 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Characterizing and Predicting Repeat Food Consumption Behavior for Just-in-Time Interventions
Sep 17, 2019
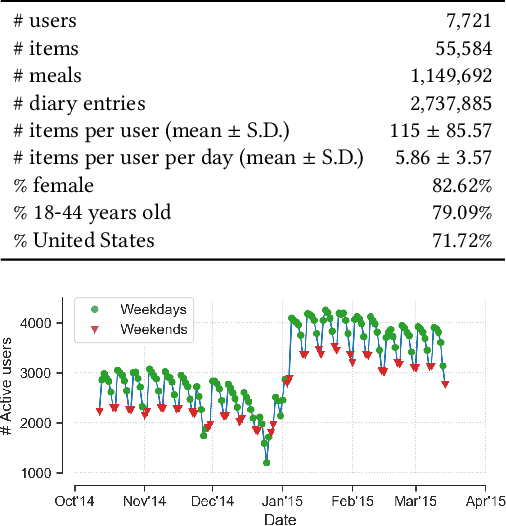
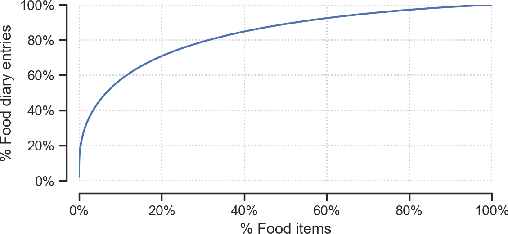

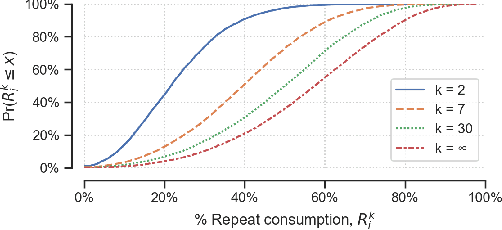
Human beings are creatures of habit. In their daily life, people tend to repeatedly consume similar types of food items over several days and occasionally switch to consuming different types of items when the consumptions become overly monotonous. However, the novel and repeat consumption behaviors have not been studied in food recommendation research. More importantly, the ability to predict daily eating habits of individuals is crucial to improve the effectiveness of food recommender systems in facilitating healthy lifestyle change. In this study, we analyze the patterns of repeat food consumptions using large-scale consumption data from a popular online fitness community called MyFitnessPal (MFP), conduct an offline evaluation of various state-of-the-art algorithms in predicting the next-day food consumption, and analyze their performance across different demographic groups and contexts. The experiment results show that algorithms incorporating the exploration-and-exploitation and temporal dynamics are more effective in the next-day recommendation task than most state-of-the-art algorithms.
Self-awareness in intelligent vehicles: Feature based dynamic Bayesian models for abnormality detection
Oct 29, 2020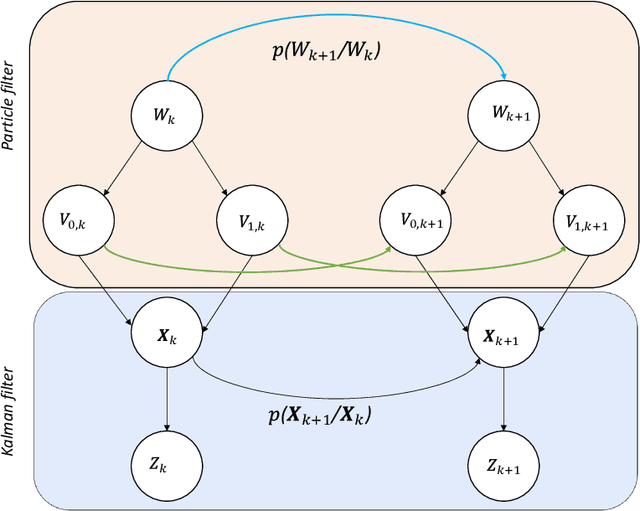

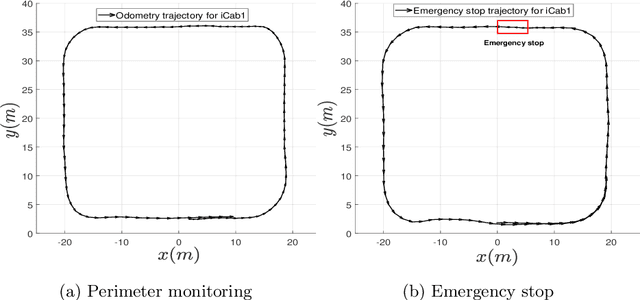
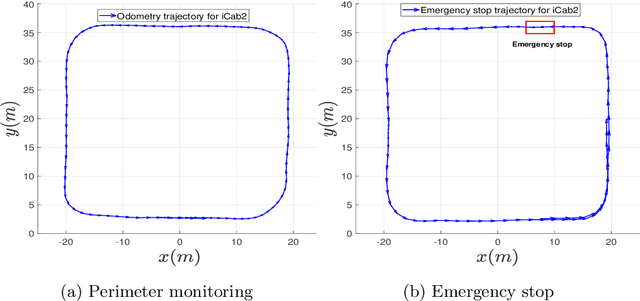
The evolution of Intelligent Transportation Systems in recent times necessitates the development of self-awareness in agents. Before the intensive use of Machine Learning, the detection of abnormalities was manually programmed by checking every variable and creating huge nested conditions that are very difficult to track. This paper aims to introduce a novel method to develop self-awareness in autonomous vehicles that mainly focuses on detecting abnormal situations around the considered agents. Multi-sensory time-series data from the vehicles are used to develop the data-driven Dynamic Bayesian Network (DBN) models used for future state prediction and the detection of dynamic abnormalities. Moreover, an initial level collective awareness model that can perform joint anomaly detection in co-operative tasks is proposed. The GNG algorithm learns the DBN models' discrete node variables; probabilistic transition links connect the node variables. A Markov Jump Particle Filter (MJPF) is applied to predict future states and detect when the vehicle is potentially misbehaving using learned DBNs as filter parameters. In this paper, datasets from real experiments of autonomous vehicles performing various tasks used to learn and test a set of switching DBN models.
Learning a Cost-Effective Annotation Policy for Question Answering
Oct 07, 2020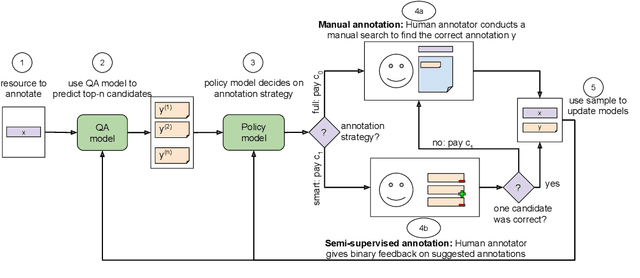

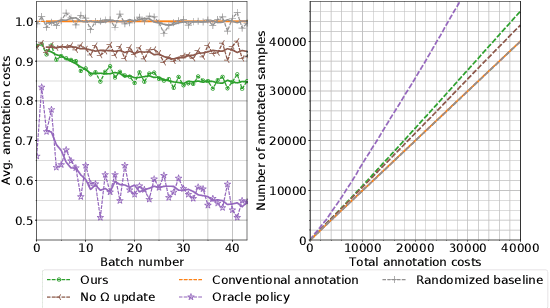

State-of-the-art question answering (QA) relies upon large amounts of training data for which labeling is time consuming and thus expensive. For this reason, customizing QA systems is challenging. As a remedy, we propose a novel framework for annotating QA datasets that entails learning a cost-effective annotation policy and a semi-supervised annotation scheme. The latter reduces the human effort: it leverages the underlying QA system to suggest potential candidate annotations. Human annotators then simply provide binary feedback on these candidates. Our system is designed such that past annotations continuously improve the future performance and thus overall annotation cost. To the best of our knowledge, this is the first paper to address the problem of annotating questions with minimal annotation cost. We compare our framework against traditional manual annotations in an extensive set of experiments. We find that our approach can reduce up to 21.1% of the annotation cost.
Meta Automatic Curriculum Learning
Nov 16, 2020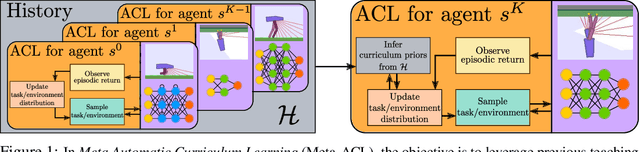

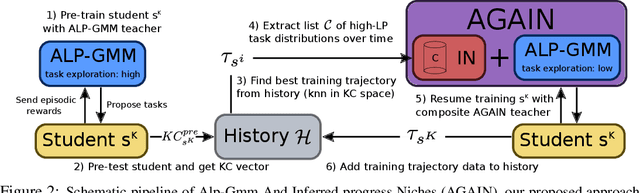
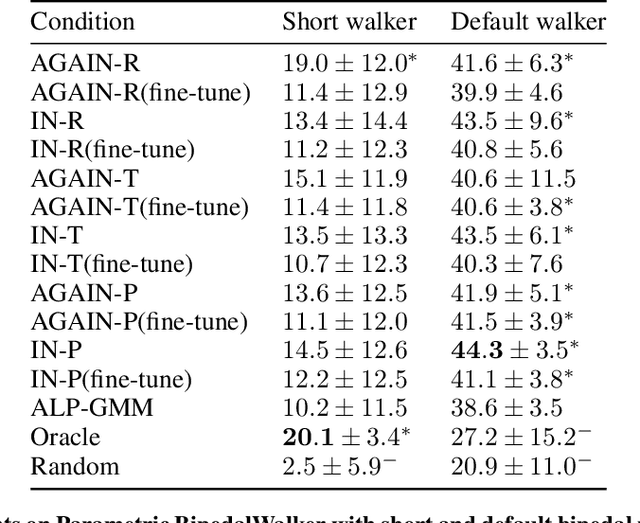
A major challenge in the Deep RL (DRL) community is to train agents able to generalize their control policy over situations never seen in training. Training on diverse tasks has been identified as a key ingredient for good generalization, which pushed researchers towards using rich procedural task generation systems controlled through complex continuous parameter spaces. In such complex task spaces, it is essential to rely on some form of Automatic Curriculum Learning (ACL) to adapt the task sampling distribution to a given learning agent, instead of randomly sampling tasks, as many could end up being either trivial or unfeasible. Since it is hard to get prior knowledge on such task spaces, many ACL algorithms explore the task space to detect progress niches over time, a costly tabula-rasa process that needs to be performed for each new learning agents, although they might have similarities in their capabilities profiles. To address this limitation, we introduce the concept of Meta-ACL, and formalize it in the context of black-box RL learners, i.e. algorithms seeking to generalize curriculum generation to an (unknown) distribution of learners. In this work, we present AGAIN, a first instantiation of Meta-ACL, and showcase its benefits for curriculum generation over classical ACL in multiple simulated environments including procedurally generated parkour environments with learners of varying morphologies. Videos and code are available at https://sites.google.com/view/meta-acl .
Real time error detection in metal arc welding process using Artificial Neural Netwroks
Mar 10, 2016
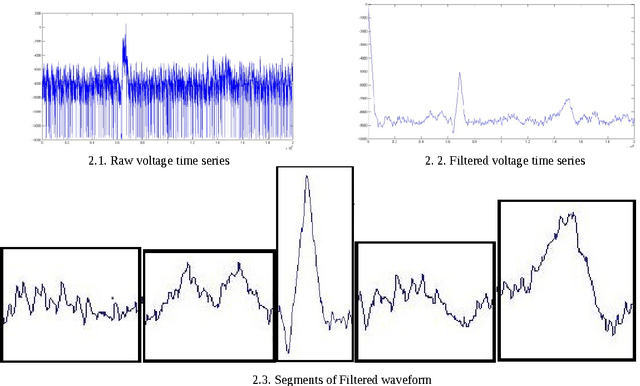
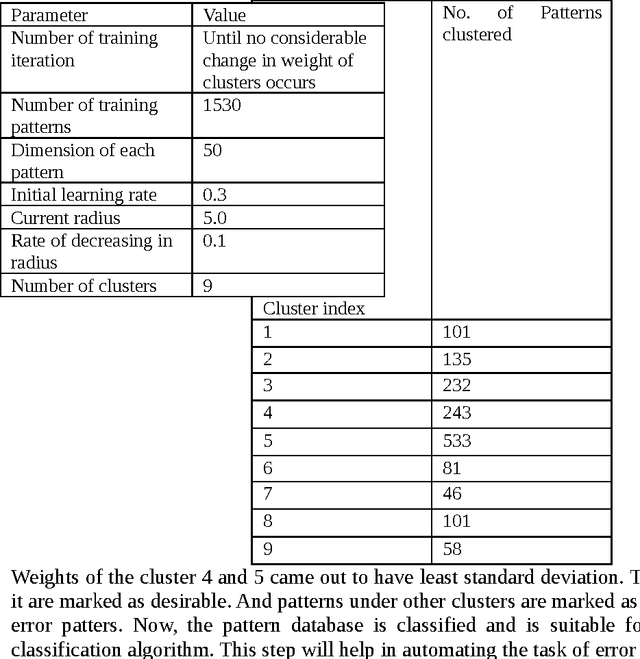
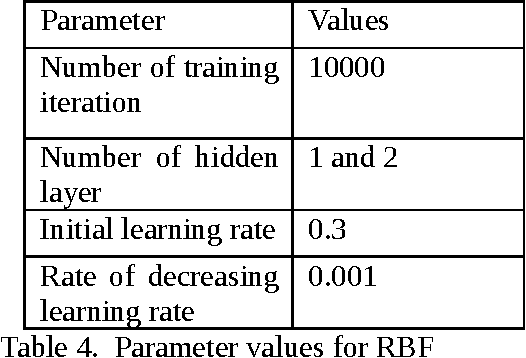
Quality assurance in production line demands reliable weld joints. Human made errors is a major cause of faulty production. Promptly Identifying errors in the weld while welding is in progress will decrease the post inspection cost spent on the welding process. Electrical parameters generated during welding, could able to characterize the process efficiently. Parameter values are collected using high speed data acquisition system. Time series analysis tasks such as filtering, pattern recognition etc. are performed over the collected data. Filtering removes the unwanted noisy signal components and pattern recognition task segregate error patterns in the time series based upon similarity, which is performed by Self Organized mapping clustering algorithm. Welder quality is thus compared by detecting and counting number of error patterns appeared in his parametric time series. Moreover, Self Organized mapping algorithm provides the database in which patterns are segregated into two classes either desirable or undesirable. Database thus generated is used to train the classification algorithms, and thereby automating the real time error detection task. Multi Layer Perceptron and Radial basis function are the two classification algorithms used, and their performance has been compared based on metrics such as specificity, sensitivity, accuracy and time required in training.
Batch Group Normalization
Dec 09, 2020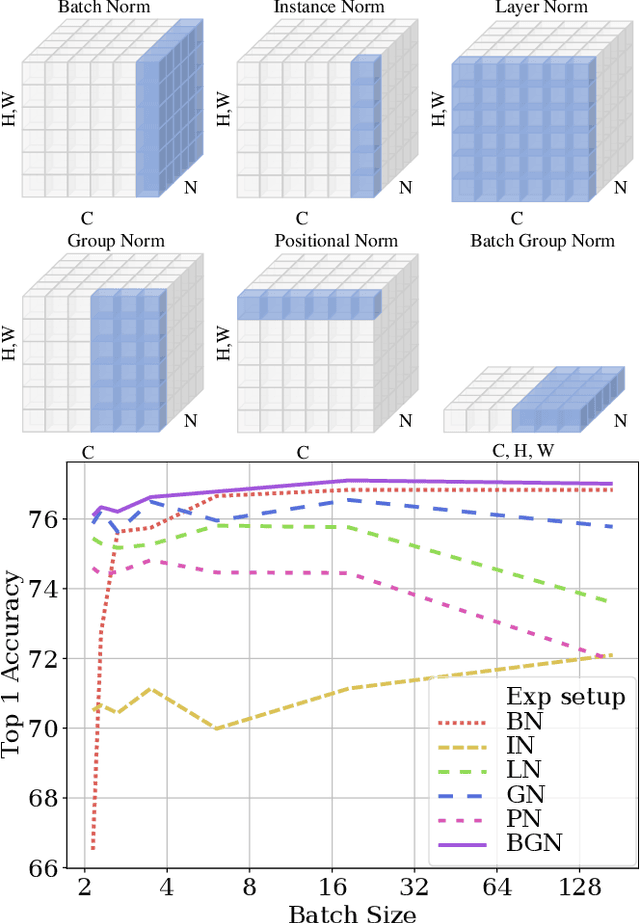

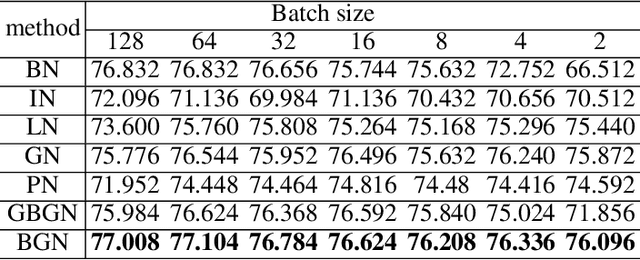
Deep Convolutional Neural Networks (DCNNs) are hard and time-consuming to train. Normalization is one of the effective solutions. Among previous normalization methods, Batch Normalization (BN) performs well at medium and large batch sizes and is with good generalizability to multiple vision tasks, while its performance degrades significantly at small batch sizes. In this paper, we find that BN saturates at extreme large batch sizes, i.e., 128 images per worker, i.e., GPU, as well and propose that the degradation/saturation of BN at small/extreme large batch sizes is caused by noisy/confused statistic calculation. Hence without adding new trainable parameters, using multiple-layer or multi-iteration information, or introducing extra computation, Batch Group Normalization (BGN) is proposed to solve the noisy/confused statistic calculation of BN at small/extreme large batch sizes with introducing the channel, height and width dimension to compensate. The group technique in Group Normalization (GN) is used and a hyper-parameter G is used to control the number of feature instances used for statistic calculation, hence to offer neither noisy nor confused statistic for different batch sizes. We empirically demonstrate that BGN consistently outperforms BN, Instance Normalization (IN), Layer Normalization (LN), GN, and Positional Normalization (PN), across a wide spectrum of vision tasks, including image classification, Neural Architecture Search (NAS), adversarial learning, Few Shot Learning (FSL) and Unsupervised Domain Adaptation (UDA), indicating its good performance, robust stability to batch size and wide generalizability. For example, for training ResNet-50 on ImageNet with a batch size of 2, BN achieves Top1 accuracy of 66.512% while BGN achieves 76.096% with notable improvement.
Stability-Guaranteed Reinforcement Learning for Contact-rich Manipulation
Apr 22, 2020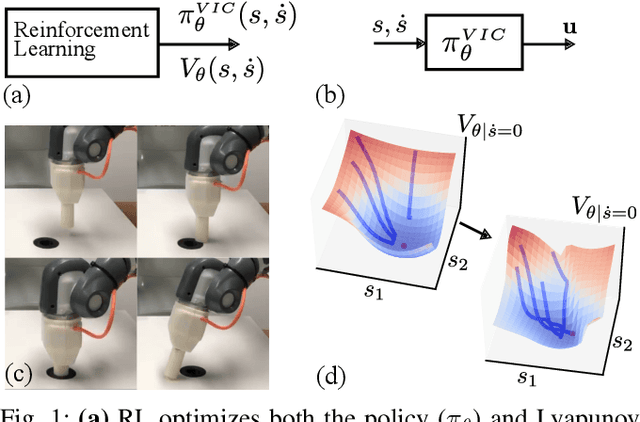
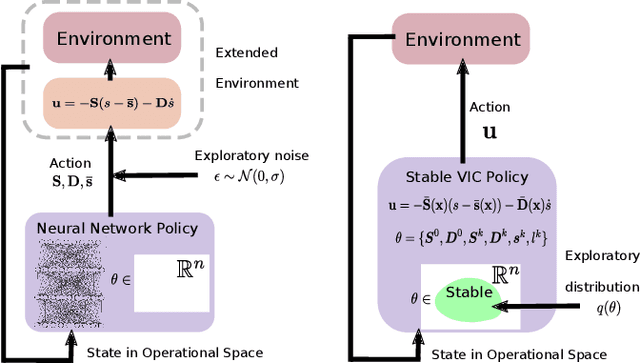
Reinforcement learning (RL) has had its fair share of success in contact-rich manipulation tasks but it still lags behind in benefiting from advances in robot control theory such as impedance control and stability guarantees. Recently, the concept of variable impedance control (VIC) was adopted into RL with encouraging results. However, the more important issue of stability remains unaddressed. To clarify the challenge in stable RL, we introduce the term all-the-time-stability that unambiguously means that every possible rollout will be stability certified. Our contribution is a model-free RL method that not only adopts VIC but also achieves all-the-time-stability. Building on a recently proposed stable VIC controller as the policy parameterization, we introduce a novel policy search algorithm that is inspired by Cross-Entropy Method and inherently guarantees stability. As a part of our extensive experimental studies, we report, to the best of our knowledge, the first successful application of RL with all-the-time-stability on the benchmark problem of peg-in-hole.
Benchmark Tests of Convolutional Neural Network and Graph Convolutional Network on HorovodRunner Enabled Spark Clusters
May 12, 2020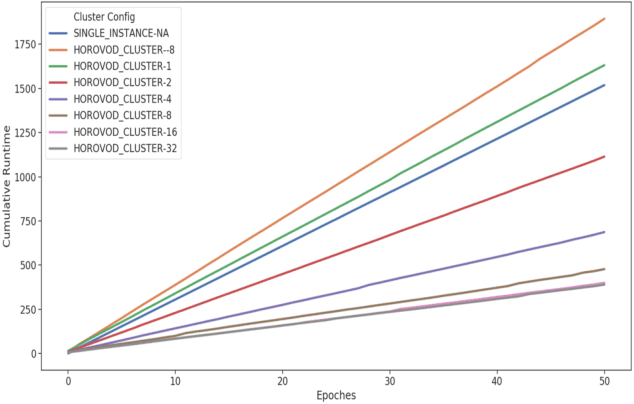
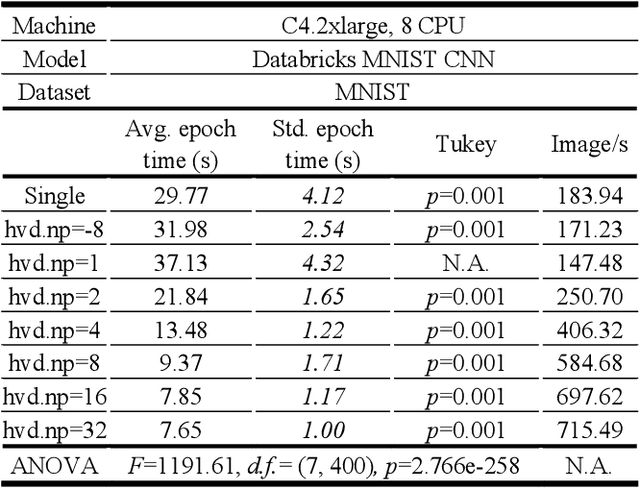
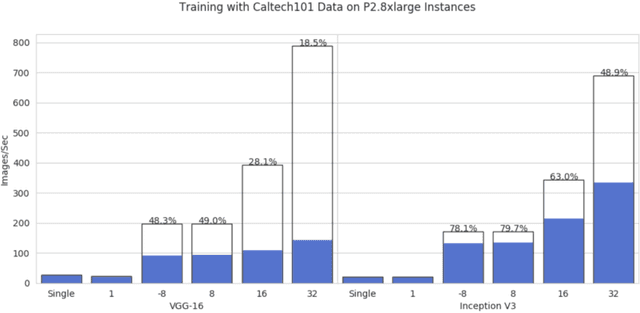
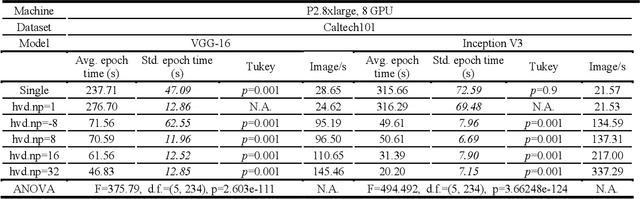
The freedom of fast iterations of distributed deep learning tasks is crucial for smaller companies to gain competitive advantages and market shares from big tech giants. HorovodRunner brings this process to relatively accessible spark clusters. There have been, however, no benchmark tests on HorovodRunner per se, nor specifically graph convolutional network (GCN, hereafter), and very limited scalability benchmark tests on Horovod, the predecessor requiring custom built GPU clusters. For the first time, we show that Databricks' HorovodRunner achieves significant lift in scaling efficiency for the convolutional neural network (CNN, hereafter) based tasks on both GPU and CPU clusters, but not the original GCN task. We also implemented the Rectified Adam optimizer for the first time in HorovodRunner.
A Machine Learning-Based Migration Strategy for Virtual Network Function Instances
Jun 15, 2020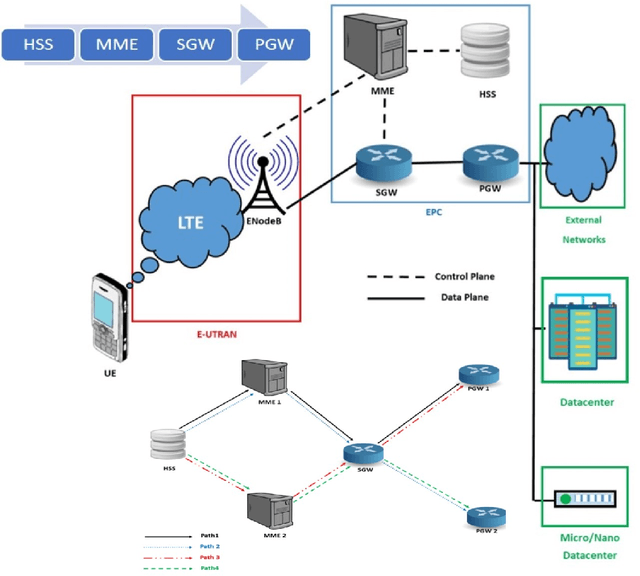
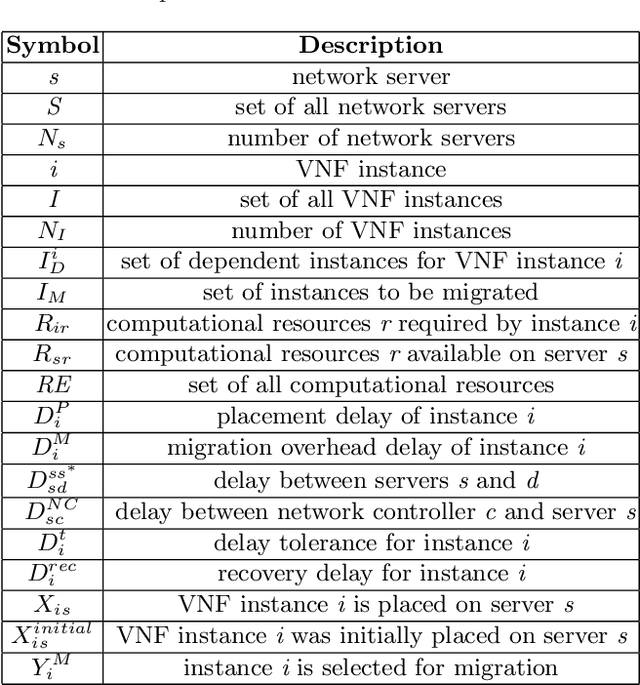


With the growing demand for data connectivity, network service providers are faced with the task of reducing their capital and operational expenses while simultaneously improving network performance and addressing the increased demand. Although Network Function Virtualization (NFV) has been identified as a promising solution, several challenges must be addressed to ensure its feasibility. In this paper, we address the Virtual Network Function (VNF) migration problem by developing the VNF Neural Network for Instance Migration (VNNIM), a migration strategy for VNF instances. The performance of VNNIM is further improved through the optimization of the learning rate hyperparameter through particle swarm optimization. Results show that the VNNIM is very effective in predicting the post-migration server exhibiting a binary accuracy of 99.07% and a delay difference distribution that is centered around a mean of zero when compared to the optimization model. The greatest advantage of VNNIM, however, is its run-time efficiency highlighted through a run-time analysis.
Robust Model-Free Learning and Control without Prior Knowledge
Oct 01, 2020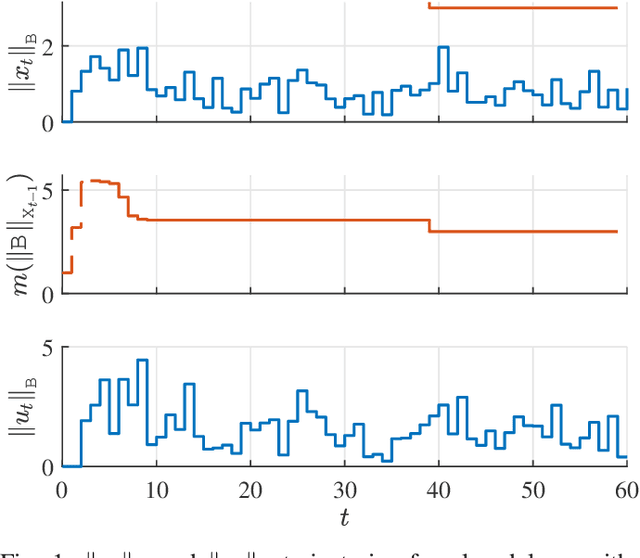
We present a simple model-free control algorithm that is able to robustly learn and stabilize an unknown discrete-time linear system with full control and state feedback subject to arbitrary bounded disturbance and noise sequences. The controller does not require any prior knowledge of the system dynamics, disturbances, or noise, yet it can guarantee robust stability and provides asymptotic and worst-case bounds on the state and input trajectories. To the best of our knowledge, this is the first model-free algorithm that comes with such robust stability guarantees without the need to make any prior assumptions about the system. We would like to highlight the new convex geometry-based approach taken towards robust stability analysis which served as a key enabler in our results. We will conclude with simulation results that show that despite the generality and simplicity, the controller demonstrates good closed-loop performance.
* 16 pages, 7 figures