 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DeNet: Scalable Real-time Object Detection with Directed Sparse Sampling
Jul 21, 2017
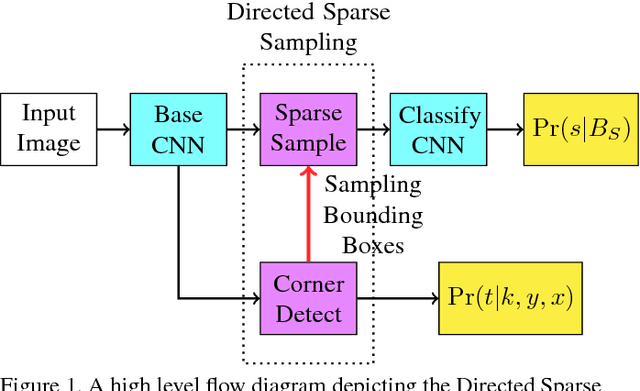

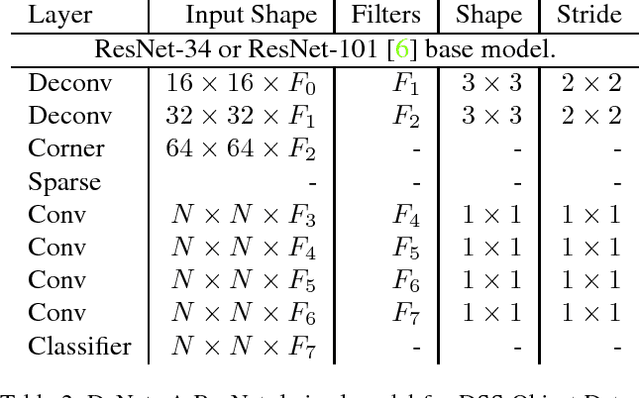
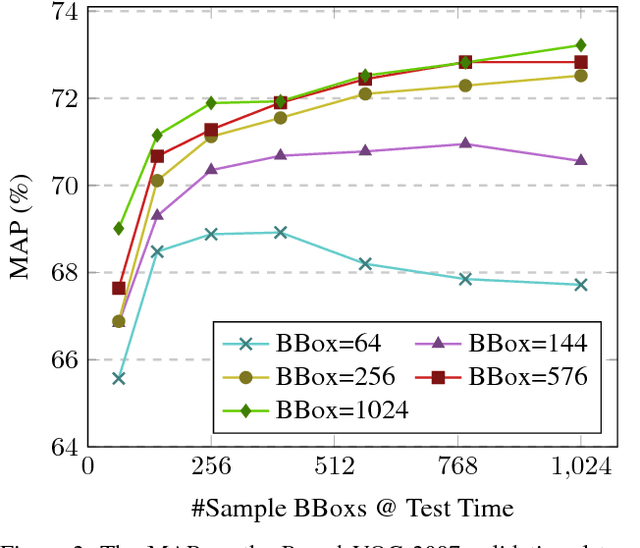
We define the object detection from imagery problem as estimating a very large but extremely sparse bounding box dependent probability distribution. Subsequently we identify a sparse distribution estimation scheme, Directed Sparse Sampling, and employ it in a single end-to-end CNN based detection model. This methodology extends and formalizes previous state-of-the-art detection models with an additional emphasis on high evaluation rates and reduced manual engineering. We introduce two novelties, a corner based region-of-interest estimator and a deconvolution based CNN model. The resulting model is scene adaptive, does not require manually defined reference bounding boxes and produces highly competitive results on MSCOCO, Pascal VOC 2007 and Pascal VOC 2012 with real-time evaluation rates. Further analysis suggests our model performs particularly well when finegrained object localization is desirable. We argue that this advantage stems from the significantly larger set of available regions-of-interest relative to other methods. Source-code is available from: https://github.com/lachlants/denet
Tele-operative Robotic Lung Ultrasound Scanning Platform for Triage of COVID-19 Patients
Oct 30, 2020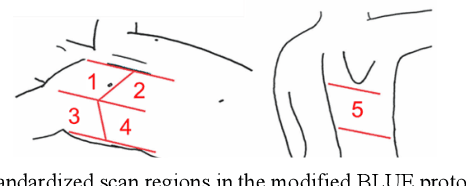
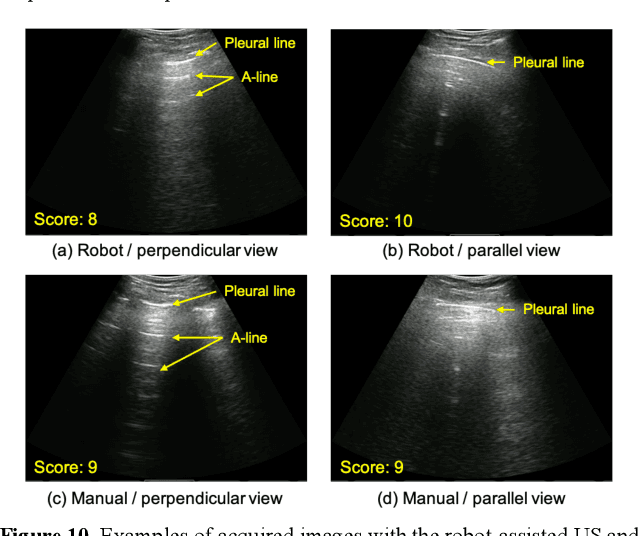
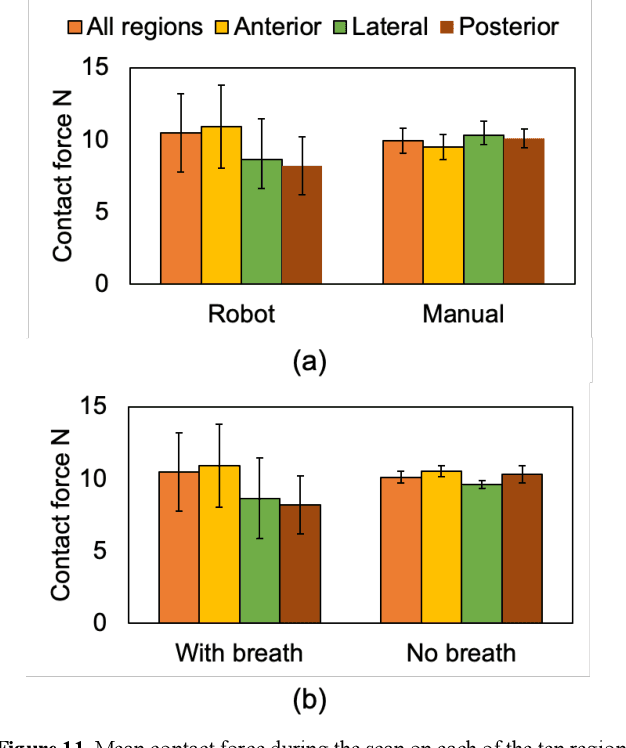
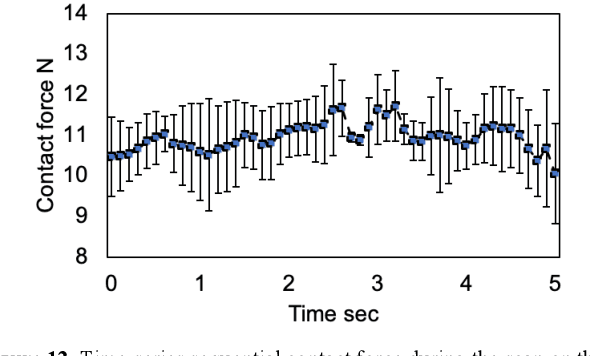
Novel severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) has become a pandemic of epic proportions and a global response to prepare health systems worldwide is of utmost importance. In addition to its cost-effectiveness in a resources-limited setting, lung ultrasound (LUS) has emerged as a rapid noninvasive imaging tool for the diagnosis of COVID-19 infected patients. Concerns surrounding LUS include the disparity of infected patients and healthcare providers, relatively small number of physicians and sonographers capable of performing LUS, and most importantly, the requirement for substantial physical contact between the patient and operator, increasing the risk of transmission. Mitigation of the spread of the virus is of paramount importance. A 2-dimensional (2D) tele-operative robotic platform capable of performing LUS in for COVID-19 infected patients may be of significant benefit. The authors address the aforementioned issues surrounding the use of LUS in the application of COVID- 19 infected patients. In addition, first time application, feasibility and safety were validated in three healthy subjects, along with 2D image optimization and comparison for overall accuracy. Preliminary results demonstrate that the proposed platform allows for successful acquisition and application of LUS in humans.
Real-Time 3D Model Tracking in Color and Depth on a Single CPU Core
Nov 22, 2019

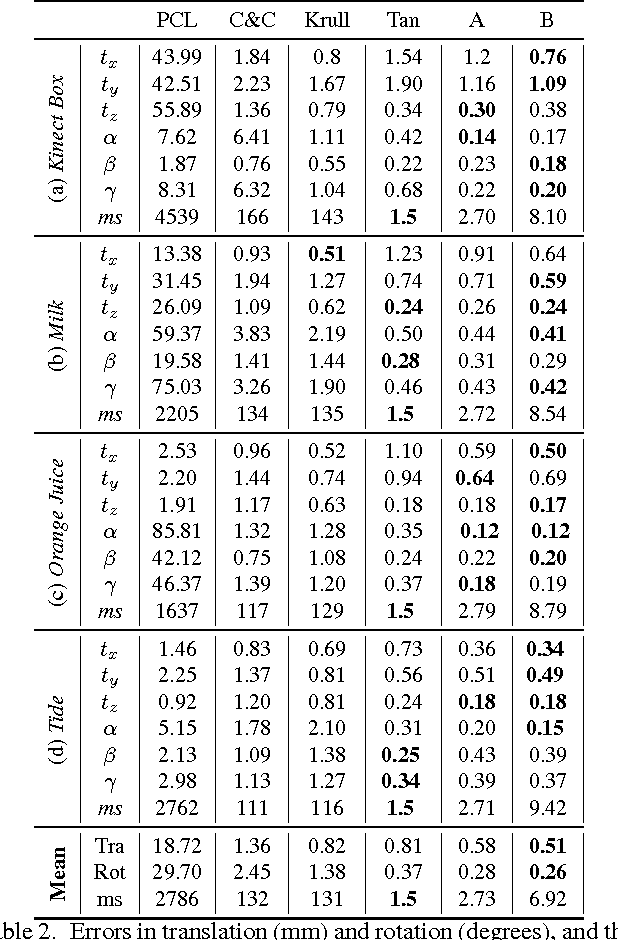
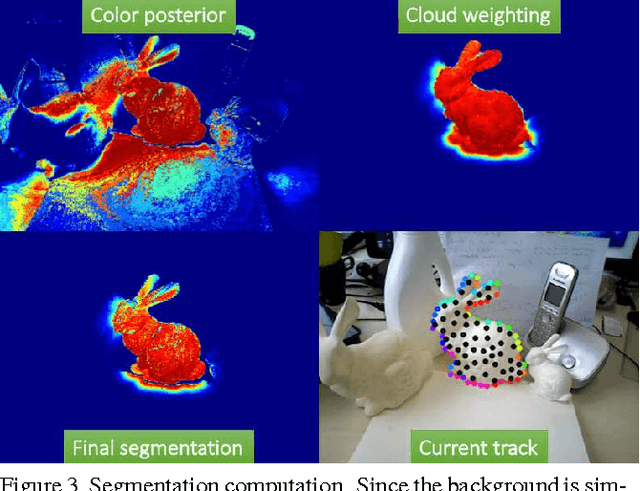
We present a novel method to track 3D models in color and depth data. To this end, we introduce approximations that accelerate the state-of-the-art in region-based tracking by an order of magnitude while retaining similar accuracy. Furthermore, we show how the method can be made more robust in the presence of depth data and consequently formulate a new joint contour and ICP tracking energy. We present better results than the state-of-the-art while being much faster then most other methods and achieving all of the above on a single CPU core.
Hybrid DCOP Solvers: Boosting Performance of Local Search Algorithms
Sep 04, 2020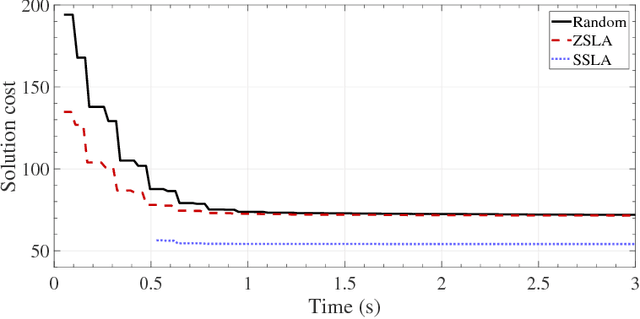
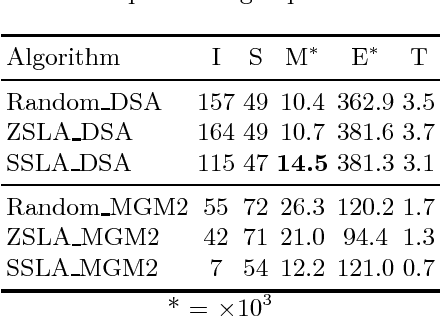
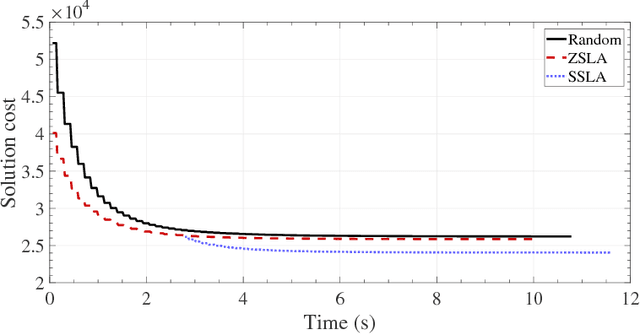
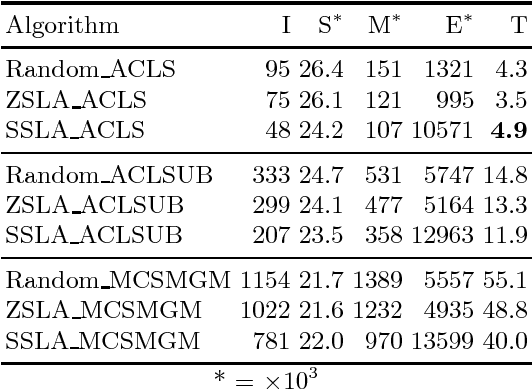
We propose a novel method for expediting both symmetric and asymmetric Distributed Constraint Optimization Problem (DCOP) solvers. The core idea is based on initializing DCOP solvers with greedy fast non-iterative DCOP solvers. This is contrary to existing methods where initialization is always achieved using a random value assignment. We empirically show that changing the starting conditions of existing DCOP solvers not only reduces the algorithm convergence time by up to 50\%, but also reduces the communication overhead and leads to a better solution quality. We show that this effect is due to structural improvements in the variable assignment, which is caused by the spreading pattern of DCOP algorithm activation.) /Subject (Hybrid DCOPs)
DyERNIE: Dynamic Evolution of Riemannian Manifold Embeddings for Temporal Knowledge Graph Completion
Nov 08, 2020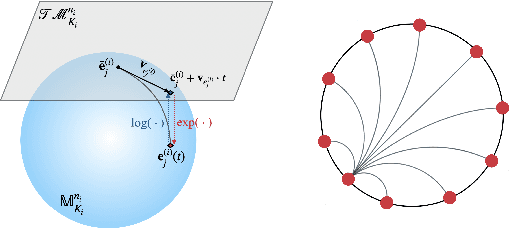
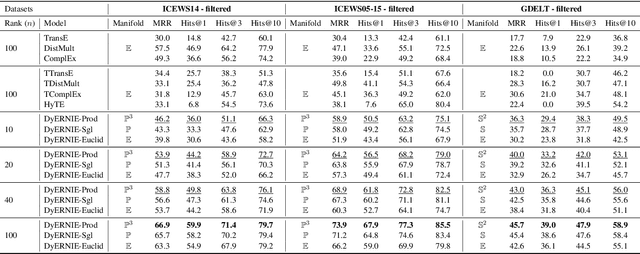
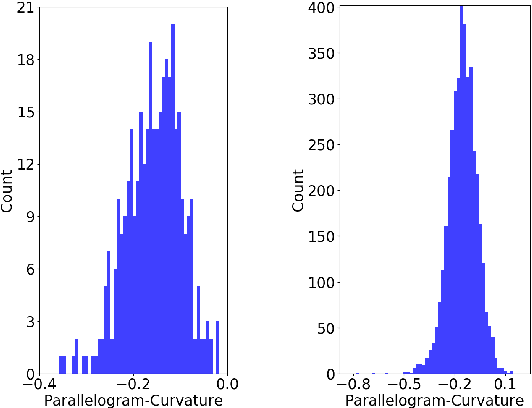

There has recently been increasing interest in learning representations of temporal knowledge graphs (KGs), which record the dynamic relationships between entities over time. Temporal KGs often exhibit multiple simultaneous non-Euclidean structures, such as hierarchical and cyclic structures. However, existing embedding approaches for temporal KGs typically learn entity representations and their dynamic evolution in the Euclidean space, which might not capture such intrinsic structures very well. To this end, we propose Dy- ERNIE, a non-Euclidean embedding approach that learns evolving entity representations in a product of Riemannian manifolds, where the composed spaces are estimated from the sectional curvatures of underlying data. Product manifolds enable our approach to better reflect a wide variety of geometric structures on temporal KGs. Besides, to capture the evolutionary dynamics of temporal KGs, we let the entity representations evolve according to a velocity vector defined in the tangent space at each timestamp. We analyze in detail the contribution of geometric spaces to representation learning of temporal KGs and evaluate our model on temporal knowledge graph completion tasks. Extensive experiments on three real-world datasets demonstrate significantly improved performance, indicating that the dynamics of multi-relational graph data can be more properly modeled by the evolution of embeddings on Riemannian manifolds.
Combining Semantic Guidance and Deep Reinforcement Learning For Generating Human Level Paintings
Nov 25, 2020

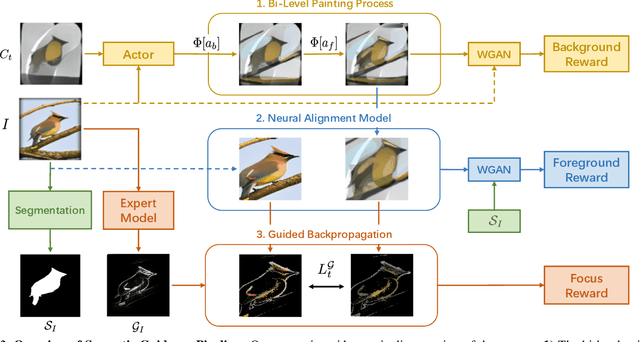

Generation of stroke-based non-photorealistic imagery, is an important problem in the computer vision community. As an endeavor in this direction, substantial recent research efforts have been focused on teaching machines "how to paint", in a manner similar to a human painter. However, the applicability of previous methods has been limited to datasets with little variation in position, scale and saliency of the foreground object. As a consequence, we find that these methods struggle to cover the granularity and diversity possessed by real world images. To this end, we propose a Semantic Guidance pipeline with 1) a bi-level painting procedure for learning the distinction between foreground and background brush strokes at training time. 2) We also introduce invariance to the position and scale of the foreground object through a neural alignment model, which combines object localization and spatial transformer networks in an end to end manner, to zoom into a particular semantic instance. 3) The distinguishing features of the in-focus object are then amplified by maximizing a novel guided backpropagation based focus reward. The proposed agent does not require any supervision on human stroke-data and successfully handles variations in foreground object attributes, thus, producing much higher quality canvases for the CUB-200 Birds and Stanford Cars-196 datasets. Finally, we demonstrate the further efficacy of our method on complex datasets with multiple foreground object instances by evaluating an extension of our method on the challenging Virtual-KITTI dataset.
Expectation Propagation for Continuous Time Bayesian Networks
Jul 04, 2012
Continuous time Bayesian networks (CTBNs) describe structured stochastic processes with finitely many states that evolve over continuous time. A CTBN is a directed (possibly cyclic) dependency graph over a set of variables, each of which represents a finite state continuous time Markov process whose transition model is a function of its parents. As shown previously, exact inference in CTBNs is intractable. We address the problem of approximate inference, allowing for general queries conditioned on evidence over continuous time intervals and at discrete time points. We show how CTBNs can be parameterized within the exponential family, and use that insight to develop a message passing scheme in cluster graphs and allows us to apply expectation propagation to CTBNs. The clusters in our cluster graph do not contain distributions over the cluster variables at individual time points, but distributions over trajectories of the variables throughout a duration. Thus, unlike discrete time temporal models such as dynamic Bayesian networks, we can adapt the time granularity at which we reason for different variables and in different conditions.
On the Practical Ability of Recurrent Neural Networks to Recognize Hierarchical Languages
Nov 08, 2020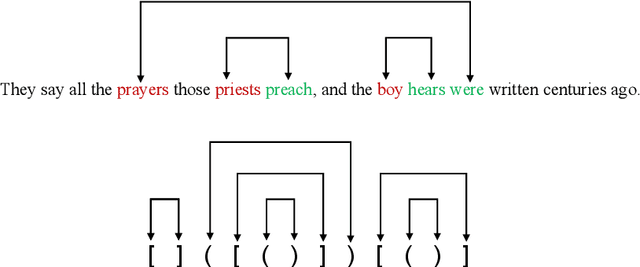
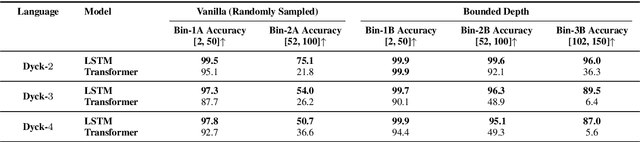
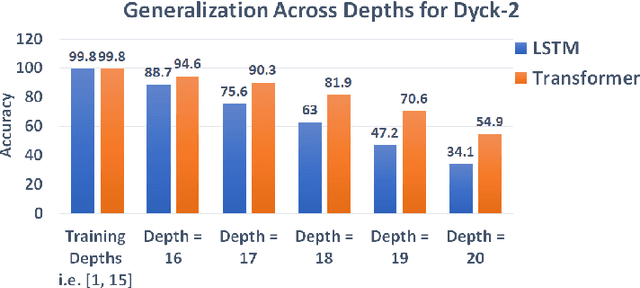
While recurrent models have been effective in NLP tasks, their performance on context-free languages (CFLs) has been found to be quite weak. Given that CFLs are believed to capture important phenomena such as hierarchical structure in natural languages, this discrepancy in performance calls for an explanation. We study the performance of recurrent models on Dyck-n languages, a particularly important and well-studied class of CFLs. We find that while recurrent models generalize nearly perfectly if the lengths of the training and test strings are from the same range, they perform poorly if the test strings are longer. At the same time, we observe that recurrent models are expressive enough to recognize Dyck words of arbitrary lengths in finite precision if their depths are bounded. Hence, we evaluate our models on samples generated from Dyck languages with bounded depth and find that they are indeed able to generalize to much higher lengths. Since natural language datasets have nested dependencies of bounded depth, this may help explain why they perform well in modeling hierarchical dependencies in natural language data despite prior works indicating poor generalization performance on Dyck languages. We perform probing studies to support our results and provide comparisons with Transformers.
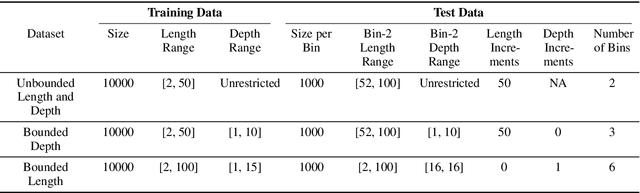
Adaptive Doubly Robust Estimator
Oct 08, 2020
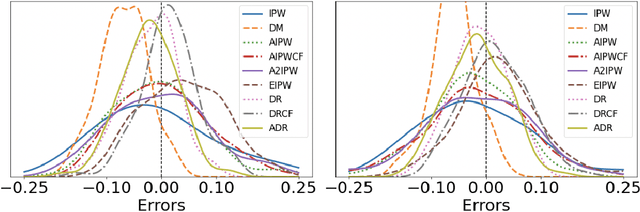
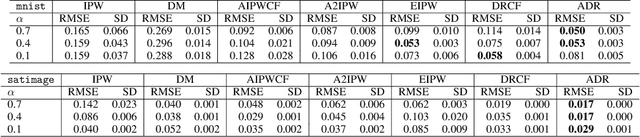
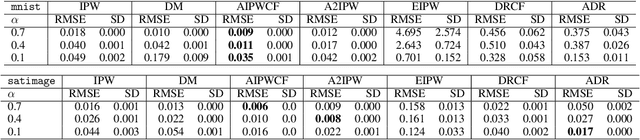
We propose a doubly robust (DR) estimator for off-policy evaluation (OPE) from data obtained via multi-armed bandit (MAB) algorithms. The goal of OPE is to evaluate a new policy using historical data. Because the MAB algorithms sequentially updates the policy based on past observations, the generated samples are not independent and identically distributed (i.i.d.). To conduct OPE from dependent samples, we propose an OPE estimator with asymptotic normality even under the dependency. In particular, we focus on a DR estimator, which consists of an inverse probability weighting (IPW) component and an estimator of the conditionally expected outcome. The proposed adaptive DR estimator only requires the convergence rate conditions of the nuisance estimators and the other mild regularity conditions; that is, we do not impose a specific time-series structure and Donsker's condition. We investigate the effectiveness by using benchmark datasets compared to a past proposed DR estimator with double/debiased machine learning and an adaptive version of an augmented IPW estimator.
RONELD: Robust Neural Network Output Enhancement for Active Lane Detection
Oct 19, 2020

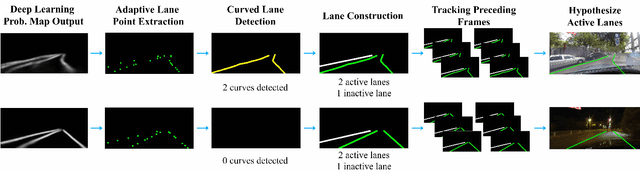
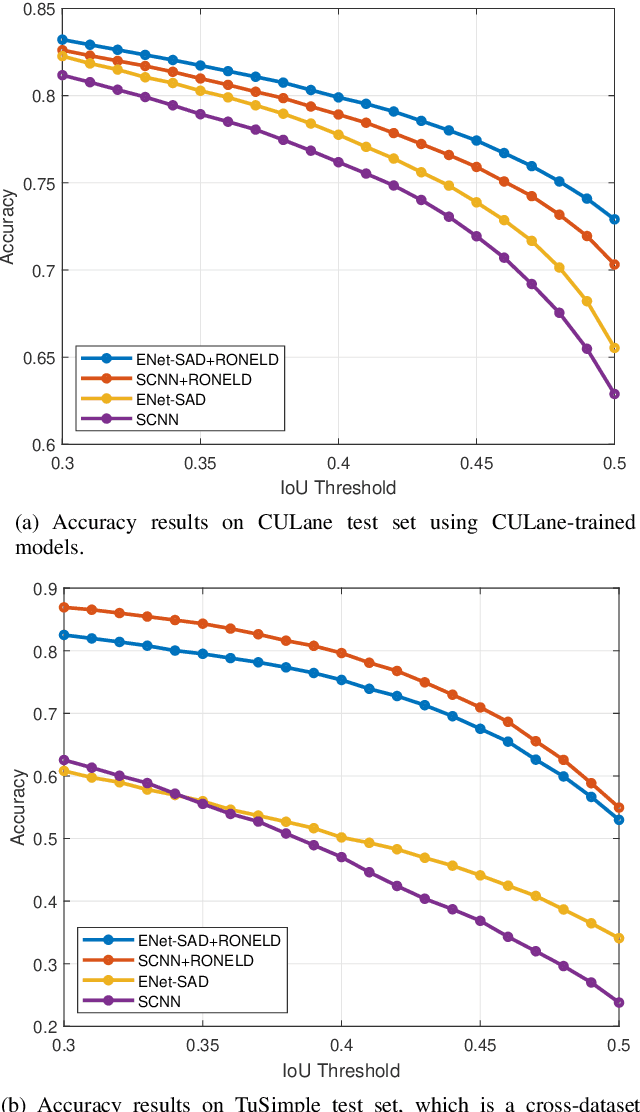
Accurate lane detection is critical for navigation in autonomous vehicles, particularly the active lane which demarcates the single road space that the vehicle is currently traveling on. Recent state-of-the-art lane detection algorithms utilize convolutional neural networks (CNNs) to train deep learning models on popular benchmarks such as TuSimple and CULane. While each of these models works particularly well on train and test inputs obtained from the same dataset, the performance drops significantly on unseen datasets of different environments. In this paper, we present a real-time robust neural network output enhancement for active lane detection (RONELD) method to identify, track, and optimize active lanes from deep learning probability map outputs. We first adaptively extract lane points from the probability map outputs, followed by detecting curved and straight lanes before using weighted least squares linear regression on straight lanes to fix broken lane edges resulting from fragmentation of edge maps in real images. Lastly, we hypothesize true active lanes through tracking preceding frames. Experimental results demonstrate an up to two-fold increase in accuracy using RONELD on cross-dataset validation tests.