 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
On the complexity of finding a local minimizer of a quadratic function over a polytope
Aug 12, 2020
We show that unless P=NP, there cannot be a polynomial-time algorithm that finds a point within Euclidean distance $c^n$ (for any constant $c \ge 0$) of a local minimizer of an $n$-variate quadratic function over a polytope. This result (even with $c=0$) answers a question of Pardalos and Vavasis that appeared in 1992 on a list of seven open problems in complexity theory for numerical optimization. Our proof technique also implies that the problem of deciding whether a quadratic function has a local minimizer over an (unbounded) polyhedron, and that of deciding if a quartic polynomial has a local minimizer are NP-hard.
RealHePoNet: a robust single-stage ConvNet for head pose estimation in the wild
Nov 03, 2020
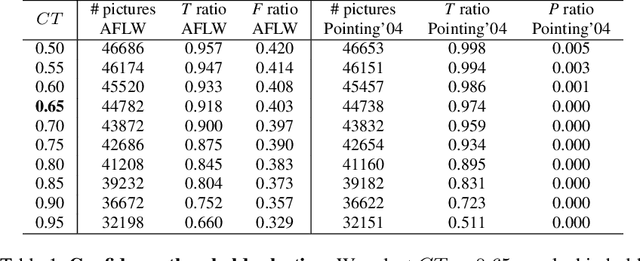

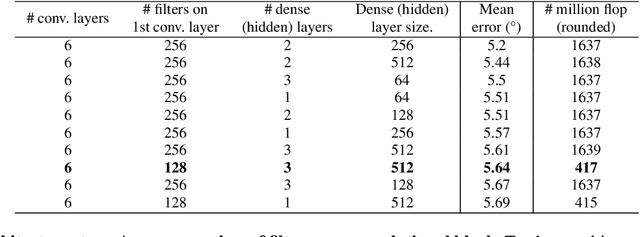
Human head pose estimation in images has applications in many fields such as human-computer interaction or video surveillance tasks. In this work, we address this problem, defined here as the estimation of both vertical (tilt/pitch) and horizontal (pan/yaw) angles, through the use of a single Convolutional Neural Network (ConvNet) model, trying to balance precision and inference speed in order to maximize its usability in real-world applications. Our model is trained over the combination of two datasets: 'Pointing'04' (aiming at covering a wide range of poses) and 'Annotated Facial Landmarks in the Wild' (in order to improve robustness of our model for its use on real-world images). Three different partitions of the combined dataset are defined and used for training, validation and testing purposes. As a result of this work, we have obtained a trained ConvNet model, coined RealHePoNet, that given a low-resolution grayscale input image, and without the need of using facial landmarks, is able to estimate with low error both tilt and pan angles (~4.4{\deg} average error on the test partition). Also, given its low inference time (~6 ms per head), we consider our model usable even when paired with medium-spec hardware (i.e. GTX 1060 GPU). * Code available at: https://github.com/rafabs97/headpose_final * Demo video at: https://www.youtube.com/watch?v=2UeuXh5DjAE
Detection of Abnormal Vessel Behaviours from AIS data using GeoTrackNet: from the Laboratory to the Ocean
Aug 12, 2020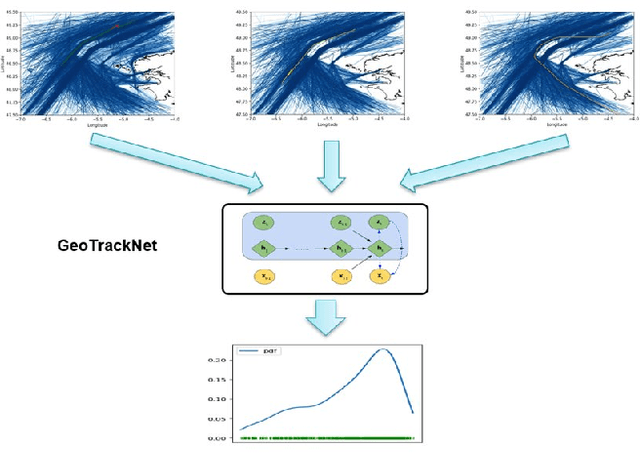
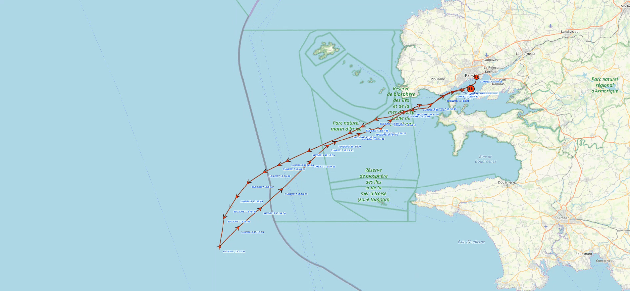
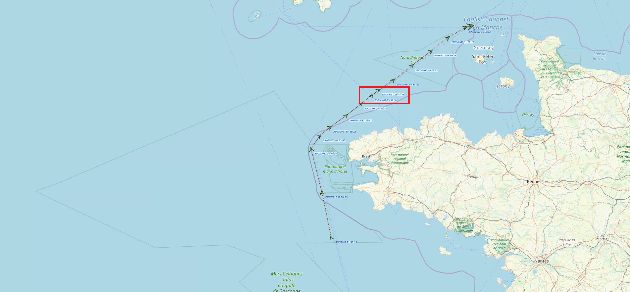
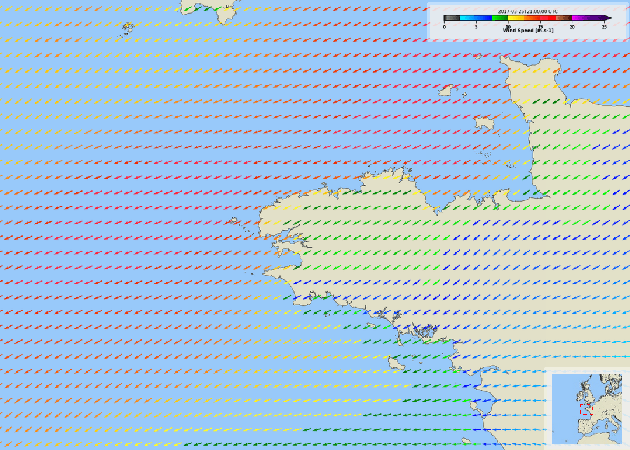
The constant growth of maritime traffic leads to the need of automatic anomaly detection, which has been attracting great research attention. Information provided by AIS (Automatic Identification System) data, together with recent outstanding progresses of deep learning, make vessel monitoring using neural networks (NNs) a very promising approach. This paper analyses a novel neural network we have recently introduced -- GeoTrackNet -- regarding operational contexts. Especially, we aim to evaluate (i) the relevance of the abnormal behaviours detected by GeoTrackNet with respect to expert interpretations, (ii) the extent to which GeoTrackNet may process AIS data streams in real time. We report experiments showing the high potential to meet operational levels of the model.
Unifying data for fine-grained visual species classification
Sep 24, 2020
Wildlife monitoring is crucial to nature conservation and has been done by manual observations from motion-triggered camera traps deployed in the field. Widespread adoption of such in-situ sensors has resulted in unprecedented data volumes being collected over the last decade. A significant challenge exists to process and reliably identify what is in these images efficiently. Advances in computer vision are poised to provide effective solutions with custom AI models built to automatically identify images of interest and label the species in them. Here we outline the data unification effort for the Wildlife Insights platform from various conservation partners, and the challenges involved. Then we present an initial deep convolutional neural network model, trained on 2.9M images across 465 fine-grained species, with a goal to reduce the load on human experts to classify species in images manually. The long-term goal is to enable scientists to make conservation recommendations from near real-time analysis of species abundance and population health.
Explaining Chemical Toxicity using Missing Features
Sep 23, 2020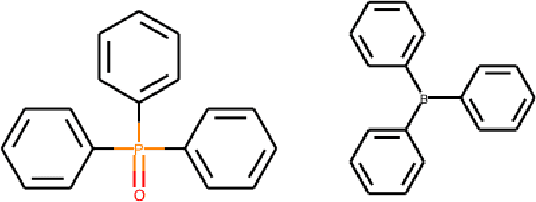
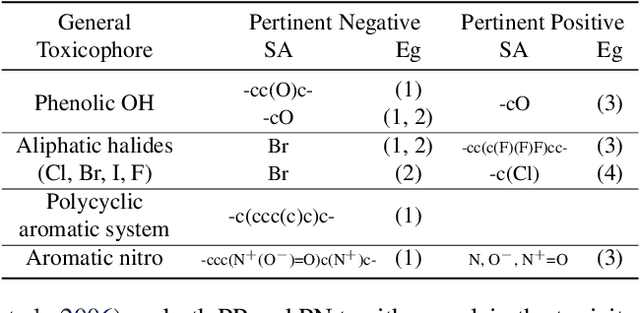
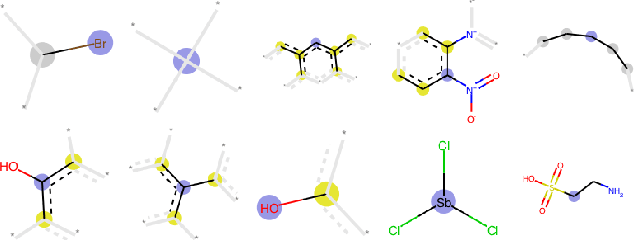
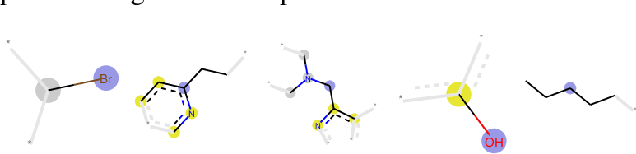
Chemical toxicity prediction using machine learning is important in drug development to reduce repeated animal and human testing, thus saving cost and time. It is highly recommended that the predictions of computational toxicology models are mechanistically explainable. Current state of the art machine learning classifiers are based on deep neural networks, which tend to be complex and harder to interpret. In this paper, we apply a recently developed method named contrastive explanations method (CEM) to explain why a chemical or molecule is predicted to be toxic or not. In contrast to popular methods that provide explanations based on what features are present in the molecule, the CEM provides additional explanation on what features are missing from the molecule that is crucial for the prediction, known as the pertinent negative. The CEM does this by optimizing for the minimum perturbation to the model using a projected fast iterative shrinkage-thresholding algorithm (FISTA). We verified that the explanation from CEM matches known toxicophores and findings from other work.
Machine Learning and Computational Mathematics
Sep 23, 2020

Neural network-based machine learning is capable of approximating functions in very high dimension with unprecedented efficiency and accuracy. This has opened up many exciting new possibilities, not just in traditional areas of artificial intelligence, but also in scientific computing and computational science. At the same time, machine learning has also acquired the reputation of being a set of "black box" type of tricks, without fundamental principles. This has been a real obstacle for making further progress in machine learning. In this article, we try to address the following two very important questions: (1) How machine learning has already impacted and will further impact computational mathematics, scientific computing and computational science? (2) How computational mathematics, particularly numerical analysis, {can} impact machine learning? We describe some of the most important progress that has been made on these issues. Our hope is to put things into a perspective that will help to integrate machine learning with computational mathematics.
EqCo: Equivalent Rules for Self-supervised Contrastive Learning
Oct 05, 2020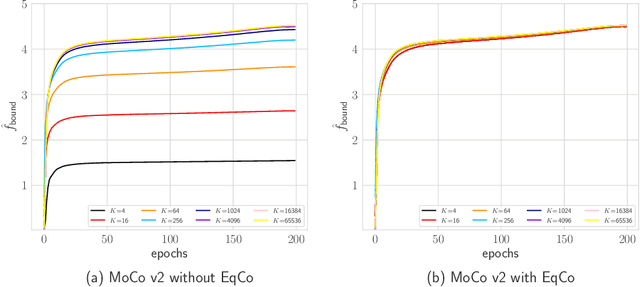

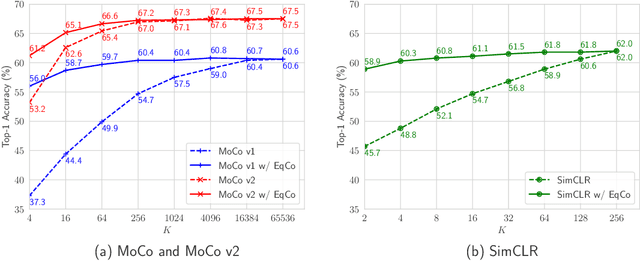
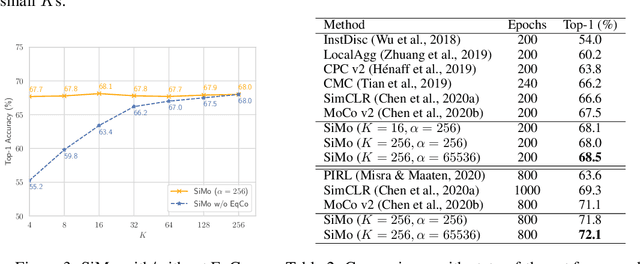
In this paper, we propose a method, named EqCo (Equivalent Rules for Contrastive Learning), to make self-supervised learning irrelevant to the number of negative samples in the contrastive learning framework. Inspired by the infomax principle, we point that the margin term in contrastive loss needs to be adaptively scaled according to the number of negative pairs in order to keep steady mutual information bound and gradient magnitude. EqCo bridges the performance gap among a wide range of negative sample sizes, so that for the first time, we can perform self-supervised contrastive training using only a few negative pairs (e.g.smaller than 256 per query) on large-scale vision tasks like ImageNet, while with little accuracy drop. This is quite a contrast to the widely used large batch training or memory bank mechanism in current practices. Equipped with EqCo, our simplified MoCo (SiMo) achieves comparable accuracy with MoCo v2 on ImageNet (linear evaluation protocol) while only involves 16 negative pairs per query instead of 65536, suggesting that large quantities of negative samples might not be a critical factor in contrastive learning frameworks.
Slip detection for grasp stabilisation with a multi-fingered tactile robot hand
Oct 05, 2020


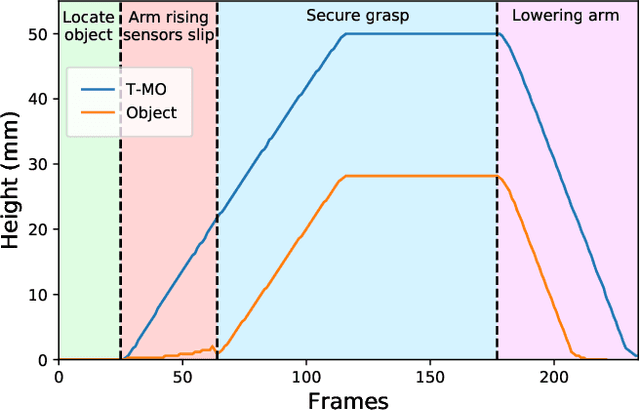
Tactile sensing is used by humans when grasping to prevent us dropping objects. One key facet of tactile sensing is slip detection, which allows a gripper to know when a grasp is failing and take action to prevent an object being dropped. This study demonstrates the slip detection capabilities of the recently developed Tactile Model O (T-MO) by using support vector machines to detect slip and test multiple slip scenarios including responding to the onset of slip in real time with eleven different objects in various grasps. We demonstrate the benefits of slip detection in grasping by testing two real-world scenarios: adding weight to destabilise a grasp and using slip detection to lift up objects at the first attempt. The T-MO is able to detect when an object is slipping, react to stabilise the grasp and be deployed in real-world scenarios. This shows the T-MO is a suitable platform for autonomous grasping by using reliable slip detection to ensure a stable grasp in unstructured environments. Supplementary video: https://youtu.be/wOwFHaiHuKY
Approximating Aggregated SQL Queries With LSTM Networks
Oct 25, 2020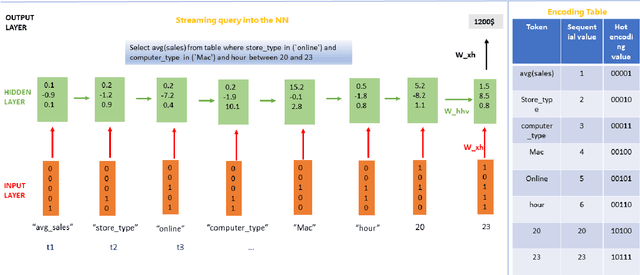
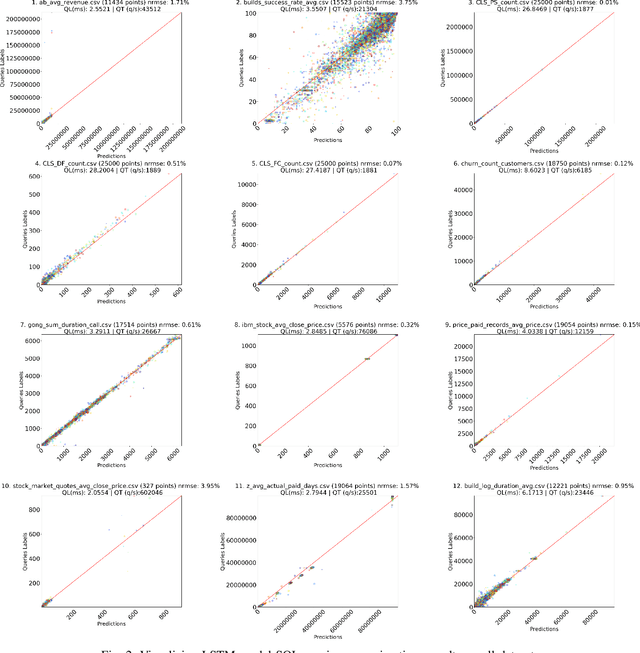
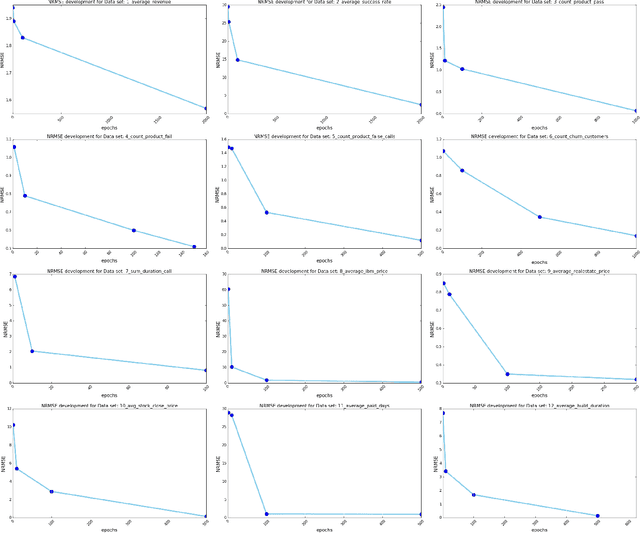
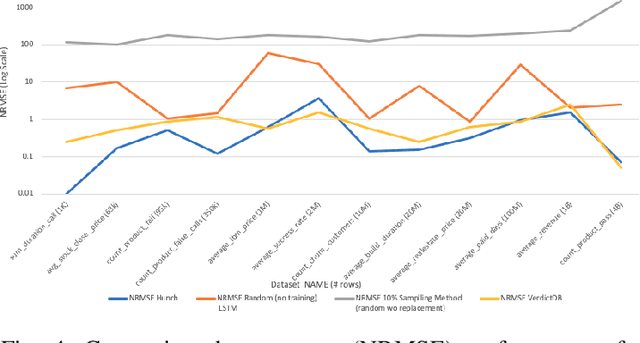
Despite continuous investments in data technologies, the latency of querying data still poses a significant challenge. Modern analytic solutions require near real-time responsiveness both to make them interactive and to support automated processing. Current technologies (Hadoop, Spark, Dataflow) scan the dataset to execute queries. They focus on providing a scalable data storage to maximize task execution speed. We argue that these solutions fail to offer an adequate level of interactivity since they depend on continual access to data. In this paper we present a method for query approximation, also known as approximate query processing (AQP), that reduce the need to scan data during inference (query calculation), thus enabling a rapid query processing tool. We use LSTM network to learn the relationship between queries and their results, and to provide a rapid inference layer for predicting query results. Our method (referred as ``Hunch``) produces a lightweight LSTM network which provides a high query throughput. We evaluated our method using 12 datasets. The results show that our method predicted queries' results with a normalized root mean squared error (NRMSE) ranging from approximately 1\% to 4\%. Moreover, our method was able to predict up to 120,000 queries in a second (streamed together), and with a single query latency of no more than 2ms.
Real-time Deep Pose Estimation with Geodesic Loss for Image-to-Template Rigid Registration
Aug 18, 2018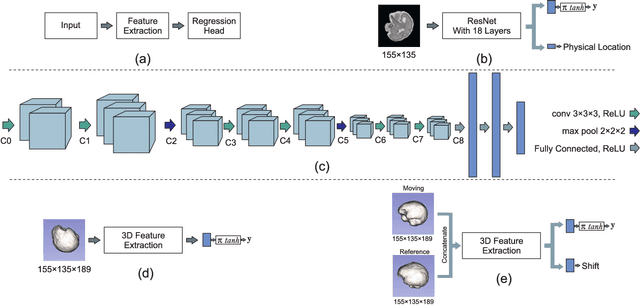
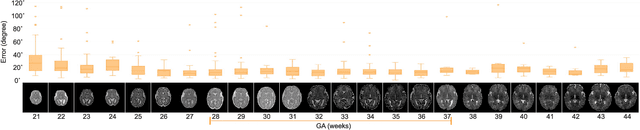
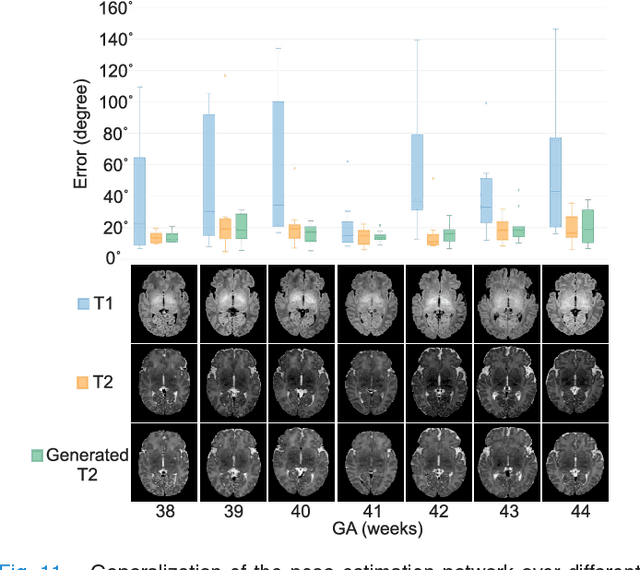
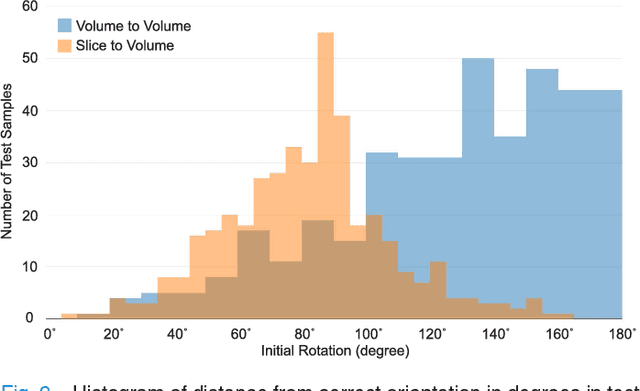
With an aim to increase the capture range and accelerate the performance of state-of-the-art inter-subject and subject-to-template 3D registration, we propose deep learning-based methods that are trained to find the 3D position of arbitrarily oriented subjects or anatomy based on slices or volumes of medical images. For this, we propose regression CNNs that learn to predict the angle-axis representation of 3D rotations and translations using image features. We use and compare mean square error and geodesic loss to train regression CNNs for 3D pose estimation used in two different scenarios: slice-to-volume registration and volume-to-volume registration. Our results show that in such registration applications that are amendable to learning, the proposed deep learning methods with geodesic loss minimization can achieve accurate results with a wide capture range in real-time (<100ms). We also tested the generalization capability of the trained CNNs on an expanded age range and on images of newborn subjects with similar and different MR image contrasts. We trained our models on T2-weighted fetal brain MRI scans and used them to predict the 3D pose of newborn brains based on T1-weighted MRI scans. We showed that the trained models generalized well for the new domain when we performed image contrast transfer through a conditional generative adversarial network. This indicates that the domain of application of the trained deep regression CNNs can be further expanded to image modalities and contrasts other than those used in training. A combination of our proposed methods with accelerated optimization-based registration algorithms can dramatically enhance the performance of automatic imaging devices and image processing methods of the future.