 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fast Decomposition of Temporal Logic Specifications for Heterogeneous Teams
Sep 30, 2020
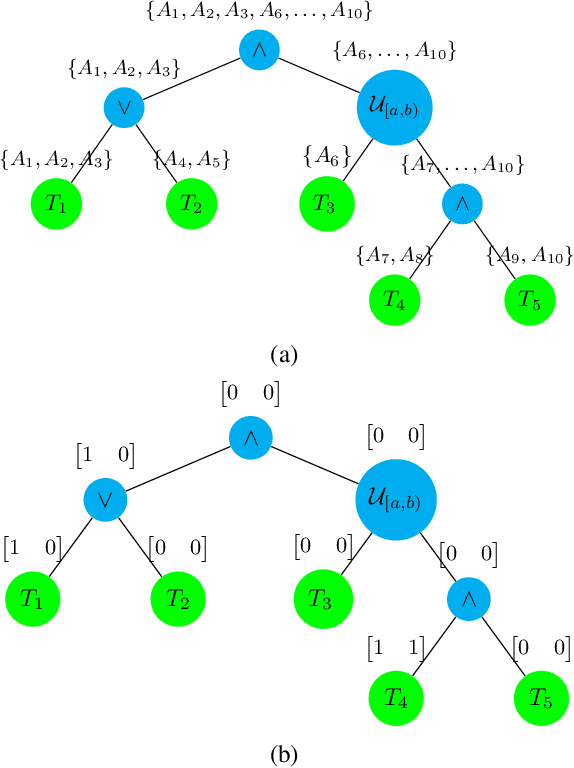
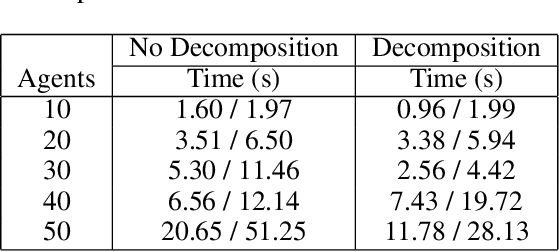
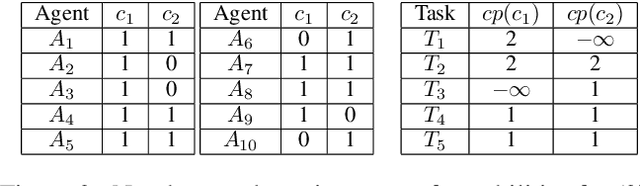
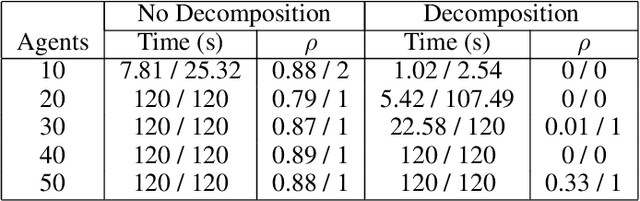
In this work, we focus on decomposing large multi-agent path planning problems with global temporal logic goals (common to all agents) into smaller sub-problems that can be solved and executed independently. Crucially, the sub-problems' solutions must jointly satisfy the common global mission specification. The agents' missions are given as Capability Temporal Logic (CaTL) formulas, a fragment of signal temporal logic, that can express properties over tasks involving multiple agent capabilities (sensors, e.g., camera, IR, and effectors, e.g., wheeled, flying, manipulators) under strict timing constraints. The approach we take is to decompose both the temporal logic specification and the team of agents. We jointly reason about the assignment of agents to subteams and the decomposition of formulas using a satisfiability modulo theories (SMT) approach. The output of the SMT is then distributed to subteams and leads to a significant speed up in planning time. We include computational results to evaluate the efficiency of our solution, as well as the trade-offs introduced by the conservative nature of the SMT encoding.
Interpreting convolutional networks trained on textual data
Oct 20, 2020
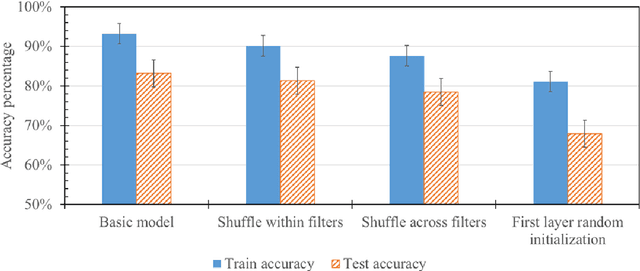

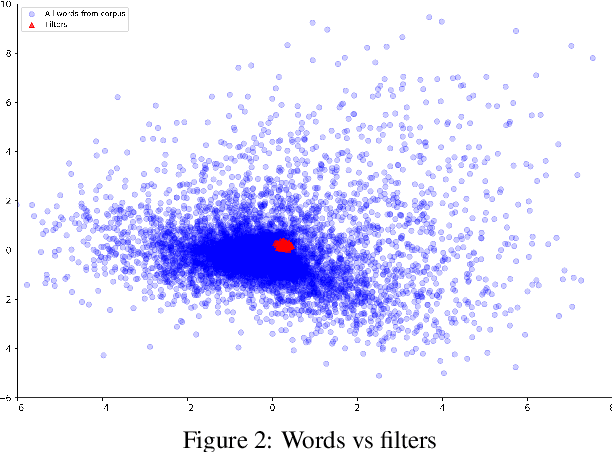
There have been many advances in the artificial intelligence field due to the emergence of deep learning. In almost all sub-fields, artificial neural networks have reached or exceeded human-level performance. However, most of the models are not interpretable. As a result, it is hard to trust their decisions, especially in life and death scenarios. In recent years, there has been a movement toward creating explainable artificial intelligence, but most work to date has concentrated on image processing models, as it is easier for humans to perceive visual patterns. There has been little work in other fields like natural language processing. In this paper, we train a convolutional model on textual data and analyze the global logic of the model by studying its filter values. In the end, we find the most important words in our corpus to our models logic and remove the rest (95%). New models trained on just the 5% most important words can achieve the same performance as the original model while reducing training time by more than half. Approaches such as this will help us to understand NLP models, explain their decisions according to their word choices, and improve them by finding blind spots and biases.
Fractional Deep Neural Network via Constrained Optimization
Apr 01, 2020
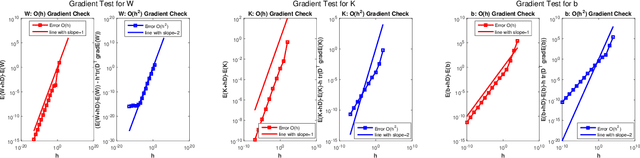
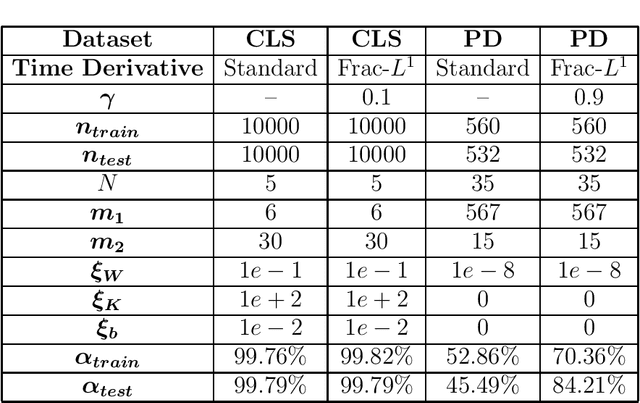
This paper introduces a novel algorithmic framework for a deep neural network (DNN), which in a mathematically rigorous manner, allows us to incorporate history (or memory) into the network -- it ensures all layers are connected to one another. This DNN, called Fractional-DNN, can be viewed as a time-discretization of a fractional in time nonlinear ordinary differential equation (ODE). The learning problem then is a minimization problem subject to that fractional ODE as constraints. We emphasize that an analogy between the existing DNN and ODEs, with standard time derivative, is well-known by now. The focus of our work is the Fractional-DNN. Using the Lagrangian approach, we provide a derivation of the backward propagation and the design equations. We test our network on several datasets for classification problems. Fractional-DNN offers various advantages over the existing DNN. The key benefits are a significant improvement to the vanishing gradient issue due to the memory effect, and better handling of nonsmooth data due to the network's ability to approximate non-smooth functions.
Quadtree Driven Lossy Event Compression
May 03, 2020

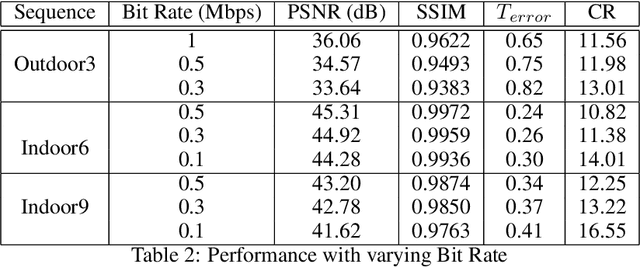
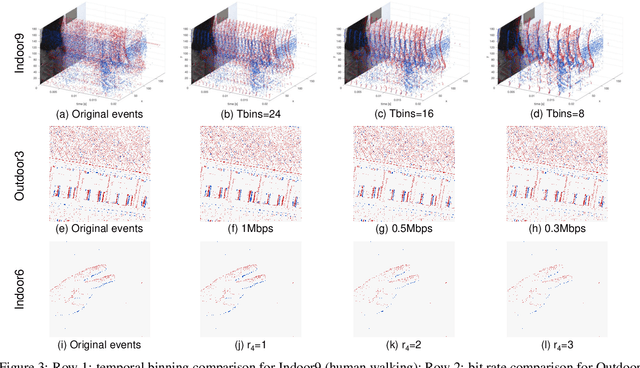
Event cameras are emerging bio-inspired sensors that offer salient benefits over traditional cameras. With high speed, high dynamic range, and low power consumption, event cameras have been increasingly employed to solve existing as well as novel visual and robotics tasks. Despite rapid advancement in event-based vision, event data compression is facing growing demand, yet remains elusively challenging and not effectively addressed. The major challenge is the unique data form, \emph{i.e.}, a stream of four-attribute events, encoding the spatial locations and the timestamp of each event, with a polarity representing the brightness increase/decrease. While events encode temporal variations at high speed, they omit rich spatial information, which is critical for image/video compression. In this paper, we perform lossy event compression (LEC) based on a quadtree (QT) segmentation map derived from an adjacent image. The QT structure provides a priority map for the 3D space-time volume, albeit in a 2D manner. LEC is performed by first quantizing the events over time, and then variably compressing the events within each QT block via Poisson Disk Sampling in 2D space for each quantized time. Our QT-LEC has flexibility in accordance with the bit-rate requirement. Experimentally, we show results with state-of-the-art coding performance. We further evaluate the performance in event-based applications such as image reconstruction and corner detection.
Recurrent Graph Tensor Networks
Sep 30, 2020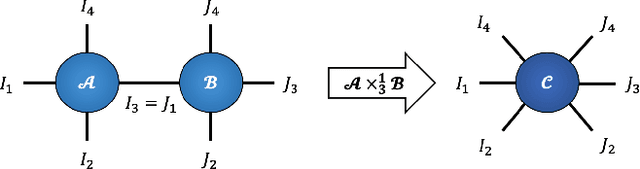

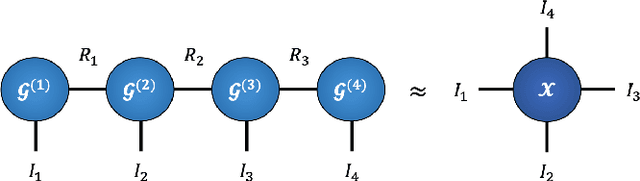
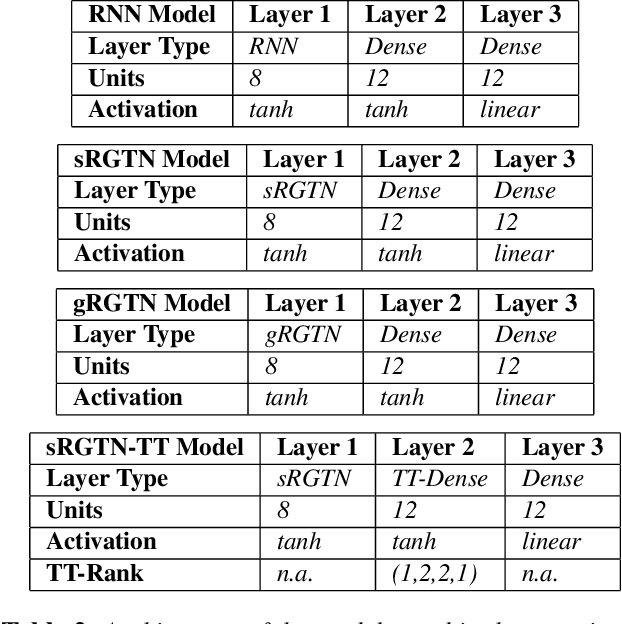
Recurrent Neural Networks (RNNs) are among the most successful machine learning models for sequence modelling. In this paper, we show that the modelling of hidden states in RNNs can be approximated through a multi-linear graph filter, which describes the directional flow of temporal information. The so derived multi-linear graph filter is then generalized to a tensor network form to improve its modelling power, resulting in a novel Recurrent Graph Tensor Network (RGTN). To validate the expressive power of the derived network, several variants of RGTN models were proposed and employed for the task of time-series forecasting, demonstrating superior properties in terms of convergence, performance, and complexity. By leveraging the multi-modal nature of tensor networks, RGTN models were shown to out-perform a standard RNN by 45% in terms of mean-squared-error while using up to 90% less parameters. Therefore, by combining the expressive power of tensor networks with a suitable graph filter, we show that the proposed RGTN models can out-perform a classical RNN at a drastically lower parameter complexity, especially in the multi-modal setting.
Multi-Objective Reinforcement Learning for Infectious Disease Control with Application to COVID-19 Spread
Sep 12, 2020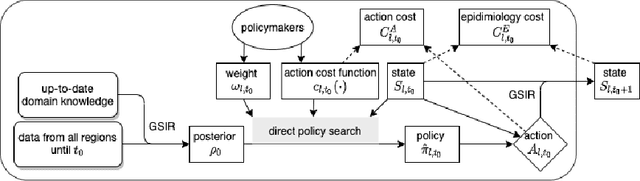

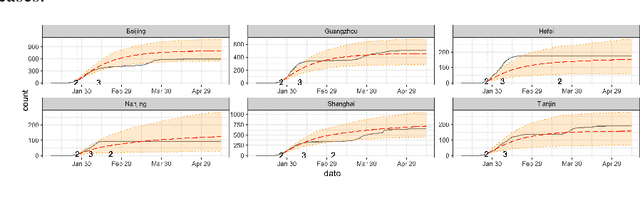
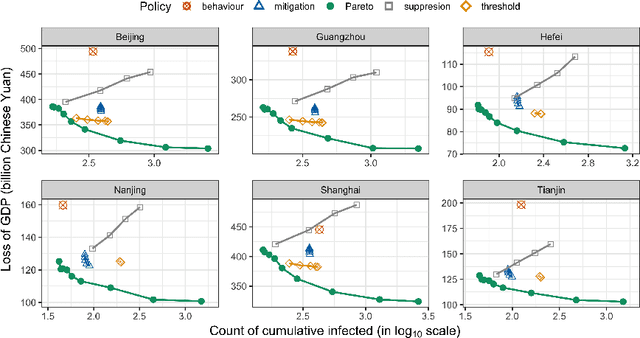
Severe infectious diseases such as the novel coronavirus (COVID-19) pose a huge threat to public health. Stringent control measures, such as school closures and stay-at-home orders, while having significant effects, also bring huge economic losses. A crucial question for policymakers around the world is how to make the trade-off and implement the appropriate interventions. In this work, we propose a Multi-Objective Reinforcement Learning framework to facilitate the data-driven decision making and minimize the long-term overall cost. Specifically, at each decision point, a Bayesian epidemiological model is first learned as the environment model, and then we use the proposed model-based multi-objective planning algorithm to find a set of Pareto-optimal policies. This framework, combined with the prediction bands for each policy, provides a real-time decision support tool for policymakers. The application is demonstrated with the spread of COVID-19 in China.
Dynamic Nonparametric Edge-Clustering Model for Time-Evolving Sparse Networks
May 29, 2019
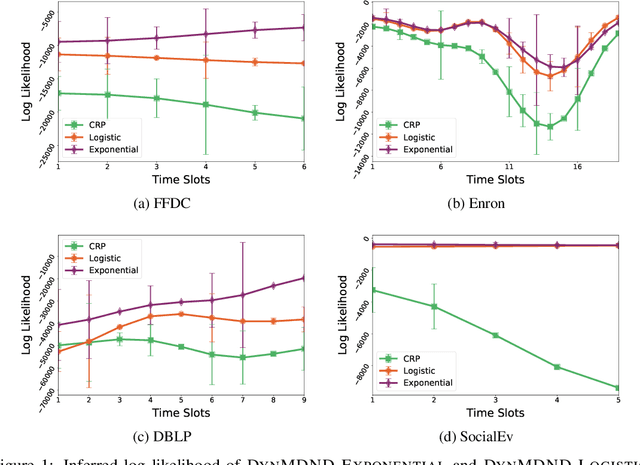
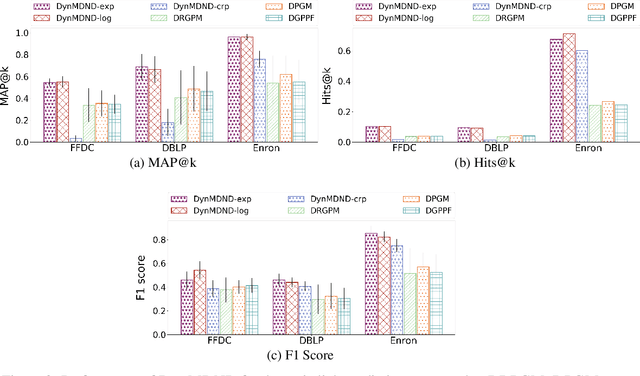
Interaction graphs, such as those recording emails between individuals or transactions between institutions, tend to be sparse yet structured, and often grow in an unbounded manner. Such behavior can be well-captured by structured, nonparametric edge-exchangeable graphs. However, such exchangeable models necessarily ignore temporal dynamics in the network. We propose a dynamic nonparametric model for interaction graphs that combine the sparsity of the exchangeable models with dynamic clustering patterns that tend to reinforce recent behavioral patterns. We show that our method yields improved held-out likelihood over stationary variants, and impressive predictive performance against a range of state-of-the-art dynamic interaction graph models.
An Online Learning Algorithm for a Neuro-Fuzzy Classifier with Mixed-Attribute Data
Sep 30, 2020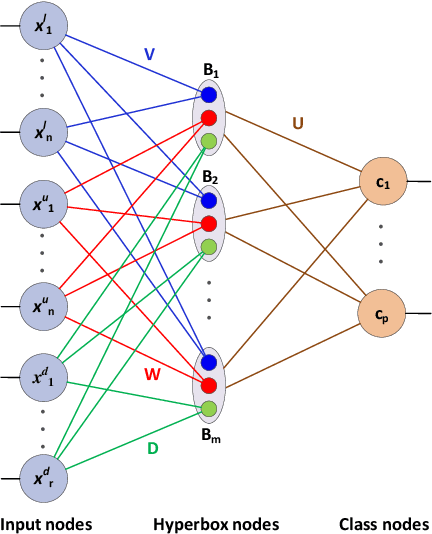
General fuzzy min-max neural network (GFMMNN) is one of the efficient neuro-fuzzy systems for data classification. However, one of the downsides of its original learning algorithms is the inability to handle and learn from the mixed-attribute data. While categorical features encoding methods can be used with the GFMMNN learning algorithms, they exhibit a lot of shortcomings. Other approaches proposed in the literature are not suitable for on-line learning as they require entire training data available in the learning phase. With the rapid change in the volume and velocity of streaming data in many application areas, it is increasingly required that the constructed models can learn and adapt to the continuous data changes in real-time without the need for their full retraining or access to the historical data. This paper proposes an extended online learning algorithm for the GFMMNN. The proposed method can handle the datasets with both continuous and categorical features. The extensive experiments confirmed superior and stable classification performance of the proposed approach in comparison to other relevant learning algorithms for the GFMM model.
Encode the Unseen: Predictive Video Hashing for Scalable Mid-Stream Retrieval
Sep 30, 2020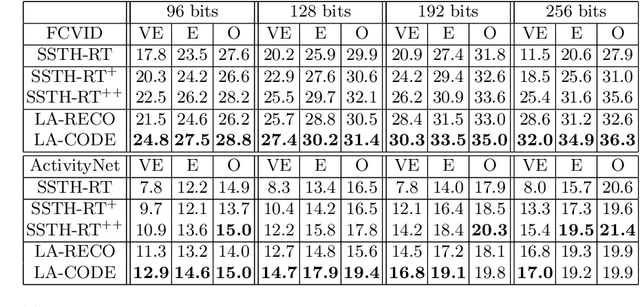
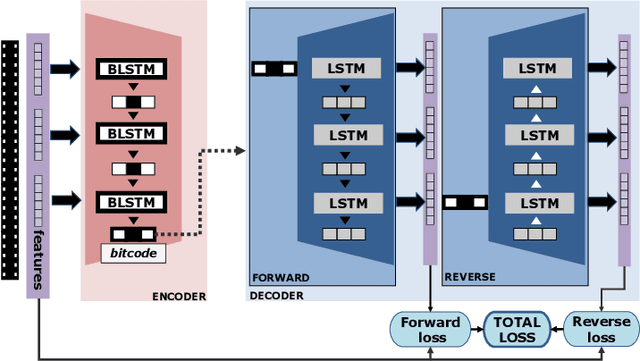
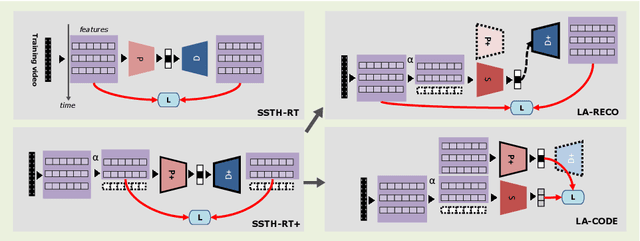

This paper tackles a new problem in computer vision: mid-stream video-to-video retrieval. This task, which consists in searching a database for content similar to a video right as it is playing, e.g. from a live stream, exhibits challenging characteristics. Only the beginning part of the video is available as query and new frames are constantly added as the video plays out. To perform retrieval in this demanding situation, we propose an approach based on a binary encoder that is both predictive and incremental in order to (1) account for the missing video content at query time and (2) keep up with repeated, continuously evolving queries throughout the streaming. In particular, we present the first hashing framework that infers the unseen future content of a currently playing video. Experiments on FCVID and ActivityNet demonstrate the feasibility of this task. Our approach also yields a significant mAP@20 performance increase compared to a baseline adapted from the literature for this task, for instance 7.4% (2.6%) increase at 20% (50%) of elapsed runtime on FCVID using bitcodes of size 192 bits.
Learning Optimal Power Flow: Worst-Case Guarantees for Neural Networks
Jun 19, 2020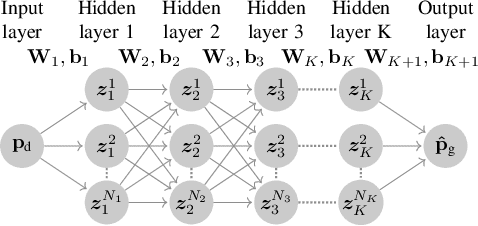
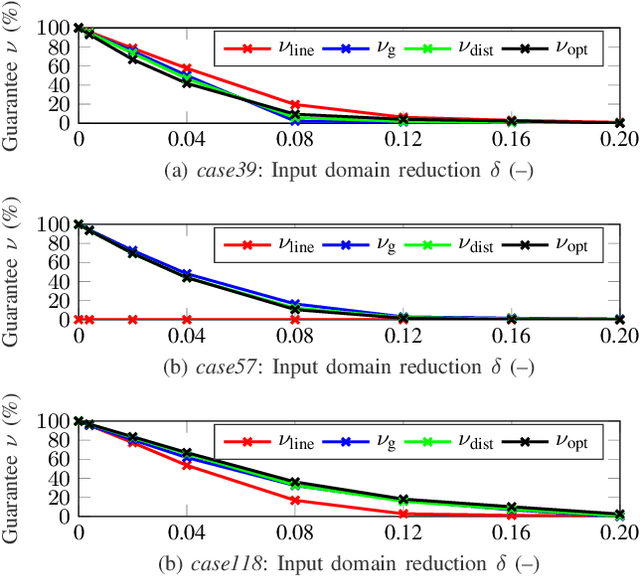
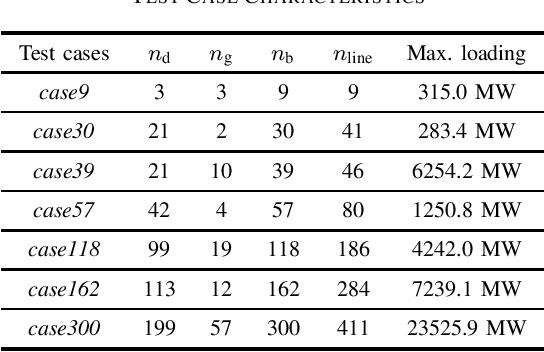
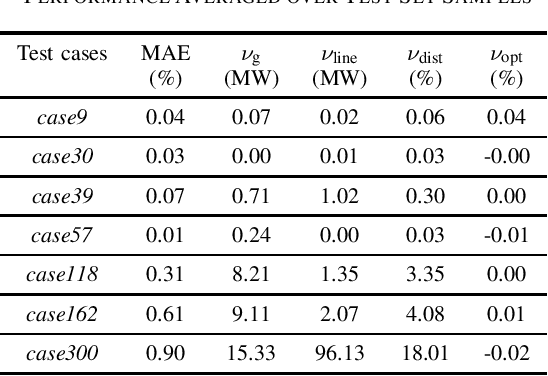
This paper introduces for the first time a framework to obtain provable worst-case guarantees for neural network performance, using learning for optimal power flow (OPF) problems as a guiding example. Neural networks have the potential to substantially reduce the computing time of OPF solutions. However, the lack of guarantees for their worst-case performance remains a major barrier for their adoption in practice. This work aims to remove this barrier. We formulate mixed-integer linear programs to obtain worst-case guarantees for neural network predictions related to (i) maximum constraint violations, (ii) maximum distances between predicted and optimal decision variables, and (iii) maximum sub-optimality. We demonstrate our methods on a range of PGLib-OPF networks up to 300 buses. We show that the worst-case guarantees can be up to one order of magnitude larger than the empirical lower bounds calculated with conventional methods. More importantly, we show that the worst-case predictions appear at the boundaries of the training input domain, and we demonstrate how we can systematically reduce the worst-case guarantees by training on a larger input domain than the domain they are evaluated on.