 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Ultra-low power on-chip learning of speech commands with phase-change memories
Oct 21, 2020
Embedding artificial intelligence at the edge (edge-AI) is an elegant solution to tackle the power and latency issues in the rapidly expanding Internet of Things. As edge devices typically spend most of their time in sleep mode and only wake-up infrequently to collect and process sensor data, non-volatile in-memory computing (NVIMC) is a promising approach to design the next generation of edge-AI devices. Recently, we proposed an NVIMC-based neuromorphic accelerator using the phase change memories (PCMs), which we call as Raven. In this work, we demonstrate the ultra-low-power on-chip training and inference of speech commands using Raven. We showed that Raven can be trained on-chip with power consumption as low as 30~uW, which is suitable for edge applications. Furthermore, we showed that at iso-accuracies, Raven needs 70.36x and 269.23x less number of computations to be performed than a deep neural network (DNN) during inference and training, respectively. Owing to such low power and computational requirements, Raven provides a promising pathway towards ultra-low-power training and inference at the edge.
Learning Efficient Constraint Graph Sampling for Robotic Sequential Manipulation
Nov 09, 2020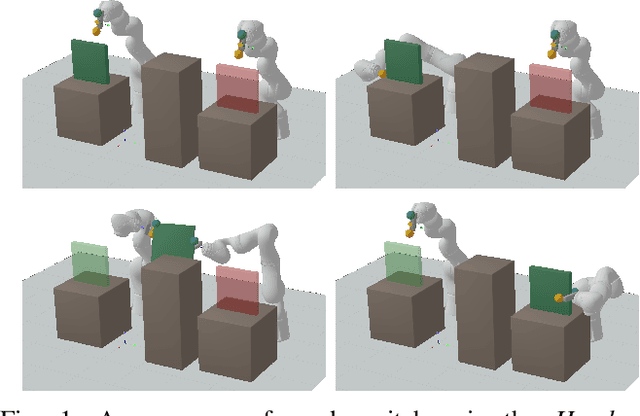
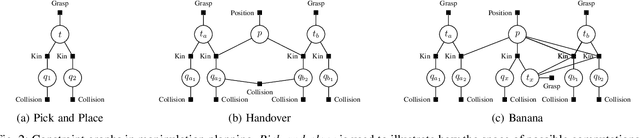
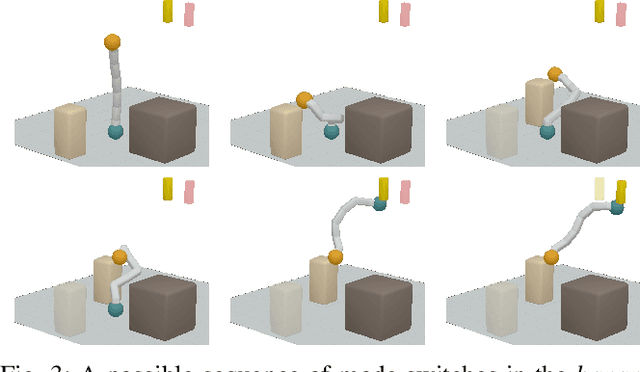
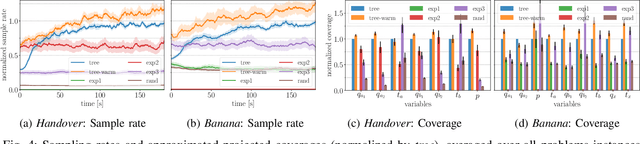
Efficient sampling from constraint manifolds, and thereby generating a diverse set of solutions of feasibility problems, is a fundamental challenge. We consider the case where a problem is factored, that is, the underlying nonlinear mathematical program is decomposed into differentiable equality and inequality constraints, each of which depends only on some variables. Such problems are at the core of efficient and robust sequential robot manipulation planning. Naive sequential conditional sampling of individual variables, as well as fully joint sampling of all variables at once (e.g., leveraging optimization methods), can be highly inefficient and non-robust. We propose a novel framework to learn how to break the overall problem into smaller sequential sampling problems. Specifically, we leverage Monte-Carlo Tree Search to learn which variable subsets should be assigned in which sequential order, in order to minimize the computation time to generate full samples. This strategy allows us to efficiently compute a set of diverse valid robot configurations for mode-switches within sequential manipulation tasks, which are waypoints for subsequent trajectory optimization or sampling-based motion planning algorithms. We show that the learning method quickly converges to the best sampling strategy for a given problem, and outperforms user-defined orderings and joint optimization, while also providing a higher sample diversity. Video: https://youtu.be/xWAjBGACZhs
Introduction to Core-sets: an Updated Survey
Nov 18, 2020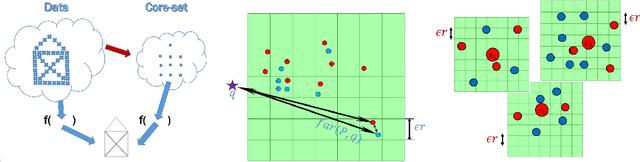
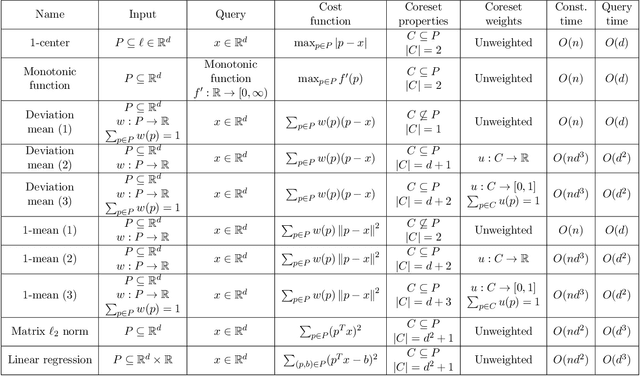
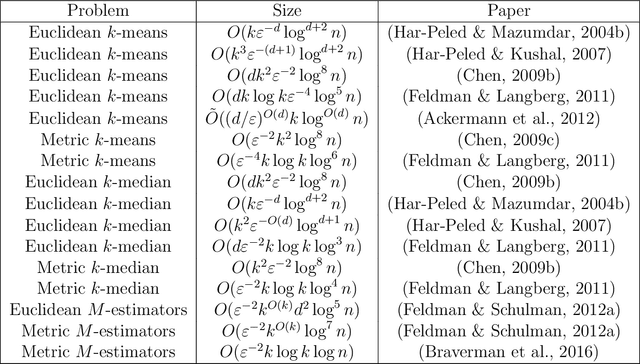
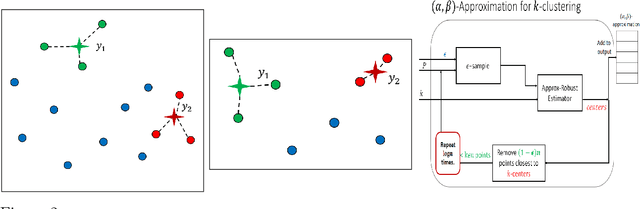
In optimization or machine learning problems we are given a set of items, usually points in some metric space, and the goal is to minimize or maximize an objective function over some space of candidate solutions. For example, in clustering problems, the input is a set of points in some metric space, and a common goal is to compute a set of centers in some other space (points, lines) that will minimize the sum of distances to these points. In database queries, we may need to compute such a some for a specific query set of $k$ centers. However, traditional algorithms cannot handle modern systems that require parallel real-time computations of infinite distributed streams from sensors such as GPS, audio or video that arrive to a cloud, or networks of weaker devices such as smartphones or robots. Core-set is a "small data" summarization of the input "big data", where every possible query has approximately the same answer on both data sets. Generic techniques enable efficient coreset \changed{maintenance} of streaming, distributed and dynamic data. Traditional algorithms can then be applied on these coresets to maintain the approximated optimal solutions. The challenge is to design coresets with provable tradeoff between their size and approximation error. This survey summarizes such constructions in a retrospective way, that aims to unified and simplify the state-of-the-art.
Testing match-3 video games with Deep Reinforcement Learning
Jun 30, 2020

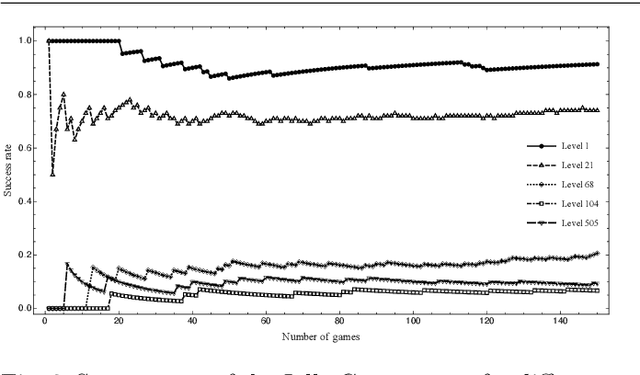
Testing a video game is a critical step for the production process and requires a great effort in terms of time and resources spent. Some software houses are trying to use the artificial intelligence to reduce the need of human resources using systems able to replace a human agent. We study the possibility to use the Deep Reinforcement Learning to automate the testing process in match-3 video games and suggest to approach the problem in the framework of a Dueling Deep Q-Network paradigm. We test this kind of network on the Jelly Juice game, a match-3 video game developed by the redBit Games. The network extracts the essential information from the game environment and infers the next move. We compare the results with the random player performance, finding that the network shows a highest success rate. The results are in most cases similar with those obtained by real users, and the network also succeeds in learning over time the different features that distinguish the game levels and adapts its strategy to the increasing difficulties.
Can We Enable the Drone to be a Filmmaker?
Oct 21, 2020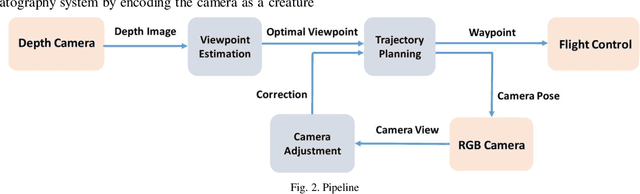
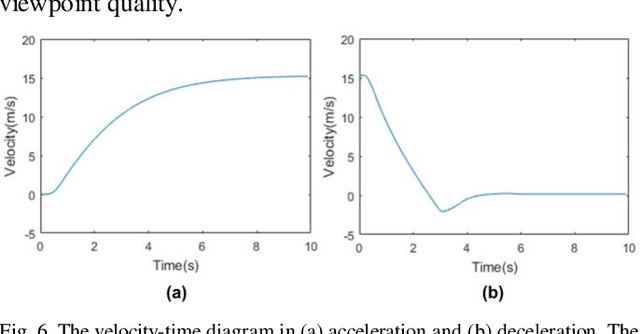
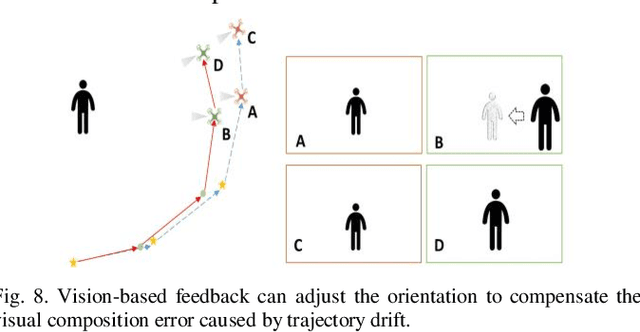

Drones are enabling new forms of cinematography. However, quadrotor cinematography requires accurate comprehension of the scene, technical skill of flying, artistic skill of composition and simultaneous realization of all the requirements in real time. These requirements could pose real challenge to drone amateurs because unsuitable camera viewpoint and motion could result in unpleasing visual composition and affect the target's visibility. In this paper, we propose a novel autonomous drone camera system which captures action scenes using proper camera viewpoint and motion. The key novelty is that our system can dynamically generate smooth drone camera trajectory associated with human movement while obeying visual composition principles. We evaluate the performance of our cinematography system on simulation and real scenario. The experimental results demonstrate that our system can capture more expressive video footage of human action than that of the state-of-the-art drone camera system. To the best of our knowledge, this is the first cinematography system that enables people to leverage the mobility of quadrotor to autonomously capture high-quality footage of action scene based on subject's movements.
A Clustering-Based Method for Automatic Educational Video Recommendation Using Deep Face-Features of Lecturers
Oct 09, 2020
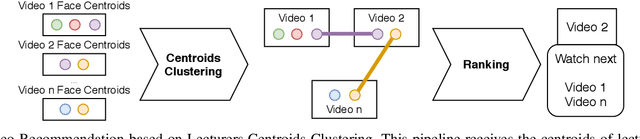

Discovering and accessing specific content within educational video bases is a challenging task, mainly because of the abundance of video content and its diversity. Recommender systems are often used to enhance the ability to find and select content. But, recommendation mechanisms, especially those based on textual information, exhibit some limitations, such as being error-prone to manually created keywords or due to imprecise speech recognition. This paper presents a method for generating educational video recommendation using deep face-features of lecturers without identifying them. More precisely, we use an unsupervised face clustering mechanism to create relations among the videos based on the lecturer's presence. Then, for a selected educational video taken as a reference, we recommend the ones where the presence of the same lecturers is detected. Moreover, we rank these recommended videos based on the amount of time the referenced lecturers were present. For this task, we achieved a mAP value of 99.165%.
Faster Biological Gradient Descent Learning
Sep 27, 2020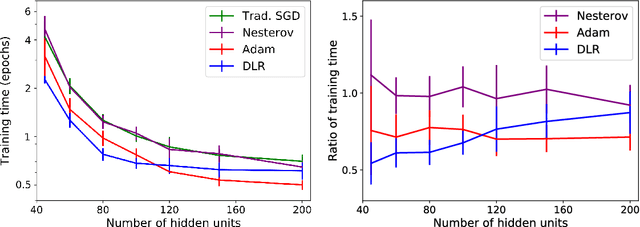
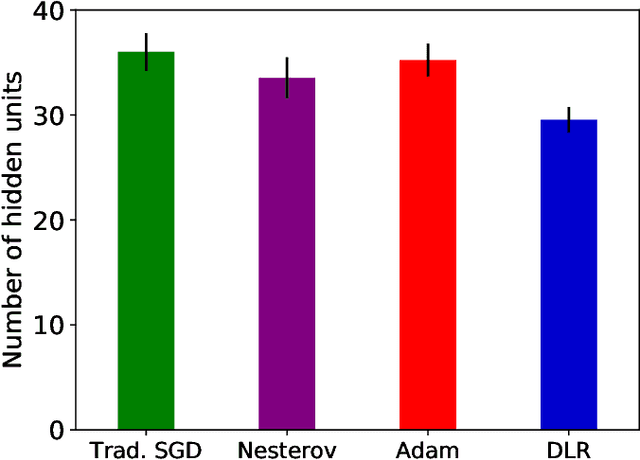
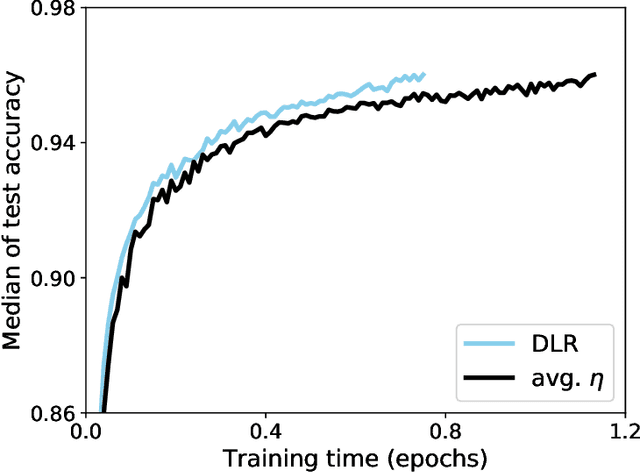
Back-propagation is a popular machine learning algorithm that uses gradient descent in training neural networks for supervised learning, but can be very slow. A number of algorithms have been developed to speed up convergence and improve robustness of the learning. However, they are complicated to implement biologically as they require information from previous updates. Inspired by synaptic competition in biology, we have come up with a simple and local gradient descent optimization algorithm that can reduce training time, with no demand on past details. Our algorithm, named dynamic learning rate (DLR), works similarly to the traditional gradient descent used in back-propagation, except that instead of having a uniform learning rate across all synapses, the learning rate depends on the current neuronal connection weights. Our algorithm is found to speed up learning, particularly for small networks.
Artificial Intelligence & Cooperation
Dec 10, 2020The rise of Artificial Intelligence (AI) will bring with it an ever-increasing willingness to cede decision-making to machines. But rather than just giving machines the power to make decisions that affect us, we need ways to work cooperatively with AI systems. There is a vital need for research in "AI and Cooperation" that seeks to understand the ways in which systems of AIs and systems of AIs with people can engender cooperative behavior. Trust in AI is also key: trust that is intrinsic and trust that can only be earned over time. Here we use the term "AI" in its broadest sense, as employed by the recent 20-Year Community Roadmap for AI Research (Gil and Selman, 2019), including but certainly not limited to, recent advances in deep learning. With success, cooperation between humans and AIs can build society just as human-human cooperation has. Whether coming from an intrinsic willingness to be helpful, or driven through self-interest, human societies have grown strong and the human species has found success through cooperation. We cooperate "in the small" -- as family units, with neighbors, with co-workers, with strangers -- and "in the large" as a global community that seeks cooperative outcomes around questions of commerce, climate change, and disarmament. Cooperation has evolved in nature also, in cells and among animals. While many cases involving cooperation between humans and AIs will be asymmetric, with the human ultimately in control, AI systems are growing so complex that, even today, it is impossible for the human to fully comprehend their reasoning, recommendations, and actions when functioning simply as passive observers.
High-order Semantic Role Labeling
Oct 09, 2020
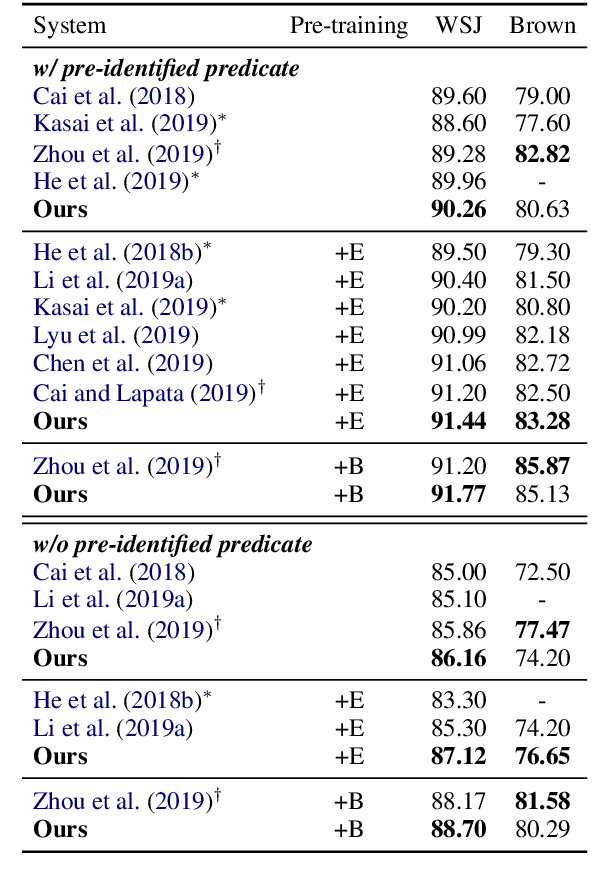
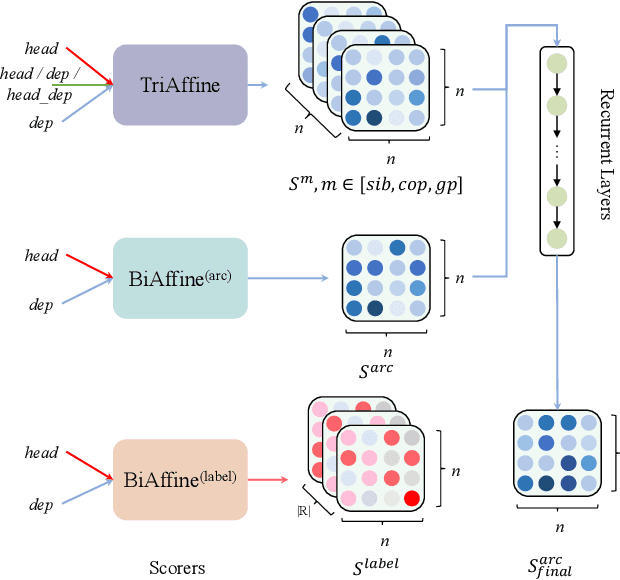
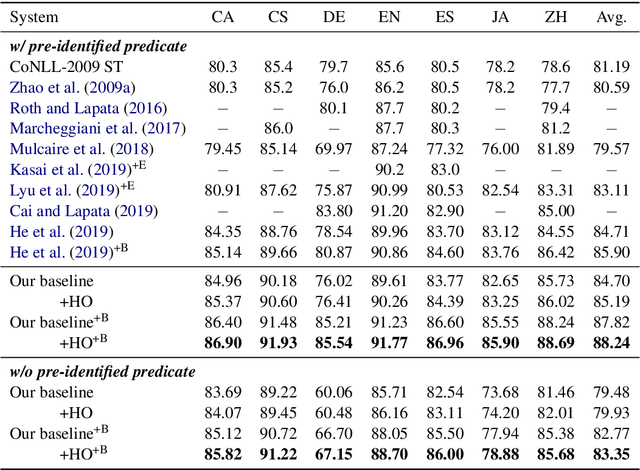
Semantic role labeling is primarily used to identify predicates, arguments, and their semantic relationships. Due to the limitations of modeling methods and the conditions of pre-identified predicates, previous work has focused on the relationships between predicates and arguments and the correlations between arguments at most, while the correlations between predicates have been neglected for a long time. High-order features and structure learning were very common in modeling such correlations before the neural network era. In this paper, we introduce a high-order graph structure for the neural semantic role labeling model, which enables the model to explicitly consider not only the isolated predicate-argument pairs but also the interaction between the predicate-argument pairs. Experimental results on 7 languages of the CoNLL-2009 benchmark show that the high-order structural learning techniques are beneficial to the strong performing SRL models and further boost our baseline to achieve new state-of-the-art results.
Find it if You Can: End-to-End Adversarial Erasing for Weakly-Supervised Semantic Segmentation
Nov 09, 2020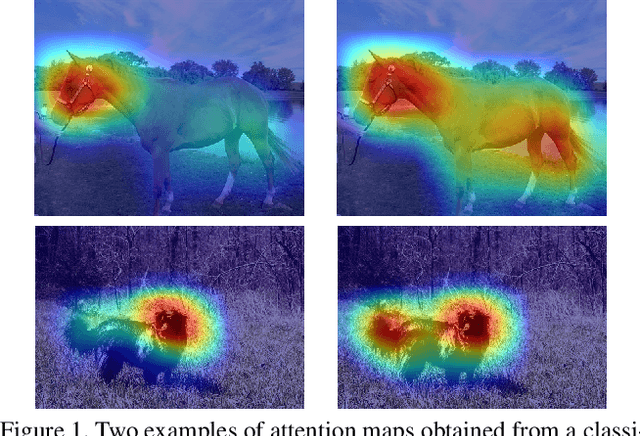
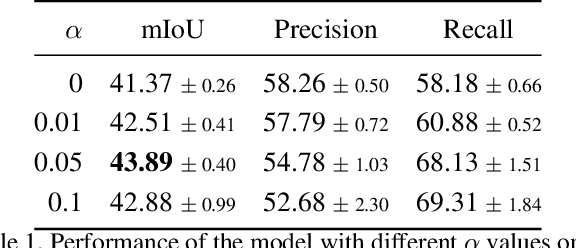


Semantic segmentation is a task that traditionally requires a large dataset of pixel-level ground truth labels, which is time-consuming and expensive to obtain. Recent advancements in the weakly-supervised setting show that reasonable performance can be obtained by using only image-level labels. Classification is often used as a proxy task to train a deep neural network from which attention maps are extracted. However, the classification task needs only the minimum evidence to make predictions, hence it focuses on the most discriminative object regions. To overcome this problem, we propose a novel formulation of adversarial erasing of the attention maps. In contrast to previous adversarial erasing methods, we optimize two networks with opposing loss functions, which eliminates the requirement of certain suboptimal strategies; for instance, having multiple training steps that complicate the training process or a weight sharing policy between networks operating on different distributions that might be suboptimal for performance. The proposed solution does not require saliency masks, instead it uses a regularization loss to prevent the attention maps from spreading to less discriminative object regions. Our experiments on the Pascal VOC dataset demonstrate that our adversarial approach increases segmentation performance by 2.1 mIoU compared to our baseline and by 1.0 mIoU compared to previous adversarial erasing approaches.