 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Weakly-supervised Fine-grained Event Recognition on Social Media Texts for Disaster Management
Oct 04, 2020



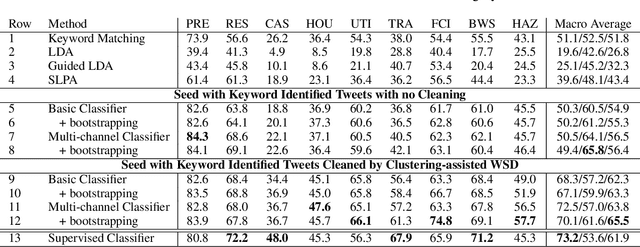
People increasingly use social media to report emergencies, seek help or share information during disasters, which makes social networks an important tool for disaster management. To meet these time-critical needs, we present a weakly supervised approach for rapidly building high-quality classifiers that label each individual Twitter message with fine-grained event categories. Most importantly, we propose a novel method to create high-quality labeled data in a timely manner that automatically clusters tweets containing an event keyword and asks a domain expert to disambiguate event word senses and label clusters quickly. In addition, to process extremely noisy and often rather short user-generated messages, we enrich tweet representations using preceding context tweets and reply tweets in building event recognition classifiers. The evaluation on two hurricanes, Harvey and Florence, shows that using only 1-2 person-hours of human supervision, the rapidly trained weakly supervised classifiers outperform supervised classifiers trained using more than ten thousand annotated tweets created in over 50 person-hours.
An Approach to Evaluating Learning Algorithms for Decision Trees
Oct 26, 2020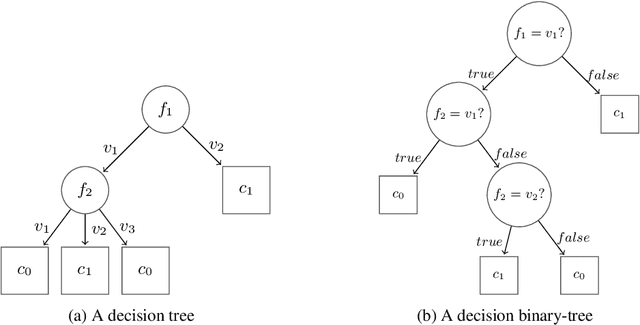
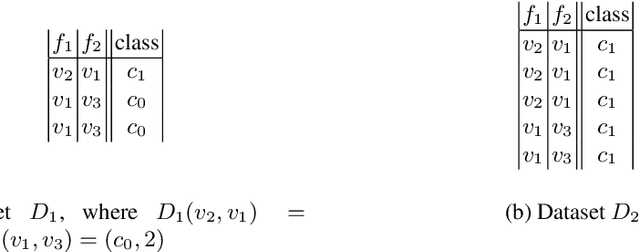
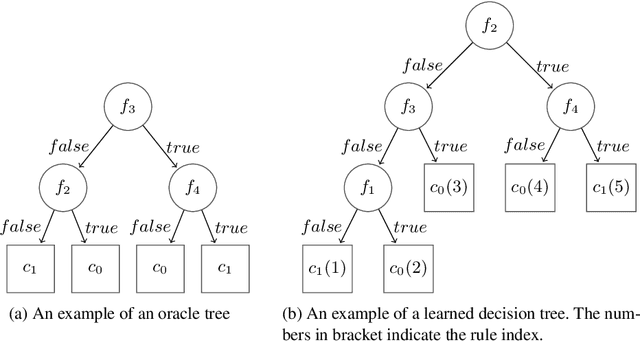

Learning algorithms produce software models for realising critical classification tasks. Decision trees models are simpler than other models such as neural network and they are used in various critical domains such as the medical and the aeronautics. Low or unknown learning ability algorithms does not permit us to trust the produced software models, which lead to costly test activities for validating the models and to the waste of learning time in case the models are likely to be faulty due to the learning inability. Methods for evaluating the decision trees learning ability, as well as that for the other models, are needed especially since the testing of the learned models is still a hot topic. We propose a novel oracle-centered approach to evaluate (the learning ability of) learning algorithms for decision trees. It consists of generating data from reference trees playing the role of oracles, producing learned trees with existing learning algorithms, and determining the degree of correctness (DOE) of the learned trees by comparing them with the oracles. The average DOE is used to estimate the quality of the learning algorithm. the We assess five decision tree learning algorithms based on the proposed approach.
Idle Vehicle Relocation Strategy through Deep Learning for Shared Autonomous Electric Vehicle System Optimization
Oct 16, 2020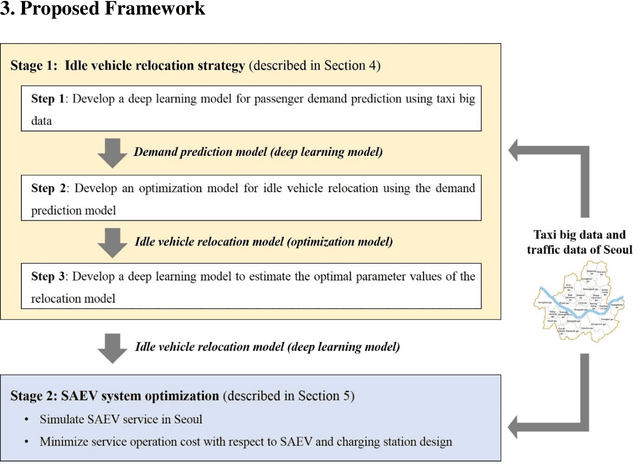

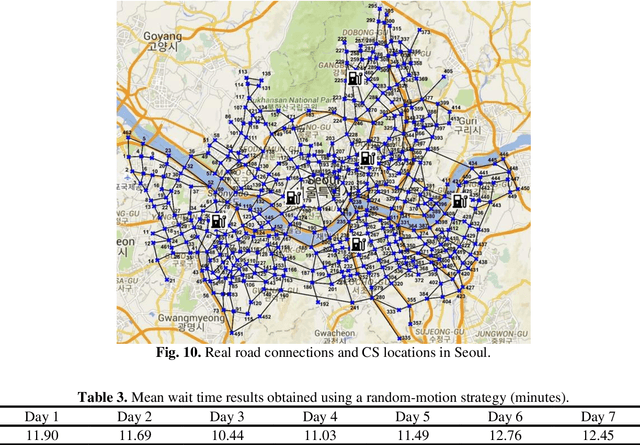
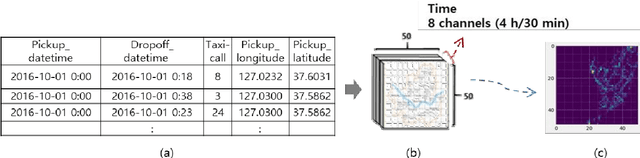
In optimization of a shared autonomous electric vehicle (SAEV) system, idle vehicle relocation strategies are important to reduce operation costs and customers' wait time. However, for an on-demand service, continuous optimization for idle vehicle relocation is computationally expensive, and thus, not effective. This study proposes a deep learning-based algorithm that can instantly predict the optimal solution to idle vehicle relocation problems under various traffic conditions. The proposed relocation process comprises three steps. First, a deep learning-based passenger demand prediction model using taxi big data is built. Second, idle vehicle relocation problems are solved based on predicted demands, and optimal solution data are collected. Finally, a deep learning model using the optimal solution data is built to estimate the optimal strategy without solving relocation. In addition, the proposed idle vehicle relocation model is validated by applying it to optimize the SAEV system. We present an optimal service system including the design of SAEV vehicles and charging stations. Further, we demonstrate that the proposed strategy can drastically reduce operation costs and wait times for on-demand services.
ALdataset: a benchmark for pool-based active learning
Oct 16, 2020
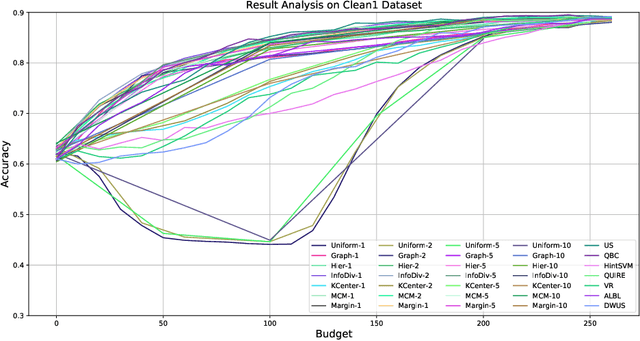
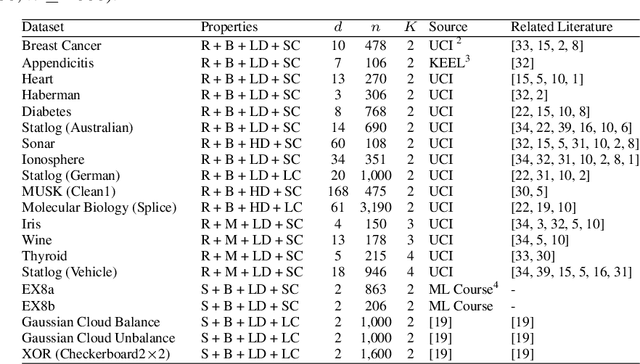
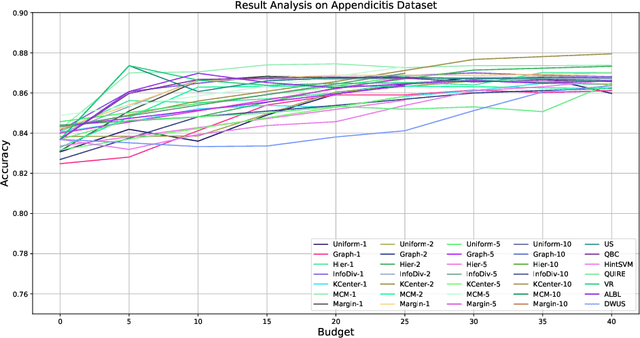
Active learning (AL) is a subfield of machine learning (ML) in which a learning algorithm could achieve good accuracy with less training samples by interactively querying a user/oracle to label new data points. Pool-based AL is well-motivated in many ML tasks, where unlabeled data is abundant, but their labels are hard to obtain. Although many pool-based AL methods have been developed, the lack of a comparative benchmarking and integration of techniques makes it difficult to: 1) determine the current state-of-the-art technique; 2) evaluate the relative benefit of new methods for various properties of the dataset; 3) understand what specific problems merit greater attention; and 4) measure the progress of the field over time. To conduct easier comparative evaluation among AL methods, we present a benchmark task for pool-based active learning, which consists of benchmarking datasets and quantitative metrics that summarize overall performance. We present experiment results for various active learning strategies, both recently proposed and classic highly-cited methods, and draw insights from the results.
Learning a Decentralized Multi-arm Motion Planner
Nov 05, 2020
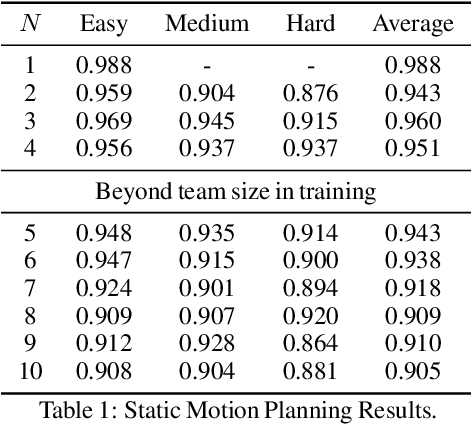
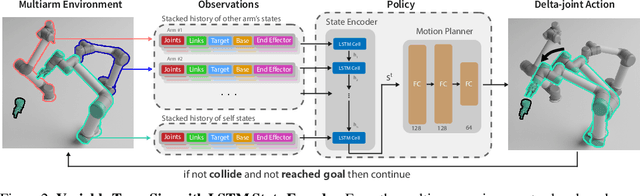
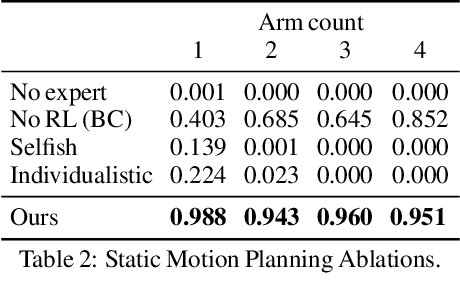
We present a closed-loop multi-arm motion planner that is scalable and flexible with team size. Traditional multi-arm robot systems have relied on centralized motion planners, whose runtimes often scale exponentially with team size, and thus, fail to handle dynamic environments with open-loop control. In this paper, we tackle this problem with multi-agent reinforcement learning, where a decentralized policy is trained to control one robot arm in the multi-arm system to reach its target end-effector pose given observations of its workspace state and target end-effector pose. The policy is trained using Soft Actor-Critic with expert demonstrations from a sampling-based motion planning algorithm (i.e., BiRRT). By leveraging classical planning algorithms, we can improve the learning efficiency of the reinforcement learning algorithm while retaining the fast inference time of neural networks. The resulting policy scales sub-linearly and can be deployed on multi-arm systems with variable team sizes. Thanks to the closed-loop and decentralized formulation, our approach generalizes to 5-10 multi-arm systems and dynamic moving targets (>90% success rate for a 10-arm system), despite being trained on only 1-4 arm planning tasks with static targets. Code and data links can be found at https://multiarm.cs.columbia.edu.
Stochastic Gradient Langevin with Delayed Gradients
Jun 12, 2020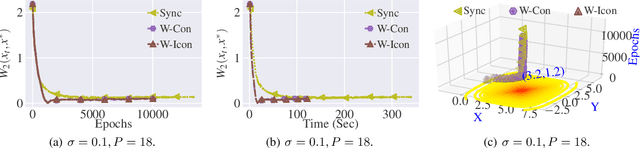
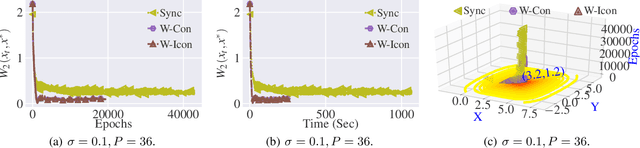
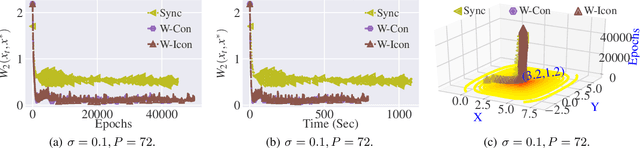
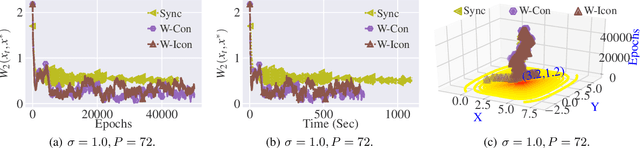
Stochastic Gradient Langevin Dynamics (SGLD) ensures strong guarantees with regards to convergence in measure for sampling log-concave posterior distributions by adding noise to stochastic gradient iterates. Given the size of many practical problems, parallelizing across several asynchronously running processors is a popular strategy for reducing the end-to-end computation time of stochastic optimization algorithms. In this paper, we are the first to investigate the effect of asynchronous computation, in particular, the evaluation of stochastic Langevin gradients at delayed iterates, on the convergence in measure. For this, we exploit recent results modeling Langevin dynamics as solving a convex optimization problem on the space of measures. We show that the rate of convergence in measure is not significantly affected by the error caused by the delayed gradient information used for computation, suggesting significant potential for speedup in wall clock time. We confirm our theoretical results with numerical experiments on some practical problems.
Desmoking laparoscopy surgery images using an image-to-image translation guided by an embedded dark channel
Apr 19, 2020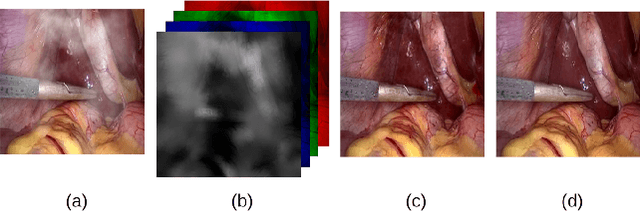
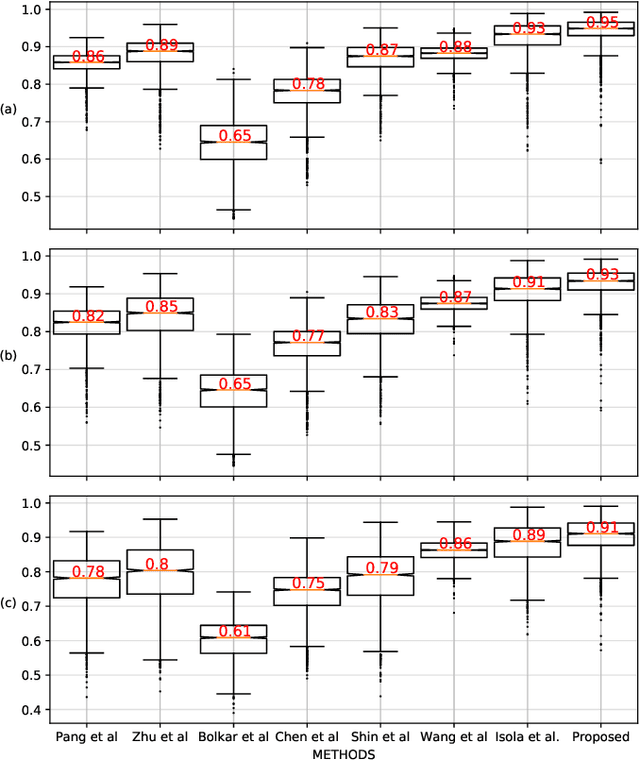
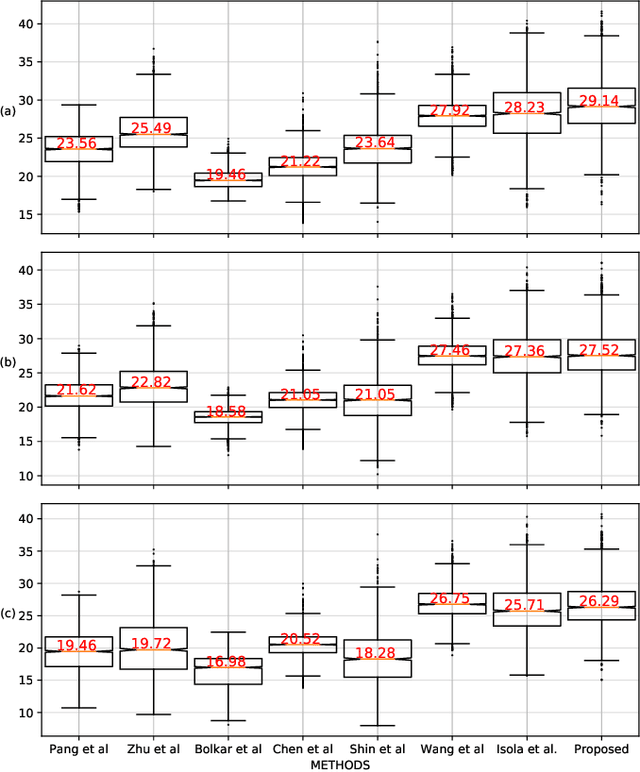
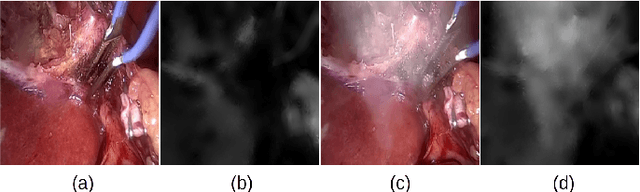
In laparoscopic surgery, the visibility in the image can be severely degraded by the smoke caused by the $CO_2$ injection, and dissection tools, thus reducing the visibility of organs and tissues. This lack of visibility increases the surgery time and even the probability of mistakes conducted by the surgeon, then producing negative consequences on the patient's health. In this paper, a novel computational approach to remove the smoke effects is introduced. The proposed method is based on an image-to-image conditional generative adversarial network in which a dark channel is used as an embedded guide mask. Obtained experimental results are evaluated and compared quantitatively with other desmoking and dehazing state-of-art methods using the metrics of the Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity (SSIM) index. Based on these metrics, it is found that the proposed method has improved performance compared to the state-of-the-art. Moreover, the processing time required by our method is 92 frames per second, and thus, it can be applied in a real-time medical system trough an embedded device.
AML-SVM: Adaptive Multilevel Learning with Support Vector Machines
Nov 05, 2020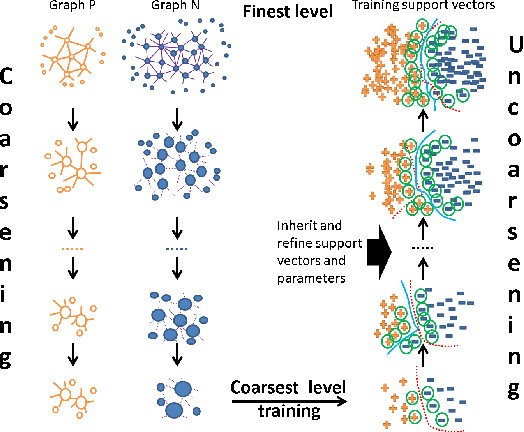
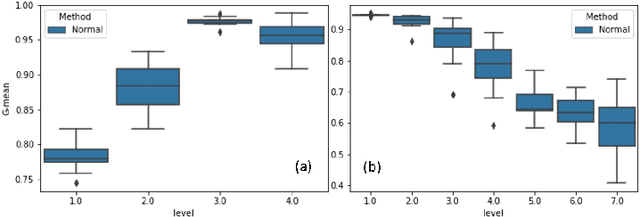
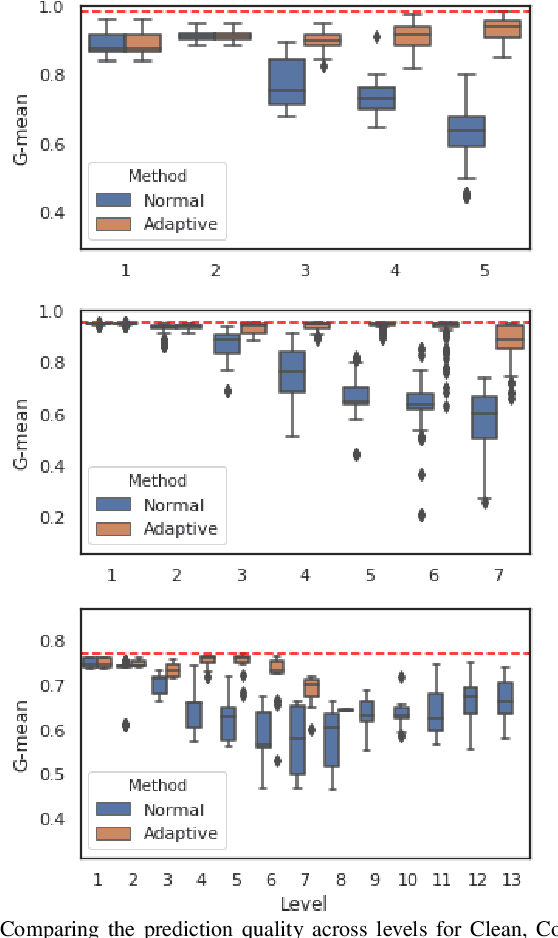

The support vector machines (SVM) is one of the most widely used and practical optimization based classification models in machine learning because of its interpretability and flexibility to produce high quality results. However, the big data imposes a certain difficulty to the most sophisticated but relatively slow versions of SVM, namely, the nonlinear SVM. The complexity of nonlinear SVM solvers and the number of elements in the kernel matrix quadratically increases with the number of samples in training data. Therefore, both runtime and memory requirements are negatively affected. Moreover, the parameter fitting has extra kernel parameters to tune, which exacerbate the runtime even further. This paper proposes an adaptive multilevel learning framework for the nonlinear SVM, which addresses these challenges, improves the classification quality across the refinement process, and leverages multi-threaded parallel processing for better performance. The integration of parameter fitting in the hierarchical learning framework and adaptive process to stop unnecessary computation significantly reduce the running time while increase the overall performance. The experimental results demonstrate reduced variance on prediction over validation and test data across levels in the hierarchy, and significant speedup compared to state-of-the-art nonlinear SVM libraries without a decrease in the classification quality. The code is accessible at https://github.com/esadr/amlsvm.
When in Doubt, Ask: Generating Answerable and Unanswerable Questions, Unsupervised
Oct 04, 2020
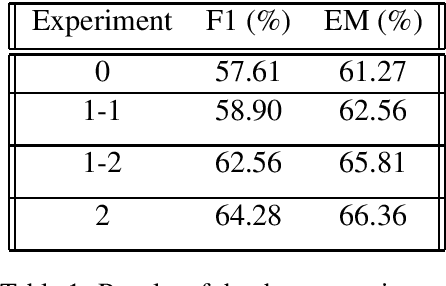


Question Answering (QA) is key for making possible a robust communication between human and machine. Modern language models used for QA have surpassed the human-performance in several essential tasks; however, these models require large amounts of human-generated training data which are costly and time-consuming to create. This paper studies augmenting human-made datasets with synthetic data as a way of surmounting this problem. A state-of-the-art model based on deep transformers is used to inspect the impact of using synthetic answerable and unanswerable questions to complement a well-known human-made dataset. The results indicate a tangible improvement in the performance of the language model (measured in terms of F1 and EM scores) trained on the mixed dataset. Specifically, unanswerable question-answers prove more effective in boosting the model: the F1 score gain from adding to the original dataset the answerable, unanswerable, and combined question-answers were 1.3\%, 5.0\%, and 6.7\%, respectively. [Link to the Github repository: https://github.com/lnikolenko/EQA]
StrObe: Streaming Object Detection from LiDAR Packets
Nov 13, 2020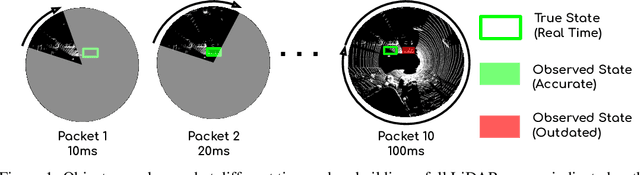

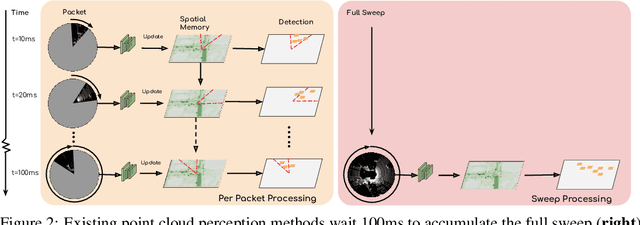
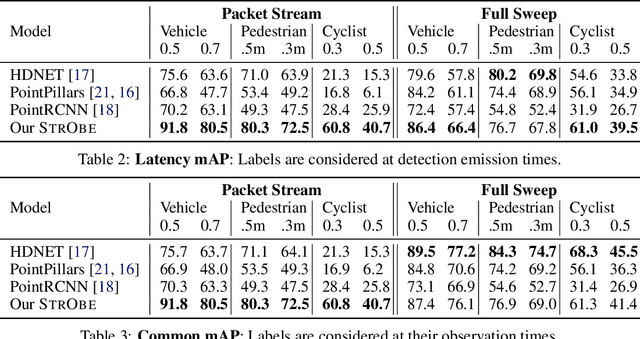
Many modern robotics systems employ LiDAR as their main sensing modality due to its geometrical richness. Rolling shutter LiDARs are particularly common, in which an array of lasers scans the scene from a rotating base. Points are emitted as a stream of packets, each covering a sector of the 360{\deg} coverage. Modern perception algorithms wait for the full sweep to be built before processing the data, which introduces an additional latency. For typical 10Hz LiDARs this will be 100ms. As a consequence, by the time an output is produced, it no longer accurately reflects the state of the world. This poses a challenge, as robotics applications require minimal reaction times, such that maneuvers can be quickly planned in the event of a safety-critical situation. In this paper we propose StrObe, a novel approach that minimizes latency by ingesting LiDAR packets and emitting a stream of detections without waiting for the full sweep to be built. StrObe reuses computations from previous packets and iteratively updates a latent spatial representation of the scene, which acts as a memory, as new evidence comes in, resulting in accurate low-latency perception. We demonstrate the effectiveness of our approach on a large scale real-world dataset, showing that StrObe far outperforms the state-of-the-art when latency is taken into account, and matches the performance in the traditional setting.