 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
RNNAccel: A Fusion Recurrent Neural Network Accelerator for Edge Intelligence
Oct 26, 2020
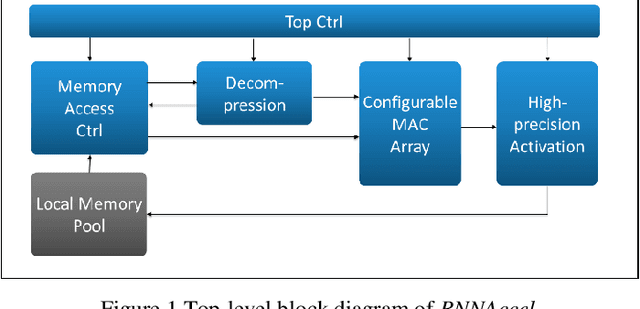
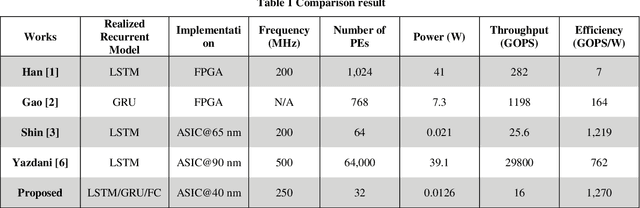
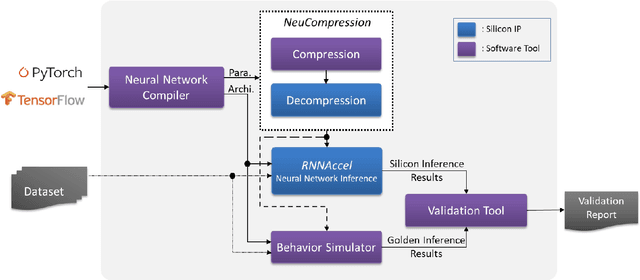
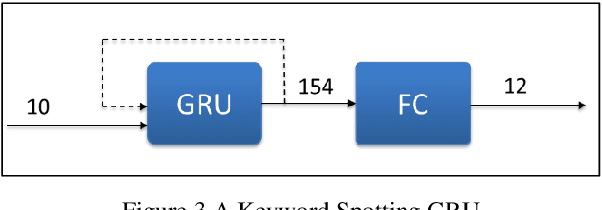
Many edge devices employ Recurrent Neural Networks (RNN) to enhance their product intelligence. However, the increasing computation complexity poses challenges for performance, energy efficiency and product development time. In this paper, we present an RNN deep learning accelerator, called RNNAccel, which supports Long Short-Term Memory (LSTM) network, Gated Recurrent Unit (GRU) network, and Fully Connected Layer (FC)/ Multiple-Perceptron Layer (MLP) networks. This RNN accelerator addresses (1) computing unit utilization bottleneck caused by RNN data dependency, (2) inflexible design for specific applications, (3) energy consumption dominated by memory access, (4) accuracy loss due to coefficient compression, and (5) unpredictable performance resulting from processor-accelerator integration. Our proposed RNN accelerator consists of a configurable 32-MAC array and a coefficient decompression engine. The MAC array can be scaled-up to meet throughput requirement and power budget. Its sophisticated off-line compression and simple hardware-friendly on-line decompression, called NeuCompression, reduces memory footprint up to 16x and decreases memory access power. Furthermore, for easy SOC integration, we developed a tool set for bit-accurate simulation and integration result validation. Evaluated using a keyword spotting application, the 32-MAC RNN accelerator achieves 90% MAC utilization, 1.27 TOPs/W at 40nm process, 8x compression ratio, and 90% inference accuracy.
Data-Driven Distributed State Estimation and Behavior Modeling in Sensor Networks
Sep 24, 2020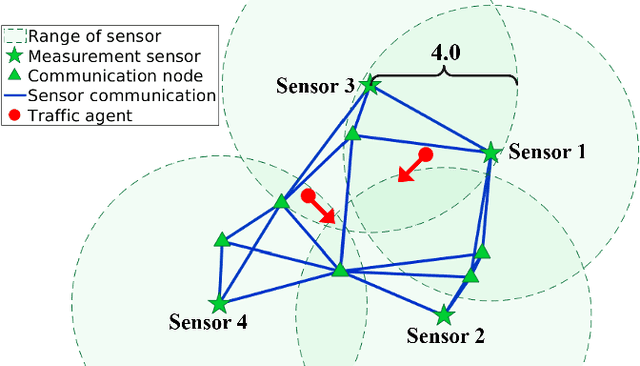
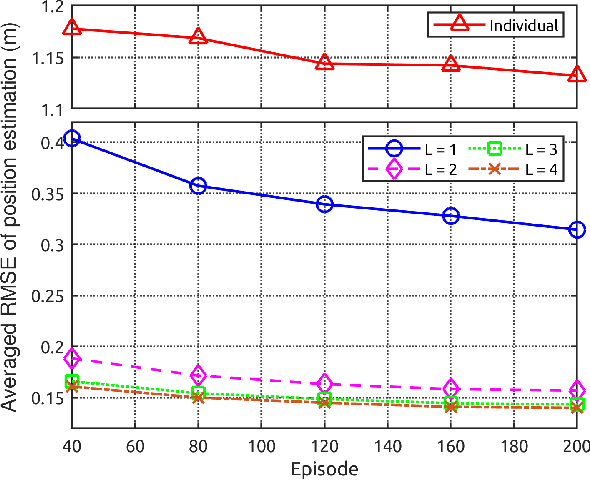
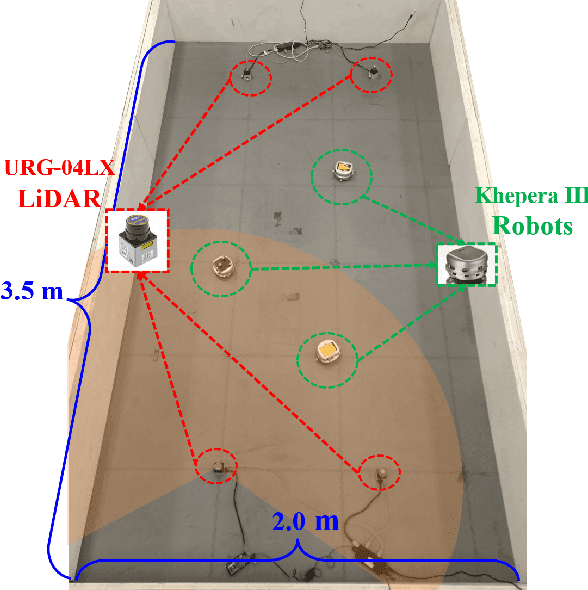
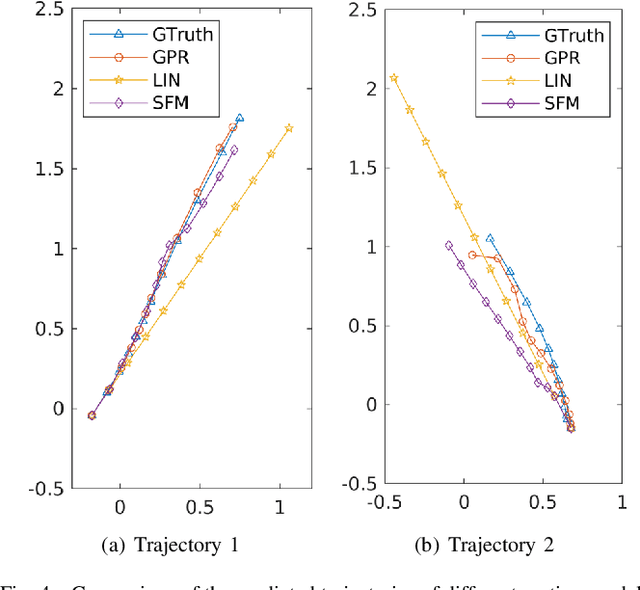
Nowadays, the prevalence of sensor networks has enabled tracking of the states of dynamic objects for a wide spectrum of applications from autonomous driving to environmental monitoring and urban planning. However, tracking real-world objects often faces two key challenges: First, due to the limitation of individual sensors, state estimation needs to be solved in a collaborative and distributed manner. Second, the objects' movement behavior is unknown, and needs to be learned using sensor observations. In this work, for the first time, we formally formulate the problem of simultaneous state estimation and behavior learning in a sensor network. We then propose a simple yet effective solution to this new problem by extending the Gaussian process-based Bayes filters (GP-BayesFilters) to an online, distributed setting. The effectiveness of the proposed method is evaluated on tracking objects with unknown movement behaviors using both synthetic data and data collected from a multi-robot platform.
A new method for parameter estimation in probabilistic models: Minimum probability flow
Jul 17, 2020
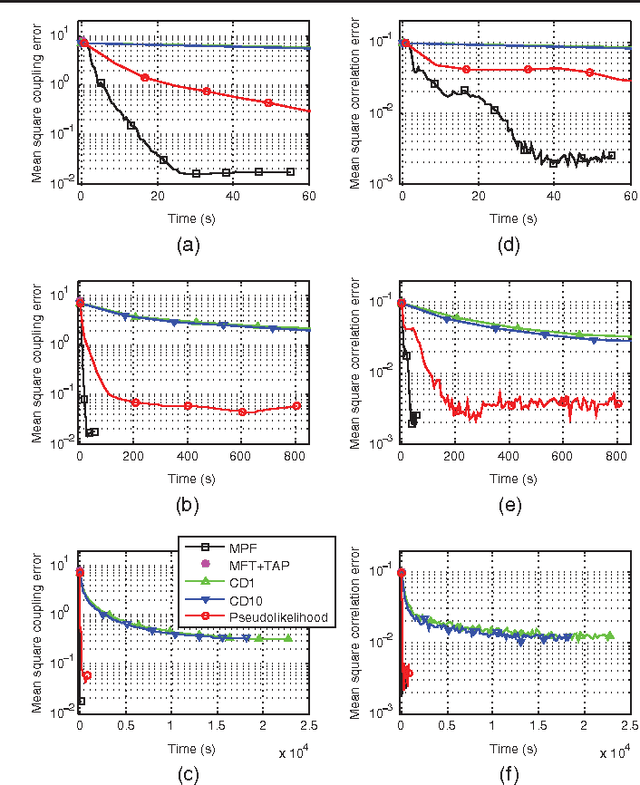

Fitting probabilistic models to data is often difficult, due to the general intractability of the partition function. We propose a new parameter fitting method, Minimum Probability Flow (MPF), which is applicable to any parametric model. We demonstrate parameter estimation using MPF in two cases: a continuous state space model, and an Ising spin glass. In the latter case it outperforms current techniques by at least an order of magnitude in convergence time with lower error in the recovered coupling parameters.
An Exploration of Target-Conditioned Segmentation Methods for Visual Object Trackers
Aug 13, 2020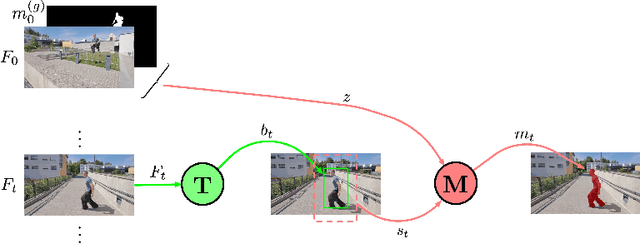

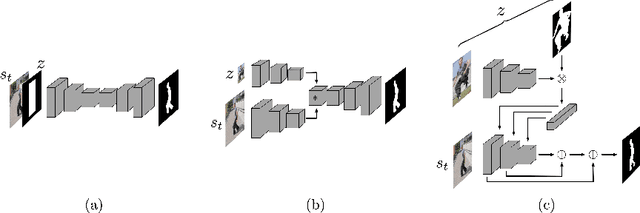
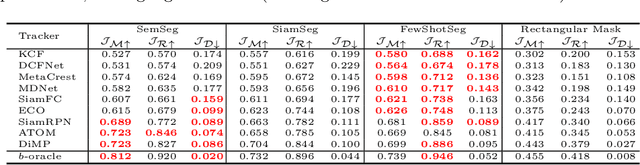
Visual object tracking is the problem of predicting a target object's state in a video. Generally, bounding-boxes have been used to represent states, and a surge of effort has been spent by the community to produce efficient causal algorithms capable of locating targets with such representations. As the field is moving towards binary segmentation masks to define objects more precisely, in this paper we propose to extensively explore target-conditioned segmentation methods available in the computer vision community, in order to transform any bounding-box tracker into a segmentation tracker. Our analysis shows that such methods allow trackers to compete with recently proposed segmentation trackers, while performing quasi real-time.
Nonlinear Model Predictive Control of Robotic Systems with Control Lyapunov Functions
Jun 01, 2020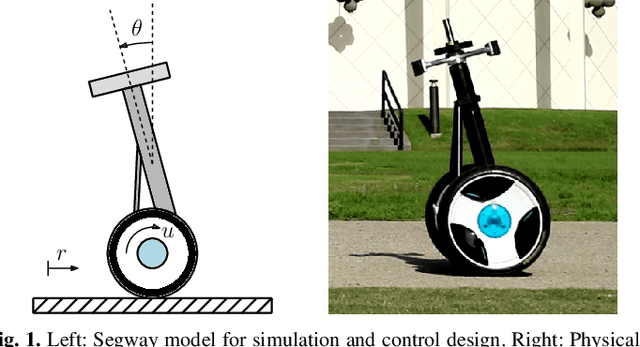
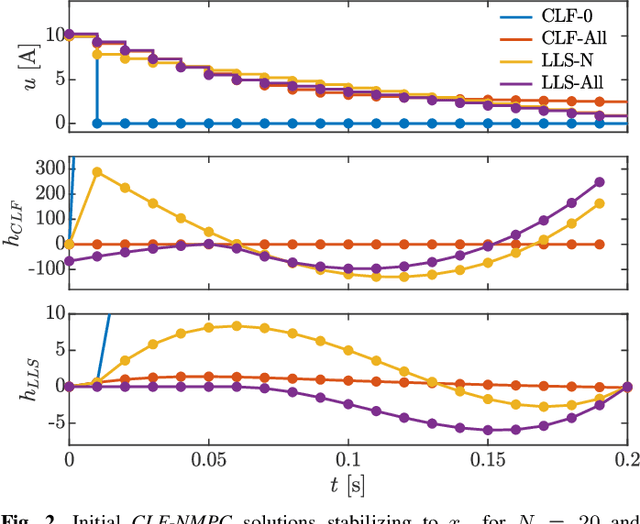
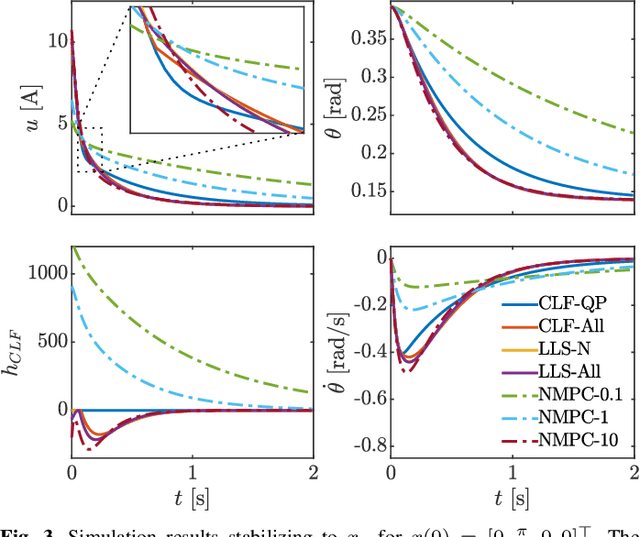
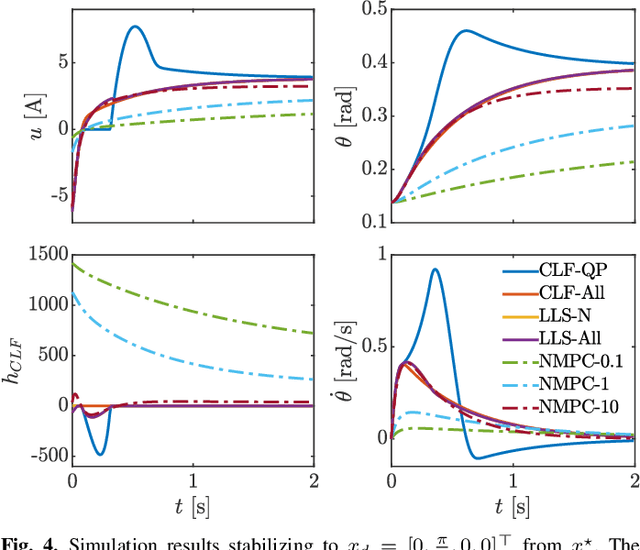
The theoretical unification of Nonlinear Model Predictive Control (NMPC) with Control Lyapunov Functions (CLFs) provides a framework for achieving optimal control performance while ensuring stability guarantees. In this paper we present the first real-time realization of a unified NMPC and CLF controller on a robotic system with limited computational resources. These limitations motivate a set of approaches for efficiently incorporating CLF stability constraints into a general NMPC formulation. We evaluate the performance of the proposed methods compared to baseline CLF and NMPC controllers with a robotic Segway platform both in simulation and on hardware. The addition of a prediction horizon provides a performance advantage over CLF based controllers, which operate optimally point-wise in time. Moreover, the explicitly imposed stability constraints remove the need for difficult cost function and parameter tuning required by NMPC. Therefore the unified controller improves the performance of each isolated controller and simplifies the overall design process.
Asynchronous ε-Greedy Bayesian Optimisation
Oct 16, 2020
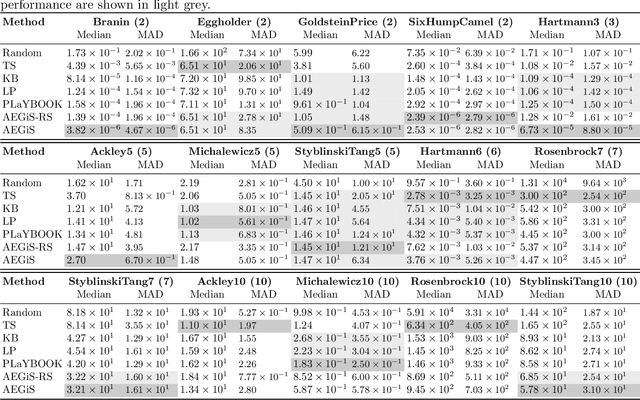
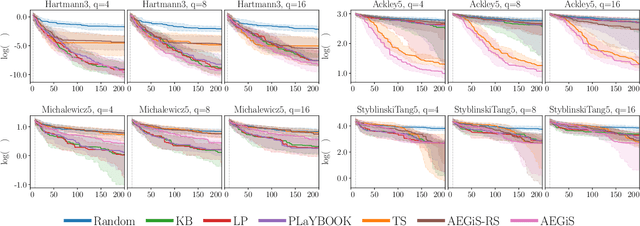
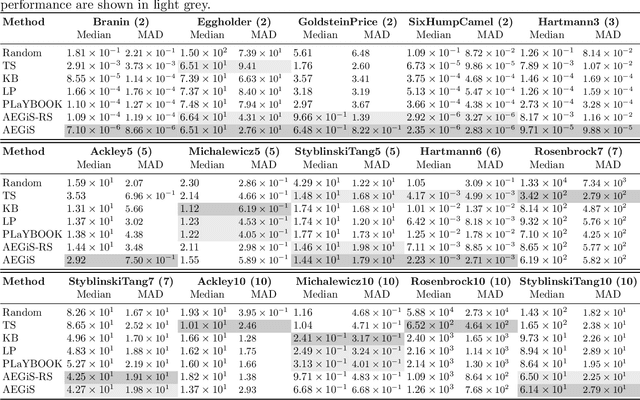
Bayesian Optimisation (BO) is a popular surrogate model-based approach for optimising expensive black-box functions. In order to reduce optimisation wallclock time, parallel evaluation of the black-box function has been proposed. Asynchronous BO allows for a new evaluation to be started as soon as another finishes, thus maximising utilisation of evaluation workers. We present AEGiS (Asynchronous $\epsilon$-Greedy Global Search), an asynchronous BO method that, with probability $2\epsilon$, performs either Thompson sampling or random selection from the approximate Pareto set trading-off between exploitation (surrogate mean prediction) and exploration (surrogate posterior variance). The remaining $1-2\epsilon$ of moves exploit the surrogate's mean prediction. Results on fifteen synthetic benchmark problems, three meta-surrogate hyperparameter tuning problems and two robot pushing problems show that AEGiS generally outperforms existing methods for asynchronous BO. When a single worker is available performance is no worse than BO using expected improvement. We also verify the importance of each of the three components in an ablation study, as well as comparing Pareto set selection to selection from the entire feasible problem domain, finding that the former is vastly superior.
Experience Augmentation: Boosting and Accelerating Off-Policy Multi-Agent Reinforcement Learning
May 19, 2020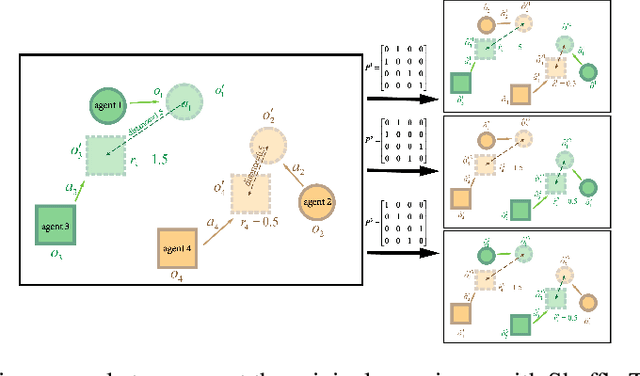

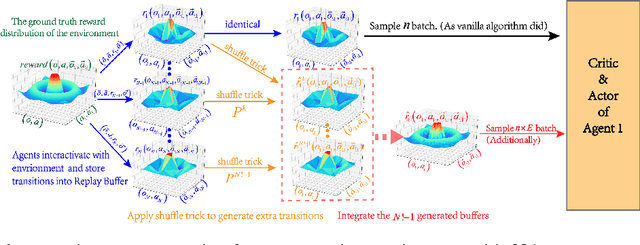

Exploration of the high-dimensional state action space is one of the biggest challenges in Reinforcement Learning (RL), especially in multi-agent domain. We present a novel technique called Experience Augmentation, which enables a time-efficient and boosted learning based on a fast, fair and thorough exploration to the environment. It can be combined with arbitrary off-policy MARL algorithms and is applicable to either homogeneous or heterogeneous environments. We demonstrate our approach by combining it with MADDPG and verifing the performance in two homogeneous and one heterogeneous environments. In the best performing scenario, the MADDPG with experience augmentation reaches to the convergence reward of vanilla MADDPG with 1/4 realistic time, and its convergence beats the original model by a significant margin. Our ablation studies show that experience augmentation is a crucial ingredient which accelerates the training process and boosts the convergence.
Clustering Based on Graph of Density Topology
Sep 24, 2020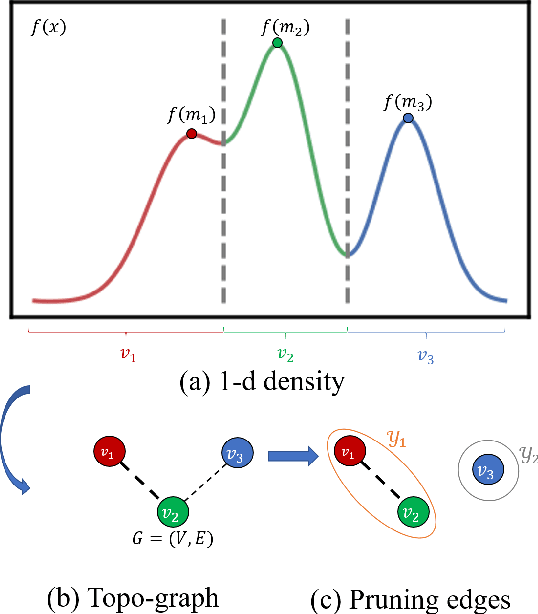

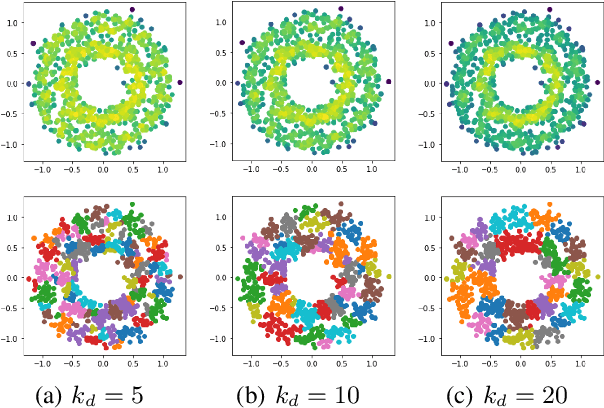
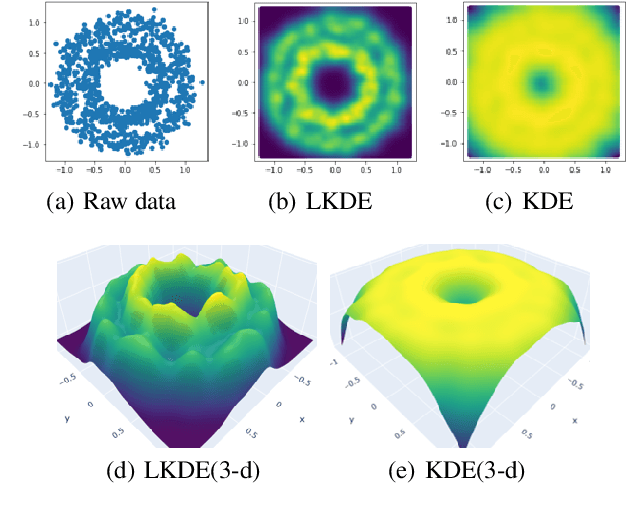
Data clustering with uneven distribution in high level noise is challenging. Currently, HDBSCAN is considered as the SOTA algorithm for this problem. In this paper, we propose a novel clustering algorithm based on what we call graph of density topology (GDT). GDT jointly considers the local and global structures of data samples: firstly forming local clusters based on a density growing process with a strategy for properly noise handling as well as cluster boundary detection; and then estimating a GDT from relationship between local clusters in terms of a connectivity measure, givingglobal topological graph. The connectivity, measuring similarity between neighboring local clusters, is based on local clusters rather than individual points, ensuring its robustness to even very large noise. Evaluation results on both toy and real-world datasets show that GDT achieves the SOTA performance by far on almost all the popular datasets, and has a low time complexity of O(nlogn). The code is available at https://github.com/gaozhangyang/DGC.git.
The Traveling Observer Model: Multi-task Learning Through Spatial Variable Embeddings
Oct 05, 2020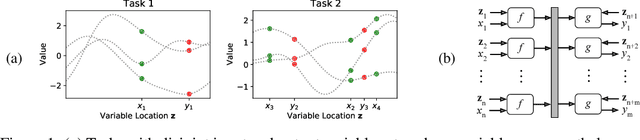
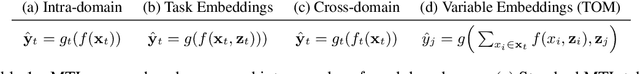
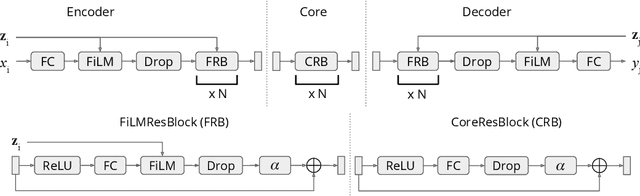

This paper frames a general prediction system as an observer traveling around a continuous space, measuring values at some locations, and predicting them at others. The observer is completely agnostic about any particular task being solved; it cares only about measurement locations and their values. This perspective leads to a machine learning framework in which seemingly unrelated tasks can be solved by a single model, by embedding their input and output variables into a shared space. An implementation of the framework is developed in which these variable embeddings are learned jointly with internal model parameters. In experiments, the approach is shown to (1) recover intuitive locations of variables in space and time, (2) exploit regularities across related datasets with completely disjoint input and output spaces, and (3) exploit regularities across seemingly unrelated tasks, outperforming task-specific single-task models and multi-task learning alternatives. The results suggest that even seemingly unrelated tasks may originate from similar underlying processes, a fact that the traveling observer model can use to make better predictions.
RealHePoNet: a robust single-stage ConvNet for head pose estimation in the wild
Nov 03, 2020
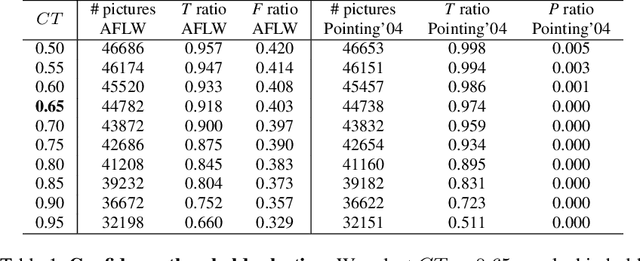

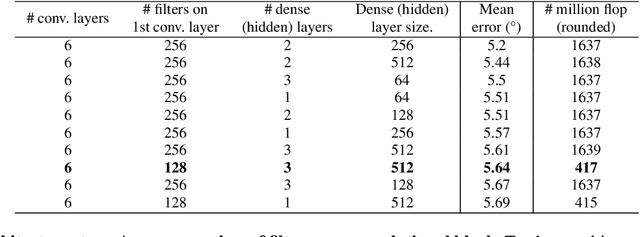
Human head pose estimation in images has applications in many fields such as human-computer interaction or video surveillance tasks. In this work, we address this problem, defined here as the estimation of both vertical (tilt/pitch) and horizontal (pan/yaw) angles, through the use of a single Convolutional Neural Network (ConvNet) model, trying to balance precision and inference speed in order to maximize its usability in real-world applications. Our model is trained over the combination of two datasets: 'Pointing'04' (aiming at covering a wide range of poses) and 'Annotated Facial Landmarks in the Wild' (in order to improve robustness of our model for its use on real-world images). Three different partitions of the combined dataset are defined and used for training, validation and testing purposes. As a result of this work, we have obtained a trained ConvNet model, coined RealHePoNet, that given a low-resolution grayscale input image, and without the need of using facial landmarks, is able to estimate with low error both tilt and pan angles (~4.4{\deg} average error on the test partition). Also, given its low inference time (~6 ms per head), we consider our model usable even when paired with medium-spec hardware (i.e. GTX 1060 GPU). * Code available at: https://github.com/rafabs97/headpose_final * Demo video at: https://www.youtube.com/watch?v=2UeuXh5DjAE