 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A kernel test for quasi-independence
Nov 17, 2020
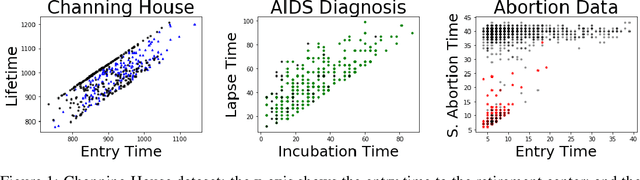
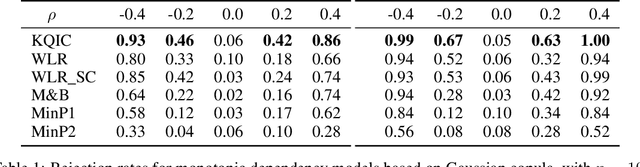
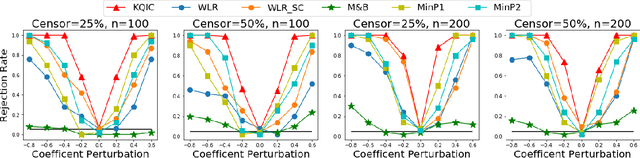

We consider settings in which the data of interest correspond to pairs of ordered times, e.g, the birth times of the first and second child, the times at which a new user creates an account and makes the first purchase on a website, and the entry and survival times of patients in a clinical trial. In these settings, the two times are not independent (the second occurs after the first), yet it is still of interest to determine whether there exists significant dependence {\em beyond} their ordering in time. We refer to this notion as "quasi-(in)dependence". For instance, in a clinical trial, to avoid biased selection, we might wish to verify that recruitment times are quasi-independent of survival times, where dependencies might arise due to seasonal effects. In this paper, we propose a nonparametric statistical test of quasi-independence. Our test considers a potentially infinite space of alternatives, making it suitable for complex data where the nature of the possible quasi-dependence is not known in advance. Standard parametric approaches are recovered as special cases, such as the classical conditional Kendall's tau, and log-rank tests. The tests apply in the right-censored setting: an essential feature in clinical trials, where patients can withdraw from the study. We provide an asymptotic analysis of our test-statistic, and demonstrate in experiments that our test obtains better power than existing approaches, while being more computationally efficient.
Better Than Reference In Low Light Image Enhancement: Conditional Re-Enhancement Networks
Aug 26, 2020
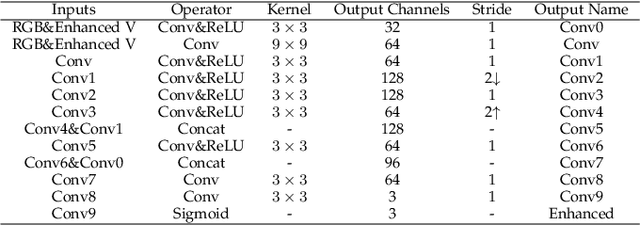

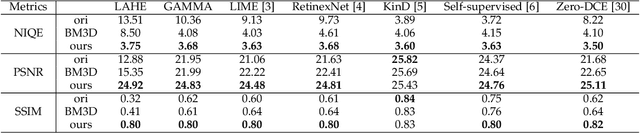
Low light images suffer from severe noise, low brightness, low contrast, etc. In previous researches, many image enhancement methods have been proposed, but few methods can deal with these problems simultaneously. In this paper, to solve these problems simultaneously, we propose a low light image enhancement method that can combined with supervised learning and previous HSV (Hue, Saturation, Value) or Retinex model based image enhancement methods. First, we analyse the relationship between the HSV color space and the Retinex theory, and show that the V channel (V channel in HSV color space, equals the maximum channel in RGB color space) of the enhanced image can well represent the contrast and brightness enhancement process. Then, a data-driven conditional re-enhancement network (denoted as CRENet) is proposed. The network takes low light images as input and the enhanced V channel as condition, then it can re-enhance the contrast and brightness of the low light image and at the same time reduce noise and color distortion. It should be noted that during the training process, any paired images with different exposure time can be used for training, and there is no need to carefully select the supervised images which will save a lot. In addition, it takes less than 20 ms to process a color image with the resolution 400*600 on a 2080Ti GPU. Finally, some comparative experiments are implemented to prove the effectiveness of the method. The results show that the method proposed in this paper can significantly improve the quality of the enhanced image, and by combining with other image contrast enhancement methods, the final enhancement result can even be better than the reference image in contrast and brightness. (Code will be available at https://github.com/hitzhangyu/image-enhancement-with-denoise)
Robust navigation with tinyML for autonomous mini-vehicles
Jul 01, 2020

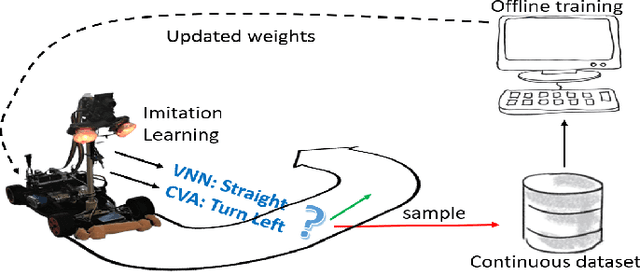
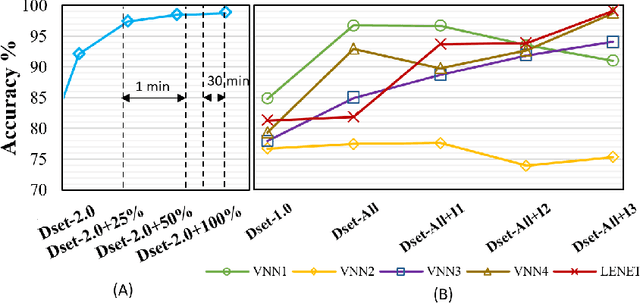
Autonomous navigation vehicles have rapidly improved thanks to the breakthroughs of Deep Learning. However, scaling autonomous driving to low-power and real-time systems deployed on dynamic environments poses several challenges that prevent their adoption. In this work, we show an end-to-end integration of data, algorithms, and deployment tools that enables the deployment of a family of tiny-CNNs on extra-low-power MCUs for autonomous driving mini-vehicles (image classification task). Our end-to-end environment enables a closed-loop learning system that allows the CNNs (learners) to learn through demonstration by imitating the original computer-vision algorithm (teacher) while doubling the throughput. Thereby, our CNNs gain robustness to lighting conditions and increase their accuracy up to 20% when deployed in the most challenging setup with a very fast-rate camera. Further, we leverage GAP8, a parallel ultra-low-power RISC-V SoC, to meet the real-time requirements. When running a family of CNN for an image classification task, GAP8 reduces their latency by over 20x compared to using an STM32L4 (Cortex-M4) or obtains +21.4% accuracy than an NXP k64f (Cortex-M4) solution with the same energy budget.
Finding Motif Sets in Time Series
Jul 14, 2014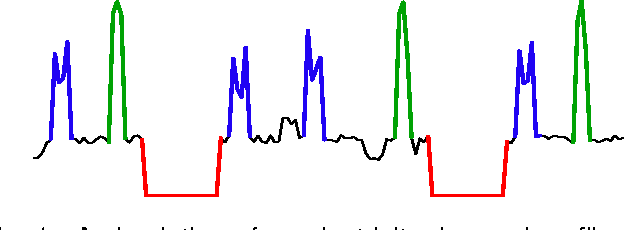



Time-series motifs are representative subsequences that occur frequently in a time series; a motif set is the set of subsequences deemed to be instances of a given motif. We focus on finding motif sets. Our motivation is to detect motif sets in household electricity-usage profiles, representing repeated patterns of household usage. We propose three algorithms for finding motif sets. Two are greedy algorithms based on pairwise comparison, and the third uses a heuristic measure of set quality to find the motif set directly. We compare these algorithms on simulated datasets and on electricity-usage data. We show that Scan MK, the simplest way of using the best-matching pair to find motif sets, is less accurate on our synthetic data than Set Finder and Cluster MK, although the latter is very sensitive to parameter settings. We qualitatively analyse the outputs for the electricity-usage data and demonstrate that both Scan MK and Set Finder can discover useful motif sets in such data.
Incremental Processing in the Age of Non-Incremental Encoders: An Empirical Assessment of Bidirectional Models for Incremental NLU
Oct 11, 2020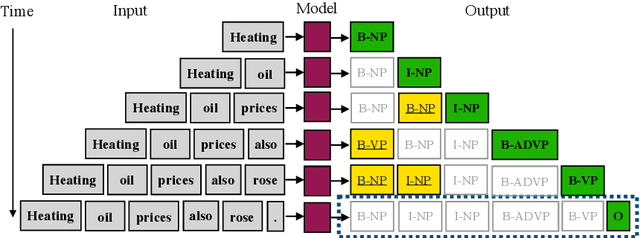
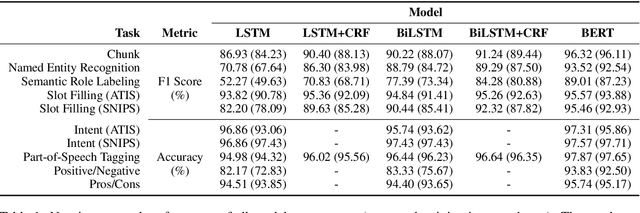
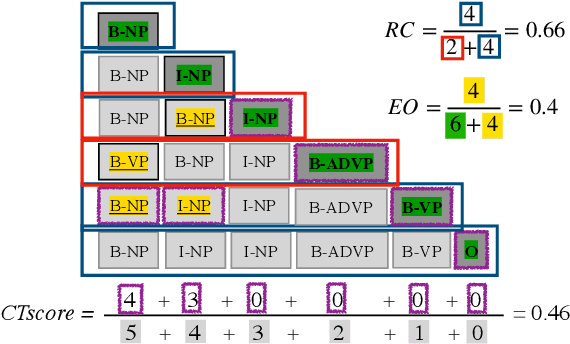
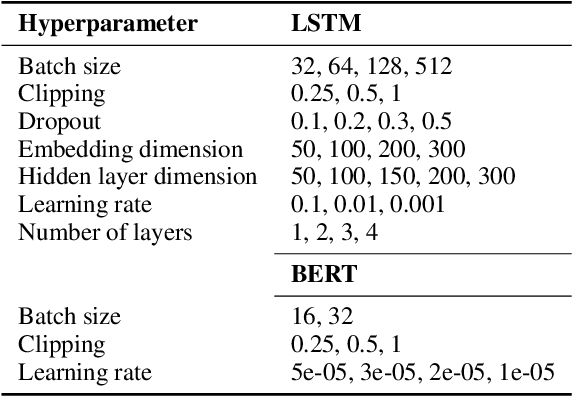
While humans process language incrementally, the best language encoders currently used in NLP do not. Both bidirectional LSTMs and Transformers assume that the sequence that is to be encoded is available in full, to be processed either forwards and backwards (BiLSTMs) or as a whole (Transformers). We investigate how they behave under incremental interfaces, when partial output must be provided based on partial input seen up to a certain time step, which may happen in interactive systems. We test five models on various NLU datasets and compare their performance using three incremental evaluation metrics. The results support the possibility of using bidirectional encoders in incremental mode while retaining most of their non-incremental quality. The "omni-directional" BERT model, which achieves better non-incremental performance, is impacted more by the incremental access. This can be alleviated by adapting the training regime (truncated training), or the testing procedure, by delaying the output until some right context is available or by incorporating hypothetical right contexts generated by a language model like GPT-2.
Particles to Partial Differential Equations Parsimoniously
Nov 09, 2020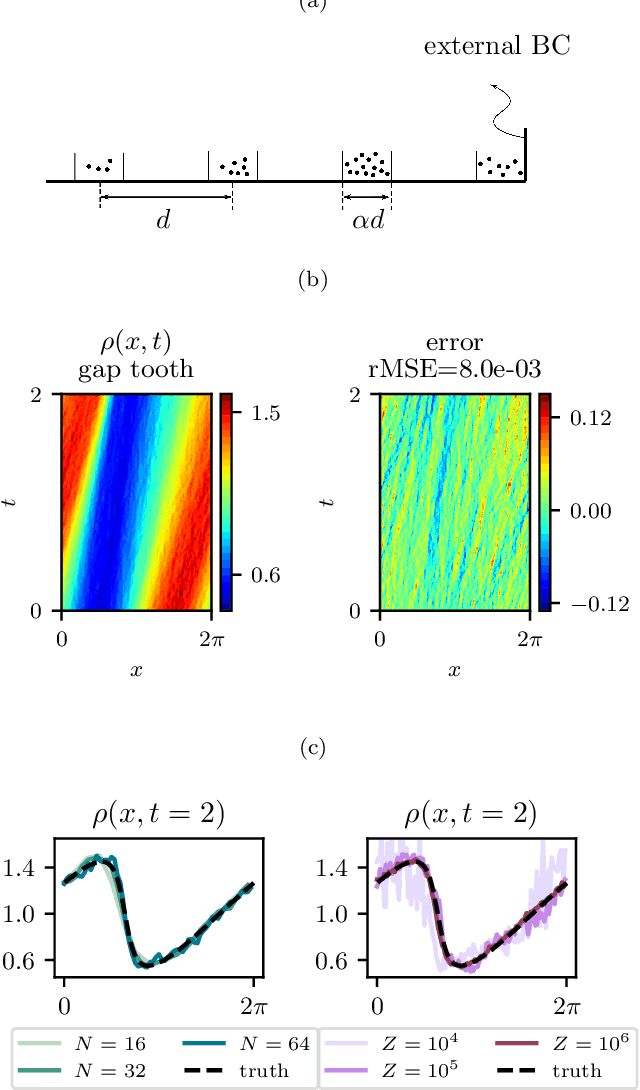
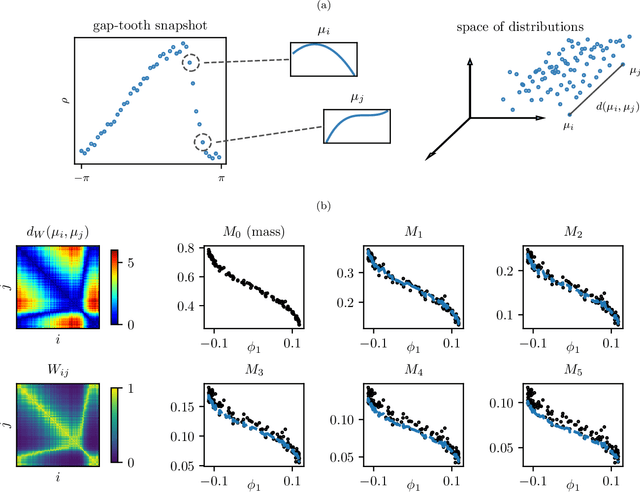
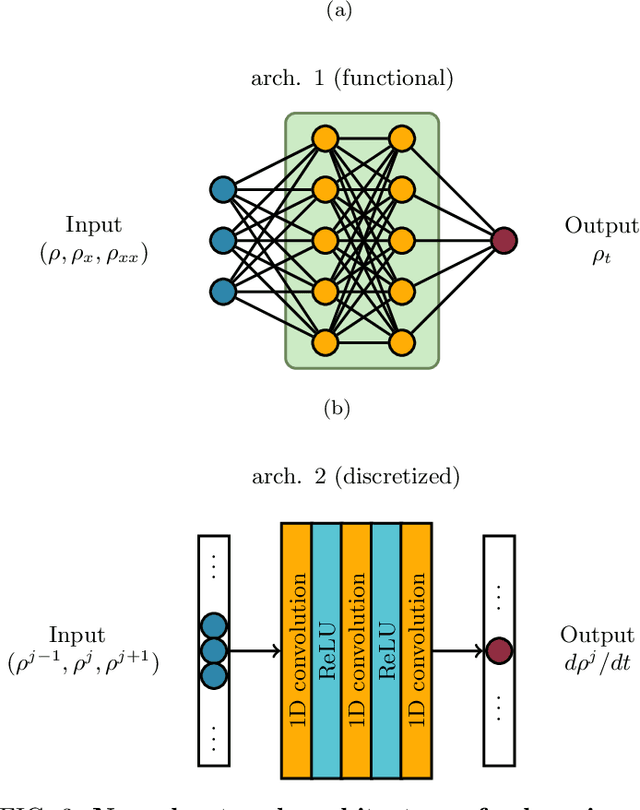
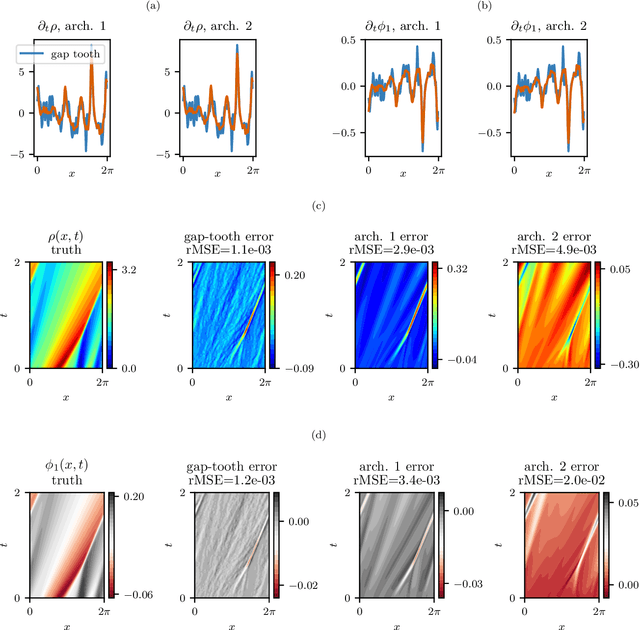
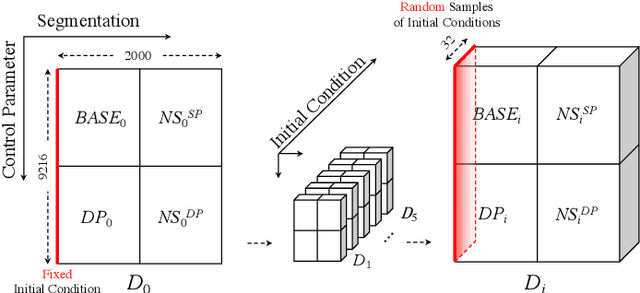
Equations governing physico-chemical processes are usually known at microscopic spatial scales, yet one suspects that there exist equations, e.g. in the form of Partial Differential Equations (PDEs), that can explain the system evolution at much coarser, meso- or macroscopic length scales. Discovering those coarse-grained effective PDEs can lead to considerable savings in computation-intensive tasks like prediction or control. We propose a framework combining artificial neural networks with multiscale computation, in the form of equation-free numerics, for efficient discovery of such macro-scale PDEs directly from microscopic simulations. Gathering sufficient microscopic data for training neural networks can be computationally prohibitive; equation-free numerics enable a more parsimonious collection of training data by only operating in a sparse subset of the space-time domain. We also propose using a data-driven approach, based on manifold learning and unnormalized optimal transport of distributions, to identify macro-scale dependent variable(s) suitable for the data-driven discovery of said PDEs. This approach can corroborate physically motivated candidate variables, or introduce new data-driven variables, in terms of which the coarse-grained effective PDE can be formulated. We illustrate our approach by extracting coarse-grained evolution equations from particle-based simulations with a priori unknown macro-scale variable(s), while significantly reducing the requisite data collection computational effort.
Generating Natural Questions from Images for Multimodal Assistants
Nov 17, 2020
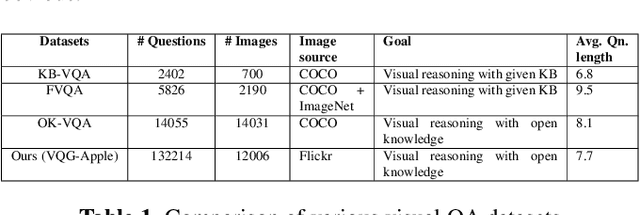

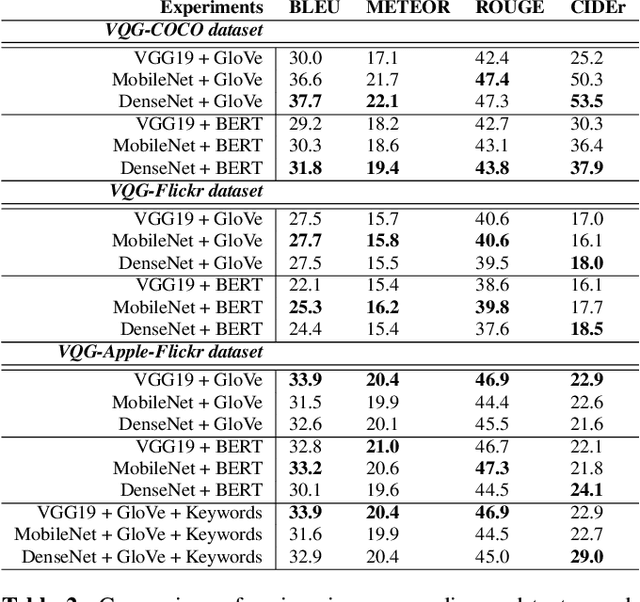
Generating natural, diverse, and meaningful questions from images is an essential task for multimodal assistants as it confirms whether they have understood the object and scene in the images properly. The research in visual question answering (VQA) and visual question generation (VQG) is a great step. However, this research does not capture questions that a visually-abled person would ask multimodal assistants. Recently published datasets such as KB-VQA, FVQA, and OK-VQA try to collect questions that look for external knowledge which makes them appropriate for multimodal assistants. However, they still contain many obvious and common-sense questions that humans would not usually ask a digital assistant. In this paper, we provide a new benchmark dataset that contains questions generated by human annotators keeping in mind what they would ask multimodal digital assistants. Large scale annotations for several hundred thousand images are expensive and time-consuming, so we also present an effective way of automatically generating questions from unseen images. In this paper, we present an approach for generating diverse and meaningful questions that consider image content and metadata of image (e.g., location, associated keyword). We evaluate our approach using standard evaluation metrics such as BLEU, METEOR, ROUGE, and CIDEr to show the relevance of generated questions with human-provided questions. We also measure the diversity of generated questions using generative strength and inventiveness metrics. We report new state-of-the-art results on the public and our datasets.
Triad State Space Construction for Chaotic Signal Classification with Deep Learning
Mar 26, 2020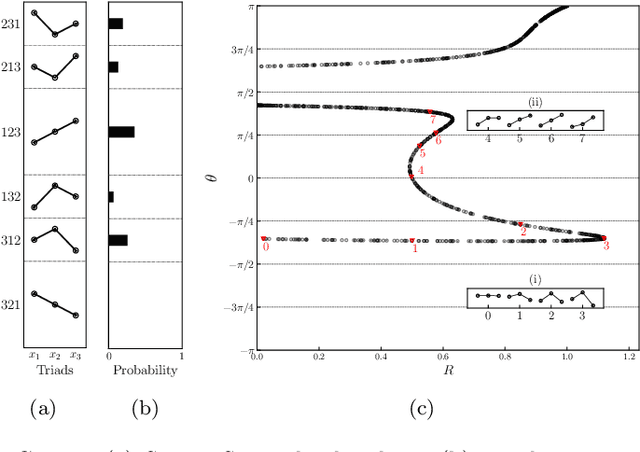
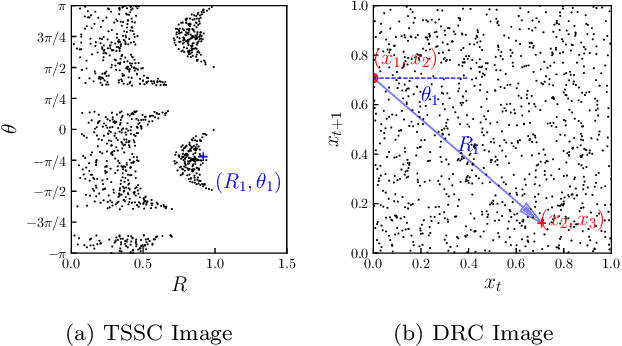
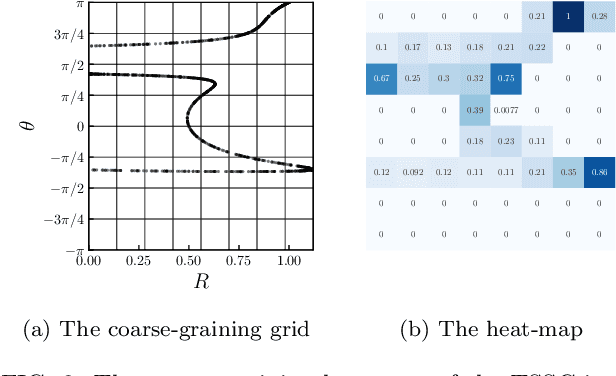
Inspired by the well-known permutation entropy (PE), an effective image encoding scheme for chaotic time series, Triad State Space Construction (TSSC), is proposed. The TSSC image can recognize higher-order temporal patterns and identify new forbidden regions in time series motifs beyond the Bandt-Pompe probabilities. The Convolutional Neural Network (ConvNet) is widely used in image classification. The ConvNet classifier based on TSSC images (TSSC-ConvNet) are highly accurate and very robust in the chaotic signal classification.
Online Domain Adaptation for Occupancy Mapping
Jul 01, 2020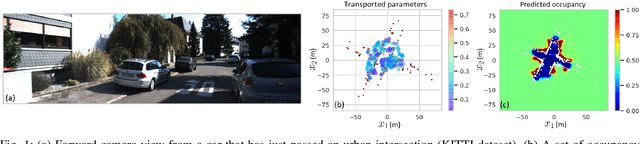
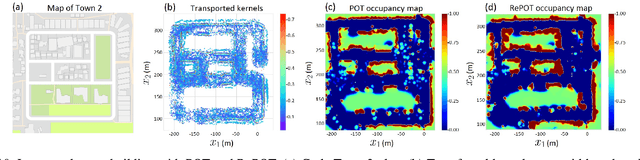
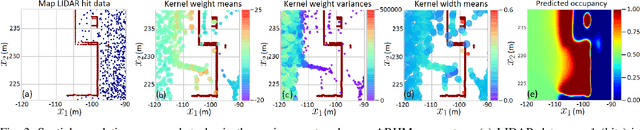
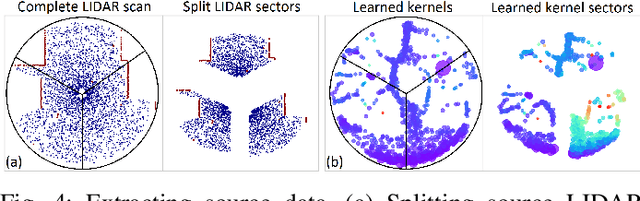
Creating accurate spatial representations that take into account uncertainty is critical for autonomous robots to safely navigate in unstructured environments. Although recent LIDAR based mapping techniques can produce robust occupancy maps, learning the parameters of such models demand considerable computational time, discouraging them from being used in real-time and large-scale applications such as autonomous driving. Recognizing the fact that real-world structures exhibit similar geometric features across a variety of urban environments, in this paper, we argue that it is redundant to learn all geometry dependent parameters from scratch. Instead, we propose a theoretical framework building upon the theory of optimal transport to adapt model parameters to account for changes in the environment, significantly amortizing the training cost. Further, with the use of high-fidelity driving simulators and real-world datasets, we demonstrate how parameters of 2D and 3D occupancy maps can be automatically adapted to accord with local spatial changes. We validate various domain adaptation paradigms through a series of experiments, ranging from inter-domain feature transfer to simulation-to-real-world feature transfer. Experiments verified the possibility of estimating parameters with a negligible computational and memory cost, enabling large-scale probabilistic mapping in urban environments.
Spectral Decomposition in Deep Networks for Segmentation of Dynamic Medical Images
Sep 30, 2020
Dynamic contrast-enhanced magnetic resonance imaging (DCE- MRI) is a widely used multi-phase technique routinely used in clinical practice. DCE and similar datasets of dynamic medical data tend to contain redundant information on the spatial and temporal components that may not be relevant for detection of the object of interest and result in unnecessarily complex computer models with long training times that may also under-perform at test time due to the abundance of noisy heterogeneous data. This work attempts to increase the training efficacy and performance of deep networks by determining redundant information in the spatial and spectral components and show that the performance of segmentation accuracy can be maintained and potentially improved. Reported experiments include the evaluation of training/testing efficacy on a heterogeneous dataset composed of abdominal images of pediatric DCE patients, showing that drastic data reduction (higher than 80%) can preserve the dynamic information and performance of the segmentation model, while effectively suppressing noise and unwanted portion of the images.