 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Invertible CNN-Based Super Resolution with Downsampling Awareness
Nov 11, 2020
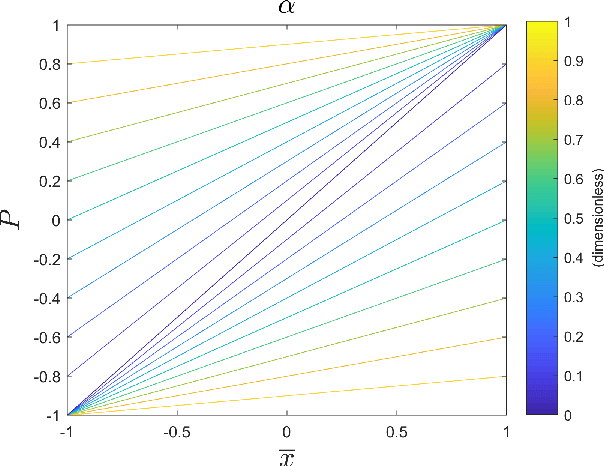
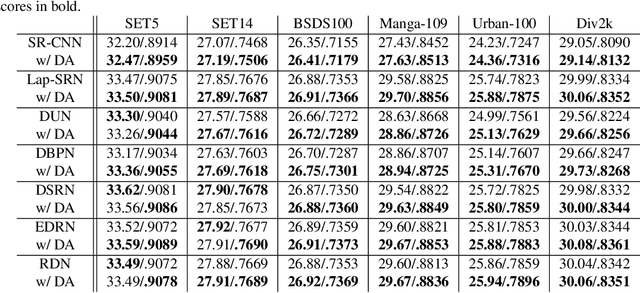
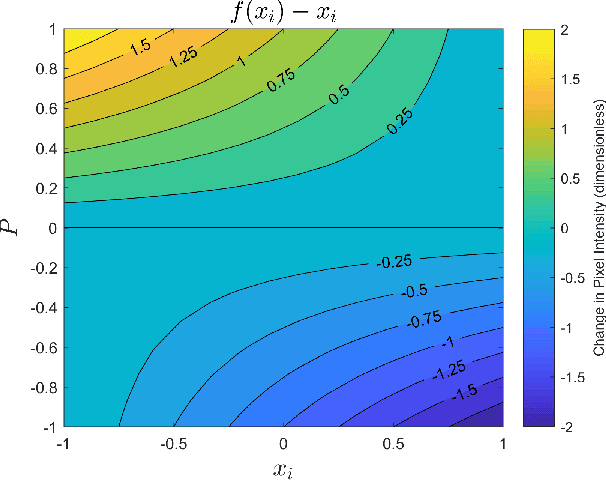
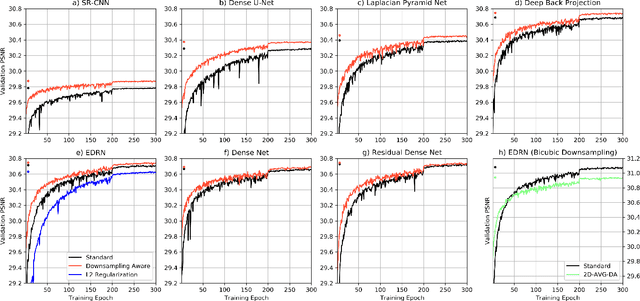
Single image super resolution involves artificially increasing the resolution of an image. Recently, convolutional neural networks have been demonstrated as very powerful tools for this problem. These networks are typically trained by artificially degrading high resolution images and training the neural network to reproduce the original. Because these neural networks are learning an inverse function for an image downsampling scheme, their high-resolution outputs should ideally re-produce the corresponding low-resolution input when the same downsampling scheme is applied. This constraint has not historically been explicitly and strictly imposed during training however. Here, a method for "downsampling aware" super resolution networks is proposed. A differentiable operator is applied as the final output layer of the neural network that forces the downsampled output to match the low resolution input data under 2D-average downsampling. It is demonstrated that appending this operator to a selection of state-of-the-art deep-learning-based super resolution schemes improves training time and overall performance on most of the common image super resolution benchmark datasets. In addition to this performance improvement for images, this method has potentially broad and significant impacts in the physical sciences. This scheme can be applied to data produced by medical scans, precipitation radars, gridded numerical simulations, satellite imagers, and many other sources. In such applications, the proposed method's guarantee of strict adherence to physical conservation laws is of critical importance.
A Survey of Deep Learning Architectures for Intelligent Reflecting Surfaces
Sep 19, 2020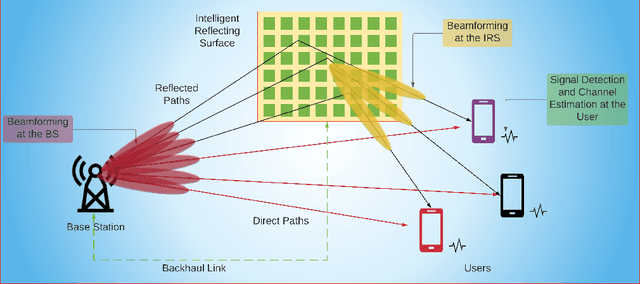
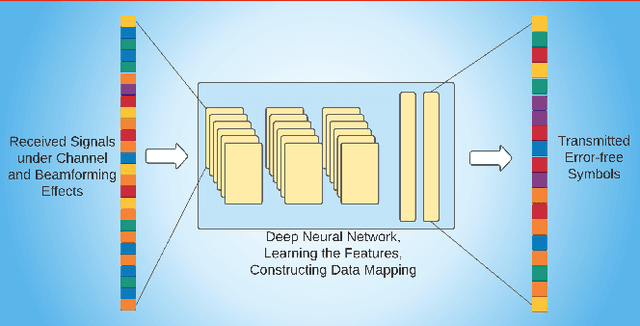
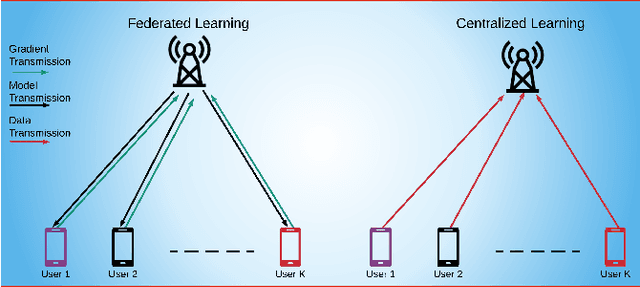
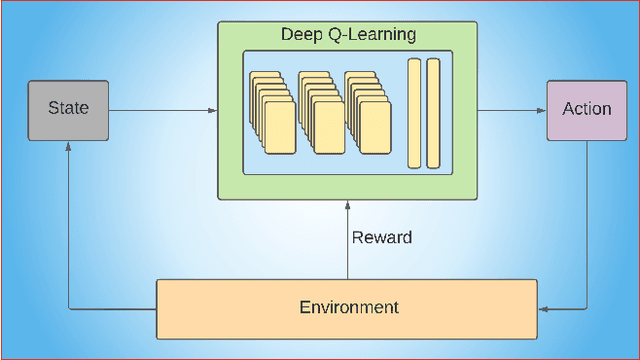
Intelligent reflecting surfaces (IRSs) have recently received significant attention for wireless communications because it reduces the hardware complexity, physical size, weight, and cost of conventional large arrays. However, deployment of IRS entails dealing with multiple channel links between the base station (BS) and the users. Further, the BS and IRS beamformers require a joint design, wherein the IRS elements must be rapidly reconfigured. Data-driven techniques, such as deep learning (DL), are critical in addressing these challenges. The lower computation time and model-free nature of DL makes it robust against the data imperfections and environmental changes. At the physical layer, DL has been shown to be effective for IRS signal detection, channel estimation and active/passive beamforming using architectures such as supervised, unsupervised and reinforcement learning. This article provides a synopsis of these techniques for designing DL-based IRS-assisted wireless systems.
EikoNet: Solving the Eikonal equation with Deep Neural Networks
Mar 25, 2020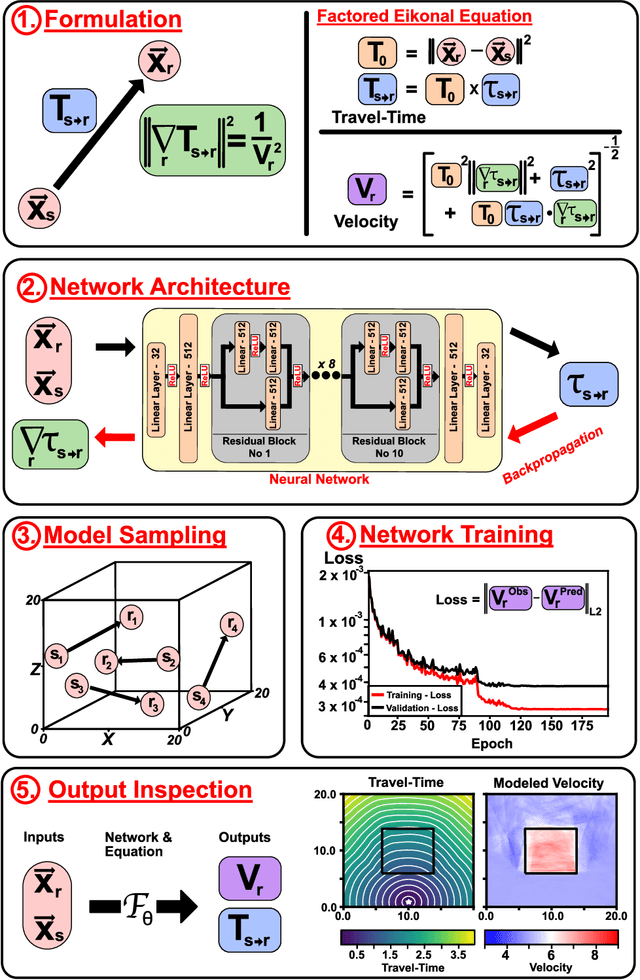
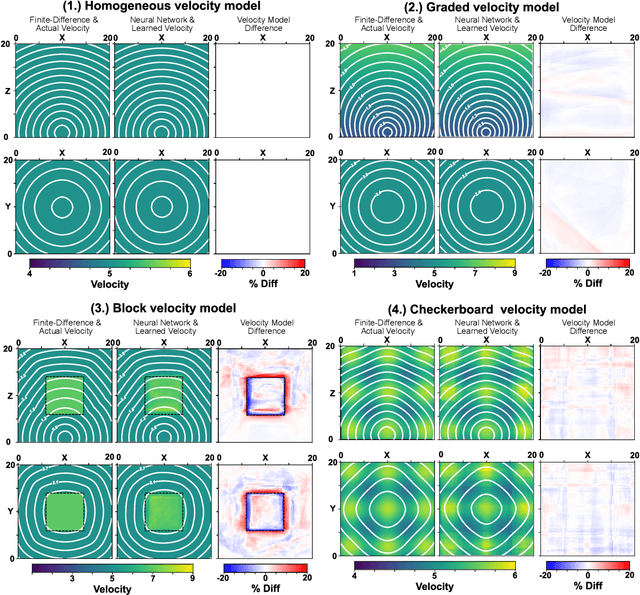
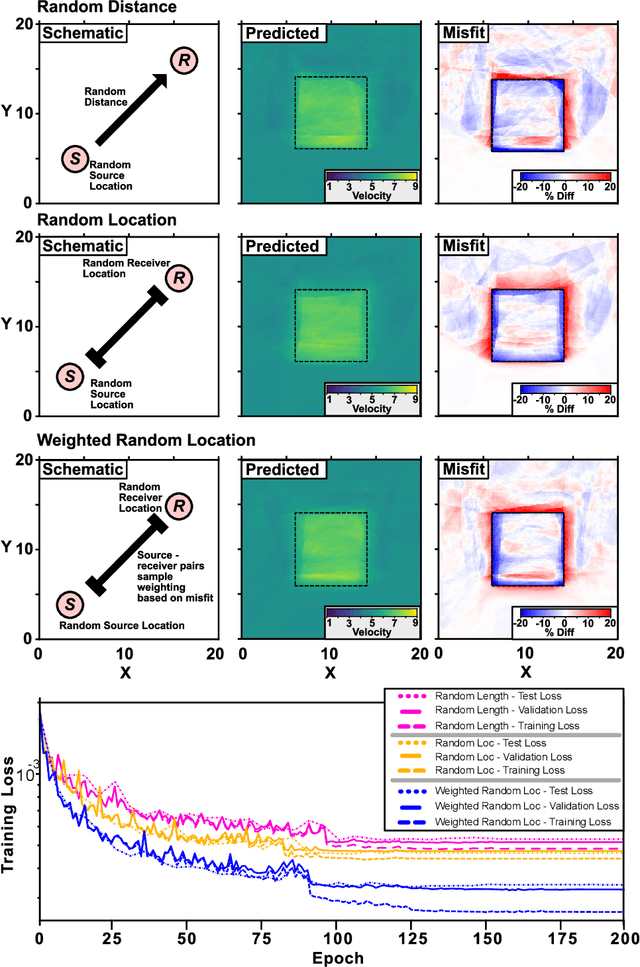
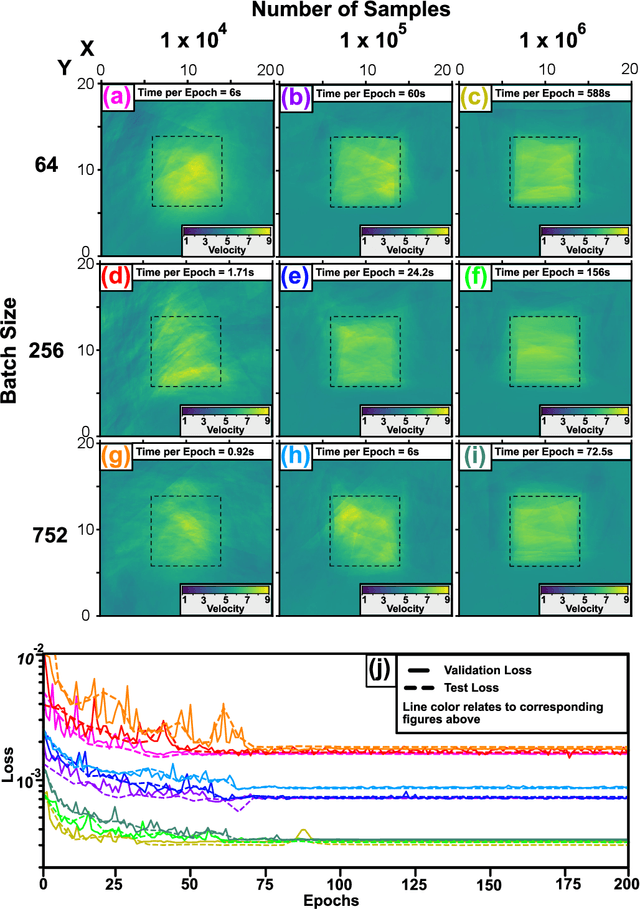
The recent deep learning revolution has created an enormous opportunity for accelerating compute capabilities in the context of physics-based simulations. Here, we propose EikoNet, a deep learning approach to solving the Eikonal equation, which characterizes the first-arrival-time field in heterogeneous 3D velocity structures. Our grid-free approach allows for rapid determination of the travel time between any two points within a continuous 3D domain. These travel time solutions are allowed to violate the differential equation - which casts the problem as one of optimization - with the goal of finding network parameters that minimize the degree to which the equation is violated. In doing so, the method exploits the differentiability of neural networks to calculate the spatial gradients analytically, meaning the network can be trained on its own without ever needing solutions from a finite difference algorithm. EikoNet is rigorously tested on several velocity models and sampling methods to demonstrate robustness and versatility. Training and inference are highly parallelized, making the approach well-suited for GPUs. EikoNet has low memory overhead, and further avoids the need for travel-time lookup tables. The developed approach has important applications to earthquake hypocenter inversion, ray multi-pathing, and tomographic modeling, as well as to other fields beyond seismology where ray tracing is essential.
Stabilizing Transformer-Based Action Sequence Generation For Q-Learning
Oct 23, 2020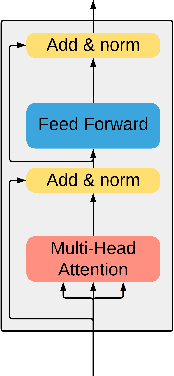
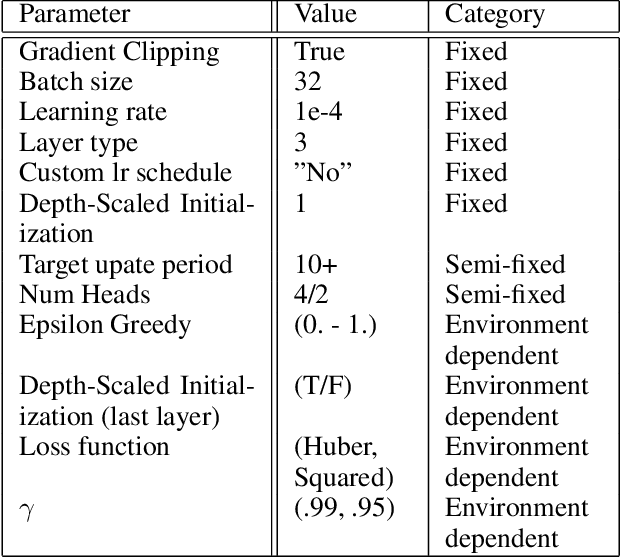
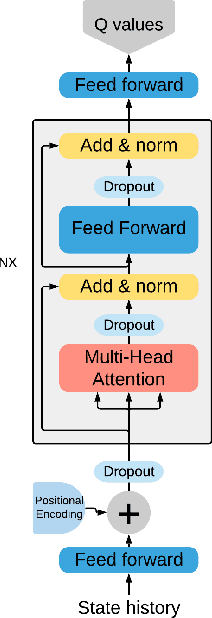

Since the publication of the original Transformer architecture (Vaswani et al. 2017), Transformers revolutionized the field of Natural Language Processing. This, mainly due to their ability to understand timely dependencies better than competing RNN-based architectures. Surprisingly, this architecture change does not affect the field of Reinforcement Learning (RL), even though RNNs are quite popular in RL, and time dependencies are very common in RL. Recently, (Parisotto et al. 2019) conducted the first promising research of Transformers in RL. To support the findings of this work, this paper seeks to provide an additional example of a Transformer-based RL method. Specifically, the goal is a simple Transformer-based Deep Q-Learning method that is stable over several environments. Due to the unstable nature of Transformers and RL, an extensive method search was conducted to arrive at a final method that leverages developments around Transformers as well as Q-learning. The proposed method can match the performance of classic Q-learning on control environments while showing potential on some selected Atari benchmarks. Furthermore, it was critically evaluated to give additional insights into the relation between Transformers and RL.
Sparse Communication for Training Deep Networks
Sep 19, 2020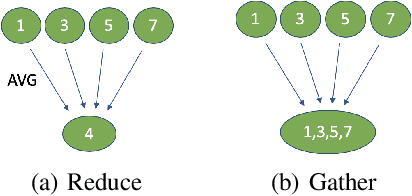
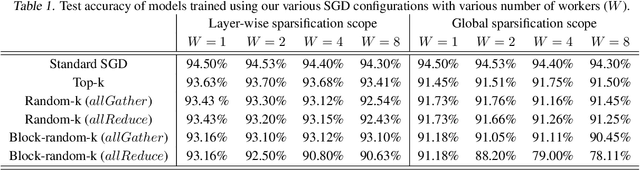
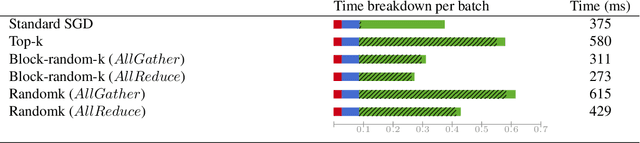
Synchronous stochastic gradient descent (SGD) is the most common method used for distributed training of deep learning models. In this algorithm, each worker shares its local gradients with others and updates the parameters using the average gradients of all workers. Although distributed training reduces the computation time, the communication overhead associated with the gradient exchange forms a scalability bottleneck for the algorithm. There are many compression techniques proposed to reduce the number of gradients that needs to be communicated. However, compressing the gradients introduces yet another overhead to the problem. In this work, we study several compression schemes and identify how three key parameters affect the performance. We also provide a set of insights on how to increase performance and introduce a simple sparsification scheme, random-block sparsification, that reduces communication while keeping the performance close to standard SGD.
Exposing the Robustness and Vulnerability of Hybrid 8T-6T SRAM Memory Architectures to Adversarial Attacks in Deep Neural Networks
Nov 26, 2020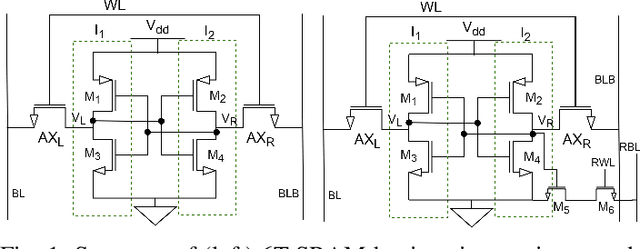
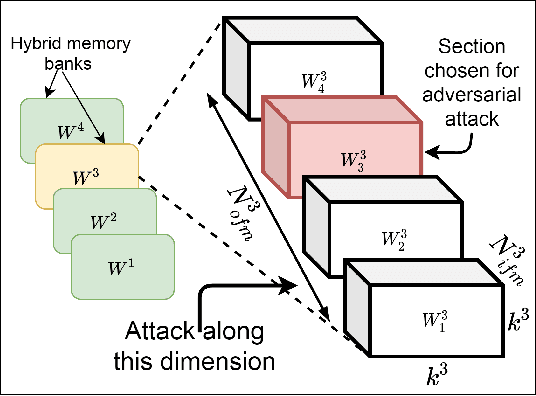
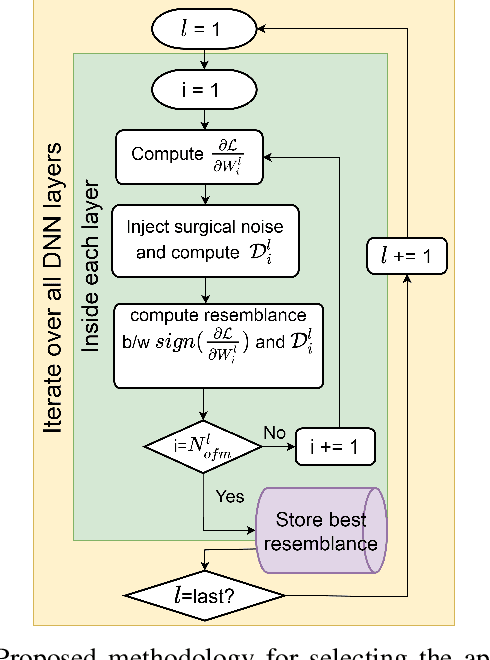
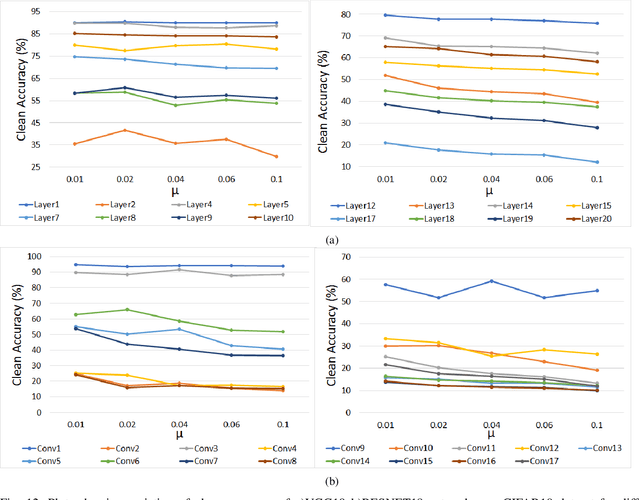
Deep Learning is able to solve a plethora of once impossible problems. However, they are vulnerable to input adversarial attacks preventing them from being autonomously deployed in critical applications. Several algorithm-centered works have discussed methods to cause adversarial attacks and improve adversarial robustness of a Deep Neural Network (DNN). In this work, we elicit the advantages and vulnerabilities of hybrid 6T-8T memories to improve the adversarial robustness and cause adversarial attacks on DNNs. We show that bit-error noise in hybrid memories due to erroneous 6T-SRAM cells have deterministic behaviour based on the hybrid memory configurations (V_DD, 8T-6T ratio). This controlled noise (surgical noise) can be strategically introduced into specific DNN layers to improve the adversarial accuracy of DNNs. At the same time, surgical noise can be carefully injected into the DNN parameters stored in hybrid memory to cause adversarial attacks. To improve the adversarial robustness of DNNs using surgical noise, we propose a methodology to select appropriate DNN layers and their corresponding hybrid memory configurations to introduce the required surgical noise. Using this, we achieve 2-8% higher adversarial accuracy without re-training against white-box attacks like FGSM, than the baseline models (with no surgical noise introduced). To demonstrate adversarial attacks using surgical noise, we design a novel, white-box attack on DNN parameters stored in hybrid memory banks that causes the DNN inference accuracy to drop by more than 60% with over 90% confidence value. We support our claims with experiments, performed using benchmark datasets-CIFAR10 and CIFAR100 on VGG19 and ResNet18 networks.
Humans learn too: Better Human-AI Interaction using Optimized Human Inputs
Sep 19, 2020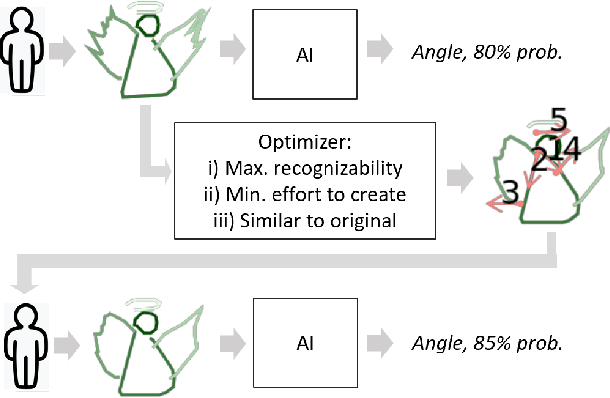
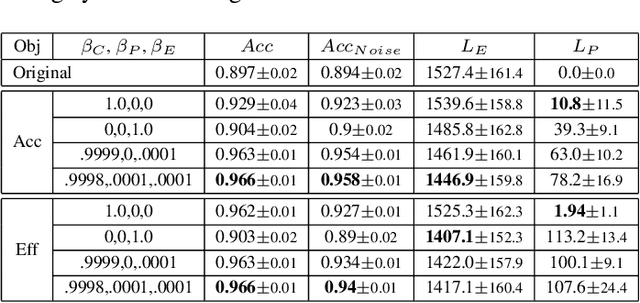
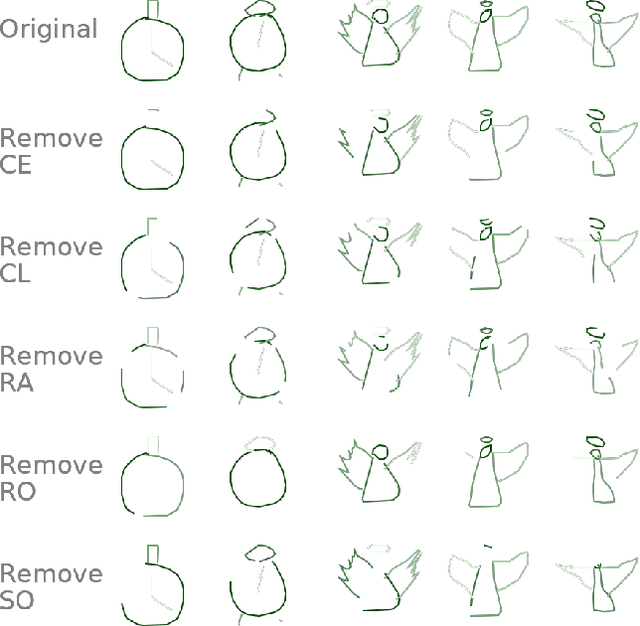
Humans rely more and more on systems with AI components. The AI community typically treats human inputs as a given and optimizes AI models only. This thinking is one-sided and it neglects the fact that humans can learn, too. In this work, human inputs are optimized for better interaction with an AI model while keeping the model fixed. The optimized inputs are accompanied by instructions on how to create them. They allow humans to save time and cut on errors, while keeping required changes to original inputs limited. We propose continuous and discrete optimization methods modifying samples in an iterative fashion. Our quantitative and qualitative evaluation including a human study on different hand-generated inputs shows that the generated proposals lead to lower error rates, require less effort to create and differ only modestly from the original samples.
Optimal Learning for Structured Bandits
Jul 14, 2020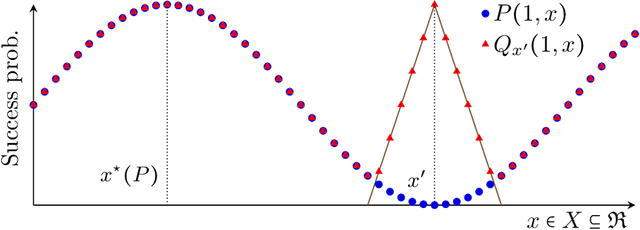

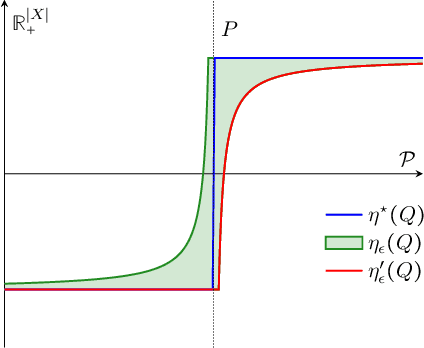
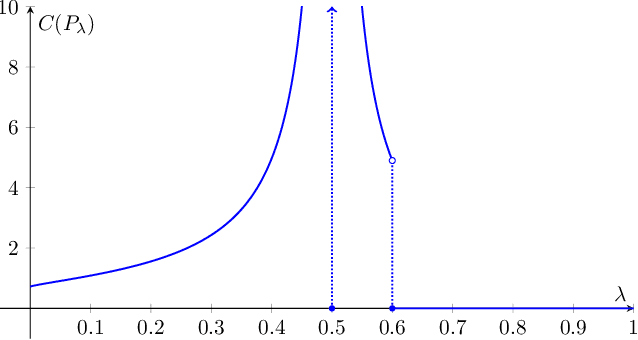
We study structured multi-armed bandits, which is the problem of online decision-making under uncertainty in the presence of structural information. In this problem, the decision-maker needs to discover the best course of action despite observing only uncertain rewards over time. The decision-maker is aware of certain structural information regarding the reward distributions and would like to minimize his regret by exploiting this information, where the regret is its performance difference against a benchmark policy which knows the best action ahead of time. In the absence of structural information, the classical UCB and Thomson sampling algorithms are well known to suffer only minimal regret. As recently pointed out, neither algorithms is, however, capable of exploiting structural information which is commonly available in practice. We propose a novel learning algorithm which we call "DUSA" whose worst-case regret matches the information-theoretic regret lower bound up to a constant factor and can handle a wide range of structural information. Our algorithm DUSA solves a dual counterpart of regret lower bound at the empirical reward distribution and follows the suggestion made by the dual problem. Our proposed algorithm is the first computationally viable learning policy for structured bandit problems that suffers asymptotic minimal regret.
Robust Document Representations using Latent Topics and Metadata
Oct 23, 2020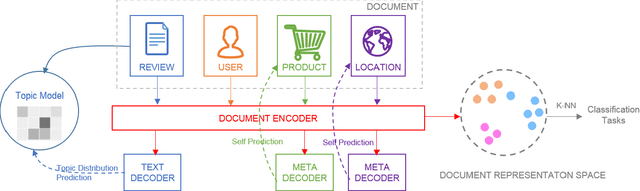

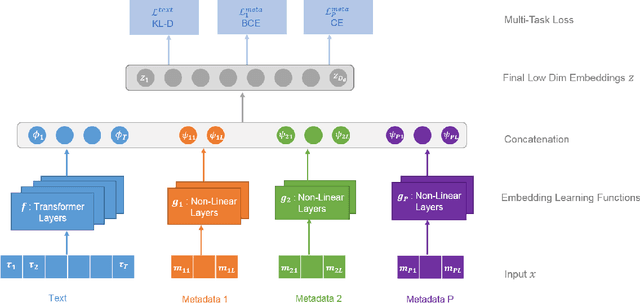

Task specific fine-tuning of a pre-trained neural language model using a custom softmax output layer is the de facto approach of late when dealing with document classification problems. This technique is not adequate when labeled examples are not available at training time and when the metadata artifacts in a document must be exploited. We address these challenges by generating document representations that capture both text and metadata artifacts in a task agnostic manner. Instead of traditional auto-regressive or auto-encoding based training, our novel self-supervised approach learns a soft-partition of the input space when generating text embeddings. Specifically, we employ a pre-learned topic model distribution as surrogate labels and construct a loss function based on KL divergence. Our solution also incorporates metadata explicitly rather than just augmenting them with text. The generated document embeddings exhibit compositional characteristics and are directly used by downstream classification tasks to create decision boundaries from a small number of labeled examples, thereby eschewing complicated recognition methods. We demonstrate through extensive evaluation that our proposed cross-model fusion solution outperforms several competitive baselines on multiple datasets.
Whole-Body MPC and Online Gait Sequence Generation for Wheeled-Legged Robots
Oct 13, 2020
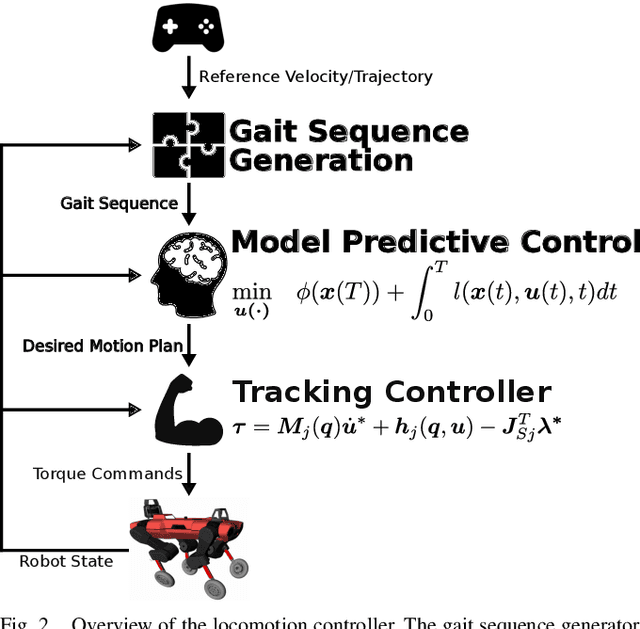
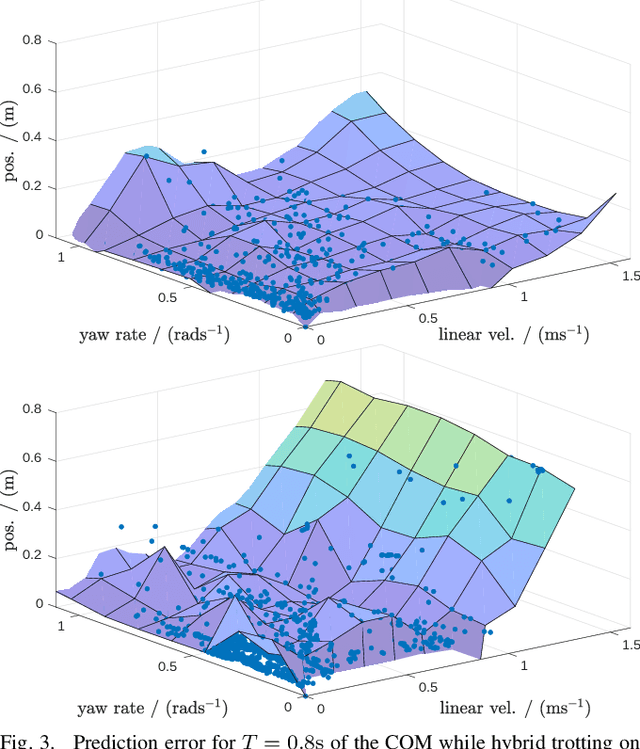
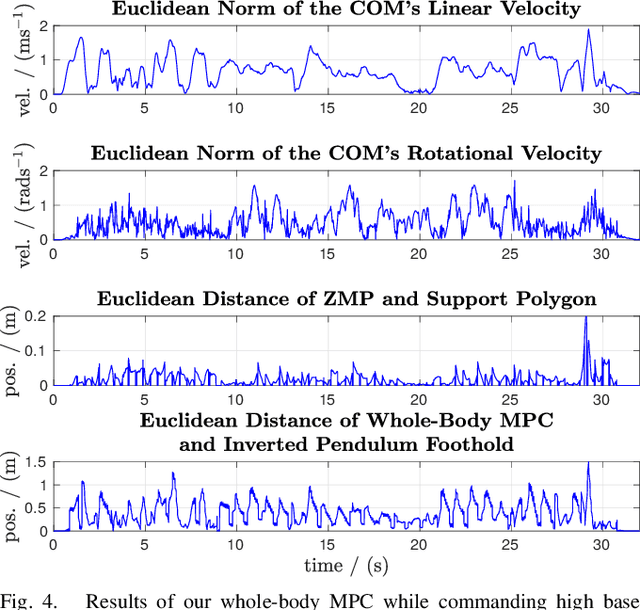
The additional degrees of freedom and missing counterparts in nature make designing locomotion capabilities for wheeled-legged robots more challenging. We propose a whole-body model predictive controller as a single task formulation that simultaneously optimizes wheel and torso motions. Due to the real-time joint velocity and ground reaction force optimization based on a kinodynamic model, our approach accurately captures the real robot's dynamics and automatically discovers complex and dynamic motions cumbersome to hand-craft through heuristics. Thanks to the single set of parameters for all behaviors, whole-body optimization makes online gait sequence adaptation possible. Aperiodic gait sequences are automatically found through kinematic leg utilities without the need for predefined contact and lift-off timings. Also, this enables us to reduce the cost of transport of wheeled-legged robots significantly. Our experiments demonstrate highly dynamic motions on a quadrupedal robot with non-steerable wheels in challenging indoor and outdoor environments. Herewith, we verify that a single task formulation is key to reveal the full potential of wheeled-legged robots.