 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Long-term prediction of chaotic systems with recurrent neural networks
Mar 06, 2020
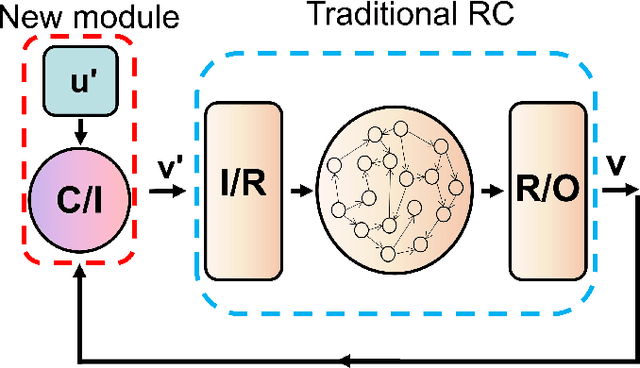
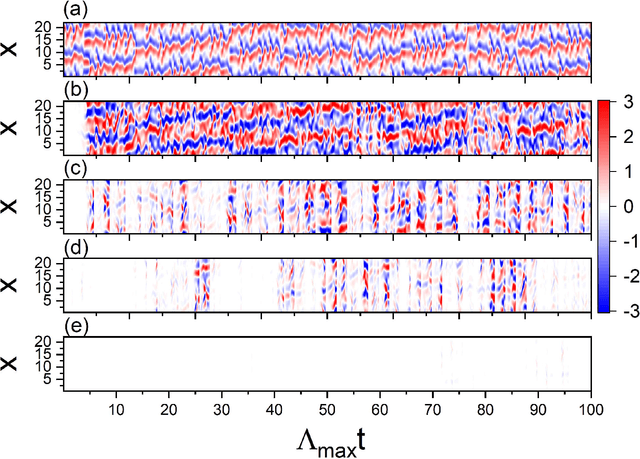
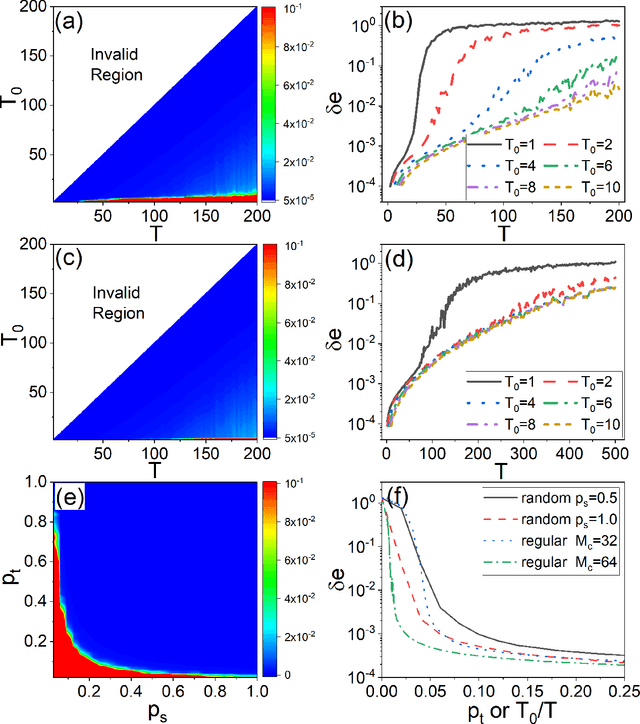
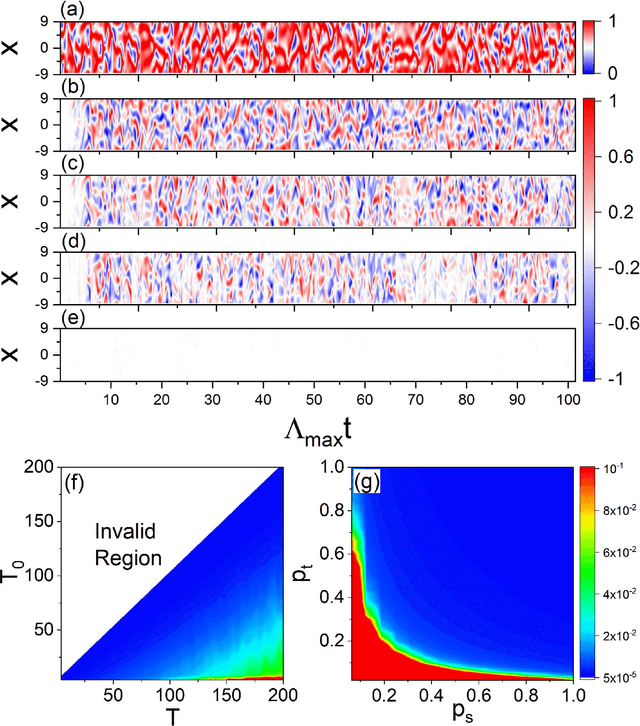
Reservoir computing systems, a class of recurrent neural networks, have recently been exploited for model-free, data-based prediction of the state evolution of a variety of chaotic dynamical systems. The prediction horizon demonstrated has been about half dozen Lyapunov time. Is it possible to significantly extend the prediction time beyond what has been achieved so far? We articulate a scheme incorporating time-dependent but sparse data inputs into reservoir computing and demonstrate that such rare "updates" of the actual state practically enable an arbitrarily long prediction horizon for a variety of chaotic systems. A physical understanding based on the theory of temporal synchronization is developed.
Optimal Subarchitecture Extraction For BERT
Oct 20, 2020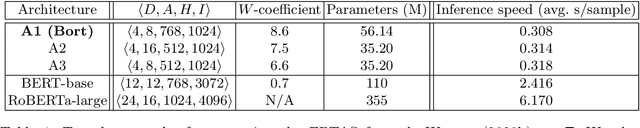
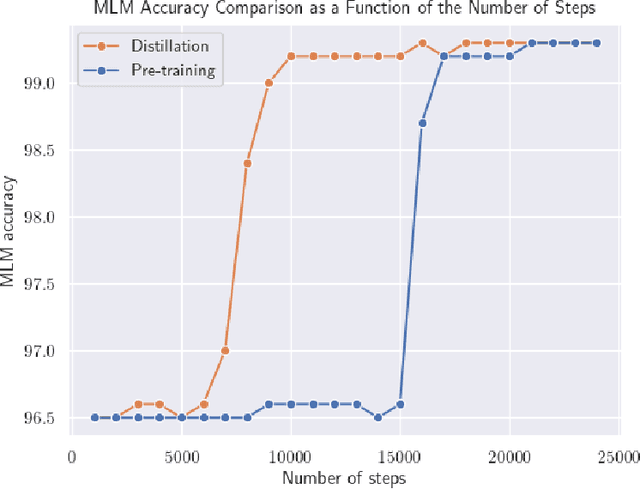
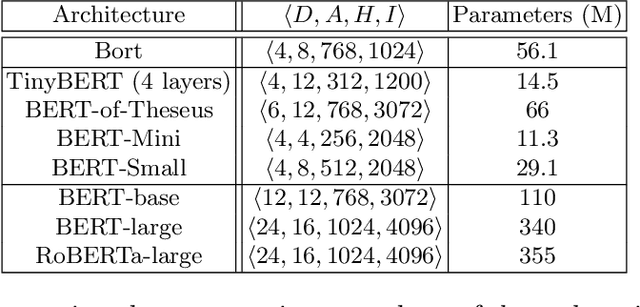

We extract an optimal subset of architectural parameters for the BERT architecture from Devlin et al. (2018) by applying recent breakthroughs in algorithms for neural architecture search. This optimal subset, which we refer to as "Bort", is demonstrably smaller, having an effective (that is, not counting the embedding layer) size of $5.5\%$ the original BERT-large architecture, and $16\%$ of the net size. Bort is also able to be pretrained in $288$ GPU hours, which is $1.2\%$ of the time required to pretrain the highest-performing BERT parametric architectural variant, RoBERTa-large (Liu et al., 2019), and about $33\%$ of that of the world-record, in GPU hours, required to train BERT-large on the same hardware. It is also $7.9$x faster on a CPU, as well as being better performing than other compressed variants of the architecture, and some of the non-compressed variants: it obtains performance improvements of between $0.3\%$ and $31\%$, absolute, with respect to BERT-large, on multiple public natural language understanding (NLU) benchmarks.
Multimodal Spatio-Temporal Deep Learning Approach for Neonatal Postoperative Pain Assessment
Dec 03, 2020
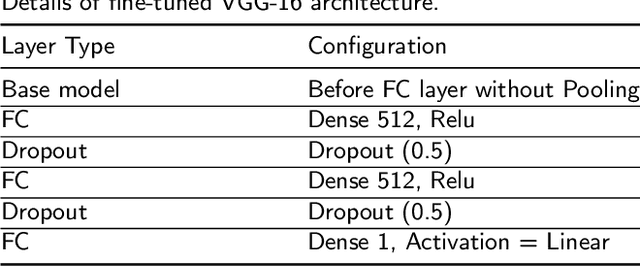
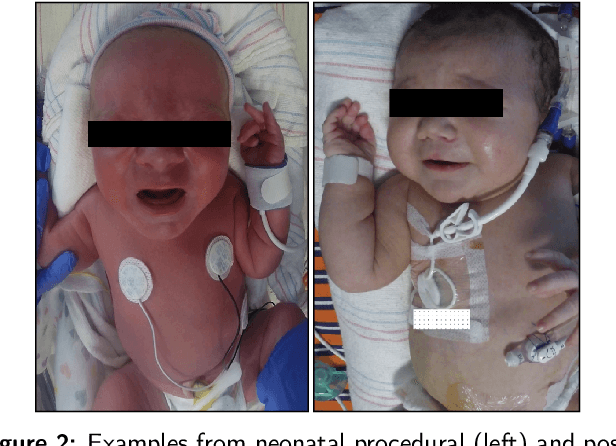
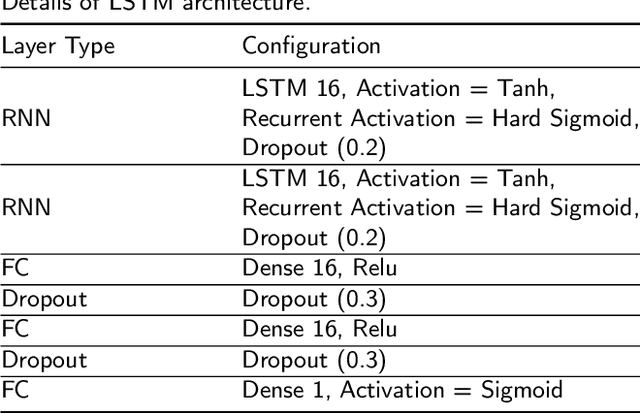
The current practice for assessing neonatal postoperative pain relies on bedside caregivers. This practice is subjective, inconsistent, slow, and discontinuous. To develop a reliable medical interpretation, several automated approaches have been proposed to enhance the current practice. These approaches are unimodal and focus mainly on assessing neonatal procedural (acute) pain. As pain is a multimodal emotion that is often expressed through multiple modalities, the multimodal assessment of pain is necessary especially in case of postoperative (acute prolonged) pain. Additionally, spatio-temporal analysis is more stable over time and has been proven to be highly effective at minimizing misclassification errors. In this paper, we present a novel multimodal spatio-temporal approach that integrates visual and vocal signals and uses them for assessing neonatal postoperative pain. We conduct comprehensive experiments to investigate the effectiveness of the proposed approach. We compare the performance of the multimodal and unimodal postoperative pain assessment, and measure the impact of temporal information integration. The experimental results, on a real-world dataset, show that the proposed multimodal spatio-temporal approach achieves the highest AUC (0.87) and accuracy (79%), which are on average 6.67% and 6.33% higher than unimodal approaches. The results also show that the integration of temporal information markedly improves the performance as compared to the non-temporal approach as it captures changes in the pain dynamic. These results demonstrate that the proposed approach can be used as a viable alternative to manual assessment, which would tread a path toward fully automated pain monitoring in clinical settings, point-of-care testing, and homes.
WHO 2016 subtyping and automated segmentation of glioma using multi-task deep learning
Oct 09, 2020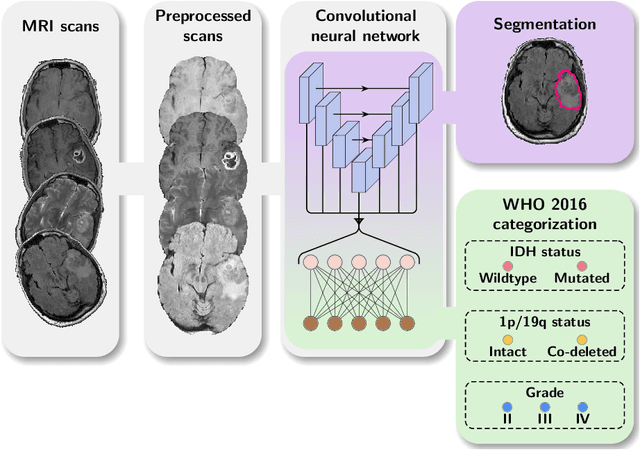
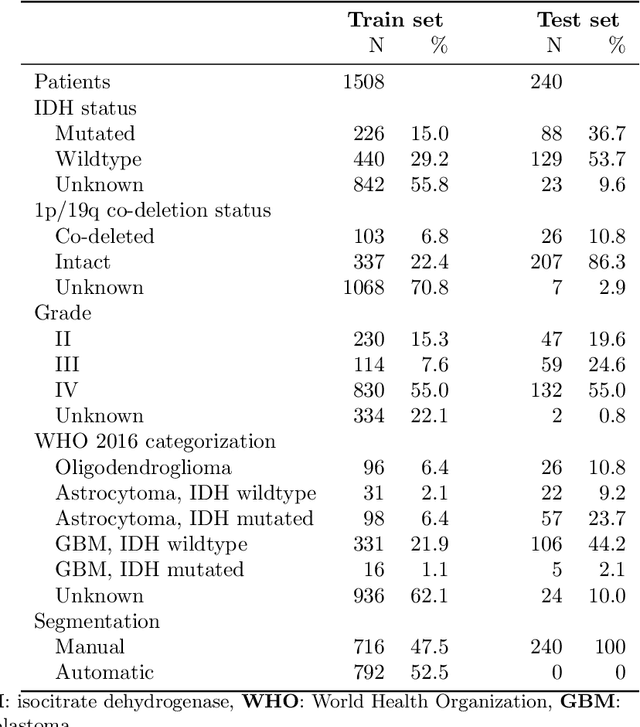
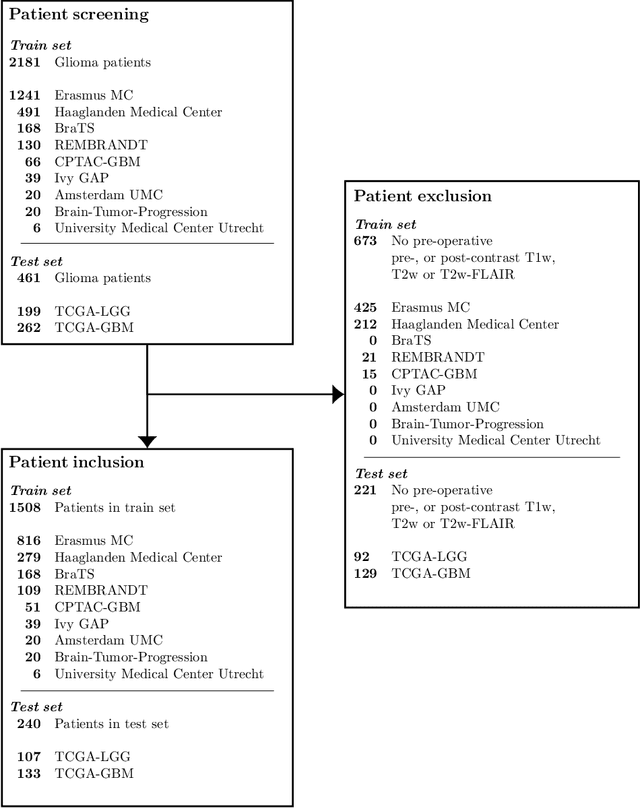
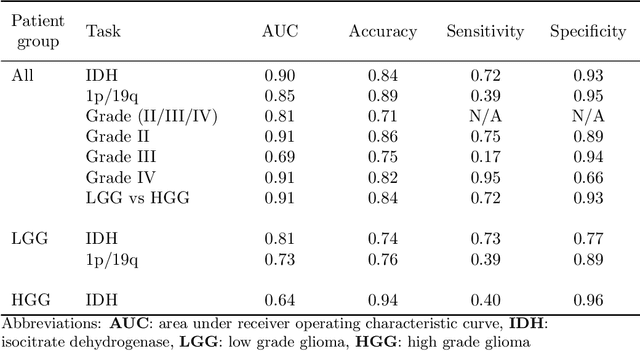
Accurate characterization of glioma is crucial for clinical decision making. A delineation of the tumor is also desirable in the initial decision stages but is a time-consuming task. Leveraging the latest GPU capabilities, we developed a single multi-task convolutional neural network that uses the full 3D, structural, pre-operative MRI scans to can predict the IDH mutation status, the 1p/19q co-deletion status, and the grade of a tumor, while simultaneously segmenting the tumor. We trained our method using the largest, most diverse patient cohort to date containing 1508 glioma patients from 16 institutes. We tested our method on an independent dataset of 240 patients from 13 different institutes, and achieved an IDH-AUC of 0.90, 1p/19q-AUC of 0.85, grade-AUC of 0.81, and a mean whole tumor DICE score of 0.84. Thus, our method non-invasively predicts multiple, clinically relevant parameters and generalizes well to the broader clinical population.
Multilevel Minimization for Deep Residual Networks
Apr 13, 2020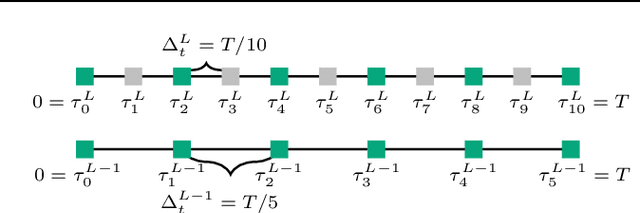
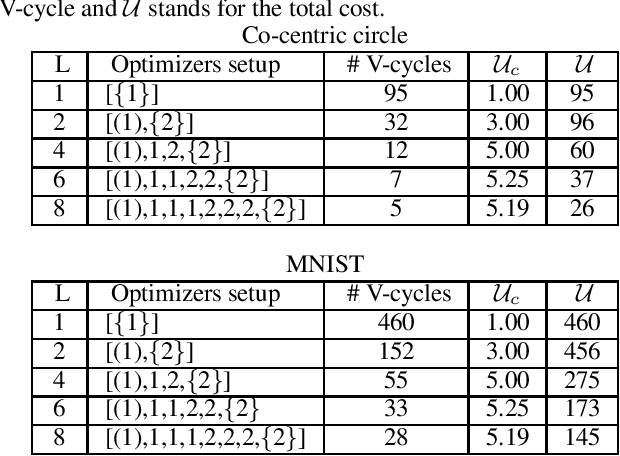
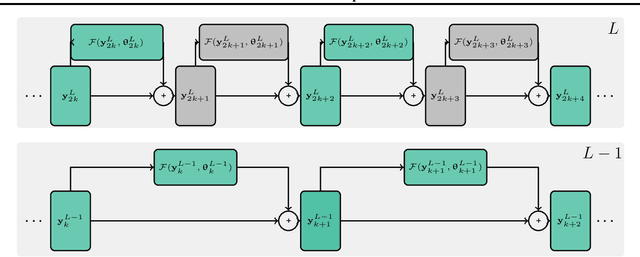
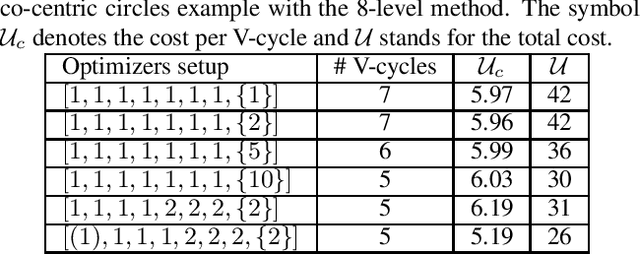
We present a new multilevel minimization framework for the training of deep residual networks (ResNets), which has the potential to significantly reduce training time and effort. Our framework is based on the dynamical system's viewpoint, which formulates a ResNet as the discretization of an initial value problem. The training process is then formulated as a time-dependent optimal control problem, which we discretize using different time-discretization parameters, eventually generating multilevel-hierarchy of auxiliary networks with different resolutions. The training of the original ResNet is then enhanced by training the auxiliary networks with reduced resolutions. By design, our framework is conveniently independent of the choice of the training strategy chosen on each level of the multilevel hierarchy. By means of numerical examples, we analyze the convergence behavior of the proposed method and demonstrate its robustness. For our examples we employ a multilevel gradient-based methods. Comparisons with standard single level methods show a speedup of more than factor three while achieving the same validation accuracy.
CharacterBERT: Reconciling ELMo and BERT for Word-Level Open-Vocabulary Representations From Characters
Oct 20, 2020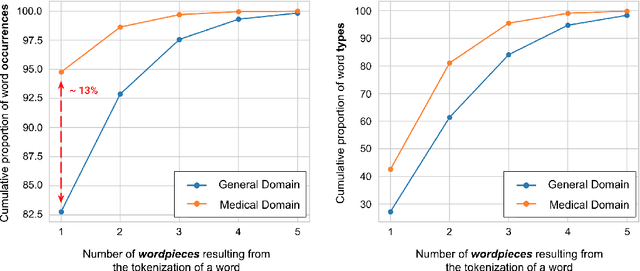

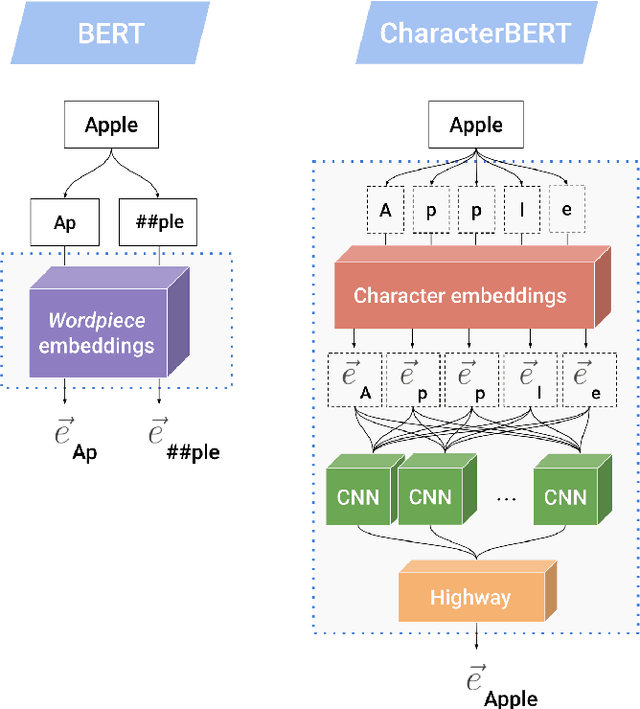
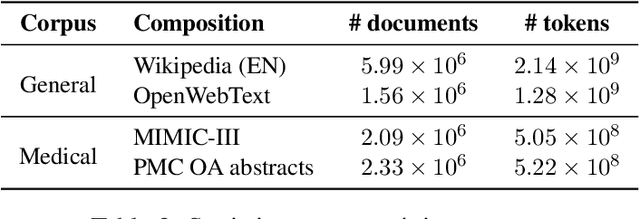
Due to the compelling improvements brought by BERT, many recent representation models adopted the Transformer architecture as their main building block, consequently inheriting the wordpiece tokenization system even if it is not intrinsically linked to the notion of Transformer. While this system is thought to achieve a good balance between the flexibility of characters and the efficiency of full words, using predefined wordpiece vocabularies from the general domain is not always suitable, especially when building models for specialized domains (e.g., the medical domain). Moreover, adopting a wordpiece tokenization shifts the focus from the word level to the subword level, making the models conceptually more complex and arguably less convenient in practice. For these reasons, we propose CharacterBERT, a new variant of BERT that drops the wordpiece system altogether and uses a Character-CNN module instead to represent entire words by consulting their characters. We show that this new model improves the performance of BERT on a variety of medical domain tasks while at the same time producing robust, word-level and open-vocabulary representations.
LookOut! Interactive Camera Gimbal Controller for Filming Long Takes
Dec 03, 2020
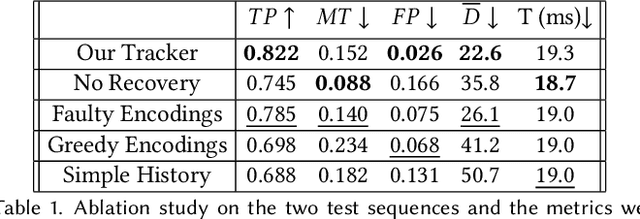

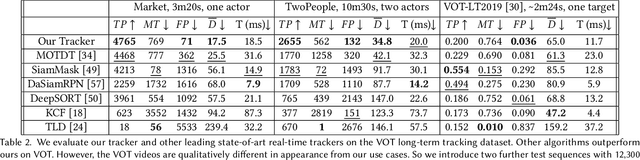
The job of a camera operator is more challenging, and potentially dangerous, when filming long moving camera shots. Broadly, the operator must keep the actors in-frame while safely navigating around obstacles, and while fulfilling an artistic vision. We propose a unified hardware and software system that distributes some of the camera operator's burden, freeing them up to focus on safety and aesthetics during a take. Our real-time system provides a solo operator with end-to-end control, so they can balance on-set responsiveness to action vs planned storyboards and framing, while looking where they're going. By default, we film without a field monitor. Our LookOut system is built around a lightweight commodity camera gimbal mechanism, with heavy modifications to the controller, which would normally just provide active stabilization. Our control algorithm reacts to speech commands, video, and a pre-made script. Specifically, our automatic monitoring of the live video feed saves the operator from distractions. In pre-production, an artist uses our GUI to design a sequence of high-level camera "behaviors." Those can be specific, based on a storyboard, or looser objectives, such as "frame both actors." Then during filming, a machine-readable script, exported from the GUI, ties together with the sensor readings to drive the gimbal. To validate our algorithm, we compared tracking strategies, interfaces, and hardware protocols, and collected impressions from a) film-makers who used all aspects of our system, and b) film-makers who watched footage filmed using LookOut.
A general solution to the preferential selection model
Aug 06, 2020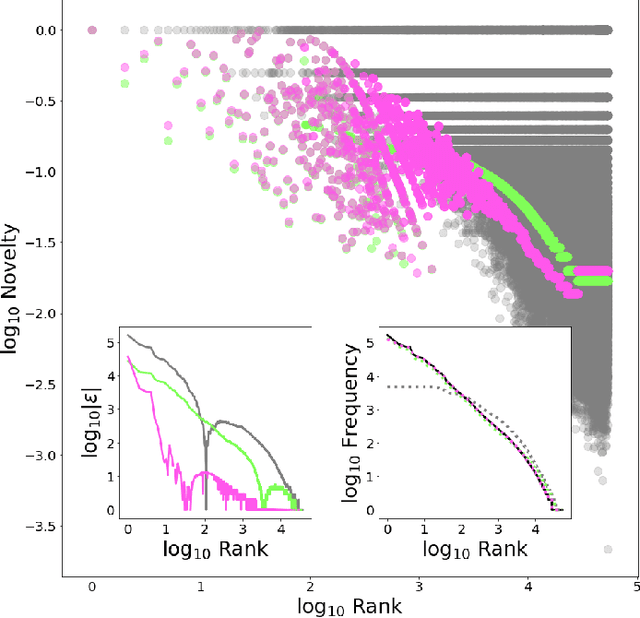
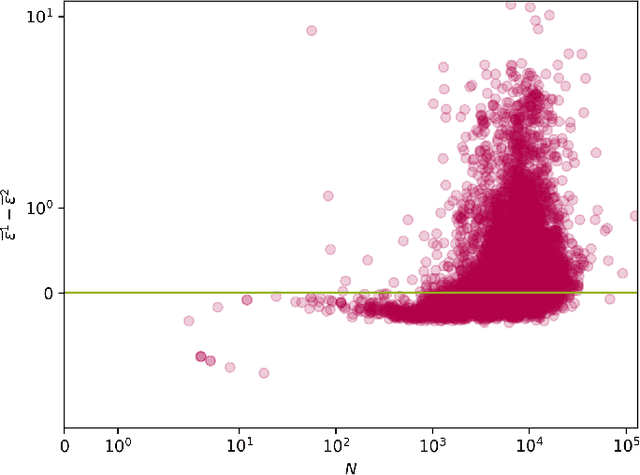
We provide a general analytic solution to Herbert Simon's 1955 model for time-evolving novelty functions. This has far-reaching consequences: Simon's is a pre-cursor model for Barabasi's 1999 preferential attachment model for growing social networks, and our general abstraction of it more considers attachment to be a form of link selection. We show that any system which can be modeled as instances of types---i.e., occurrence data (frequencies)---can be generatively modeled (and simulated) from a distributional perspective with an exceptionally high-degree of accuracy.
TRACER: A Framework for Facilitating Accurate and Interpretable Analytics for High Stakes Applications
Mar 24, 2020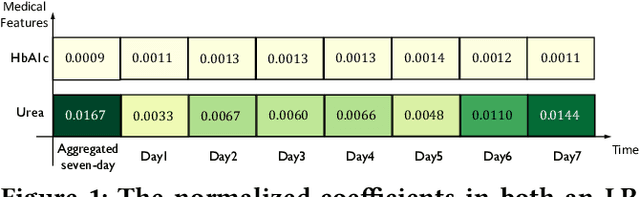
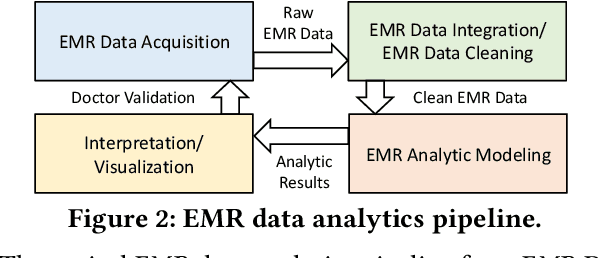
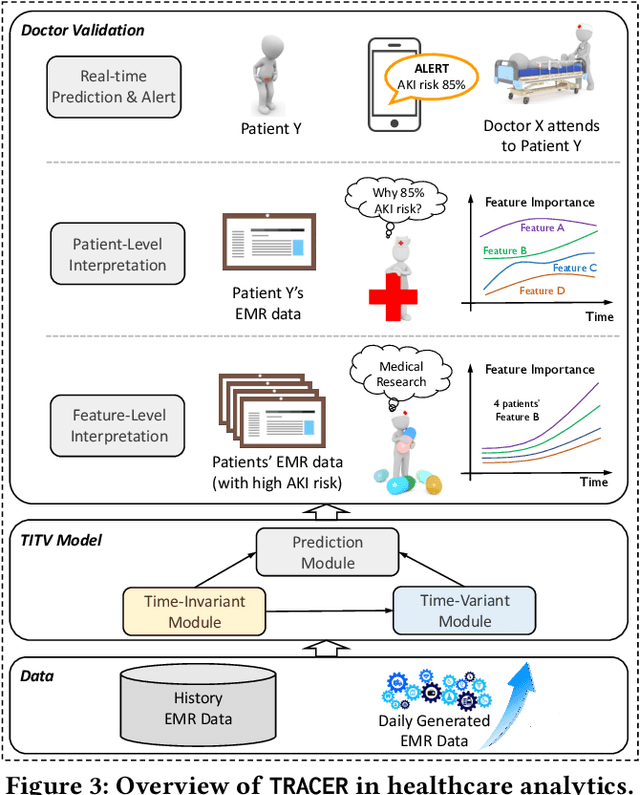
In high stakes applications such as healthcare and finance analytics, the interpretability of predictive models is required and necessary for domain practitioners to trust the predictions. Traditional machine learning models, e.g., logistic regression (LR), are easy to interpret in nature. However, many of these models aggregate time-series data without considering the temporal correlations and variations. Therefore, their performance cannot match up to recurrent neural network (RNN) based models, which are nonetheless difficult to interpret. In this paper, we propose a general framework TRACER to facilitate accurate and interpretable predictions, with a novel model TITV devised for healthcare analytics and other high stakes applications such as financial investment and risk management. Different from LR and other existing RNN-based models, TITV is designed to capture both the time-invariant and the time-variant feature importance using a feature-wise transformation subnetwork and a self-attention subnetwork, for the feature influence shared over the entire time series and the time-related importance respectively. Healthcare analytics is adopted as a driving use case, and we note that the proposed TRACER is also applicable to other domains, e.g., fintech. We evaluate the accuracy of TRACER extensively in two real-world hospital datasets, and our doctors/clinicians further validate the interpretability of TRACER in both the patient level and the feature level. Besides, TRACER is also validated in a high stakes financial application and a critical temperature forecasting application. The experimental results confirm that TRACER facilitates both accurate and interpretable analytics for high stakes applications.
Coupled regularized sample covariance matrix estimator for multiple classes
Nov 09, 2020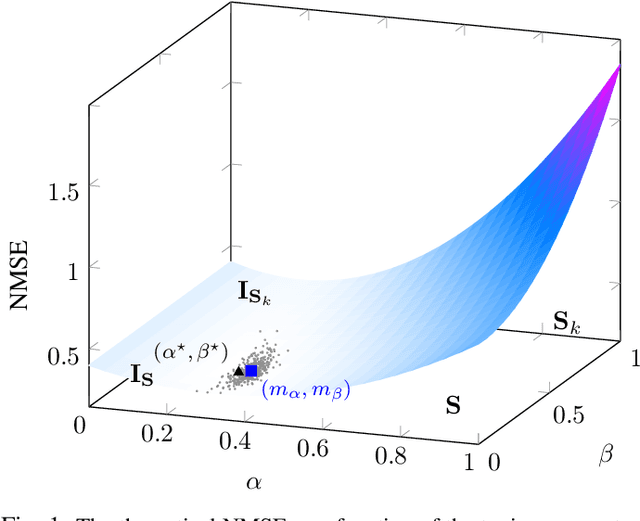
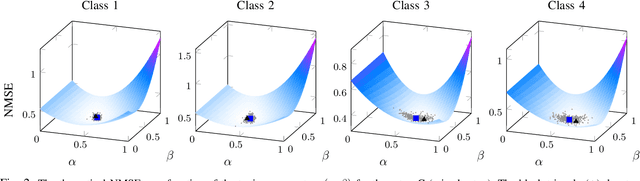
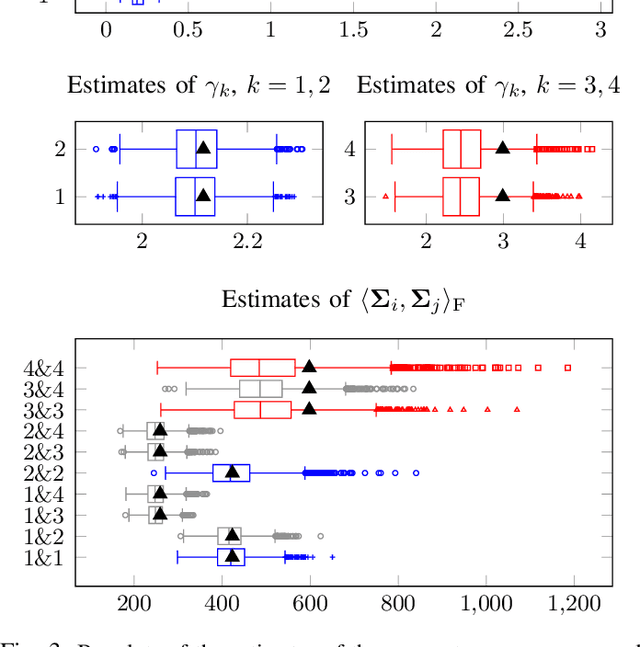
The estimation of covariance matrices of multiple classes with limited training data is a difficult problem. The sample covariance matrix (SCM) is known to perform poorly when the number of variables is large compared to the available number of samples. In order to reduce the mean squared error (MSE) of the SCM, regularized (shrinkage) SCM estimators are often used. In this work, we consider regularized SCM (RSCM) estimators for multiclass problems that couple together two different target matrices for regularization: the pooled (average) SCM of the classes and the scaled identity matrix. Regularization toward the pooled SCM is beneficial when the population covariances are similar, whereas regularization toward the identity matrix guarantees that the estimators are positive definite. We derive the MSE optimal tuning parameters for the estimators as well as propose a method for their estimation under the assumption that the class populations follow (unspecified) elliptical distributions with finite fourth-order moments. The MSE performance of the proposed coupled RSCMs are evaluated with simulations and in a regularized discriminant analysis (RDA) classification set-up on real data. The results based on three different real data sets indicate comparable performance to cross-validation but with a significant speed-up in computation time.