 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ALdataset: a benchmark for pool-based active learning
Oct 16, 2020

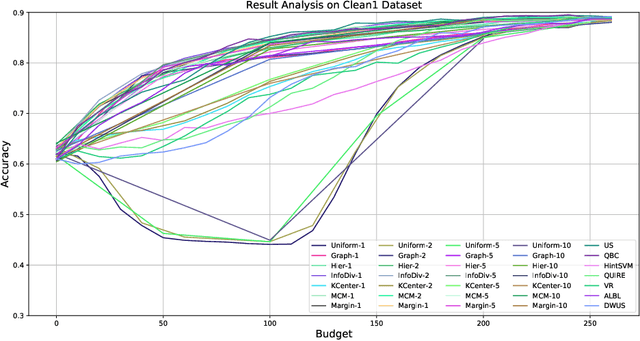
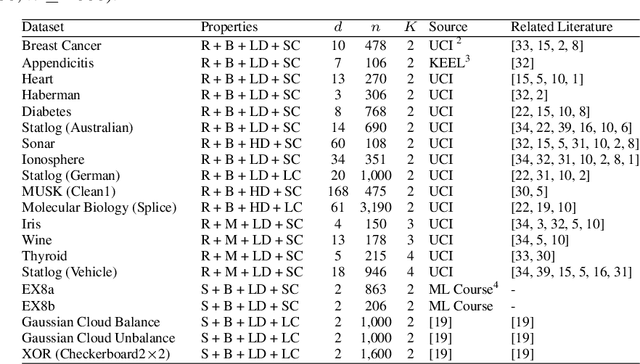
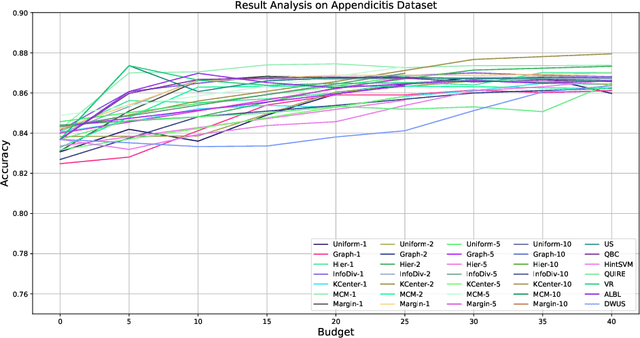
Active learning (AL) is a subfield of machine learning (ML) in which a learning algorithm could achieve good accuracy with less training samples by interactively querying a user/oracle to label new data points. Pool-based AL is well-motivated in many ML tasks, where unlabeled data is abundant, but their labels are hard to obtain. Although many pool-based AL methods have been developed, the lack of a comparative benchmarking and integration of techniques makes it difficult to: 1) determine the current state-of-the-art technique; 2) evaluate the relative benefit of new methods for various properties of the dataset; 3) understand what specific problems merit greater attention; and 4) measure the progress of the field over time. To conduct easier comparative evaluation among AL methods, we present a benchmark task for pool-based active learning, which consists of benchmarking datasets and quantitative metrics that summarize overall performance. We present experiment results for various active learning strategies, both recently proposed and classic highly-cited methods, and draw insights from the results.
Multi-microphone Complex Spectral Mapping for Utterance-wise and Continuous Speaker Separation
Oct 04, 2020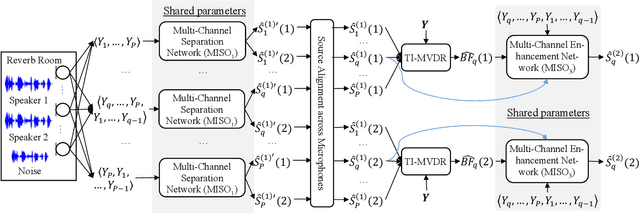
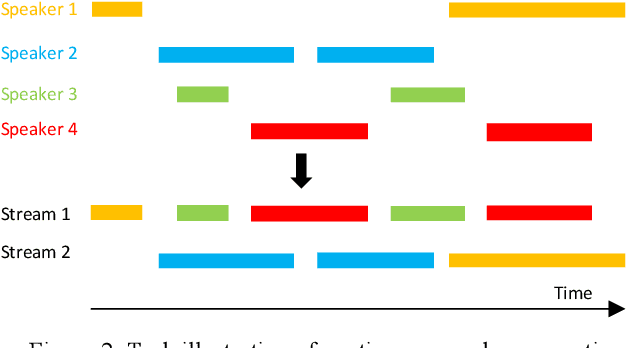
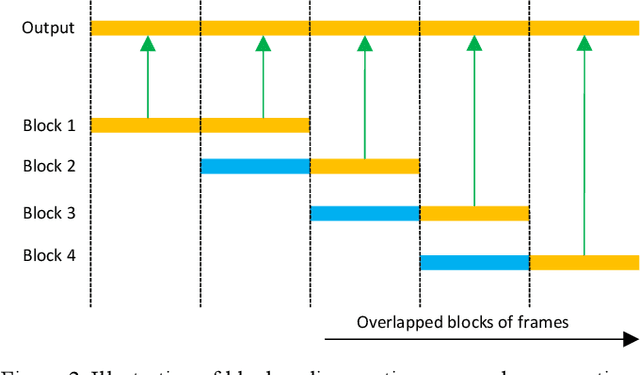
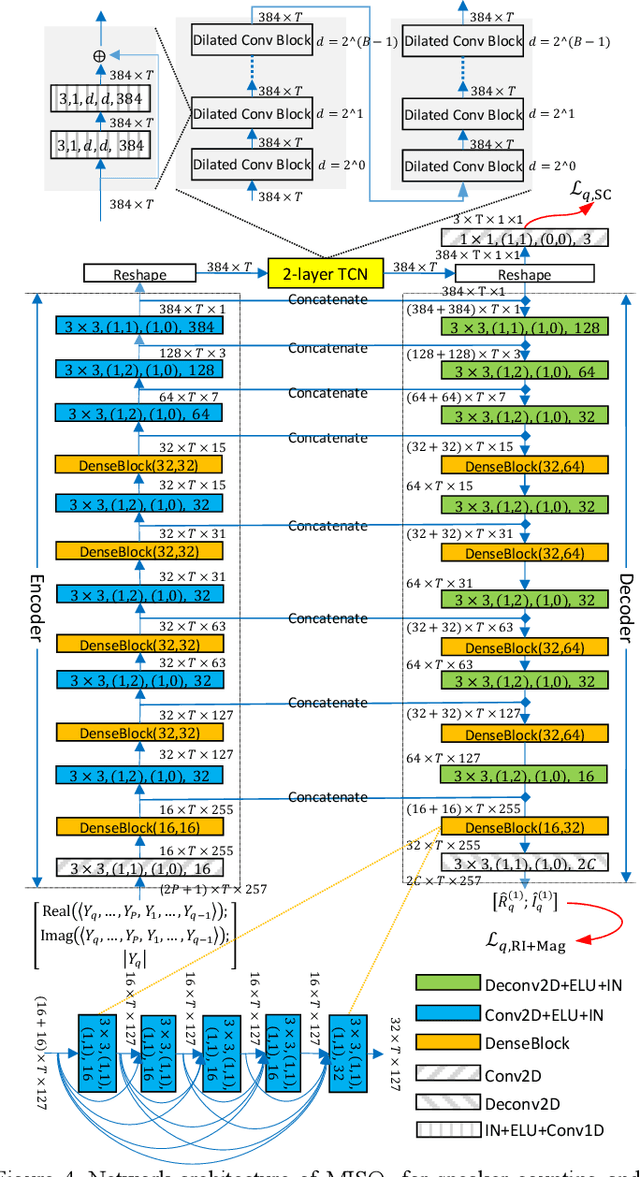
We propose multi-microphone complex spectral mapping, a simple way of applying deep learning for time-varying non-linear beamforming, for offline utterance-wise and block-online continuous speaker separation in reverberant conditions, aiming at both speaker separation and dereverberation. Assuming a fixed array geometry between training and testing, we train deep neural networks (DNN) to predict the real and imaginary (RI) components of target speech at a reference microphone from the RI components of multiple microphones. We then integrate multi-microphone complex spectral mapping with beamforming and post-filtering to further improve separation, and combine it with frame-level speaker counting for block-online continuous speaker separation (CSS). Although our system is trained on simulated room impulse responses (RIR) based on a fixed number of microphones arranged in a given geometry, it generalizes well to a real array with the same geometry. State-of-the-art separation performance is obtained on the simulated two-talker SMS-WSJ corpus and the real-recorded LibriCSS dataset.
Weakly-supervised Fine-grained Event Recognition on Social Media Texts for Disaster Management
Oct 04, 2020


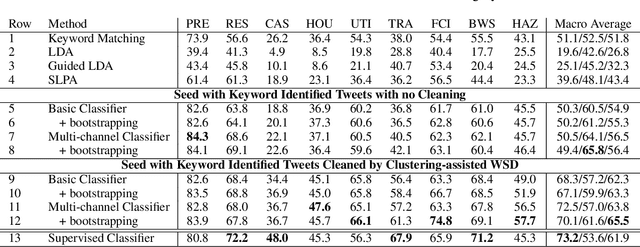
People increasingly use social media to report emergencies, seek help or share information during disasters, which makes social networks an important tool for disaster management. To meet these time-critical needs, we present a weakly supervised approach for rapidly building high-quality classifiers that label each individual Twitter message with fine-grained event categories. Most importantly, we propose a novel method to create high-quality labeled data in a timely manner that automatically clusters tweets containing an event keyword and asks a domain expert to disambiguate event word senses and label clusters quickly. In addition, to process extremely noisy and often rather short user-generated messages, we enrich tweet representations using preceding context tweets and reply tweets in building event recognition classifiers. The evaluation on two hurricanes, Harvey and Florence, shows that using only 1-2 person-hours of human supervision, the rapidly trained weakly supervised classifiers outperform supervised classifiers trained using more than ten thousand annotated tweets created in over 50 person-hours.
Perpetual Motion: Generating Unbounded Human Motion
Jul 27, 2020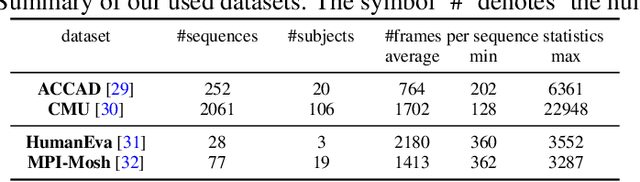
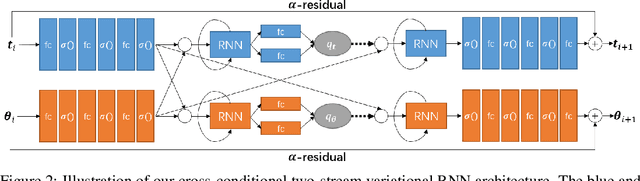
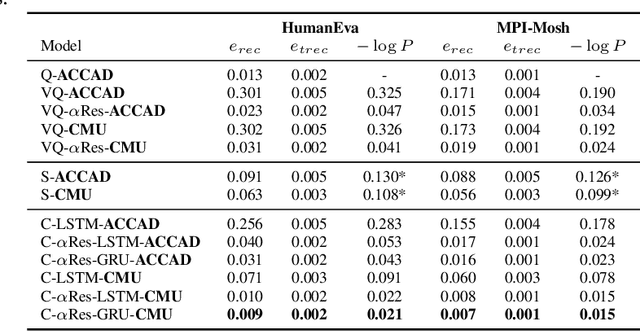
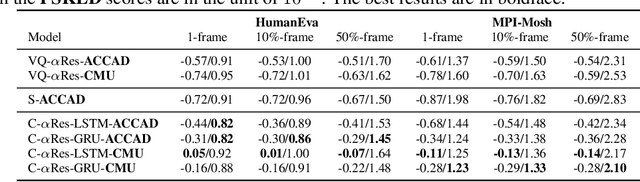
The modeling of human motion using machine learning methods has been widely studied. In essence it is a time-series modeling problem involving predicting how a person will move in the future given how they moved in the past. Existing methods, however, typically have a short time horizon, predicting a only few frames to a few seconds of human motion. Here we focus on long-term prediction; that is, generating long sequences (potentially infinite) of human motion that is plausible. Furthermore, we do not rely on a long sequence of input motion for conditioning, but rather, can predict how someone will move from as little as a single pose. Such a model has many uses in graphics (video games and crowd animation) and vision (as a prior for human motion estimation or for dataset creation). To address this problem, we propose a model to generate non-deterministic, \textit{ever-changing}, perpetual human motion, in which the global trajectory and the body pose are cross-conditioned. We introduce a novel KL-divergence term with an implicit, unknown, prior. We train this using a heavy-tailed function of the KL divergence of a white-noise Gaussian process, allowing latent sequence temporal dependency. We perform systematic experiments to verify its effectiveness and find that it is superior to baseline methods.
Autoregressive Knowledge Distillation through Imitation Learning
Sep 15, 2020
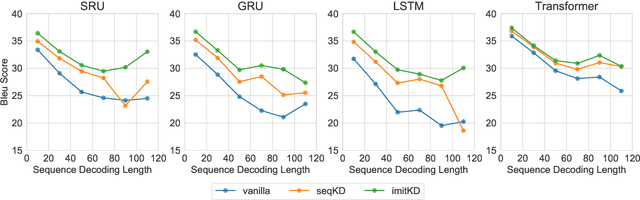
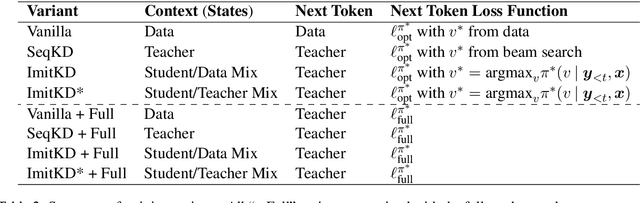
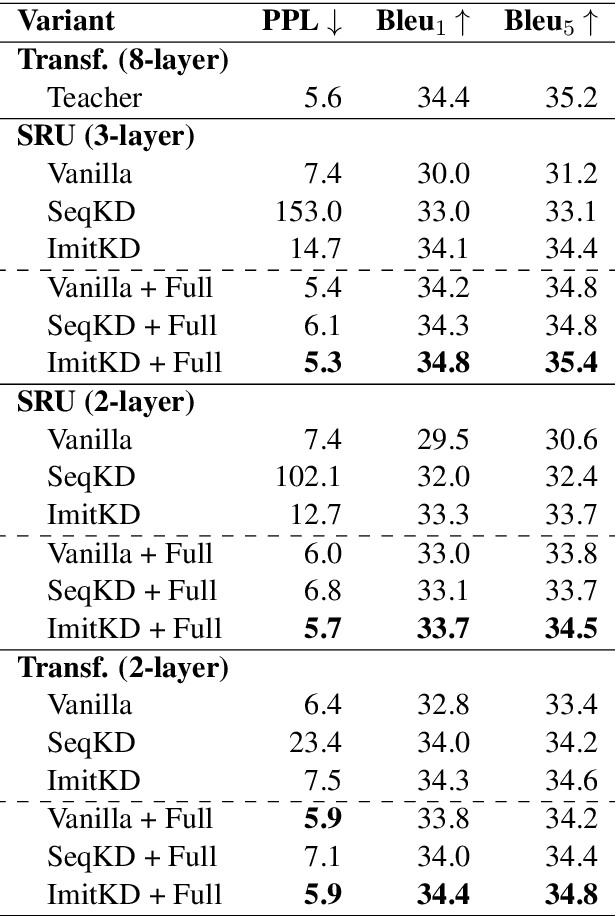
The performance of autoregressive models on natural language generation tasks has dramatically improved due to the adoption of deep, self-attentive architectures. However, these gains have come at the cost of hindering inference speed, making state-of-the-art models cumbersome to deploy in real-world, time-sensitive settings. We develop a compression technique for autoregressive models that is driven by an imitation learning perspective on knowledge distillation. The algorithm is designed to address the exposure bias problem. On prototypical language generation tasks such as translation and summarization, our method consistently outperforms other distillation algorithms, such as sequence-level knowledge distillation. Student models trained with our method attain 1.4 to 4.8 BLEU/ROUGE points higher than those trained from scratch, while increasing inference speed by up to 14 times in comparison to the teacher model.
End-to-End Learning from Noisy Crowd to Supervised Machine Learning Models
Nov 13, 2020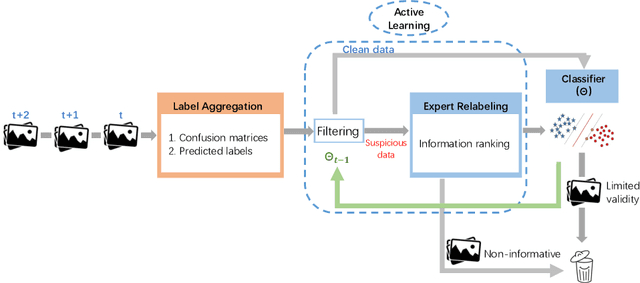
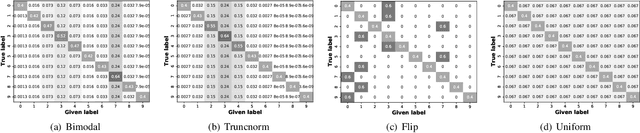
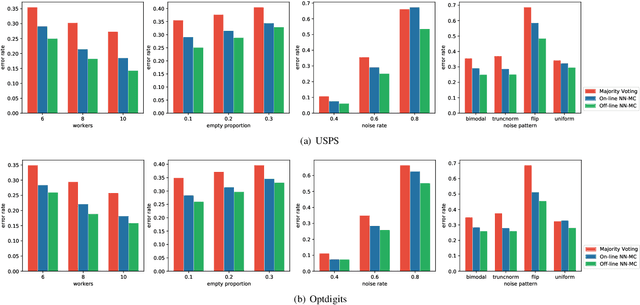
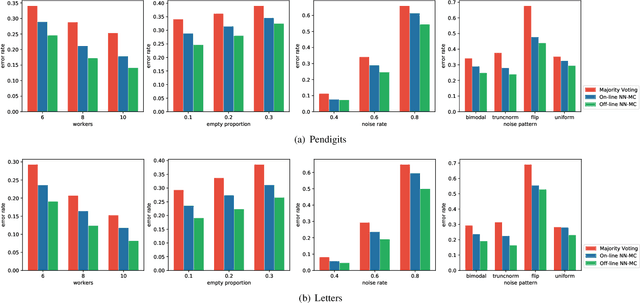
Labeling real-world datasets is time consuming but indispensable for supervised machine learning models. A common solution is to distribute the labeling task across a large number of non-expert workers via crowd-sourcing. Due to the varying background and experience of crowd workers, the obtained labels are highly prone to errors and even detrimental to the learning models. In this paper, we advocate using hybrid intelligence, i.e., combining deep models and human experts, to design an end-to-end learning framework from noisy crowd-sourced data, especially in an on-line scenario. We first summarize the state-of-the-art solutions that address the challenges of noisy labels from non-expert crowd and learn from multiple annotators. We show how label aggregation can benefit from estimating the annotators' confusion matrices to improve the learning process. Moreover, with the help of an expert labeler as well as classifiers, we cleanse aggregated labels of highly informative samples to enhance the final classification accuracy. We demonstrate the effectiveness of our strategies on several image datasets, i.e. UCI and CIFAR-10, using SVM and deep neural networks. Our evaluation shows that our on-line label aggregation with confusion matrix estimation reduces the error rate of labels by over 30%. Furthermore, relabeling only 10% of the data using the expert's results in over 90% classification accuracy with SVM.
When in Doubt, Ask: Generating Answerable and Unanswerable Questions, Unsupervised
Oct 04, 2020
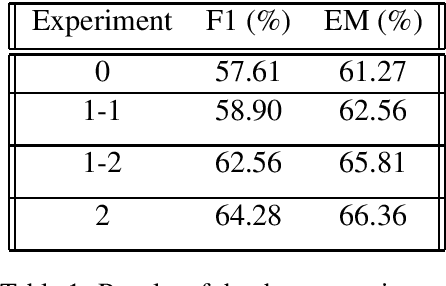


Question Answering (QA) is key for making possible a robust communication between human and machine. Modern language models used for QA have surpassed the human-performance in several essential tasks; however, these models require large amounts of human-generated training data which are costly and time-consuming to create. This paper studies augmenting human-made datasets with synthetic data as a way of surmounting this problem. A state-of-the-art model based on deep transformers is used to inspect the impact of using synthetic answerable and unanswerable questions to complement a well-known human-made dataset. The results indicate a tangible improvement in the performance of the language model (measured in terms of F1 and EM scores) trained on the mixed dataset. Specifically, unanswerable question-answers prove more effective in boosting the model: the F1 score gain from adding to the original dataset the answerable, unanswerable, and combined question-answers were 1.3\%, 5.0\%, and 6.7\%, respectively. [Link to the Github repository: https://github.com/lnikolenko/EQA]
An Efficiency-boosting Client Selection Scheme for Federated Learning with Fairness Guarantee
Nov 04, 2020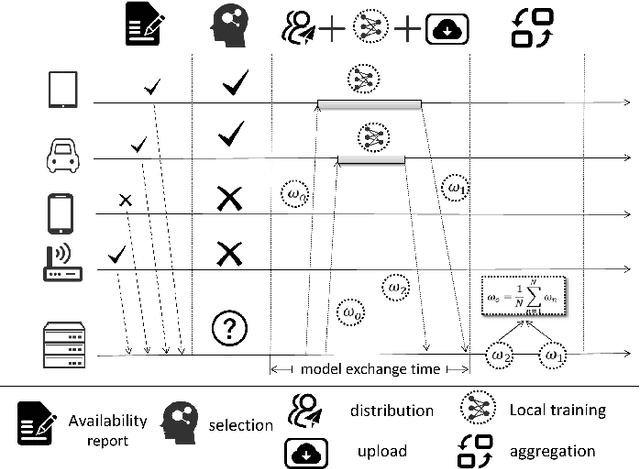


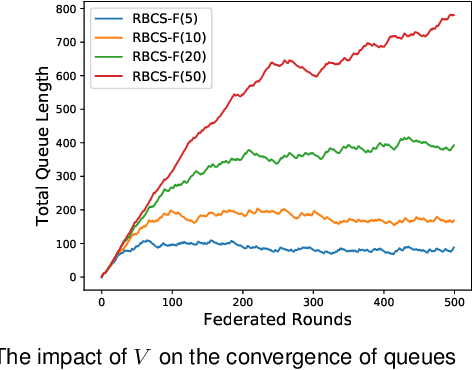
The issue of potential privacy leakage during centralized AI's model training has drawn intensive concern from the public. A Parallel and Distributed Computing (or PDC) scheme, termed Federated Learning (FL), has emerged as a new paradigm to cope with the privacy issue by allowing clients to perform model training locally, without the necessity to upload their personal sensitive data. In FL, the number of clients could be sufficiently large, but the bandwidth available for model distribution and re-upload is quite limited, making it sensible to only involve part of the volunteers to participate in the training process. The client selection policy is critical to an FL process in terms of training efficiency, the final model's quality as well as fairness. In this paper, we will model the fairness guaranteed client selection as a Lyapunov optimization problem and then a C2MAB-based method is proposed for estimation of the model exchange time between each client and the server, based on which we design a fairness guaranteed algorithm termed RBCS-F for problem-solving. The regret of RBCS-F is strictly bounded by a finite constant, justifying its theoretical feasibility. Barring the theoretical results, more empirical data can be derived from our real training experiments on public datasets.
No more 996: Understanding Deep Learning Inference Serving with an Automatic Benchmarking system
Nov 04, 2020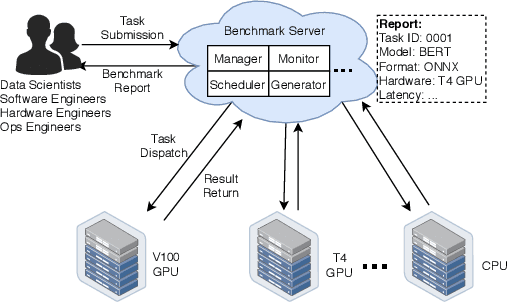

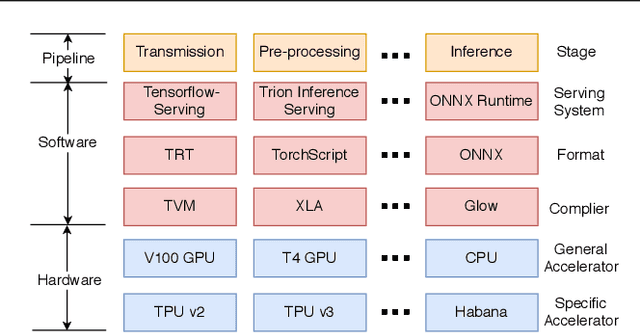
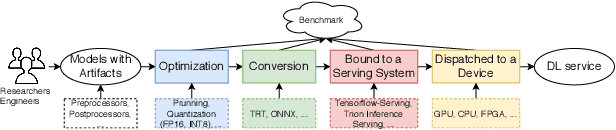
Deep learning (DL) models have become core modules for many applications. However, deploying these models without careful performance benchmarking that considers both hardware and software's impact often leads to poor service and costly operational expenditure. To facilitate DL models' deployment, we implement an automatic and comprehensive benchmark system for DL developers. To accomplish benchmark-related tasks, the developers only need to prepare a configuration file consisting of a few lines of code. Our system, deployed to a leader server in DL clusters, will dispatch users' benchmark jobs to follower workers. Next, the corresponding requests, workload, and even models can be generated automatically by the system to conduct DL serving benchmarks. Finally, developers can leverage many analysis tools and models in our system to gain insights into the trade-offs of different system configurations. In addition, a two-tier scheduler is incorporated to avoid unnecessary interference and improve average job compilation time by up to 1.43x (equivalent of 30\% reduction). Our system design follows the best practice in DL clusters operations to expedite day-to-day DL service evaluation efforts by the developers. We conduct many benchmark experiments to provide in-depth and comprehensive evaluations. We believe these results are of great values as guidelines for DL service configuration and resource allocation.
Quantal synaptic dilution enhances sparse encoding and dropout regularisation in deep networks
Sep 28, 2020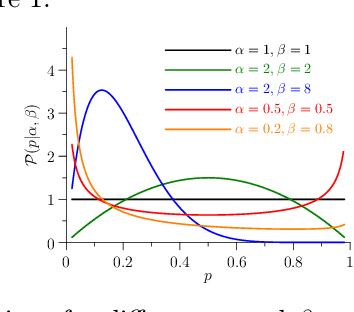
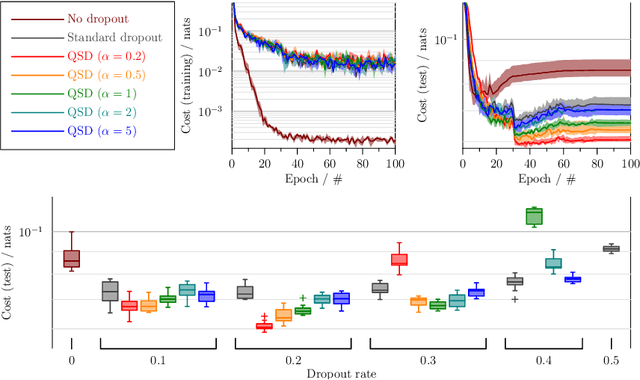
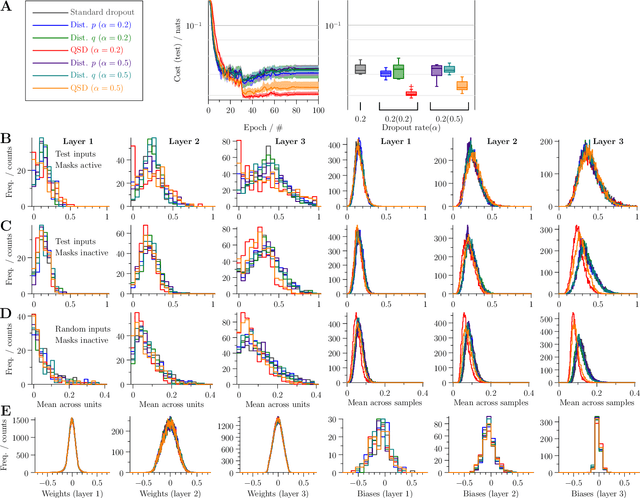
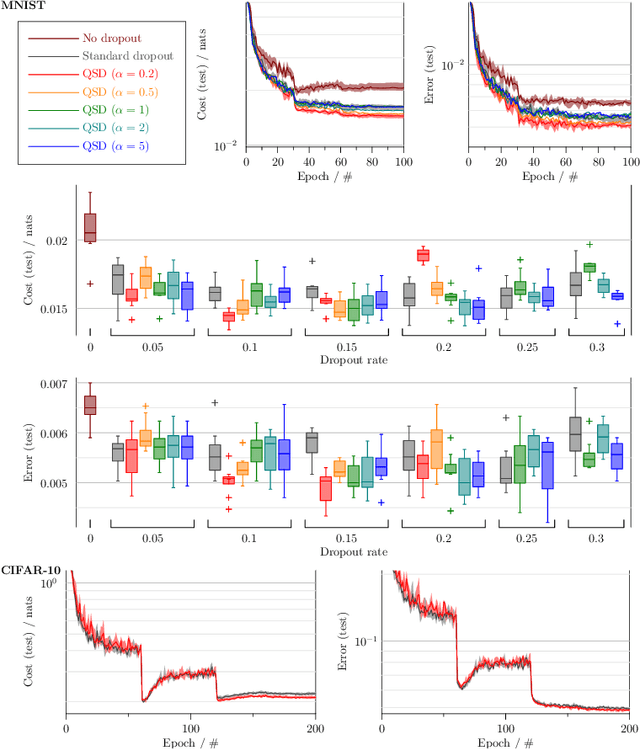
Dropout is a technique that silences the activity of units stochastically while training deep networks to reduce overfitting. Here we introduce Quantal Synaptic Dilution (QSD), a biologically plausible model of dropout regularisation based on the quantal properties of neuronal synapses, that incorporates heterogeneities in response magnitudes and release probabilities for vesicular quanta. QSD outperforms standard dropout in ReLU multilayer perceptrons, with enhanced sparse encoding at test time when dropout masks are replaced with identity functions, without shifts in trainable weight or bias distributions. For convolutional networks, the method also improves generalisation in computer vision tasks with and without inclusion of additional forms of regularisation. QSD also outperforms standard dropout in recurrent networks for language modelling and sentiment analysis. An advantage of QSD over many variations of dropout is that it can be implemented generally in all conventional deep networks where standard dropout is applicable.