 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Formalizing Integration Patterns with Multimedia Data (Extended Version)
Sep 09, 2020
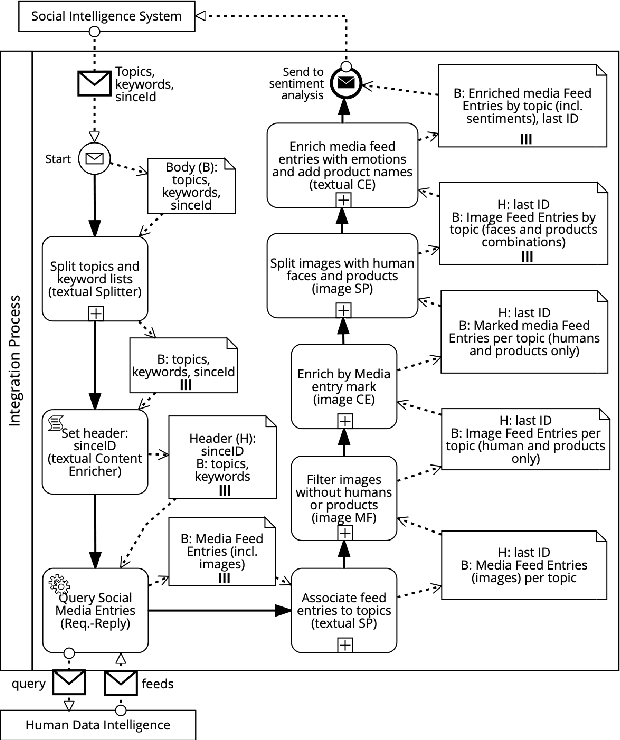
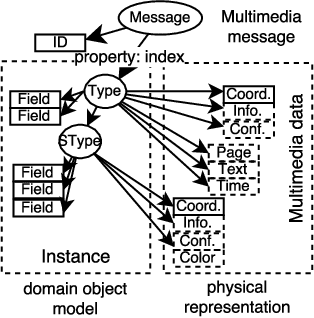
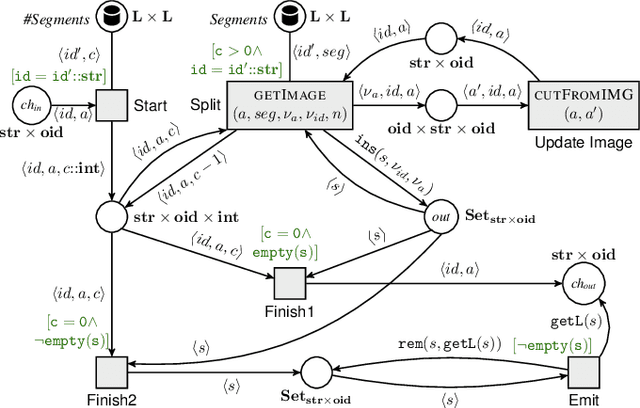
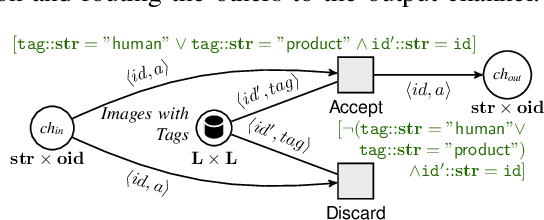
The previous works on formalizing enterprise application integration (EAI) scenarios showed an emerging need for setting up formal foundations for integration patterns, the EAI building blocks, in order to facilitate the model-driven development and ensure its correctness. So far, the formalization requirements were focusing on more "conventional" integration scenarios, in which control-flow, transactional persistent data and time aspects were considered. However, none of these works took into consideration another arising EAI trend that covers social and multimedia computing. In this work we propose a Petri net-based formalism that addresses requirements arising from the multimedia domain. We also demonstrate realizations of one of the most frequently used multimedia patterns and discuss which implications our formal proposal may bring into the area of the multimedia EAI development.
Product Reservoir Computing: Time-Series Computation with Multiplicative Neurons
Apr 26, 2015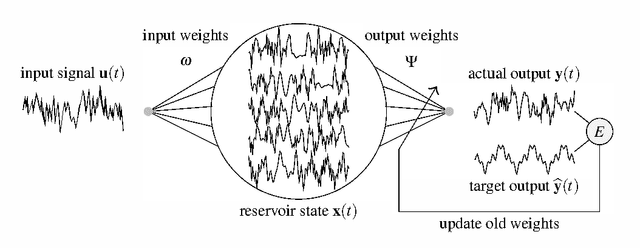
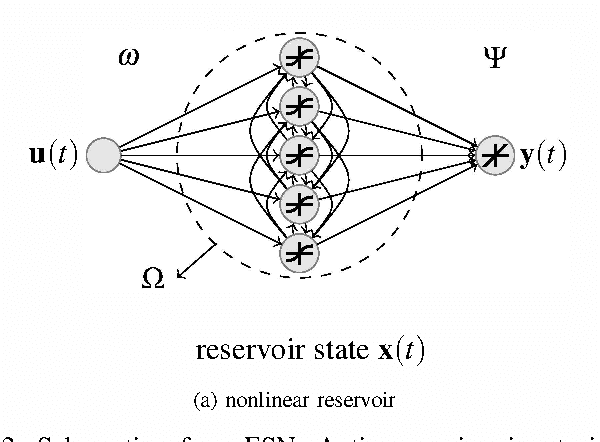
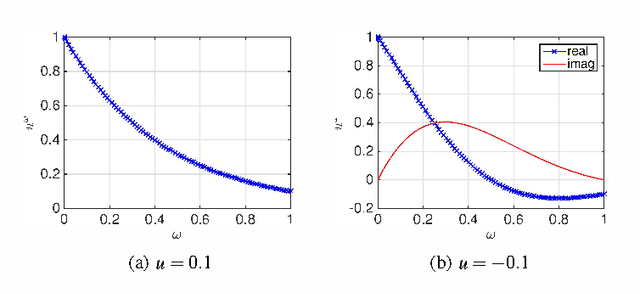
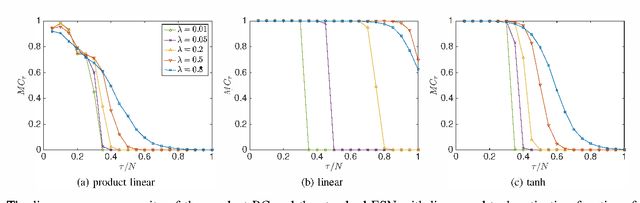
Echo state networks (ESN), a type of reservoir computing (RC) architecture, are efficient and accurate artificial neural systems for time series processing and learning. An ESN consists of a core of recurrent neural networks, called a reservoir, with a small number of tunable parameters to generate a high-dimensional representation of an input, and a readout layer which is easily trained using regression to produce a desired output from the reservoir states. Certain computational tasks involve real-time calculation of high-order time correlations, which requires nonlinear transformation either in the reservoir or the readout layer. Traditional ESN employs a reservoir with sigmoid or tanh function neurons. In contrast, some types of biological neurons obey response curves that can be described as a product unit rather than a sum and threshold. Inspired by this class of neurons, we introduce a RC architecture with a reservoir of product nodes for time series computation. We find that the product RC shows many properties of standard ESN such as short-term memory and nonlinear capacity. On standard benchmarks for chaotic prediction tasks, the product RC maintains the performance of a standard nonlinear ESN while being more amenable to mathematical analysis. Our study provides evidence that such networks are powerful in highly nonlinear tasks owing to high-order statistics generated by the recurrent product node reservoir.
DARE: AI-based Diver Action Recognition System using Multi-Channel CNNs for AUV Supervision
Nov 16, 2020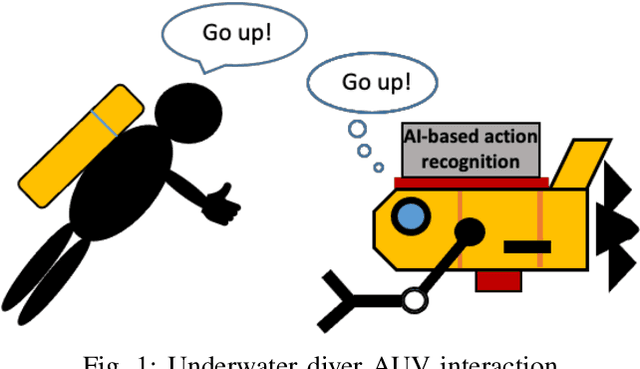
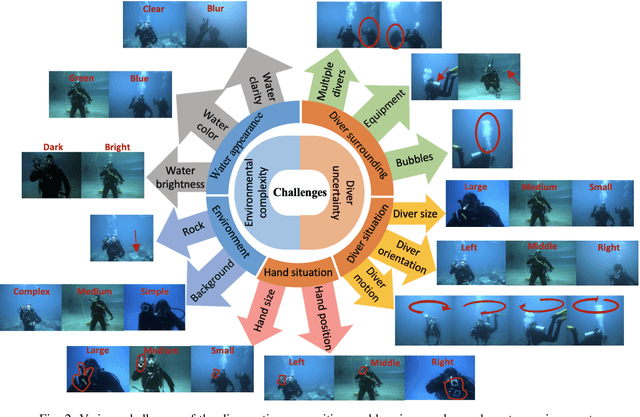
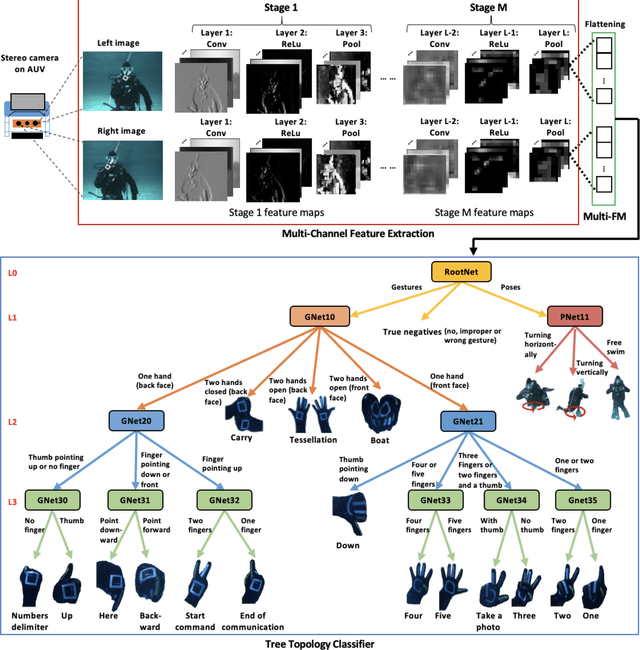

With the growth of sensing, control and robotic technologies, autonomous underwater vehicles (AUVs) have become useful assistants to human divers for performing various underwater operations. In the current practice, the divers are required to carry expensive, bulky, and waterproof keyboards or joystick-based controllers for supervision and control of AUVs. Therefore, diver action-based supervision is becoming increasingly popular because it is convenient, easier to use, faster, and cost effective. However, the various environmental, diver and sensing uncertainties present underwater makes it challenging to train a robust and reliable diver action recognition system. In this regard, this paper presents DARE, a diver action recognition system, that is trained based on Cognitive Autonomous Driving Buddy (CADDY) dataset, which is a rich set of data containing images of different diver gestures and poses in several different and realistic underwater environments. DARE is based on fusion of stereo-pairs of camera images using a multi-channel convolutional neural network supported with a systematically trained tree-topological deep neural network classifier to enhance the classification performance. DARE is fast and requires only a few milliseconds to classify one stereo-pair, thus making it suitable for real-time underwater implementation. DARE is comparatively evaluated against several existing classifier architectures and the results show that DARE supersedes the performance of all classifiers for diver action recognition in terms of overall as well as individual class accuracies and F1-scores.
Generative Adversarial Simulator
Nov 23, 2020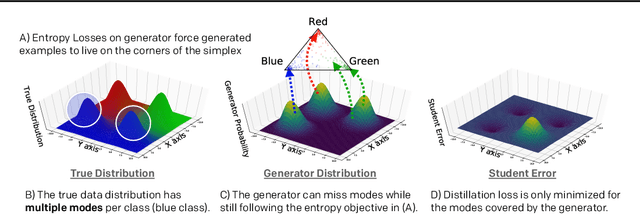
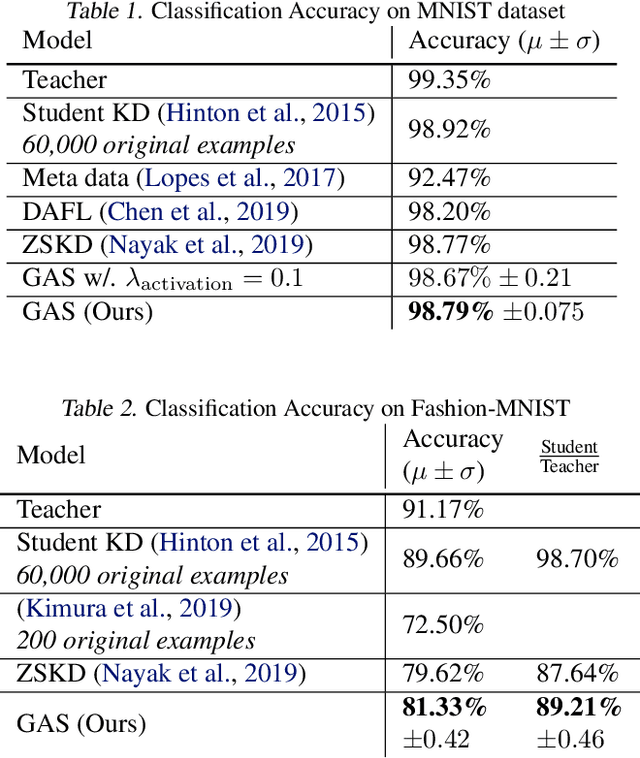
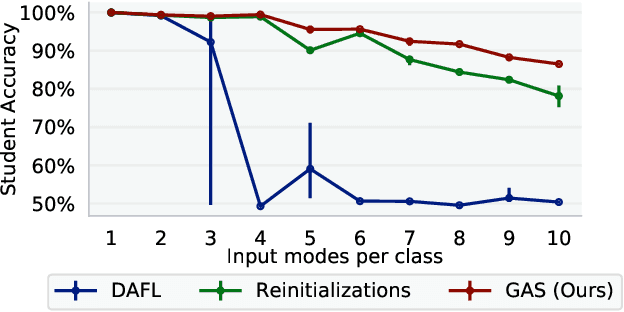
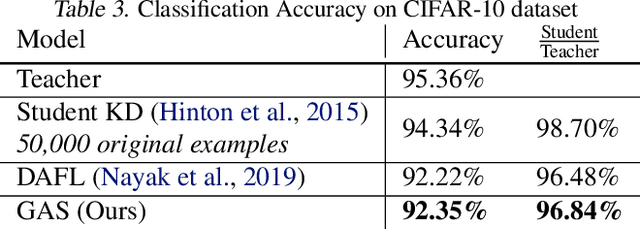
Knowledge distillation between machine learning models has opened many new avenues for parameter count reduction, performance improvements, or amortizing training time when changing architectures between the teacher and student network. In the case of reinforcement learning, this technique has also been applied to distill teacher policies to students. Until now, policy distillation required access to a simulator or real world trajectories. In this paper we introduce a simulator-free approach to knowledge distillation in the context of reinforcement learning. A key challenge is having the student learn the multiplicity of cases that correspond to a given action. While prior work has shown that data-free knowledge distillation is possible with supervised learning models by generating synthetic examples, these approaches to are vulnerable to only producing a single prototype example for each class. We propose an extension to explicitly handle multiple observations per output class that seeks to find as many exemplars as possible for a given output class by reinitializing our data generator and making use of an adversarial loss. To the best of our knowledge, this is the first demonstration of simulator-free knowledge distillation between a teacher and a student policy. This new approach improves over the state of the art on data-free learning of student networks on benchmark datasets (MNIST, Fashion-MNIST, CIFAR-10), and we also demonstrate that it specifically tackles issues with multiple input modes. We also identify open problems when distilling agents trained in high dimensional environments such as Pong, Breakout, or Seaquest.
Data-Driven Transient Stability Boundary Generation for Online Security Monitoring
Apr 03, 2020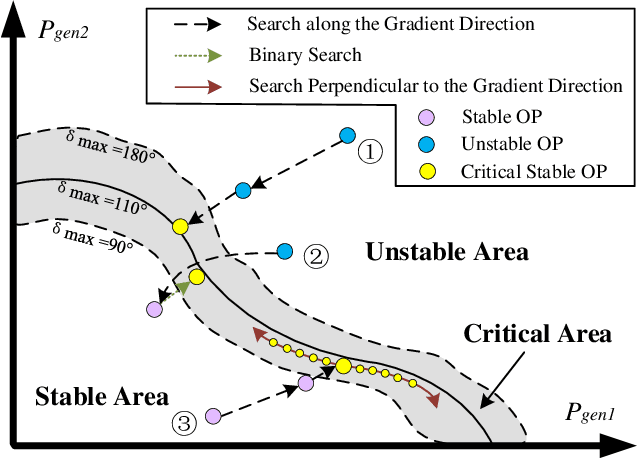
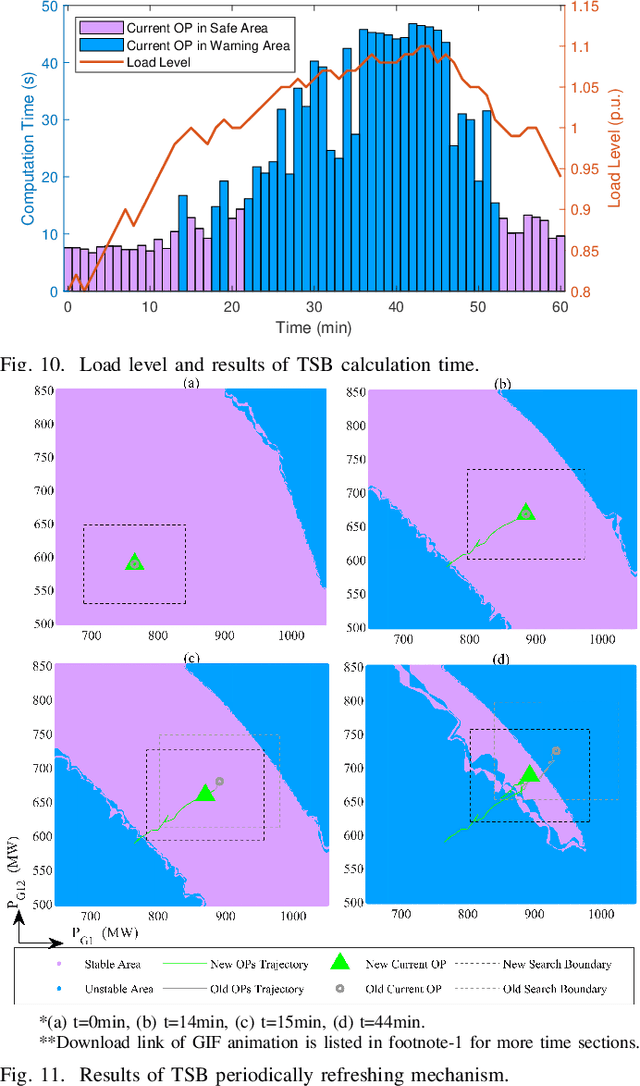
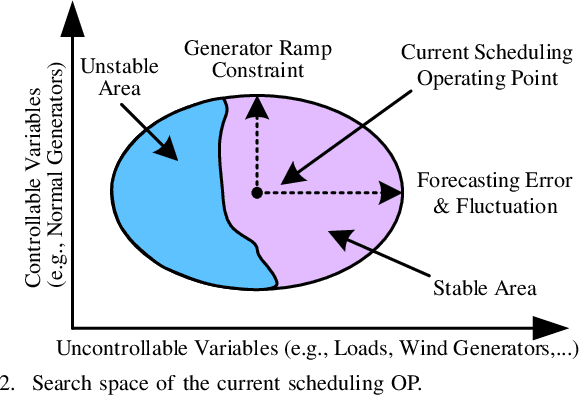
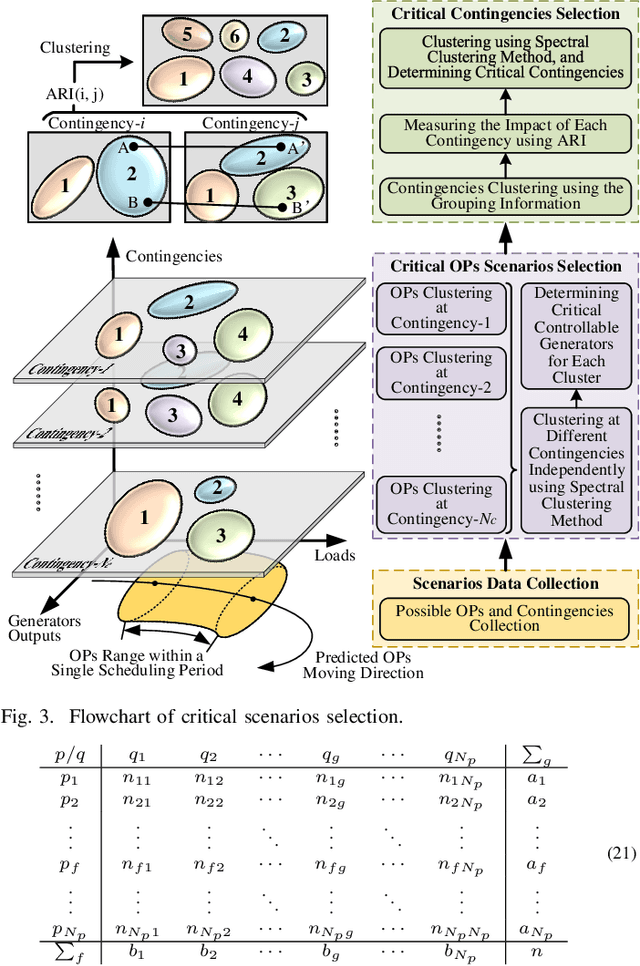
Transient stability boundary (TSB) is an important tool in power system online security monitoring, but practically it suffers from high computational burden using state-of-the-art methods, such as time-domain simulation (TDS), with numerous scenarios taken into account (e.g., operating points (OPs) and N-1 contingencies). The purpose of this work is to establish a data-driven framework to generate sufficient critical samples close to the boundary within a limited time, covering all critical scenarios in current OP. Therefore, accurate TSB can be periodically refreshed by tracking current OP in time. The idea is to develop a search strategy to obtain more data samples near the stability boundary, while traverse the rest part with fewer samples. To achieve this goal, a specially designed transient index sensitivity based search strategy and critical scenarios selection mechanism are proposed, in order to find out the most representative scenarios and periodically update TSB for online monitoring. Two case studies validate effectiveness of the proposed method.
A Triclustering Approach for Time Evolving Graphs
Jan 12, 2013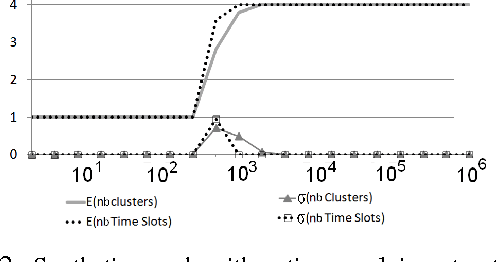
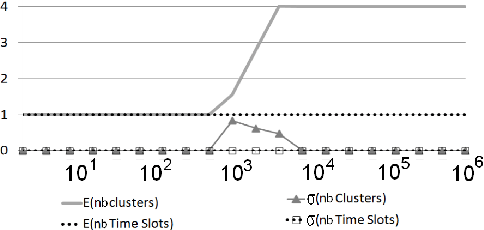
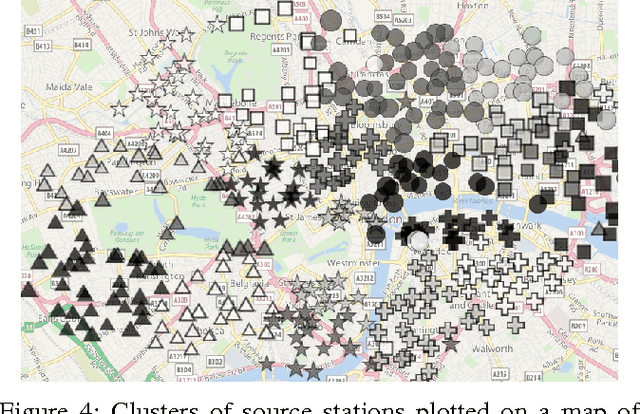
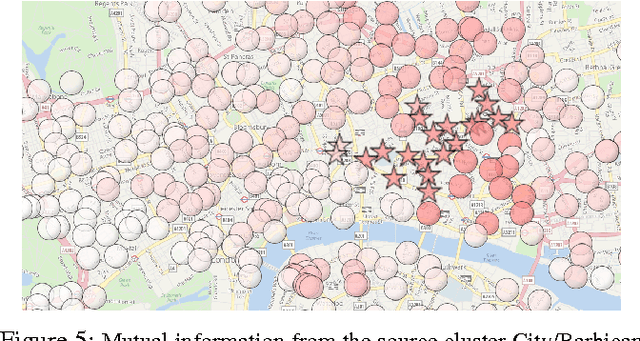
This paper introduces a novel technique to track structures in time evolving graphs. The method is based on a parameter free approach for three-dimensional co-clustering of the source vertices, the target vertices and the time. All these features are simultaneously segmented in order to build time segments and clusters of vertices whose edge distributions are similar and evolve in the same way over the time segments. The main novelty of this approach lies in that the time segments are directly inferred from the evolution of the edge distribution between the vertices, thus not requiring the user to make an a priori discretization. Experiments conducted on a synthetic dataset illustrate the good behaviour of the technique, and a study of a real-life dataset shows the potential of the proposed approach for exploratory data analysis.
A Comprehensive Survey of Machine Learning Applied to Radar Signal Processing
Sep 29, 2020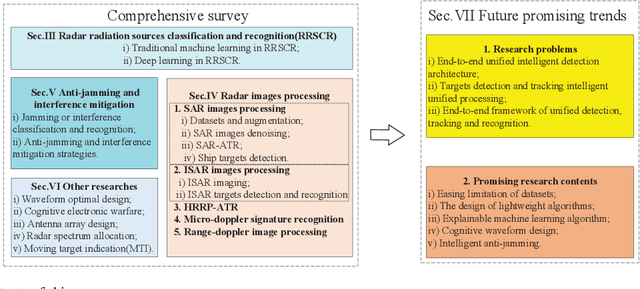
Modern radar systems have high requirements in terms of accuracy, robustness and real-time capability when operating on increasingly complex electromagnetic environments. Traditional radar signal processing (RSP) methods have shown some limitations when meeting such requirements, particularly in matters of target classification. With the rapid development of machine learning (ML), especially deep learning, radar researchers have started integrating these new methods when solving RSP-related problems. This paper aims at helping researchers and practitioners to better understand the application of ML techniques to RSP-related problems by providing a comprehensive, structured and reasoned literature overview of ML-based RSP techniques. This work is amply introduced by providing general elements of ML-based RSP and by stating the motivations behind them. The main applications of ML-based RSP are then analysed and structured based on the application field. This paper then concludes with a series of open questions and proposed research directions, in order to indicate current gaps and potential future solutions and trends.
Learning Knowledge Bases with Parameters for Task-Oriented Dialogue Systems
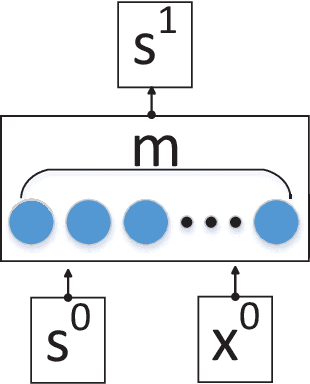
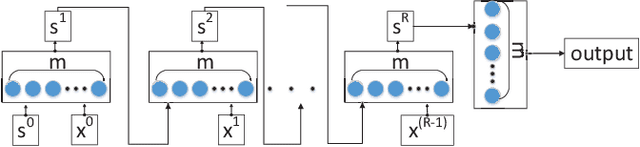
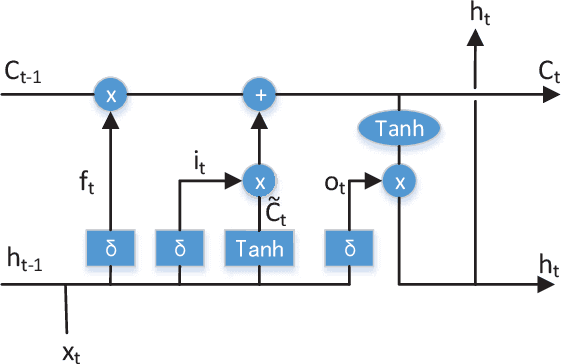
Sep 28, 2020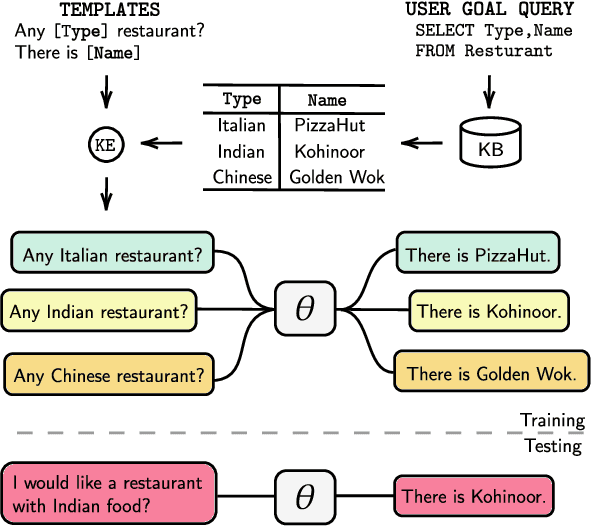

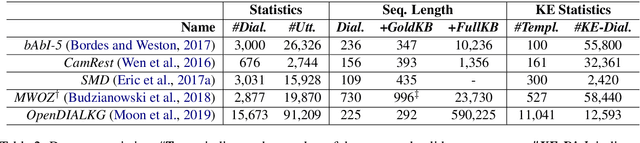
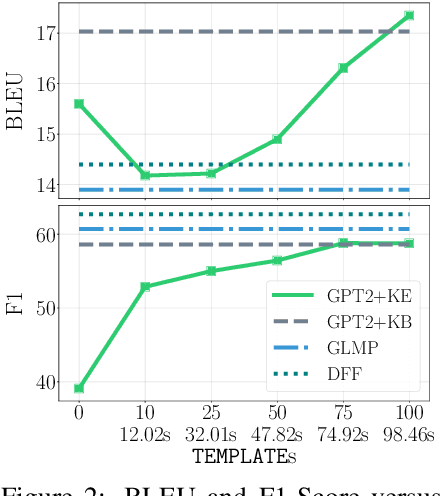
Task-oriented dialogue systems are either modularized with separate dialogue state tracking (DST) and management steps or end-to-end trainable. In either case, the knowledge base (KB) plays an essential role in fulfilling user requests. Modularized systems rely on DST to interact with the KB, which is expensive in terms of annotation and inference time. End-to-end systems use the KB directly as input, but they cannot scale when the KB is larger than a few hundred entries. In this paper, we propose a method to embed the KB, of any size, directly into the model parameters. The resulting model does not require any DST or template responses, nor the KB as input, and it can dynamically update its KB via fine-tuning. We evaluate our solution in five task-oriented dialogue datasets with small, medium, and large KB size. Our experiments show that end-to-end models can effectively embed knowledge bases in their parameters and achieve competitive performance in all evaluated datasets.
Deep Hurdle Networks for Zero-Inflated Multi-Target Regression: Application to Multiple Species Abundance Estimation
Oct 30, 2020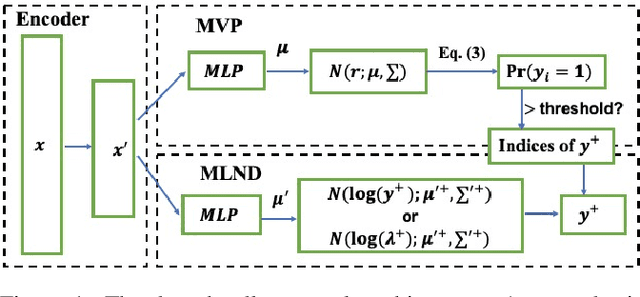
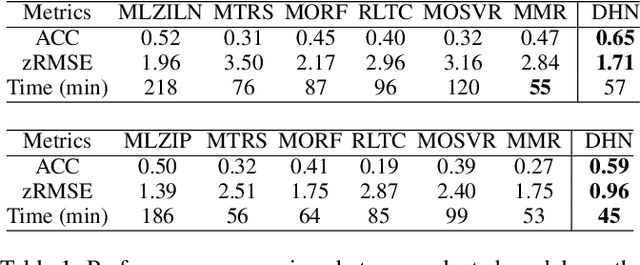
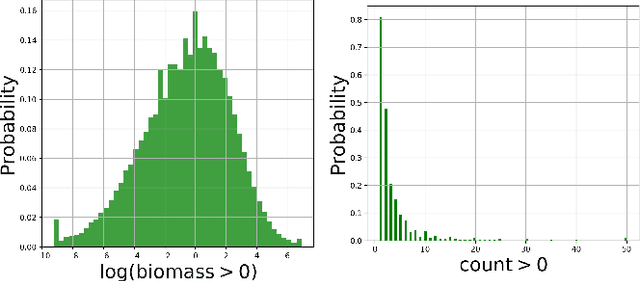
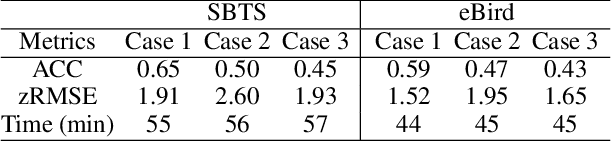
A key problem in computational sustainability is to understand the distribution of species across landscapes over time. This question gives rise to challenging large-scale prediction problems since (i) hundreds of species have to be simultaneously modeled and (ii) the survey data are usually inflated with zeros due to the absence of species for a large number of sites. The problem of tackling both issues simultaneously, which we refer to as the zero-inflated multi-target regression problem, has not been addressed by previous methods in statistics and machine learning. In this paper, we propose a novel deep model for the zero-inflated multi-target regression problem. To this end, we first model the joint distribution of multiple response variables as a multivariate probit model and then couple the positive outcomes with a multivariate log-normal distribution. By penalizing the difference between the two distributions' covariance matrices, a link between both distributions is established. The whole model is cast as an end-to-end learning framework and we provide an efficient learning algorithm for our model that can be fully implemented on GPUs. We show that our model outperforms the existing state-of-the-art baselines on two challenging real-world species distribution datasets concerning bird and fish populations.
Exploring the structure of a real-time, arbitrary neural artistic stylization network
Aug 24, 2017


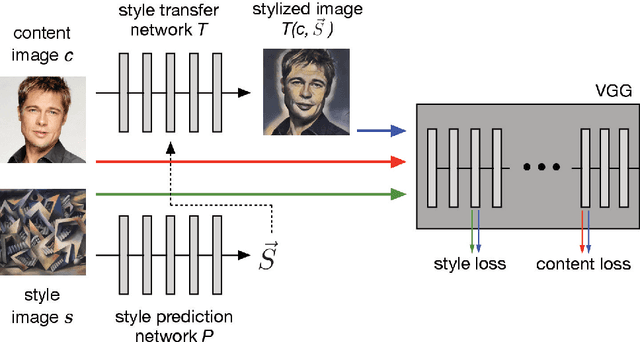
In this paper, we present a method which combines the flexibility of the neural algorithm of artistic style with the speed of fast style transfer networks to allow real-time stylization using any content/style image pair. We build upon recent work leveraging conditional instance normalization for multi-style transfer networks by learning to predict the conditional instance normalization parameters directly from a style image. The model is successfully trained on a corpus of roughly 80,000 paintings and is able to generalize to paintings previously unobserved. We demonstrate that the learned embedding space is smooth and contains a rich structure and organizes semantic information associated with paintings in an entirely unsupervised manner.