 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Directed Time Series Regression for Control
Jun 26, 2012
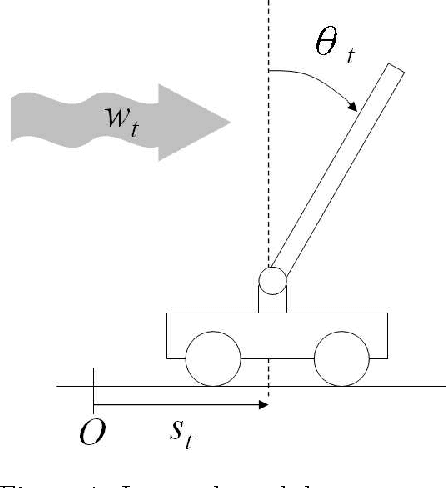
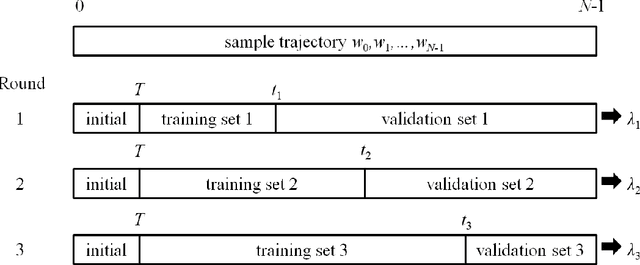
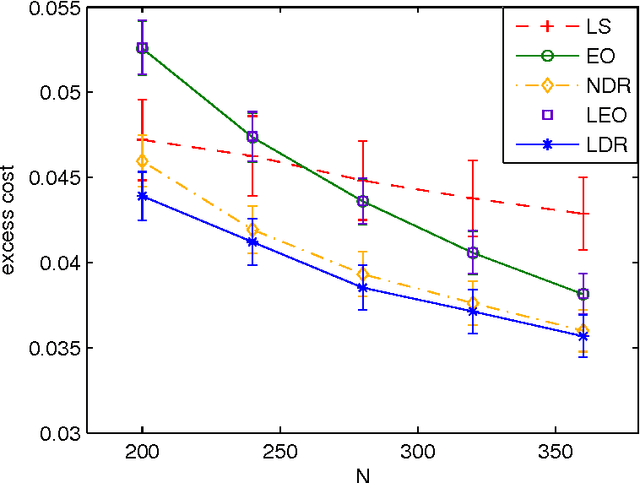
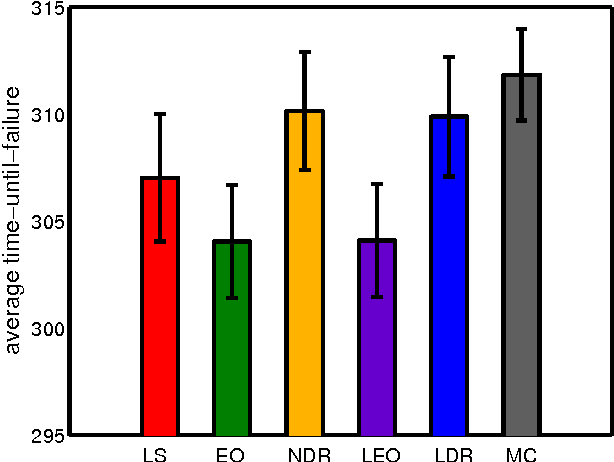
We propose directed time series regression, a new approach to estimating parameters of time-series models for use in certainty equivalent model predictive control. The approach combines merits of least squares regression and empirical optimization. Through a computational study involving a stochastic version of a well known inverted pendulum balancing problem, we demonstrate that directed time series regression can generate significant improvements in controller performance over either of the aforementioned alternatives.
No more 996: Understanding Deep Learning Inference Serving with an Automatic Benchmarking System
Nov 12, 2020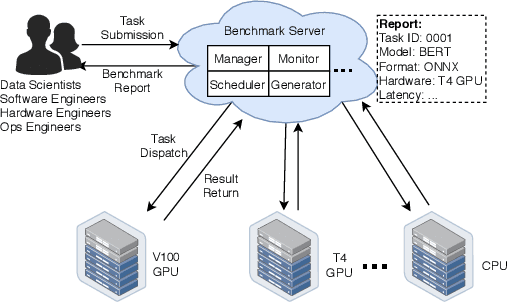

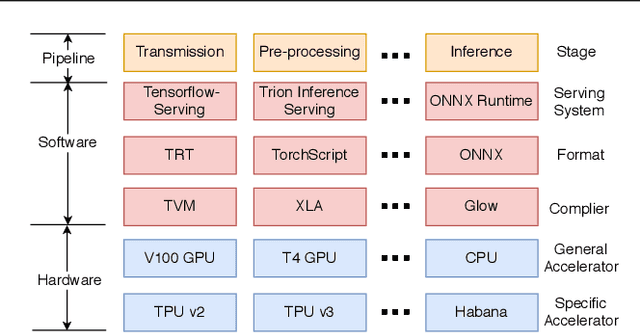
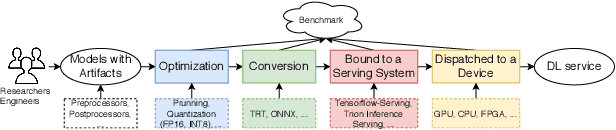
Deep learning (DL) models have become core modules for many applications. However, deploying these models without careful performance benchmarking that considers both hardware and software's impact often leads to poor service and costly operational expenditure. To facilitate DL models' deployment, we implement an automatic and comprehensive benchmark system for DL developers. To accomplish benchmark-related tasks, the developers only need to prepare a configuration file consisting of a few lines of code. Our system, deployed to a leader server in DL clusters, will dispatch users' benchmark jobs to follower workers. Next, the corresponding requests, workload, and even models can be generated automatically by the system to conduct DL serving benchmarks. Finally, developers can leverage many analysis tools and models in our system to gain insights into the trade-offs of different system configurations. In addition, a two-tier scheduler is incorporated to avoid unnecessary interference and improve average job compilation time by up to 1.43x (equivalent of 30\% reduction). Our system design follows the best practice in DL clusters operations to expedite day-to-day DL service evaluation efforts by the developers. We conduct many benchmark experiments to provide in-depth and comprehensive evaluations. We believe these results are of great values as guidelines for DL service configuration and resource allocation.
A Ranking-based, Balanced Loss Function Unifying Classification and Localisation in Object Detection
Oct 23, 2020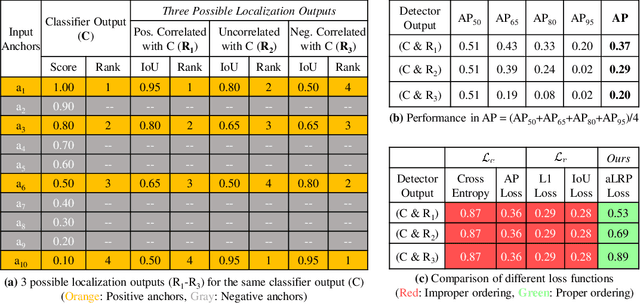

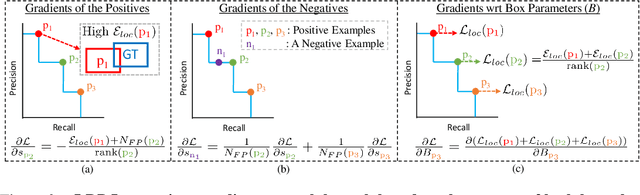

We propose \textit{average Localisation-Recall-Precision} (aLRP), a unified, bounded, balanced and ranking-based loss function for both classification and localisation tasks in object detection. aLRP extends the Localisation-Recall-Precision (LRP) performance metric (Oksuz et al., 2018) inspired from how Average Precision (AP) Loss extends precision to a ranking-based loss function for classification (Chen et al., 2020). aLRP has the following distinct advantages: (i) aLRP is the first ranking-based loss function for both classification and localisation tasks. (ii) Thanks to using ranking for both tasks, aLRP naturally enforces high-quality localisation for high-precision classification. (iii) aLRP provides provable balance between positives and negatives. (iv) Compared to on average $\sim$6 hyperparameters in the loss functions of state-of-the-art detectors, aLRP Loss has only one hyperparameter, which we did not tune in practice. On the COCO dataset, aLRP Loss improves its ranking-based predecessor, AP Loss, up to around $5$ AP points, achieves $48.9$ AP without test time augmentation and outperforms all one-stage detectors. Code available at: https://github.com/kemaloksuz/aLRPLoss .
A Low Complexity Decentralized Neural Net with Centralized Equivalence using Layer-wise Learning
Sep 29, 2020
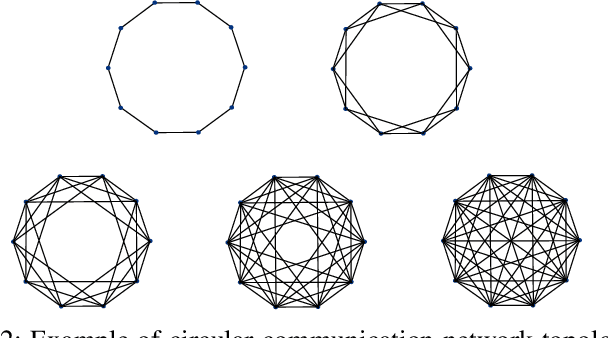
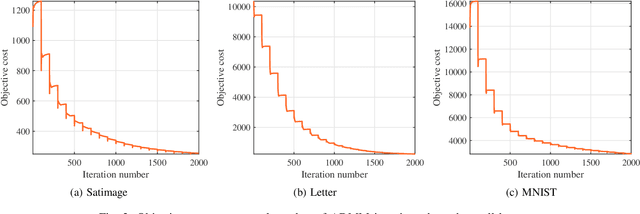
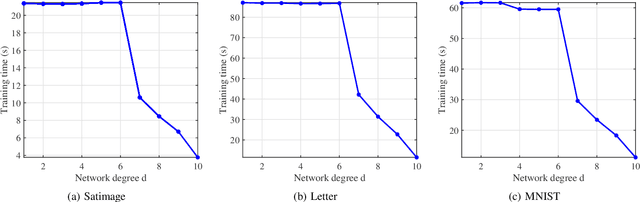
We design a low complexity decentralized learning algorithm to train a recently proposed large neural network in distributed processing nodes (workers). We assume the communication network between the workers is synchronized and can be modeled as a doubly-stochastic mixing matrix without having any master node. In our setup, the training data is distributed among the workers but is not shared in the training process due to privacy and security concerns. Using alternating-direction-method-of-multipliers (ADMM) along with a layerwise convex optimization approach, we propose a decentralized learning algorithm which enjoys low computational complexity and communication cost among the workers. We show that it is possible to achieve equivalent learning performance as if the data is available in a single place. Finally, we experimentally illustrate the time complexity and convergence behavior of the algorithm.
Improvement of Classification in One-Stage Detector
Nov 20, 2020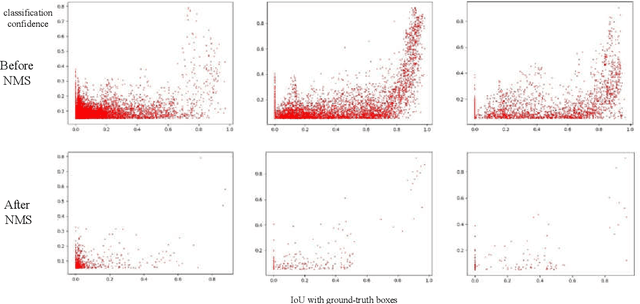
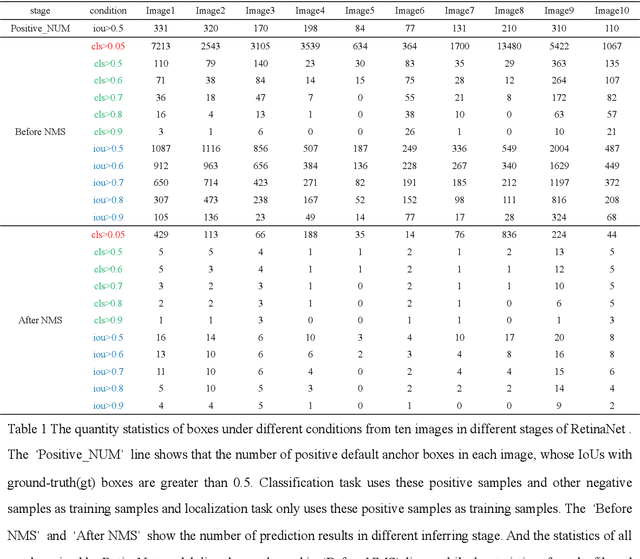
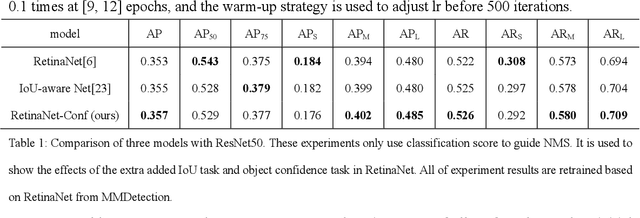
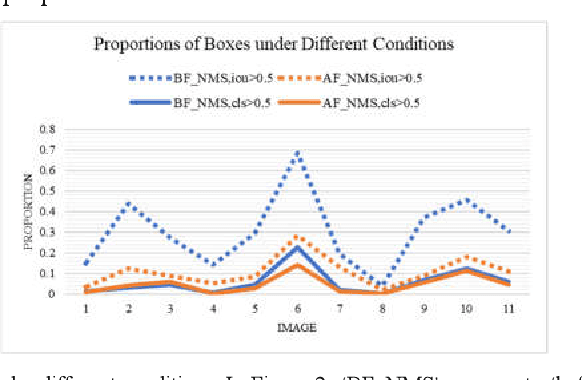
RetinaNet proposed Focal Loss for classification task and improved one-stage detectors greatly. However, there is still a gap between it and two-stage detectors. We analyze the prediction of RetinaNet and find that the misalignment of classification and localization is the main factor. Most of predicted boxes, whose IoU with ground-truth boxes are greater than 0.5, while their classification scores are lower than 0.5, which shows that the classification task still needs to be optimized. In this paper we proposed an object confidence task for this problem, and it shares features with classification task. This task uses IoUs between samples and ground-truth boxes as targets, and it only uses losses of positive samples in training, which can increase loss weight of positive samples in classification task training. Also the joint of classification score and object confidence will be used to guide NMS. Our method can not only improve classification task, but also ease misalignment of classification and localization. To evaluate the effectiveness of this method, we show our experiments on MS COCO 2017 dataset. Without whistles and bells, our method can improve AP by 0.7% and 1.0% on COCO validation dataset with ResNet50 and ResNet101 respectively at same training configs, and it can achieve 38.4% AP with two times training time. Code is at: http://github.com/chenzuge1/RetinaNet-Conf.git.
A Comparative Study of Deep Learning Loss Functions for Multi-Label Remote Sensing Image Classification
Sep 29, 2020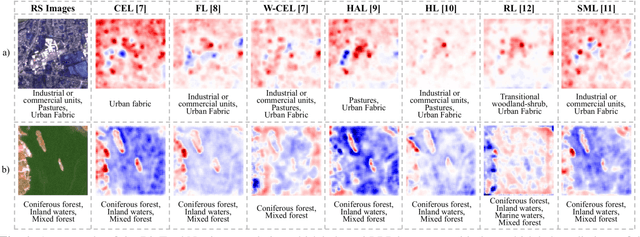
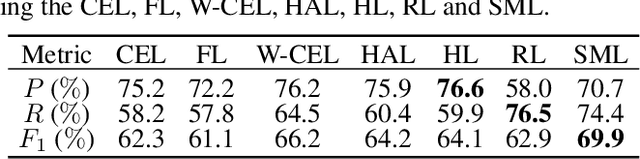
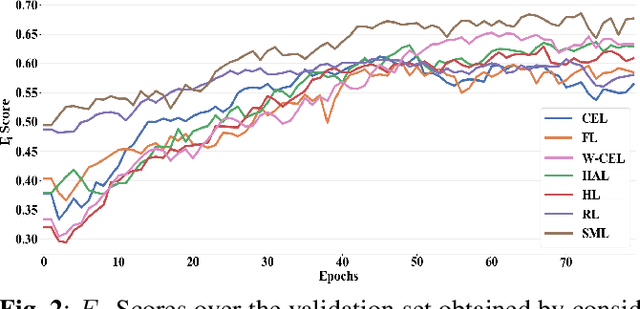
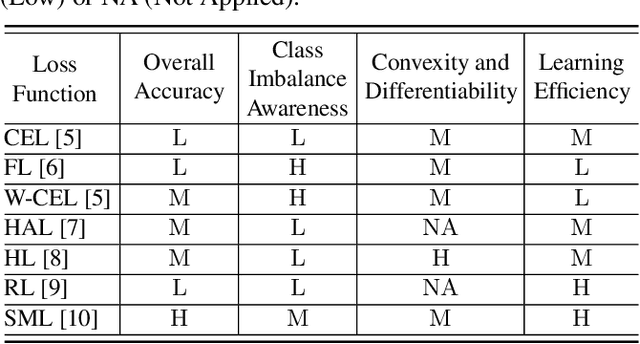
This paper analyzes and compares different deep learning loss functions in the framework of multi-label remote sensing (RS) image scene classification problems. We consider seven loss functions: 1) cross-entropy loss; 2) focal loss; 3) weighted cross-entropy loss; 4) Hamming loss; 5) Huber loss; 6) ranking loss; and 7) sparseMax loss. All the considered loss functions are analyzed for the first time in RS. After a theoretical analysis, an experimental analysis is carried out to compare the considered loss functions in terms of their: 1) overall accuracy; 2) class imbalance awareness (for which the number of samples associated to each class significantly varies); 3) convexibility and differentiability; and 4) learning efficiency (i.e., convergence speed). On the basis of our analysis, some guidelines are derived for a proper selection of a loss function in multi-label RS scene classification problems.
Learning in the Wild with Incremental Skeptical Gaussian Processes
Nov 02, 2020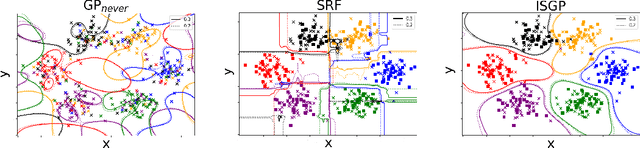
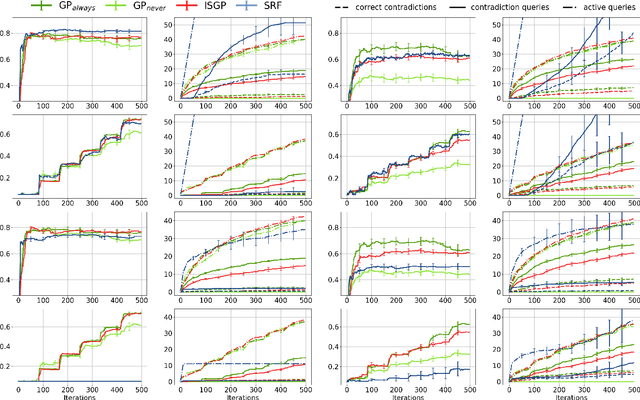

The ability to learn from human supervision is fundamental for personal assistants and other interactive applications of AI. Two central challenges for deploying interactive learners in the wild are the unreliable nature of the supervision and the varying complexity of the prediction task. We address a simple but representative setting, incremental classification in the wild, where the supervision is noisy and the number of classes grows over time. In order to tackle this task, we propose a redesign of skeptical learning centered around Gaussian Processes (GPs). Skeptical learning is a recent interactive strategy in which, if the machine is sufficiently confident that an example is mislabeled, it asks the annotator to reconsider her feedback. In many cases, this is often enough to obtain clean supervision. Our redesign, dubbed ISGP, leverages the uncertainty estimates supplied by GPs to better allocate labeling and contradiction queries, especially in the presence of noise. Our experiments on synthetic and real-world data show that, as a result, while the original formulation of skeptical learning produces over-confident models that can fail completely in the wild, ISGP works well at varying levels of noise and as new classes are observed.
* 7 pages, 3 figures, code: https://gitlab.com/abonte/incremental-skeptical-gp
Ultra-Low-Power FDSOI Neural Circuits for Extreme-Edge Neuromorphic Intelligence
Jul 14, 2020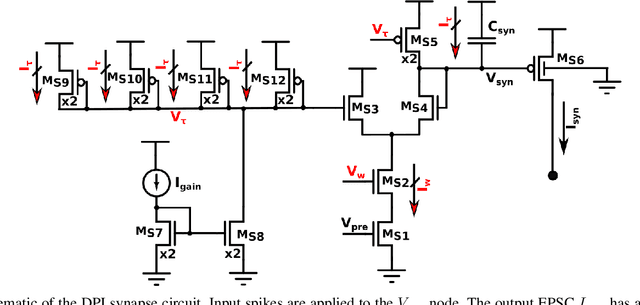
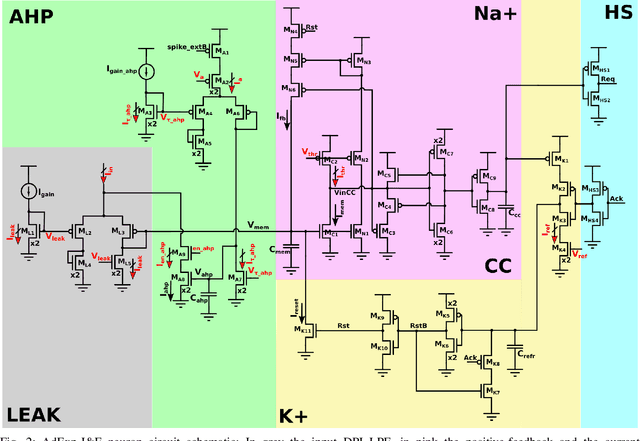
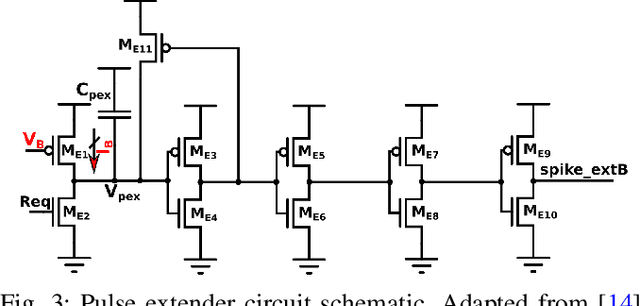
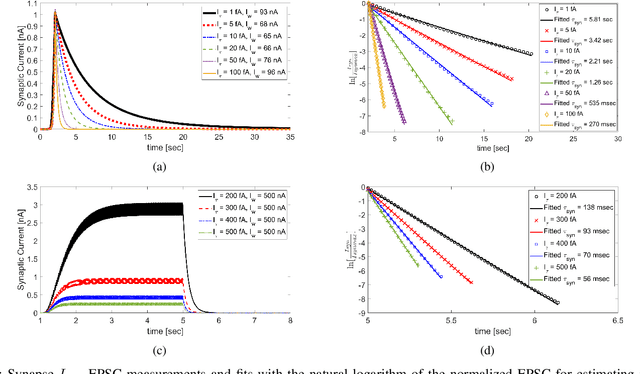
Recent years have seen an increasing interest in the development of artificial intelligence circuits and systems for edge computing applications. In-memory computing mixed-signal neuromorphic architectures provide promising ultra-low-power solutions for edge-computing sensory-processing applications, thanks to their ability to emulate spiking neural networks in real-time. The fine-grain parallelism offered by this approach allows such neural circuits to process the sensory data efficiently by adapting their dynamics to the ones of the sensed signals, without having to resort to the time-multiplexed computing paradigm of von Neumann architectures. To reduce power consumption even further, we present a set of mixed-signal analog/digital circuits that exploit the features of advanced Fully-Depleted Silicon on Insulator (FDSOI) integration processes. Specifically, we explore the options of advanced FDSOI technologies to address analog design issues and optimize the design of the synapse integrator and of the adaptive neuron circuits accordingly. We present circuit simulation results and demonstrate the circuit's ability to produce biologically plausible neural dynamics with compact designs, optimized for the realization of large-scale spiking neural networks in neuromorphic processors.
Quantitative Propagation of Chaos for SGD in Wide Neural Networks
Jul 14, 2020In this paper, we investigate the limiting behavior of a continuous-time counterpart of the Stochastic Gradient Descent (SGD) algorithm applied to two-layer overparameterized neural networks, as the number or neurons (ie, the size of the hidden layer) $N \to +\infty$. Following a probabilistic approach, we show 'propagation of chaos' for the particle system defined by this continuous-time dynamics under different scenarios, indicating that the statistical interaction between the particles asymptotically vanishes. In particular, we establish quantitative convergence with respect to $N$ of any particle to a solution of a mean-field McKean-Vlasov equation in the metric space endowed with the Wasserstein distance. In comparison to previous works on the subject, we consider settings in which the sequence of stepsizes in SGD can potentially depend on the number of neurons and the iterations. We then identify two regimes under which different mean-field limits are obtained, one of them corresponding to an implicitly regularized version of the minimization problem at hand. We perform various experiments on real datasets to validate our theoretical results, assessing the existence of these two regimes on classification problems and illustrating our convergence results.
Seasonal-adjustment Based Feature Selection Method for Large-scale Search Engine Logs
Aug 22, 2020



Search engine logs have a great potential in tracking and predicting outbreaks of infectious disease. More precisely, one can use the search volume of some search terms to predict the infection rate of an infectious disease in nearly real-time. However, conducting accurate and stable prediction of outbreaks using search engine logs is a challenging task due to the following two-way instability characteristics of the search logs. First, the search volume of a search term may change irregularly in the short-term, for example, due to environmental factors such as the amount of media or news. Second, the search volume may also change in the long-term due to the demographic change of the search engine. That is to say, if a model is trained with such search logs with ignoring such characteristic, the resulting prediction would contain serious mispredictions when these changes occur. In this work, we proposed a novel feature selection method to overcome this instability problem. In particular, we employ a seasonal-adjustment method that decomposes each time series into three components: seasonal, trend and irregular component and build prediction models for each component individually. We also carefully design a feature selection method to select proper search terms to predict each component. We conducted comprehensive experiments on ten different kinds of infectious diseases. The experimental results show that the proposed method outperforms all comparative methods in prediction accuracy for seven of ten diseases, in both now-casting and forecasting setting. Also, the proposed method is more successful in selecting search terms that are semantically related to target diseases.