 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
VOR Adaptation on a Humanoid iCub Robot Using a Spiking Cerebellar Model
Mar 03, 2020

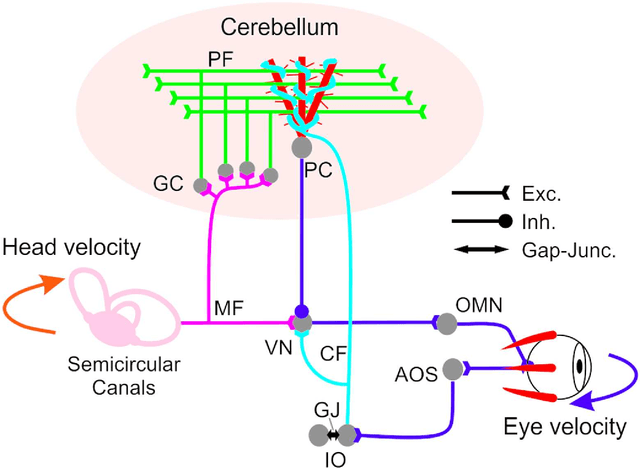
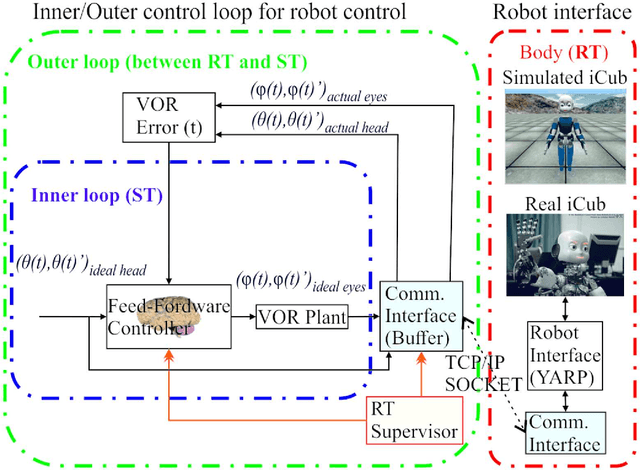
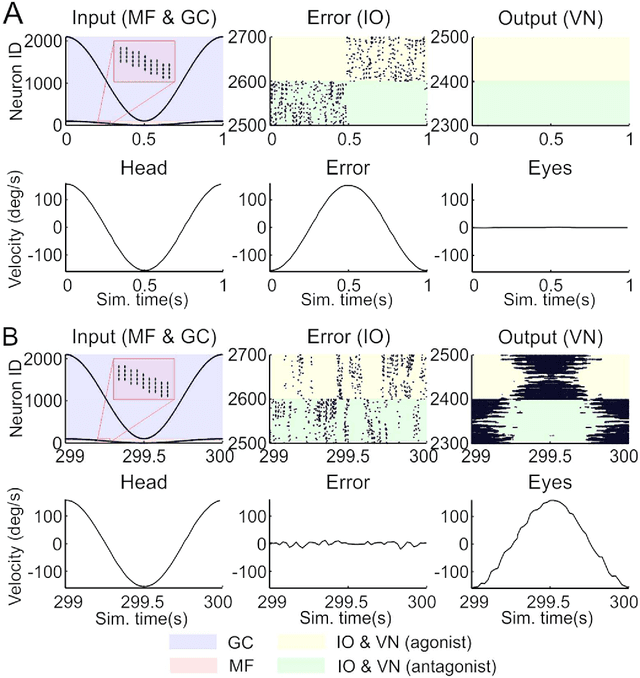
We embed a spiking cerebellar model within an adaptive real-time (RT) control loop that is able to operate a real robotic body (iCub) when performing different vestibulo-ocular reflex (VOR) tasks. The spiking neural network computation, including event- and time-driven neural dynamics, neural activity, and spike-timing dependent plasticity (STDP) mechanisms, leads to a nondeterministic computation time caused by the neural activity volleys encountered during cerebellar simulation. This nondeterministic computation time motivates the integration of an RT supervisor module that is able to ensure a well-orchestrated neural computation time and robot operation. Actually, our neurorobotic experimental setup (VOR) benefits from the biological sensory motor delay between the cerebellum and the body to buffer the computational overloads as well as providing flexibility in adjusting the neural computation time and RT operation. The RT supervisor module provides for incremental countermeasures that dynamically slow down or speed up the cerebellar simulation by either halting the simulation or disabling certain neural computation features (i.e., STDP mechanisms, spike propagation, and neural updates) to cope with the RT constraints imposed by the real robot operation. This neurorobotic experimental setup is applied to different horizontal and vertical VOR adaptive tasks that are widely used by the neuroscientific community to address cerebellar functioning. We aim to elucidate the manner in which the combination of the cerebellar neural substrate and the distributed plasticity shapes the cerebellar neural activity to mediate motor adaptation. This paper underlies the need for a two-stage learning process to facilitate VOR acquisition.
Stochastic Modified Equations for Continuous Limit of Stochastic ADMM
Mar 07, 2020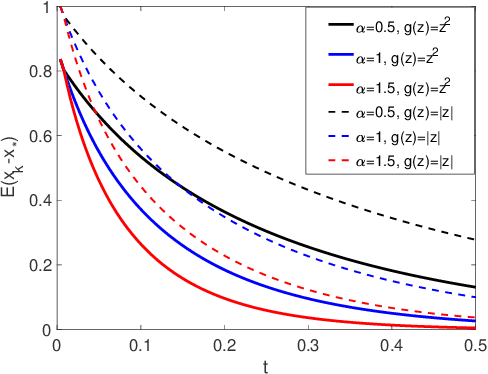
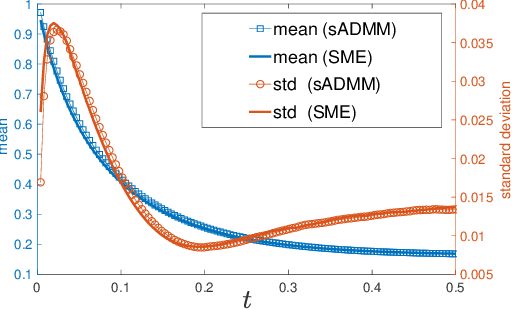
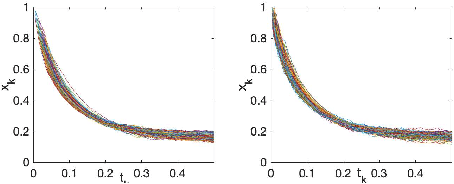
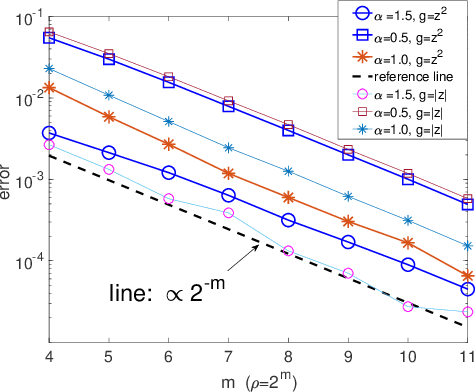
Stochastic version of alternating direction method of multiplier (ADMM) and its variants (linearized ADMM, gradient-based ADMM) plays a key role for modern large scale machine learning problems. One example is the regularized empirical risk minimization problem. In this work, we put different variants of stochastic ADMM into a unified form, which includes standard, linearized and gradient-based ADMM with relaxation, and study their dynamics via a continuous-time model approach. We adapt the mathematical framework of stochastic modified equation (SME), and show that the dynamics of stochastic ADMM is approximated by a class of stochastic differential equations with small noise parameters in the sense of weak approximation. The continuous-time analysis would uncover important analytical insights into the behaviors of the discrete-time algorithm, which are non-trivial to gain otherwise. For example, we could characterize the fluctuation of the solution paths precisely, and decide optimal stopping time to minimize the variance of solution paths.
Fixing Asymptotic Uncertainty of Bayesian Neural Networks with Infinite ReLU Features
Oct 06, 2020
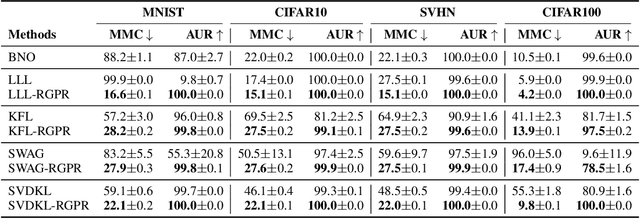

Approximate Bayesian methods can mitigate overconfidence in ReLU networks. However, far away from the training data, even Bayesian neural networks (BNNs) can still underestimate uncertainty and thus be overconfident. We suggest to fix this by considering an infinite number of ReLU features over the input domain that are never part of the training process and thus remain at prior values. Perhaps surprisingly, we show that this model leads to a tractable Gaussian process (GP) term that can be added to a pre-trained BNN's posterior at test time with negligible cost overhead. The BNN then yields structured uncertainty in the proximity of training data, while the GP prior calibrates uncertainty far away from them. As a key contribution, we prove that the added uncertainty yields cubic predictive variance growth, and thus the ideal uniform (maximum entropy) confidence in multi-class classification far from the training data.
Discriminative, Generative and Self-Supervised Approaches for Target-Agnostic Learning
Nov 12, 2020
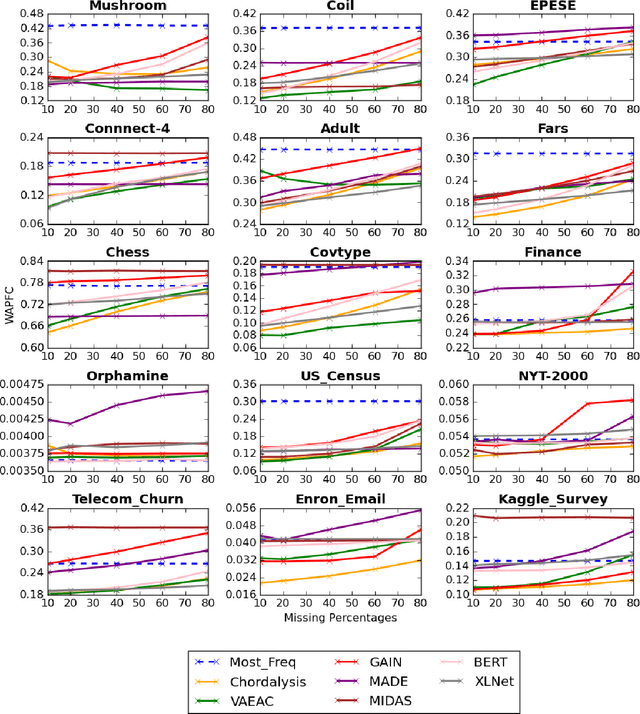
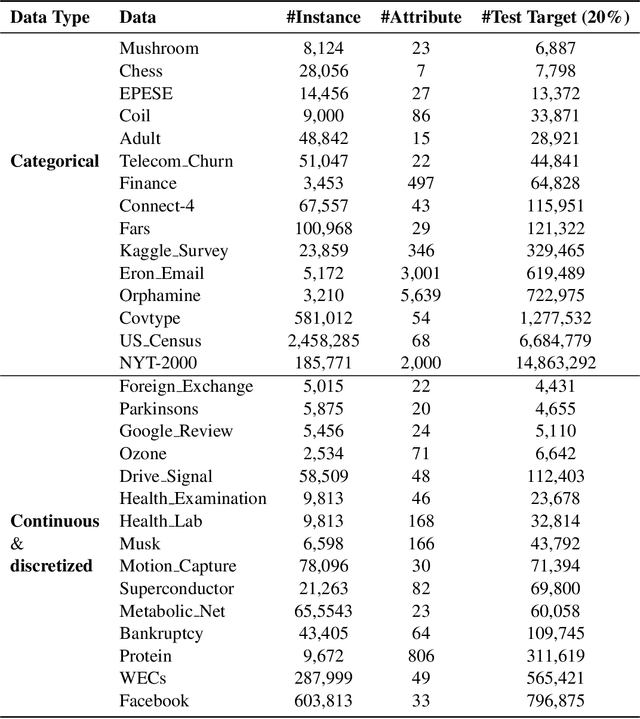
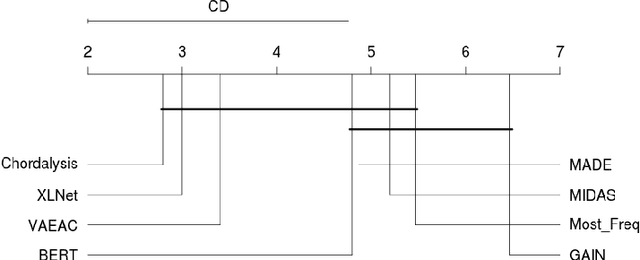
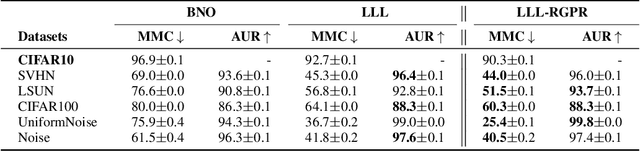
Supervised learning, characterized by both discriminative and generative learning, seeks to predict the values of single (or sometimes multiple) predefined target attributes based on a predefined set of predictor attributes. For applications where the information available and predictions to be made may vary from instance to instance, we propose the task of target-agnostic learning where arbitrary disjoint sets of attributes can be used for each of predictors and targets for each to-be-predicted instance. For this task, we survey a wide range of techniques available for handling missing values, self-supervised training and pseudo-likelihood training, and adapt them to a suite of algorithms that are suitable for the task. We conduct extensive experiments on this suite of algorithms on a large collection of categorical, continuous and discretized datasets, and report their performance in terms of both classification and regression errors. We also report the training and prediction time of these algorithms when handling large-scale datasets. Both generative and self-supervised learning models are shown to perform well at the task, although their characteristics towards the different types of data are quite different. Nevertheless, our derived theorem for the pseudo-likelihood theory also shows that they are related for inferring a joint distribution model based on the pseudo-likelihood training.
Perspective Texture Synthesis Based on Improved Energy Optimization
Jun 21, 2020
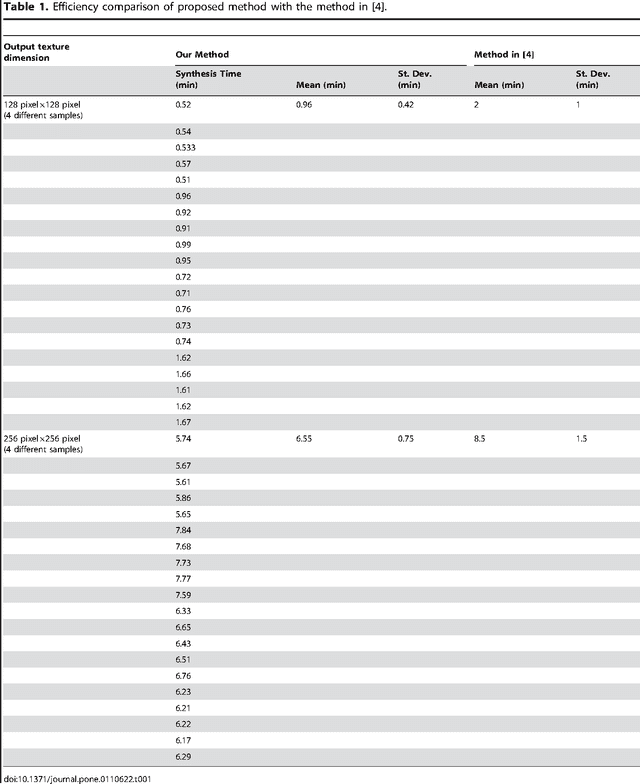
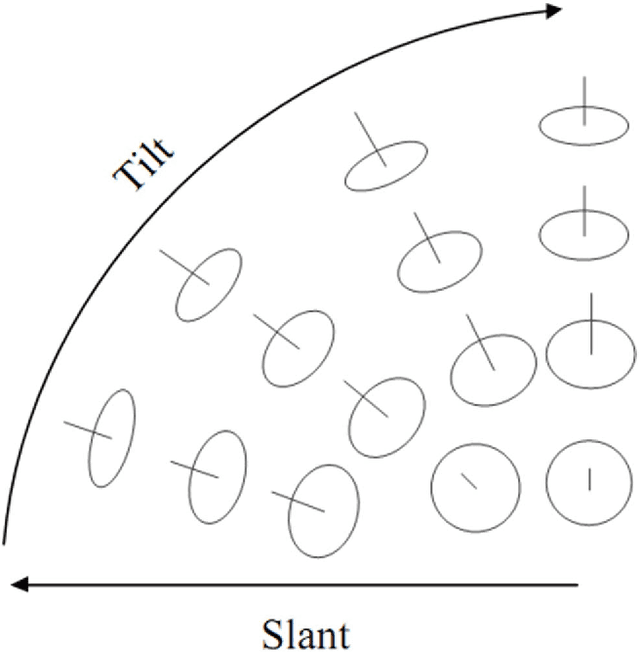
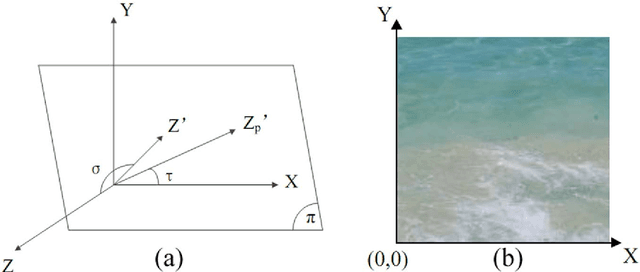
Perspective texture synthesis has great significance in many fields like video editing, scene capturing etc., due to its ability to read and control global feature information. In this paper, we present a novel example-based, specifically energy optimization-based algorithm, to synthesize perspective textures. Energy optimization technique is a pixel-based approach, so it is time-consuming. We improve it from two aspects with the purpose of achieving faster synthesis and high quality. Firstly, we change this pixel-based technique by replacing the pixel computation with a little patch. Secondly, we present a novel technique to accelerate searching nearest neighborhoods in energy optimization. Using k- means clustering technique to build a search tree to accelerate the search. Hence, we make use of principal component analysis (PCA) technique to reduce dimensions of input vectors. The high quality results prove that our approach is feasible. Besides, our proposed algorithm needs shorter time relative to other similar methods.
* Published in PLOS One
On Minimum Word Error Rate Training of the Hybrid Autoregressive Transducer
Oct 23, 2020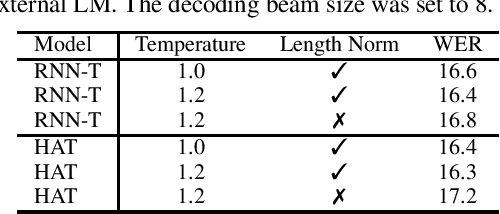
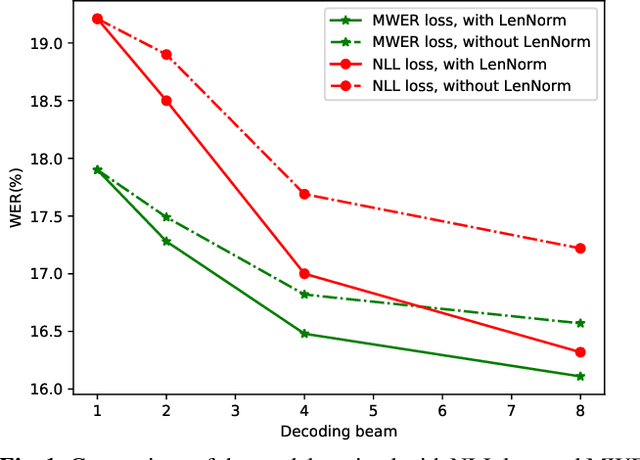
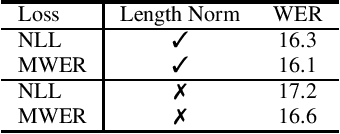
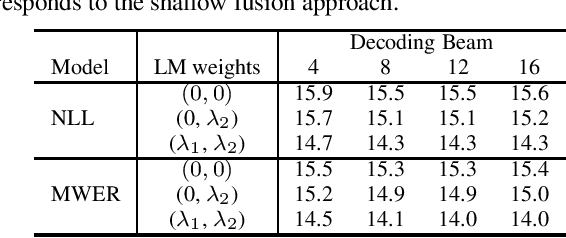
Hybrid Autoregressive Transducer (HAT) is a recently proposed end-to-end acoustic model that extends the standard Recurrent Neural Network Transducer (RNN-T) for the purpose of the external language model (LM) fusion. In HAT, the blank probability and the label probability are estimated using two separate probability distributions, which provides a more accurate solution for internal LM score estimation, and thus works better when combining with an external LM. Previous work mainly focuses on HAT model training with the negative log-likelihood loss, while in this paper, we study the minimum word error rate (MWER) training of HAT -- a criterion that is closer to the evaluation metric for speech recognition, and has been successfully applied to other types of end-to-end models such as sequence-to-sequence (S2S) and RNN-T models. From experiments with around 30,000 hours of training data, we show that MWER training can improve the accuracy of HAT models, while at the same time, improving the robustness of the model against the decoding hyper-parameters such as length normalization and decoding beam during inference.
Human-Robot Team Coordination with Dynamic and Latent Human Task Proficiencies: Scheduling with Learning Curves
Jul 03, 2020
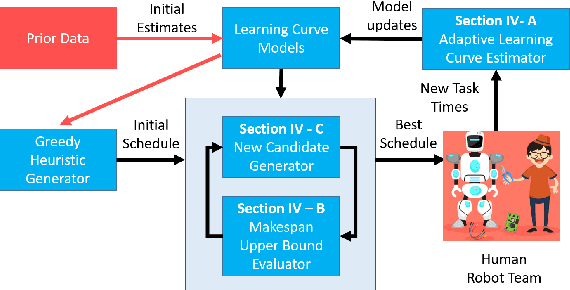
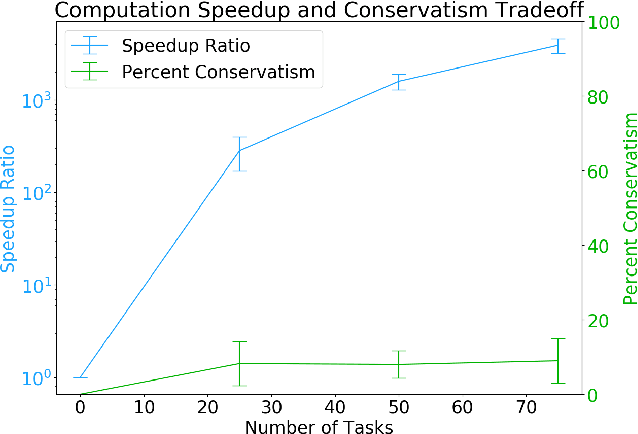
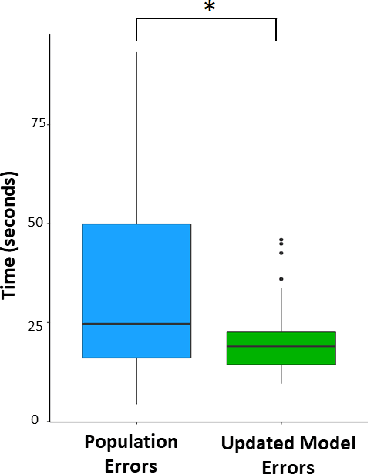
As robots become ubiquitous in the workforce, it is essential that human-robot collaboration be both intuitive and adaptive. A robot's quality improves based on its ability to explicitly reason about the time-varying (i.e. learning curves) and stochastic capabilities of its human counterparts, and adjust the joint workload to improve efficiency while factoring human preferences. We introduce a novel resource coordination algorithm that enables robots to explore the relative strengths and learning abilities of their human teammates, by constructing schedules that are robust to stochastic and time-varying human task performance. We first validate our algorithmic approach using data we collected from a user study (n = 20), showing we can quickly generate and evaluate a robust schedule while discovering the latest individual worker proficiency. Second, we conduct a between-subjects experiment (n = 90) to validate the efficacy of our coordinating algorithm. Results from the human-subjects experiment indicate that scheduling strategies favoring exploration tend to be beneficial for human-robot collaboration as it improves team fluency (p = 0.0438), while also maximizing team efficiency (p < 0.001).
Multi-focus Image Fusion for Visual Sensor Networks
Sep 30, 2020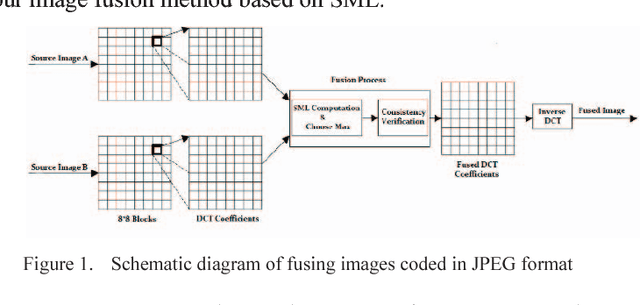



Image fusion in visual sensor networks (VSNs) aims to combine information from multiple images of the same scene in order to transform a single image with more information. Image fusion methods based on discrete cosine transform (DCT) are less complex and time-saving in DCT based standards of image and video which makes them more suitable for VSN applications. In this paper, an efficient algorithm for the fusion of multi-focus images in the DCT domain is proposed. The Sum of modified laplacian (SML) of corresponding blocks of source images is used as a contrast criterion and blocks with the larger value of SML are absorbed to output images. The experimental results on several images show the improvement of the proposed algorithm in terms of both subjective and objective quality of fused image relative to other DCT based techniques.
MIRA: Leveraging Multi-Intention Co-click Information in Web-scale Document Retrieval using Deep Neural Networks
Jul 03, 2020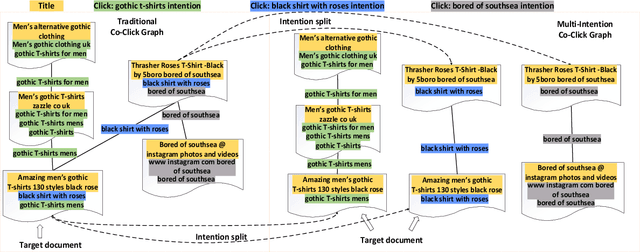
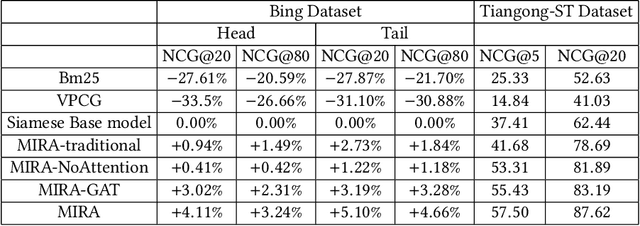
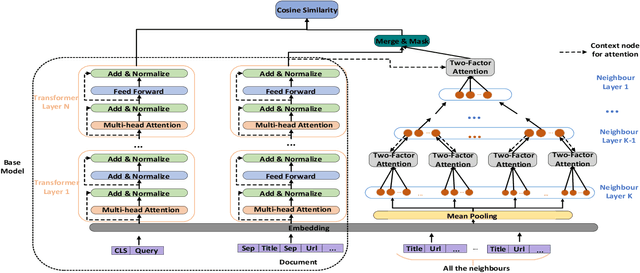
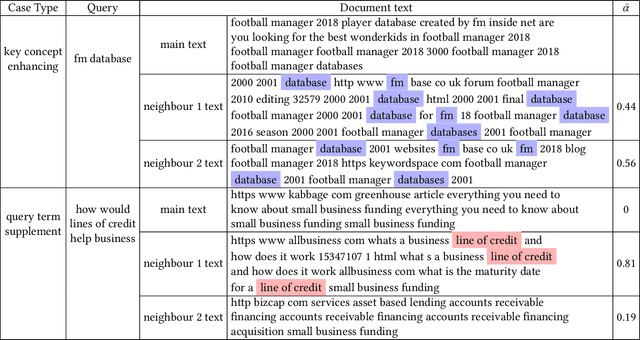
We study the problem of deep recall model in industrial web search, which is, given a user query, retrieve hundreds of most relevance documents from billions of candidates. The common framework is to train two encoding models based on neural embedding which learn the distributed representations of queries and documents separately and match them in the latent semantic space. However, all the exiting encoding models only leverage the information of the document itself, which is often not sufficient in practice when matching with query terms, especially for the hard tail queries. In this work we aim to leverage the additional information for each document from its co-click neighbour to help document retrieval. The challenges include how to effectively extract information and eliminate noise when involving co-click information in deep model while meet the demands of billion-scale data size for real time online inference. To handle the noise in co-click relations, we firstly propose a web-scale Multi-Intention Co-click document Graph(MICG) which builds the co-click connections between documents on click intention level but not on document level. Then we present an encoding framework MIRA based on Bert and graph attention networks which leverages a two-factor attention mechanism to aggregate neighbours. To meet the online latency requirements, we only involve neighbour information in document side, which can save the time-consuming query neighbor search in real time serving. We conduct extensive offline experiments on both public dataset and private web-scale dataset from two major commercial search engines demonstrating the effectiveness and scalability of the proposed method compared with several baselines. And a further case study reveals that co-click relations mainly help improve web search quality from two aspects: key concept enhancing and query term complementary.
GAGE: Geometry Preserving Attributed Graph Embeddings
Nov 03, 2020


Node representation learning is the task of extracting concise and informative feature embeddings of certain entities that are connected in a network. Many real world network datasets include information about both node connectivity and certain node attributes, in the form of features or time-series data. Modern representation learning techniques utilize both connectivity and attribute information of the nodes to produce embeddings in an unsupervised manner. In this context, deriving embeddings that preserve the geometry of the network and the attribute vectors would be highly desirable, as they would reflect both the topological neighborhood structure and proximity in feature space. While this is fairly straightforward to maintain when only observing the connectivity or attributed information of the network, preserving the geometry of both types of information is challenging. A novel tensor factorization approach for node embedding in attributed networks that preserves the distances of both the connections and the attributes is proposed in this paper, along with an effective and lightweight algorithm to tackle the learning task. Judicious experiments with multiple state-of-art baselines suggest that the proposed algorithm offers significant performance improvements in node classification and link prediction tasks.