 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
That is a Known Lie: Detecting Previously Fact-Checked Claims
May 12, 2020
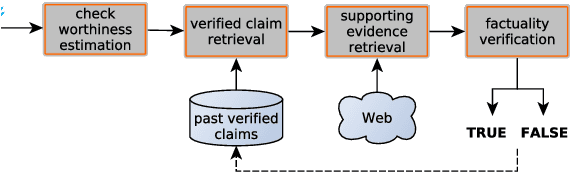
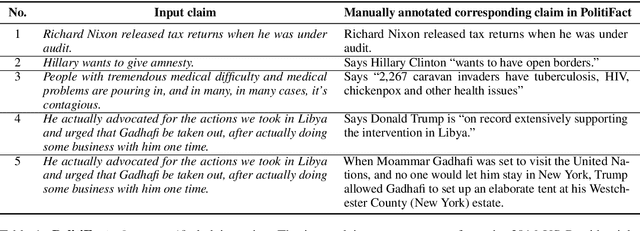

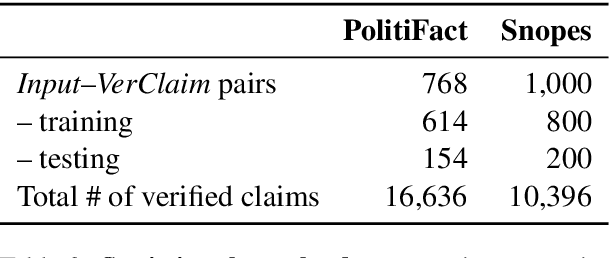
The recent proliferation of "fake news" has triggered a number of responses, most notably the emergence of several manual fact-checking initiatives. As a result and over time, a large number of fact-checked claims have been accumulated, which increases the likelihood that a new claim in social media or a new statement by a politician might have already been fact-checked by some trusted fact-checking organization, as viral claims often come back after a while in social media, and politicians like to repeat their favorite statements, true or false, over and over again. As manual fact-checking is very time-consuming (and fully automatic fact-checking has credibility issues), it is important to try to save this effort and to avoid wasting time on claims that have already been fact-checked. Interestingly, despite the importance of the task, it has been largely ignored by the research community so far. Here, we aim to bridge this gap. In particular, we formulate the task and we discuss how it relates to, but also differs from, previous work. We further create a specialized dataset, which we release to the research community. Finally, we present learning-to-rank experiments that demonstrate sizable improvements over state-of-the-art retrieval and textual similarity approaches.
* detecting previously fact-checked claims, fact-checking, disinformation, fake news, social media, political debates
CASS-NAT: CTC Alignment-based Single Step Non-autoregressive Transformer for Speech Recognition
Oct 28, 2020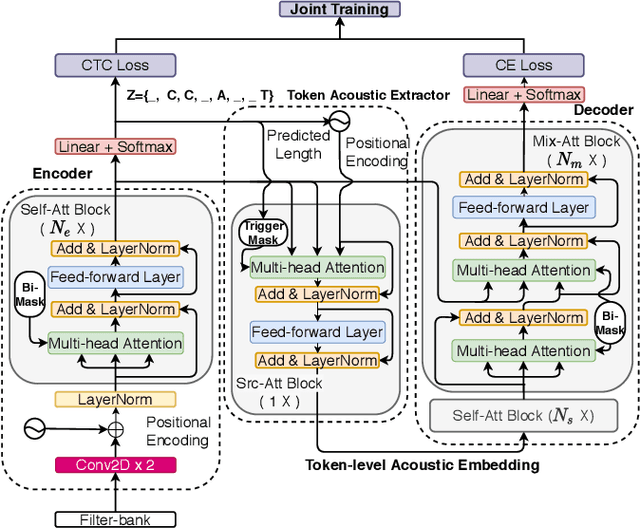
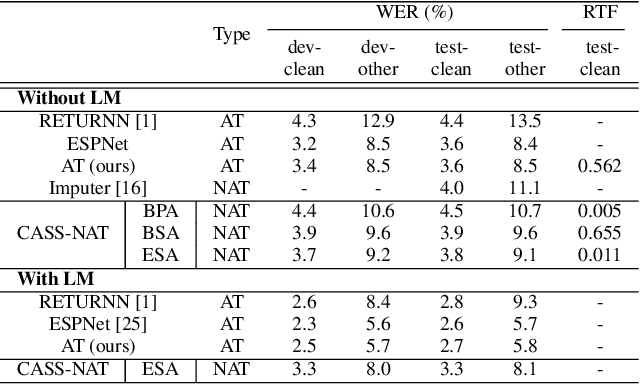


We propose a CTC alignment-based single step non-autoregressive transformer (CASS-NAT) for speech recognition. Specifically, the CTC alignment contains the information of (a) the number of tokens for decoder input, and (b) the time span of acoustics for each token. The information are used to extract acoustic representation for each token in parallel, referred to as token-level acoustic embedding which substitutes the word embedding in autoregressive transformer (AT) to achieve parallel generation in decoder. During inference, an error-based alignment sampling method is proposed to be applied to the CTC output space, reducing the WER and retaining the parallelism as well. Experimental results show that the proposed method achieves WERs of 3.8%/9.1% on Librispeech test clean/other dataset without an external LM, and a CER of 5.8% on Aishell1 Mandarin corpus, respectively1. Compared to the AT baseline, the CASS-NAT has a performance reduction on WER, but is 51.2x faster in terms of RTF. When decoding with an oracle CTC alignment, the lower bound of WER without LM reaches 2.3% on the test-clean set, indicating the potential of the proposed method.
Deep-learning based down-scaling of summer monsoon rainfall data over Indian region
Nov 23, 2020
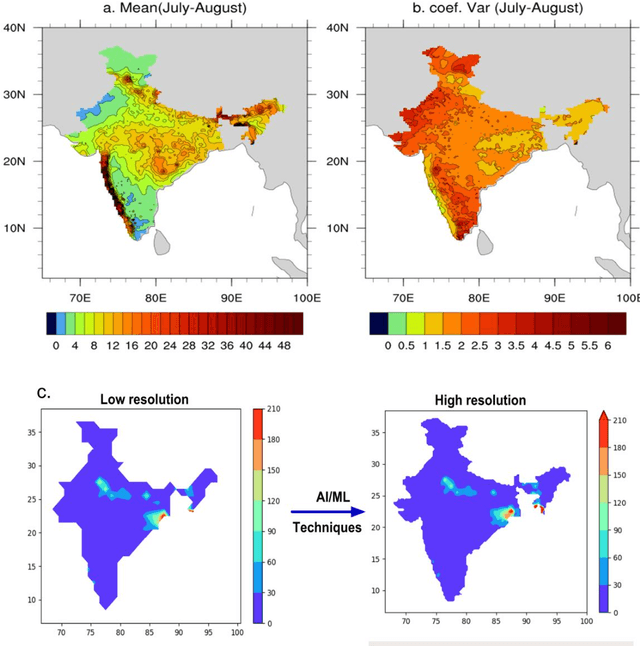
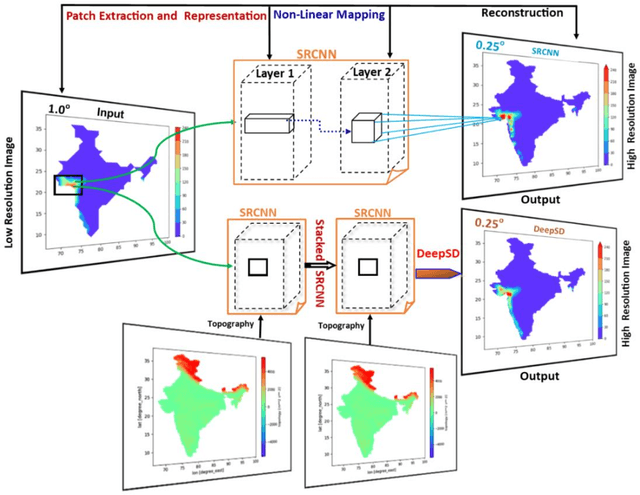
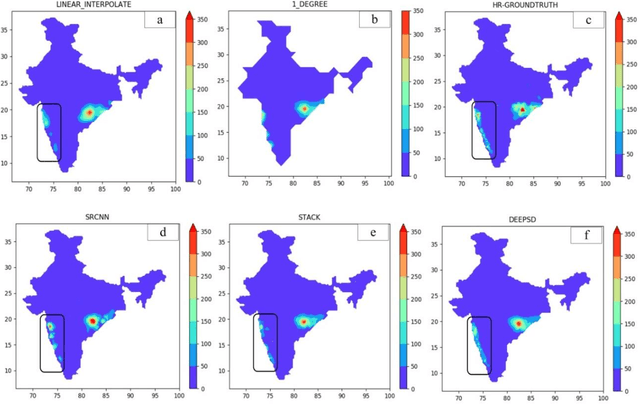
Downscaling is necessary to generate high-resolution observation data to validate the climate model forecast or monitor rainfall at the micro-regional level operationally. Dynamical and statistical downscaling models are often used to get information at high-resolution gridded data over larger domains. As rainfall variability is dependent on the complex Spatio-temporal process leading to non-linear or chaotic Spatio-temporal variations, no single downscaling method can be considered efficient enough. In data with complex topographies, quasi-periodicities, and non-linearities, deep Learning (DL) based methods provide an efficient solution in downscaling rainfall data for regional climate forecasting and real-time rainfall observation data at high spatial resolutions. In this work, we employed three deep learning-based algorithms derived from the super-resolution convolutional neural network (SRCNN) methods, to precipitation data, in particular, IMD and TRMM data to produce 4x-times high-resolution downscaled rainfall data during the summer monsoon season. Among the three algorithms, namely SRCNN, stacked SRCNN, and DeepSD, employed here, the best spatial distribution of rainfall amplitude and minimum root-mean-square error is produced by DeepSD based downscaling. Hence, the use of the DeepSD algorithm is advocated for future use. We found that spatial discontinuity in amplitude and intensity rainfall patterns is the main obstacle in the downscaling of precipitation. Furthermore, we applied these methods for model data postprocessing, in particular, ERA5 data. Downscaled ERA5 rainfall data show a much better distribution of spatial covariance and temporal variance when compared with observation.
Mo2Cap2: Real-time Mobile 3D Motion Capture with a Cap-mounted Fisheye Camera
Mar 15, 2018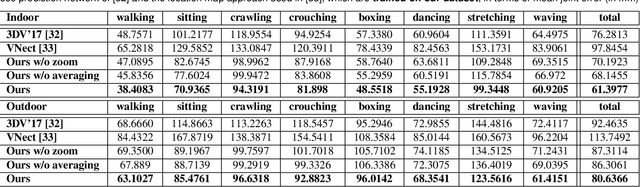


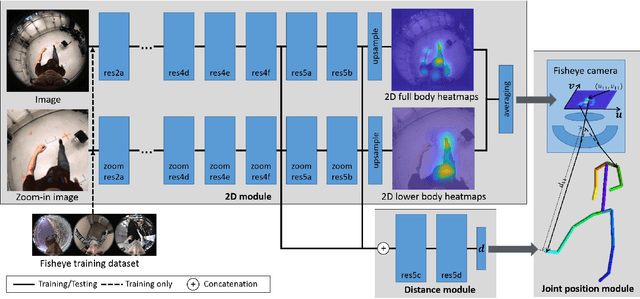
We propose the first real-time approach for the egocentric estimation of 3D human body pose in a wide range of unconstrained everyday activities. This setting has a unique set of challenges, such as mobility of the hardware setup, and robustness to long capture sessions with fast recovery from tracking failures. We tackle these challenges based on a novel lightweight setup that converts a standard baseball cap to a device for high-quality pose estimation based on a single cap-mounted fisheye camera. From the captured egocentric live stream, our CNN based 3D pose estimation approach runs at 60Hz on a consumer-level GPU. In addition to the novel hardware setup, our other main contributions are: 1) a large ground truth training corpus of top-down fisheye images and 2) a novel disentangled 3D pose estimation approach that takes the unique properties of the egocentric viewpoint into account. As shown by our evaluation, we achieve lower 3D joint error as well as better 2D overlay than the existing baselines.
PoWER-BERT: Accelerating BERT inference for Classification Tasks
Jan 24, 2020
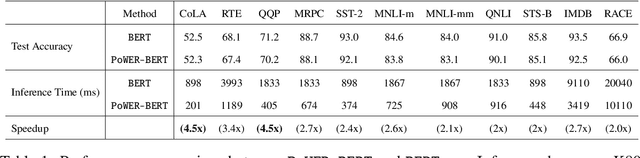
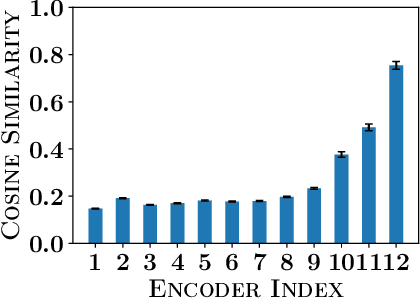
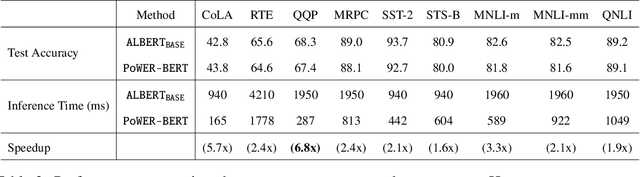
BERT has emerged as a popular model for natural language understanding. Given its compute intensive nature, even for inference, many recent studies have considered optimization of two important performance characteristics: model size and inference time. We consider classification tasks and propose a novel method, called PoWER-BERT, for improving the inference time for the BERT model without significant loss in the accuracy. The method works by eliminating word-vectors (intermediate vector outputs) from the encoder pipeline. We design a strategy for measuring the significance of the word-vectors based on the self-attention mechanism of the encoders which helps us identify the word-vectors to be eliminated. Experimental evaluation on the standard GLUE benchmark shows that PoWER-BERT achieves up to 4.5x reduction in inference time over BERT with < 1% loss in accuracy. We show that compared to the prior inference time reduction methods, PoWER-BERT offers better trade-off between accuracy and inference time. Lastly, we demonstrate that our scheme can also be used in conjunction with ALBERT (a highly compressed version of BERT) and can attain up to 6.8x factor reduction in inference time with < 1% loss in accuracy.
Simulating Crowds and Autonomous Vehicles
Aug 25, 2020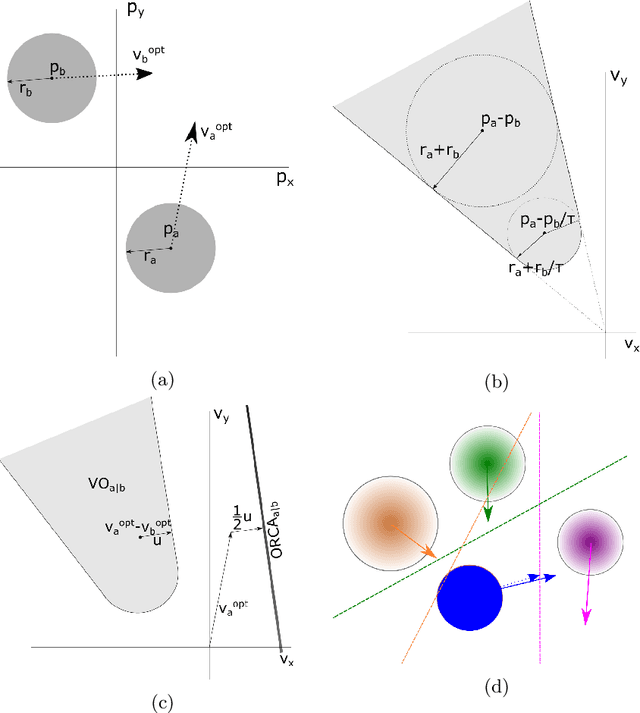


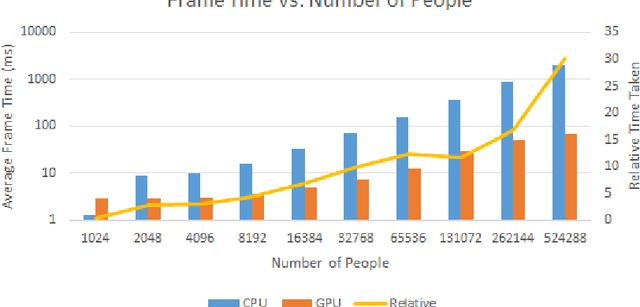
Understanding how people view and interact with autonomous vehicles is important to guide future directions of research. One such way of aiding understanding is through simulations of virtual environments involving people and autonomous vehicles. We present a simulation model that incorporates people and autonomous vehicles in a shared urban space. The model is able to simulate many thousands of people and vehicles in real-time. This is achieved by use of GPU hardware, and through a novel linear program solver optimized for large numbers of problems on the GPU. The model is up to 30 times faster than the equivalent multi-core CPU model.
* 15 pages, 4 figures. arXiv admin note: substantial text overlap with arXiv:1908.10107
AAMDRL: Augmented Asset Management with Deep Reinforcement Learning
Sep 30, 2020
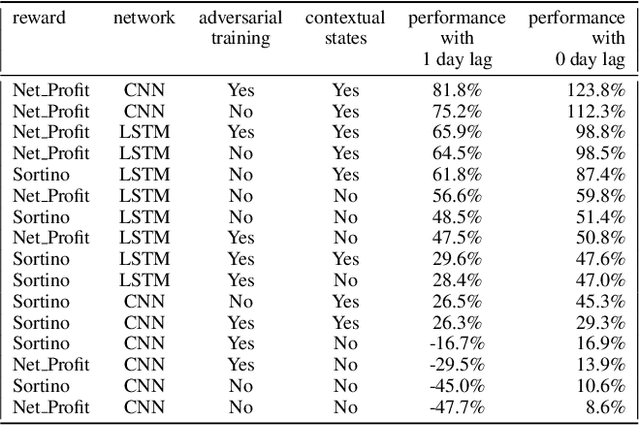

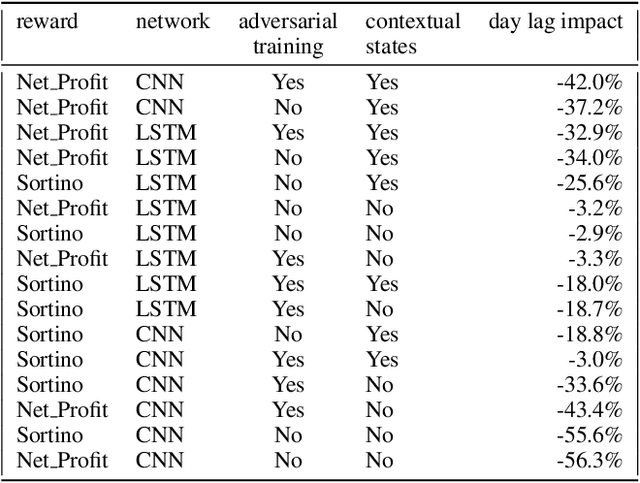
Can an agent learn efficiently in a noisy and self adapting environment with sequential, non-stationary and non-homogeneous observations? Through trading bots, we illustrate how Deep Reinforcement Learning (DRL) can tackle this challenge. Our contributions are threefold: (i) the use of contextual information also referred to as augmented state in DRL, (ii) the impact of a one period lag between observations and actions that is more realistic for an asset management environment, (iii) the implementation of a new repetitive train test method called walk forward analysis, similar in spirit to cross validation for time series. Although our experiment is on trading bots, it can easily be translated to other bot environments that operate in sequential environment with regime changes and noisy data. Our experiment for an augmented asset manager interested in finding the best portfolio for hedging strategies shows that AAMDRL achieves superior returns and lower risk.
Recurrent Graph Tensor Networks
Oct 17, 2020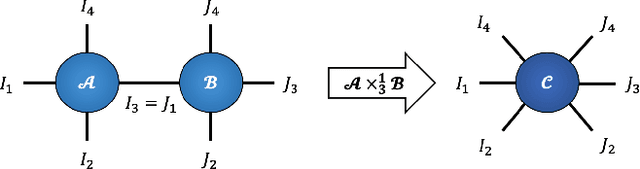

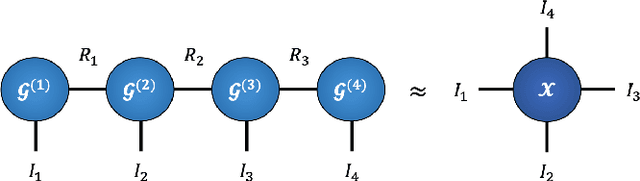
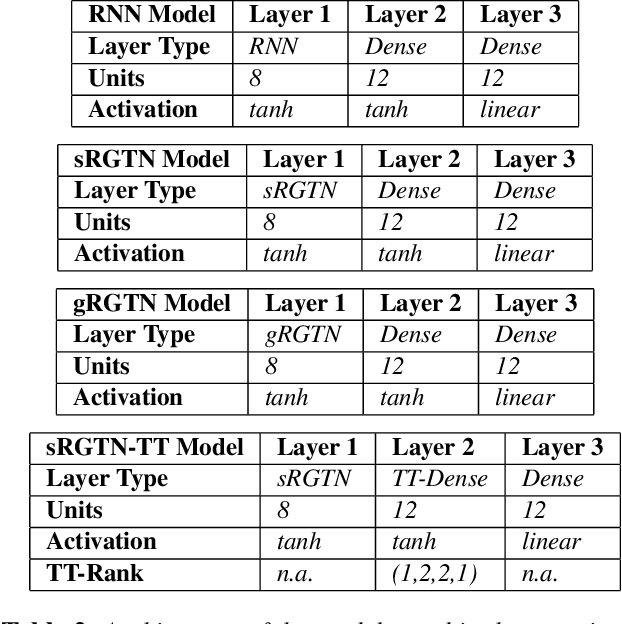
Recurrent Neural Networks (RNNs) are among the most successful machine learning models for sequence modelling. In this paper, we show that the modelling of hidden states in RNNs can be approximated through a multi-linear graph filter, which describes the directional flow of temporal information. The so derived multi-linear graph filter is then generalized to a tensor network form to improve its modelling power, resulting in a novel Recurrent Graph Tensor Network (RGTN). To validate the expressive power of the derived network, several variants of RGTN models were proposed and employed for the task of time-series forecasting, demonstrating superior properties in terms of convergence, performance, and complexity. By leveraging the multi-modal nature of tensor networks, RGTN models were shown to out-perform a standard RNN by 23% in terms of mean-squared-error while using up to 86% less parameters. Therefore, by combining the expressive power of tensor networks with a suitable graph filter, we show that the proposed RGTN models can out-perform a classical RNN at a drastically lower parameter complexity, especially in the multi-modal setting.
Multiple Word Embeddings for Increased Diversity of Representation
Sep 30, 2020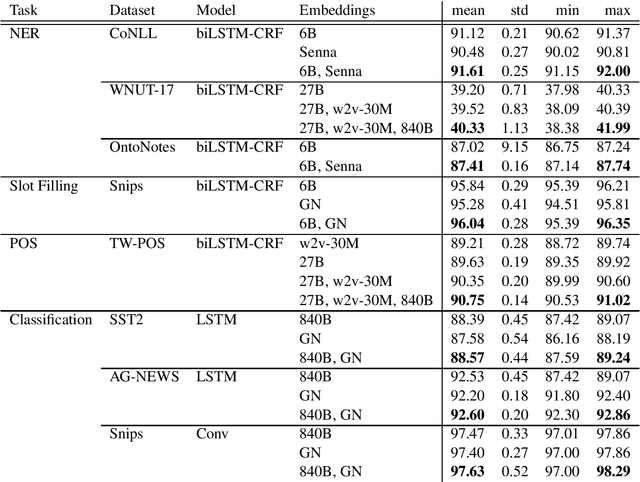

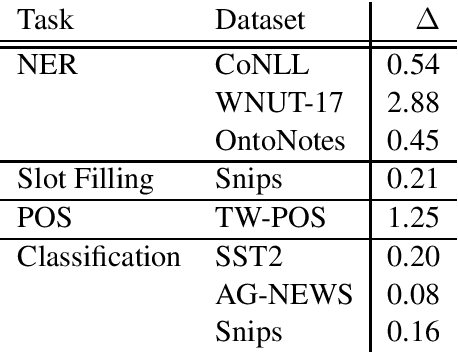
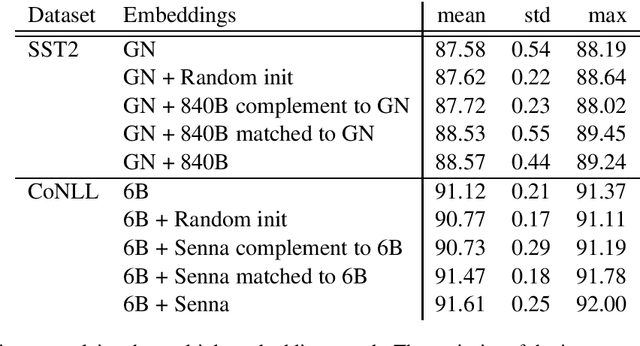
Most state-of-the-art models in natural language processing (NLP) are neural models built on top of large, pre-trained, contextual language models that generate representations of words in context and are fine-tuned for the task at hand. The improvements afforded by these "contextual embeddings" come with a high computational cost. In this work, we explore a simple technique that substantially and consistently improves performance over a strong baseline with negligible increase in run time. We concatenate multiple pre-trained embeddings to strengthen our representation of words. We show that this concatenation technique works across many tasks, datasets, and model types. We analyze aspects of pre-trained embedding similarity and vocabulary coverage and find that the representational diversity between different pre-trained embeddings is the driving force of why this technique works. We provide open source implementations of our models in both TensorFlow and PyTorch.
UniCon: Universal Neural Controller For Physics-based Character Motion
Nov 30, 2020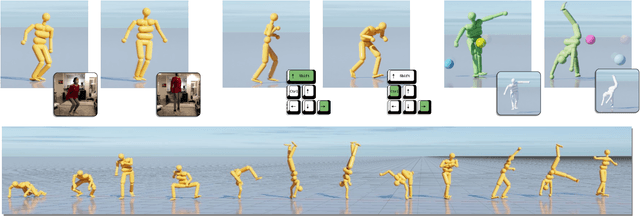
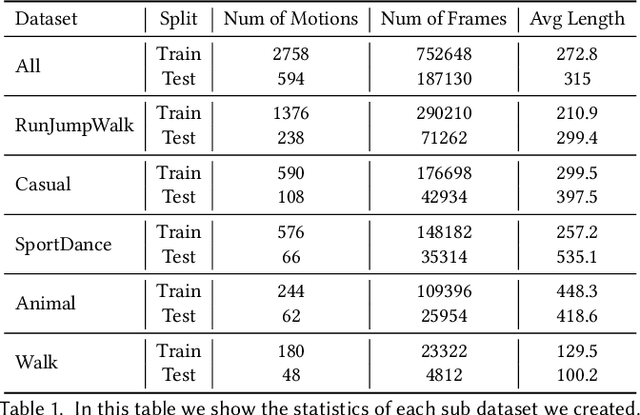
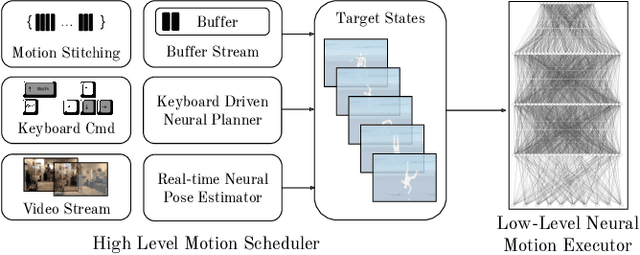

The field of physics-based animation is gaining importance due to the increasing demand for realism in video games and films, and has recently seen wide adoption of data-driven techniques, such as deep reinforcement learning (RL), which learn control from (human) demonstrations. While RL has shown impressive results at reproducing individual motions and interactive locomotion, existing methods are limited in their ability to generalize to new motions and their ability to compose a complex motion sequence interactively. In this paper, we propose a physics-based universal neural controller (UniCon) that learns to master thousands of motions with different styles by learning on large-scale motion datasets. UniCon is a two-level framework that consists of a high-level motion scheduler and an RL-powered low-level motion executor, which is our key innovation. By systematically analyzing existing multi-motion RL frameworks, we introduce a novel objective function and training techniques which make a significant leap in performance. Once trained, our motion executor can be combined with different high-level schedulers without the need for retraining, enabling a variety of real-time interactive applications. We show that UniCon can support keyboard-driven control, compose motion sequences drawn from a large pool of locomotion and acrobatics skills and teleport a person captured on video to a physics-based virtual avatar. Numerical and qualitative results demonstrate a significant improvement in efficiency, robustness and generalizability of UniCon over prior state-of-the-art, showcasing transferability to unseen motions, unseen humanoid models and unseen perturbation.