 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
REDE: End-to-end Object 6D Pose Robust Estimation Using Differentiable Outliers Elimination
Oct 24, 2020
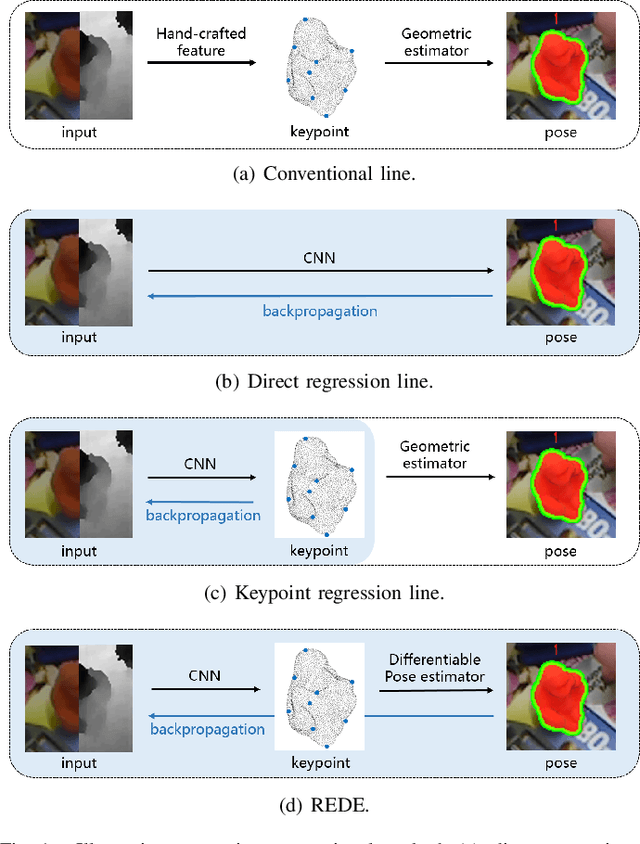
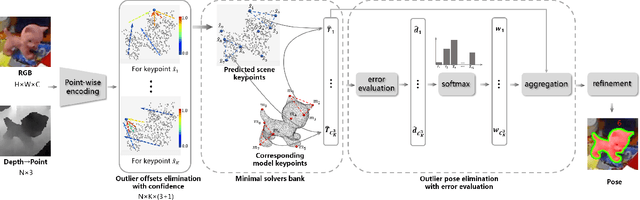
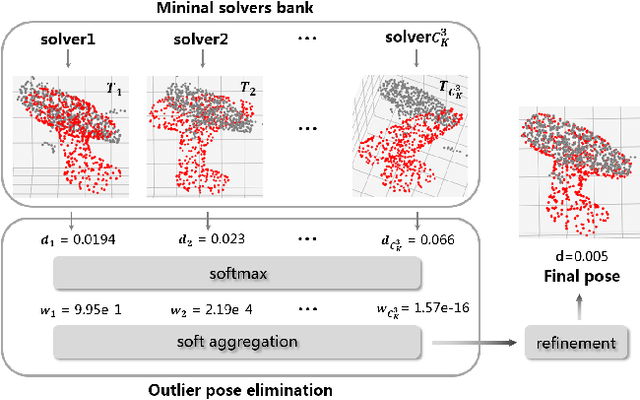

Object 6D pose estimation is a fundamental task in many applications. Conventional methods solve the task by detecting and matching the keypoints, then estimating the pose. Recent efforts bringing deep learning into the problem mainly overcome the vulnerability of conventional methods to environmental variation due to the hand-crafted feature design. However, these methods cannot achieve end-to-end learning and good interpretability at the same time. In this paper, we propose REDE, a novel end-to-end object pose estimator using RGB-D data, which utilizes network for keypoint regression, and a differentiable geometric pose estimator for pose error back-propagation. Besides, to achieve better robustness when outlier keypoint prediction occurs, we further propose a differentiable outliers elimination method that regresses the candidate result and the confidence simultaneously. Via confidence weighted aggregation of multiple candidates, we can reduce the effect from the outliers in the final estimation. Finally, following the conventional method, we apply a learnable refinement process to further improve the estimation. The experimental results on three benchmark datasets show that REDE slightly outperforms the state-of-the-art approaches and is more robust to object occlusion.
Trust-Based Cloud Machine Learning Model Selection For Industrial IoT and Smart City Services
Aug 11, 2020With Machine Learning (ML) services now used in a number of mission-critical human-facing domains, ensuring the integrity and trustworthiness of ML models becomes all-important. In this work, we consider the paradigm where cloud service providers collect big data from resource-constrained devices for building ML-based prediction models that are then sent back to be run locally on the intermittently-connected resource-constrained devices. Our proposed solution comprises an intelligent polynomial-time heuristic that maximizes the level of trust of ML models by selecting and switching between a subset of the ML models from a superset of models in order to maximize the trustworthiness while respecting the given reconfiguration budget/rate and reducing the cloud communication overhead. We evaluate the performance of our proposed heuristic using two case studies. First, we consider Industrial IoT (IIoT) services, and as a proxy for this setting, we use the turbofan engine degradation simulation dataset to predict the remaining useful life of an engine. Our results in this setting show that the trust level of the selected models is 0.49% to 3.17% less compared to the results obtained using Integer Linear Programming (ILP). Second, we consider Smart Cities services, and as a proxy of this setting, we use an experimental transportation dataset to predict the number of cars. Our results show that the selected model's trust level is 0.7% to 2.53% less compared to the results obtained using ILP. We also show that our proposed heuristic achieves an optimal competitive ratio in a polynomial-time approximation scheme for the problem.
A Survey of Deep Learning Architectures for Intelligent Reflecting Surfaces
Sep 19, 2020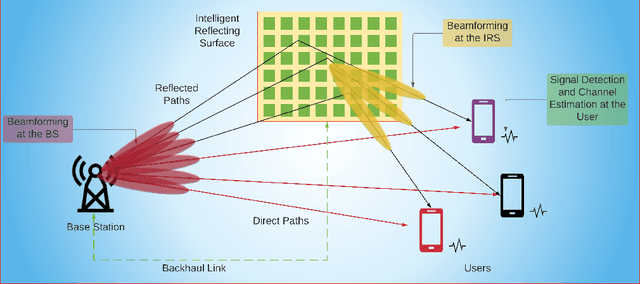
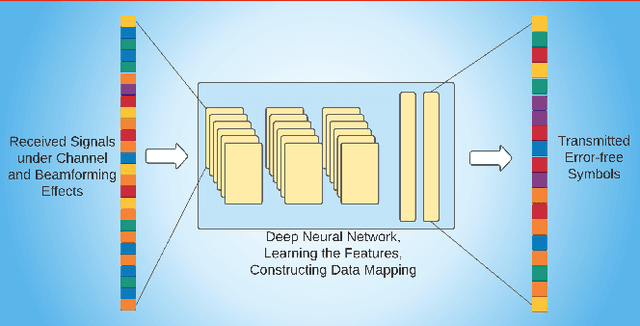
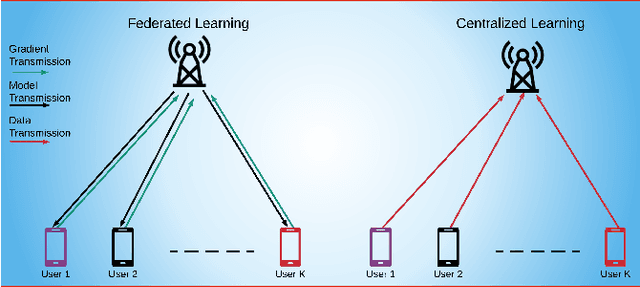
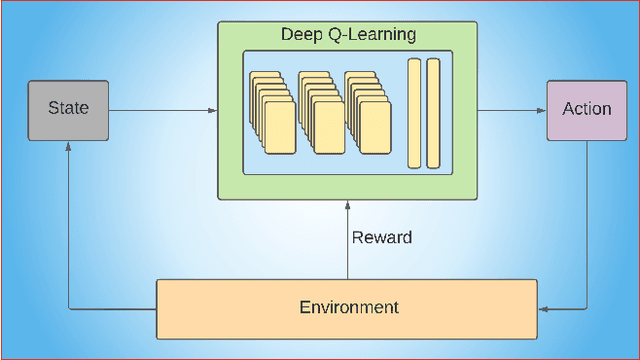
Intelligent reflecting surfaces (IRSs) have recently received significant attention for wireless communications because it reduces the hardware complexity, physical size, weight, and cost of conventional large arrays. However, deployment of IRS entails dealing with multiple channel links between the base station (BS) and the users. Further, the BS and IRS beamformers require a joint design, wherein the IRS elements must be rapidly reconfigured. Data-driven techniques, such as deep learning (DL), are critical in addressing these challenges. The lower computation time and model-free nature of DL makes it robust against the data imperfections and environmental changes. At the physical layer, DL has been shown to be effective for IRS signal detection, channel estimation and active/passive beamforming using architectures such as supervised, unsupervised and reinforcement learning. This article provides a synopsis of these techniques for designing DL-based IRS-assisted wireless systems.
Approximating Aggregated SQL Queries With LSTM Networks
Nov 02, 2020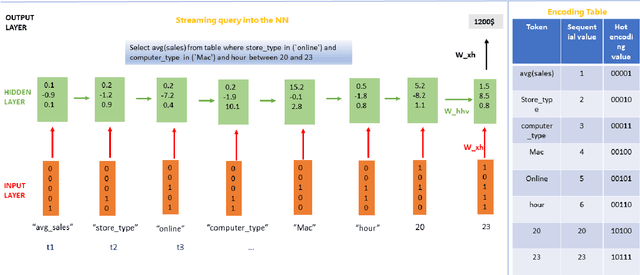
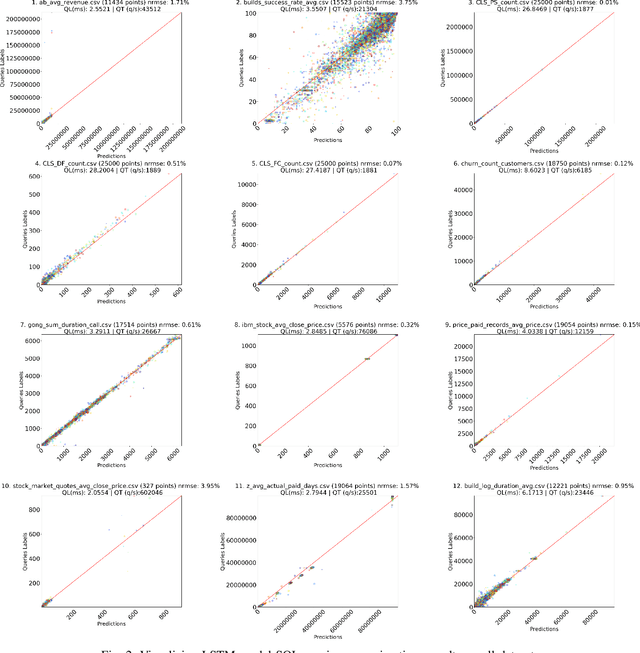
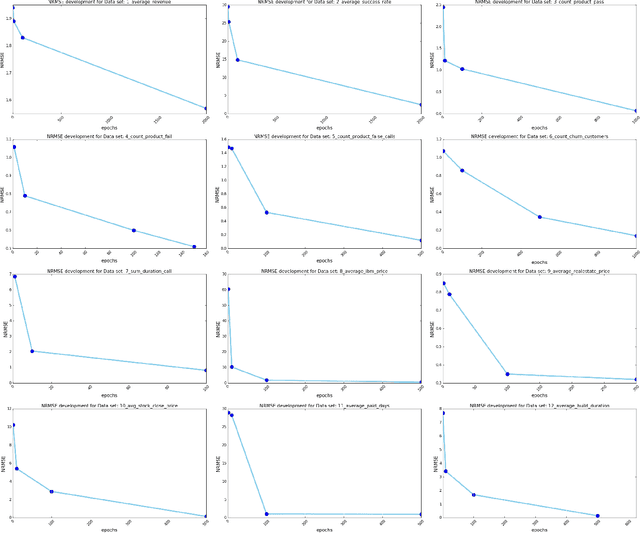
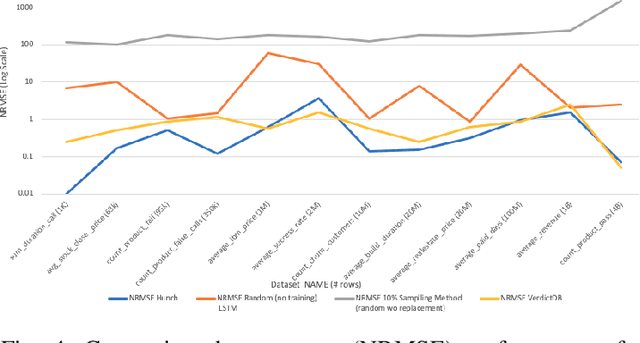
Despite continuous investments in data technologies, the latency of querying data still poses a significant challenge. Modern analytic solutions require near real-time responsiveness both to make them interactive and to support automated processing. Current technologies (Hadoop, Spark, Dataflow) scan the dataset to execute queries. They focus on providing a scalable data storage to maximize task execution speed. We argue that these solutions fail to offer an adequate level of interactivity since they depend on continual access to data. In this paper we present a method for query approximation, also known as approximate query processing (AQP), that reduce the need to scan data during inference (query calculation), thus enabling a rapid query processing tool. We use LSTM network to learn the relationship between queries and their results, and to provide a rapid inference layer for predicting query results. Our method (referred as ``Hunch``) produces a lightweight LSTM network which provides a high query throughput. We evaluated our method using 12 datasets. The results show that our method predicted queries' results with a normalized root mean squared error (NRMSE) ranging from approximately 1\% to 4\%. Moreover, our method was able to predict up to 120,000 queries in a second (streamed together), and with a single query latency of no more than 2ms.
Sparse Communication for Training Deep Networks
Sep 19, 2020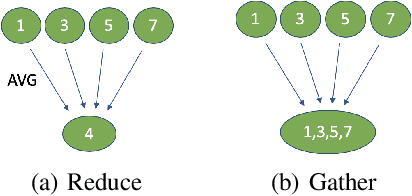
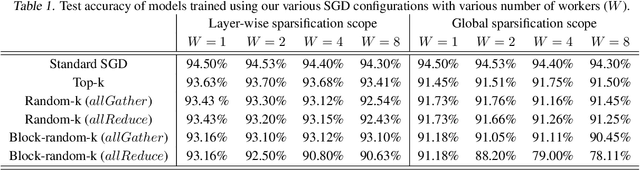
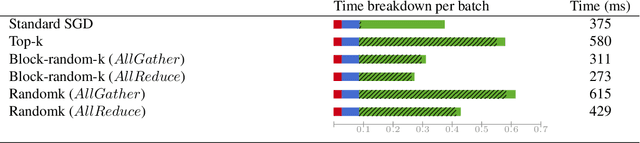
Synchronous stochastic gradient descent (SGD) is the most common method used for distributed training of deep learning models. In this algorithm, each worker shares its local gradients with others and updates the parameters using the average gradients of all workers. Although distributed training reduces the computation time, the communication overhead associated with the gradient exchange forms a scalability bottleneck for the algorithm. There are many compression techniques proposed to reduce the number of gradients that needs to be communicated. However, compressing the gradients introduces yet another overhead to the problem. In this work, we study several compression schemes and identify how three key parameters affect the performance. We also provide a set of insights on how to increase performance and introduce a simple sparsification scheme, random-block sparsification, that reduces communication while keeping the performance close to standard SGD.
Humans learn too: Better Human-AI Interaction using Optimized Human Inputs
Sep 19, 2020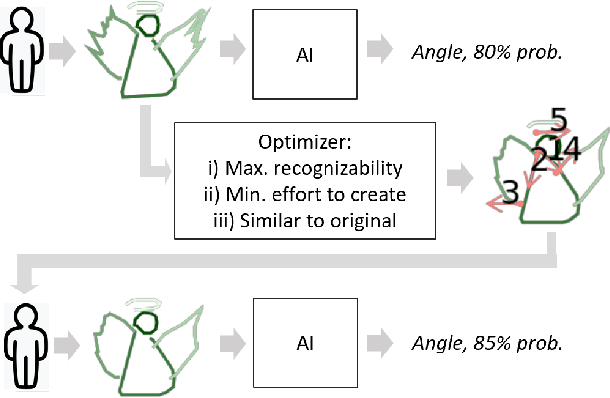
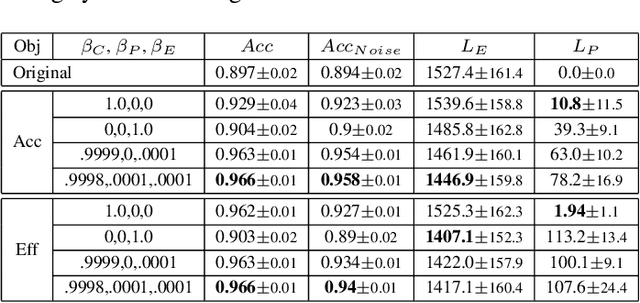
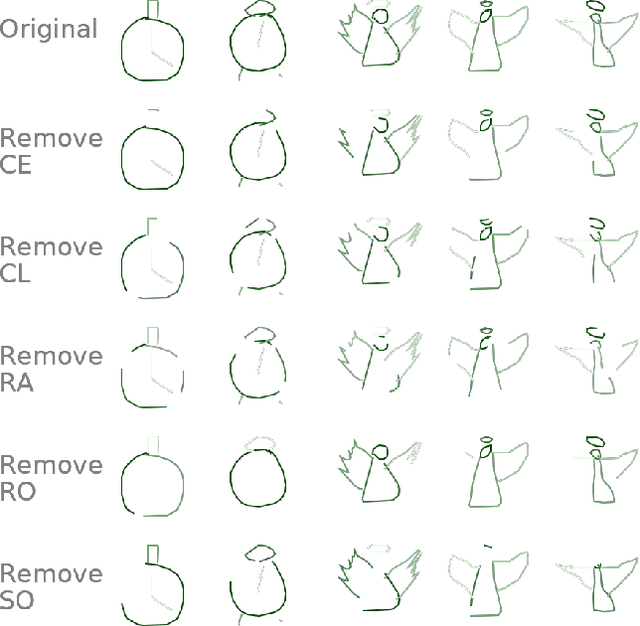
Humans rely more and more on systems with AI components. The AI community typically treats human inputs as a given and optimizes AI models only. This thinking is one-sided and it neglects the fact that humans can learn, too. In this work, human inputs are optimized for better interaction with an AI model while keeping the model fixed. The optimized inputs are accompanied by instructions on how to create them. They allow humans to save time and cut on errors, while keeping required changes to original inputs limited. We propose continuous and discrete optimization methods modifying samples in an iterative fashion. Our quantitative and qualitative evaluation including a human study on different hand-generated inputs shows that the generated proposals lead to lower error rates, require less effort to create and differ only modestly from the original samples.
Learning in School: Multi-teacher Knowledge Inversion for Data-Free Quantization
Nov 19, 2020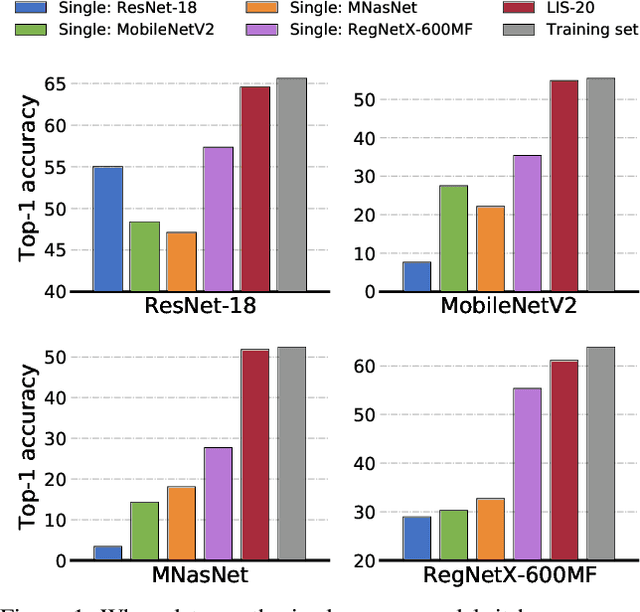
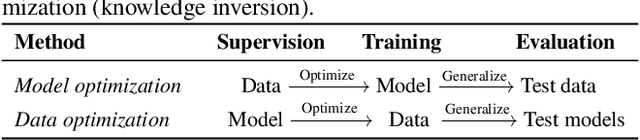
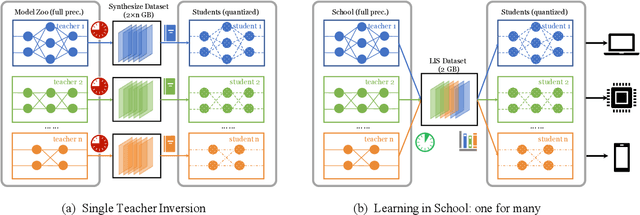
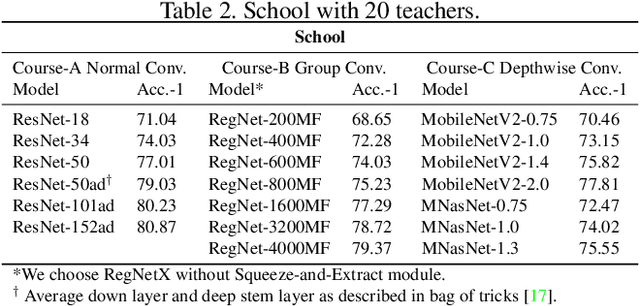
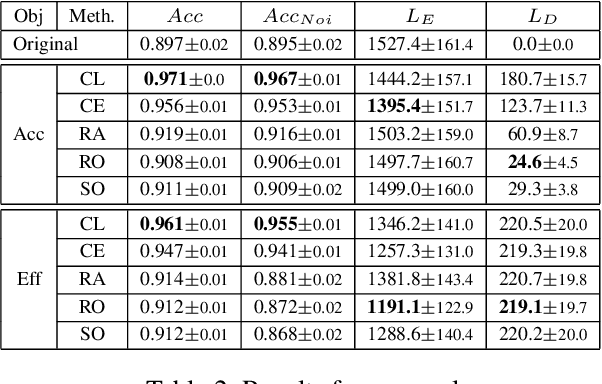
User data confidentiality protection is becoming a rising challenge in the present deep learning research. In that case, data-free quantization has emerged as a promising method to conduct model compression without the need for user data. With no access to data, model quantization naturally becomes less resilient and faces a higher risk of performance degradation. Prior works propose to distill fake images by matching the activation distribution given a specific pre-trained model. However, this fake data cannot be applied to other models easily and is optimized by an invariant objective, resulting in the lack of generalizability and diversity whereas these properties can be found in the natural image dataset. To address these problems, we propose Learning in School~(LIS) algorithm, capable to generate the images suitable for all models by inverting the knowledge in multiple teachers. We further introduce a decentralized training strategy by sampling teachers from hierarchical courses to simultaneously maintain the diversity of generated images. LIS data is highly diverse, not model-specific and only requires one-time synthesis to generalize multiple models and applications. Extensive experiments prove that LIS images resemble natural images with high quality and high fidelity. On data-free quantization, our LIS method significantly surpasses the existing model-specific methods. In particular, LIS data is effective in both post-training quantization and quantization-aware training on the ImageNet dataset and achieves up to 33\% top-1 accuracy uplift compared with existing methods.
$R^3$: Reverse, Retrieve, and Rank for Sarcasm Generation with Commonsense Knowledge
Apr 28, 2020
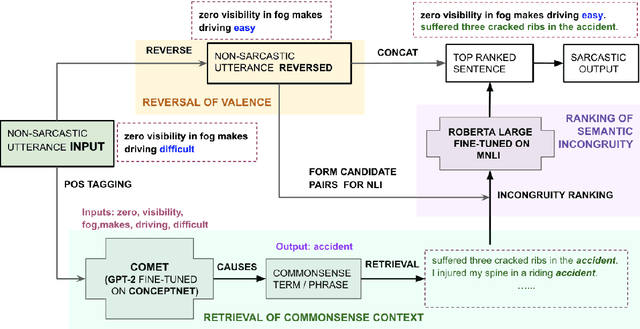
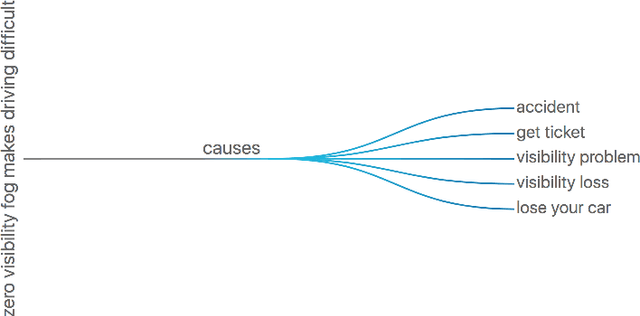
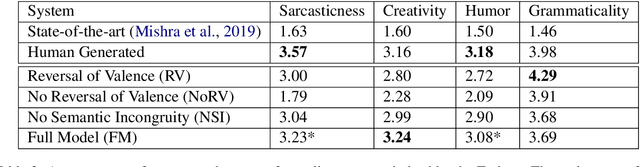
We propose an unsupervised approach for sarcasm generation based on a non-sarcastic input sentence. Our method employs a retrieve-and-edit framework to instantiate two major characteristics of sarcasm: reversal of valence and semantic incongruity with the context which could include shared commonsense or world knowledge between the speaker and the listener. While prior works on sarcasm generation predominantly focus on context incongruity, we show that combining valence reversal and semantic incongruity based on the commonsense knowledge generates sarcasm of higher quality. Human evaluation shows that our system generates sarcasm better than human annotators 34% of the time, and better than a reinforced hybrid baseline 90% of the time.
Multi-Task Learning for Calorie Prediction on a Novel Large-Scale Recipe Dataset Enriched with Nutritional Information
Nov 02, 2020
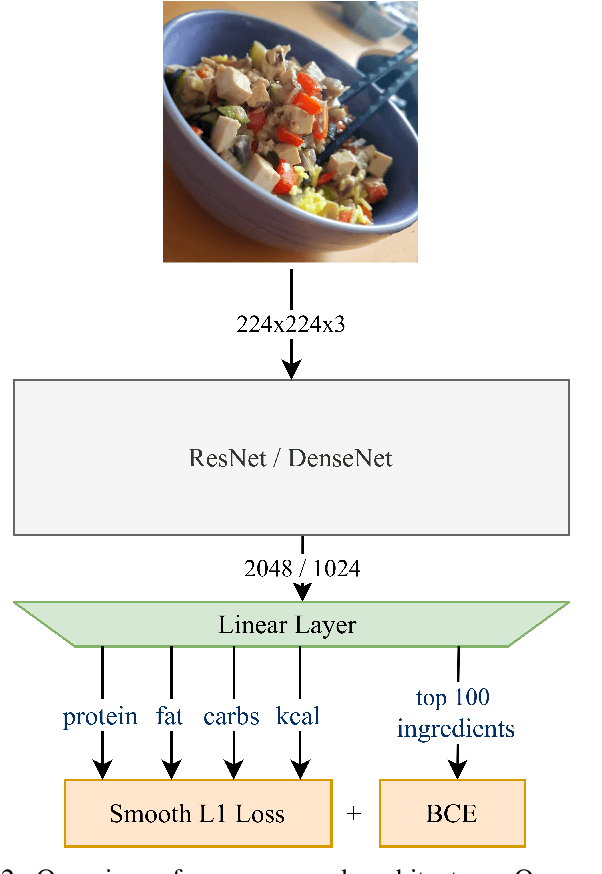
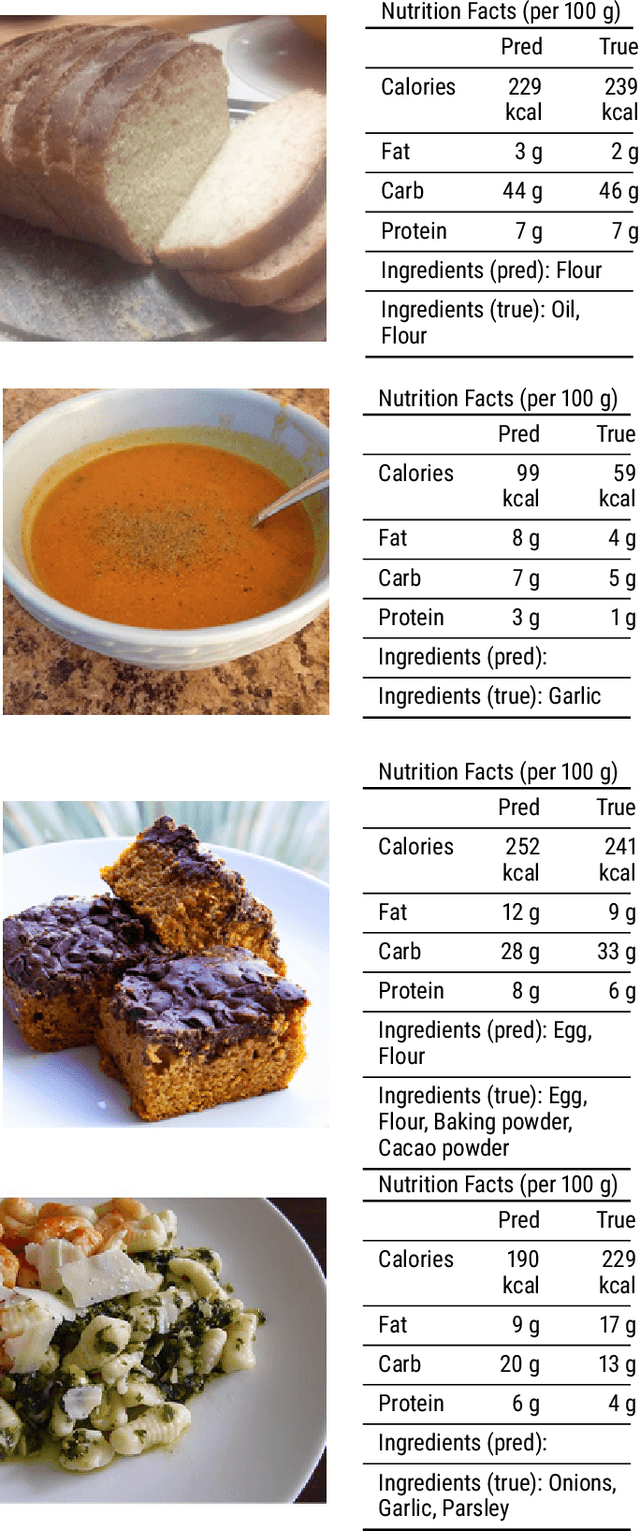
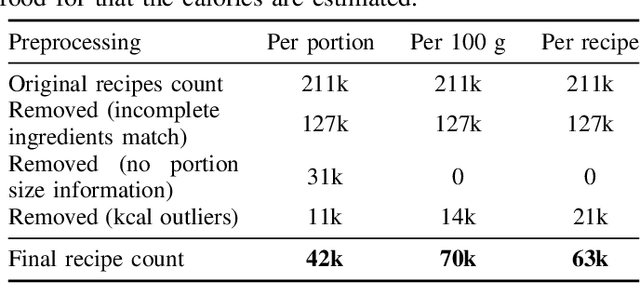
A rapidly growing amount of content posted online, such as food recipes, opens doors to new exciting applications at the intersection of vision and language. In this work, we aim to estimate the calorie amount of a meal directly from an image by learning from recipes people have published on the Internet, thus skipping time-consuming manual data annotation. Since there are few large-scale publicly available datasets captured in unconstrained environments, we propose the pic2kcal benchmark comprising 308,000 images from over 70,000 recipes including photographs, ingredients and instructions. To obtain nutritional information of the ingredients and automatically determine the ground-truth calorie value, we match the items in the recipes with structured information from a food item database. We evaluate various neural networks for regression of the calorie quantity and extend them with the multi-task paradigm. Our learning procedure combines the calorie estimation with prediction of proteins, carbohydrates, and fat amounts as well as a multi-label ingredient classification. Our experiments demonstrate clear benefits of multi-task learning for calorie estimation, surpassing the single-task calorie regression by 9.9%. To encourage further research on this task, we make the code for generating the dataset and the models publicly available.
Towards Interpretable Natural Language Understanding with Explanations as Latent Variables
Oct 24, 2020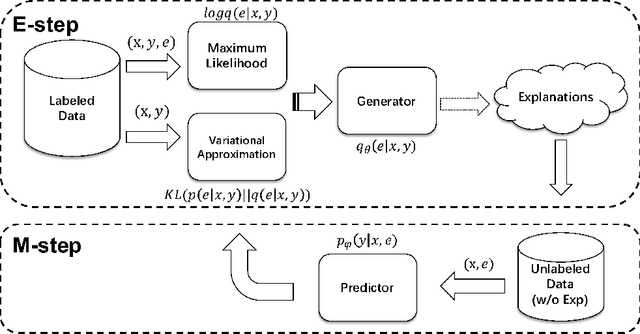

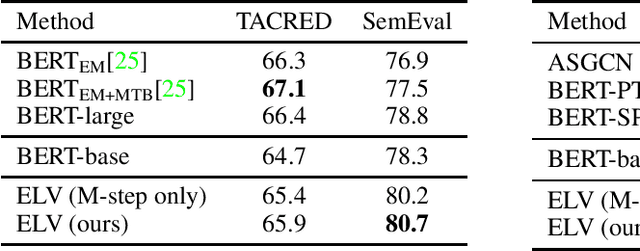
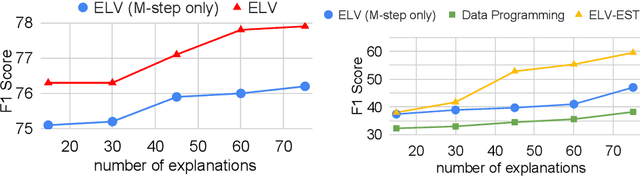
Recently generating natural language explanations has shown very promising results in not only offering interpretable explanations but also providing additional information and supervision for prediction. However, existing approaches usually require a large set of human annotated explanations for training while collecting a large set of explanations is not only time consuming but also expensive. In this paper, we develop a general framework for interpretable natural language understanding that requires only a small set of human annotated explanations for training. Our framework treats natural language explanations as latent variables that model the underlying reasoning process of a neural model. We develop a variational EM framework for optimization where an explanation generation module and an explanation-augmented prediction module are alternatively optimized and mutually enhance each other. Moreover, we further propose an explanation-based self-training method under this framework for semi-supervised learning. It alternates between assigning pseudo-labels to unlabeled data and generating new explanations to iteratively improve each other. Experiments on two natural language understanding tasks demonstrate that our framework can not only make effective predictions in both supervised and semi-supervised settings, but also generate good natural language explanation.