 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Complementary Meta-Reinforcement Learning for Fault-Adaptive Control
Sep 26, 2020

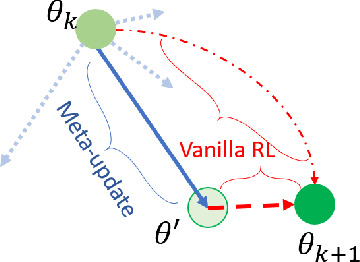
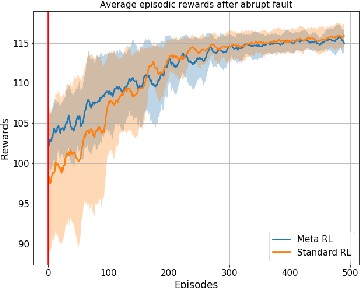
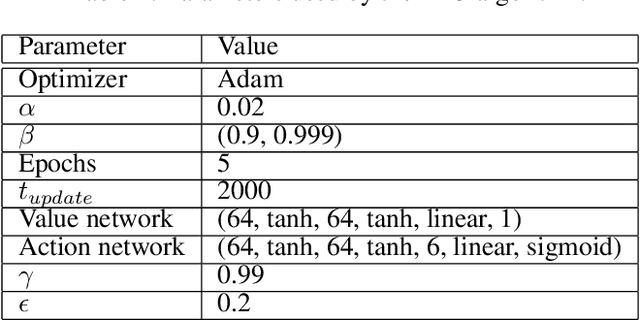
Faults are endemic to all systems. Adaptive fault-tolerant control maintains degraded performance when faults occur as opposed to unsafe conditions or catastrophic events. In systems with abrupt faults and strict time constraints, it is imperative for control to adapt quickly to system changes to maintain system operations. We present a meta-reinforcement learning approach that quickly adapts its control policy to changing conditions. The approach builds upon model-agnostic meta learning (MAML). The controller maintains a complement of prior policies learned under system faults. This "library" is evaluated on a system after a new fault to initialize the new policy. This contrasts with MAML, where the controller derives intermediate policies anew, sampled from a distribution of similar systems, to initialize a new policy. Our approach improves sample efficiency of the reinforcement learning process. We evaluate our approach on an aircraft fuel transfer system under abrupt faults.
Evolutionary Multi-Objective Design of SARS-CoV-2 Protease Inhibitor Candidates
May 06, 2020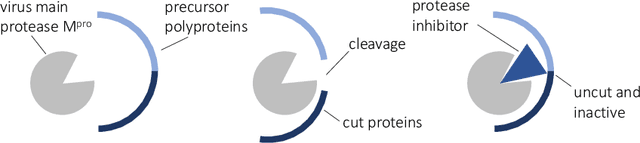

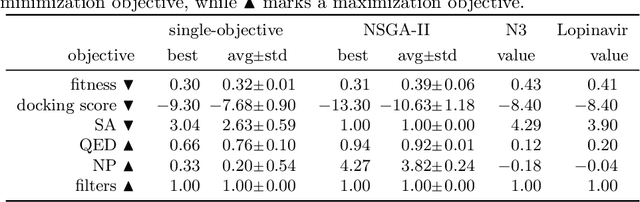
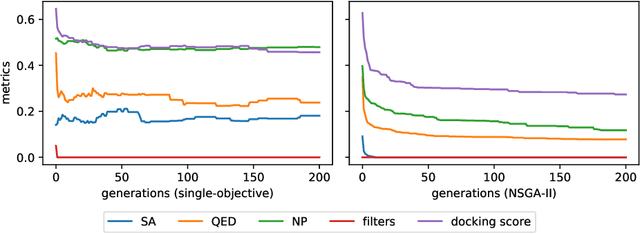
Computational drug design based on artificial intelligence is an emerging research area. At the time of writing this paper, the world suffers from an outbreak of the coronavirus SARS-CoV-2. A promising way to stop the virus replication is via protease inhibition. We propose an evolutionary multi-objective algorithm (EMOA) to design potential protease inhibitors for SARS-CoV-2's main protease. Based on the SELFIES representation the EMOA maximizes the binding of candidate ligands to the protein using the docking tool QuickVina 2, while at the same time taking into account further objectives like drug-likeliness or the fulfillment of filter constraints. The experimental part analyzes the evolutionary process and discusses the inhibitor candidates.
Optimal Learning for Structured Bandits
Jul 14, 2020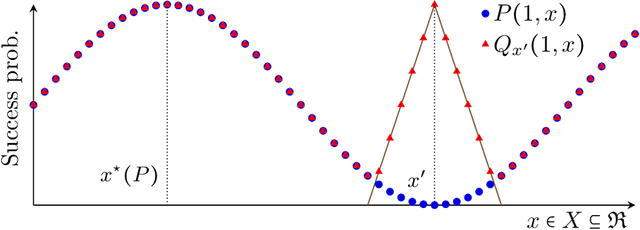

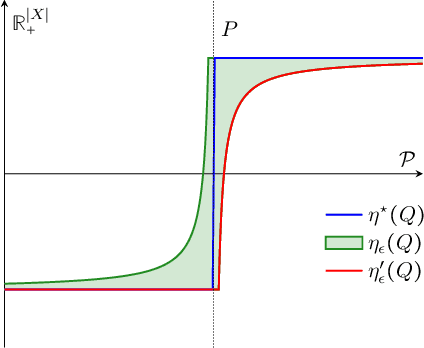
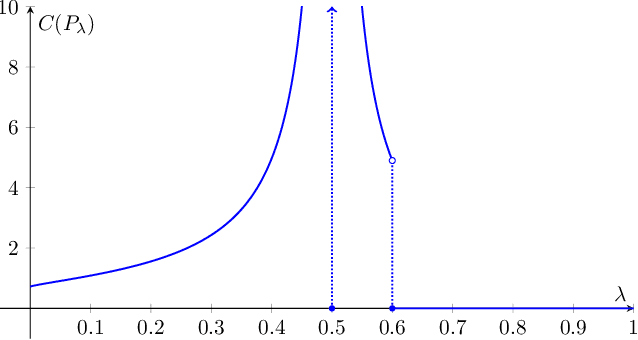
We study structured multi-armed bandits, which is the problem of online decision-making under uncertainty in the presence of structural information. In this problem, the decision-maker needs to discover the best course of action despite observing only uncertain rewards over time. The decision-maker is aware of certain structural information regarding the reward distributions and would like to minimize his regret by exploiting this information, where the regret is its performance difference against a benchmark policy which knows the best action ahead of time. In the absence of structural information, the classical UCB and Thomson sampling algorithms are well known to suffer only minimal regret. As recently pointed out, neither algorithms is, however, capable of exploiting structural information which is commonly available in practice. We propose a novel learning algorithm which we call "DUSA" whose worst-case regret matches the information-theoretic regret lower bound up to a constant factor and can handle a wide range of structural information. Our algorithm DUSA solves a dual counterpart of regret lower bound at the empirical reward distribution and follows the suggestion made by the dual problem. Our proposed algorithm is the first computationally viable learning policy for structured bandit problems that suffers asymptotic minimal regret.
Multi-armed Bandits with Cost Subsidy
Nov 03, 2020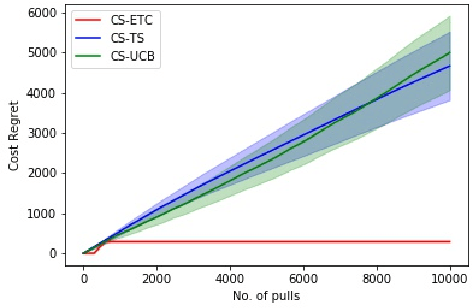

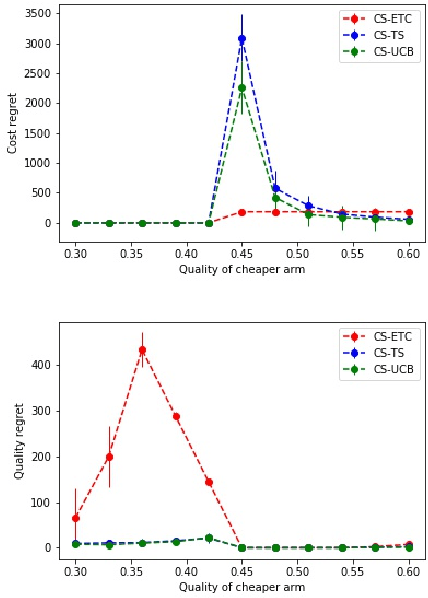
In this paper, we consider a novel variant of the multi-armed bandit (MAB) problem, \emph{MAB with cost subsidy}, which models many real-life applications where the learning agent has to pay to select an arm and is concerned about optimizing cumulative costs and rewards. We present two applications, \emph{intelligent SMS routing problem} and \emph{ad audience optimization problem} faced by a number of businesses (especially online platforms) and show how our problem uniquely captures key features of these applications. We show that naive generalizations of existing MAB algorithms like Upper Confidence Bound and Thompson Sampling do not perform well for this problem. We then establish fundamental lower bound of $\Omega(K^{1/3} T^{2/3})$ on the performance of any online learning algorithm for this problem, highlighting the hardness of our problem in comparison to the classical MAB problem (where $T$ is the time horizon and $K$ is the number of arms). We also present a simple variant of \textit{explore-then-commit} and establish near-optimal regret bounds for this algorithm. Lastly, we perform extensive numerical simulations to understand the behavior of a suite of algorithms for various instances and recommend a practical guide to employ different algorithms.
Leveraging Regular Fundus Images for Training UWF Fundus Diagnosis Models via Adversarial Learning and Pseudo-Labeling
Nov 27, 2020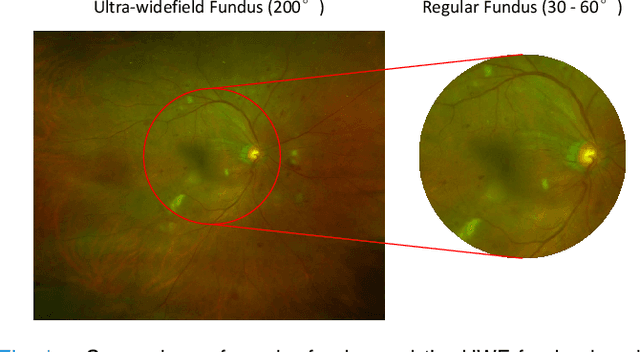
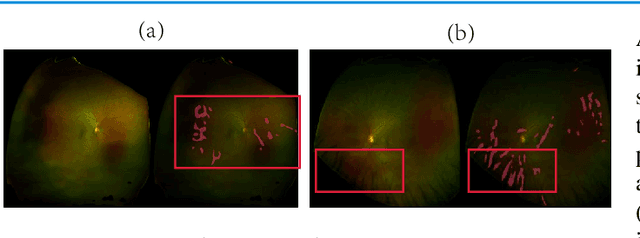
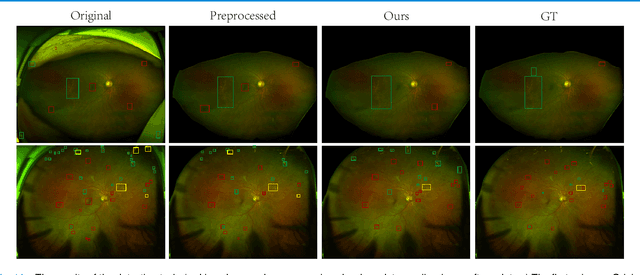
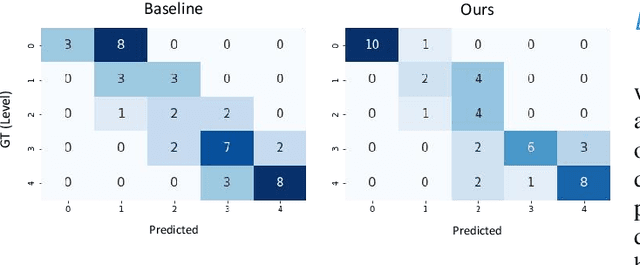
Recently, ultra-widefield (UWF) 200-degree fundus imaging by Optos cameras has gradually been introduced because of its broader insights for detecting more information on the fundus than regular 30-degree - 60-degree fundus cameras. Compared with UWF fundus images, regular fundus images contain a large amount of high-quality and well-annotated data. Due to the domain gap, models trained by regular fundus images to recognize UWF fundus images perform poorly. Hence, given that annotating medical data is labor intensive and time consuming, in this paper, we explore how to leverage regular fundus images to improve the limited UWF fundus data and annotations for more efficient training. We propose the use of a modified cycle generative adversarial network (CycleGAN) model to bridge the gap between regular and UWF fundus and generate additional UWF fundus images for training. A consistency regularization term is proposed in the loss of the GAN to improve and regulate the quality of the generated data. Our method does not require that images from the two domains be paired or even that the semantic labels be the same, which provides great convenience for data collection. Furthermore, we show that our method is robust to noise and errors introduced by the generated unlabeled data with the pseudo-labeling technique. We evaluated the effectiveness of our methods on several common fundus diseases and tasks, such as diabetic retinopathy (DR) classification, lesion detection and tessellated fundus segmentation. The experimental results demonstrate that our proposed method simultaneously achieves superior generalizability of the learned representations and performance improvements in multiple tasks.
Joint Device Scheduling and Resource Allocation for Latency Constrained Wireless Federated Learning
Jul 14, 2020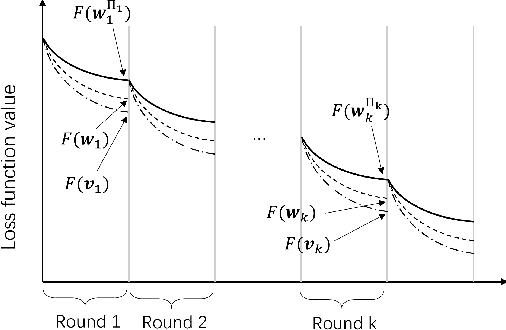
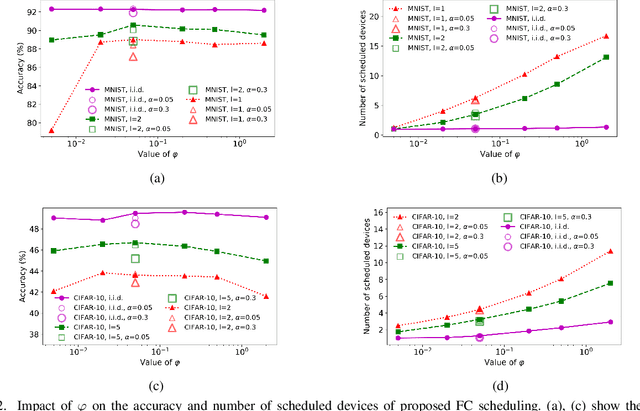
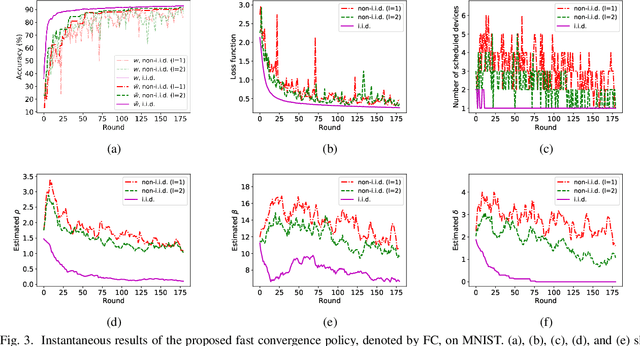
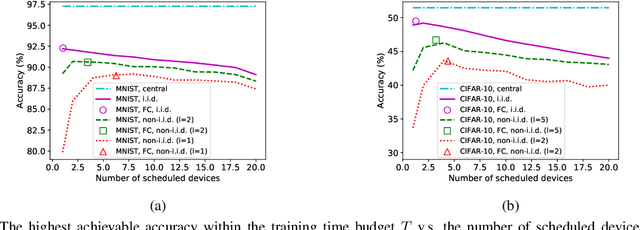
In federated learning (FL), devices contribute to the global training by uploading their local model updates via wireless channels. Due to limited computation and communication resources, device scheduling is crucial to the convergence rate of FL. In this paper, we propose a joint device scheduling and resource allocation policy to maximize the model accuracy within a given total training time budget for latency constrained wireless FL. A lower bound on the reciprocal of the training performance loss, in terms of the number of training rounds and the number of scheduled devices per round, is derived. Based on the bound, the accuracy maximization problem is solved by decoupling it into two sub-problems. First, given the scheduled devices, the optimal bandwidth allocation suggests allocating more bandwidth to the devices with worse channel conditions or weaker computation capabilities. Then, a greedy device scheduling algorithm is introduced, which in each step selects the device consuming the least updating time obtained by the optimal bandwidth allocation, until the lower bound begins to increase, meaning that scheduling more devices will degrade the model accuracy. Experiments show that the proposed policy outperforms state-of-the-art scheduling policies under extensive settings of data distributions and cell radius.
fMRI Multiple Missing Values Imputation Regularized by a Recurrent Denoiser
Sep 26, 2020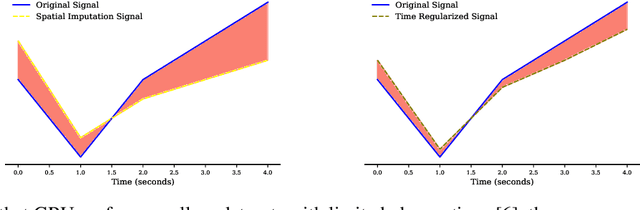
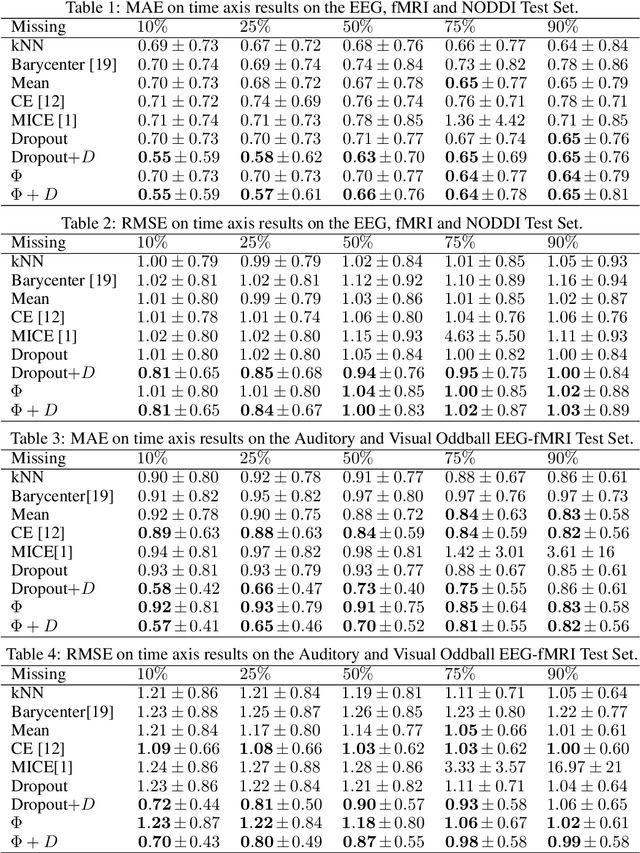
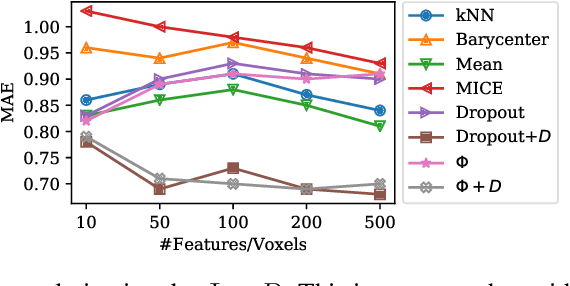
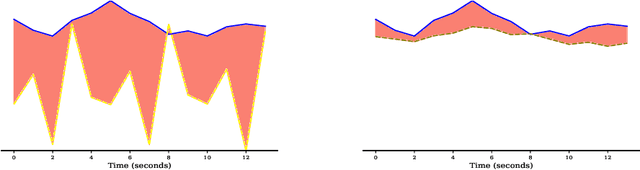
Functional Magnetic Resonance Imaging (fMRI) is a neuroimaging technique with pivotal importance due to its scientific and clinical applications. As with any widely used imaging modality, there is a need to ensure the quality of the same, with missing values being highly frequent due to the presence of artifacts or sub-optimal imaging resolutions. Our work focus on missing values imputation on multivariate signal data. To do so, a new imputation method is proposed consisting on two major steps: spatial-dependent signal imputation and time-dependent regularization of the imputed signal. A novel layer, to be used in deep learning architectures, is proposed in this work, bringing back the concept of chained equations for multiple imputation. Finally, a recurrent layer is applied to tune the signal, such that it captures its true patterns. Both operations yield an improved robustness against state-of-the-art alternatives.
Better Together: Resnet-50 accuracy with $13x$ fewer parameters and at $3x$ speed
Jun 10, 2020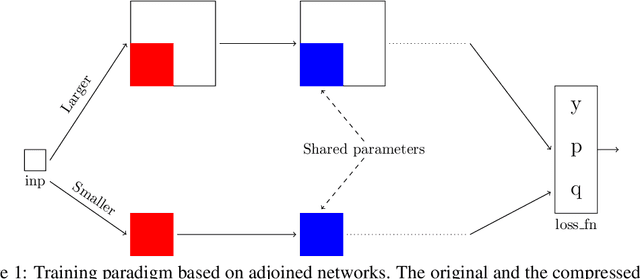
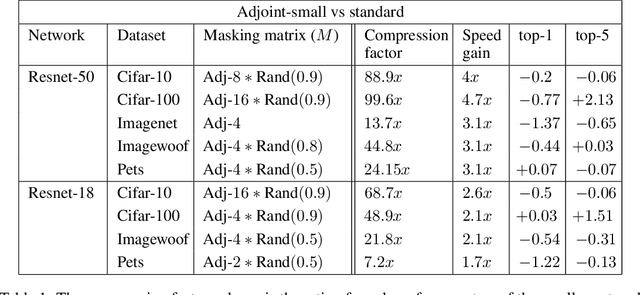
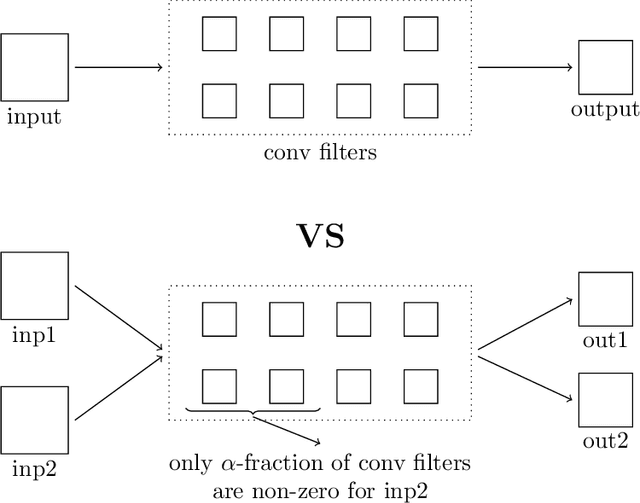
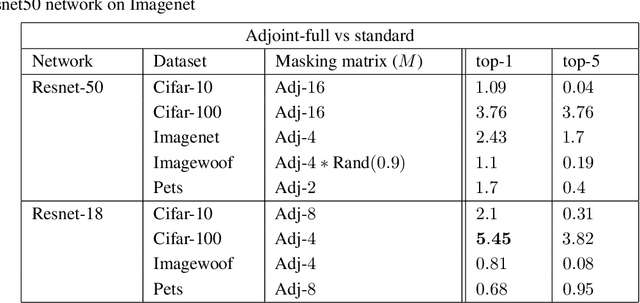
Recent research on compressing deep neural networks has focused on reducing the number of parameters. Smaller networks are easier to export and deploy on edge-devices. We introduce Adjoined networks as a training approach that can compress and regularize any CNN-based neural architecture. Our one-shot learning paradigm trains both the original and the smaller networks together. The parameters of the smaller network are shared across both the architectures. For resnet-50 trained on Imagenet, we are able to achieve a $13.7x$ reduction in the number of parameters and a $3x$ improvement in inference time without any significant drop in accuracy. For the same architecture on CIFAR-100, we are able to achieve a $99.7x$ reduction in the number of parameters and a $5x$ improvement in inference time. On both these datasets, the original network trained in the adjoint fashion gains about $3\%$ in top-1 accuracy as compared to the same network trained in the standard fashion.
Cross-Lingual Transfer Learning for Complex Word Identification
Oct 02, 2020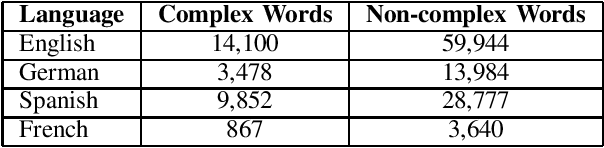
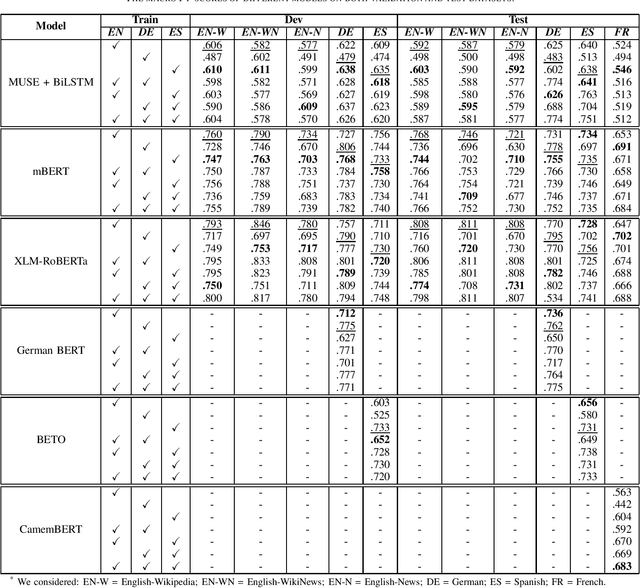
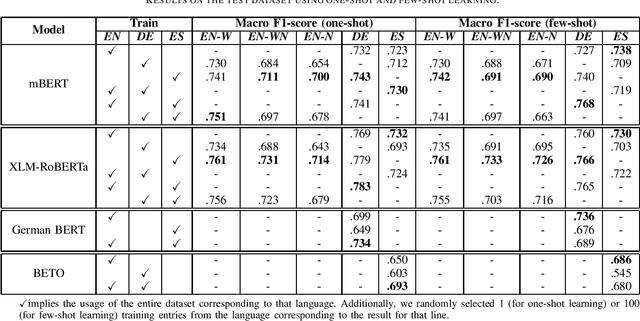
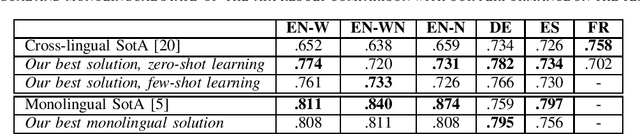
Complex Word Identification (CWI) is a task centered on detecting hard-to-understand words, or groups of words, in texts from different areas of expertise. The purpose of CWI is to highlight problematic structures that non-native speakers would usually find difficult to understand. Our approach uses zero-shot, one-shot, and few-shot learning techniques, alongside state-of-the-art solutions for Natural Language Processing (NLP) tasks (i.e., Transformers). Our aim is to provide evidence that the proposed models can learn the characteristics of complex words in a multilingual environment by relying on the CWI shared task 2018 dataset available for four different languages (i.e., English, German, Spanish, and also French). Our approach surpasses state-of-the-art cross-lingual results in terms of macro F1-score on English (0.774), German (0.782), and Spanish (0.734) languages, for the zero-shot learning scenario. At the same time, our model also outperforms the state-of-the-art monolingual result for German (0.795 macro F1-score).
Bidirectional Recurrent Neural Networks as Generative Models - Reconstructing Gaps in Time Series
Nov 02, 2015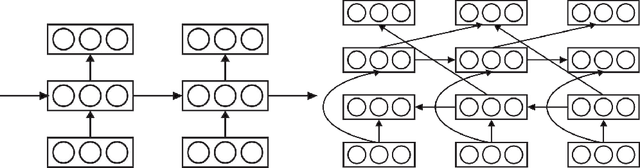

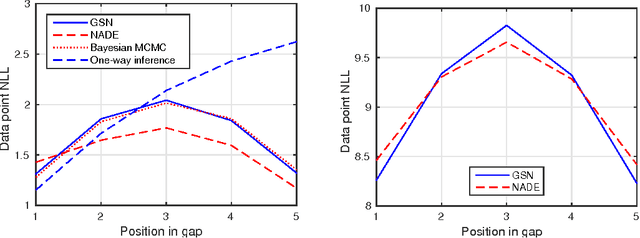
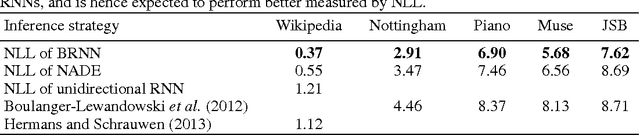
Bidirectional recurrent neural networks (RNN) are trained to predict both in the positive and negative time directions simultaneously. They have not been used commonly in unsupervised tasks, because a probabilistic interpretation of the model has been difficult. Recently, two different frameworks, GSN and NADE, provide a connection between reconstruction and probabilistic modeling, which makes the interpretation possible. As far as we know, neither GSN or NADE have been studied in the context of time series before. As an example of an unsupervised task, we study the problem of filling in gaps in high-dimensional time series with complex dynamics. Although unidirectional RNNs have recently been trained successfully to model such time series, inference in the negative time direction is non-trivial. We propose two probabilistic interpretations of bidirectional RNNs that can be used to reconstruct missing gaps efficiently. Our experiments on text data show that both proposed methods are much more accurate than unidirectional reconstructions, although a bit less accurate than a computationally complex bidirectional Bayesian inference on the unidirectional RNN. We also provide results on music data for which the Bayesian inference is computationally infeasible, demonstrating the scalability of the proposed methods.