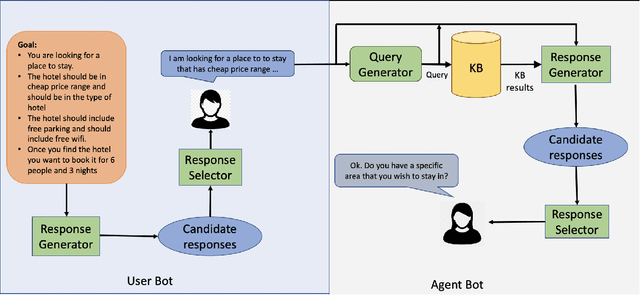
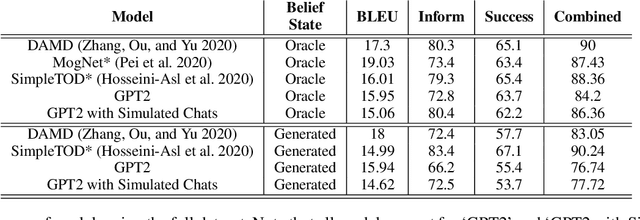

Popular task-oriented dialog data sets such as MultiWOZ (Budzianowski et al. 2018) are created by providing crowd-sourced workers a goal instruction, expressed in natural language, that describes the task to be accomplished. Crowd-sourced workers play the role of a user and an agent to generate dialogs to accomplish tasks involving booking restaurant tables, making train reservations, calling a taxi etc. However, creating large crowd-sourced datasets can be time consuming and expensive. To reduce the cost associated with generating such dialog datasets, recent work has explored methods to automatically create larger datasets from small samples.In this paper, we present a data creation strategy that uses the pre-trained language model, GPT2 (Radford et al. 2018), to simulate the interaction between crowd-sourced workers by creating a user bot and an agent bot. We train the simulators using a smaller percentage of actual crowd-generated conversations and their corresponding goal instructions. We demonstrate that by using the simulated data, we achieve significant improvements in both low-resource setting as well as in over-all task performance. To the best of our knowledge we are the first to present a model for generating entire conversations by simulating the crowd-sourced data collection process
Interpretable Machine Learning Approaches to Prediction of Chronic Homelessness
Sep 12, 2020We introduce a machine learning approach to predict chronic homelessness from de-identified client shelter records drawn from a commonly used Canadian homelessness management information system. Using a 30-day time step, a dataset for 6521 individuals was generated. Our model, HIFIS-RNN-MLP, incorporates both static and dynamic features of a client's history to forecast chronic homelessness 6 months into the client's future. The training method was fine-tuned to achieve a high F1-score, giving a desired balance between high recall and precision. Mean recall and precision across 10-fold cross validation were 0.921 and 0.651 respectively. An interpretability method was applied to explain individual predictions and gain insight into the overall factors contributing to chronic homelessness among the population studied. The model achieves state-of-the-art performance and improved stakeholder trust of what is usually a "black box" neural network model through interpretable AI.
Compliant Conditions for Polynomial Time Approximation of Operator Counts
Jul 05, 2016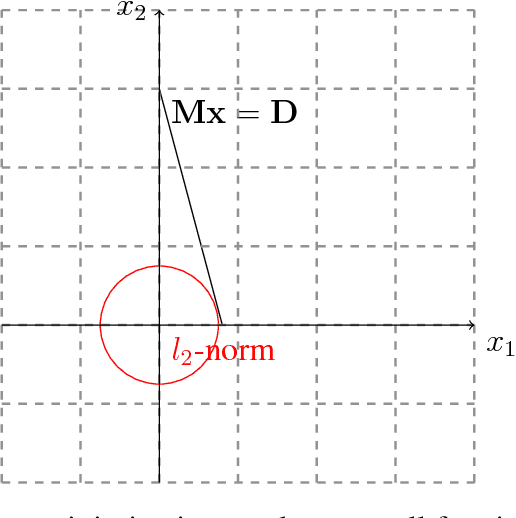
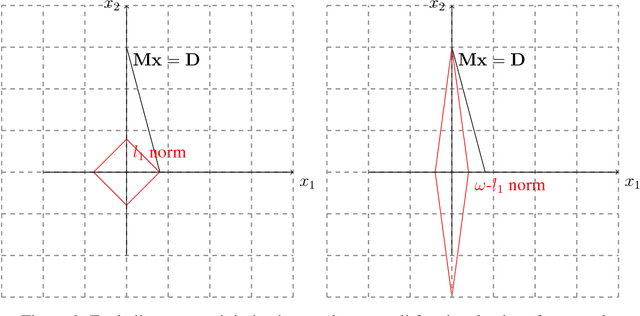
In this paper, we develop a computationally simpler version of the operator count heuristic for a particular class of domains. The contribution of this abstract is threefold, we (1) propose an efficient closed form approximation to the operator count heuristic using the Lagrangian dual; (2) leverage compressed sensing techniques to obtain an integer approximation for operator counts in polynomial time; and (3) discuss the relationship of the proposed formulation to existing heuristics and investigate properties of domains where such approaches appear to be useful.
AnomalyBench: An Open Benchmark for Explainable Anomaly Detection
Oct 10, 2020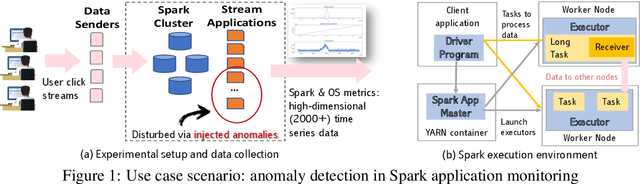
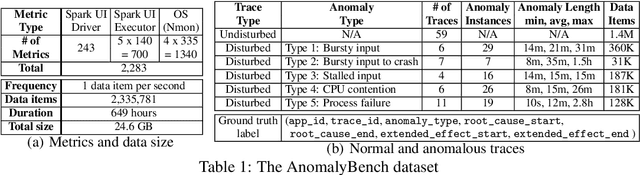
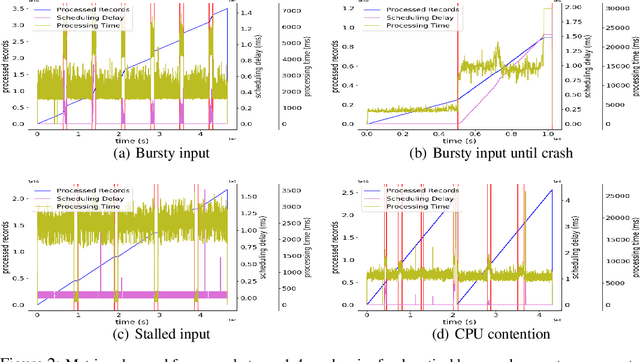

Access to high-quality data repositories and benchmarks have been instrumental in advancing the state of the art in many domains, as they provide the research community a common ground for training, testing, evaluating, comparing, and experimenting with novel machine learning models. Lack of such community resources for anomaly detection (AD) severely limits progress. In this report, we present AnomalyBench, the first comprehensive benchmark for explainable AD over high-dimensional (2000+) time series data. AnomalyBench has been systematically constructed based on real data traces from ~100 repeated executions of 10 large-scale stream processing jobs on a Spark cluster. 30+ of these executions were disturbed by introducing ~100 instances of different types of anomalous events (e.g., misbehaving inputs, resource contention, process failures). For each of these anomaly instances, ground truth labels for the root-cause interval as well as those for the effect interval are available, providing a means for supporting both AD tasks and explanation discovery (ED) tasks via root-cause analysis. We demonstrate the key design features and practical utility of AnomalyBench through an experimental study with three state-of-the-art semi-supervised AD techniques.
Learning to Actively Learn: A Robust Approach
Oct 29, 2020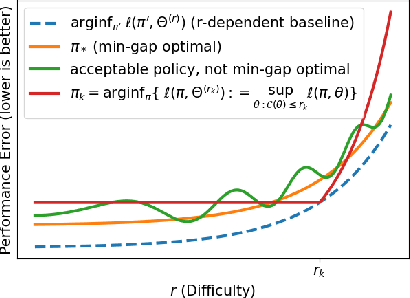
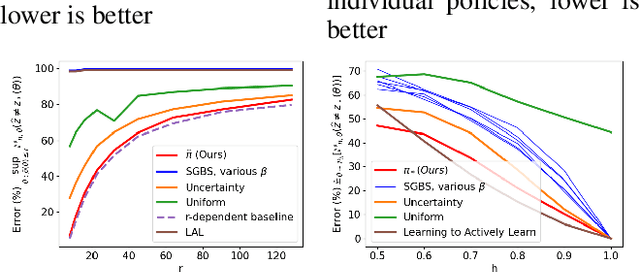
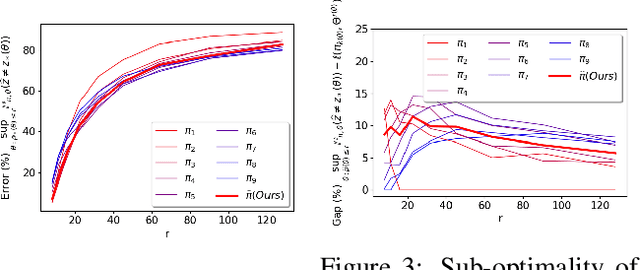
This work proposes a procedure for designing algorithms for specific adaptive data collection tasks like active learning and pure-exploration multi-armed bandits. Unlike the design of traditional adaptive algorithms that rely on concentration of measure and careful analysis to justify the correctness and sample complexity of the procedure, our adaptive algorithm is learned via adversarial training over equivalence classes of problems derived from information theoretic lower bounds. In particular, a single adaptive learning algorithm is learned that competes with the best adaptive algorithm learned for each equivalence class. Our procedure takes as input just the available queries, set of hypotheses, loss function, and total query budget. This is in contrast to existing meta-learning work that learns an adaptive algorithm relative to an explicit, user-defined subset or prior distribution over problems which can be challenging to define and be mismatched to the instance encountered at test time. This work is particularly focused on the regime when the total query budget is very small, such as a few dozen, which is much smaller than those budgets typically considered by theoretically derived algorithms. We perform synthetic experiments to justify the stability and effectiveness of the training procedure, and then evaluate the method on tasks derived from real data including a noisy 20 Questions game and a joke recommendation task.
Tiny SSD: A Tiny Single-shot Detection Deep Convolutional Neural Network for Real-time Embedded Object Detection
Feb 19, 2018
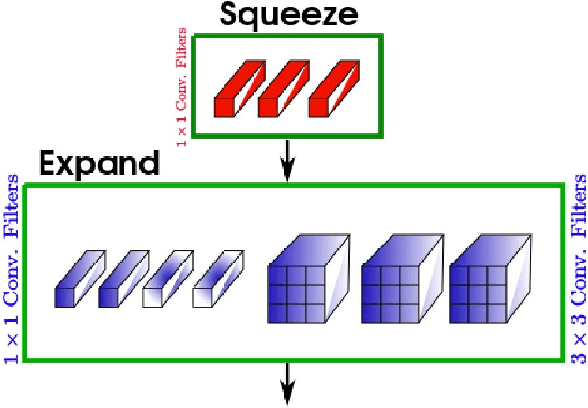
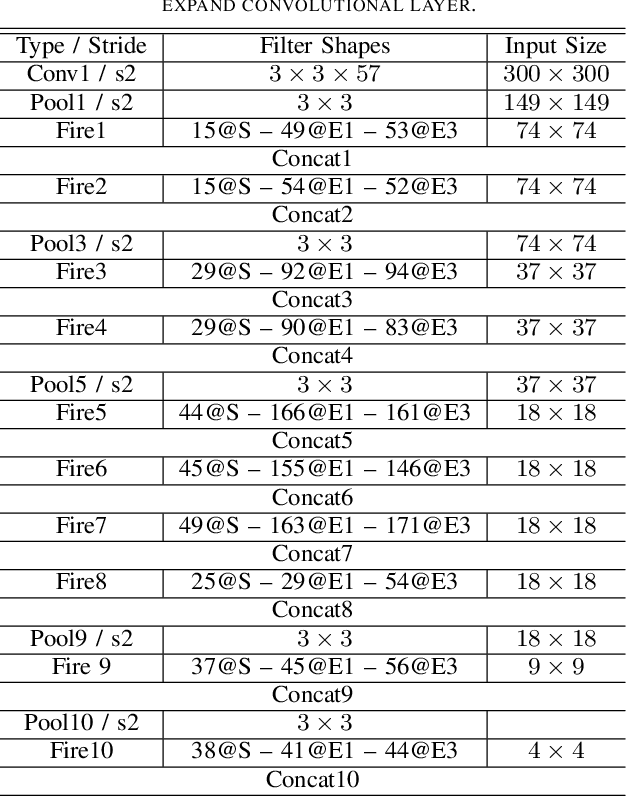

Object detection is a major challenge in computer vision, involving both object classification and object localization within a scene. While deep neural networks have been shown in recent years to yield very powerful techniques for tackling the challenge of object detection, one of the biggest challenges with enabling such object detection networks for widespread deployment on embedded devices is high computational and memory requirements. Recently, there has been an increasing focus in exploring small deep neural network architectures for object detection that are more suitable for embedded devices, such as Tiny YOLO and SqueezeDet. Inspired by the efficiency of the Fire microarchitecture introduced in SqueezeNet and the object detection performance of the single-shot detection macroarchitecture introduced in SSD, this paper introduces Tiny SSD, a single-shot detection deep convolutional neural network for real-time embedded object detection that is composed of a highly optimized, non-uniform Fire sub-network stack and a non-uniform sub-network stack of highly optimized SSD-based auxiliary convolutional feature layers designed specifically to minimize model size while maintaining object detection performance. The resulting Tiny SSD possess a model size of 2.3MB (~26X smaller than Tiny YOLO) while still achieving an mAP of 61.3% on VOC 2007 (~4.2% higher than Tiny YOLO). These experimental results show that very small deep neural network architectures can be designed for real-time object detection that are well-suited for embedded scenarios.
OrcVIO: Object residual constrained Visual-Inertial Odometry
Jul 29, 2020
Introducing object-level semantic information into simultaneous localization and mapping (SLAM) system is critical. It not only improves the performance but also enables tasks specified in terms of meaningful objects. This work presents OrcVIO, for visual-inertial odometry tightly coupled with tracking and optimization over structured object models. OrcVIO differentiates through semantic feature and bounding-box reprojection errors to perform batch optimization over the pose and shape of objects. The estimated object states aid in real-time incremental optimization over the IMU-camera states. The ability of OrcVIO for accurate trajectory estimation and large-scale object-level mapping is evaluated using real data.
Dynamic Nonparametric Edge-Clustering Model for Time-Evolving Sparse Networks
May 29, 2019
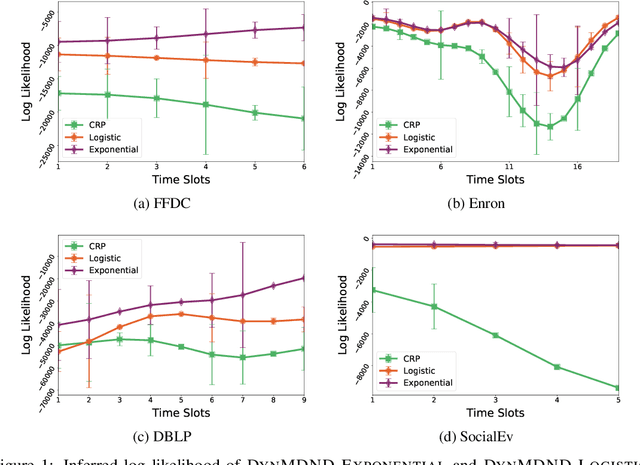
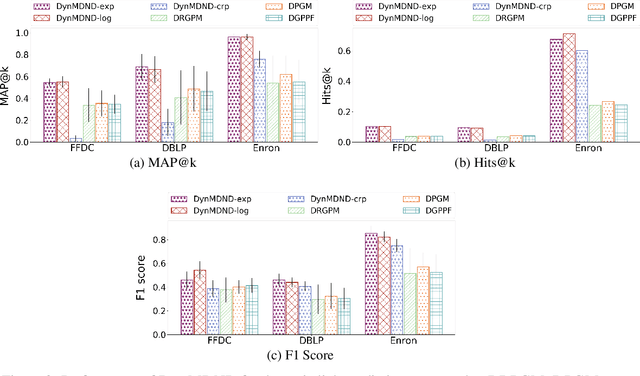
Interaction graphs, such as those recording emails between individuals or transactions between institutions, tend to be sparse yet structured, and often grow in an unbounded manner. Such behavior can be well-captured by structured, nonparametric edge-exchangeable graphs. However, such exchangeable models necessarily ignore temporal dynamics in the network. We propose a dynamic nonparametric model for interaction graphs that combine the sparsity of the exchangeable models with dynamic clustering patterns that tend to reinforce recent behavioral patterns. We show that our method yields improved held-out likelihood over stationary variants, and impressive predictive performance against a range of state-of-the-art dynamic interaction graph models.
STDI-Net: Spatial-Temporal Network with Dynamic Interval Mapping for Bike Sharing Demand Prediction
Jun 07, 2020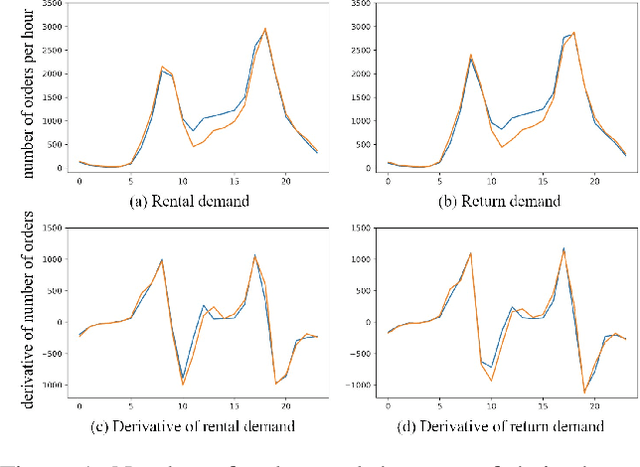
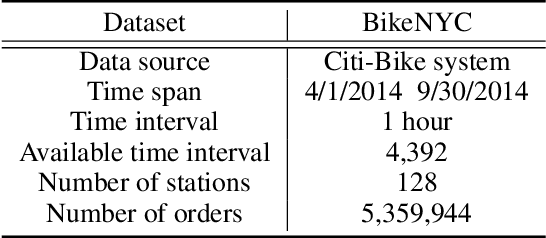
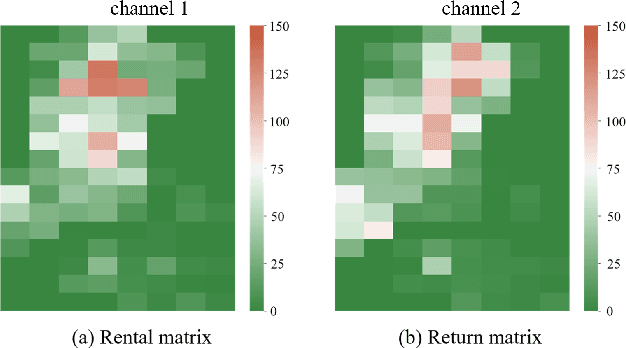
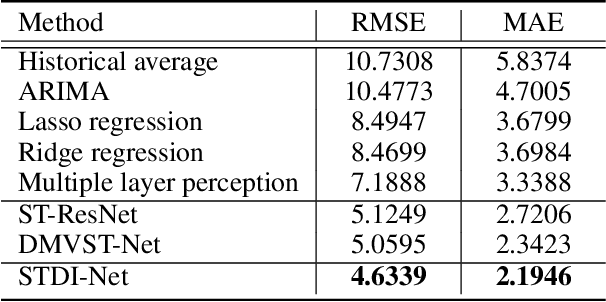
As an economical and healthy mode of shared transportation, Bike Sharing System (BSS) develops quickly in many big cities. An accurate prediction method can help BSS schedule resources in advance to meet the demands of users, and definitely improve operating efficiencies of it. However, most of the existing methods for similar tasks just utilize spatial or temporal information independently. Though there are some methods consider both, they only focus on demand prediction in a single location or between location pairs. In this paper, we propose a novel deep learning method called Spatial-Temporal Dynamic Interval Network (STDI-Net). The method predicts the number of renting and returning orders of multiple connected stations in the near future by modeling joint spatial-temporal information. Furthermore, we embed an additional module that generates dynamical learnable mappings for different time intervals, to include the factor that different time intervals have a strong influence on demand prediction in BSS. Extensive experiments are conducted on the NYC Bike dataset, the results demonstrate the superiority of our method over existing methods.