 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Automated Contrastive Learning Strategy Search for Time Series
Mar 19, 2024
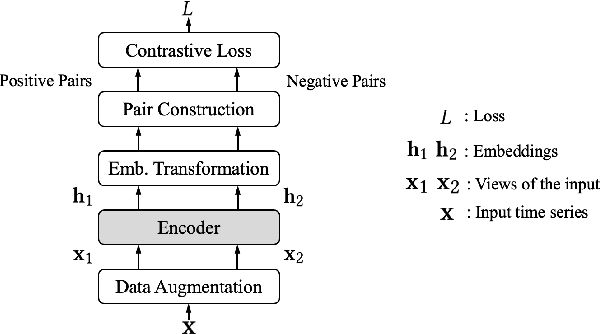
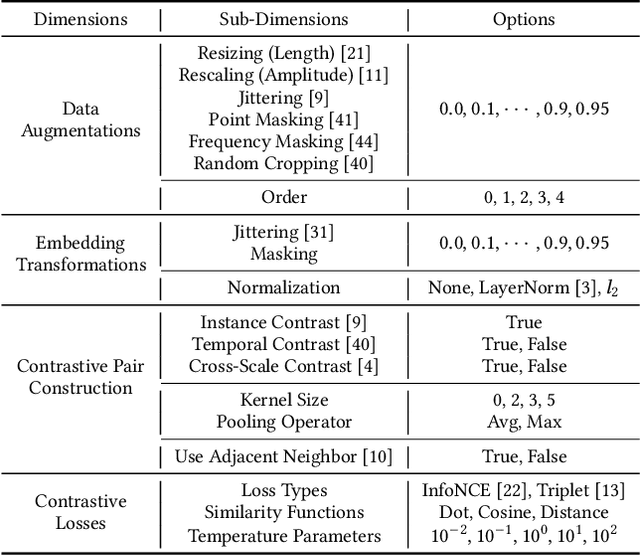
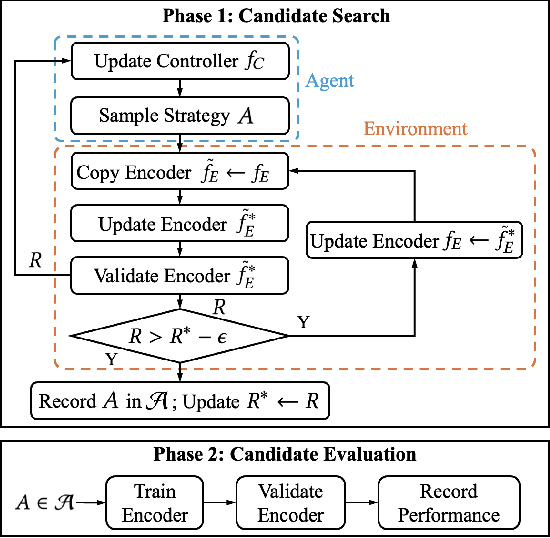
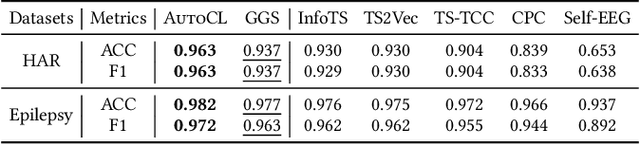
In recent years, Contrastive Learning (CL) has become a predominant representation learning paradigm for time series. Most existing methods in the literature focus on manually building specific Contrastive Learning Strategies (CLS) by human heuristics for certain datasets and tasks. However, manually developing CLS usually require excessive prior knowledge about the datasets and tasks, e.g., professional cognition of the medical time series in healthcare, as well as huge human labor and massive experiments to determine the detailed learning configurations. In this paper, we present an Automated Machine Learning (AutoML) practice at Microsoft, which automatically learns to contrastively learn representations for various time series datasets and tasks, namely Automated Contrastive Learning (AutoCL). We first construct a principled universal search space of size over 3x1012, covering data augmentation, embedding transformation, contrastive pair construction and contrastive losses. Further, we introduce an efficient reinforcement learning algorithm, which optimizes CLS from the performance on the validation tasks, to obtain more effective CLS within the space. Experimental results on various real-world tasks and datasets demonstrate that AutoCL could automatically find the suitable CLS for a given dataset and task. From the candidate CLS found by AutoCL on several public datasets/tasks, we compose a transferable Generally Good Strategy (GGS), which has a strong performance for other datasets. We also provide empirical analysis as a guidance for future design of CLS.
Long-form factuality in large language models
Apr 03, 2024Large language models (LLMs) often generate content that contains factual errors when responding to fact-seeking prompts on open-ended topics. To benchmark a model's long-form factuality in open domains, we first use GPT-4 to generate LongFact, a prompt set comprising thousands of questions spanning 38 topics. We then propose that LLM agents can be used as automated evaluators for long-form factuality through a method which we call Search-Augmented Factuality Evaluator (SAFE). SAFE utilizes an LLM to break down a long-form response into a set of individual facts and to evaluate the accuracy of each fact using a multi-step reasoning process comprising sending search queries to Google Search and determining whether a fact is supported by the search results. Furthermore, we propose extending F1 score as an aggregated metric for long-form factuality. To do so, we balance the percentage of supported facts in a response (precision) with the percentage of provided facts relative to a hyperparameter representing a user's preferred response length (recall). Empirically, we demonstrate that LLM agents can outperform crowdsourced human annotators - on a set of ~16k individual facts, SAFE agrees with crowdsourced human annotators 72% of the time, and on a random subset of 100 disagreement cases, SAFE wins 76% of the time. At the same time, SAFE is more than 20 times cheaper than human annotators. We also benchmark thirteen language models on LongFact across four model families (Gemini, GPT, Claude, and PaLM-2), finding that larger language models generally achieve better long-form factuality. LongFact, SAFE, and all experimental code are available at https://github.com/google-deepmind/long-form-factuality.
An Optimization Framework to Personalize Passive Cardiac Mechanics
Apr 06, 2024Personalized cardiac mechanics modeling is a powerful tool for understanding the biomechanics of cardiac function in health and disease and assisting in treatment planning. However, current models are limited to using medical images acquired at a single cardiac phase, often limiting their applicability for processing dynamic image acquisitions. This study introduces an inverse finite element analysis (iFEA) framework to estimate the passive mechanical properties of cardiac tissue using time-dependent medical image data. The iFEA framework relies on a novel nested optimization scheme, in which the outer iterations utilize a traditional optimization method to best approximate material parameters that fit image data, while the inner iterations employ an augmented Sellier's algorithm to estimate the stress-free reference configuration. With a focus on characterizing the passive mechanical behavior, the framework employs structurally based anisotropic hyperelastic constitutive models and physiologically relevant boundary conditions to simulate myocardial mechanics. We use a stabilized variational multiscale formulation for solving the governing nonlinear elastodynamics equations, verified for cardiac mechanics applications. The framework is tested in myocardium models of biventricle and left atrium derived from cardiac phase-resolved computed tomographic (CT) images of a healthy subject and three patients with hypertrophic obstructive cardiomyopathy (HOCM). The impact of the choice of optimization methods and other numerical settings, including fiber direction parameters, mesh size, initial parameters for optimization, and perturbations to optimal material parameters, is assessed using a rigorous sensitivity analysis. The performance of the current iFEA is compared against an assumed power-law-based pressure-volume relation, typically used for single-phase image acquisition.
Capsule Neural Networks as Noise Stabilizer for Time Series Data
Mar 20, 2024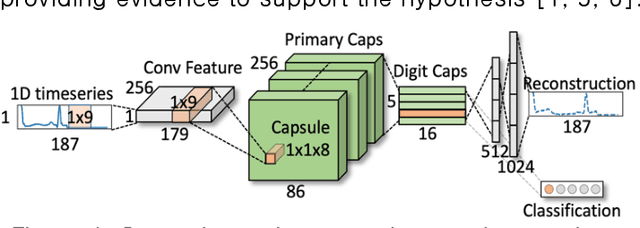
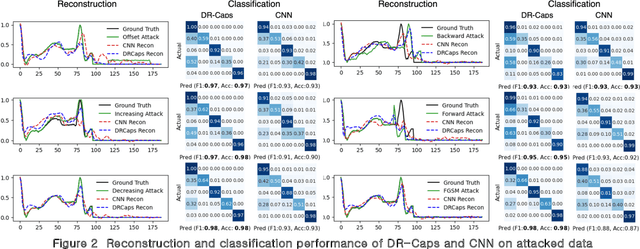
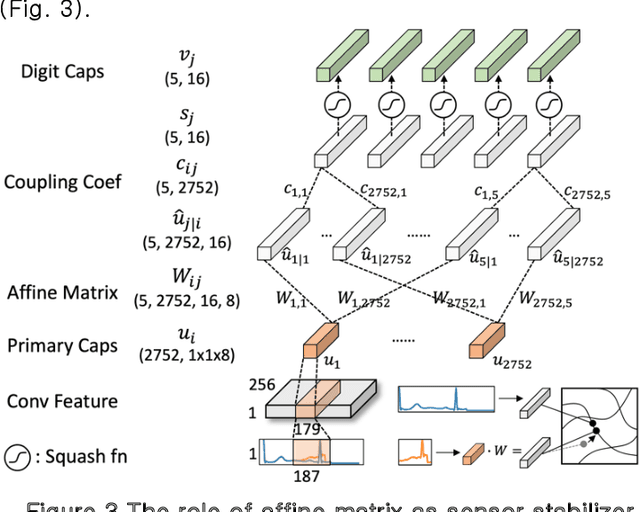

Capsule Neural Networks utilize capsules, which bind neurons into a single vector and learn position equivariant features, which makes them more robust than original Convolutional Neural Networks. CapsNets employ an affine transformation matrix and dynamic routing with coupling coefficients to learn robustly. In this paper, we investigate the effectiveness of CapsNets in analyzing highly sensitive and noisy time series sensor data. To demonstrate CapsNets robustness, we compare their performance with original CNNs on electrocardiogram data, a medical time series sensor data with complex patterns and noise. Our study provides empirical evidence that CapsNets function as noise stabilizers, as investigated by manual and adversarial attack experiments using the fast gradient sign method and three manual attacks, including offset shifting, gradual drift, and temporal lagging. In summary, CapsNets outperform CNNs in both manual and adversarial attacked data. Our findings suggest that CapsNets can be effectively applied to various sensor systems to improve their resilience to noise attacks. These results have significant implications for designing and implementing robust machine learning models in real world applications. Additionally, this study contributes to the effectiveness of CapsNet models in handling noisy data and highlights their potential for addressing the challenges of noise data in time series analysis.
* 3 pages, 3 figures
TEeVTOL: Balancing Energy and Time Efficiency in eVTOL Aircraft Path Planning Across City-Scale Wind Fields
Mar 21, 2024Electric vertical-takeoff and landing (eVTOL) aircraft, recognized for their maneuverability and flexibility, offer a promising alternative to our transportation system. However, the operational effectiveness of these aircraft faces many challenges, such as the delicate balance between energy and time efficiency, stemming from unpredictable environmental factors, including wind fields. Mathematical modeling-based approaches have been adopted to plan aircraft flight path in urban wind fields with the goal to save energy and time costs. While effective, they are limited in adapting to dynamic and complex environments. To optimize energy and time efficiency in eVTOL's flight through dynamic wind fields, we introduce a novel path planning method leveraging deep reinforcement learning. We assess our method with extensive experiments, comparing it to Dijkstra's algorithm -- the theoretically optimal approach for determining shortest paths in a weighted graph, where weights represent either energy or time cost. The results show that our method achieves a graceful balance between energy and time efficiency, closely resembling the theoretically optimal values for both objectives.
Marrying NeRF with Feature Matching for One-step Pose Estimation
Apr 01, 2024Given the image collection of an object, we aim at building a real-time image-based pose estimation method, which requires neither its CAD model nor hours of object-specific training. Recent NeRF-based methods provide a promising solution by directly optimizing the pose from pixel loss between rendered and target images. However, during inference, they require long converging time, and suffer from local minima, making them impractical for real-time robot applications. We aim at solving this problem by marrying image matching with NeRF. With 2D matches and depth rendered by NeRF, we directly solve the pose in one step by building 2D-3D correspondences between target and initial view, thus allowing for real-time prediction. Moreover, to improve the accuracy of 2D-3D correspondences, we propose a 3D consistent point mining strategy, which effectively discards unfaithful points reconstruted by NeRF. Moreover, current NeRF-based methods naively optimizing pixel loss fail at occluded images. Thus, we further propose a 2D matches based sampling strategy to preclude the occluded area. Experimental results on representative datasets prove that our method outperforms state-of-the-art methods, and improves inference efficiency by 90x, achieving real-time prediction at 6 FPS.
Kalman filter based localization in hybrid BLE-UWB positioning system
Apr 02, 2024In this paper a concept of hybrid Bluetooth Low Energy (BLE) Ultra-wideband (UWB) positioning system is presented. The system is intended to be energy efficient. Low energy BLE unit is used as a primary source of measurement data and for most of the time localization is calculated based on received signal strength (RSS). UWB technology is used less often. Time difference of arrival (TDOA) values measured with UWB radios are periodically used to improve RSS based localization. The paper contains a description of proposed hybrid positioning algorithm. Results of simulations and experiments confirming algorithm's efficiency are also included.
MI-NeRF: Learning a Single Face NeRF from Multiple Identities
Apr 03, 2024
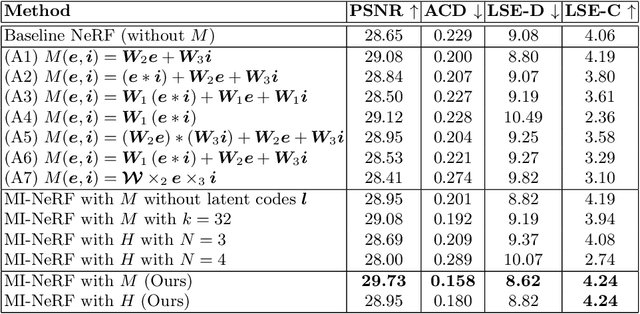
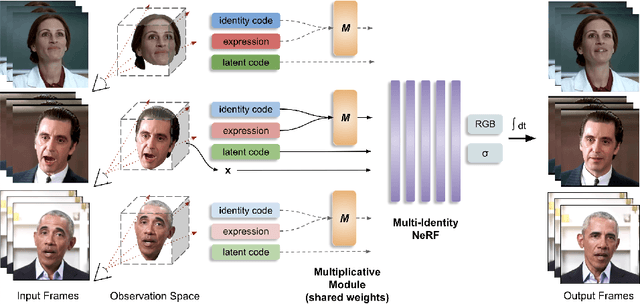
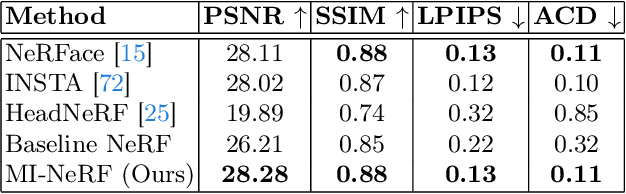
In this work, we introduce a method that learns a single dynamic neural radiance field (NeRF) from monocular talking face videos of multiple identities. NeRFs have shown remarkable results in modeling the 4D dynamics and appearance of human faces. However, they require per-identity optimization. Although recent approaches have proposed techniques to reduce the training and rendering time, increasing the number of identities can be expensive. We introduce MI-NeRF (multi-identity NeRF), a single unified network that models complex non-rigid facial motion for multiple identities, using only monocular videos of arbitrary length. The core premise in our method is to learn the non-linear interactions between identity and non-identity specific information with a multiplicative module. By training on multiple videos simultaneously, MI-NeRF not only reduces the total training time compared to standard single-identity NeRFs, but also demonstrates robustness in synthesizing novel expressions for any input identity. We present results for both facial expression transfer and talking face video synthesis. Our method can be further personalized for a target identity given only a short video.
Evaluating the Effectiveness of Artificial Intelligence in Predicting Adverse Drug Reactions among Cancer Patients: A Systematic Review and Meta-Analysis
Apr 06, 2024Adverse drug reactions considerably impact patient outcomes and healthcare costs in cancer therapy. Using artificial intelligence to predict adverse drug reactions in real time could revolutionize oncology treatment. This study aims to assess the performance of artificial intelligence models in predicting adverse drug reactions in patients with cancer. This is the first systematic review and meta-analysis. Scopus, PubMed, IEEE Xplore, and ACM Digital Library databases were searched for studies in English, French, and Arabic from January 1, 2018, to August 20, 2023. The inclusion criteria were: (1) peer-reviewed research articles; (2) use of artificial intelligence algorithms (machine learning, deep learning, knowledge graphs); (3) study aimed to predict adverse drug reactions (cardiotoxicity, neutropenia, nephrotoxicity, hepatotoxicity); (4) study was on cancer patients. The data were extracted and evaluated by three reviewers for study quality. Of the 332 screened articles, 17 studies (5%) involving 93,248 oncology patients from 17 countries were included in the systematic review, of which ten studies synthesized the meta-analysis. A random-effects model was created to pool the sensitivity, specificity, and AUC of the included studies. The pooled results were 0.82 (95% CI:0.69, 0.9), 0.84 (95% CI:0.75, 0.9), and 0.83 (95% CI:0.77, 0.87) for sensitivity, specificity, and AUC, respectively, of ADR predictive models. Biomarkers proved their effectiveness in predicting ADRs, yet they were adopted by only half of the reviewed studies. The use of AI in cancer treatment shows great potential, with models demonstrating high specificity and sensitivity in predicting ADRs. However, standardized research and multicenter studies are needed to improve the quality of evidence. AI can enhance cancer patient care by bridging the gap between data-driven insights and clinical expertise.
A self-attention model for robust rigid slice-to-volume registration of functional MRI
Apr 06, 2024Functional Magnetic Resonance Imaging (fMRI) is vital in neuroscience, enabling investigations into brain disorders, treatment monitoring, and brain function mapping. However, head motion during fMRI scans, occurring between shots of slice acquisition, can result in distortion, biased analyses, and increased costs due to the need for scan repetitions. Therefore, retrospective slice-level motion correction through slice-to-volume registration (SVR) is crucial. Previous studies have utilized deep learning (DL) based models to address the SVR task; however, they overlooked the uncertainty stemming from the input stack of slices and did not assign weighting or scoring to each slice. In this work, we introduce an end-to-end SVR model for aligning 2D fMRI slices with a 3D reference volume, incorporating a self-attention mechanism to enhance robustness against input data variations and uncertainties. It utilizes independent slice and volume encoders and a self-attention module to assign pixel-wise scores for each slice. We conducted evaluation experiments on 200 images involving synthetic rigid motion generated from 27 subjects belonging to the test set, from the publicly available Healthy Brain Network (HBN) dataset. Our experimental results demonstrate that our model achieves competitive performance in terms of alignment accuracy compared to state-of-the-art deep learning-based methods (Euclidean distance of $0.93$ [mm] vs. $1.86$ [mm]). Furthermore, our approach exhibits significantly faster registration speed compared to conventional iterative methods ($0.096$ sec. vs. $1.17$ sec.). Our end-to-end SVR model facilitates real-time head motion tracking during fMRI acquisition, ensuring reliability and robustness against uncertainties in inputs. source code, which includes the training and evaluations, will be available soon.