 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
$R^3$: Reverse, Retrieve, and Rank for Sarcasm Generation with Commonsense Knowledge
May 01, 2020

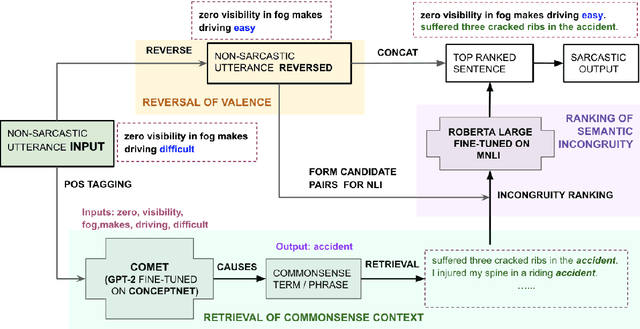
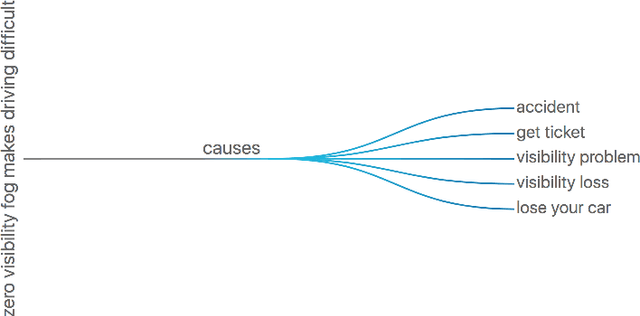
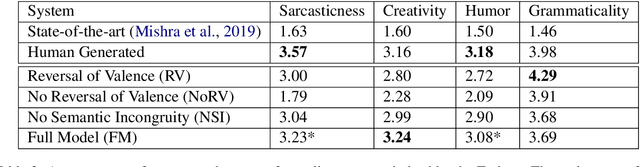
We propose an unsupervised approach for sarcasm generation based on a non-sarcastic input sentence. Our method employs a retrieve-and-edit framework to instantiate two major characteristics of sarcasm: reversal of valence and semantic incongruity with the context which could include shared commonsense or world knowledge between the speaker and the listener. While prior works on sarcasm generation predominantly focus on context incongruity, we show that combining valence reversal and semantic incongruity based on the commonsense knowledge generates sarcasm of higher quality. Human evaluation shows that our system generates sarcasm better than human annotators 34% of the time, and better than a reinforced hybrid baseline 90% of the time.
Stochastic Gradient Langevin with Delayed Gradients
Jun 12, 2020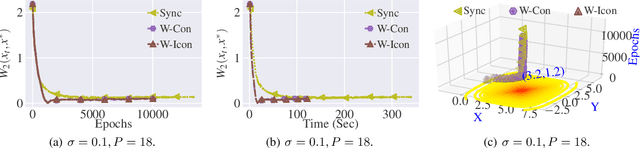
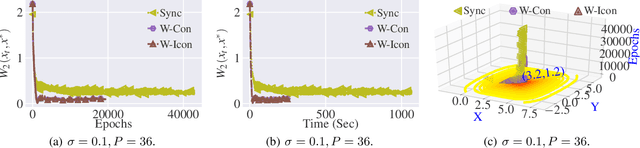
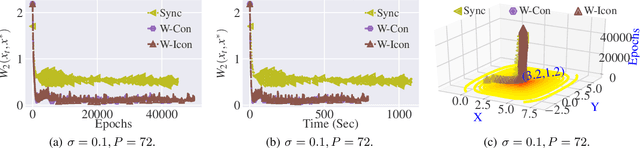
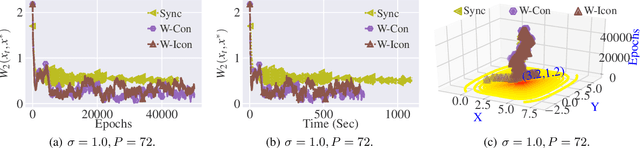
Stochastic Gradient Langevin Dynamics (SGLD) ensures strong guarantees with regards to convergence in measure for sampling log-concave posterior distributions by adding noise to stochastic gradient iterates. Given the size of many practical problems, parallelizing across several asynchronously running processors is a popular strategy for reducing the end-to-end computation time of stochastic optimization algorithms. In this paper, we are the first to investigate the effect of asynchronous computation, in particular, the evaluation of stochastic Langevin gradients at delayed iterates, on the convergence in measure. For this, we exploit recent results modeling Langevin dynamics as solving a convex optimization problem on the space of measures. We show that the rate of convergence in measure is not significantly affected by the error caused by the delayed gradient information used for computation, suggesting significant potential for speedup in wall clock time. We confirm our theoretical results with numerical experiments on some practical problems.
Taking A Closer Look at Synthesis: Fine-grained Attribute Analysis for Person Re-Identification
Oct 15, 2020
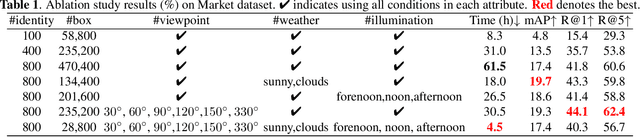


Person re-identification (re-ID) plays an important role in applications such as public security and video surveillance. Recently, learning from synthetic data, which benefits from the popularity of synthetic data engine, has achieved remarkable performance. However, in pursuit of high accuracy, researchers in the academic always focus on training with large-scale datasets at a high cost of time and label expenses, while neglect to explore the potential of performing efficient training from millions of synthetic data. To facilitate development in this field, we reviewed the previously developed synthetic dataset GPR and built an improved one (GPR+) with larger number of identities and distinguished attributes. Based on it, we quantitatively analyze the influence of dataset attribute on re-ID system. To our best knowledge, we are among the first attempts to explicitly dissect person re-ID from the aspect of attribute on synthetic dataset. This research helps us have a deeper understanding of the fundamental problems in person re-ID, which also provides useful insights for dataset building and future practical usage.
Towards A Sentiment Analyzer for Low-Resource Languages
Nov 12, 2020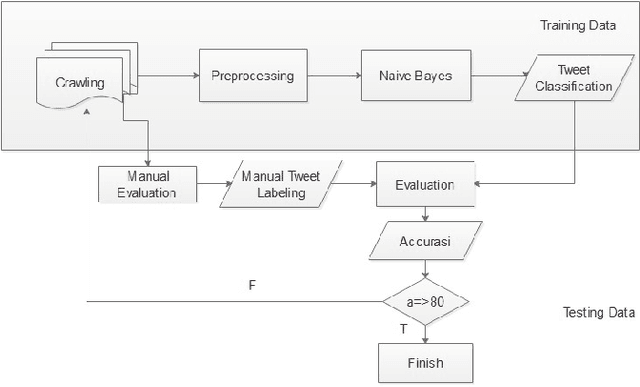
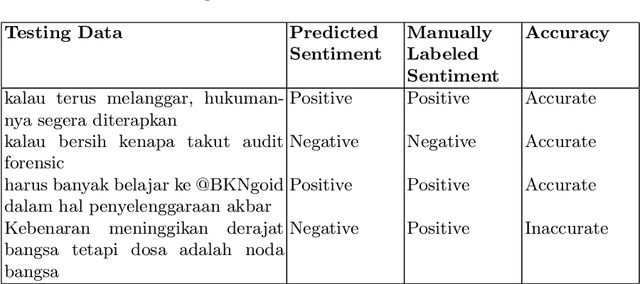
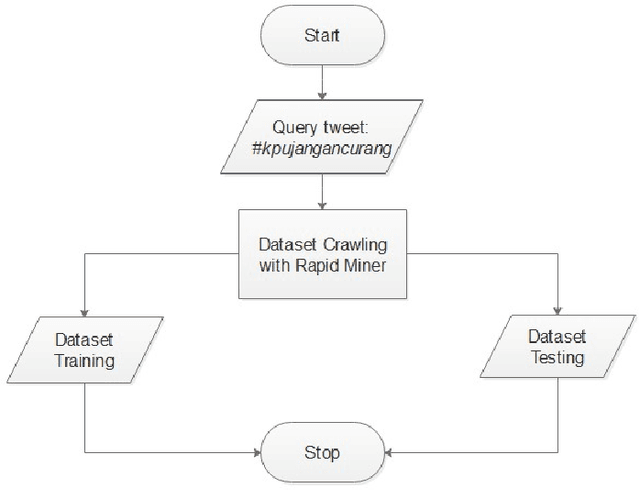

Twitter is one of the top influenced social media which has a million number of active users. It is commonly used for microblogging that allows users to share messages, ideas, thoughts and many more. Thus, millions interaction such as short messages or tweets are flowing around among the twitter users discussing various topics that has been happening world-wide. This research aims to analyse a sentiment of the users towards a particular trending topic that has been actively and massively discussed at that time. We chose a hashtag \textit{\#kpujangancurang} that was the trending topic during the Indonesia presidential election in 2019. We use the hashtag to obtain a set of data from Twitter to analyse and investigate further the positive or the negative sentiment of the users from their tweets. This research utilizes rapid miner tool to generate the twitter data and comparing Naive Bayes, K-Nearest Neighbor, Decision Tree, and Multi-Layer Perceptron classification methods to classify the sentiment of the twitter data. There are overall 200 labeled data in this experiment. Overall, Naive Bayes and Multi-Layer Perceptron classification outperformed the other two methods on 11 experiments with different size of training-testing data split. The two classifiers are potential to be used in creating sentiment analyzer for low-resource languages with small corpus.
Predicting First Passage Percolation Shapes Using Neural Networks
Jun 24, 2020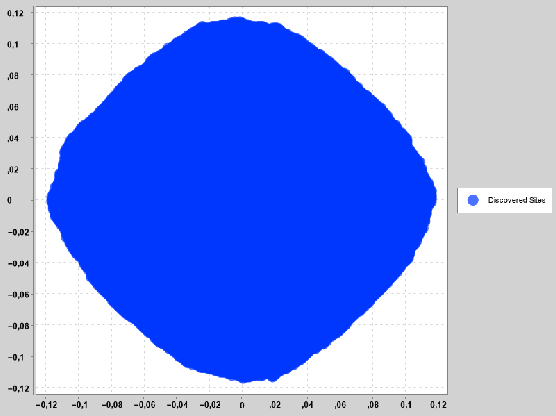

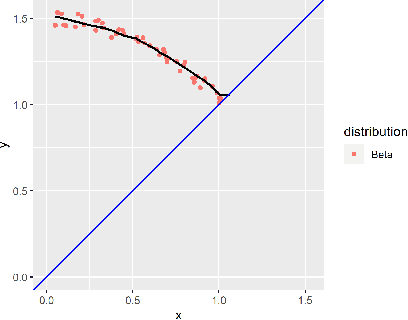

Many random growth models have the property that the set of discovered sites, scaled properly, converges to some deterministic set as time grows. Such results are known as shape theorems. Typically, not much is known about the shapes. For first passage percolation on $\mathbb{Z}^d$ we only know that the shape is convex, compact, and inherits all the symmetries of $\mathbb{Z}^d$. Using simulated data we construct and fit a neural network able to adequately predict the shape of the set of discovered sites from the mean, standard deviation, and percentiles of the distribution of the passage times. The purpose of the note is two-fold. The main purpose is to give researchers a new tool for \textit{quickly} getting an impression of the shape from the distribution of the passage times -- instead of having to wait some time for the simulations to run, as is the only available way today. The second purpose of the note is simply to introduce modern machine learning methods into this area of discrete probability, and a hope that it stimulates further research.
Dynamic Walking: Toward Agile and Efficient Bipedal Robots
Oct 15, 2020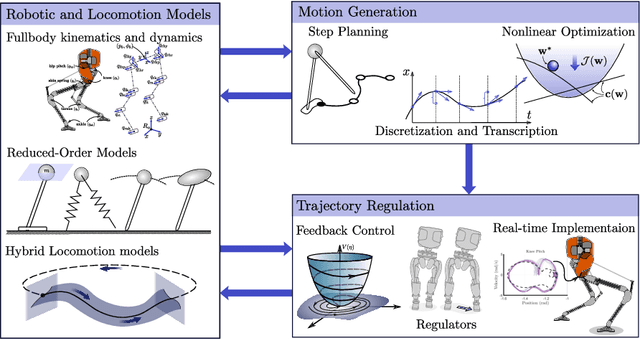
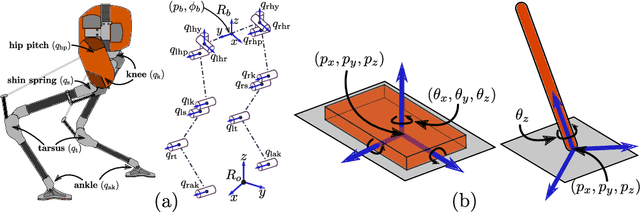
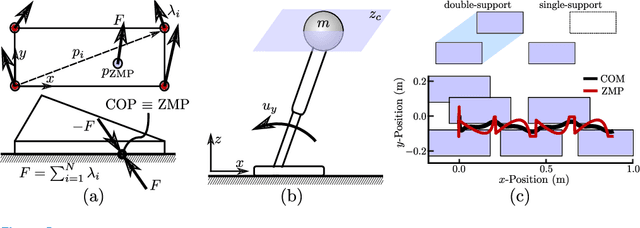
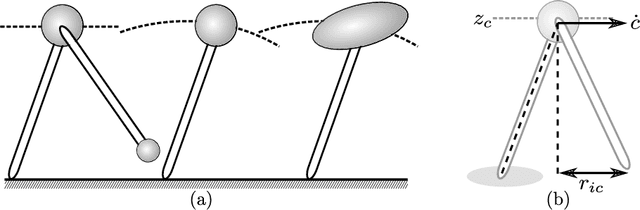
Dynamic walking on bipedal robots has evolved from an idea in science fiction to a practical reality. This is due to continued progress in three key areas: a mathematical understanding of locomotion, the computational ability to encode this mathematics through optimization, and the hardware capable of realizing this understanding in practice. In this context, this review article outlines the end-to-end process of methods which have proven effective in the literature for achieving dynamic walking on bipedal robots. We begin by introducing mathematical models of locomotion, from reduced order models that capture essential walking behaviors to hybrid dynamical systems that encode the full order continuous dynamics along with discrete footstrike dynamics. These models form the basis for gait generation via (nonlinear) optimization problems. Finally, models and their generated gaits merge in the context of real-time control, wherein walking behaviors are translated to hardware. The concepts presented are illustrated throughout in simulation, and experimental instantiation on multiple walking platforms are highlighted to demonstrate the ability to realize dynamic walking on bipedal robots that is agile and efficient.
Physics-informed Tensor-train ConvLSTM for Volumetric Velocity Forecasting
Aug 04, 2020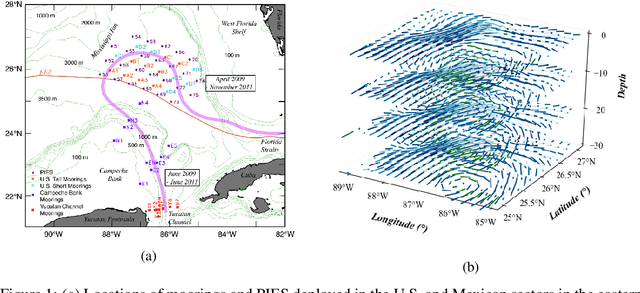
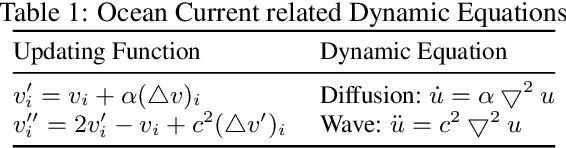
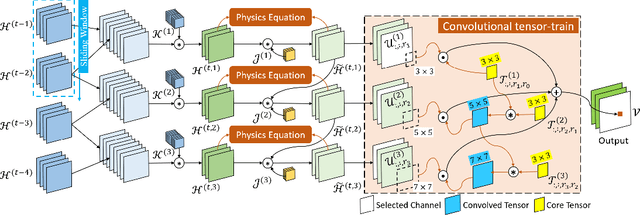
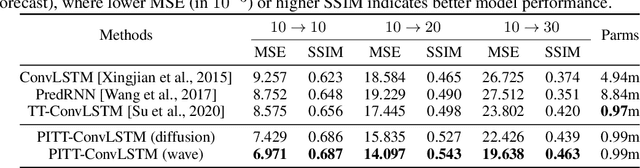
According to the National Academies, a weekly forecast of velocity, vertical structure, and duration of the Loop Current (LC) and its eddies is critical for understanding the oceanography and ecosystem, and for mitigating outcomes of anthropogenic and natural disasters in the Gulf of Mexico (GoM). However, this forecast is a challenging problem since the LC behaviour is dominated by long-range spatial connections across multiple timescales. In this paper, we extend spatiotemporal predictive learning, showing its effectiveness beyond video prediction, to a 4D model, i.e., a novel Physics-informed Tensor-train ConvLSTM (PITT-ConvLSTM) for temporal sequences of 3D geospatial data forecasting. Specifically, we propose 1) a novel 4D higher-order recurrent neural network with empirical orthogonal function analysis to capture the hidden uncorrelated patterns of each hierarchy, 2) a convolutional tensor-train decomposition to capture higher-order space-time correlations, and 3) to incorporate prior physic knowledge that is provided from domain experts by informing the learning in latent space. The advantage of our proposed method is clear: constrained by physical laws, it simultaneously learns good representations for frame dependencies (both short-term and long-term high-level dependency) and inter-hierarchical relations within each time frame. Experiments on geospatial data collected from the GoM demonstrate that PITT-ConvLSTM outperforms the state-of-the-art methods in forecasting the volumetric velocity of the LC and its eddies for a period of over one week.
Experimental Comparison of Semi-parametric, Parametric, and Machine Learning Models for Time-to-Event Analysis Through the Concordance Index
Mar 13, 2020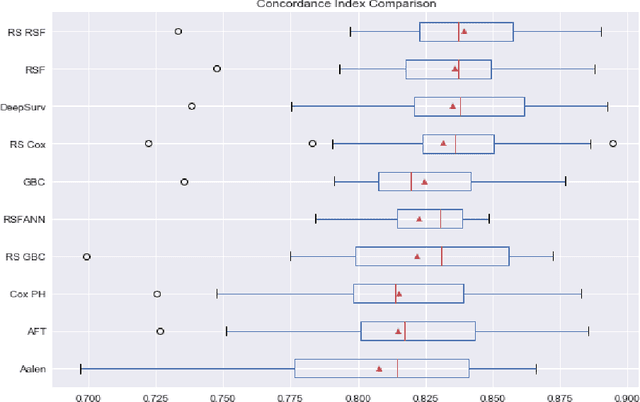
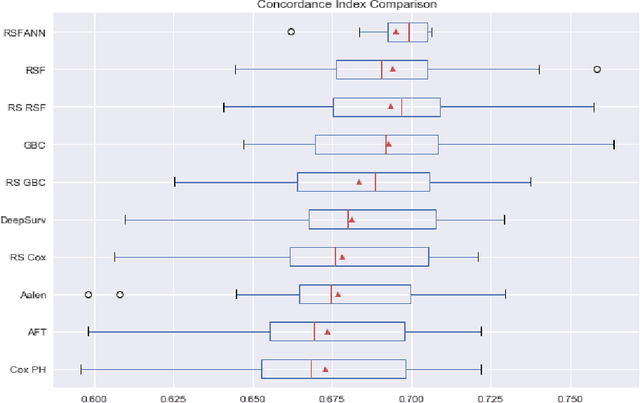
In this paper, we make an experimental comparison of semi-parametric (Cox proportional hazards model, Aalen's additive regression model), parametric (Weibull AFT model), and machine learning models (Random Survival Forest, Gradient Boosting with Cox Proportional Hazards Loss, DeepSurv) through the concordance index on two different datasets (PBC and GBCSG2). We present two comparisons: one with the default hyper-parameters of these models and one with the best hyper-parameters found by randomized search.
Tractable contextual bandits beyond realizability
Oct 25, 2020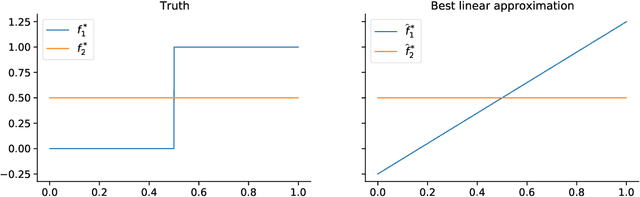
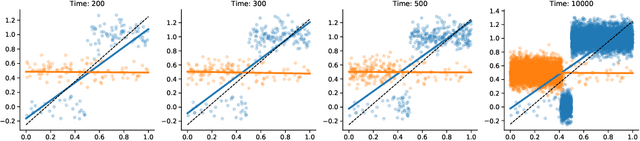
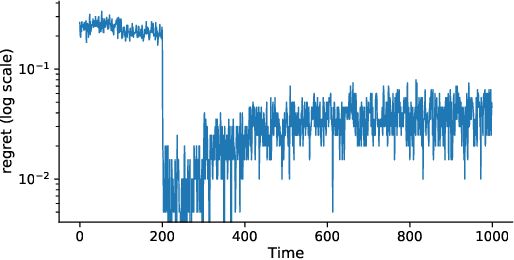
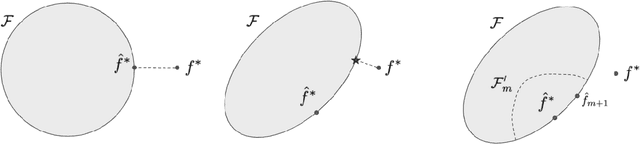
Tractable contextual bandit algorithms often rely on the realizability assumption -- i.e., that the true expected reward model belongs to a known class, such as linear functions. We investigate issues that arise in the absence of realizability and note that the dynamics of adaptive data collection can lead commonly used bandit algorithms to learn a suboptimal policy. In this work, we present a tractable bandit algorithm that is not sensitive to the realizability assumption and computationally reduces to solving a constrained regression problem in every epoch. When realizability does not hold, our algorithm ensures the same guarantees on regret achieved by realizability-based algorithms under realizability, up to an additive term that accounts for the misspecification error. This extra term is proportional to T times the (2/5)-root of the mean squared error between the best model in the class and the true model, where T is the total number of time-steps. Our work sheds light on the bias-variance trade-off for tractable contextual bandits. This trade-off is not captured by algorithms that assume realizability, since under this assumption there exists an estimator in the class that attains zero bias.
Relation of the Relations: A New Paradigm of the Relation Extraction Problem
Jun 05, 2020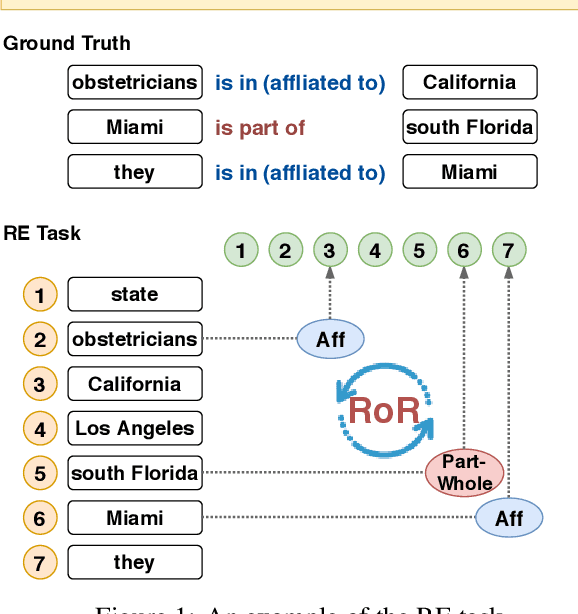
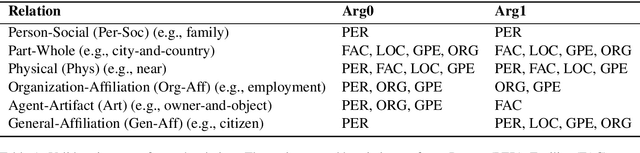
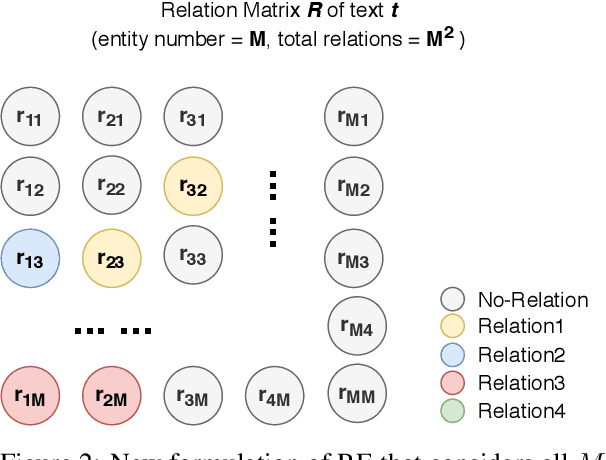
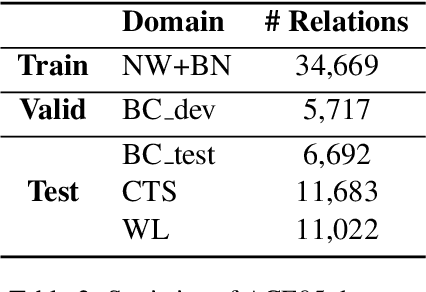
In natural language, often multiple entities appear in the same text. However, most previous works in Relation Extraction (RE) limit the scope to identifying the relation between two entities at a time. Such an approach induces a quadratic computation time, and also overlooks the interdependency between multiple relations, namely the relation of relations (RoR). Due to the significance of RoR in existing datasets, we propose a new paradigm of RE that considers as a whole the predictions of all relations in the same context. Accordingly, we develop a data-driven approach that does not require hand-crafted rules but learns by itself the RoR, using Graph Neural Networks and a relation matrix transformer. Experiments show that our model outperforms the state-of-the-art approaches by +1.12\% on the ACE05 dataset and +2.55\% on SemEval 2018 Task 7.2, which is a substantial improvement on the two competitive benchmarks.