 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Robust Model-Free Learning and Control without Prior Knowledge
Oct 01, 2020
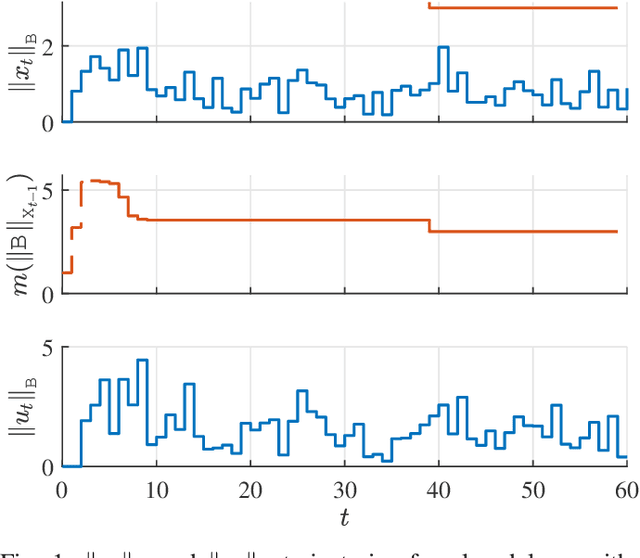
We present a simple model-free control algorithm that is able to robustly learn and stabilize an unknown discrete-time linear system with full control and state feedback subject to arbitrary bounded disturbance and noise sequences. The controller does not require any prior knowledge of the system dynamics, disturbances, or noise, yet it can guarantee robust stability and provides asymptotic and worst-case bounds on the state and input trajectories. To the best of our knowledge, this is the first model-free algorithm that comes with such robust stability guarantees without the need to make any prior assumptions about the system. We would like to highlight the new convex geometry-based approach taken towards robust stability analysis which served as a key enabler in our results. We will conclude with simulation results that show that despite the generality and simplicity, the controller demonstrates good closed-loop performance.
* 16 pages, 7 figures
Dynamically Tie the Right Offer to the Right Customer in Telecommunications Industry
Oct 18, 2020For a successful business, engaging in an effective campaign is a key task for marketers. Most previous studies used various mathematical models to segment customers without considering the correlation between customer segmentation and a campaign. This work presents a conceptual model by studying the significant campaign-dependent variables of customer targeting in customer segmentation context. In this way, the processes of customer segmentation and targeting thus can be linked and solved together. The outcomes of customer segmentation of this study could be more meaningful and relevant for marketers. This investigation applies a customer life time value (LTV) model to assess the fitness between targeted customer groups and marketing strategies. To integrate customer segmentation and customer targeting, this work uses the genetic algorithm (GA) to determine the optimized marketing strategy. Later, we suggest using C&RT (Classification and Regression Tree) in SPSS PASW Modeler as the replacement to Genetic Algorithm technique to accomplish these results. We also suggest using LOSSYCOUNTING and Counting Bloom Filter to dynamically design the right and up-to-date offer to the right customer.
* Published in 2011 RESEARCH COUNCIL JOURNAL, An Annual Publication From The Direct Marketing Association Research Council- https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=&cad=rja&uact=8&ved=2ahUKEwiitNPbyr7sAhXyct8KHfSpDsEQFjABegQIAxAC&url=https%3A%2F%2Fthedma.org%2Fwp-content%2Fuploads%2F2011-Analytics-Journal.pdf&usg=AOvVaw1XhGZBELMr3-_HAPhysVPp
Automatic joint damage quantification using computer vision and deep learning
Oct 29, 2020
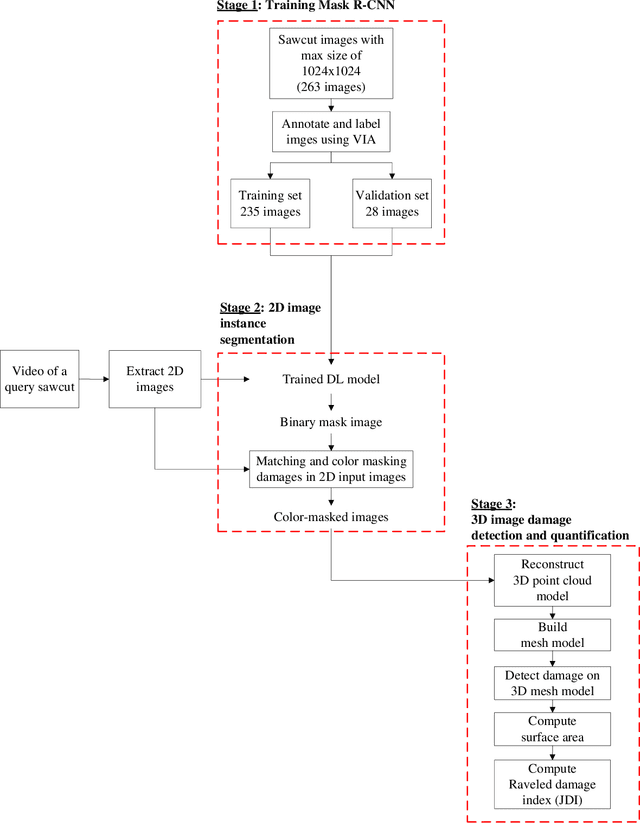
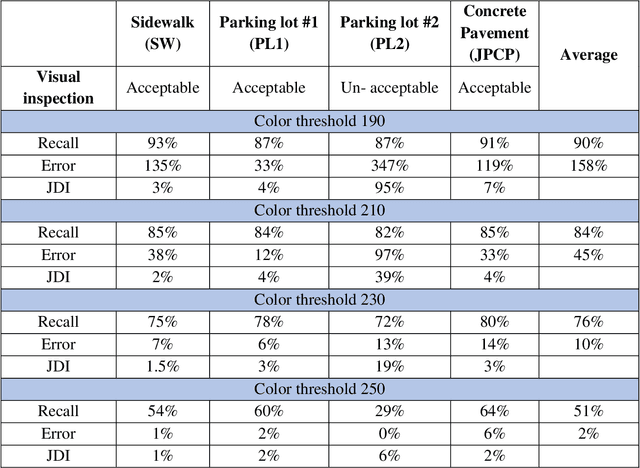
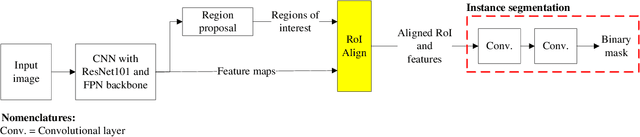
Joint raveled or spalled damage (henceforth called joint damage) can affect the safety and long-term performance of concrete pavements. It is important to assess and quantify the joint damage over time to assist in building action plans for maintenance, predicting maintenance costs, and maximize the concrete pavement service life. A framework for the accurate, autonomous, and rapid quantification of joint damage with a low-cost camera is proposed using a computer vision technique with a deep learning (DL) algorithm. The DL model is employed to train 263 images of sawcuts with joint damage. The trained DL model is used for pixel-wise color-masking joint damage in a series of query 2D images, which are used to reconstruct a 3D image using open-source structure from motion algorithm. Another damage quantification algorithm using a color threshold is applied to detect and compute the surface area of the damage in the 3D reconstructed image. The effectiveness of the framework was validated through inspecting joint damage at four transverse contraction joints in Illinois, USA, including three acceptable joints and one unacceptable joint by visual inspection. The results show the framework achieves 76% recall and 10% error.
Full Quaternion Representation of Color images: A Case Study on QSVD-based Color Image Compression
Jul 19, 2020
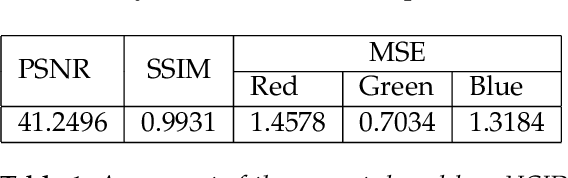
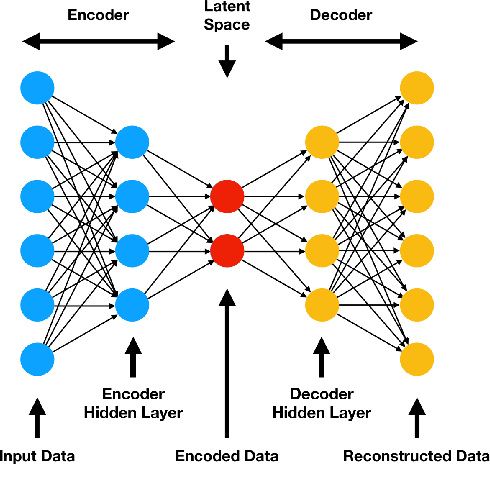
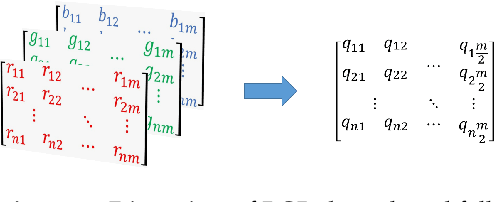
For many years, channels of a color image have been processed individually, or the image has been converted to grayscale one with respect to color image processing. Pure quaternion representation of color images solves this issue as it allows images to be processed in a holistic space. Nevertheless, it brings additional costs due to the extra fourth dimension. In this paper, we propose an approach for representing color images with full quaternion numbers that enables us to process color images holistically without additional cost in time, space and computation. With taking auto- and cross-correlation of color channels into account, an autoencoder neural network is used to generate a global model for transforming a color image into a full quaternion matrix. To evaluate the model, we use UCID dataset, and the results indicate that the model has an acceptable performance on color images. Moreover, we propose a compression method based on the generated model and QSVD as a case study. The method is compared with the same compression method using pure quaternion representation and is assessed with UCID dataset. The results demonstrate that the compression method using the proposed full quaternion representation fares better than the other in terms of time, quality, and size of compressed files.
Toward Adaptive Trust Calibration for Level 2 Driving Automation
Sep 24, 2020
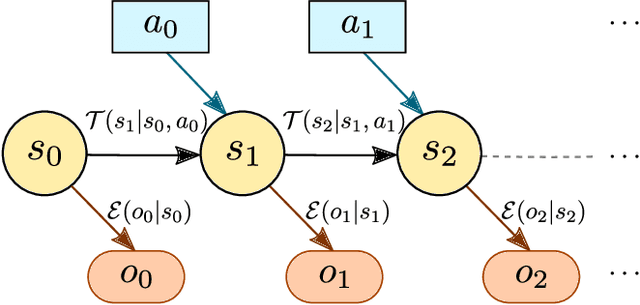
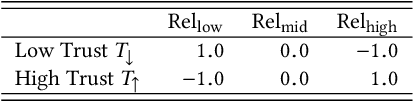
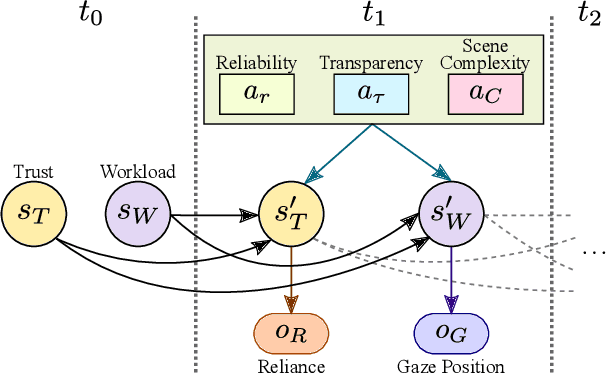
Properly calibrated human trust is essential for successful interaction between humans and automation. However, while human trust calibration can be improved by increased automation transparency, too much transparency can overwhelm human workload. To address this tradeoff, we present a probabilistic framework using a partially observable Markov decision process (POMDP) for modeling the coupled trust-workload dynamics of human behavior in an action-automation context. We specifically consider hands-off Level 2 driving automation in a city environment involving multiple intersections where the human chooses whether or not to rely on the automation. We consider automation reliability, automation transparency, and scene complexity, along with human reliance and eye-gaze behavior, to model the dynamics of human trust and workload. We demonstrate that our model framework can appropriately vary automation transparency based on real-time human trust and workload belief estimates to achieve trust calibration.
Representation Learning for Sequence Data with Deep Autoencoding Predictive Components
Oct 07, 2020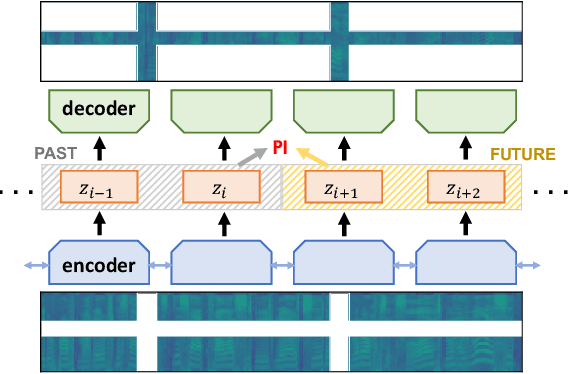
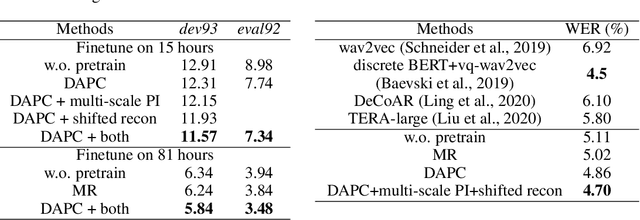
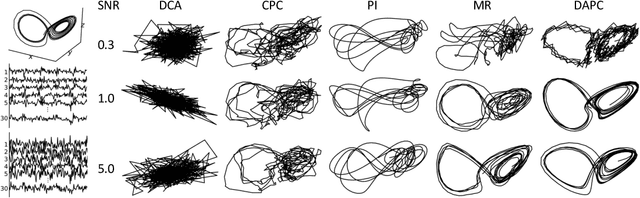
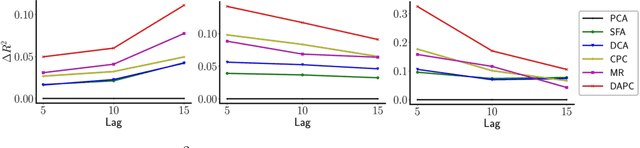
We propose Deep Autoencoding Predictive Components (DAPC) -- a self-supervised representation learning method for sequence data, based on the intuition that useful representations of sequence data should exhibit a simple structure in the latent space. We encourage this latent structure by maximizing an estimate of predictive information of latent feature sequences, which is the mutual information between past and future windows at each time step. In contrast to the mutual information lower bound commonly used by contrastive learning, the estimate of predictive information we adopt is exact under a Gaussian assumption. Additionally, it can be computed without negative sampling. To reduce the degeneracy of the latent space extracted by powerful encoders and keep useful information from the inputs, we regularize predictive information learning with a challenging masked reconstruction loss. We demonstrate that our method recovers the latent space of noisy dynamical systems, extracts predictive features for forecasting tasks, and improves automatic speech recognition when used to pretrain the encoder on large amounts of unlabeled data.
IEO: Intelligent Evolutionary Optimisation for Hyperparameter Tuning
Sep 10, 2020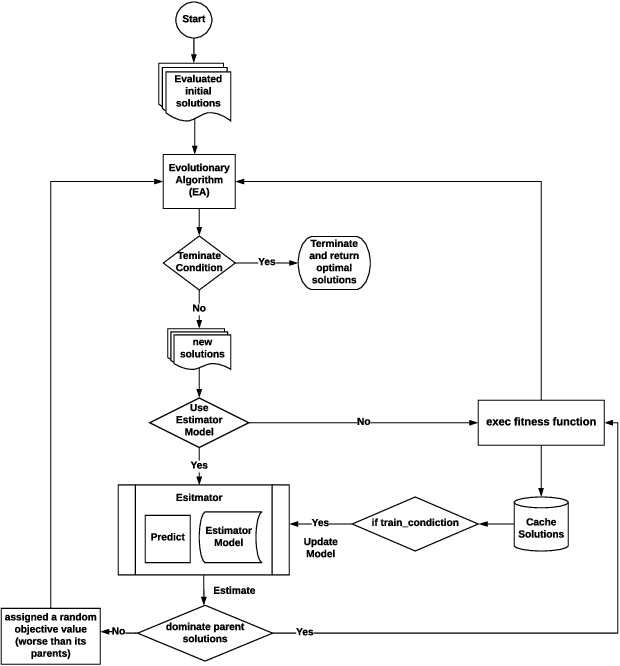
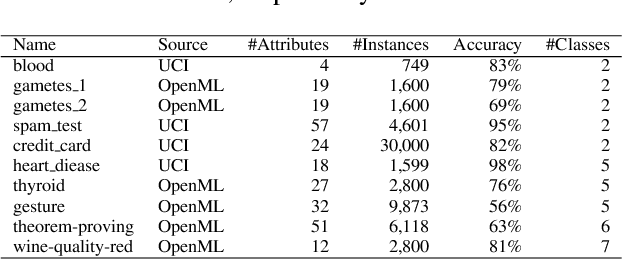
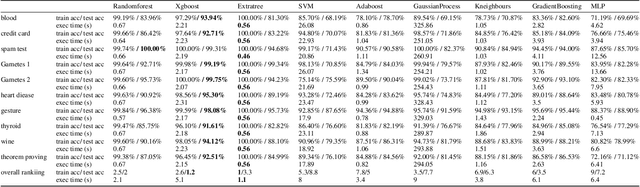
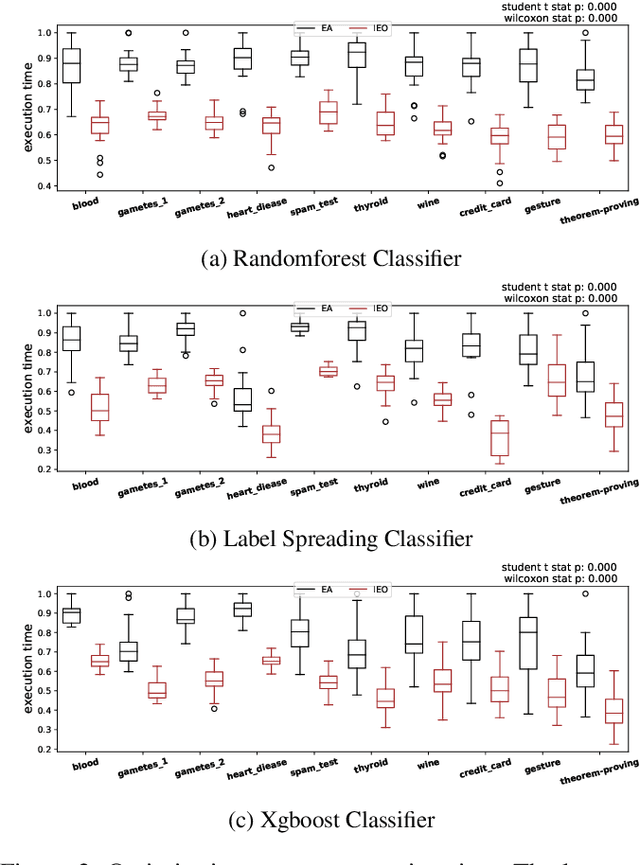
Hyperparameter optimisation is a crucial process in searching the optimal machine learning model. The efficiency of finding the optimal hyperparameter settings has been a big concern in recent researches since the optimisation process could be time-consuming, especially when the objective functions are highly expensive to evaluate. In this paper, we introduce an intelligent evolutionary optimisation algorithm which applies machine learning technique to the traditional evolutionary algorithm to accelerate the overall optimisation process of tuning machine learning models in classification problems. We demonstrate our Intelligent Evolutionary Optimisation (IEO)in a series of controlled experiments, comparing with traditional evolutionary optimisation in hyperparameter tuning. The empirical study shows that our approach accelerates the optimisation speed by 30.40% on average and up to 77.06% in the best scenarios.
SipMask: Spatial Information Preservation for Fast Image and Video Instance Segmentation
Jul 29, 2020
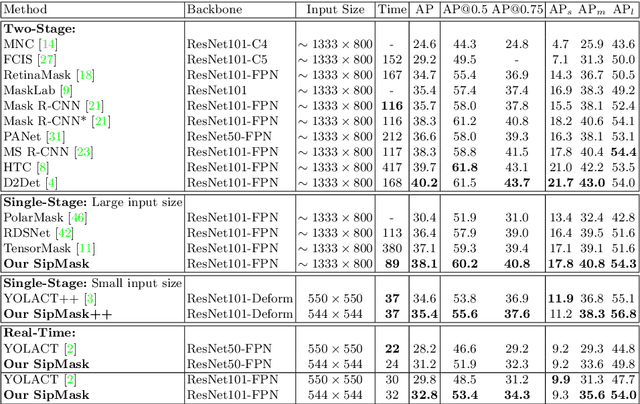
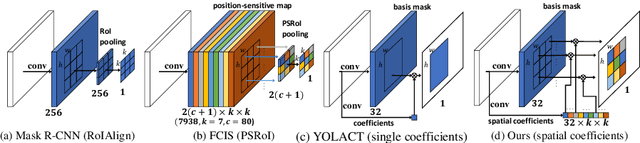
Single-stage instance segmentation approaches have recently gained popularity due to their speed and simplicity, but are still lagging behind in accuracy, compared to two-stage methods. We propose a fast single-stage instance segmentation method, called SipMask, that preserves instance-specific spatial information by separating mask prediction of an instance to different sub-regions of a detected bounding-box. Our main contribution is a novel light-weight spatial preservation (SP) module that generates a separate set of spatial coefficients for each sub-region within a bounding-box, leading to improved mask predictions. It also enables accurate delineation of spatially adjacent instances. Further, we introduce a mask alignment weighting loss and a feature alignment scheme to better correlate mask prediction with object detection. On COCO test-dev, our SipMask outperforms the existing single-stage methods. Compared to the state-of-the-art single-stage TensorMask, SipMask obtains an absolute gain of 1.0% (mask AP), while providing a four-fold speedup. In terms of real-time capabilities, SipMask outperforms YOLACT with an absolute gain of 3.0% (mask AP) under similar settings, while operating at comparable speed on a Titan Xp. We also evaluate our SipMask for real-time video instance segmentation, achieving promising results on YouTube-VIS dataset. The source code is available at https://github.com/JialeCao001/SipMask.
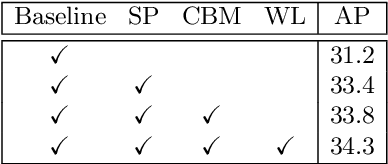
DORB: Dynamically Optimizing Multiple Rewards with Bandits
Nov 15, 2020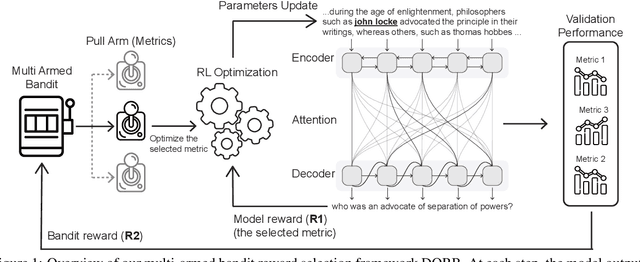
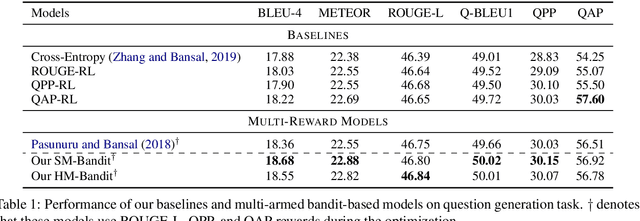
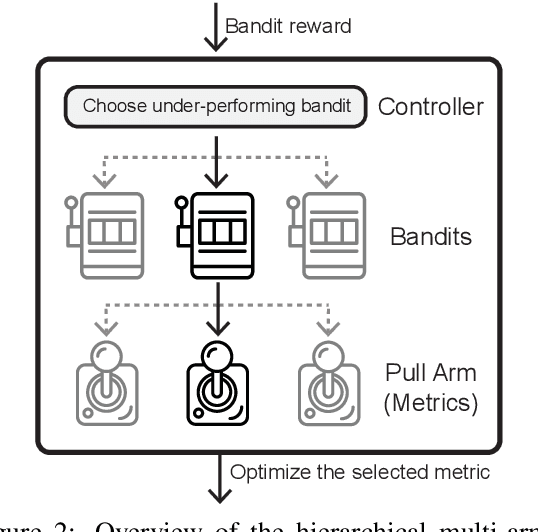
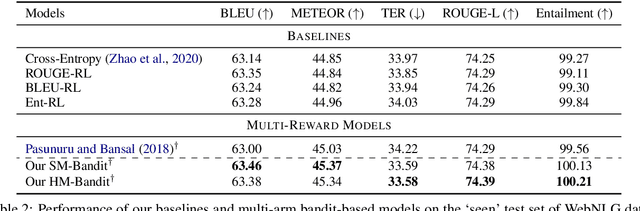
Policy gradients-based reinforcement learning has proven to be a promising approach for directly optimizing non-differentiable evaluation metrics for language generation tasks. However, optimizing for a specific metric reward leads to improvements in mostly that metric only, suggesting that the model is gaming the formulation of that metric in a particular way without often achieving real qualitative improvements. Hence, it is more beneficial to make the model optimize multiple diverse metric rewards jointly. While appealing, this is challenging because one needs to manually decide the importance and scaling weights of these metric rewards. Further, it is important to consider using a dynamic combination and curriculum of metric rewards that flexibly changes over time. Considering the above aspects, in our work, we automate the optimization of multiple metric rewards simultaneously via a multi-armed bandit approach (DORB), where at each round, the bandit chooses which metric reward to optimize next, based on expected arm gains. We use the Exp3 algorithm for bandits and formulate two approaches for bandit rewards: (1) Single Multi-reward Bandit (SM-Bandit); (2) Hierarchical Multi-reward Bandit (HM-Bandit). We empirically show the effectiveness of our approaches via various automatic metrics and human evaluation on two important NLG tasks: question generation and data-to-text generation, including on an unseen-test transfer setup. Finally, we present interpretable analyses of the learned bandit curriculum over the optimized rewards.
Mo2Cap2: Real-time Mobile 3D Motion Capture with a Cap-mounted Fisheye Camera
Mar 15, 2018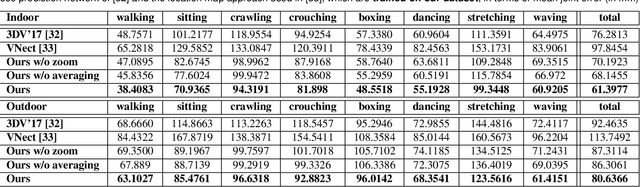


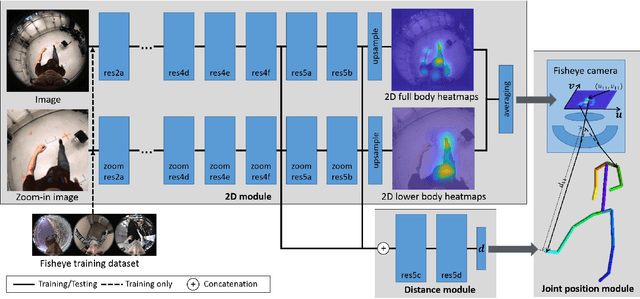
We propose the first real-time approach for the egocentric estimation of 3D human body pose in a wide range of unconstrained everyday activities. This setting has a unique set of challenges, such as mobility of the hardware setup, and robustness to long capture sessions with fast recovery from tracking failures. We tackle these challenges based on a novel lightweight setup that converts a standard baseball cap to a device for high-quality pose estimation based on a single cap-mounted fisheye camera. From the captured egocentric live stream, our CNN based 3D pose estimation approach runs at 60Hz on a consumer-level GPU. In addition to the novel hardware setup, our other main contributions are: 1) a large ground truth training corpus of top-down fisheye images and 2) a novel disentangled 3D pose estimation approach that takes the unique properties of the egocentric viewpoint into account. As shown by our evaluation, we achieve lower 3D joint error as well as better 2D overlay than the existing baselines.