 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Self-Explaining Structures Improve NLP Models
Dec 09, 2020
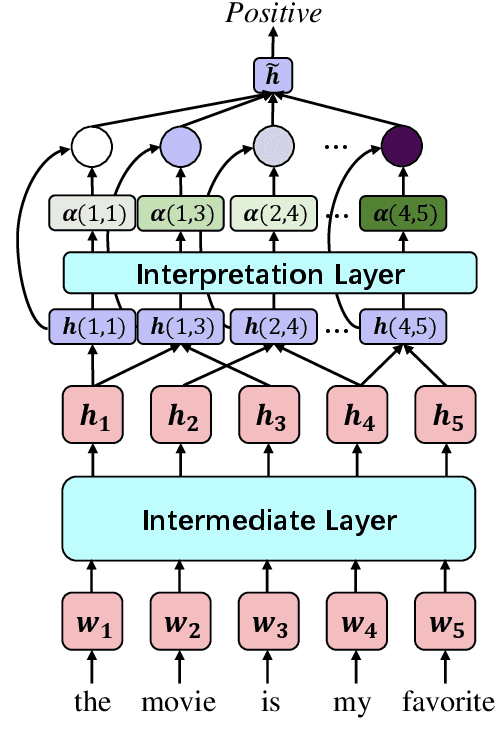
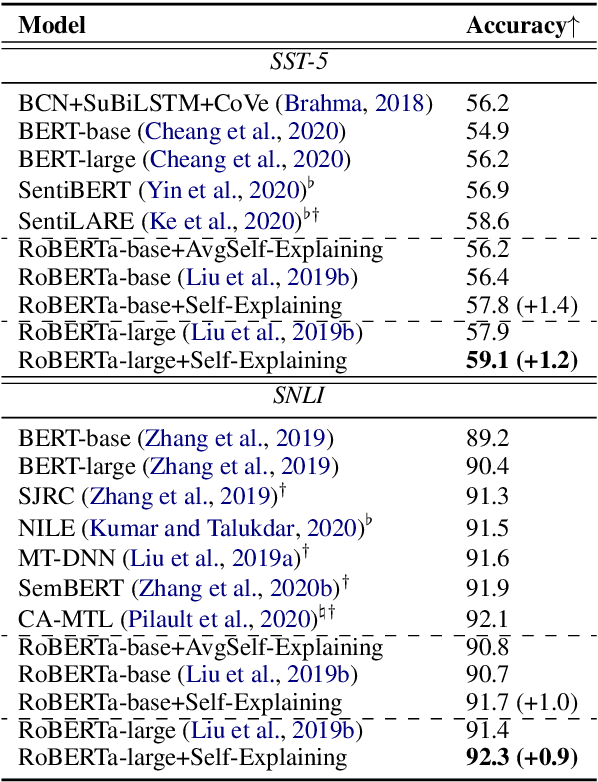

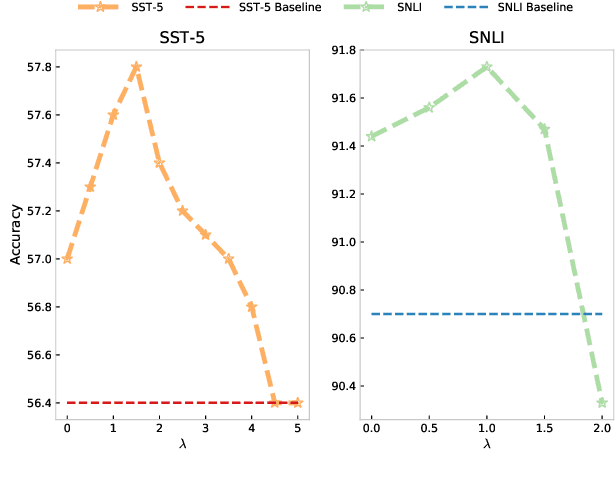
Existing approaches to explaining deep learning models in NLP usually suffer from two major drawbacks: (1) the main model and the explaining model are decoupled: an additional probing or surrogate model is used to interpret an existing model, and thus existing explaining tools are not self-explainable; (2) the probing model is only able to explain a model's predictions by operating on low-level features by computing saliency scores for individual words but are clumsy at high-level text units such as phrases, sentences, or paragraphs. To deal with these two issues, in this paper, we propose a simple yet general and effective self-explaining framework for deep learning models in NLP. The key point of the proposed framework is to put an additional layer, as is called by the interpretation layer, on top of any existing NLP model. This layer aggregates the information for each text span, which is then associated with a specific weight, and their weighted combination is fed to the softmax function for the final prediction. The proposed model comes with the following merits: (1) span weights make the model self-explainable and do not require an additional probing model for interpretation; (2) the proposed model is general and can be adapted to any existing deep learning structures in NLP; (3) the weight associated with each text span provides direct importance scores for higher-level text units such as phrases and sentences. We for the first time show that interpretability does not come at the cost of performance: a neural model of self-explaining features obtains better performances than its counterpart without the self-explaining nature, achieving a new SOTA performance of 59.1 on SST-5 and a new SOTA performance of 92.3 on SNLI.
Multi-step Estimation for Gradient-based Meta-learning
Jun 08, 2020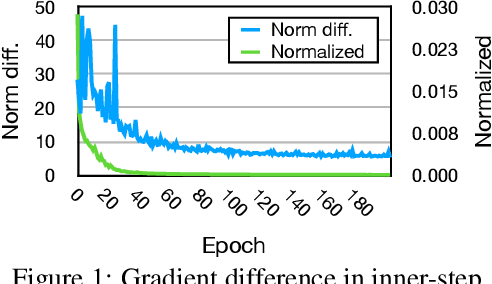

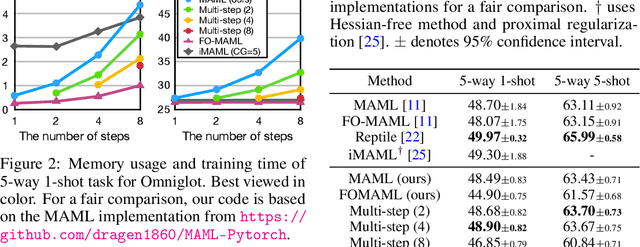

Gradient-based meta-learning approaches have been successful in few-shot learning, transfer learning, and a wide range of other domains. Despite its efficacy and simplicity, the burden of calculating the Hessian matrix with large memory footprints is the critical challenge in large-scale applications. To tackle this issue, we propose a simple yet straightforward method to reduce the cost by reusing the same gradient in a window of inner steps. We describe the dynamics of the multi-step estimation in the Lagrangian formalism and discuss how to reduce evaluating second-order derivatives estimating the dynamics. To validate our method, we experiment on meta-transfer learning and few-shot learning tasks for multiple settings. The experiment on meta-transfer emphasizes the applicability of training meta-networks, where other approximations are limited. For few-shot learning, we evaluate time and memory complexities compared with popular baselines. We show that our method significantly reduces training time and memory usage, maintaining competitive accuracies, or even outperforming in some cases.
Enabling certification of verification-agnostic networks via memory-efficient semidefinite programming
Oct 22, 2020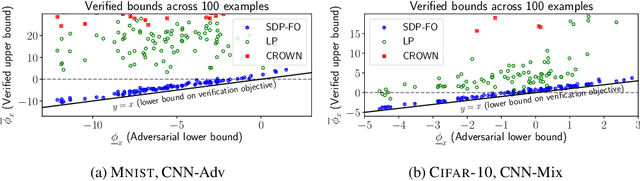
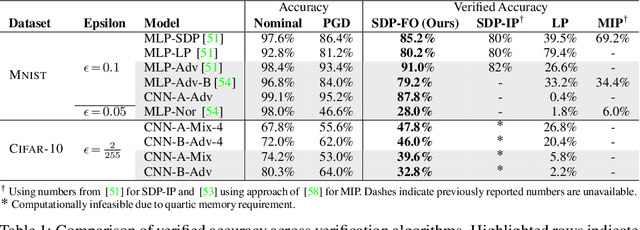
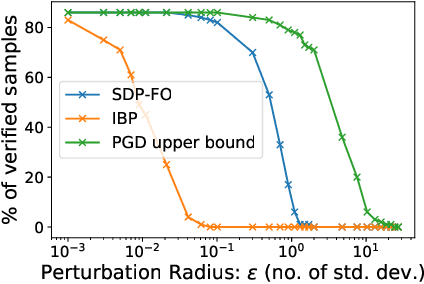

Convex relaxations have emerged as a promising approach for verifying desirable properties of neural networks like robustness to adversarial perturbations. Widely used Linear Programming (LP) relaxations only work well when networks are trained to facilitate verification. This precludes applications that involve verification-agnostic networks, i.e., networks not specially trained for verification. On the other hand, semidefinite programming (SDP) relaxations have successfully be applied to verification-agnostic networks, but do not currently scale beyond small networks due to poor time and space asymptotics. In this work, we propose a first-order dual SDP algorithm that (1) requires memory only linear in the total number of network activations, (2) only requires a fixed number of forward/backward passes through the network per iteration. By exploiting iterative eigenvector methods, we express all solver operations in terms of forward and backward passes through the network, enabling efficient use of hardware like GPUs/TPUs. For two verification-agnostic networks on MNIST and CIFAR-10, we significantly improve L-inf verified robust accuracy from 1% to 88% and 6% to 40% respectively. We also demonstrate tight verification of a quadratic stability specification for the decoder of a variational autoencoder.
A Passive Navigation Planning Algorithm for Collision-free Control of Mobile Robots
Nov 01, 2020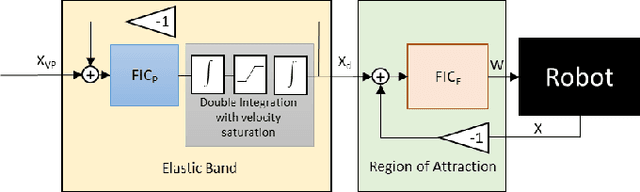
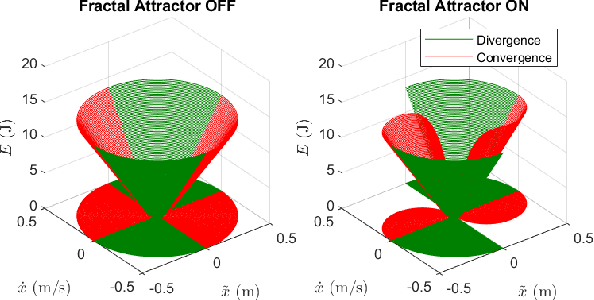
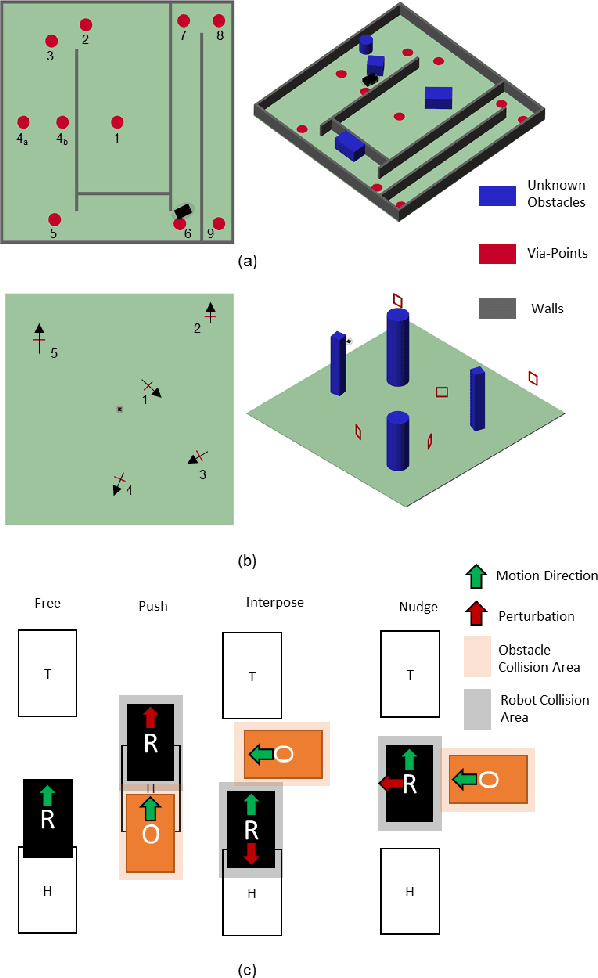
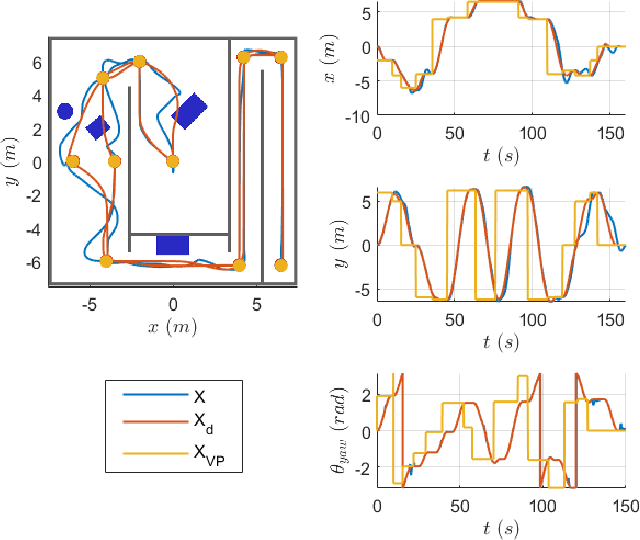
Path planning and collision avoidance are challenging in complex and highly variable environments due to the limited horizon of events. In literature, there are multiple model- and learning-based approaches that require significant computational resources to be effectively deployed and they may have limited generality. We propose a planning algorithm based on a globally stable passive controller that can plan smooth trajectories using limited computational resources in challenging environmental conditions. The architecture combines the recently proposed fractal impedance controller with elastic bands and regions of finite time invariance. As the method is based on an impedance controller, it can also be used directly as a force/torque controller. We validated our method in simulation to analyse the ability of interactive navigation in challenging concave domains via the issuing of via-points, and its robustness to low bandwidth feedback. A swarm simulation using 11 agents validated the scalability of the proposed method. We have performed hardware experiments on a holonomic wheeled platform validating smoothness and robustness of interaction with dynamic agents (i.e., humans and robots). The computational complexity of the proposed local planner enables deployment with low-power micro-controllers lowering the energy consumption compared to other methods that rely upon numeric optimisation.
Data-Driven Transient Stability Boundary Generation for Online Security Monitoring
Apr 03, 2020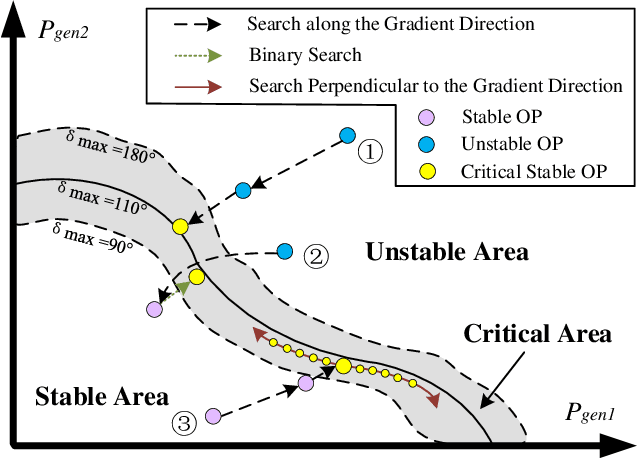
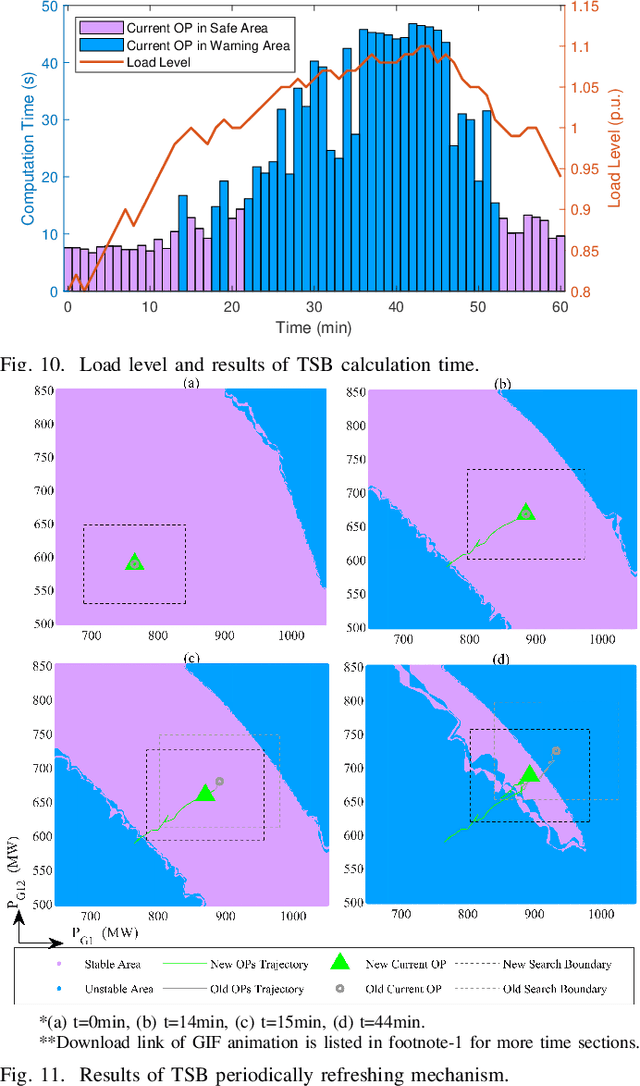
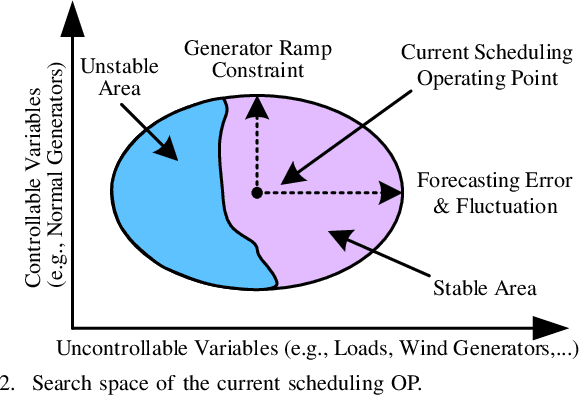
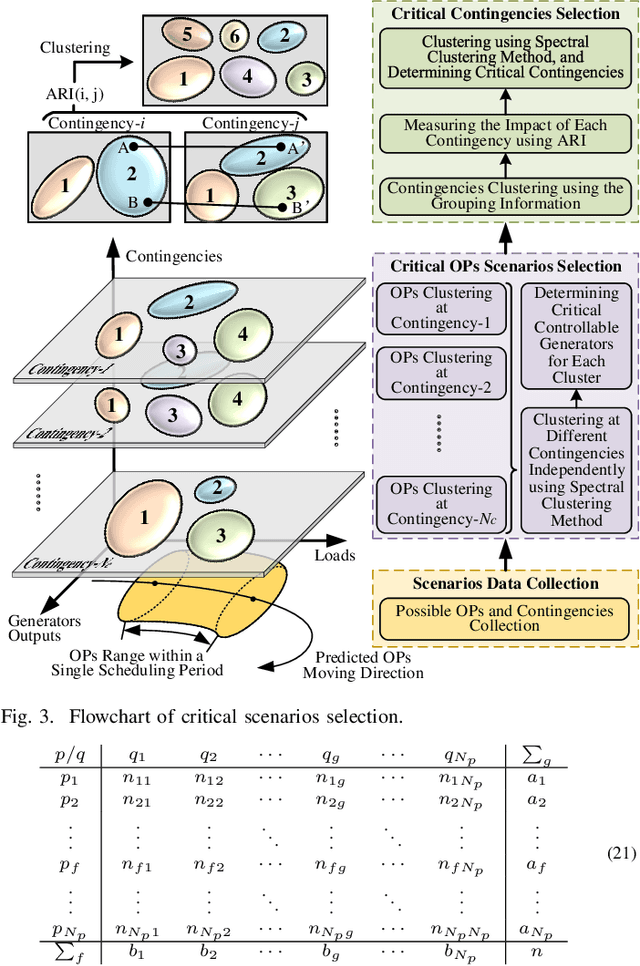
Transient stability boundary (TSB) is an important tool in power system online security monitoring, but practically it suffers from high computational burden using state-of-the-art methods, such as time-domain simulation (TDS), with numerous scenarios taken into account (e.g., operating points (OPs) and N-1 contingencies). The purpose of this work is to establish a data-driven framework to generate sufficient critical samples close to the boundary within a limited time, covering all critical scenarios in current OP. Therefore, accurate TSB can be periodically refreshed by tracking current OP in time. The idea is to develop a search strategy to obtain more data samples near the stability boundary, while traverse the rest part with fewer samples. To achieve this goal, a specially designed transient index sensitivity based search strategy and critical scenarios selection mechanism are proposed, in order to find out the most representative scenarios and periodically update TSB for online monitoring. Two case studies validate effectiveness of the proposed method.
A kernel test for quasi-independence
Nov 17, 2020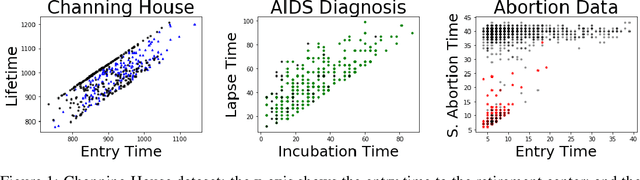
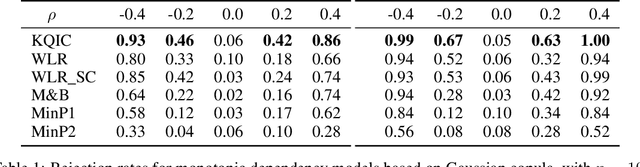
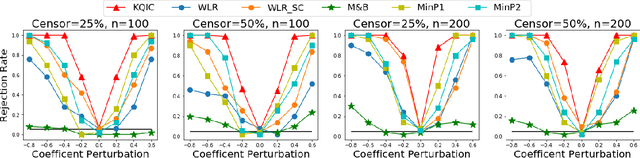

We consider settings in which the data of interest correspond to pairs of ordered times, e.g, the birth times of the first and second child, the times at which a new user creates an account and makes the first purchase on a website, and the entry and survival times of patients in a clinical trial. In these settings, the two times are not independent (the second occurs after the first), yet it is still of interest to determine whether there exists significant dependence {\em beyond} their ordering in time. We refer to this notion as "quasi-(in)dependence". For instance, in a clinical trial, to avoid biased selection, we might wish to verify that recruitment times are quasi-independent of survival times, where dependencies might arise due to seasonal effects. In this paper, we propose a nonparametric statistical test of quasi-independence. Our test considers a potentially infinite space of alternatives, making it suitable for complex data where the nature of the possible quasi-dependence is not known in advance. Standard parametric approaches are recovered as special cases, such as the classical conditional Kendall's tau, and log-rank tests. The tests apply in the right-censored setting: an essential feature in clinical trials, where patients can withdraw from the study. We provide an asymptotic analysis of our test-statistic, and demonstrate in experiments that our test obtains better power than existing approaches, while being more computationally efficient.
Explainable Deep Reinforcement Learning for UAV Autonomous Navigation
Sep 30, 2020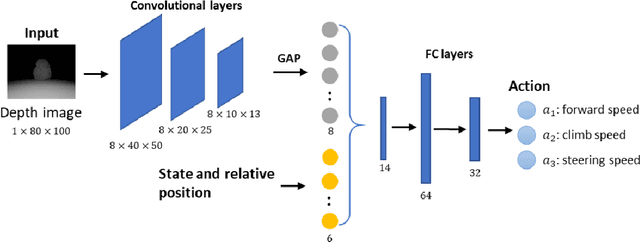


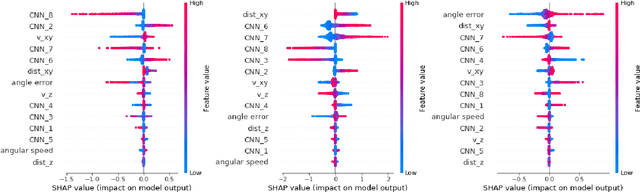
Modern deep reinforcement learning plays an important role to solve a wide range of complex decision-making tasks. However, due to the use of deep neural networks, the trained models are lacking transparency which causes distrust from their user and hard to be used in the critical field such as self-driving car and unmanned aerial vehicles. In this paper, an explainable deep reinforcement learning method is proposed to deal with the multirotor obstacle avoidance and navigation problem. Both visual and textual explanation is provided to make the trained agent more transparency and comprehensible for humans. Our model can provide real-time decision explanation for non-expert users. Also, some global explanation results are provided for experts to diagnose the learned policy. Our method is validated in the simulation environment. The simulation result shows our proposed method can get useful explanations to increase the user's trust to the network and also improve the network performance.
A Fleet Learning Architecture for Enhanced Behavior Predictions during Challenging External Conditions
Sep 24, 2020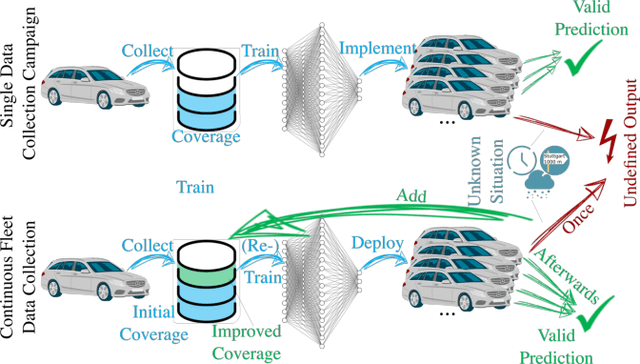
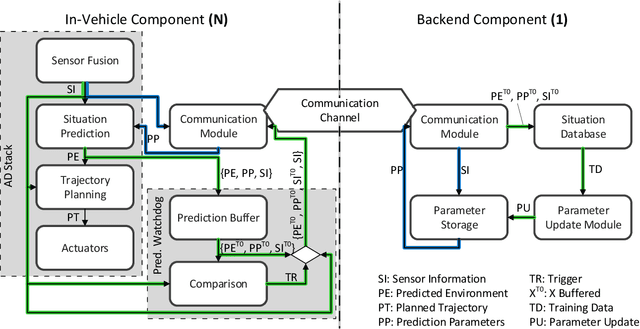
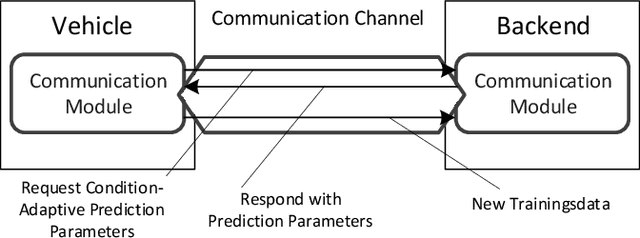
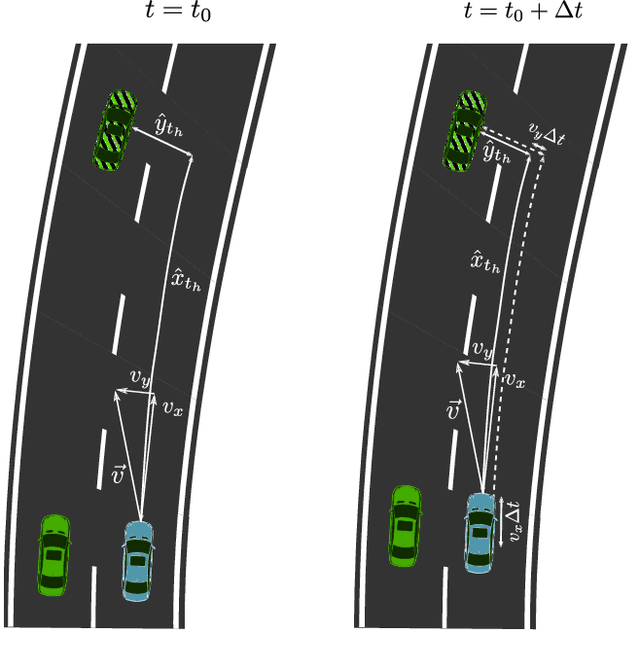
Already today, driver assistance systems help to make daily traffic more comfortable and safer. However, there are still situations that are quite rare but are hard to handle at the same time. In order to cope with these situations and to bridge the gap towards fully automated driving, it becomes necessary to not only collect enormous amounts of data but rather the right ones. This data can be used to develop and validate the systems through machine learning and simulation pipelines. Along this line this paper presents a fleet learning-based architecture that enables continuous improvements of systems predicting the movement of surrounding traffic participants. Moreover, the presented architecture is applied to a testing vehicle in order to prove the fundamental feasibility of the system. Finally, it is shown that the system collects meaningful data which are helpful to improve the underlying prediction systems.
Efficient implementations of echo state network cross-validation
Jun 19, 2020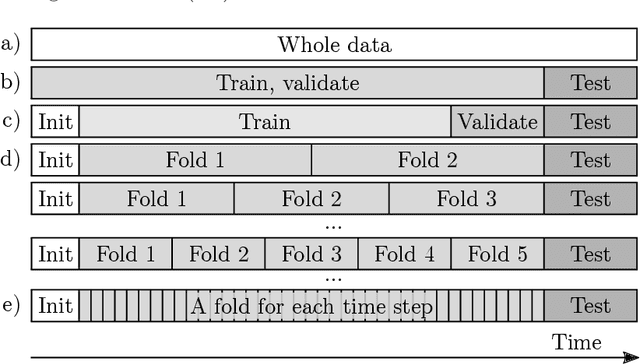
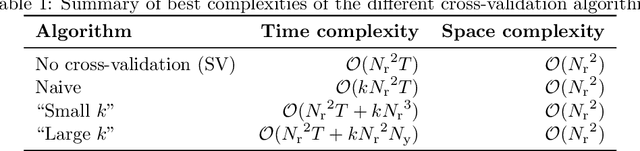
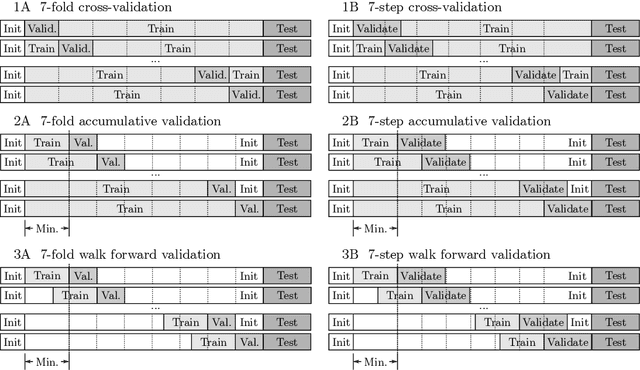

Background/introduction: Cross-validation is still uncommon in time series modeling. Echo State Networks (ESNs), as a prime example of Reservoir Computing (RC) models, are known for their fast and precise one-shot learning, that often benefit from good hyper-parameter tuning. This makes them ideal to change the status quo. Methods: We suggest several schemes for cross-validating ESNs and introduce an efficient algorithm for implementing them. This algorithm is presented as two levels of optimizations of doing $k$-fold cross-validation. Training an RC model typically consists of two stages: (i) running the reservoir with the data and (ii) computing the optimal readouts. The first level of our proposed optimization addresses the most computationally expensive part (i) and makes it remain constant irrespective of $k$. It dramatically reduces reservoir computations in any type of RC system and is enough if $k$ is small. The second level of optimization also makes the (ii) part remain constant irrespective of large $k$, as long as the dimension of the output is low. We discuss when the proposed validation schemes for ESNs could be beneficial, three options for producing the final model and empirically investigate them on six different real-world datasets, as well as do empirical computation time experiments. We provide the code in an online repository. Results: Proposed cross-validation schemes give better and more stable test performance in all the six different real-world datasets, three task types. Empirical run times confirm our complexity analysis. Conclusions: In most situations $k$-fold cross-validation of ESNs and many other RC models can be done for virtually the same time complexity as a simple single-split validation. Space complexity can also remain the same in all the cases. This enables cross-validation to become a standard practice in reservoir computing.
Incremental Processing in the Age of Non-Incremental Encoders: An Empirical Assessment of Bidirectional Models for Incremental NLU
Oct 11, 2020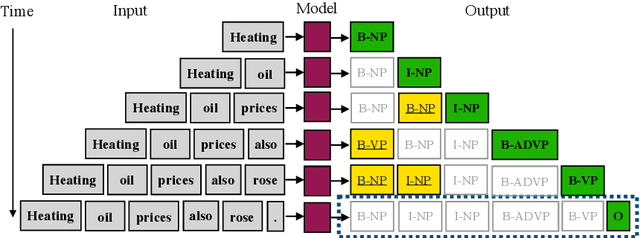
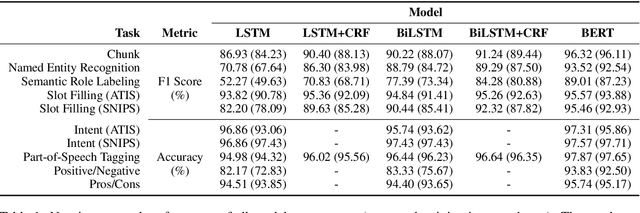
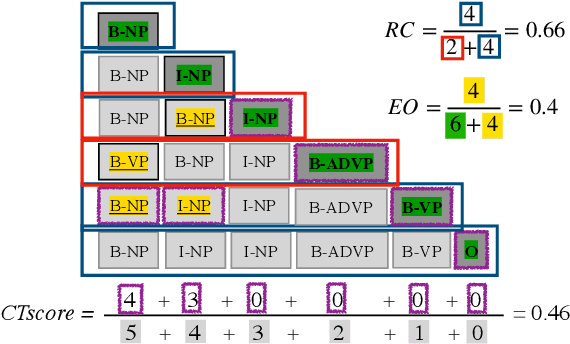
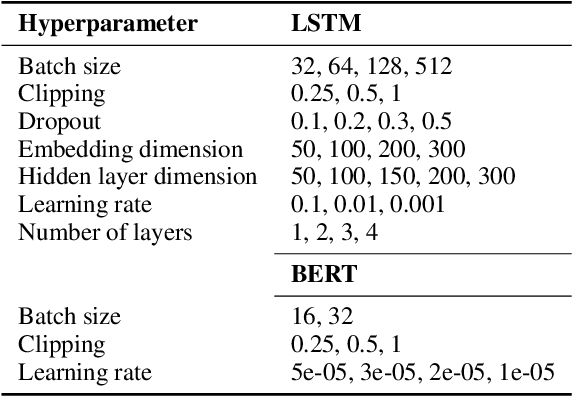
While humans process language incrementally, the best language encoders currently used in NLP do not. Both bidirectional LSTMs and Transformers assume that the sequence that is to be encoded is available in full, to be processed either forwards and backwards (BiLSTMs) or as a whole (Transformers). We investigate how they behave under incremental interfaces, when partial output must be provided based on partial input seen up to a certain time step, which may happen in interactive systems. We test five models on various NLU datasets and compare their performance using three incremental evaluation metrics. The results support the possibility of using bidirectional encoders in incremental mode while retaining most of their non-incremental quality. The "omni-directional" BERT model, which achieves better non-incremental performance, is impacted more by the incremental access. This can be alleviated by adapting the training regime (truncated training), or the testing procedure, by delaying the output until some right context is available or by incorporating hypothetical right contexts generated by a language model like GPT-2.