 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Leveraging Natural Language Processing to Mine Issues on Twitter During the COVID-19 Pandemic
Nov 03, 2020
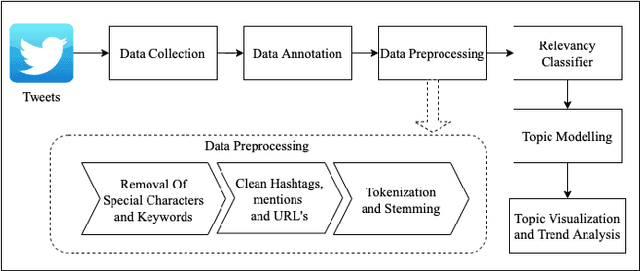
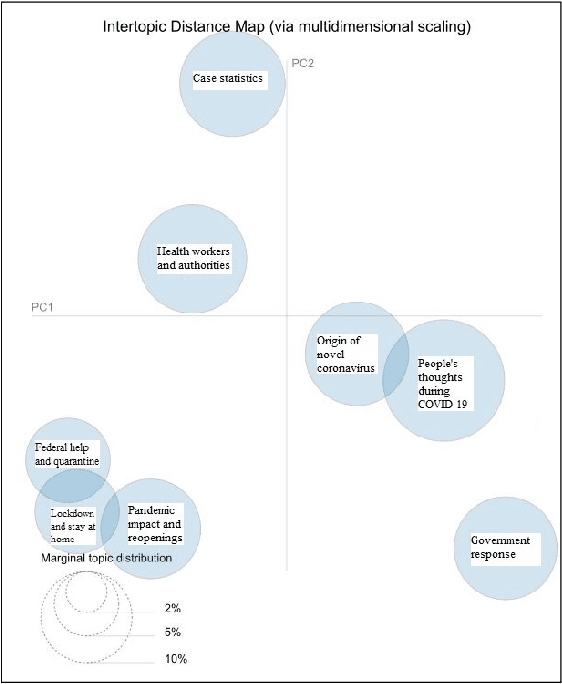
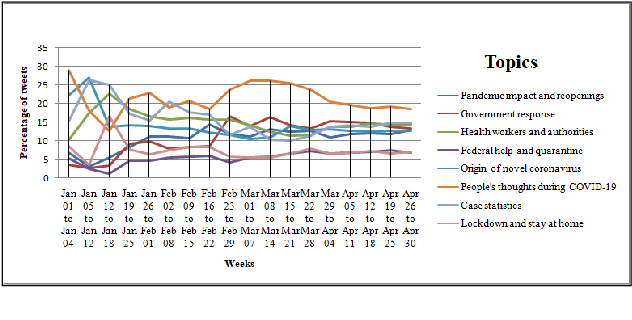
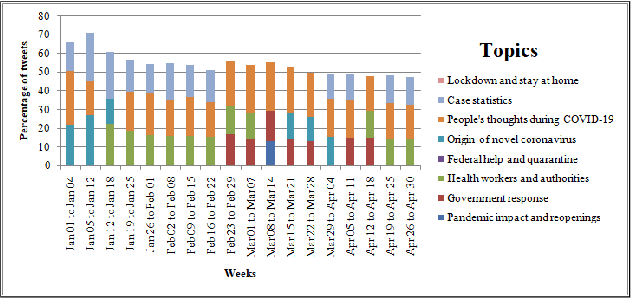
The recent global outbreak of the coronavirus disease (COVID-19) has spread to all corners of the globe. The international travel ban, panic buying, and the need for self-quarantine are among the many other social challenges brought about in this new era. Twitter platforms have been used in various public health studies to identify public opinion about an event at the local and global scale. To understand the public concerns and responses to the pandemic, a system that can leverage machine learning techniques to filter out irrelevant tweets and identify the important topics of discussion on social media platforms like Twitter is needed. In this study, we constructed a system to identify the relevant tweets related to the COVID-19 pandemic throughout January 1st, 2020 to April 30th, 2020, and explored topic modeling to identify the most discussed topics and themes during this period in our data set. Additionally, we analyzed the temporal changes in the topics with respect to the events that occurred during this pandemic. We found out that eight topics were sufficient to identify the themes in our corpus. These topics depicted a temporal trend. The dominant topics vary over time and align with the events related to the COVID-19 pandemic.
A Deeper Look at Discounting Mismatch in Actor-Critic Algorithms
Oct 02, 2020
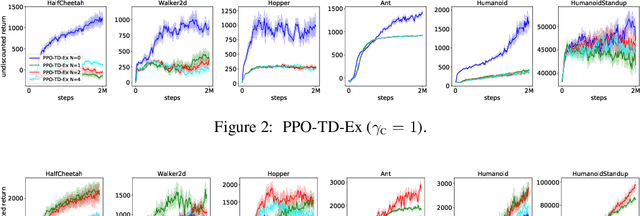
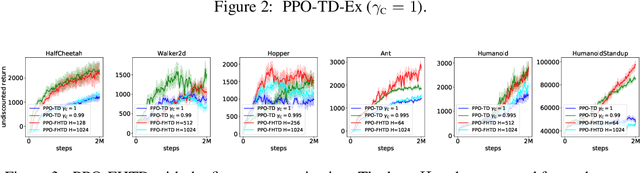

We investigate the discounting mismatch in actor-critic algorithm implementations from a representation learning perspective. Theoretically, actor-critic algorithms usually have discounting for both actor and critic, i.e., there is a $\gamma^t$ term in the actor update for the transition observed at time $t$ in a trajectory and the critic is a discounted value function. Practitioners, however, usually ignore the discounting ($\gamma^t$) for the actor while using a discounted critic. We investigate this mismatch in two scenarios. In the first scenario, we consider optimizing an undiscounted objective $(\gamma = 1)$ where $\gamma^t$ disappears naturally $(1^t = 1)$. We then propose to interpret the discounting in critic in terms of a bias-variance-representation trade-off and provide supporting empirical results. In the second scenario, we consider optimizing a discounted objective ($\gamma < 1$) and propose to interpret the omission of the discounting in the actor update from an auxiliary task perspective and provide supporting empirical results.
Rotation Averaging with Attention Graph Neural Networks
Oct 14, 2020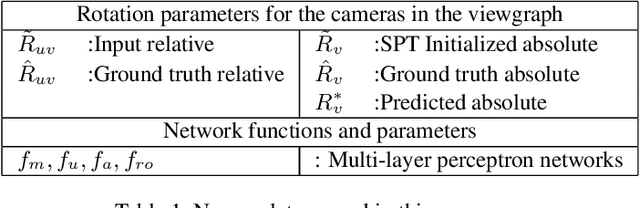
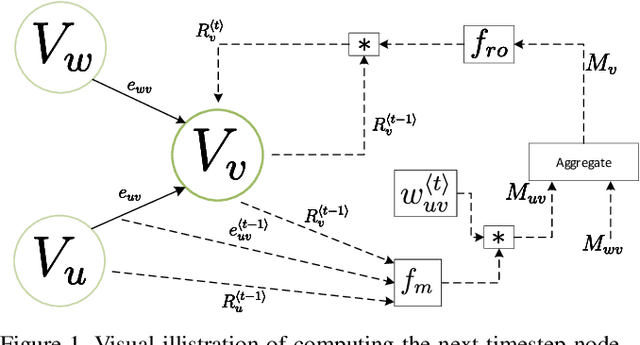
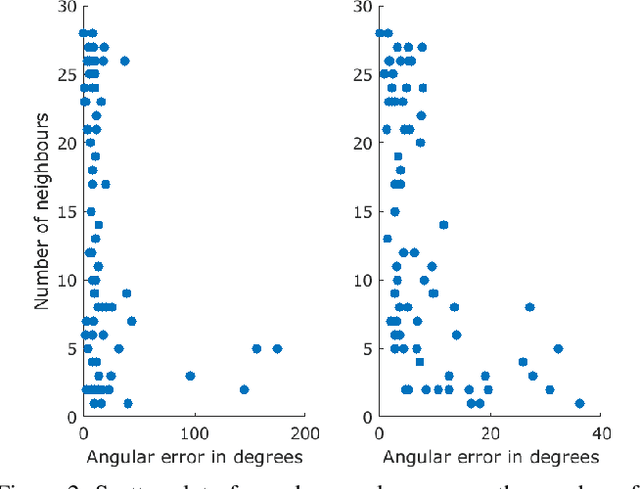

In this paper we propose a real-time and robust solution to large-scale multiple rotation averaging. Until recently, Multiple rotation averaging problem had been solved using conventional iterative optimization algorithms. Such methods employed robust cost functions that were chosen based on assumptions made about the sensor noise and outlier distribution. In practice, these assumptions do not always fit real datasets very well. A recent work showed that the noise distribution could be learnt using a graph neural network. This solution required a second network for outlier detection and removal as the averaging network was sensitive to a poor initialization. In this paper we propose a single-stage graph neural network that can robustly perform rotation averaging in the presence of noise and outliers. Our method uses all observations, suppressing outliers effects through the use of weighted averaging and an attention mechanism within the network design. The result is a network that is faster, more robust and can be trained with less samples than the previous neural approach, ultimately outperforming conventional iterative algorithms in accuracy and in inference times.
Better Together: Resnet-50 accuracy with $13x$ fewer parameters and at $3x$ speed
Jun 10, 2020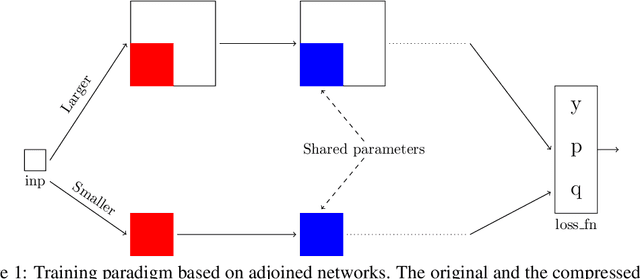
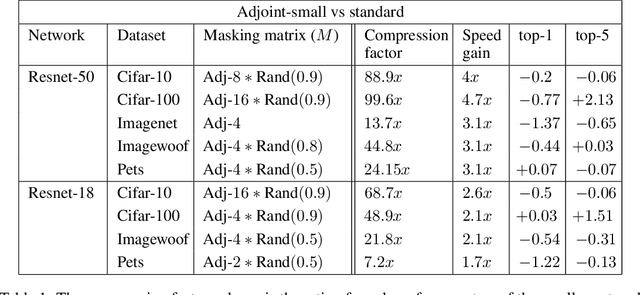
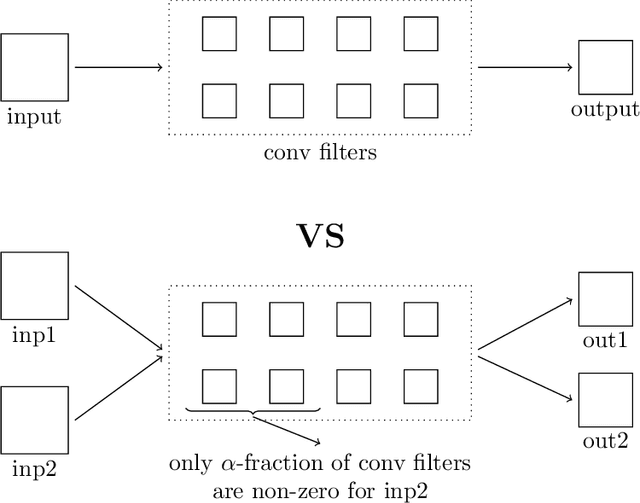
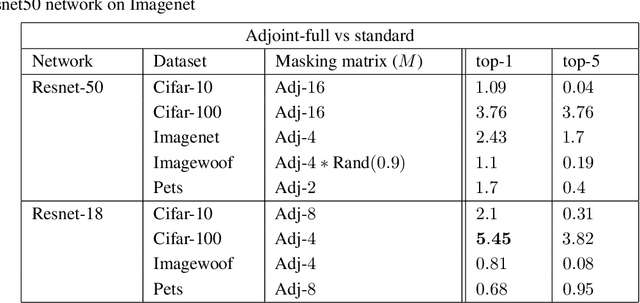
Recent research on compressing deep neural networks has focused on reducing the number of parameters. Smaller networks are easier to export and deploy on edge-devices. We introduce Adjoined networks as a training approach that can compress and regularize any CNN-based neural architecture. Our one-shot learning paradigm trains both the original and the smaller networks together. The parameters of the smaller network are shared across both the architectures. For resnet-50 trained on Imagenet, we are able to achieve a $13.7x$ reduction in the number of parameters and a $3x$ improvement in inference time without any significant drop in accuracy. For the same architecture on CIFAR-100, we are able to achieve a $99.7x$ reduction in the number of parameters and a $5x$ improvement in inference time. On both these datasets, the original network trained in the adjoint fashion gains about $3\%$ in top-1 accuracy as compared to the same network trained in the standard fashion.
The Rise of AI-Driven Simulators: Building a New Crystal Ball
Dec 11, 2020The use of computational simulation is by now so pervasive in society that it is no exaggeration to say that continued U.S. and international prosperity, security, and health depend in part on continued improvements in simulation capabilities. What if we could predict weather two weeks out, guide the design of new drugs for new viral diseases, or manage new manufacturing processes that cut production costs and times by an order of magnitude? What if we could predict collective human behavior, for example, response to an evacuation request during a natural disaster, or labor response to fiscal stimulus? (See also the companion CCC Quad Paper on Pandemic Informatics, which discusses features that would be essential to solving large-scale problems like preparation for, and response to, the inevitable next pandemic.) The past decade has brought remarkable advances in complementary areas: in sensors, which can now capture enormous amounts of data about the world, and in AI methods capable of learning to extract predictive patterns from those data. These advances may lead to a new era in computational simulation, in which sensors of many kinds are used to produce vast quantities of data, AI methods identify patterns in those data, and new AI-driven simulators combine machine-learned and mathematical rules to make accurate and actionable predictions. At the same time, there are new challenges -- computers in some important regards are no longer getting faster, and in some areas we are reaching the limits of mathematical understanding, or at least of our ability to translate mathematical understanding into efficient simulation. In this paper, we lay out some themes that we envision forming part of a cohesive, multi-disciplinary, and application-inspired research agenda on AI-driven simulators.
NeuroLogic Decoding: (Un)supervised Neural Text Generation with Predicate Logic Constraints
Oct 24, 2020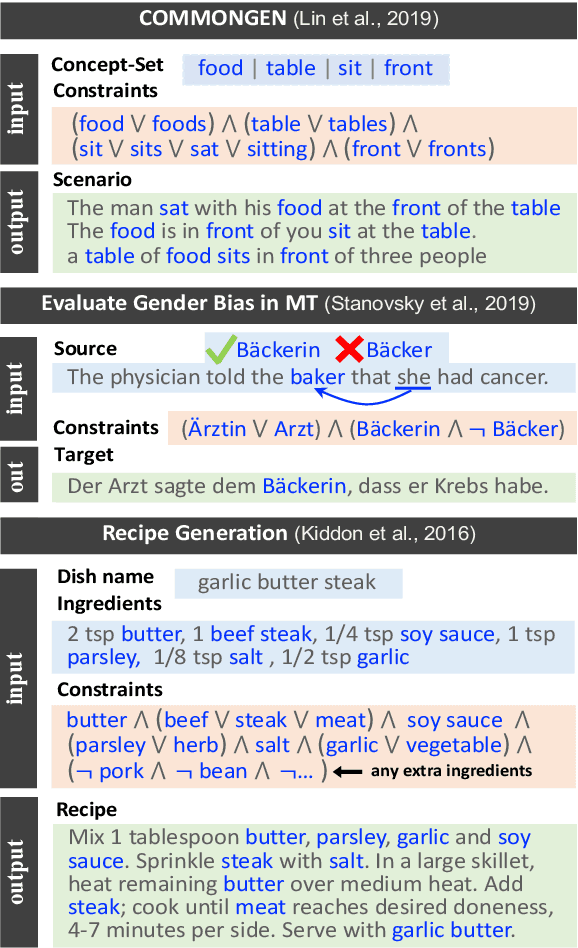
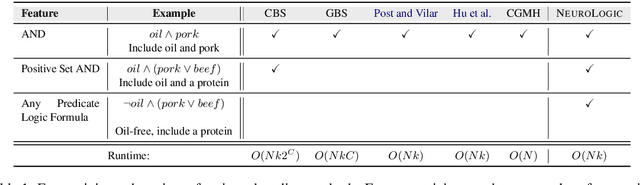
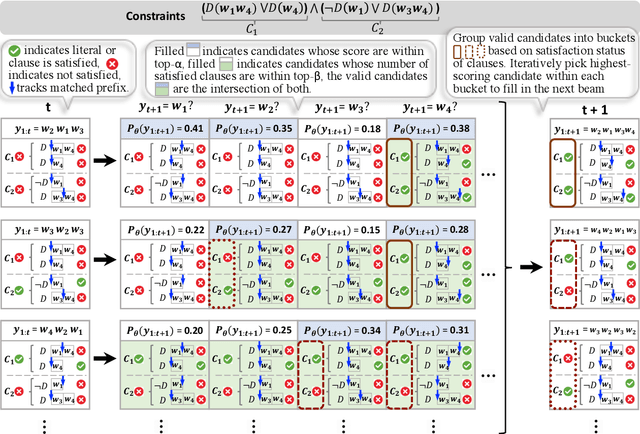
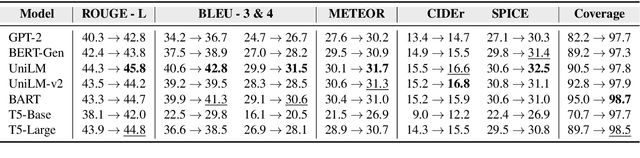
Conditional text generation often requires lexical constraints, i.e., which words should or shouldn't be included in the output text. While the dominant recipe for conditional text generation has been large-scale pretrained language models that are finetuned on the task-specific training data, such models do not learn to follow the underlying constraints reliably, even when supervised with large amounts of task-specific examples. We propose NeuroLogic Decoding, a simple yet effective algorithm that enables neural language models -- supervised or not -- to generate fluent text while satisfying complex lexical constraints. Our approach is powerful yet efficient. It handles any set of lexical constraints that is expressible under predicate logic, while its asymptotic runtime is equivalent to conventional beam search. Empirical results on four benchmarks show that NeuroLogic Decoding outperforms previous approaches, including algorithms that handle a subset of our constraints. Moreover, we find that unsupervised models with NeuroLogic Decoding often outperform supervised models with conventional decoding, even when the latter is based on considerably larger networks. Our results suggest the limit of large-scale neural networks for fine-grained controllable generation and the promise of inference-time algorithms.
Understanding Boolean Function Learnability on Deep Neural Networks
Sep 13, 2020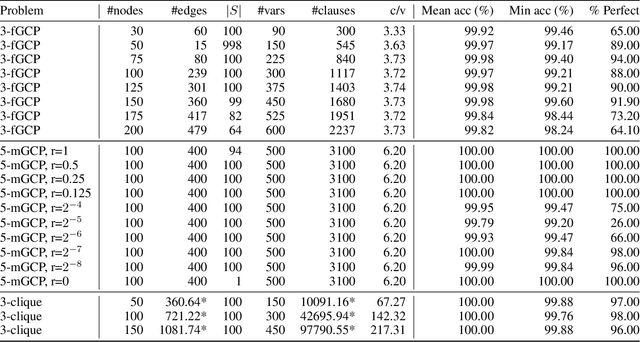
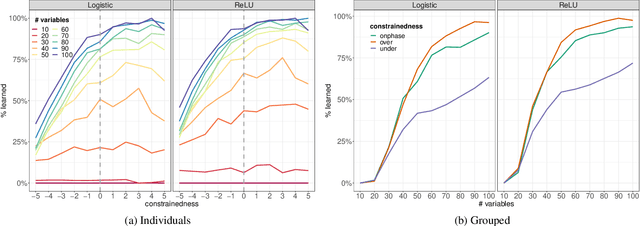
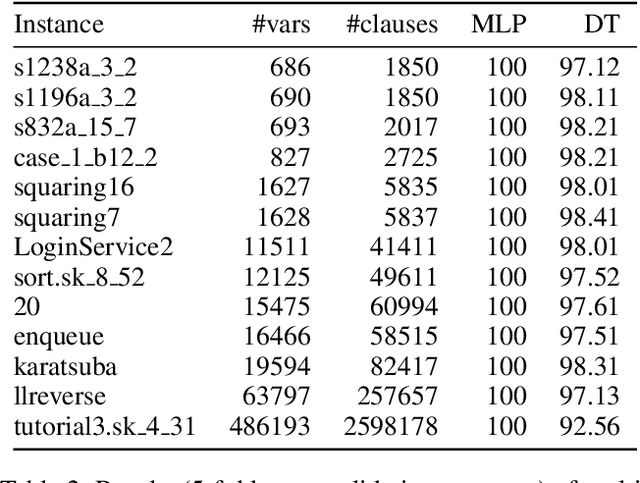
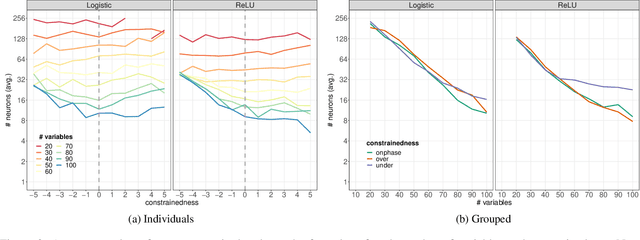
Computational learning theory states that many classes of boolean formulas are learnable in polynomial time. This paper addresses the understudied subject of how, in practice, such formulas can be learned by deep neural networks. Specifically, we analyse boolean formulas associated with the decision version of combinatorial optimisation problems, model sampling benchmarks, and random 3-CNFs with varying degrees of constrainedness. Our extensive experiments indicate that: (i) regardless of the combinatorial optimisation problem, relatively small and shallow neural networks are very good approximators of the associated formulas; (ii) smaller formulas seem harder to learn, possibly due to the fewer positive (satisfying) examples available; and (iii) interestingly, underconstrained 3-CNF formulas are more challenging to learn than overconstrained ones. Source code and relevant datasets are publicly available (https://github.com/machine-reasoning-ufrgs/mlbf).
Impact of Community Structure on Consensus Machine Learning
Nov 02, 2020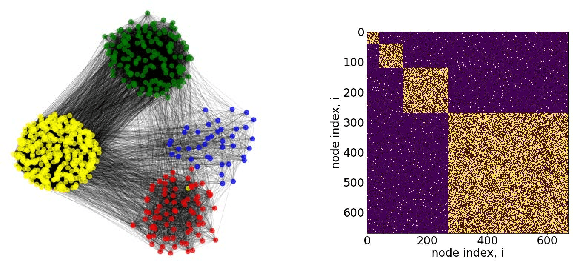
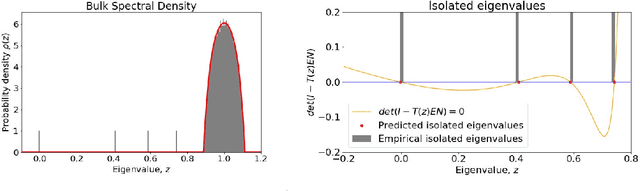
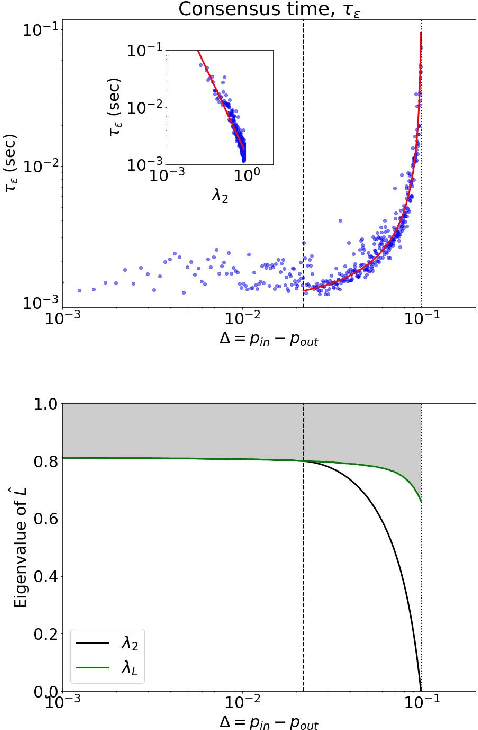
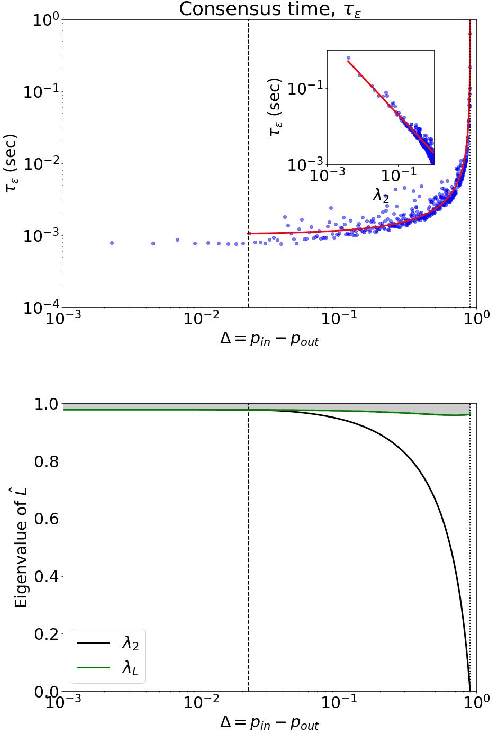
Consensus dynamics support decentralized machine learning for data that is distributed across a cloud compute cluster or across the internet of things. In these and other settings, one seeks to minimize the time $\tau_\epsilon$ required to obtain consensus within some $\epsilon>0$ margin of error. $\tau_\epsilon$ typically depends on the topology of the underlying communication network, and for many algorithms $\tau_\epsilon$ depends on the second-smallest eigenvalue $\lambda_2\in[0,1]$ of the network's normalized Laplacian matrix: $\tau_\epsilon\sim\mathcal{O}(\lambda_2^{-1})$. Here, we analyze the effect on $\tau_\epsilon$ of network community structure, which can arise when compute nodes/sensors are spatially clustered, for example. We study consensus machine learning over networks drawn from stochastic block models, which yield random networks that can contain heterogeneous communities with different sizes and densities. Using random matrix theory, we analyze the effects of communities on $\lambda_2$ and consensus, finding that $\lambda_2$ generally increases (i.e., $\tau_\epsilon$ decreases) as one decreases the extent of community structure. We further observe that there exists a critical level of community structure at which $\tau_\epsilon$ reaches a lower bound and is no longer limited by the presence of communities. We support our findings with empirical experiments for decentralized support vector machines.
Does the brain function as a quantum phase computer using phase ternary computation?
Dec 04, 2020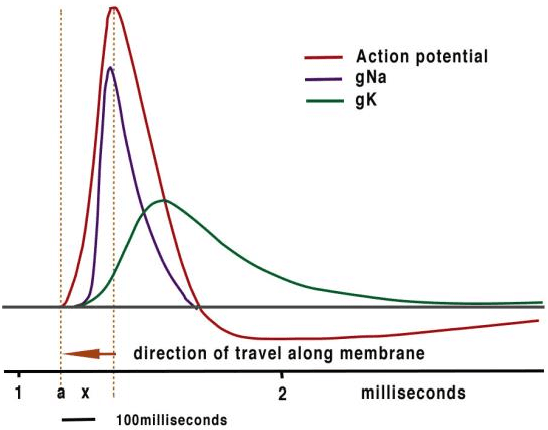
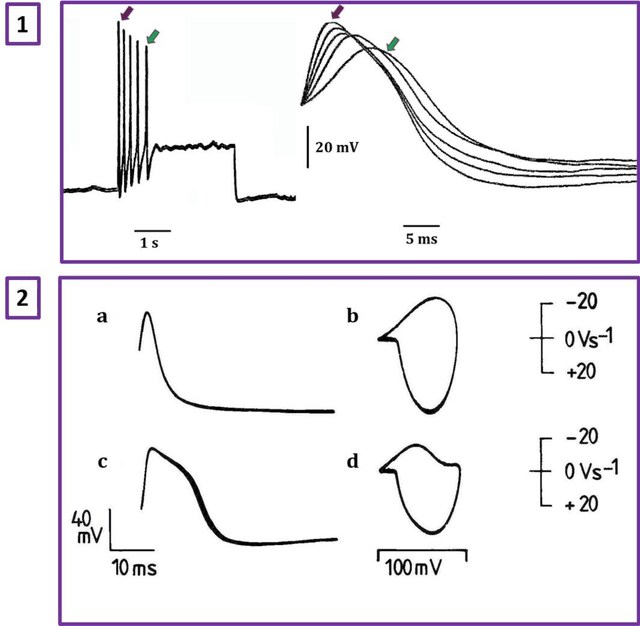
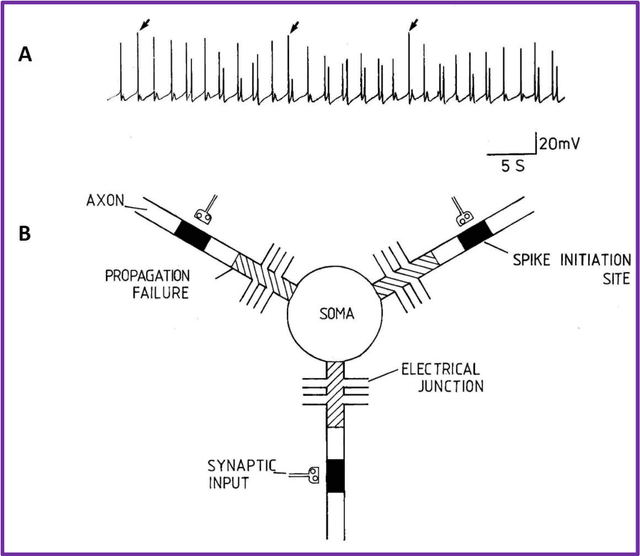
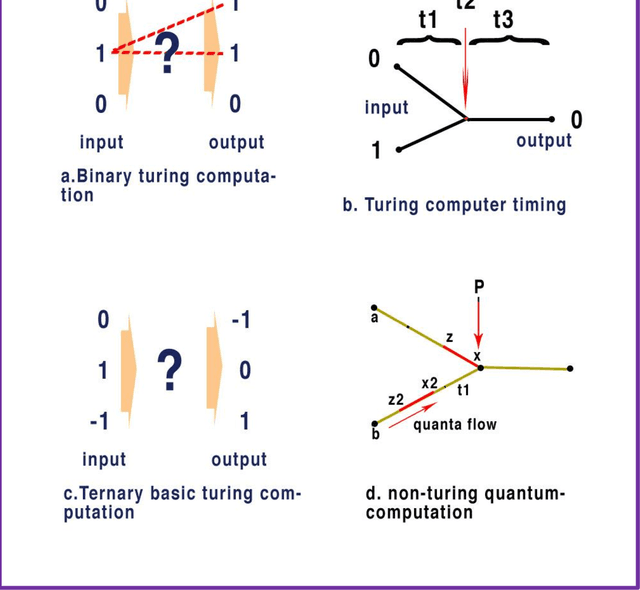
Here we provide evidence that the fundamental basis of nervous communication is derived from a pressure pulse/soliton capable of computation with sufficient temporal precision to overcome any processing errors. Signalling and computing within the nervous system are complex and different phenomena. Action potentials are plastic and this makes the action potential peak an inappropriate fixed point for neural computation, but the action potential threshold is suitable for this purpose. Furthermore, neural models timed by spiking neurons operate below the rate necessary to overcome processing error. Using retinal processing as our example, we demonstrate that the contemporary theory of nerve conduction based on cable theory is inappropriate to account for the short computational time necessary for the full functioning of the retina and by implication the rest of the brain. Moreover, cable theory cannot be instrumental in the propagation of the action potential because at the activation-threshold there is insufficient charge at the activation site for successive ion channels to be electrostatically opened. Deconstruction of the brain neural network suggests that it is a member of a group of Quantum phase computers of which the Turing machine is the simplest: the brain is another based upon phase ternary computation. However, attempts to use Turing based mechanisms cannot resolve the coding of the retina or the computation of intelligence, as the technology of Turing based computers is fundamentally different. We demonstrate that that coding in the brain neural network is quantum based, where the quanta have a temporal variable and a phase-base variable enabling phase ternary computation as previously demonstrated in the retina.
Trust-Based Cloud Machine Learning Model Selection For Industrial IoT and Smart City Services
Aug 11, 2020With Machine Learning (ML) services now used in a number of mission-critical human-facing domains, ensuring the integrity and trustworthiness of ML models becomes all-important. In this work, we consider the paradigm where cloud service providers collect big data from resource-constrained devices for building ML-based prediction models that are then sent back to be run locally on the intermittently-connected resource-constrained devices. Our proposed solution comprises an intelligent polynomial-time heuristic that maximizes the level of trust of ML models by selecting and switching between a subset of the ML models from a superset of models in order to maximize the trustworthiness while respecting the given reconfiguration budget/rate and reducing the cloud communication overhead. We evaluate the performance of our proposed heuristic using two case studies. First, we consider Industrial IoT (IIoT) services, and as a proxy for this setting, we use the turbofan engine degradation simulation dataset to predict the remaining useful life of an engine. Our results in this setting show that the trust level of the selected models is 0.49% to 3.17% less compared to the results obtained using Integer Linear Programming (ILP). Second, we consider Smart Cities services, and as a proxy of this setting, we use an experimental transportation dataset to predict the number of cars. Our results show that the selected model's trust level is 0.7% to 2.53% less compared to the results obtained using ILP. We also show that our proposed heuristic achieves an optimal competitive ratio in a polynomial-time approximation scheme for the problem.