 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Uncertainty Quantification for Hyperspectral Image Denoising Frameworks based on Low-rank Matrix Approximation
Apr 23, 2020

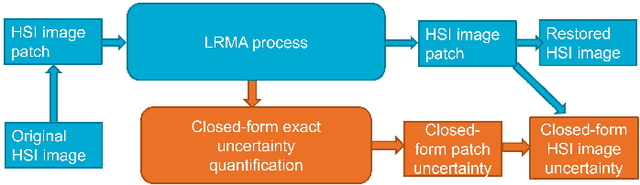

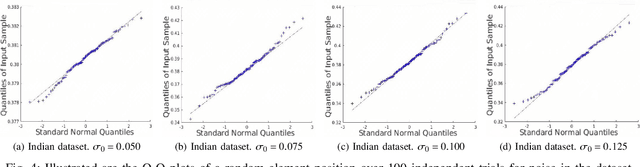
Low-rank matrix approximation (LRMA) is a technique widely applied in hyperspectral images (HSI) denoising or completion. The uncertainty quantification of the estimated restored HSI, however, has not been addressed in previous researches. The lack of uncertainty of the product significantly limits the applications like multi-source or multi-scale data fusion, data assimilation and product confidence quantification, since these applications require an accurate way to describe the statistical distributions of the source data. To address this issue, we propose a prior-free closed-form element-wise uncertainty quantification method for the LRMA based HSI restoration. The proposed approach only requires the uncertainty of the observed HSI and can yield uncertainty in a limited amount of time and with similar time complexity comparing to the LRMA technique. We conduct extensive experiments to validate that the closed-form uncertainty describes the estimation accurately, is robust to at least 10\% ratio of random impulse noises and takes only around 10-20% amount of time of LRMA. All the experiments indicate that the proposed closed-form uncertainty quantification method is more applicable to be deployed to real-world applications than the baseline Monte-Carlo tests.
S3VAE: Self-Supervised Sequential VAE for Representation Disentanglement and Data Generation
May 23, 2020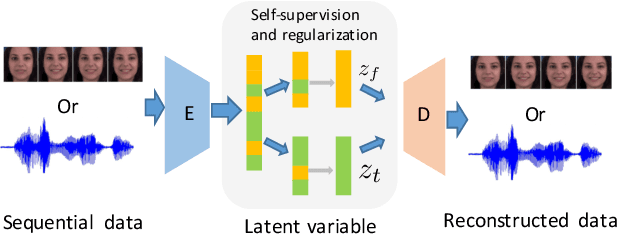

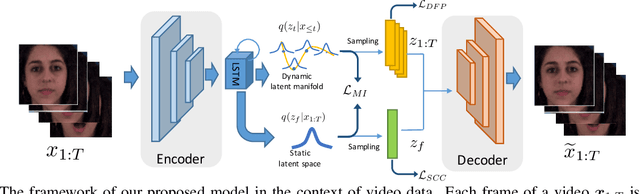
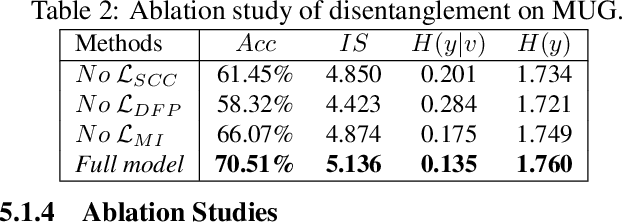
We propose a sequential variational autoencoder to learn disentangled representations of sequential data (e.g., videos and audios) under self-supervision. Specifically, we exploit the benefits of some readily accessible supervisory signals from input data itself or some off-the-shelf functional models and accordingly design auxiliary tasks for our model to utilize these signals. With the supervision of the signals, our model can easily disentangle the representation of an input sequence into static factors and dynamic factors (i.e., time-invariant and time-varying parts). Comprehensive experiments across videos and audios verify the effectiveness of our model on representation disentanglement and generation of sequential data, and demonstrate that, our model with self-supervision performs comparable to, if not better than, the fully-supervised model with ground truth labels, and outperforms state-of-the-art unsupervised models by a large margin.
Primal-Dual $π$ Learning: Sample Complexity and Sublinear Run Time for Ergodic Markov Decision Problems
Oct 17, 2017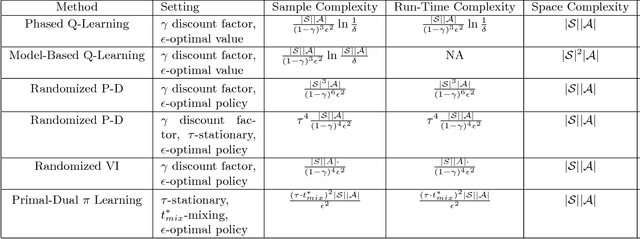
Consider the problem of approximating the optimal policy of a Markov decision process (MDP) by sampling state transitions. In contrast to existing reinforcement learning methods that are based on successive approximations to the nonlinear Bellman equation, we propose a Primal-Dual $\pi$ Learning method in light of the linear duality between the value and policy. The $\pi$ learning method is model-free and makes primal-dual updates to the policy and value vectors as new data are revealed. For infinite-horizon undiscounted Markov decision process with finite state space $S$ and finite action space $A$, the $\pi$ learning method finds an $\epsilon$-optimal policy using the following number of sample transitions $$ \tilde{O}( \frac{(\tau\cdot t^*_{mix})^2 |S| |A| }{\epsilon^2} ),$$ where $t^*_{mix}$ is an upper bound of mixing times across all policies and $\tau$ is a parameter characterizing the range of stationary distributions across policies. The $\pi$ learning method also applies to the computational problem of MDP where the transition probabilities and rewards are explicitly given as the input. In the case where each state transition can be sampled in $\tilde{O}(1)$ time, the $\pi$ learning method gives a sublinear-time algorithm for solving the averaged-reward MDP.
Decoupling Pronunciation and Language for End-to-end Code-switching Automatic Speech Recognition
Oct 28, 2020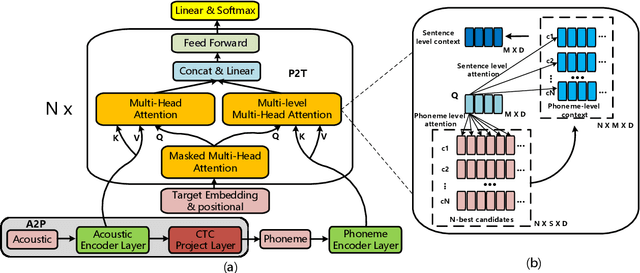
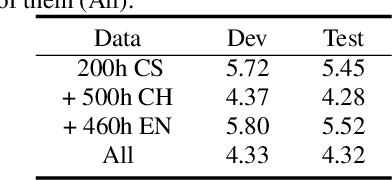
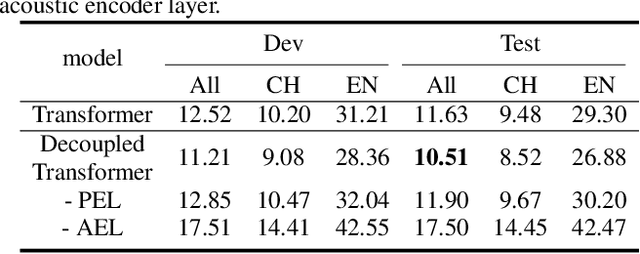
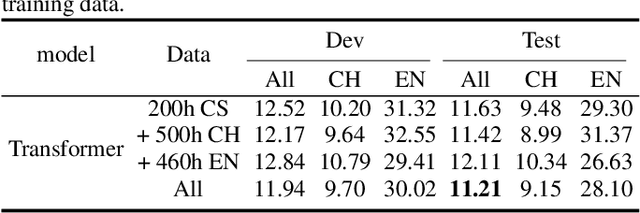
Despite the recent significant advances witnessed in end-to-end (E2E) ASR system for code-switching, hunger for audio-text paired data limits the further improvement of the models' performance. In this paper, we propose a decoupled transformer model to use monolingual paired data and unpaired text data to alleviate the problem of code-switching data shortage. The model is decoupled into two parts: audio-to-phoneme (A2P) network and phoneme-to-text (P2T) network. The A2P network can learn acoustic pattern scenarios using large-scale monolingual paired data. Meanwhile, it generates multiple phoneme sequence candidates for single audio data in real-time during the training process. Then the generated phoneme-text paired data is used to train the P2T network. This network can be pre-trained with large amounts of external unpaired text data. By using monolingual data and unpaired text data, the decoupled transformer model reduces the high dependency on code-switching paired training data of E2E model to a certain extent. Finally, the two networks are optimized jointly through attention fusion. We evaluate the proposed method on the public Mandarin-English code-switching dataset. Compared with our transformer baseline, the proposed method achieves 18.14% relative mix error rate reduction.
Managing Industrial Communication Delays with Software-Defined Networking
Apr 14, 2020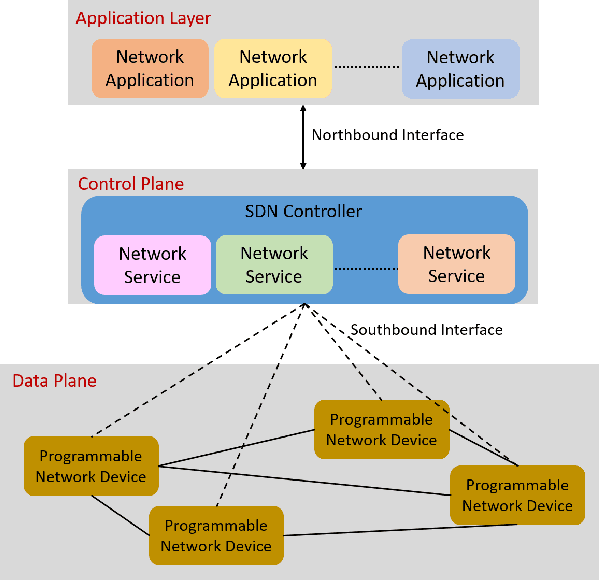
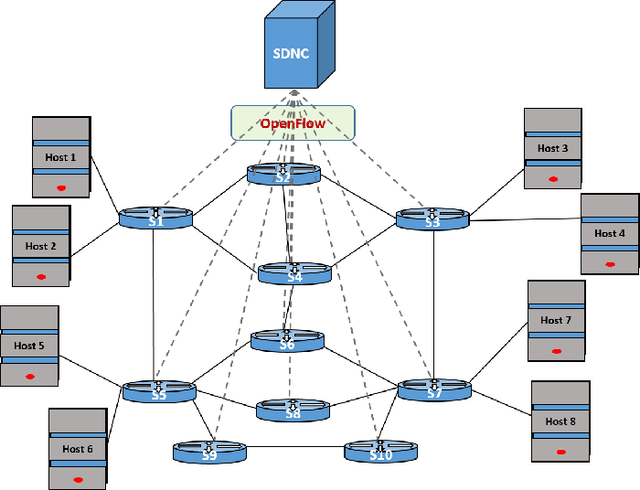
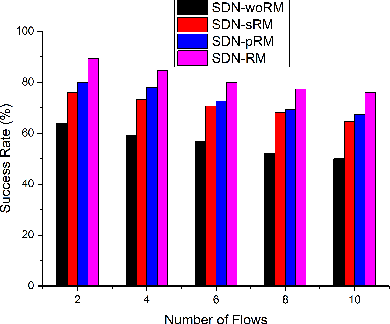
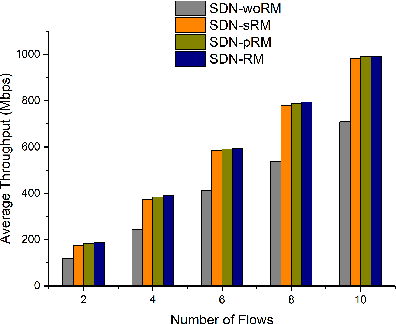
Recent technological advances have fostered the development of complex industrial cyber-physical systems which demand real-time communication with delay guarantees. The consequences of delay requirement violation in such systems may become increasingly severe. In this paper, we propose a contract-based fault-resilient methodology which aims at managing the communication delays of real-time flows in industries. With this objective, we present a light-weight mechanism to estimate end-to-end delay in the network in which the clocks of the switches are not synchronized. The mechanism aims at providing high level of accuracy with lower communication overhead. We then propose a contract-based framework using software-defined networking where the components are associated with delay contracts and a resilience manager. The proposed resilience management framework contains: (1) contracts which state guarantees about components behaviors, (2) observers which are responsible to detect contract failure (fault), (3) monitors to detect events such as run-time changes in the delay requirements and link failure, (4) control logic to take suitable decisions based on the type of the fault, (5) resilience manager to decide response strategies containing the best course of action as per the control logic decision. Finally, we present a delay-aware path finding algorithm which is used to route/reroute the real-time flows to provide resiliency in the case of faults and, to adapt to the changes in the network state. Performance of the proposed framework is evaluated with the Ryu SDN controller and Mininet network emulator.
Bidirectional Recurrent Neural Networks as Generative Models - Reconstructing Gaps in Time Series
Nov 02, 2015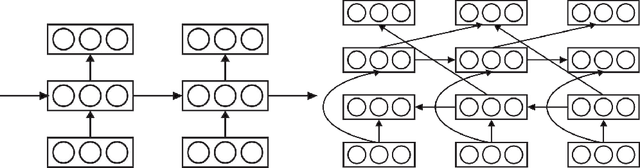

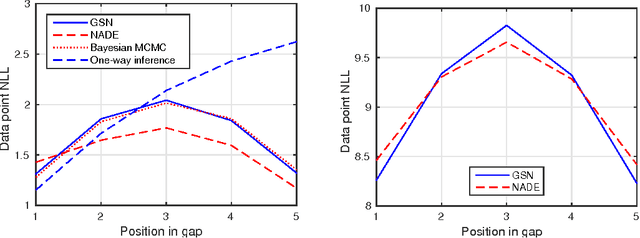
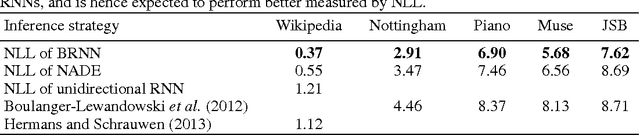
Bidirectional recurrent neural networks (RNN) are trained to predict both in the positive and negative time directions simultaneously. They have not been used commonly in unsupervised tasks, because a probabilistic interpretation of the model has been difficult. Recently, two different frameworks, GSN and NADE, provide a connection between reconstruction and probabilistic modeling, which makes the interpretation possible. As far as we know, neither GSN or NADE have been studied in the context of time series before. As an example of an unsupervised task, we study the problem of filling in gaps in high-dimensional time series with complex dynamics. Although unidirectional RNNs have recently been trained successfully to model such time series, inference in the negative time direction is non-trivial. We propose two probabilistic interpretations of bidirectional RNNs that can be used to reconstruct missing gaps efficiently. Our experiments on text data show that both proposed methods are much more accurate than unidirectional reconstructions, although a bit less accurate than a computationally complex bidirectional Bayesian inference on the unidirectional RNN. We also provide results on music data for which the Bayesian inference is computationally infeasible, demonstrating the scalability of the proposed methods.
Generalizable and Explainable Dialogue Generation via Explicit Action Learning
Oct 08, 2020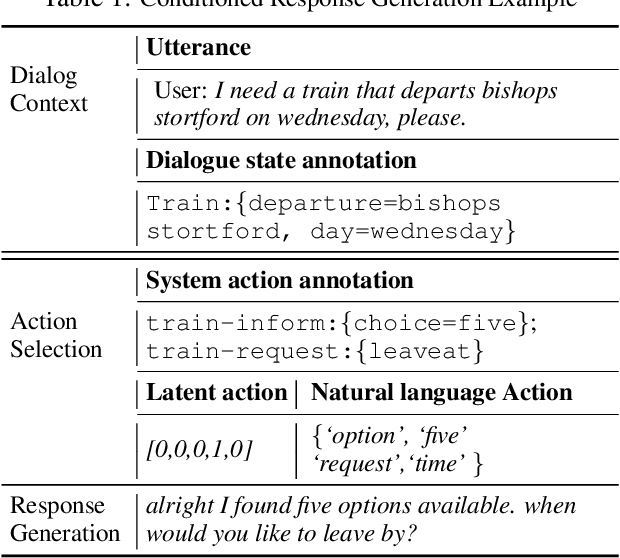
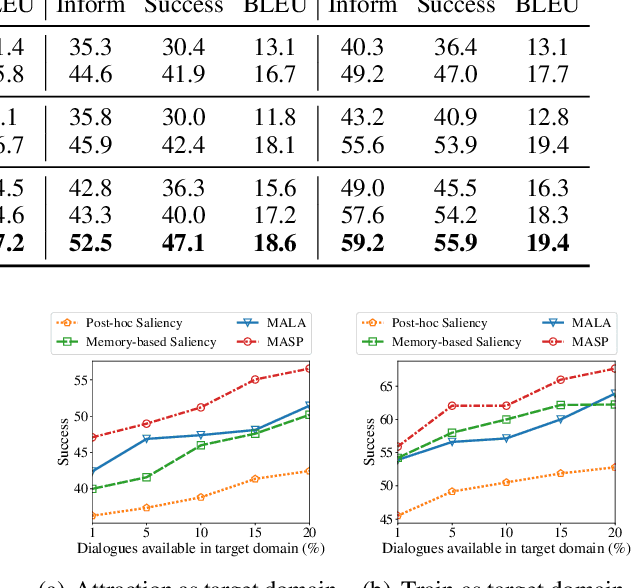
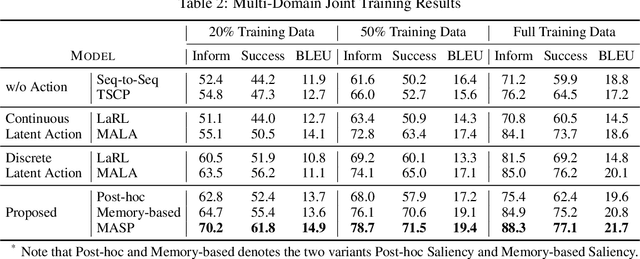
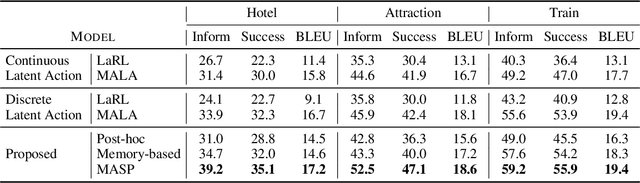
Response generation for task-oriented dialogues implicitly optimizes two objectives at the same time: task completion and language quality. Conditioned response generation serves as an effective approach to separately and better optimize these two objectives. Such an approach relies on system action annotations which are expensive to obtain. To alleviate the need of action annotations, latent action learning is introduced to map each utterance to a latent representation. However, this approach is prone to over-dependence on the training data, and the generalization capability is thus restricted. To address this issue, we propose to learn natural language actions that represent utterances as a span of words. This explicit action representation promotes generalization via the compositional structure of language. It also enables an explainable generation process. Our proposed unsupervised approach learns a memory component to summarize system utterances into a short span of words. To further promote a compact action representation, we propose an auxiliary task that restores state annotations as the summarized dialogue context using the memory component. Our proposed approach outperforms latent action baselines on MultiWOZ, a benchmark multi-domain dataset.
Scalable Synthesis of Minimum-Information Linear-Gaussian Control by Distributed Optimization
Apr 11, 2020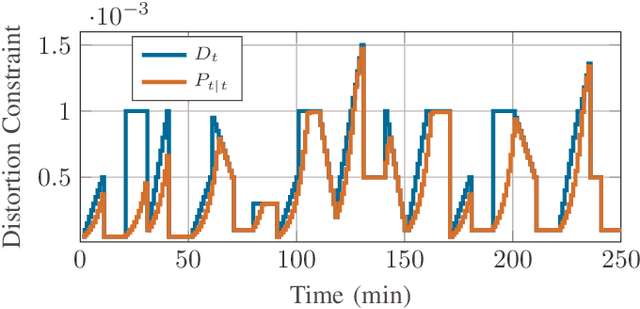
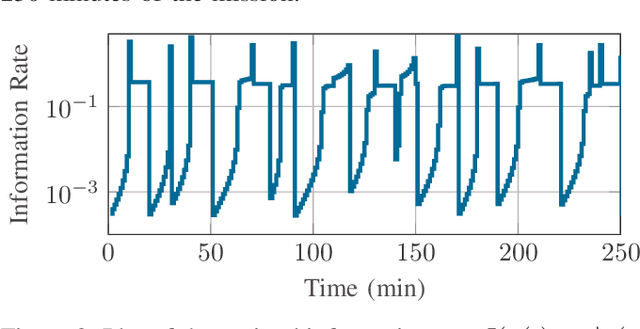
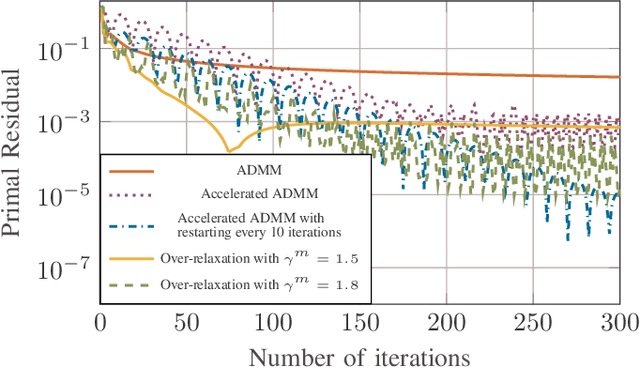
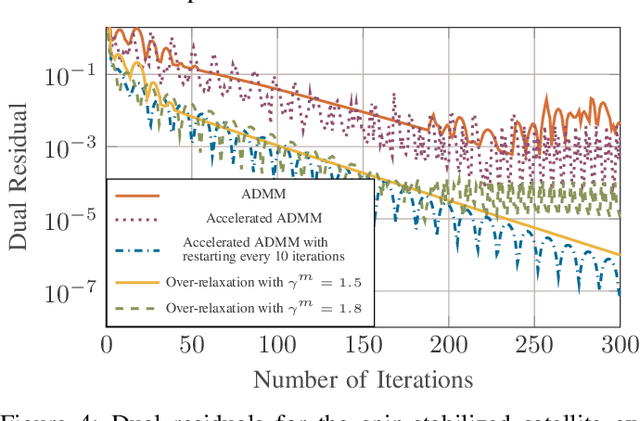
We consider a discrete-time linear-quadratic Gaussian control problem in which we minimize a weighted sum of the directed information from the state of the system to the control input and the control cost. The optimal control and sensing policies can be synthesized jointly by solving a semidefinite programming problem. However, the existing solutions typically scale cubic with the horizon length. We leverage the structure in the problem to develop a distributed algorithm that decomposes the synthesis problem into a set of smaller problems, one for each time step. We prove that the algorithm runs in time linear in the horizon length. As an application of the algorithm, we consider a path-planning problem in a state space with obstacles under the presence of stochastic disturbances. The algorithm computes a locally optimal solution that jointly minimizes the perception and control cost while ensuring the safety of the path. The numerical examples show that the algorithm can scale to thousands of horizon length and compute locally optimal solutions.
Leveraging Discourse Rewards for Document-Level Neural Machine Translation
Oct 08, 2020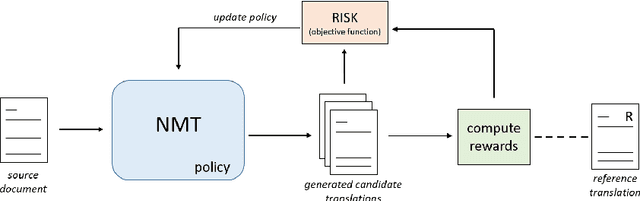
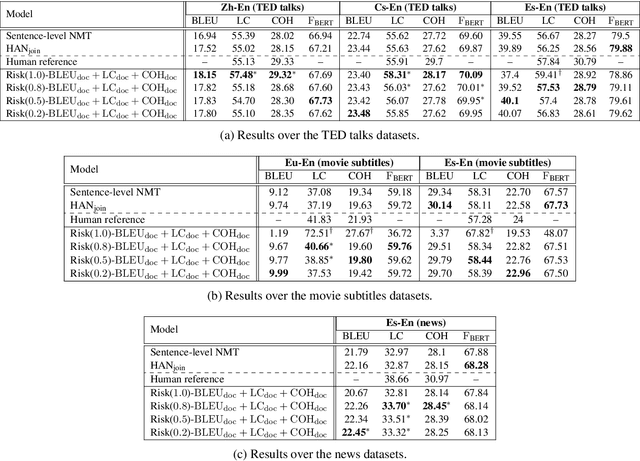
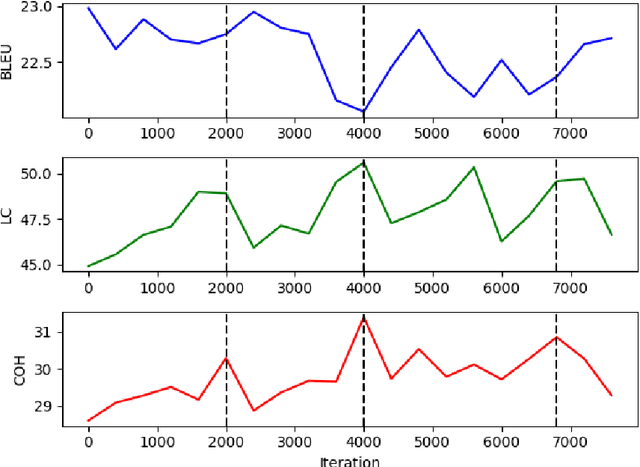
Document-level machine translation focuses on the translation of entire documents from a source to a target language. It is widely regarded as a challenging task since the translation of the individual sentences in the document needs to retain aspects of the discourse at document level. However, document-level translation models are usually not trained to explicitly ensure discourse quality. Therefore, in this paper we propose a training approach that explicitly optimizes two established discourse metrics, lexical cohesion (LC) and coherence (COH), by using a reinforcement learning objective. Experiments over four different language pairs and three translation domains have shown that our training approach has been able to achieve more cohesive and coherent document translations than other competitive approaches, yet without compromising the faithfulness to the reference translation. In the case of the Zh-En language pair, our method has achieved an improvement of 2.46 percentage points (pp) in LC and 1.17 pp in COH over the runner-up, while at the same time improving 0.63 pp in BLEU score and 0.47 pp in F_BERT.
Dynamic Spatiotemporal Graph Neural Network with Tensor Network
Mar 12, 2020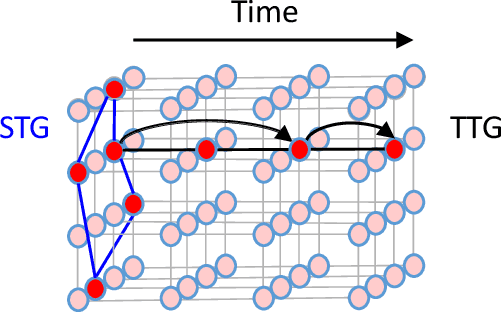
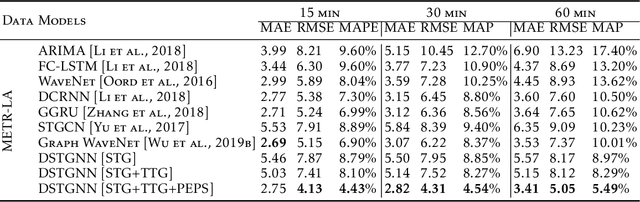
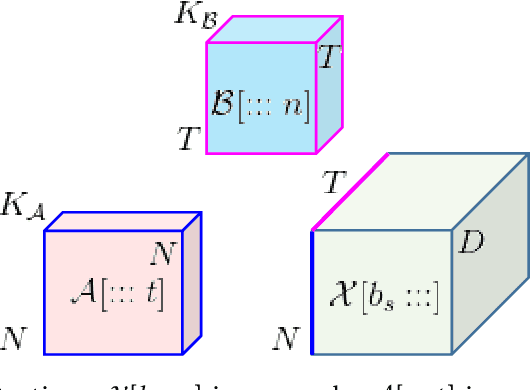
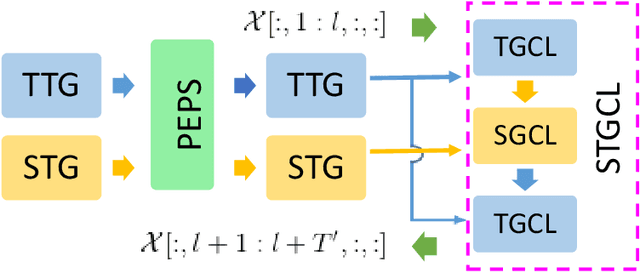
Dynamic spatial graph construction is a challenge in graph neural network (GNN) for time series data problems. Although some adaptive graphs are conceivable, only a 2D graph is embedded in the network to reflect the current spatial relation, regardless of all the previous situations. In this work, we generate a spatial tensor graph (STG) to collect all the dynamic spatial relations, as well as a temporal tensor graph (TTG) to find the latent pattern along time at each node. These two tensor graphs share the same nodes and edges, which leading us to explore their entangled correlations by Projected Entangled Pair States (PEPS) to optimize the two graphs. We experimentally compare the accuracy and time costing with the state-of-the-art GNN based methods on the public traffic datasets.