 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Model-Based Machine Learning for Joint Digital Backpropagation and PMD Compensation
Oct 23, 2020
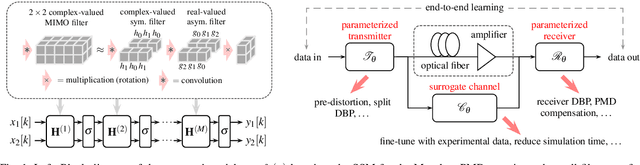
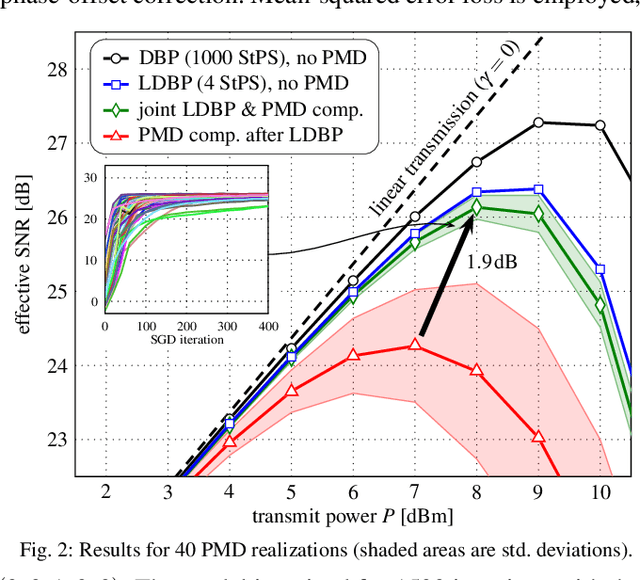
In this paper, we propose a model-based machine-learning approach for dual-polarization systems by parameterizing the split-step Fourier method for the Manakov-PMD equation. The resulting method combines hardware-friendly time-domain nonlinearity mitigation via the recently proposed learned digital backpropagation (LDBP) with distributed compensation of polarization-mode dispersion (PMD). We refer to the resulting approach as LDBP-PMD. We train LDBP-PMD on multiple PMD realizations and show that it converges within 1% of its peak dB performance after 428 training iterations on average, yielding a peak effective signal-to-noise ratio of only 0.30 dB below the PMD-free case. Similar to state-of-the-art lumped PMD compensation algorithms in practical systems, our approach does not assume any knowledge about the particular PMD realization along the link, nor any knowledge about the total accumulated PMD. This is a significant improvement compared to prior work on distributed PMD compensation, where knowledge about the accumulated PMD is typically assumed. We also compare different parameterization choices in terms of performance, complexity, and convergence behavior. Lastly, we demonstrate that the learned models can be successfully retrained after an abrupt change of the PMD realization along the fiber.
Weighted Model Counting in FO2 with Cardinality Constraints and Counting Quantifiers: A Closed Form Formula
Oct 01, 2020Weighted First Order Model Counting (WFOMC) computes the weighted sum of the models of a first order theory on a domain of a given finite size. WFOMC has emerged as a fundamental tool for probabilistic inference. Algorithms for WFOMC that run in polynomial time w.r.t. the domain size are called lifted inference algorithms. Such algorithms have been developed for multiple extensions of FO$^2$(the fragment of First Order Logic with two variables) for the special case of symmetric weight functions. In this paper, instead of developing a specific algorithm, we derive a closed form formula for WFOMC in FO$^2$. The three key advantages of our proposal are: (i) it deals with existential quantifiers without introducing negative weights; (ii) it easily extends to FO$^2$ with cardinality constraints and counting quantifiers (aka C$^2$); finally, (iii) it supports WFOMC for a class of weight functions strictly larger than symmetric weight functions, which can model count distributions, without introducing complex or negative weights.
State space models for building control: how deep should you go?
Oct 23, 2020Power consumption in buildings show non-linear behaviors that linear models cannot capture whereas recurrent neural networks (RNNs) can. This ability makes RNNs attractive alternatives for the model-predictive control (MPC) of buildings. However RNN models lack mathematical regularity which makes their use challenging in optimization problems. This work therefore systematically investigates whether using RNNs for building control provides net gains in an MPC framework. It compares the representation power and control performance of two architectures: a fully non-linear RNN architecture and a linear state-space model with non-linear regressor. The comparison covers five instances of each architecture over two months of simulated operation in identical conditions. The error on the one-hour forecast of temperature is 69% lower with the RNN model than with the linear one. In control the linear state-space model outperforms by 10% on the objective function, shows 2.8 times higher average temperature violations, and needs a third of the computation time the RNN model requires. This work therefore demonstrates that in their current form RNNs do improve accuracy but on balance well-designed linear state-space models with non-linear regressors are best in most cases of MPC.
Exact Indexing for Massive Time Series Databases under Time Warping Distance
Jun 13, 2009


Among many existing distance measures for time series data, Dynamic Time Warping (DTW) distance has been recognized as one of the most accurate and suitable distance measures due to its flexibility in sequence alignment. However, DTW distance calculation is computationally intensive. Especially in very large time series databases, sequential scan through the entire database is definitely impractical, even with random access that exploits some index structures since high dimensionality of time series data incurs extremely high I/O cost. More specifically, a sequential structure consumes high CPU but low I/O costs, while an index structure requires low CPU but high I/O costs. In this work, we therefore propose a novel indexed sequential structure called TWIST (Time Warping in Indexed Sequential sTructure) which benefits from both sequential access and index structure. When a query sequence is issued, TWIST calculates lower bounding distances between a group of candidate sequences and the query sequence, and then identifies the data access order in advance, hence reducing a great number of both sequential and random accesses. Impressively, our indexed sequential structure achieves significant speedup in a querying process by a few orders of magnitude. In addition, our method shows superiority over existing rival methods in terms of query processing time, number of page accesses, and storage requirement with no false dismissal guaranteed.
Primal-Dual $π$ Learning: Sample Complexity and Sublinear Run Time for Ergodic Markov Decision Problems
Oct 17, 2017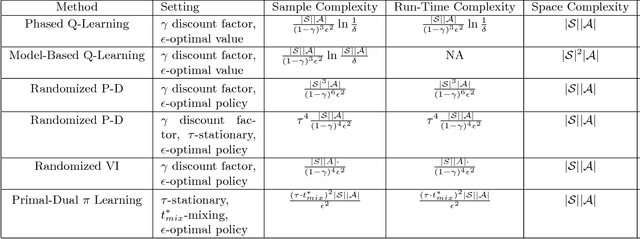
Consider the problem of approximating the optimal policy of a Markov decision process (MDP) by sampling state transitions. In contrast to existing reinforcement learning methods that are based on successive approximations to the nonlinear Bellman equation, we propose a Primal-Dual $\pi$ Learning method in light of the linear duality between the value and policy. The $\pi$ learning method is model-free and makes primal-dual updates to the policy and value vectors as new data are revealed. For infinite-horizon undiscounted Markov decision process with finite state space $S$ and finite action space $A$, the $\pi$ learning method finds an $\epsilon$-optimal policy using the following number of sample transitions $$ \tilde{O}( \frac{(\tau\cdot t^*_{mix})^2 |S| |A| }{\epsilon^2} ),$$ where $t^*_{mix}$ is an upper bound of mixing times across all policies and $\tau$ is a parameter characterizing the range of stationary distributions across policies. The $\pi$ learning method also applies to the computational problem of MDP where the transition probabilities and rewards are explicitly given as the input. In the case where each state transition can be sampled in $\tilde{O}(1)$ time, the $\pi$ learning method gives a sublinear-time algorithm for solving the averaged-reward MDP.
Deep Group-wise Variational Diffeomorphic Image Registration
Oct 01, 2020
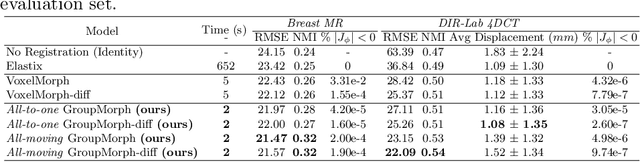
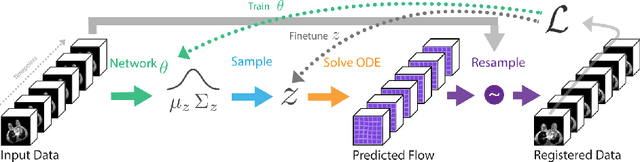
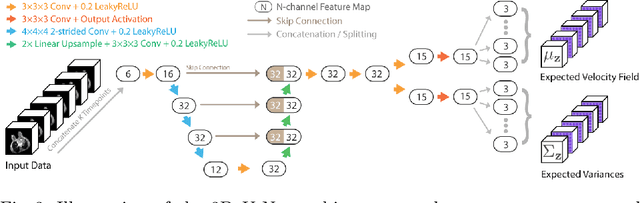
Deep neural networks are increasingly used for pair-wise image registration. We propose to extend current learning-based image registration to allow simultaneous registration of multiple images. To achieve this, we build upon the pair-wise variational and diffeomorphic VoxelMorph approach and present a general mathematical framework that enables both registration of multiple images to their geodesic average and registration in which any of the available images can be used as a fixed image. In addition, we provide a likelihood based on normalized mutual information, a well-known image similarity metric in registration, between multiple images, and a prior that allows for explicit control over the viscous fluid energy to effectively regularize deformations. We trained and evaluated our approach using intra-patient registration of breast MRI and Thoracic 4DCT exams acquired over multiple time points. Comparison with Elastix and VoxelMorph demonstrates competitive quantitative performance of the proposed method in terms of image similarity and reference landmark distances at significantly faster registration.
Impact and dynamics of hate and counter speech online
Sep 18, 2020
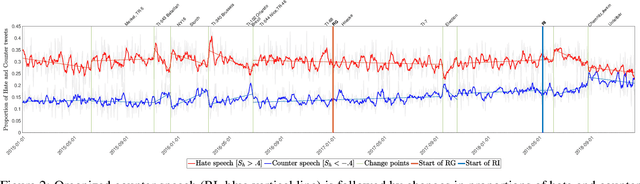
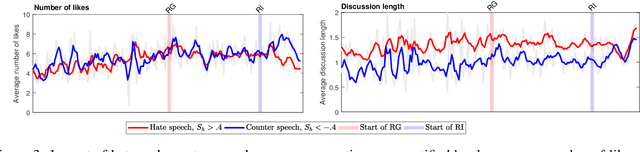
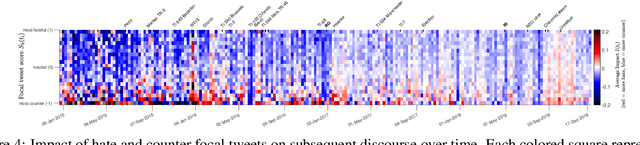
Citizen-generated counter speech is a promising way to fight hate speech and promote peaceful, non-polarized discourse. However, there is a lack of large-scale longitudinal studies of its effectiveness for reducing hate speech. We investigate the effectiveness of counter speech using several different macro- and micro-level measures of over 180,000 political conversations that took place on German Twitter over four years. We report on the dynamic interactions of hate and counter speech over time and provide insights into whether, as in `classic' bullying situations, organized efforts are more effective than independent individuals in steering online discourse. Taken together, our results build a multifaceted picture of the dynamics of hate and counter speech online. They suggest that organized hate speech produced changes in the public discourse. Counter speech, especially when organized, could help in curbing hate speech in online discussions.
A Multi-Plant Disease Diagnosis Method using Convolutional Neural Network
Nov 10, 2020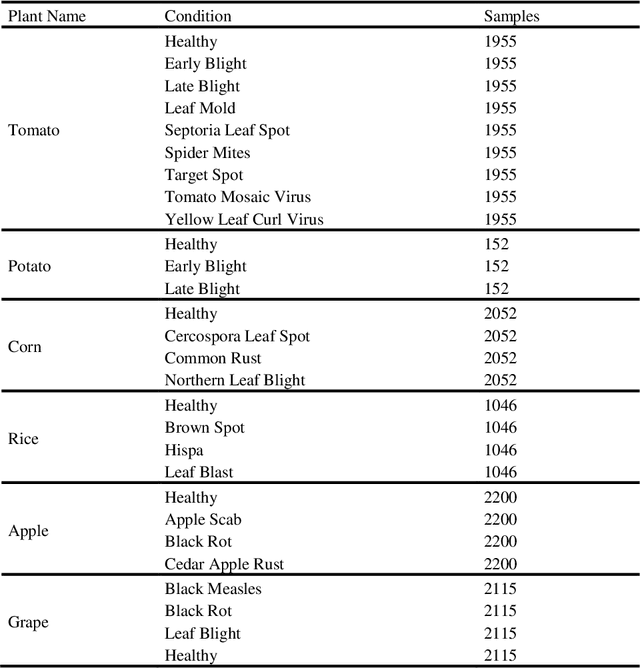

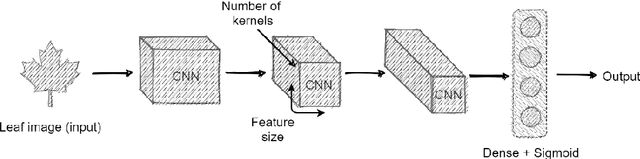
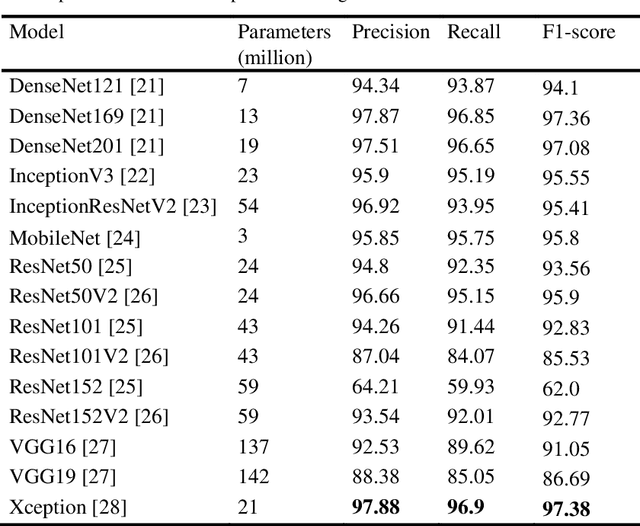
A disease that limits a plant from its maximal capacity is defined as plant disease. From the perspective of agriculture, diagnosing plant disease is crucial, as diseases often limit plants' production capacity. However, manual approaches to recognize plant diseases are often temporal, challenging, and time-consuming. Therefore, computerized recognition of plant diseases is highly desired in the field of agricultural automation. Due to the recent improvement of computer vision, identifying diseases using leaf images of a particular plant has already been introduced. Nevertheless, the most introduced model can only diagnose diseases of a specific plant. Hence, in this chapter, we investigate an optimal plant disease identification model combining the diagnosis of multiple plants. Despite relying on multi-class classification, the model inherits a multilabel classification method to identify the plant and the type of disease in parallel. For the experiment and evaluation, we collected data from various online sources that included leaf images of six plants, including tomato, potato, rice, corn, grape, and apple. In our investigation, we implement numerous popular convolutional neural network (CNN) architectures. The experimental results validate that the Xception and DenseNet architectures perform better in multi-label plant disease classification tasks. Through architectural investigation, we imply that skip connections, spatial convolutions, and shorter hidden layer connectivity cause better results in plant disease classification.
Accelerating Text Mining Using Domain-Specific Stop Word Lists
Nov 18, 2020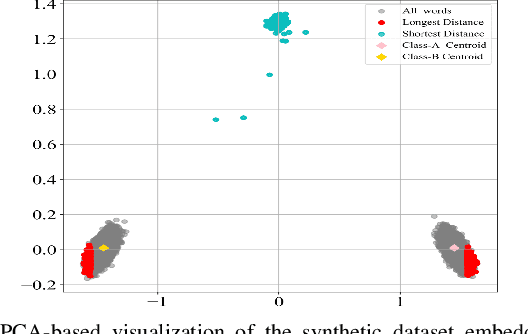
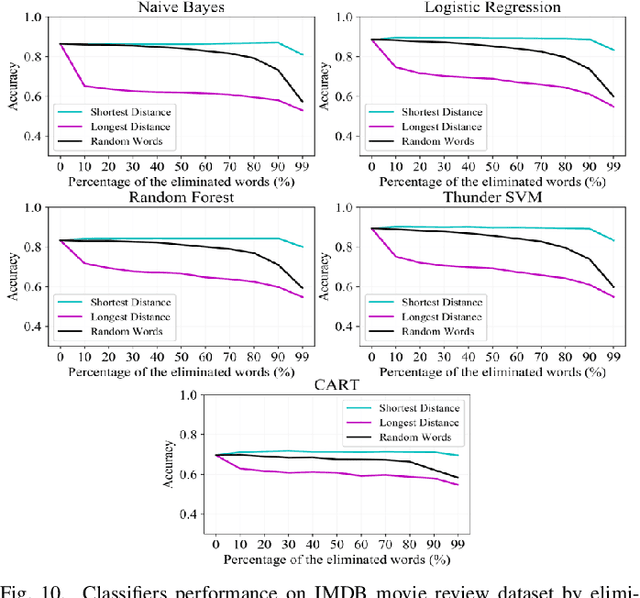
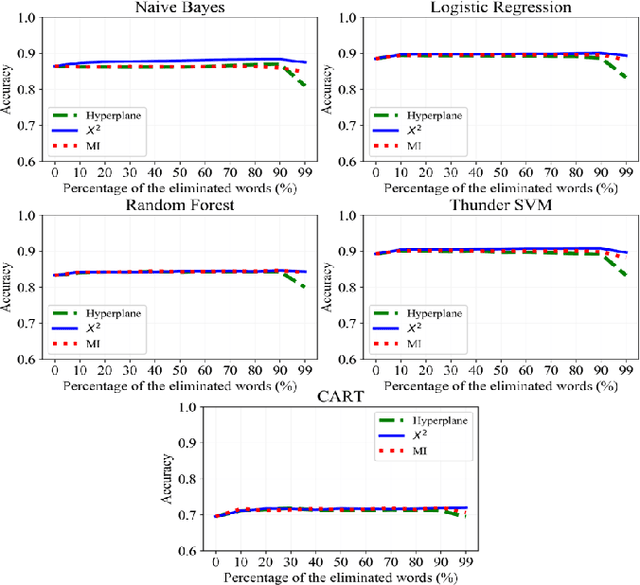
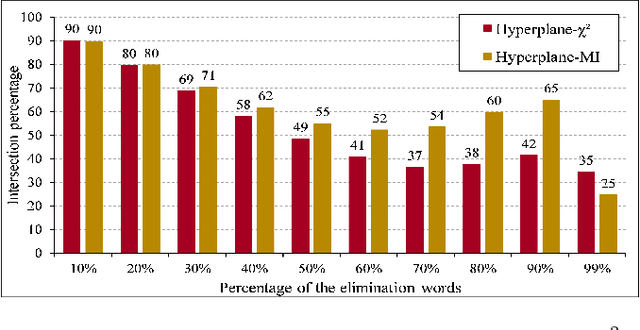
Text preprocessing is an essential step in text mining. Removing words that can negatively impact the quality of prediction algorithms or are not informative enough is a crucial storage-saving technique in text indexing and results in improved computational efficiency. Typically, a generic stop word list is applied to a dataset regardless of the domain. However, many common words are different from one domain to another but have no significance within a particular domain. Eliminating domain-specific common words in a corpus reduces the dimensionality of the feature space, and improves the performance of text mining tasks. In this paper, we present a novel mathematical approach for the automatic extraction of domain-specific words called the hyperplane-based approach. This new approach depends on the notion of low dimensional representation of the word in vector space and its distance from hyperplane. The hyperplane-based approach can significantly reduce text dimensionality by eliminating irrelevant features. We compare the hyperplane-based approach with other feature selection methods, namely \c{hi}2 and mutual information. An experimental study is performed on three different datasets and five classification algorithms, and measure the dimensionality reduction and the increase in the classification performance. Results indicate that the hyperplane-based approach can reduce the dimensionality of the corpus by 90% and outperforms mutual information. The computational time to identify the domain-specific words is significantly lower than mutual information.
Computational tool to study high dimensional dynamic in NMM
Sep 25, 2020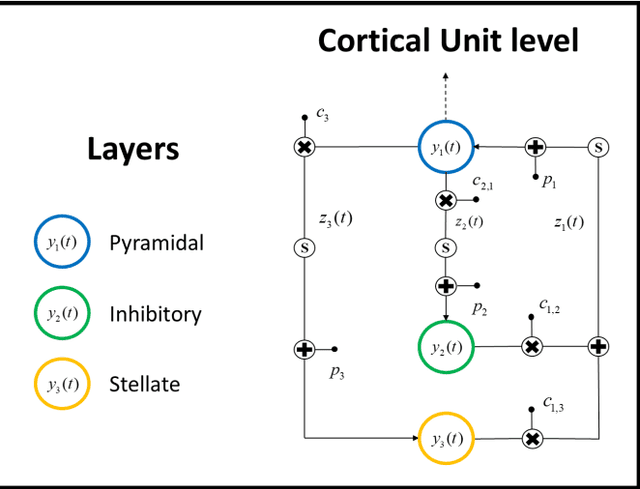
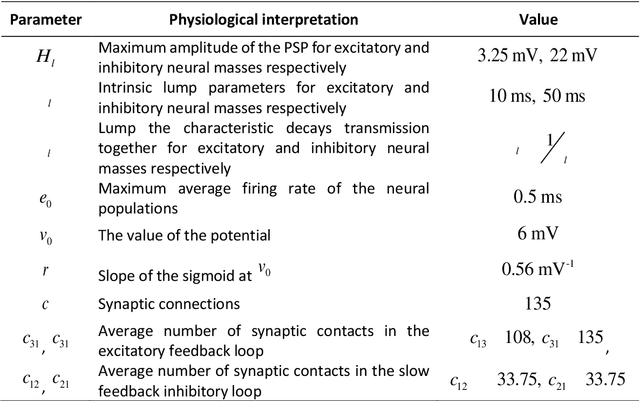
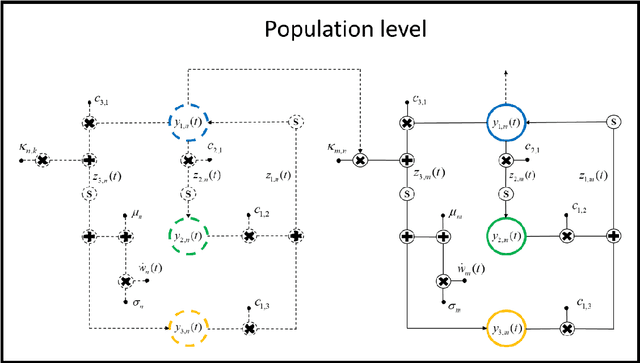

Neuroscience has shown great progress in recent years. Several of the theoretical bases have arisen from the examination of dynamic systems, using Neural Mass Models (NMMs). Due to the largescale brain dynamics of NMMs and the difficulty of studying nonlinear systems, the local linearization approach to discretize the state equation was used via an algebraic formulation, as it intervenes favorably in the speed and efficiency of numerical integration. To study the spacetime organization of the brain and generate more complex dynamics, three structural levels (cortical unit, population and system) were defined and assumed, in which the new assumed representation for conduction delays and new ways of connecting were defined. This is a new time-delay NMM, which can simulate several types of EEG activities since kinetics information was considered at three levels of complexity. Results obtained in this analysis provide additional theoretical foundations and indicate specific characteristics for understanding neurodynamic.