 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Fully Bayesian Gradient-Free Supervised Dimension Reduction Method using Gaussian Processes
Aug 08, 2020
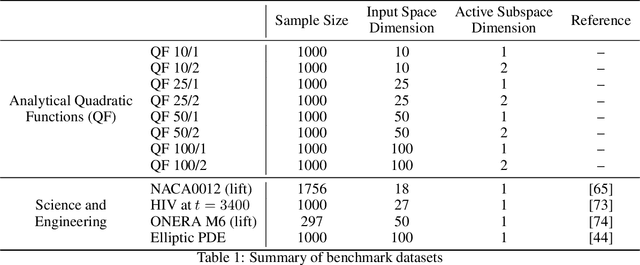
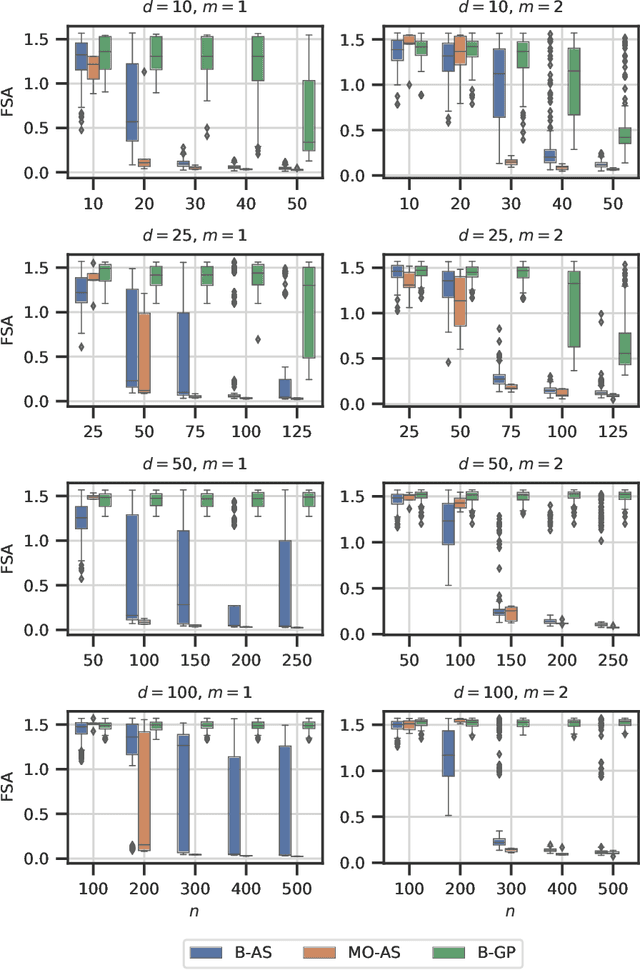
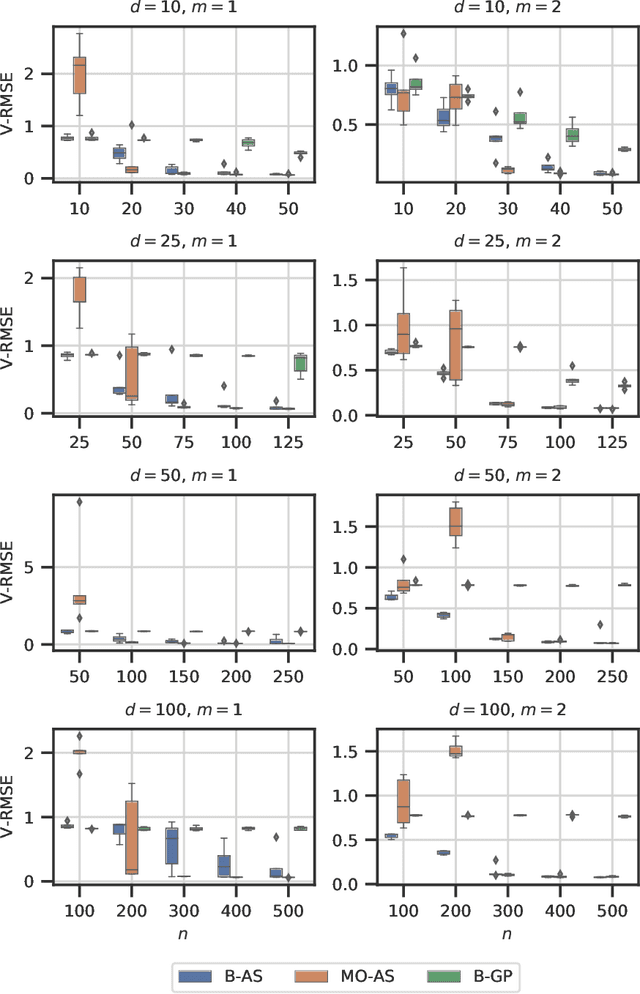
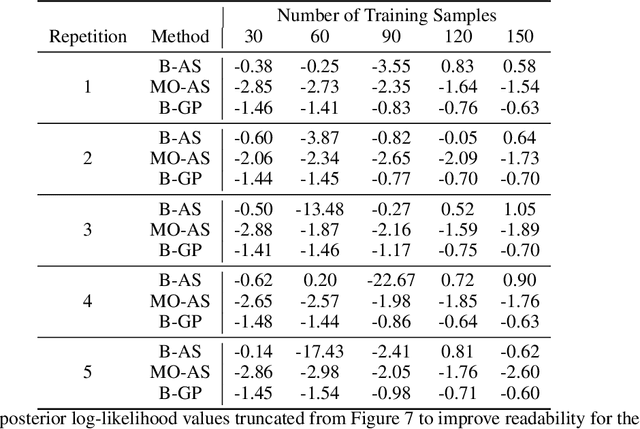
Modern day engineering problems are ubiquitously characterized by sophisticated computer codes that map parameters or inputs to an underlying physical process. In other situations, experimental setups are used to model the physical process in a laboratory, ensuring high precision while being costly in materials and logistics. In both scenarios, only limited amount of data can be generated by querying the expensive information source at a finite number of inputs or designs. This problem is compounded further in the presence of a high-dimensional input space. State-of-the-art parameter space dimension reduction methods, such as active subspace, aim to identify a subspace of the original input space that is sufficient to explain the output response. These methods are restricted by their reliance on gradient evaluations or copious data, making them inadequate to expensive problems without direct access to gradients. The proposed methodology is gradient-free and fully Bayesian, as it quantifies uncertainty in both the low-dimensional subspace and the surrogate model parameters. This enables a full quantification of epistemic uncertainty and robustness to limited data availability. It is validated on multiple datasets from engineering and science and compared to two other state-of-the-art methods based on four aspects: a) recovery of the active subspace, b) deterministic prediction accuracy, c) probabilistic prediction accuracy, and d) training time. The comparison shows that the proposed method improves the active subspace recovery and predictive accuracy, in both the deterministic and probabilistic sense, when only few model observations are available for training, at the cost of increased training time.
Independent innovation analysis for nonlinear vector autoregressive process
Jun 19, 2020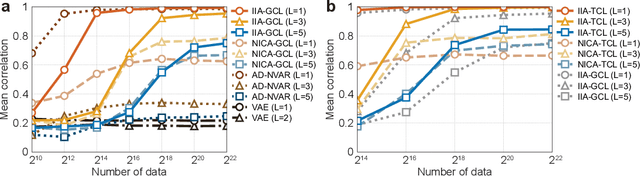
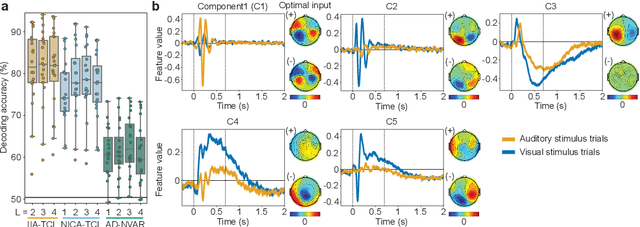
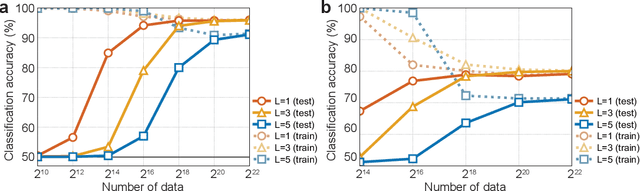
The nonlinear vector autoregressive (NVAR) model provides an appealing framework to analyze multivariate time series obtained from a nonlinear dynamical system. However, the innovation (or error), which plays a key role by driving the dynamics, is almost always assumed to be additive. Additivity greatly limits the generality of the model, hindering analysis of general NVAR process which have nonlinear interactions between the innovations. Here, we propose a new general framework called independent innovation analysis (IIA), which estimates the innovations from completely general NVAR. We assume mutual independence of the innovations as well as their modulation by a fully observable auxiliary variable (which is often taken as the time index and simply interpreted as nonstationarity). We show that IIA guarantees the identifiability of the innovations with arbitrary nonlinearities, up to a permutation and component-wise invertible nonlinearities. We propose two practical estimation methods, both of which can be easily implemented by ordinary neural network training. We thus provide the first rigorous identifiability result for general NVAR, as well as very general tools for learning such models.
Tactical Decision Making for Emergency Vehicles based on a Combinational Learning Method
Sep 09, 2020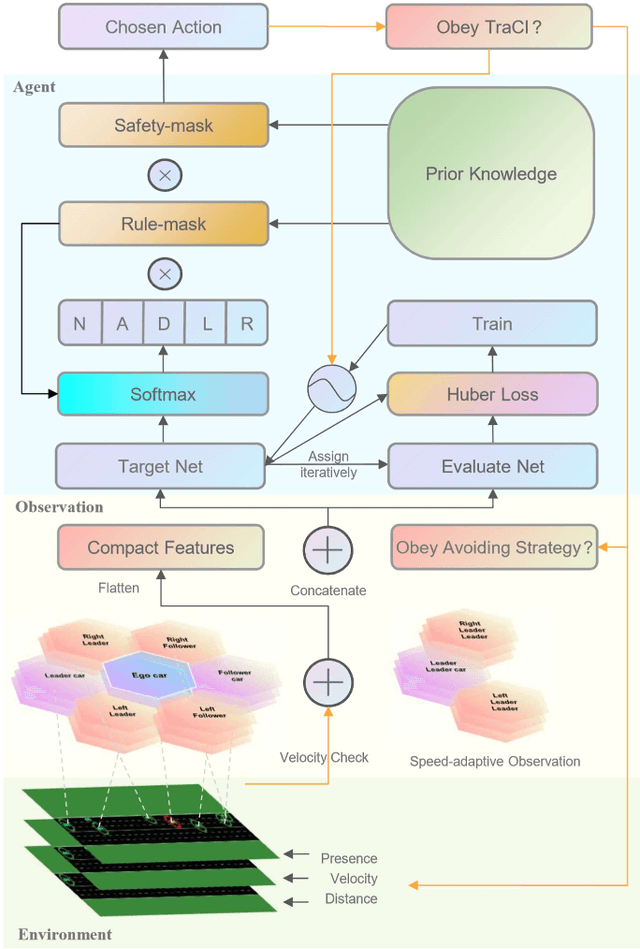
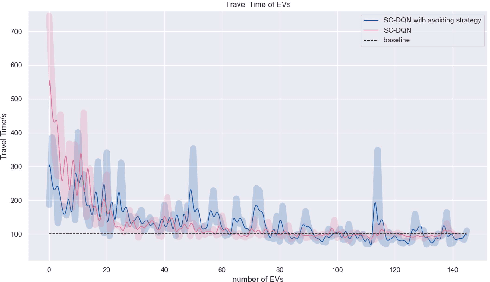
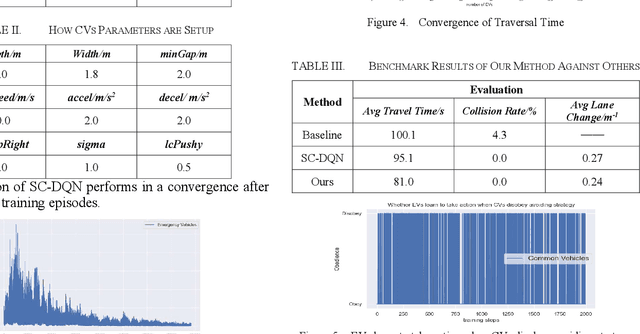
Increasing response time of emergency vehicles (EVs) could lead to an immensurable loss of property and life. On this account, tactical decision making for EV's microscopic control remains an indispensable issue to be improved. Our approach verifies that deep reinforcement learning could complement rule-based methods in generalization. It reveals that deterministic avoidance strategy for common vehicles at a low speed benefits EVs a lot, nevertheless, when at a high velocity, DQN breaks the deadlock of reduced safe distance and brings boldness to EVs in lane changing. Besides, a novel DQN method with speed-adaptive compact state space (SC-DQN) is put forward to fit in EVs' high-speed feature and generalize in various road topologies. All Above is implemented in SUMO emulator, where common vehicles are modeled rule-based whereas EVs are intelligently controlled.
Product Reservoir Computing: Time-Series Computation with Multiplicative Neurons
Apr 26, 2015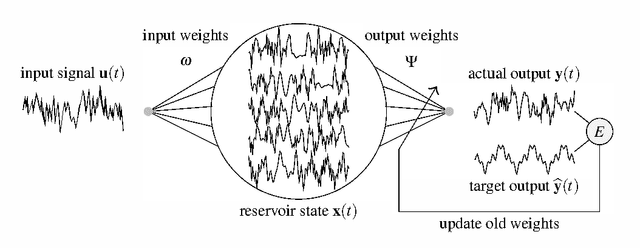
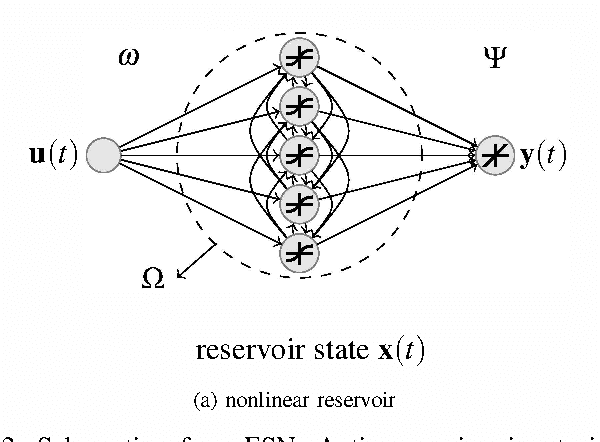
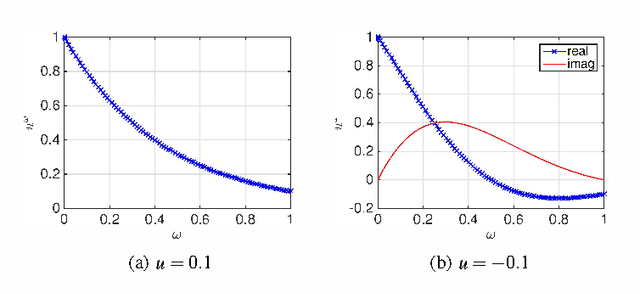
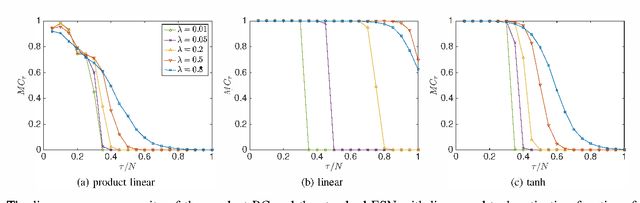
Echo state networks (ESN), a type of reservoir computing (RC) architecture, are efficient and accurate artificial neural systems for time series processing and learning. An ESN consists of a core of recurrent neural networks, called a reservoir, with a small number of tunable parameters to generate a high-dimensional representation of an input, and a readout layer which is easily trained using regression to produce a desired output from the reservoir states. Certain computational tasks involve real-time calculation of high-order time correlations, which requires nonlinear transformation either in the reservoir or the readout layer. Traditional ESN employs a reservoir with sigmoid or tanh function neurons. In contrast, some types of biological neurons obey response curves that can be described as a product unit rather than a sum and threshold. Inspired by this class of neurons, we introduce a RC architecture with a reservoir of product nodes for time series computation. We find that the product RC shows many properties of standard ESN such as short-term memory and nonlinear capacity. On standard benchmarks for chaotic prediction tasks, the product RC maintains the performance of a standard nonlinear ESN while being more amenable to mathematical analysis. Our study provides evidence that such networks are powerful in highly nonlinear tasks owing to high-order statistics generated by the recurrent product node reservoir.
Identification of deep breath while moving forward based on multiple body regions and graph signal analysis
Oct 20, 2020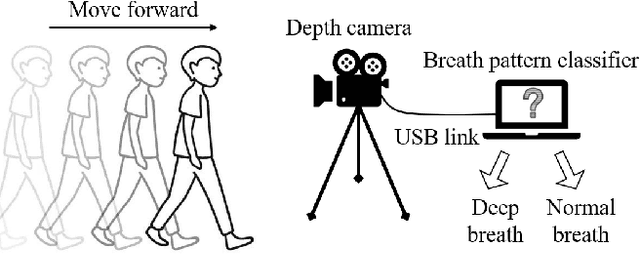
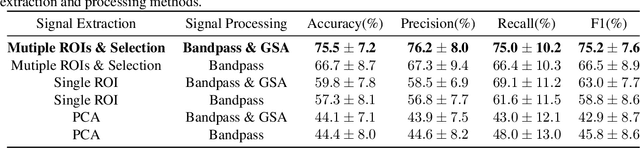
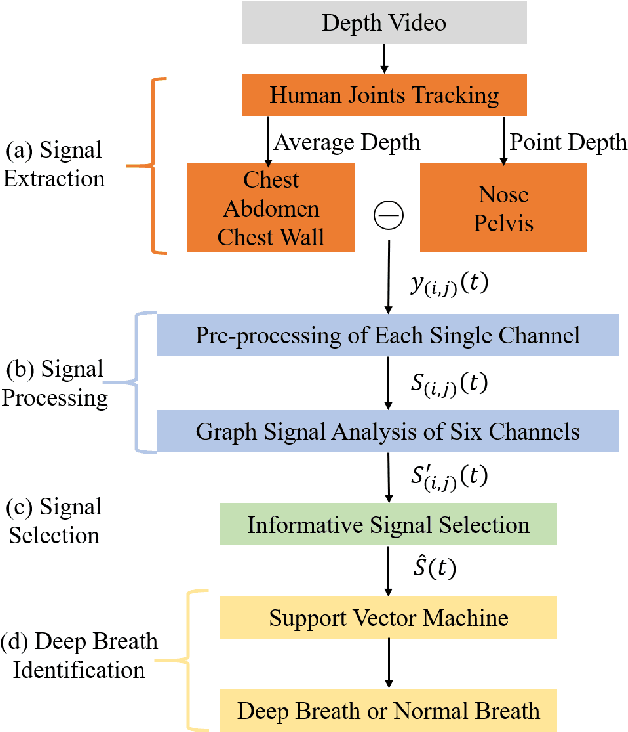
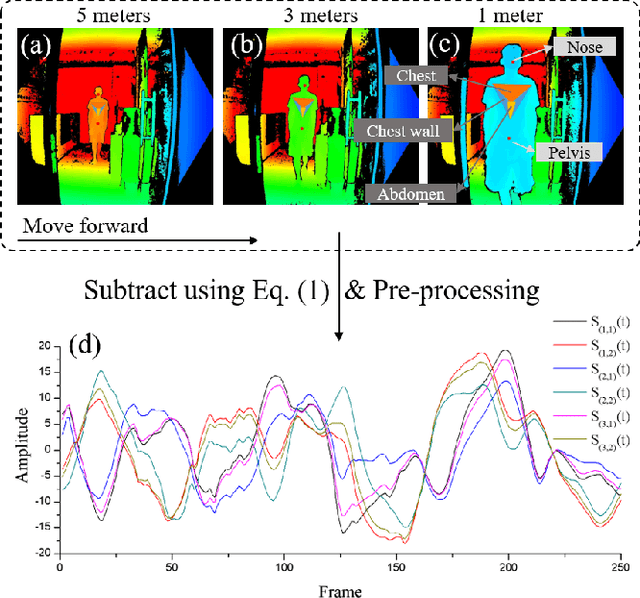
This paper presents an unobtrusive solution that can automatically identify deep breath when a person is walking past the global depth camera. Existing non-contact breath assessments achieve satisfactory results under restricted conditions when human body stays relatively still. When someone moves forward, the breath signals detected by depth camera are hidden within signals of trunk displacement and deformation, and the signal length is short due to the short stay time, posing great challenges for us to establish models. To overcome these challenges, multiple region of interests (ROIs) based signal extraction and selection method is proposed to automatically obtain the signal informative to breath from depth video. Subsequently, graph signal analysis (GSA) is adopted as a spatial-temporal filter to wipe the components unrelated to breath. Finally, a classifier for identifying deep breath is established based on the selected breath-informative signal. In validation experiments, the proposed approach outperforms the comparative methods with the accuracy, precision, recall and F1 of 75.5%, 76.2%, 75.0% and 75.2%, respectively. This system can be extended to public places to provide timely and ubiquitous help for those who may have or are going through physical or mental trouble.
Solving Inverse Stochastic Problems from Discrete Particle Observations Using the Fokker-Planck Equation and Physics-informed Neural Networks
Aug 24, 2020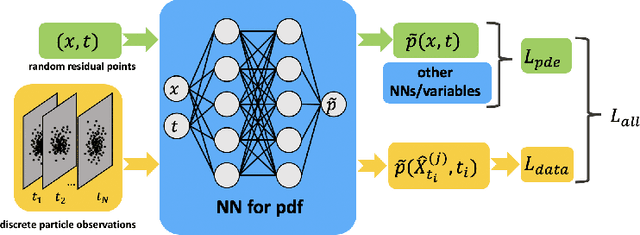
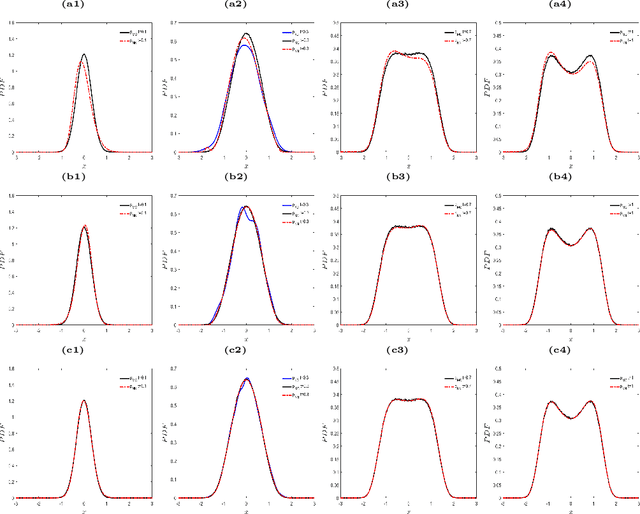
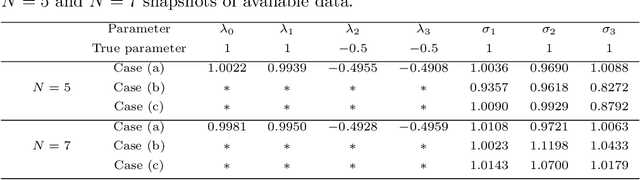
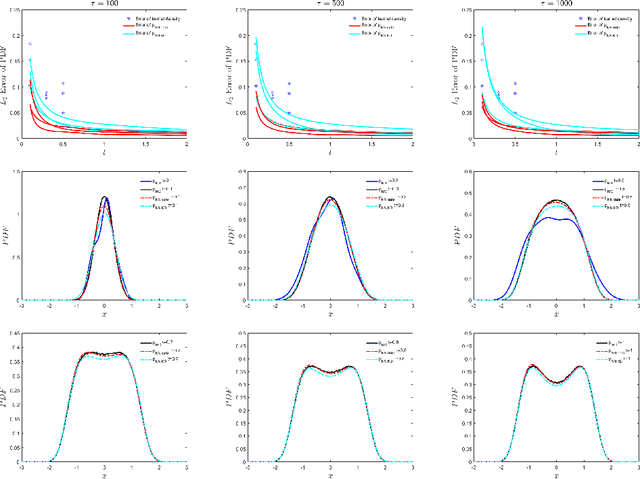
The Fokker-Planck (FP) equation governing the evolution of the probability density function (PDF) is applicable to many disciplines but it requires specification of the coefficients for each case, which can be functions of space-time and not just constants, hence requiring the development of a data-driven modeling approach. When the data available is directly on the PDF, then there exist methods for inverse problems that can be employed to infer the coefficients and thus determine the FP equation and subsequently obtain its solution. Herein, we address a more realistic scenario, where only sparse data are given on the particles' positions at a few time instants, which are not sufficient to accurately construct directly the PDF even at those times from existing methods, e.g., kernel estimation algorithms. To this end, we develop a general framework based on physics-informed neural networks (PINNs) that introduces a new loss function using the Kullback-Leibler divergence to connect the stochastic samples with the FP equation, to simultaneously learn the equation and infer the multi-dimensional PDF at all times. In particular, we consider two types of inverse problems, type I where the FP equation is known but the initial PDF is unknown, and type II in which, in addition to unknown initial PDF, the drift and diffusion terms are also unknown. In both cases, we investigate problems with either Brownian or Levy noise or a combination of both. We demonstrate the new PINN framework in detail in the one-dimensional case (1D) but we also provide results for up to 5D demonstrating that we can infer both the FP equation and} dynamics simultaneously at all times with high accuracy using only very few discrete observations of the particles.
An Evaluation of Change Point Detection Algorithms
Mar 13, 2020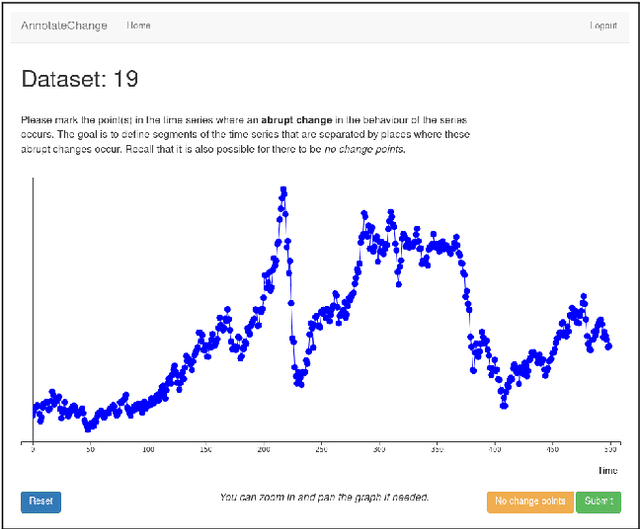

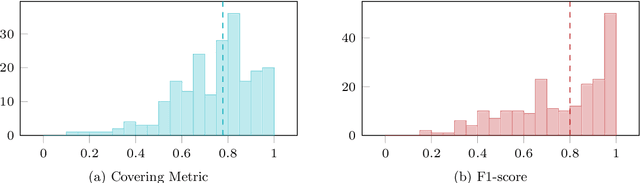
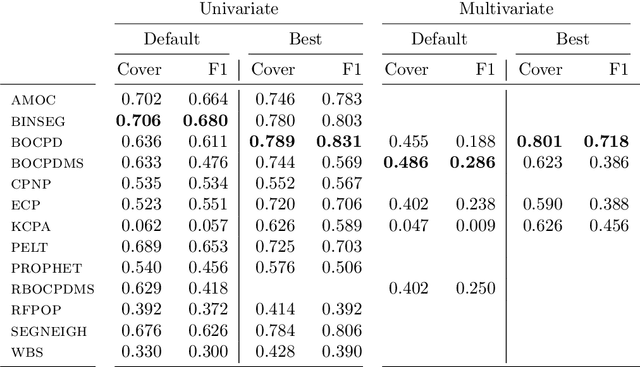
Change point detection is an important part of time series analysis, as the presence of a change point indicates an abrupt and significant change in the data generating process. While many algorithms for change point detection exist, little attention has been paid to evaluating their performance on real-world time series. Algorithms are typically evaluated on simulated data and a small number of commonly-used series with unreliable ground truth. Clearly this does not provide sufficient insight into the comparative performance of these algorithms. Therefore, instead of developing yet another change point detection method, we consider it vastly more important to properly evaluate existing algorithms on real-world data. To achieve this, we present the first data set specifically designed for the evaluation of change point detection algorithms, consisting of 37 time series from various domains. Each time series was annotated by five expert human annotators to provide ground truth on the presence and location of change points. We analyze the consistency of the human annotators, and describe evaluation metrics that can be used to measure algorithm performance in the presence of multiple ground truth annotations. Subsequently, we present a benchmark study where 13 existing algorithms are evaluated on each of the time series in the data set. This study shows that binary segmentation (Scott and Knott, 1974) and Bayesian online change point detection (Adams and MacKay, 2007) are among the best performing methods. Our aim is that this data set will serve as a proving ground in the development of novel change point detection algorithms.
MixML: A Unified Analysis of Weakly Consistent Parallel Learning
Jun 06, 2020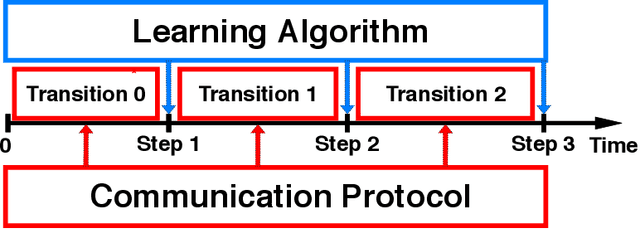
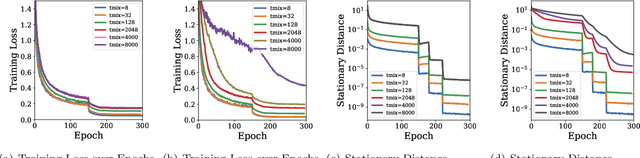
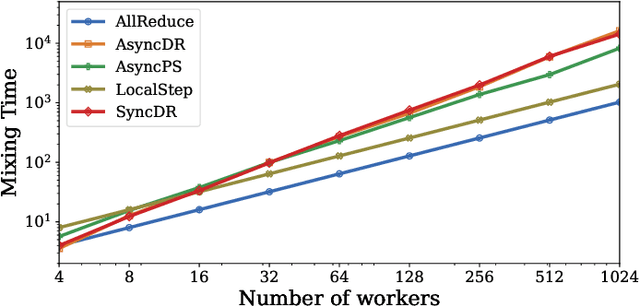
Parallelism is a ubiquitous method for accelerating machine learning algorithms. However, theoretical analysis of parallel learning is usually done in an algorithm- and protocol-specific setting, giving little insight about how changes in the structure of communication could affect convergence. In this paper we propose MixML, a general framework for analyzing convergence of weakly consistent parallel machine learning. Our framework includes: (1) a unified way of modeling the communication process among parallel workers; (2) a new parameter, the mixing time tmix, that quantifies how the communication process affects convergence; and (3) a principled way of converting a convergence proof for a sequential algorithm into one for a parallel version that depends only on tmix. We show MixML recovers and improves on known convergence bounds for asynchronous and/or decentralized versions of many algorithms, includingSGD and AMSGrad. Our experiments substantiate the theory and show the dependency of convergence on the underlying mixing time.
ECG Classification with a Convolutional Recurrent Neural Network
Sep 28, 2020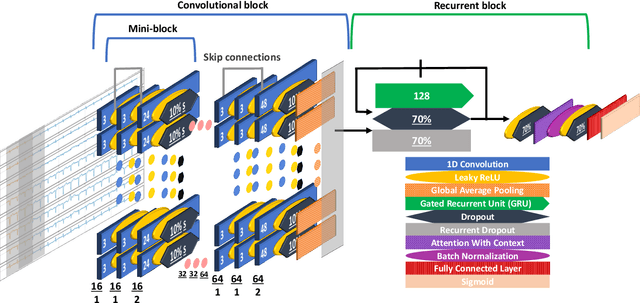
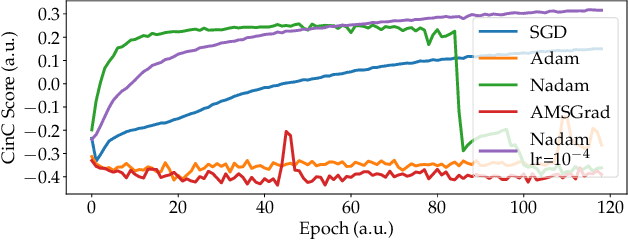
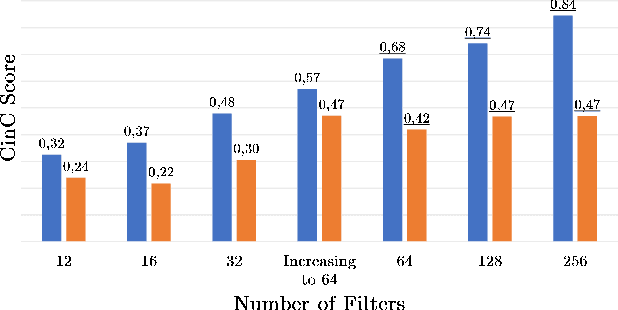
We developed a convolutional recurrent neural network to classify 12-lead ECG signals for the challenge of PhysioNet/ Computing in Cardiology 2020 as team Pink Irish Hat. The model combines convolutional and recurrent layers, takes sliding windows of ECG signals as input and yields the probability of each class as output. The convolutional part extracts features from each sliding window. The bi-directional gated recurrent unit (GRU) layer and an attention layer aggregate these features from all windows into a single feature vector. Finally, a dense layer outputs class probabilities. The final decision is made using test time augmentation (TTA) and an optimized decision threshold. Several hyperparameters of our architecture were optimized, the most important of which turned out to be the choice of optimizer and the number of filters per convolutional layer. Our network achieved a challenge score of 0.511 on the hidden validation set and 0.167 on the full hidden test set, ranking us 23rd out of 41 in the official ranking.
Impact and dynamics of hate and counter speech online
Sep 16, 2020
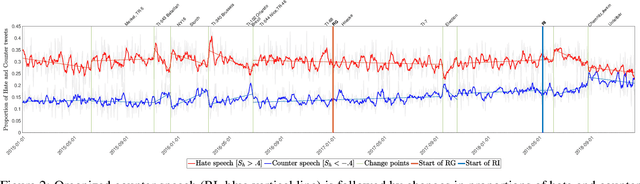
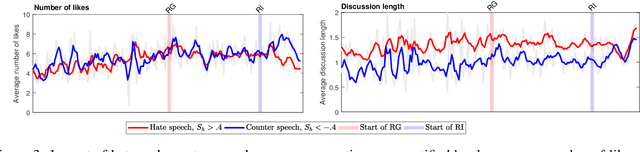
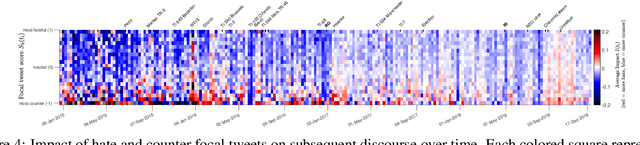
Citizen-generated counter speech is a promising way to fight hate speech and promote peaceful, non-polarized discourse. However, there is a lack of large-scale longitudinal studies of its effectiveness for reducing hate speech. We investigate the effectiveness of counter speech using several different macro- and micro-level measures of over 180,000 political conversations that took place on German Twitter over four years. We report on the dynamic interactions of hate and counter speech over time and provide insights into whether, as in `classic' bullying situations, organized efforts are more effective than independent individuals in steering online discourse. Taken together, our results build a multifaceted picture of the dynamics of hate and counter speech online. They suggest that organized hate speech produced changes in the public discourse. Counter speech, especially when organized, could help in curbing hate speech in online discussions.