 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Discrete solution pools and noise-contrastive estimation for predict-and-optimize
Nov 10, 2020
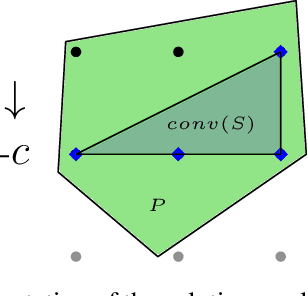


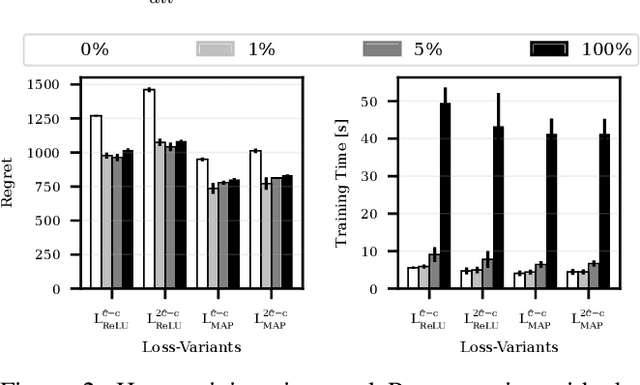
Numerous real-life decision-making processes involve solving a combinatorial optimization problem with uncertain input that can be estimated from historic data. There is a growing interest in decision-focused learning methods, where the loss function used for learning to predict the uncertain input uses the outcome of solving the combinatorial problem over a set of predictions. Different surrogate loss functions have been identified, often using a continuous approximation of the combinatorial problem. However, a key bottleneck is that to compute the loss, one has to solve the combinatorial optimisation problem for each training instance in each epoch, which is computationally expensive even in the case of continuous approximations. We propose a different solver-agnostic method for decision-focused learning, namely by considering a pool of feasible solutions as a discrete approximation of the full combinatorial problem. Solving is now trivial through a single pass over the solution pool. We design several variants of a noise-contrastive loss over the solution pool, which we substantiate theoretically and empirically. Furthermore, we show that by dynamically re-solving only a fraction of the training instances each epoch, our method performs on par with the state of the art, whilst drastically reducing the time spent solving, hence increasing the feasibility of predict-and-optimize for larger problems.
Accelerated Analog Neuromorphic Computing
Mar 26, 2020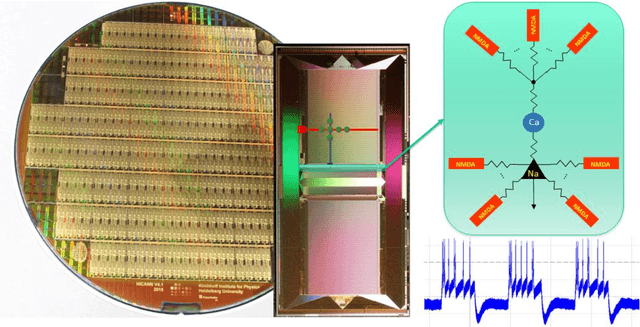
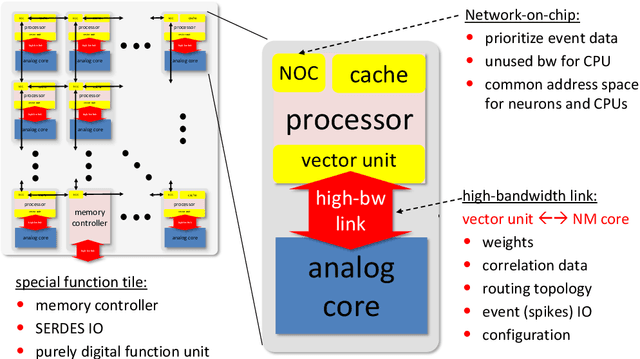
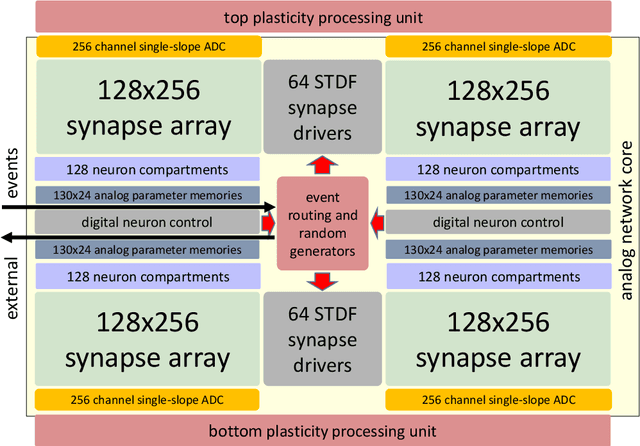

This paper presents the concepts behind the BrainScales (BSS) accelerated analog neuromorphic computing architecture. It describes the second-generation BrainScales-2 (BSS-2) version and its most recent in-silico realization, the HICANN-X Application Specific Integrated Circuit (ASIC), as it has been developed as part of the neuromorphic computing activities within the European Human Brain Project (HBP). While the first generation is implemented in an 180nm process, the second generation uses 65nm technology. This allows the integration of a digital plasticity processing unit, a highly-parallel micro processor specially built for the computational needs of learning in an accelerated analog neuromorphic systems. The presented architecture is based upon a continuous-time, analog, physical model implementation of neurons and synapses, resembling an analog neuromorphic accelerator attached to build-in digital compute cores. While the analog part emulates the spike-based dynamics of the neural network in continuous-time, the latter simulates biological processes happening on a slower time-scale, like structural and parameter changes. Compared to biological time-scales, the emulation is highly accelerated, i.e. all time-constants are several orders of magnitude smaller than in biology. Programmable ion channel emulation and inter-compartmental conductances allow the modeling of nonlinear dendrites, back-propagating action-potentials as well as NMDA and Calcium plateau potentials. To extend the usability of the analog accelerator, it also supports vector-matrix multiplication. Thereby, BSS-2 supports inference of deep convolutional networks as well as local-learning with complex ensembles of spiking neurons within the same substrate.
Fuzzy c-Shape: A new algorithm for clustering finite time series waveforms
Aug 03, 2016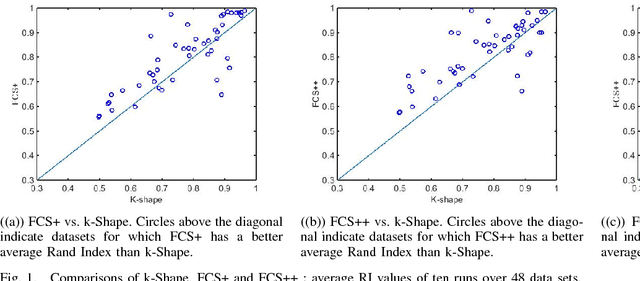
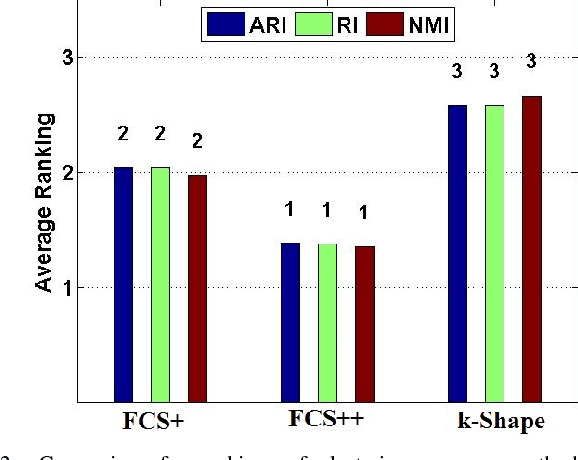
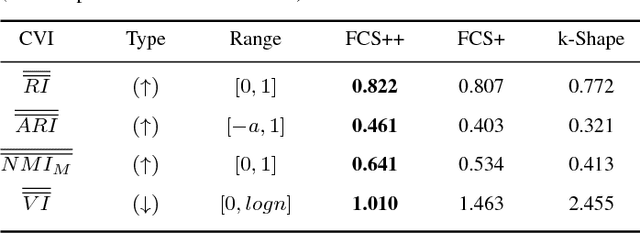
The existence of large volumes of time series data in many applications has motivated data miners to investigate specialized methods for mining time series data. Clustering is a popular data mining method due to its powerful exploratory nature and its usefulness as a preprocessing step for other data mining techniques. This article develops two novel clustering algorithms for time series data that are extensions of a crisp c-shapes algorithm. The two new algorithms are heuristic derivatives of fuzzy c-means (FCM). Fuzzy c-Shapes plus (FCS+) replaces the inner product norm in the FCM model with a shape-based distance function. Fuzzy c-Shapes double plus (FCS++) uses the shape-based distance, and also replaces the FCM cluster centers with shape-extracted prototypes. Numerical experiments on 48 real time series data sets show that the two new algorithms outperform state-of-the-art shape-based clustering algorithms in terms of accuracy and efficiency. Four external cluster validity indices (the Rand index, Adjusted Rand Index, Variation of Information, and Normalized Mutual Information) are used to match candidate partitions generated by each of the studied algorithms. All four indices agree that for these finite waveform data sets, FCS++ gives a small improvement over FCS+, and in turn, FCS+ is better than the original crisp c-shapes method. Finally, we apply two tests of statistical significance to the three algorithms. The Wilcoxon and Friedman statistics both rank the three algorithms in exactly the same way as the four cluster validity indices.
Deep-learning based down-scaling of summer monsoon rainfall data over Indian region
Nov 27, 2020
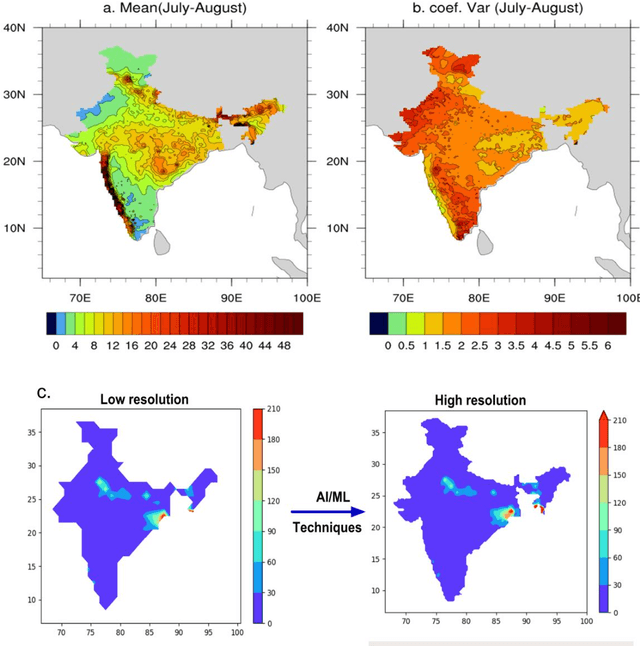
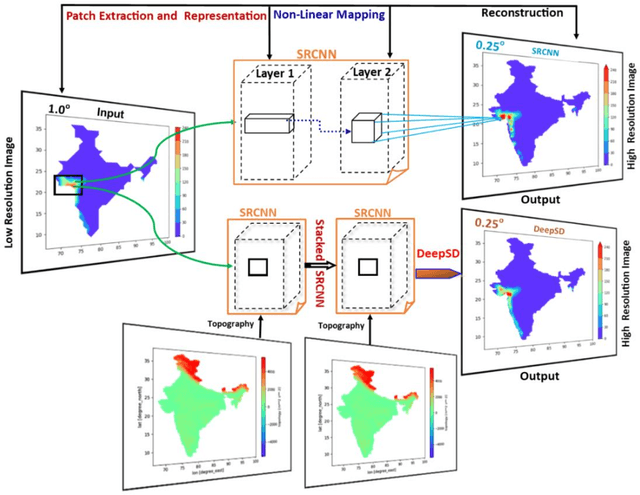
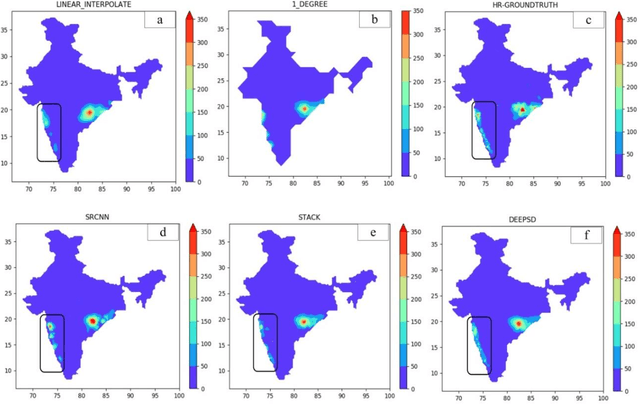
Downscaling is necessary to generate high-resolution observation data to validate the climate model forecast or monitor rainfall at the micro-regional level operationally. Dynamical and statistical downscaling models are often used to get information at high-resolution gridded data over larger domains. As rainfall variability is dependent on the complex Spatio-temporal process leading to non-linear or chaotic Spatio-temporal variations, no single downscaling method can be considered efficient enough. In data with complex topographies, quasi-periodicities, and non-linearities, deep Learning (DL) based methods provide an efficient solution in downscaling rainfall data for regional climate forecasting and real-time rainfall observation data at high spatial resolutions. In this work, we employed three deep learning-based algorithms derived from the super-resolution convolutional neural network (SRCNN) methods, to precipitation data, in particular, IMD and TRMM data to produce 4x-times high-resolution downscaled rainfall data during the summer monsoon season. Among the three algorithms, namely SRCNN, stacked SRCNN, and DeepSD, employed here, the best spatial distribution of rainfall amplitude and minimum root-mean-square error is produced by DeepSD based downscaling. Hence, the use of the DeepSD algorithm is advocated for future use. We found that spatial discontinuity in amplitude and intensity rainfall patterns is the main obstacle in the downscaling of precipitation. Furthermore, we applied these methods for model data postprocessing, in particular, ERA5 data. Downscaled ERA5 rainfall data show a much better distribution of spatial covariance and temporal variance when compared with observation.
Prediction of Hemolysis Tendency of Peptides using a Reliable Evaluation Method
Dec 11, 2020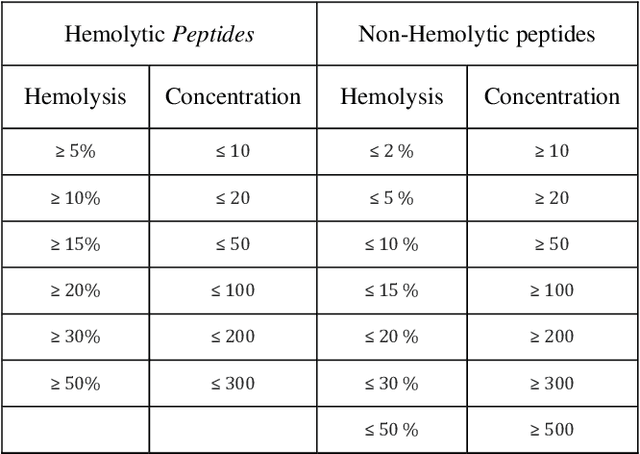
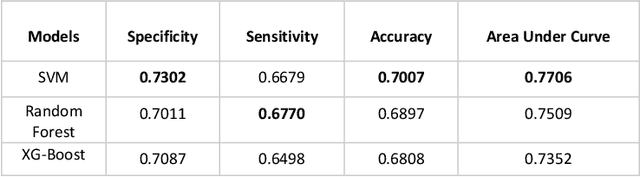
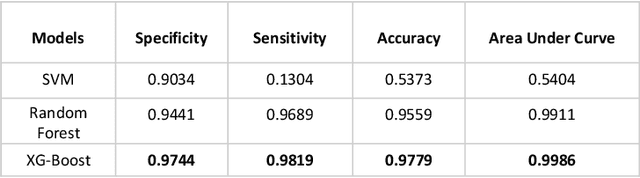
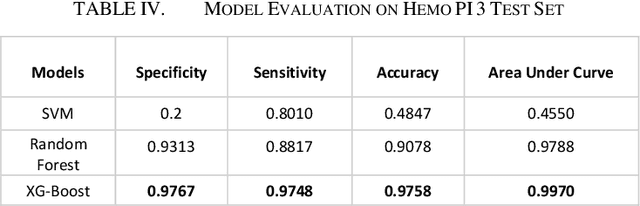
There are numerous peptides discovered through past decades, which exhibit antimicrobial and anti-cancerous tendencies. Due to these reasons, peptides are supposed to be sound therapeutic candidates. Some peptides can pose low metabolic stability, high toxicity and high hemolity of peptides. This highlights the importance for evaluating hemolytic tendencies and toxicity of peptides, before using them for therapeutics. Traditional methods for evaluation of toxicity of peptides can be time-consuming and costly. In this study, we have extracted peptides data (Hemo-DB) from Database of Antimicrobial Activity and Structure of Peptides (DBAASP) based on certain hemolity criteria and we present a machine learning based method for prediction of hemolytic tendencies of peptides (i.e. Hemolytic or Non-Hemolytic). Our model offers significant improvement on hemolity prediction benchmarks. we also propose a reliable clustering-based train-tests splitting method which ensures that no peptide in train set is more than 40% similar to any peptide in test set. Using this train-test split, we can get reliable estimated of expected model performance on unseen data distribution or newly discovered peptides. Our model tests 0.9986 AUC-ROC (Area Under Receiver Operating Curve) and 97.79% Accuracy on test set of Hemo-DB using traditional random train-test splitting method. Moreover, our model tests AUC-ROC of 0.997 and Accuracy of 97.58% while using clustering-based train-test data split. Furthermore, we check our model on an unseen data distribution (at Hemo-PI 3) and we recorded 0.8726 AUC-ROC and 79.5% accuracy. Using the proposed method, potential therapeutic peptides can be screened, which may further in therapeutics and get reliable predictions for unseen amino acids distribution of peptides and newly discovered peptides.
Fine-grained Language Identification with Multilingual CapsNet Model
Jul 12, 2020
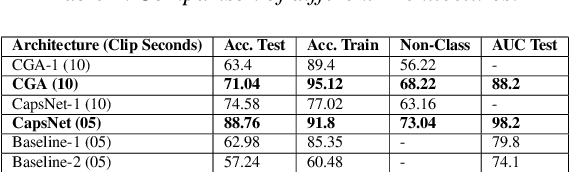
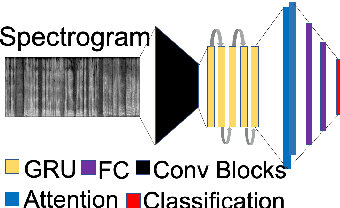
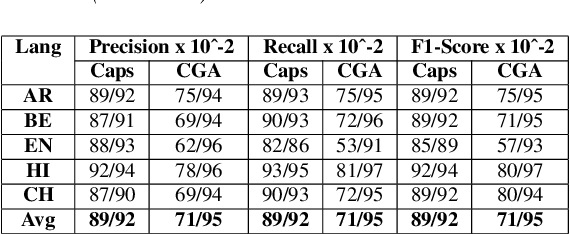
Due to a drastic improvement in the quality of internet services worldwide, there is an explosion of multilingual content generation and consumption. This is especially prevalent in countries with large multilingual audience, who are increasingly consuming media outside their linguistic familiarity/preference. Hence, there is an increasing need for real-time and fine-grained content analysis services, including language identification, content transcription, and analysis. Accurate and fine-grained spoken language detection is an essential first step for all the subsequent content analysis algorithms. Current techniques in spoken language detection may lack on one of these fronts: accuracy, fine-grained detection, data requirements, manual effort in data collection \& pre-processing. Hence in this work, a real-time language detection approach to detect spoken language from 5 seconds' audio clips with an accuracy of 91.8\% is presented with exiguous data requirements and minimal pre-processing. Novel architectures for Capsule Networks is proposed which operates on spectrogram images of the provided audio snippets. We use previous approaches based on Recurrent Neural Networks and iVectors to present the results. Finally we show a ``Non-Class'' analysis to further stress on why CapsNet architecture works for LID task.
Neural Star Domain as Primitive Representation
Oct 21, 2020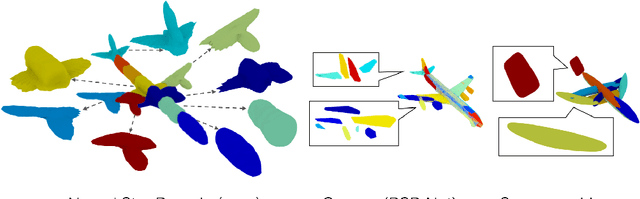

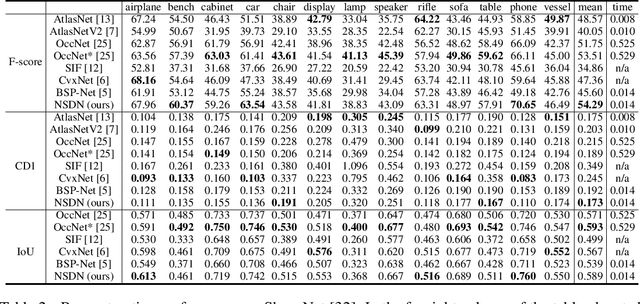
Reconstructing 3D objects from 2D images is a fundamental task in computer vision. Accurate structured reconstruction by parsimonious and semantic primitive representation further broadens its application. When reconstructing a target shape with multiple primitives, it is preferable that one can instantly access the union of basic properties of the shape such as collective volume and surface, treating the primitives as if they are one single shape. This becomes possible by primitive representation with unified implicit and explicit representations. However, primitive representations in current approaches do not satisfy all of the above requirements at the same time. To solve this problem, we propose a novel primitive representation named neural star domain (NSD) that learns primitive shapes in the star domain. We show that NSD is a universal approximator of the star domain and is not only parsimonious and semantic but also an implicit and explicit shape representation. We demonstrate that our approach outperforms existing methods in image reconstruction tasks, semantic capabilities, and speed and quality of sampling high-resolution meshes.
CocoPIE: Making Mobile AI Sweet As PIE --Compression-Compilation Co-Design Goes a Long Way
Mar 14, 2020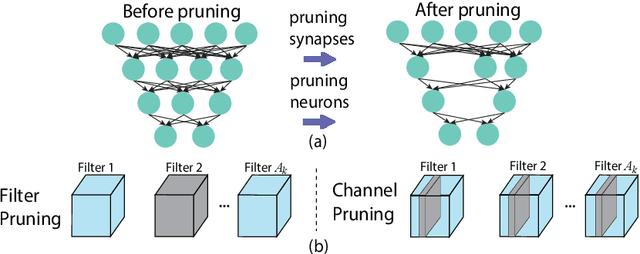
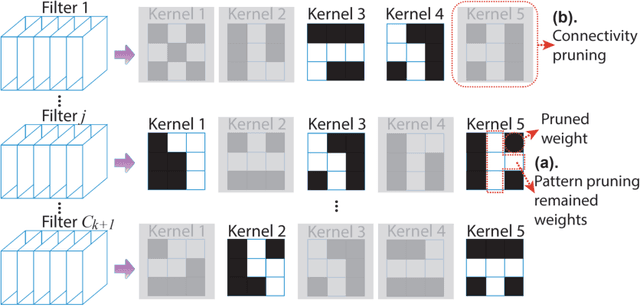

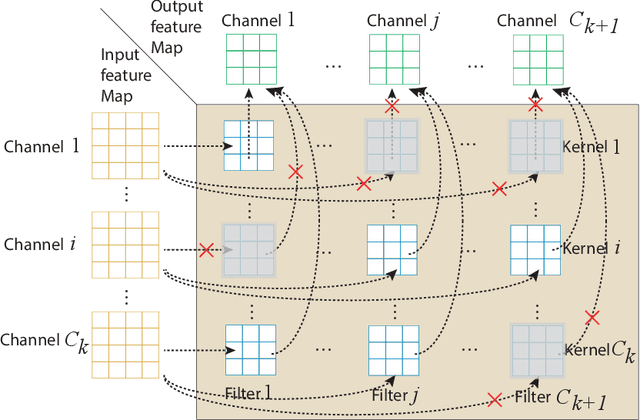
Assuming hardware is the major constraint for enabling real-time mobile intelligence, the industry has mainly dedicated their efforts to developing specialized hardware accelerators for machine learning and inference. This article challenges the assumption. By drawing on a recent real-time AI optimization framework CoCoPIE, it maintains that with effective compression-compiler co-design, it is possible to enable real-time artificial intelligence on mainstream end devices without special hardware. CoCoPIE is a software framework that holds numerous records on mobile AI: the first framework that supports all main kinds of DNNs, from CNNs to RNNs, transformer, language models, and so on; the fastest DNN pruning and acceleration framework, up to 180X faster compared with current DNN pruning on other frameworks such as TensorFlow-Lite; making many representative AI applications able to run in real-time on off-the-shelf mobile devices that have been previously regarded possible only with special hardware support; making off-the-shelf mobile devices outperform a number of representative ASIC and FPGA solutions in terms of energy efficiency and/or performance.
In-the-wild Drowsiness Detection from Facial Expressions
Oct 21, 2020
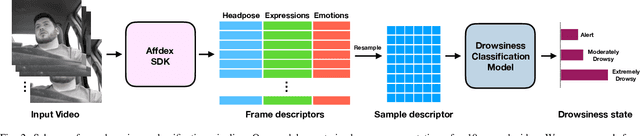
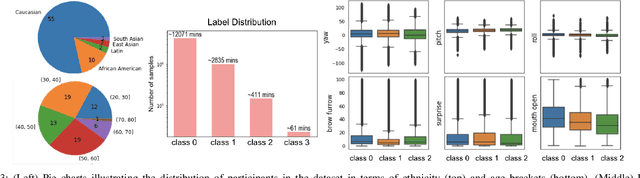
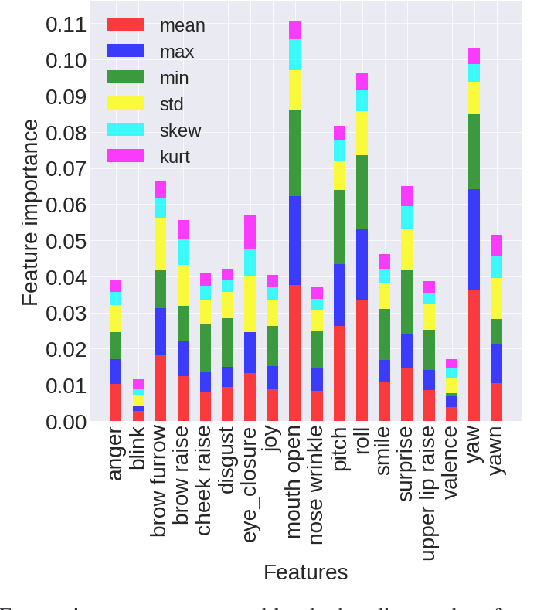
Driving in a state of drowsiness is a major cause of road accidents, resulting in tremendous damage to life and property. Developing robust, automatic, real-time systems that can infer drowsiness states of drivers has the potential of making life-saving impact. However, developing drowsiness detection systems that work well in real-world scenarios is challenging because of the difficulties associated with collecting high-volume realistic drowsy data and modeling the complex temporal dynamics of evolving drowsy states. In this paper, we propose a data collection protocol that involves outfitting vehicles of overnight shift workers with camera kits that record their faces while driving. We develop a drowsiness annotation guideline to enable humans to label the collected videos into 4 levels of drowsiness: `alert', `slightly drowsy', `moderately drowsy' and `extremely drowsy'. We experiment with different convolutional and temporal neural network architectures to predict drowsiness states from pose, expression and emotion-based representation of the input video of the driver's face. Our best performing model achieves a macro ROC-AUC of 0.78, compared to 0.72 for a baseline model.
Human-centric Spatio-Temporal Video Grounding With Visual Transformers
Nov 10, 2020

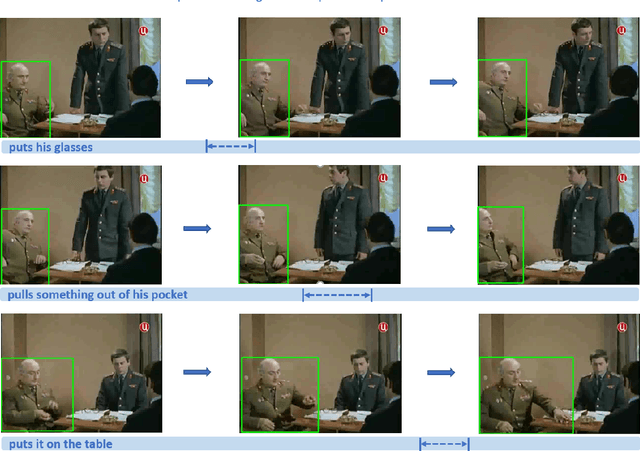
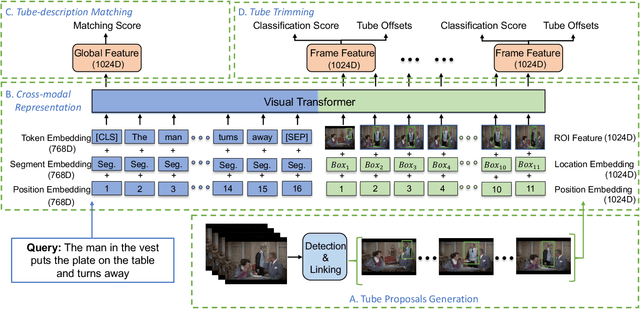
In this work, we introduce a novel task - Humancentric Spatio-Temporal Video Grounding (HC-STVG). Unlike the existing referring expression tasks in images or videos, by focusing on humans, HC-STVG aims to localize a spatiotemporal tube of the target person from an untrimmed video based on a given textural description. This task is useful, especially for healthcare and security-related applications, where the surveillance videos can be extremely long but only a specific person during a specific period of time is concerned. HC-STVG is a video grounding task that requires both spatial (where) and temporal (when) localization. Unfortunately, the existing grounding methods cannot handle this task well. We tackle this task by proposing an effective baseline method named Spatio-Temporal Grounding with Visual Transformers (STGVT), which utilizes Visual Transformers to extract cross-modal representations for video-sentence matching and temporal localization. To facilitate this task, we also contribute an HC-STVG dataset consisting of 5,660 video-sentence pairs on complex multi-person scenes. Specifically, each video lasts for 20 seconds, pairing with a natural query sentence with an average of 17.25 words. Extensive experiments are conducted on this dataset, demonstrating the newly-proposed method outperforms the existing baseline methods.