 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Note on the Linear Convergence of Policy Gradient Methods
Jul 21, 2020
We revisit the finite time analysis of policy gradient methods in the simplest setting: finite state and action problems with a policy class consisting of all stochastic policies and with exact gradient evaluations. Some recent works have viewed these problems as instances of smooth nonlinear optimization problems, suggesting suggest small stepsizes and showing sublinear convergence rates. This note instead takes a policy iteration perspective and highlights that many versions of policy gradient succeed with extremely large stepsizes and attain a linear rate of convergence.
Self-Explaining Structures Improve NLP Models
Dec 03, 2020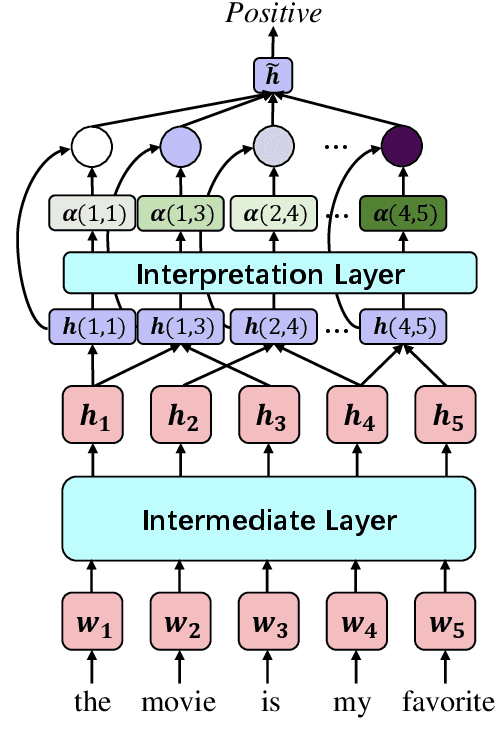
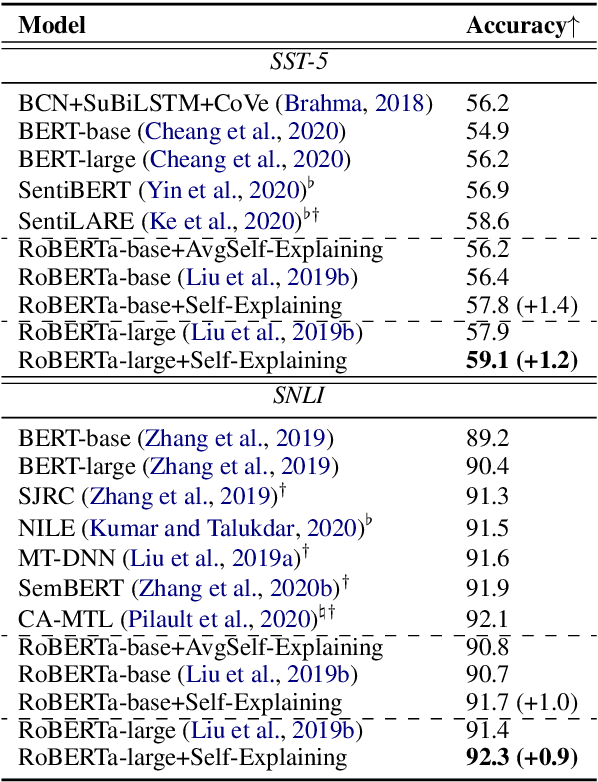

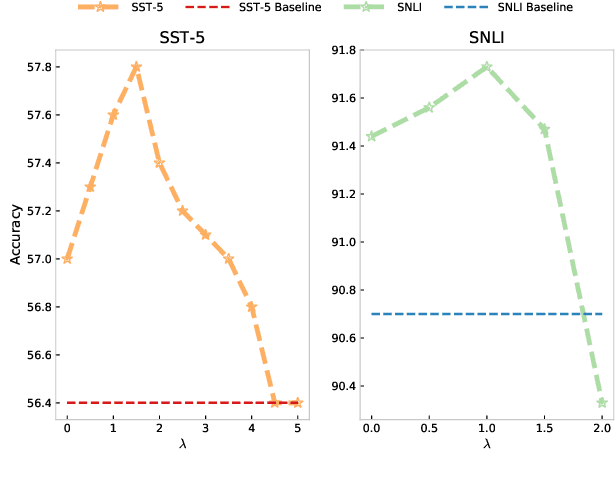
Existing approaches to explaining deep learning models in NLP usually suffer from two major drawbacks: (1) the main model and the explaining model are decoupled: an additional probing or surrogate model is used to interpret an existing model, and thus existing explaining tools are not self-explainable; (2) the probing model is only able to explain a model's predictions by operating on low-level features by computing saliency scores for individual words but are clumsy at high-level text units such as phrases, sentences, or paragraphs. To deal with these two issues, in this paper, we propose a simple yet general and effective self-explaining framework for deep learning models in NLP. The key point of the proposed framework is to put an additional layer, as is called by the interpretation layer, on top of any existing NLP model. This layer aggregates the information for each text span, which is then associated with a specific weight, and their weighted combination is fed to the softmax function for the final prediction. The proposed model comes with the following merits: (1) span weights make the model self-explainable and do not require an additional probing model for interpretation; (2) the proposed model is general and can be adapted to any existing deep learning structures in NLP; (3) the weight associated with each text span provides direct importance scores for higher-level text units such as phrases and sentences. We for the first time show that interpretability does not come at the cost of performance: a neural model of self-explaining features obtains better performances than its counterpart without the self-explaining nature, achieving a new SOTA performance of 59.1 on SST-5 and a new SOTA performance of 92.3 on SNLI.
RNNAccel: A Fusion Recurrent Neural Network Accelerator for Edge Intelligence
Oct 26, 2020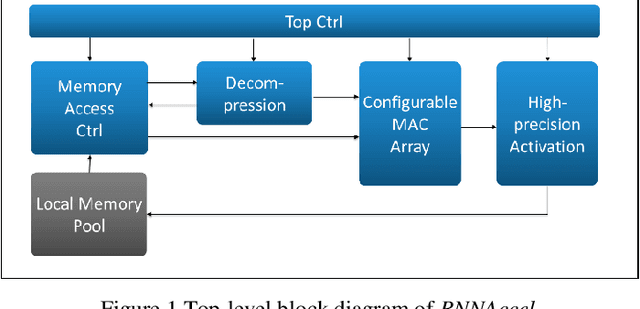
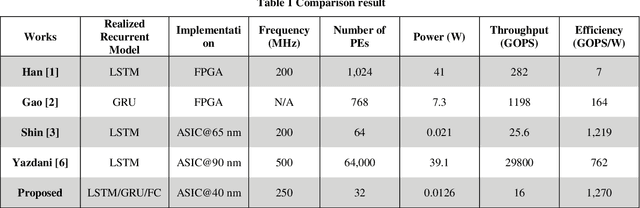
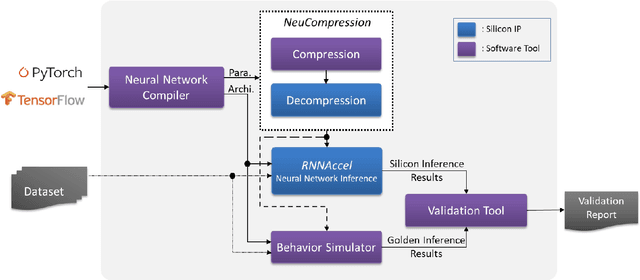
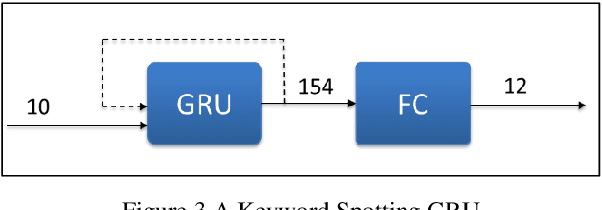
Many edge devices employ Recurrent Neural Networks (RNN) to enhance their product intelligence. However, the increasing computation complexity poses challenges for performance, energy efficiency and product development time. In this paper, we present an RNN deep learning accelerator, called RNNAccel, which supports Long Short-Term Memory (LSTM) network, Gated Recurrent Unit (GRU) network, and Fully Connected Layer (FC)/ Multiple-Perceptron Layer (MLP) networks. This RNN accelerator addresses (1) computing unit utilization bottleneck caused by RNN data dependency, (2) inflexible design for specific applications, (3) energy consumption dominated by memory access, (4) accuracy loss due to coefficient compression, and (5) unpredictable performance resulting from processor-accelerator integration. Our proposed RNN accelerator consists of a configurable 32-MAC array and a coefficient decompression engine. The MAC array can be scaled-up to meet throughput requirement and power budget. Its sophisticated off-line compression and simple hardware-friendly on-line decompression, called NeuCompression, reduces memory footprint up to 16x and decreases memory access power. Furthermore, for easy SOC integration, we developed a tool set for bit-accurate simulation and integration result validation. Evaluated using a keyword spotting application, the 32-MAC RNN accelerator achieves 90% MAC utilization, 1.27 TOPs/W at 40nm process, 8x compression ratio, and 90% inference accuracy.
Real-time Quasi-Optimal Trajectory Planning for Autonomous Underwater Docking
May 03, 2016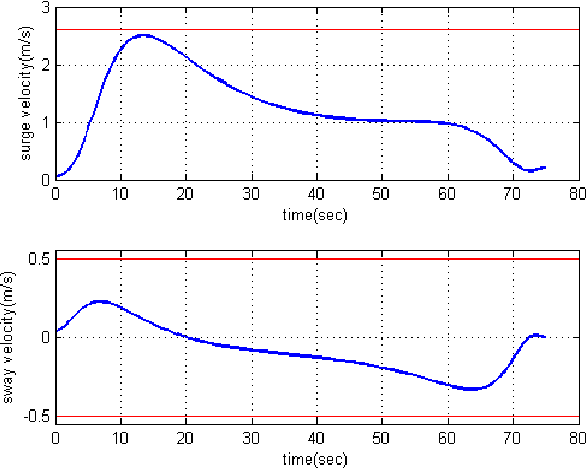
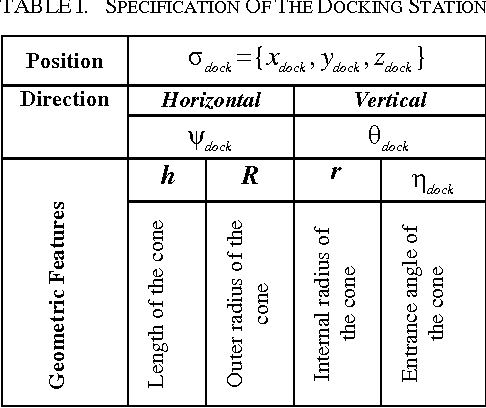
In this paper, a real-time quasi-optimal trajectory planning scheme is employed to guide an autonomous underwater vehicle (AUV) safely into a funnel-shape stationary docking station. By taking advantage of the direct method of calculus of variation and inverse dynamics optimization, the proposed trajectory planner provides a computationally efficient framework for autonomous underwater docking in a 3D cluttered undersea environment. Vehicular constraints, such as constraints on AUV states and actuators; boundary conditions, including initial and final vehicle poses; and environmental constraints, for instance no-fly zones and current disturbances, are all modelled and considered in the problem formulation. The performance of the proposed planner algorithm is analyzed through simulation studies. To show the reliability and robustness of the method in dealing with uncertainty, Monte Carlo runs and statistical analysis are carried out. The results of the simulations indicate that the proposed planner is well suited for real-time implementation in a dynamic and uncertain environment.
Asynchronous ε-Greedy Bayesian Optimisation
Oct 16, 2020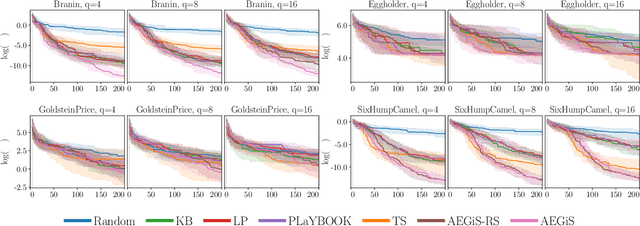
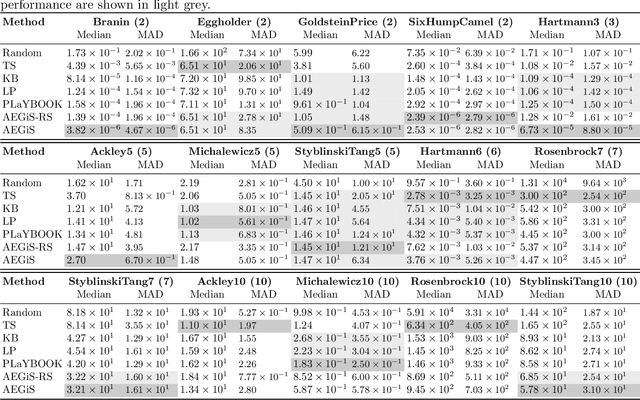
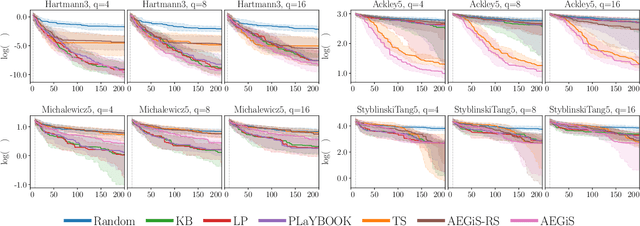
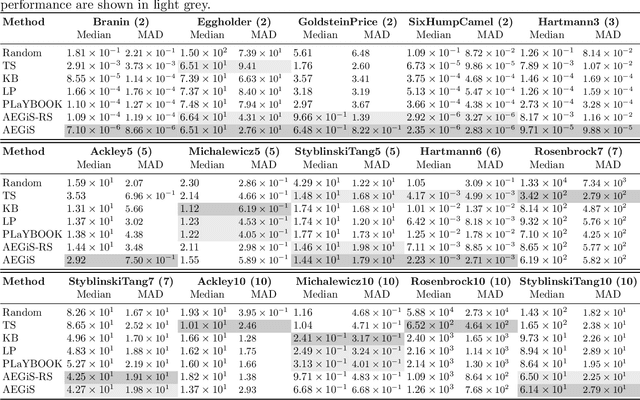
Bayesian Optimisation (BO) is a popular surrogate model-based approach for optimising expensive black-box functions. In order to reduce optimisation wallclock time, parallel evaluation of the black-box function has been proposed. Asynchronous BO allows for a new evaluation to be started as soon as another finishes, thus maximising utilisation of evaluation workers. We present AEGiS (Asynchronous $\epsilon$-Greedy Global Search), an asynchronous BO method that, with probability $2\epsilon$, performs either Thompson sampling or random selection from the approximate Pareto set trading-off between exploitation (surrogate mean prediction) and exploration (surrogate posterior variance). The remaining $1-2\epsilon$ of moves exploit the surrogate's mean prediction. Results on fifteen synthetic benchmark problems, three meta-surrogate hyperparameter tuning problems and two robot pushing problems show that AEGiS generally outperforms existing methods for asynchronous BO. When a single worker is available performance is no worse than BO using expected improvement. We also verify the importance of each of the three components in an ablation study, as well as comparing Pareto set selection to selection from the entire feasible problem domain, finding that the former is vastly superior.
The Traveling Observer Model: Multi-task Learning Through Spatial Variable Embeddings
Oct 05, 2020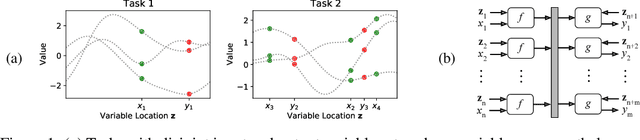
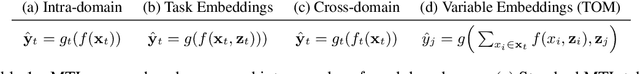
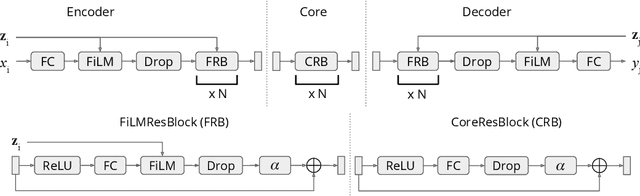

This paper frames a general prediction system as an observer traveling around a continuous space, measuring values at some locations, and predicting them at others. The observer is completely agnostic about any particular task being solved; it cares only about measurement locations and their values. This perspective leads to a machine learning framework in which seemingly unrelated tasks can be solved by a single model, by embedding their input and output variables into a shared space. An implementation of the framework is developed in which these variable embeddings are learned jointly with internal model parameters. In experiments, the approach is shown to (1) recover intuitive locations of variables in space and time, (2) exploit regularities across related datasets with completely disjoint input and output spaces, and (3) exploit regularities across seemingly unrelated tasks, outperforming task-specific single-task models and multi-task learning alternatives. The results suggest that even seemingly unrelated tasks may originate from similar underlying processes, a fact that the traveling observer model can use to make better predictions.
Labeled Optimal Partitioning
Jun 24, 2020
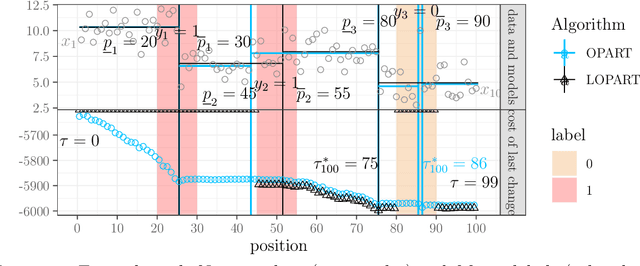
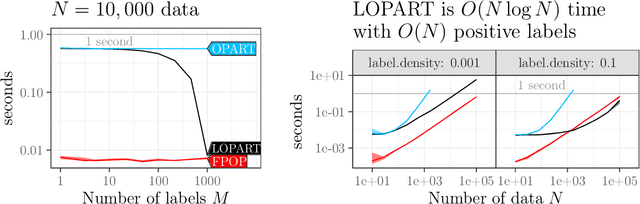
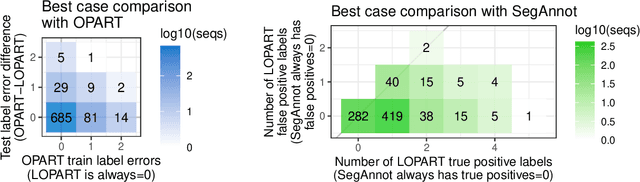
In data sequences measured over space or time, an important problem is accurate detection of abrupt changes. In partially labeled data, it is important to correctly predict presence/absence of changes in positive/negative labeled regions, in both the train and test sets. One existing dynamic programming algorithm is designed for prediction in unlabeled test regions (and ignores the labels in the train set); another is for accurate fitting of train labels (but does not predict changepoints in unlabeled test regions). We resolve these issues by proposing a new optimal changepoint detection model that is guaranteed to fit the labels in the train data, and can also provide predictions of unlabeled changepoints in test data. We propose a new dynamic programming algorithm, Labeled Optimal Partitioning (LOPART), and we provide a formal proof that it solves the resulting non-convex optimization problem. We provide theoretical and empirical analysis of the time complexity of our algorithm, in terms of the number of labels and the size of the data sequence to segment. Finally, we provide empirical evidence that our algorithm is more accurate than the existing baselines, in terms of train and test label error.
BALM: Bundle Adjustment for Lidar Mapping
Oct 16, 2020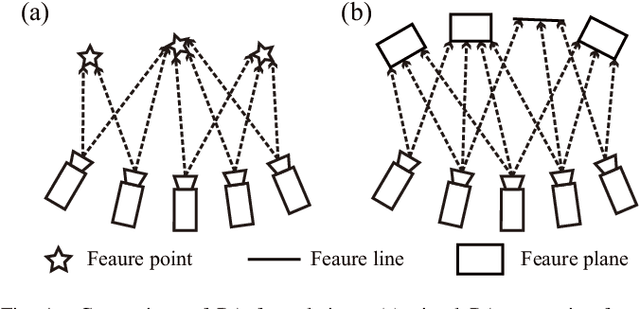

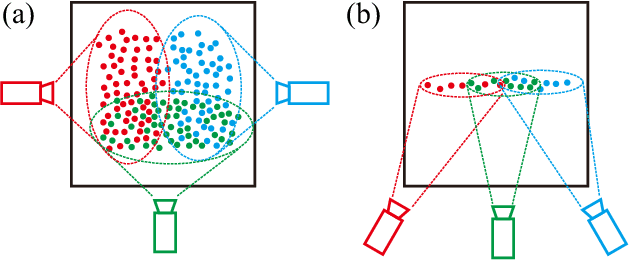
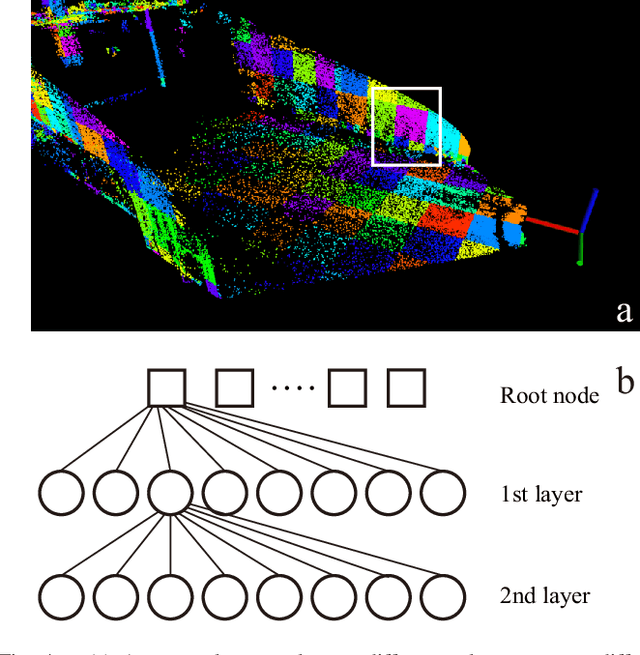
We propose a framework for bundle adjustment (BA) on sparse lidar points and incorporate it to a lidar odometry and mapping (LOAM) to lower the drift. A local BA on a sliding window of keyframes has been widely used in visual SLAM and has proved to be very effective in lowering the drift. But in lidar mapping, BA method is hardly used because the sparse feature points (e.g., edge and plane) in a lidar point-cloud make the exact feature matching impossible. Our method is to enforce feature points lie on the same edge or plane by minimizing the eigenvalue of the covariance matrix. To speedup the optimization, we derive the analytical derivatives, up to second order, in closed form. Moreoever, we propose a novel adaptive voxelization method to search feature correspondence efficiently. The proposed formulations are incorporated into a LOAM back-end for map refinement. Results show that, although as a back-end, the local BA can be solved very efficiently, even in real-time at 10Hz when optimizing 20 scans of point-cloud. The local BA also considerably lowers the LOAM drift. Our implementation of the BA optimization and LOAM are open-sourced to benefit the community.
Non-greedy Gradient-based Hyperparameter Optimization Over Long Horizons
Jul 15, 2020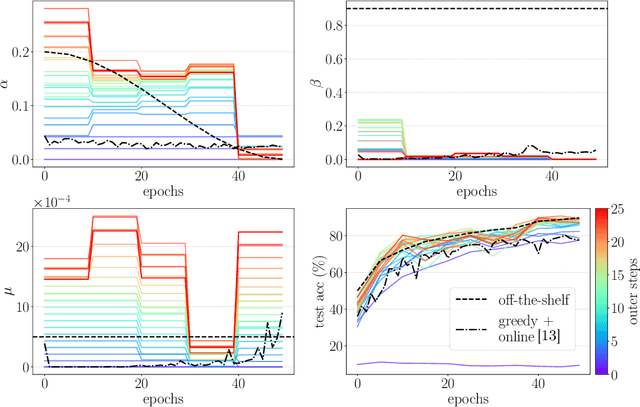
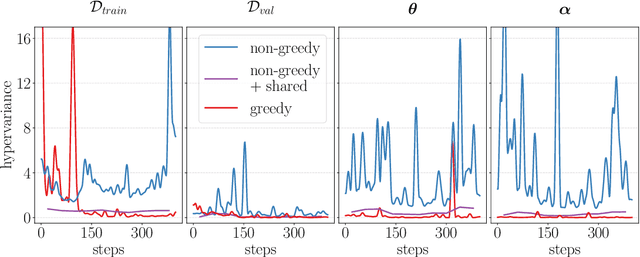
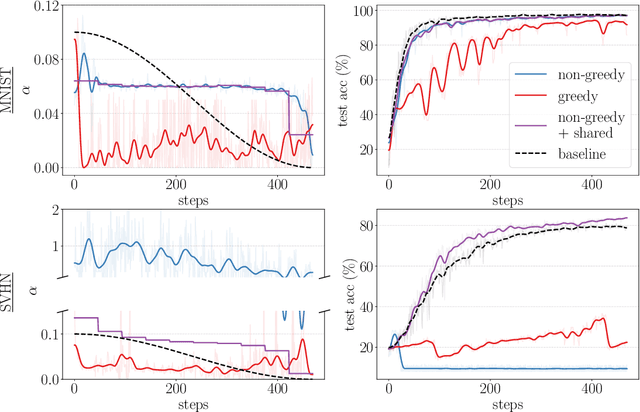
Gradient-based hyperparameter optimization is an attractive way to perform meta-learning across a distribution of tasks, or improve the performance of an optimizer on a single task. However, this approach has been unpopular for tasks requiring long horizons (many gradient steps), due to memory scaling and gradient degradation issues. A common workaround is to learn hyperparameters online or split the horizon into smaller chunks. However, this introduces greediness which comes with a large performance drop, since the best local hyperparameters can make for poor global solutions. In this work, we enable non-greediness over long horizons with a two-fold solution. First, we share hyperparameters that are contiguous in time, and show that this drastically mitigates gradient degradation issues. Then, we derive a forward-mode differentiation algorithm for the popular momentum-based SGD optimizer, which allows for a memory cost that is constant with horizon size. When put together, these solutions allow us to learn hyperparameters without any prior knowledge. Compared to the baseline of hand-tuned off-the-shelf hyperparameters, our method compares favorably on simple datasets like SVHN. On CIFAR-10 we match the baseline performance, and demonstrate for the first time that learning rate, momentum and weight decay schedules can be learned with gradients on a dataset of this size. Code is available at https://github.com/polo5/NonGreedyGradientHPO
VidCEP: Complex Event Processing Framework to Detect Spatiotemporal Patterns in Video Streams
Jul 15, 2020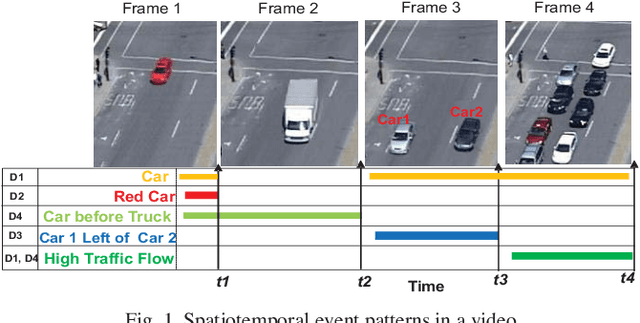
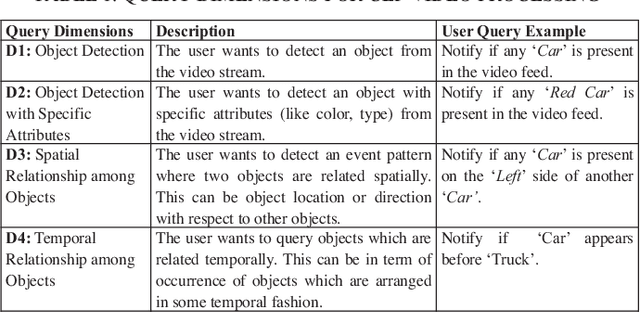
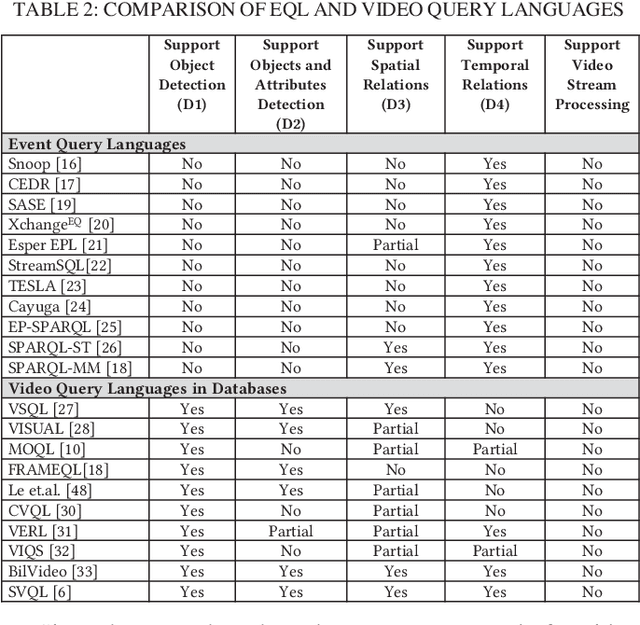
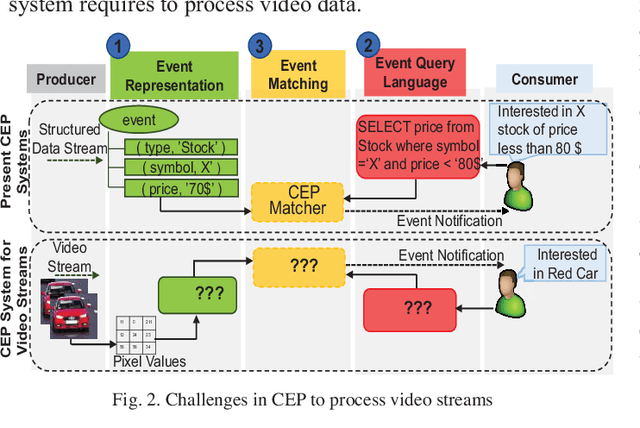
Video data is highly expressive and has traditionally been very difficult for a machine to interpret. Querying event patterns from video streams is challenging due to its unstructured representation. Middleware systems such as Complex Event Processing (CEP) mine patterns from data streams and send notifications to users in a timely fashion. Current CEP systems have inherent limitations to query video streams due to their unstructured data model and lack of expressive query language. In this work, we focus on a CEP framework where users can define high-level expressive queries over videos to detect a range of spatiotemporal event patterns. In this context, we propose: i) VidCEP, an in-memory, on the fly, near real-time complex event matching framework for video streams. The system uses a graph-based event representation for video streams which enables the detection of high-level semantic concepts from video using cascades of Deep Neural Network models, ii) a Video Event Query language (VEQL) to express high-level user queries for video streams in CEP, iii) a complex event matcher to detect spatiotemporal video event patterns by matching expressive user queries over video data. The proposed approach detects spatiotemporal video event patterns with an F-score ranging from 0.66 to 0.89. VidCEP maintains near real-time performance with an average throughput of 70 frames per second for 5 parallel videos with sub-second matching latency.