 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Simple and optimal methods for stochastic variational inequalities, II: Markovian noise and policy evaluation in reinforcement learning
Nov 25, 2020

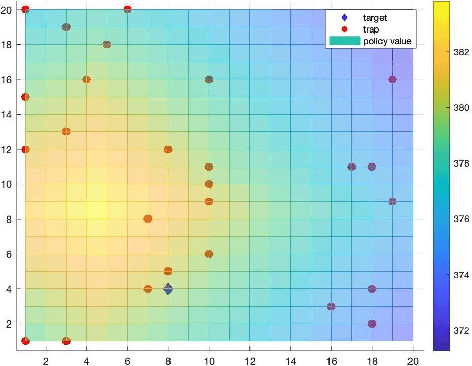
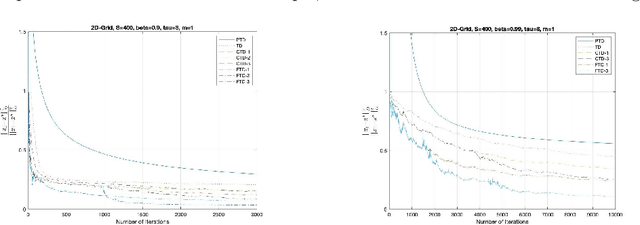
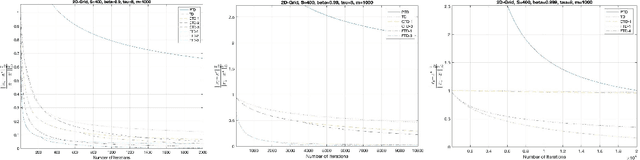
The focus of this paper is on stochastic variational inequalities (VI) under Markovian noise. A prominent application of our algorithmic developments is the stochastic policy evaluation problem in reinforcement learning. Prior investigations in the literature focused on temporal difference (TD) learning by employing nonsmooth finite time analysis motivated by stochastic subgradient descent leading to certain limitations. These encompass the requirement of analyzing a modified TD algorithm that involves projection to an a-priori defined Euclidean ball, achieving a non-optimal convergence rate and no clear way of deriving the beneficial effects of parallel implementation. Our approach remedies these shortcomings in the broader context of stochastic VIs and in particular when it comes to stochastic policy evaluation. We developed a variety of simple TD learning type algorithms motivated by its original version that maintain its simplicity, while offering distinct advantages from a non-asymptotic analysis point of view. We first provide an improved analysis of the standard TD algorithm that can benefit from parallel implementation. Then we present versions of a conditional TD algorithm (CTD), that involves periodic updates of the stochastic iterates, which reduce the bias and therefore exhibit improved iteration complexity. This brings us to the fast TD (FTD) algorithm which combines elements of CTD and the stochastic operator extrapolation method of the companion paper. For a novel index resetting policy FTD exhibits the best known convergence rate. We also devised a robust version of the algorithm that is particularly suitable for discounting factors close to 1.
Weighted Model Counting in FO2 with Cardinality Constraints and Counting Quantifiers: A Closed Form Formula
Oct 01, 2020Weighted First Order Model Counting (WFOMC) computes the weighted sum of the models of a first order theory on a domain of a given finite size. WFOMC has emerged as a fundamental tool for probabilistic inference. Algorithms for WFOMC that run in polynomial time w.r.t. the domain size are called lifted inference algorithms. Such algorithms have been developed for multiple extensions of FO$^2$(the fragment of First Order Logic with two variables) for the special case of symmetric weight functions. In this paper, instead of developing a specific algorithm, we derive a closed form formula for WFOMC in FO$^2$. The three key advantages of our proposal are: (i) it deals with existential quantifiers without introducing negative weights; (ii) it easily extends to FO$^2$ with cardinality constraints and counting quantifiers (aka C$^2$); finally, (iii) it supports WFOMC for a class of weight functions strictly larger than symmetric weight functions, which can model count distributions, without introducing complex or negative weights.
Experimental Validation of a Real-Time Optimal Controller for Coordination of CAVs in a Multi-Lane Roundabout
Jan 30, 2020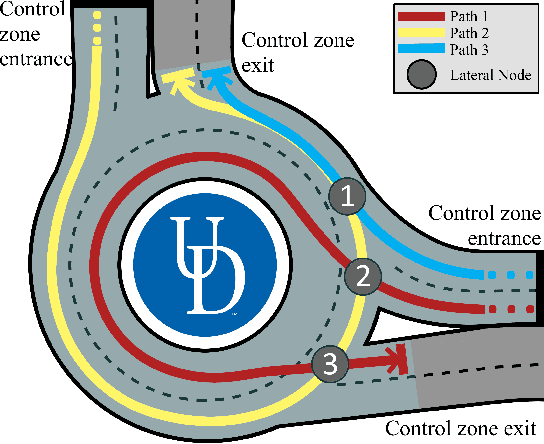


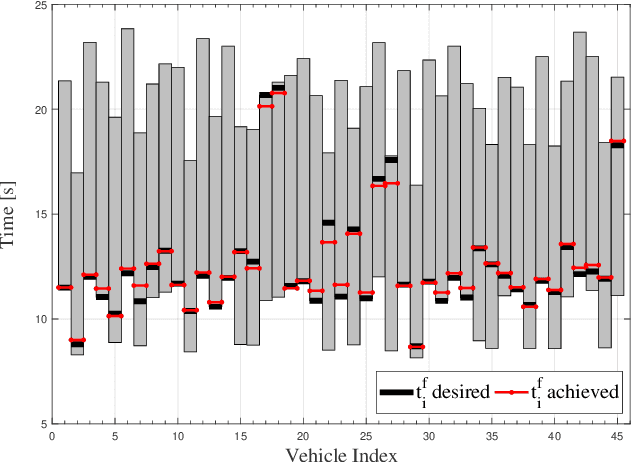
Roundabouts and other transportation bottlenecks may induce congestion in a traffic system due to driver responses to various disturbances. Research efforts have shown that smoothing traffic flow and eliminating stop-and-go driving can both improve fuel efficiency of the vehicles and the throughput of a roundabout. In this paper, we validate an optimal control algorithm developed earlier in a multi-lane roundabout scenario using University of Delaware's scaled smart city (UDSSC). We first provide conditions where the solution is optimal. Then, we demonstrate the feasibility of the solution using experiments at UDSSC, and show that the optimal solution completely eliminates stop-and-go driving while preserving safety.
Physics Guided Machine Learning Methods for Hydrology
Dec 02, 2020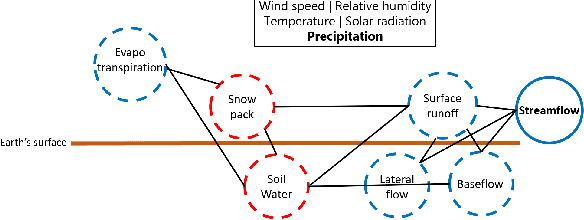
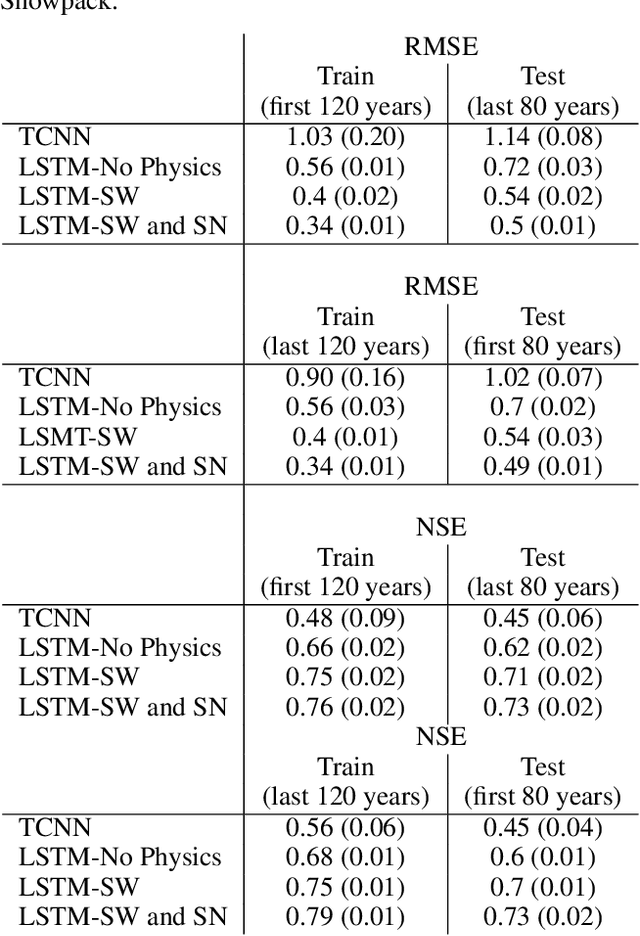
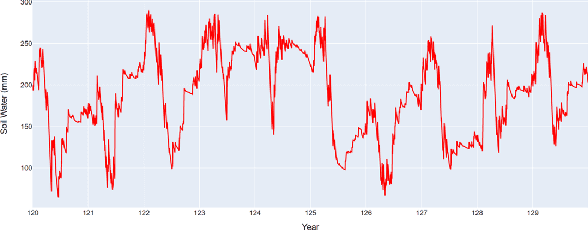
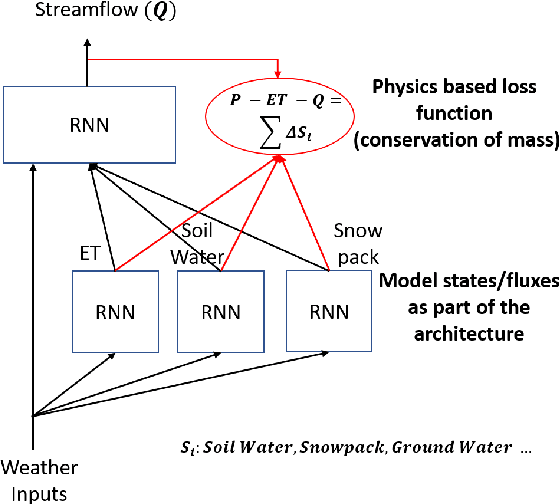
Streamflow prediction is one of the key challenges in the field of hydrology due to the complex interplay between multiple non-linear physical mechanisms behind streamflow generation. While physically-based models are rooted in rich understanding of the physical processes, a significant performance gap still remains which can be potentially addressed by leveraging the recent advances in machine learning. The goal of this work is to incorporate our understanding of physical processes and constraints in hydrology into machine learning algorithms, and thus bridge the performance gap while reducing the need for large amounts of data compared to traditional data-driven approaches. In particular, we propose an LSTM based deep learning architecture that is coupled with SWAT (Soil and Water Assessment Tool), an hydrology model that is in wide use today. The key idea of the approach is to model auxiliary intermediate processes that connect weather drivers to streamflow, rather than directly mapping runoff from weather variables which is what a deep learning architecture without physical insight will do. The efficacy of the approach is being analyzed on several small catchments located in the South Branch of the Root River Watershed in southeast Minnesota. Apart from observation data on runoff, the approach also leverages a 200-year synthetic dataset generated by SWAT to improve the performance while reducing convergence time. In the early phases of this study, simpler versions of the physics guided deep learning architectures are being used to achieve a system understanding of the coupling of physics and machine learning. As more complexity is introduced into the present implementation, the framework will be able to generalize to more sophisticated cases where spatial heterogeneity is present.
DA2: Deep Attention Adapter for Memory-EfficientOn-Device Multi-Domain Learning
Dec 02, 2020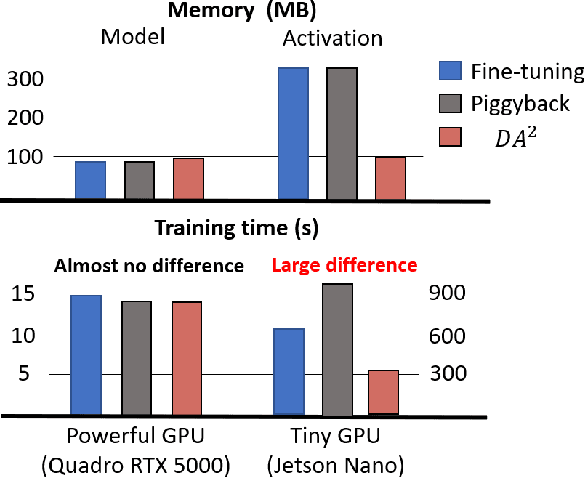

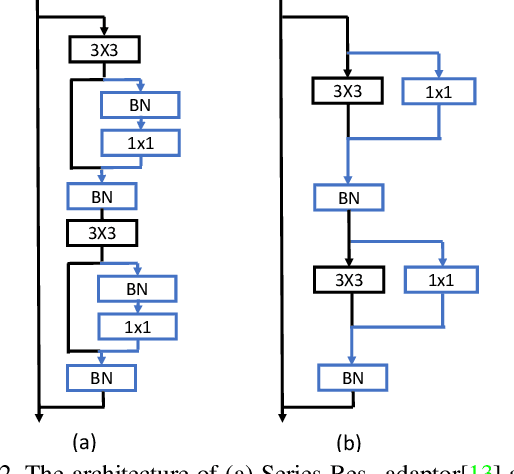
Nowadays, one practical limitation of deep neural network (DNN) is its high degree of specialization to a single task or domain (e.g. one visual domain). It motivates researchers to develop algorithms that can adapt DNN model to multiple domains sequentially, meanwhile still performing well on the past domains, which is known as multi-domain learning. Conventional methods only focus on improving accuracy with minimal parameter update, while ignoring high computing and memory usage during training, which makes it impossible to deploy into more and more widely used resource-limited edge devices, like mobile phone, IoT, embedded systems, etc. During our study, we observe that memory used for activation storage is the bottleneck that largely limits the training time and cost on edge devices. To reduce training memory usage, while keeping the domain adaption accuracy performance, in this work, we propose Deep Attention Adaptor, a novel on-device multi-domain learning method, aiming to achieve domain adaption on resource-limited edge devices in both fast and memory-efficient manner. During on-device training, DA2 freezes the weights of pre-trained backbone model to reduce the training memory consumption (i.e., no need to store activation features during backward propagation). Furthermore, to improve the adaption accuracy performance, we propose to improve the model capacity by learning a light-weight memory-efficient residual attention adaptor module. We validate DA2 on multiple datasets against state-of-the-art methods, which shows good improvement in both accuracy and training cost. Finally, we demonstrate the algorithm's efficiency on NIVDIA Jetson Nano tiny GPU, proving the proposed DA2 reduces the on-device memory consumption by 19-37x during training in comparison to the baseline methods.
Neural Enhancement in Content Delivery Systems: The State-of-the-Art and Future Directions
Oct 12, 2020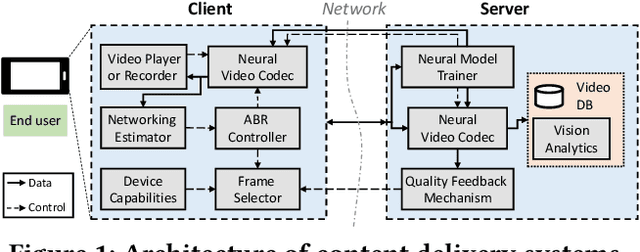


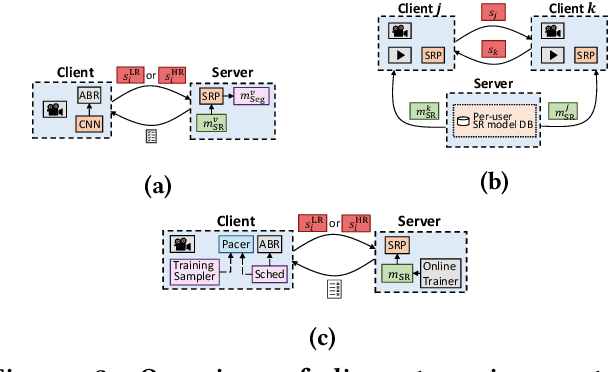
Internet-enabled smartphones and ultra-wide displays are transforming a variety of visual apps spanning from on-demand movies and 360-degree videos to video-conferencing and live streaming. However, robustly delivering visual content under fluctuating networking conditions on devices of diverse capabilities remains an open problem. In recent years, advances in the field of deep learning on tasks such as super-resolution and image enhancement have led to unprecedented performance in generating high-quality images from low-quality ones, a process we refer to as neural enhancement. In this paper, we survey state-of-the-art content delivery systems that employ neural enhancement as a key component in achieving both fast response time and high visual quality. We first present the deployment challenges of neural enhancement models. We then cover systems targeting diverse use-cases and analyze their design decisions in overcoming technical challenges. Moreover, we present promising directions based on the latest insights from deep learning research to further boost the quality of experience of these systems.
Forecasting asylum applications in the European Union with machine learning and data at scale
Nov 10, 2020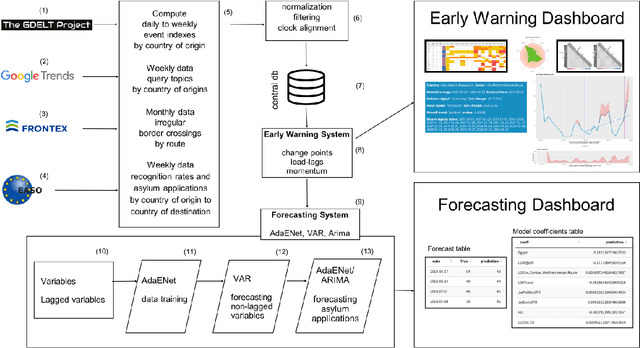
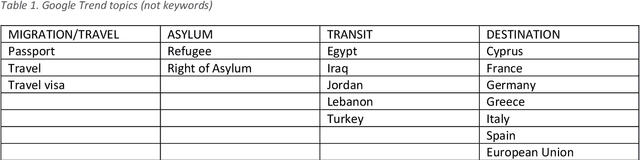
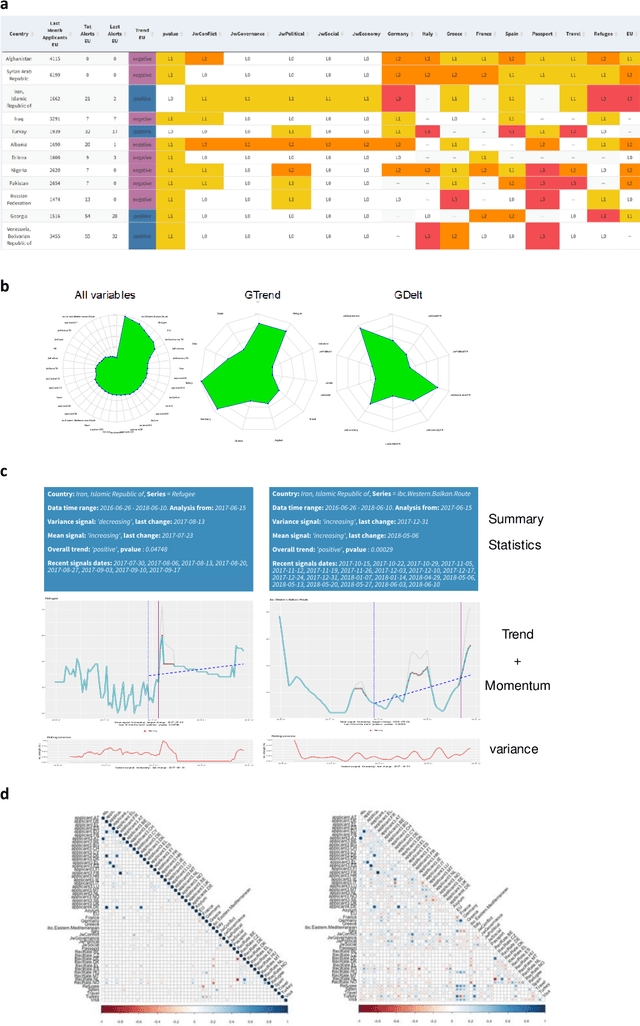
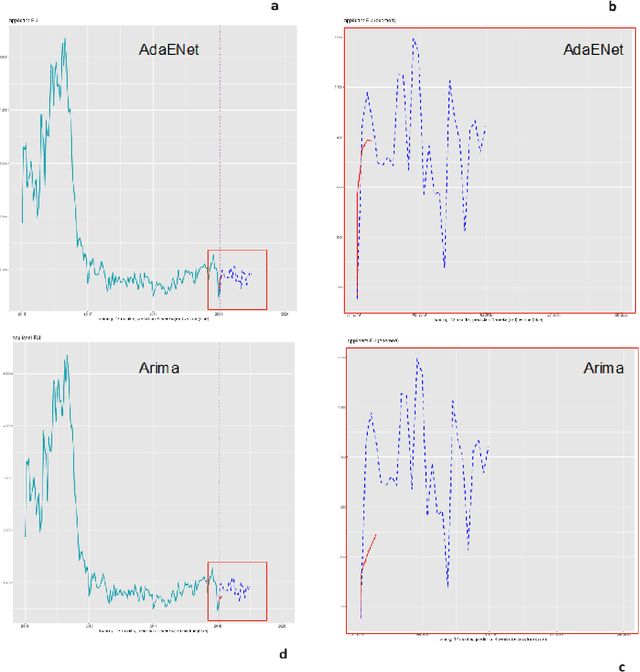
The effects of the so-called "refugee crisis" of 2015-16 continue to dominate much of the European political agenda. Migration flows were sudden and unexpected, exposing significant shortcomings in the field of migration forecasting and leaving governments and NGOs unprepared. Migration is a complex system typified by episodic variation, underpinned by causal factors that are interacting, highly context dependent and short-lived. Correspondingly, migration nowcasts rely on scattered low-quality data and much-needed forecasts are local and inconsistent. Here we describe a data-driven adaptive system for forecasting asylum applications in the European Union (EU), built on machine learning algorithms that combine administrative data with non-traditional data sources at scale. We exploit three tiers of data: geolocated events and internet searches in countries of origin, detections at the EU external border, and asylum recognition rates in the EU, to effectively forecast individual asylum-migration flows up to four weeks ahead with high accuracy. Uniquely our approach a) models individual country-to-country migration flows; b) detects migration drivers early onset; c) anticipates lagged effects; d) estimates the effect of individual drivers; and e) describes how patterns of drivers shift over time. This is, to our knowledge, the first comprehensive system for forecasting asylum applications based on an unsupervised algorithm and data at scale. Importantly, this approach can be extended to forecast other migration social-economic indicators.
Deep Group-wise Variational Diffeomorphic Image Registration
Oct 01, 2020
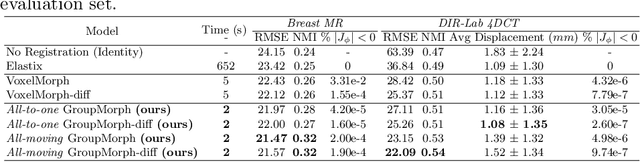
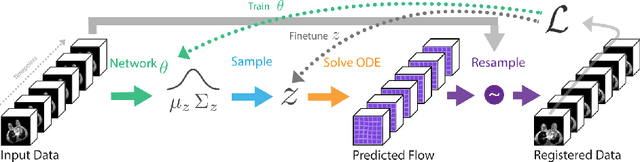
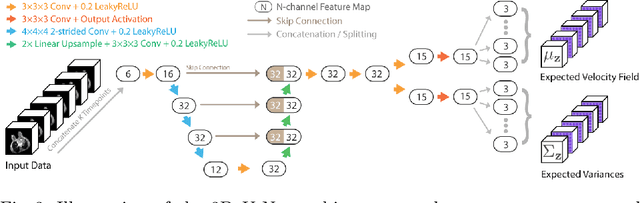
Deep neural networks are increasingly used for pair-wise image registration. We propose to extend current learning-based image registration to allow simultaneous registration of multiple images. To achieve this, we build upon the pair-wise variational and diffeomorphic VoxelMorph approach and present a general mathematical framework that enables both registration of multiple images to their geodesic average and registration in which any of the available images can be used as a fixed image. In addition, we provide a likelihood based on normalized mutual information, a well-known image similarity metric in registration, between multiple images, and a prior that allows for explicit control over the viscous fluid energy to effectively regularize deformations. We trained and evaluated our approach using intra-patient registration of breast MRI and Thoracic 4DCT exams acquired over multiple time points. Comparison with Elastix and VoxelMorph demonstrates competitive quantitative performance of the proposed method in terms of image similarity and reference landmark distances at significantly faster registration.
Recalibration of Neural Networks for Point Cloud Analysis
Nov 25, 2020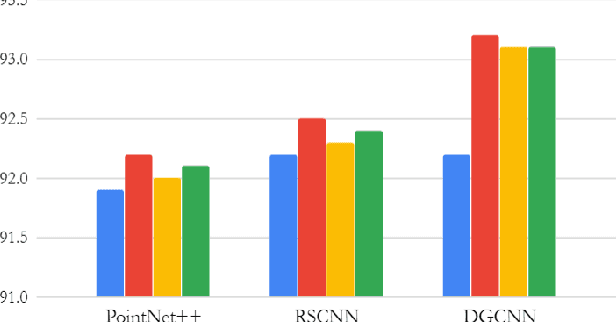
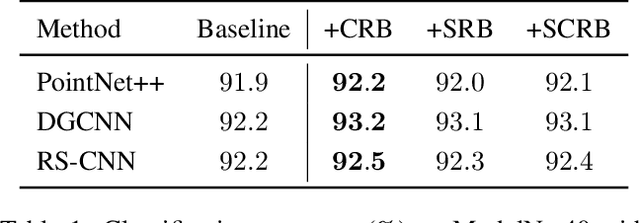
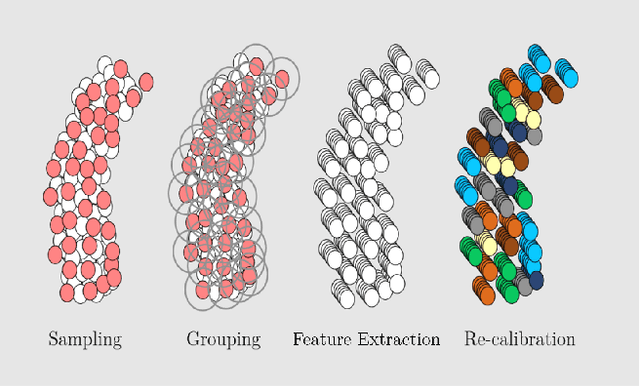

Spatial and channel re-calibration have become powerful concepts in computer vision. Their ability to capture long-range dependencies is especially useful for those networks that extract local features, such as CNNs. While re-calibration has been widely studied for image analysis, it has not yet been used on shape representations. In this work, we introduce re-calibration modules on deep neural networks for 3D point clouds. We propose a set of re-calibration blocks that extend Squeeze and Excitation blocks and that can be added to any network for 3D point cloud analysis that builds a global descriptor by hierarchically combining features from multiple local neighborhoods. We run two sets of experiments to validate our approach. First, we demonstrate the benefit and versatility of our proposed modules by incorporating them into three state-of-the-art networks for 3D point cloud analysis: PointNet++, DGCNN, and RSCNN. We evaluate each network on two tasks: object classification on ModelNet40, and object part segmentation on ShapeNet. Our results show an improvement of up to 1% in accuracy for ModelNet40 compared to the baseline method. In the second set of experiments, we investigate the benefits of re-calibration blocks on Alzheimer's Disease (AD) diagnosis. Our results demonstrate that our proposed methods yield a 2% increase in accuracy for diagnosing AD and a 2.3% increase in concordance index for predicting AD onset with time-to-event analysis. Concluding, re-calibration improves the accuracy of point cloud architectures, while only minimally increasing the number of parameters.
Evolutionary Multi-Objective Design of SARS-CoV-2 Protease Inhibitor Candidates
May 06, 2020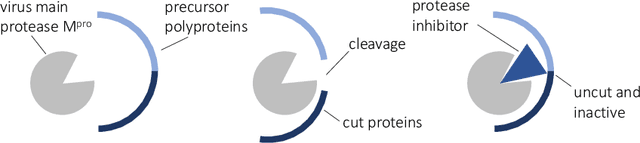

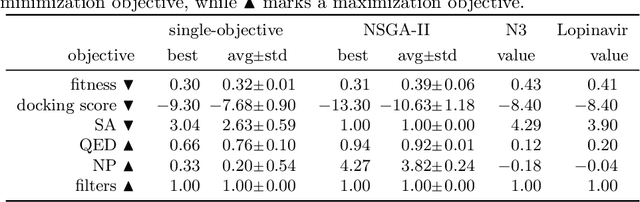
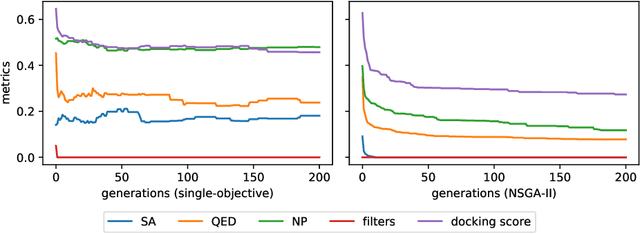
Computational drug design based on artificial intelligence is an emerging research area. At the time of writing this paper, the world suffers from an outbreak of the coronavirus SARS-CoV-2. A promising way to stop the virus replication is via protease inhibition. We propose an evolutionary multi-objective algorithm (EMOA) to design potential protease inhibitors for SARS-CoV-2's main protease. Based on the SELFIES representation the EMOA maximizes the binding of candidate ligands to the protein using the docking tool QuickVina 2, while at the same time taking into account further objectives like drug-likeliness or the fulfillment of filter constraints. The experimental part analyzes the evolutionary process and discusses the inhibitor candidates.