 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
The item selection problem for user cold-start recommendation
Oct 27, 2020

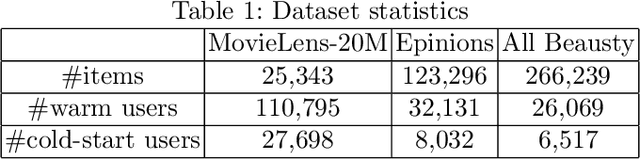
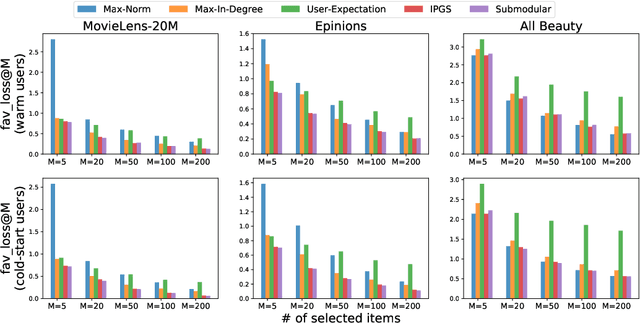
When a new user just signs up on a website, we usually have no information about him/her, i.e. no interaction with items, no user profile and no social links with other users. Under such circumstances, we still expect our recommender systems could attract the users at the first time so that the users decide to stay on the website and become active users. This problem falls into new user cold-start category and it is crucial to the development and even survival of a company. Existing works on user cold-start recommendation either require additional user efforts, e.g. setting up an interview process, or make use of side information [10] such as user demographics, locations, social relations, etc. However, users may not be willing to take the interview and side information on cold-start users is usually not available. Therefore, we consider a pure cold-start scenario where neither interaction nor side information is available and no user effort is required. Studying this setting is also important for the initialization of other cold-start solutions, such as initializing the first few questions of an interview.
SuperSuit: Simple Microwrappers for Reinforcement Learning Environments
Aug 17, 2020In reinforcement learning, wrappers are universally used to transform the information that passes between a model and an environment. Despite their ubiquity, no library exists with reasonable implementations of all popular preprocessing methods. This leads to unnecessary bugs, code inefficiencies, and wasted developer time. Accordingly we introduce SuperSuit, a Python library that includes all popular wrappers, and wrappers that can easily apply lambda functions to the observations/actions/reward. It's compatible with the standard Gym environment specification, as well as the PettingZoo specification for multi-agent environments. The library is available at https://github.com/PettingZoo-Team/SuperSuit,and can be installed via pip.
Esophageal Tumor Segmentation in CT Images using a 3D Convolutional Neural Network
Dec 06, 2020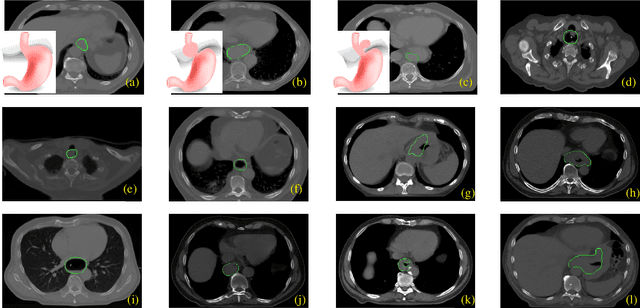
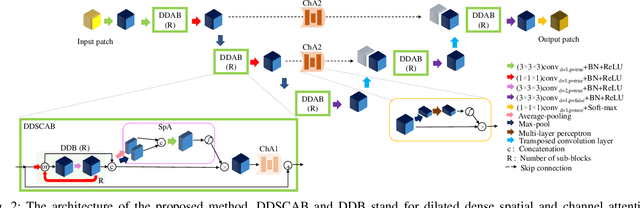
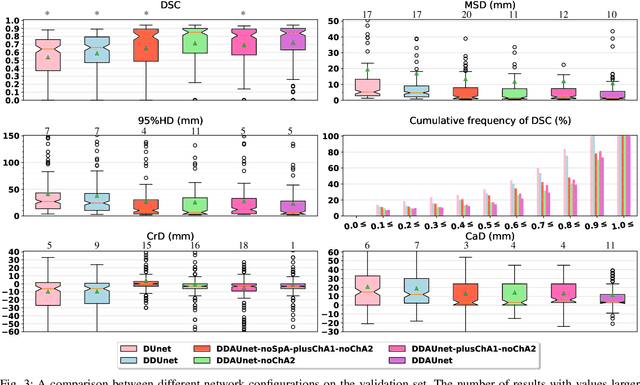
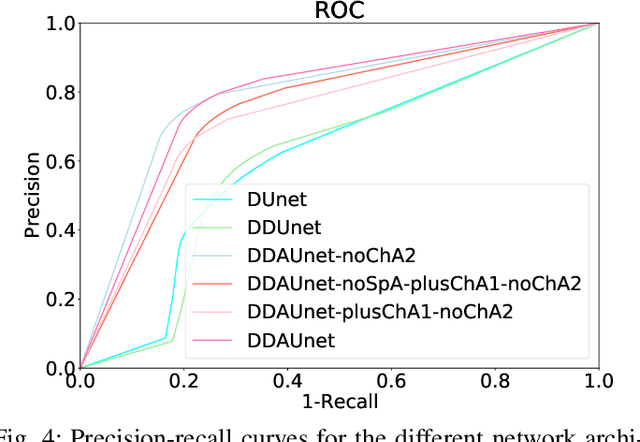
Manual or automatic delineation of the esophageal tumor in CT images is known to be very challenging. This is due to the low contrast between the tumor and adjacent tissues, the anatomical variation of the esophagus, as well as the occasional presence of foreign bodies (e.g. feeding tubes). Physicians therefore usually exploit additional knowledge such as endoscopic findings, clinical history, additional imaging modalities like PET scans. Achieving his additional information is time-consuming, while the results are error-prone and might lead to non-deterministic results. In this paper we aim to investigate if and to what extent a simplified clinical workflow based on CT alone, allows one to automatically segment the esophageal tumor with sufficient quality. For this purpose, we present a fully automatic end-to-end esophageal tumor segmentation method based on convolutional neural networks (CNNs). The proposed network, called Dilated Dense Attention Unet (DDAUnet), leverages spatial and channel attention gates in each dense block to selectively concentrate on determinant feature maps and regions. Dilated convolutional layers are used to manage GPU memory and increase the network receptive field. We collected a dataset of 792 scans from 288 distinct patients including varying anatomies with \mbox{air pockets}, feeding tubes and proximal tumors. Repeatability and reproducibility studies were conducted for three distinct splits of training and validation sets. The proposed network achieved a $\mathrm{DSC}$ value of $0.79 \pm 0.20$, a mean surface distance of $5.4 \pm 20.2mm$ and $95\%$ Hausdorff distance of $14.7 \pm 25.0mm$ for 287 test scans, demonstrating promising results with a simplified clinical workflow based on CT alone. Our code is publicly available via \url{https://github.com/yousefis/DenseUnet_Esophagus_Segmentation}.
Directed Time Series Regression for Control
Jun 26, 2012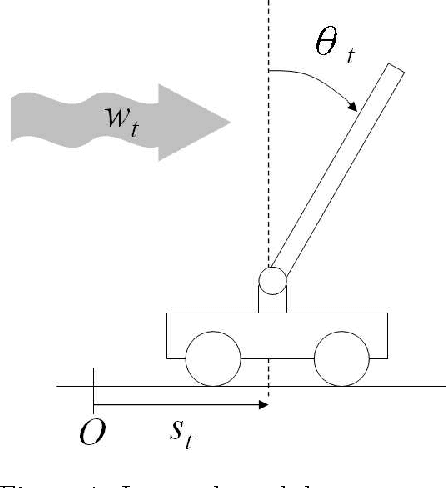
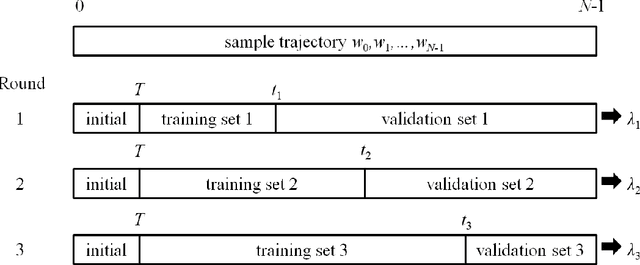
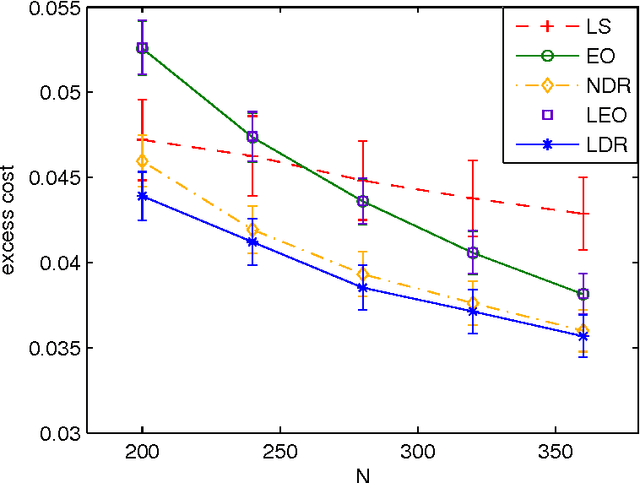
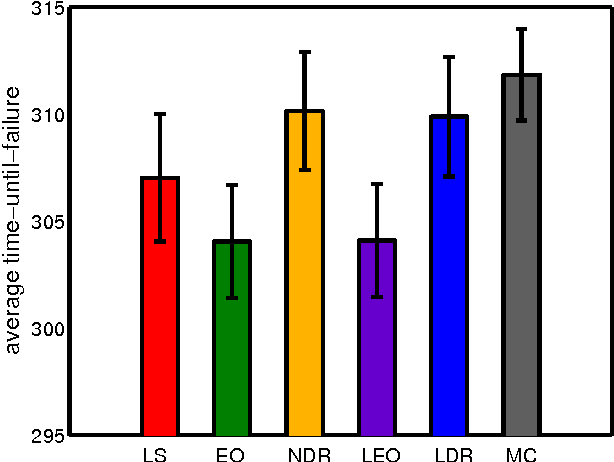
We propose directed time series regression, a new approach to estimating parameters of time-series models for use in certainty equivalent model predictive control. The approach combines merits of least squares regression and empirical optimization. Through a computational study involving a stochastic version of a well known inverted pendulum balancing problem, we demonstrate that directed time series regression can generate significant improvements in controller performance over either of the aforementioned alternatives.
Leveraging TSP Solver Complementarity via Deep Learning
Jun 01, 2020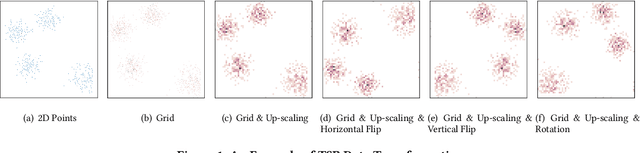
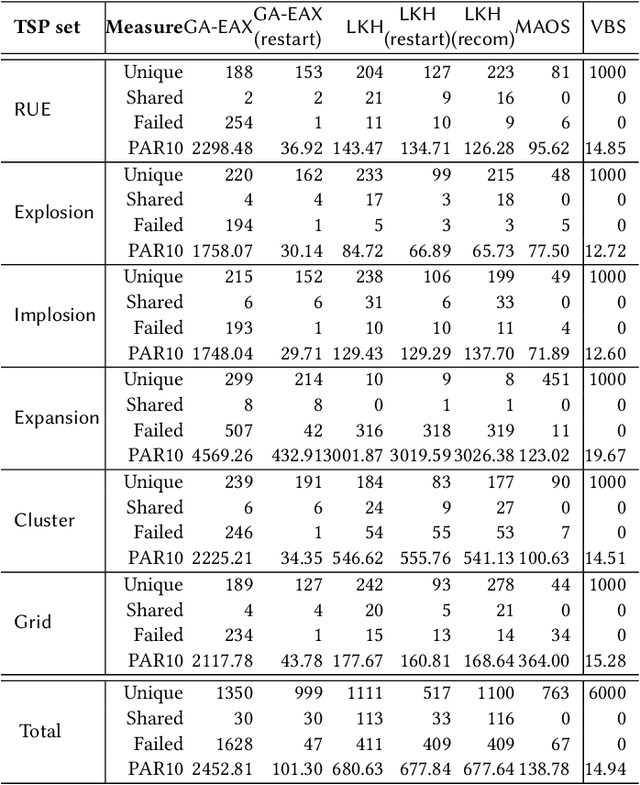

The Travelling Salesman Problem (TSP) is a classical NP-hard problem and has broad applications in many disciplines and industries. In a large scale location-based services system, users issue TSP queries concurrently, where a TSP query is a TSP instance with $n$ points. In the literature, many advanced TSP solvers are developed to find high-quality solutions. Such solvers can solve some TSP instances efficiently but may take an extremely long time for some other instances. Due to the diversity of TSP instances, it is well-known that there exists no universal best solver dominating all other solvers on all possible TSP instances. To solve TSP efficiently, in addition to developing new TSP solvers, it needs to find a per-instance solver for each TSP instance, which is known as the TSP solver selection problem. In this paper, for the first time, we propose a deep learning framework, \CTAS, for TSP solver selection in an end-to-end manner. Specifically, \CTAS exploits deep convolutional neural networks to extract informative features from TSP instances and involves data argumentation strategies to handle the scarcity of labeled TSP instances. Moreover, to support large scale TSP solver selection, we construct a challenging TSP benchmark dataset with 6,000 instances, which is known as the largest TSP benchmark. Our \CTAS achieves over 2$\times$ speedup of the average running time, comparing the single best solver, and outperforms the state-of-the-art statistical models.
Feature Selection for Huge Data via Minipatch Learning
Oct 16, 2020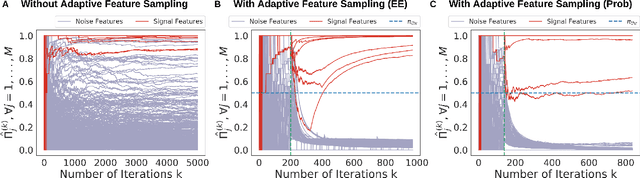
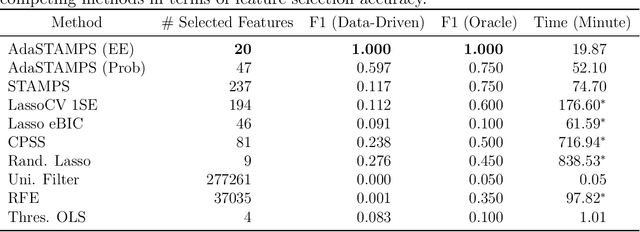
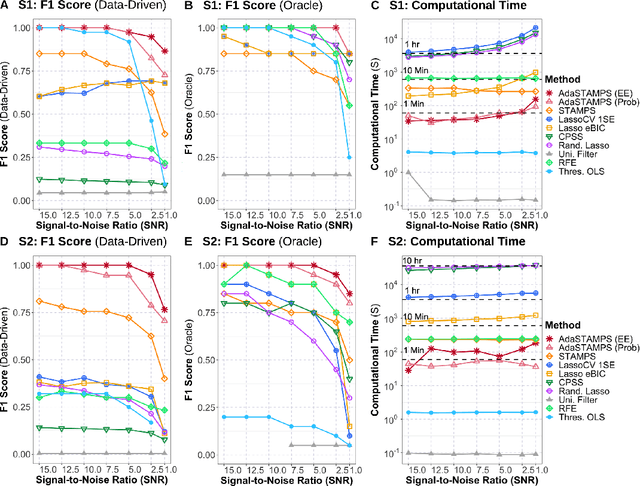
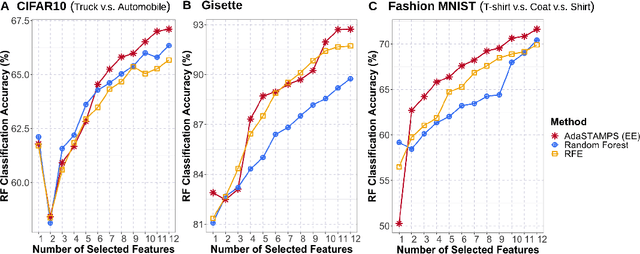
Feature selection often leads to increased model interpretability, faster computation, and improved model performance by discarding irrelevant or redundant features. While feature selection is a well-studied problem with many widely-used techniques, there are typically two key challenges: i) many existing approaches become computationally intractable in huge-data settings with millions of observations and features; and ii) the statistical accuracy of selected features degrades in high-noise, high-correlation settings, thus hindering reliable model interpretation. We tackle these problems by proposing Stable Minipatch Selection (STAMPS) and Adaptive STAMPS (AdaSTAMPS). These are meta-algorithms that build ensembles of selection events of base feature selectors trained on many tiny, (adaptively-chosen) random subsets of both the observations and features of the data, which we call minipatches. Our approaches are general and can be employed with a variety of existing feature selection strategies and machine learning techniques. In addition, we provide theoretical insights on STAMPS and empirically demonstrate that our approaches, especially AdaSTAMPS, dominate competing methods in terms of feature selection accuracy and computational time.
Message Passing Neural Processes
Sep 29, 2020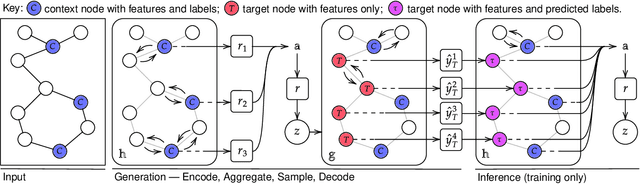
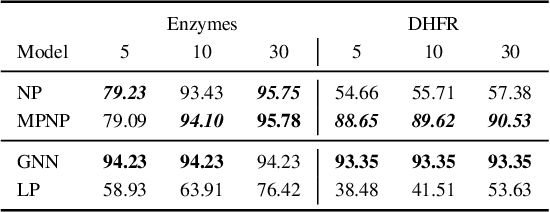
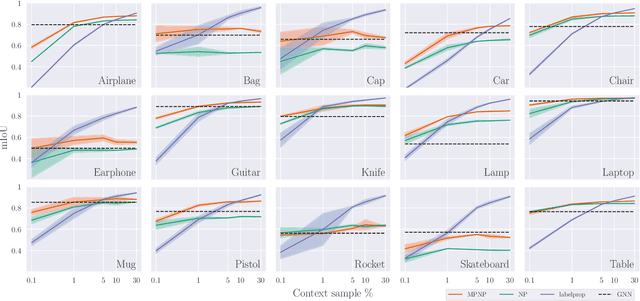
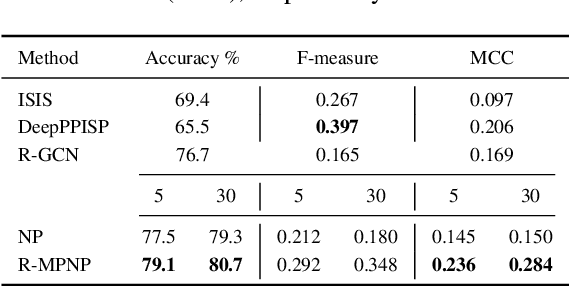
Neural Processes (NPs) are powerful and flexible models able to incorporate uncertainty when representing stochastic processes, while maintaining a linear time complexity. However, NPs produce a latent description by aggregating independent representations of context points and lack the ability to exploit relational information present in many datasets. This renders NPs ineffective in settings where the stochastic process is primarily governed by neighbourhood rules, such as cellular automata (CA), and limits performance for any task where relational information remains unused. We address this shortcoming by introducing Message Passing Neural Processes (MPNPs), the first class of NPs that explicitly makes use of relational structure within the model. Our evaluation shows that MPNPs thrive at lower sampling rates, on existing benchmarks and newly-proposed CA and Cora-Branched tasks. We further report strong generalisation over density-based CA rule-sets and significant gains in challenging arbitrary-labelling and few-shot learning setups.
Machine Learning-Powered Mitigation Policy Optimization in Epidemiological Models
Oct 16, 2020
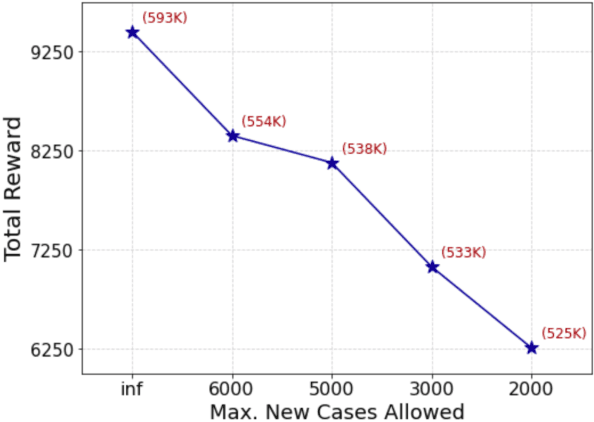

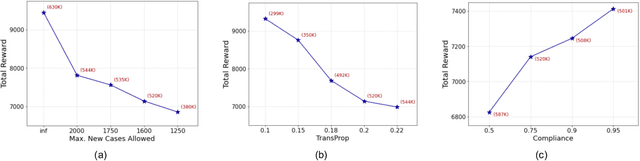
A crucial aspect of managing a public health crisis is to effectively balance prevention and mitigation strategies, while taking their socio-economic impact into account. In particular, determining the influence of different non-pharmaceutical interventions (NPIs) on the effective use of public resources is an important problem, given the uncertainties on when a vaccine will be made available. In this paper, we propose a new approach for obtaining optimal policy recommendations based on epidemiological models, which can characterize the disease progression under different interventions, and a look-ahead reward optimization strategy to choose the suitable NPI at different stages of an epidemic. Given the time delay inherent in any epidemiological model and the exponential nature especially of an unmanaged epidemic, we find that such a look-ahead strategy infers non-trivial policies that adhere well to the constraints specified. Using two different epidemiological models, namely SEIR and EpiCast, we evaluate the proposed algorithm to determine the optimal NPI policy, under a constraint on the number of daily new cases and the primary reward being the absence of restrictions.
A Homotopic Method to Solve the Lasso Problems with an Improved Upper Bound of Convergence Rate
Oct 26, 2020
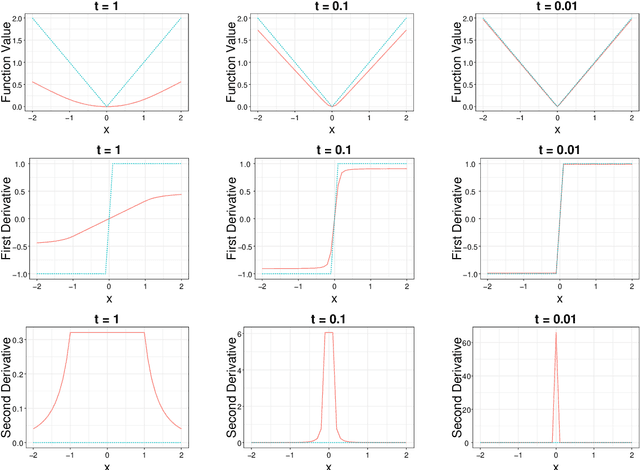
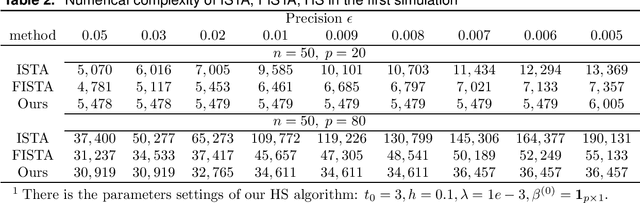
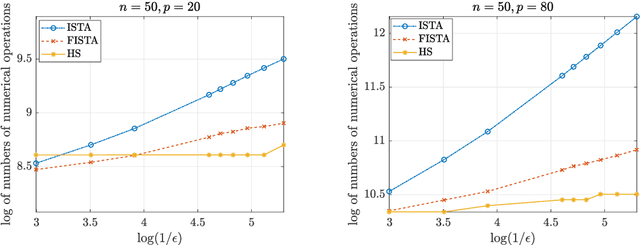
In optimization, it is known that when the objective functions are strictly convex and well-conditioned, gradient based approaches can be extremely effective, e.g., achieving the exponential rate in convergence. On the other hand, the existing Lasso-type of estimator in general cannot achieve the optimal rate due to the undesirable behavior of the absolute function at the origin. A homotopic method is to use a sequence of surrogate functions to approximate the $\ell_1$ penalty that is used in the Lasso-type of estimators. The surrogate functions will converge to the $\ell_1$ penalty in the Lasso estimator. At the same time, each surrogate function is strictly convex, which enables provable faster numerical rate of convergence. In this paper, we demonstrate that by meticulously defining the surrogate functions, one can prove faster numerical convergence rate than any existing methods in computing for the Lasso-type of estimators. Namely, the state-of-the-art algorithms can only guarantee $O(1/\epsilon)$ or $O(1/\sqrt{\epsilon})$ convergence rates, while we can prove an $O([\log(1/\epsilon)]^2)$ for the newly proposed algorithm. Our numerical simulations show that the new algorithm also performs better empirically.
An efficient representation of chronological events in medical texts
Oct 16, 2020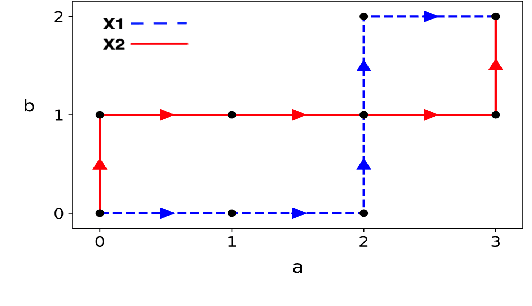
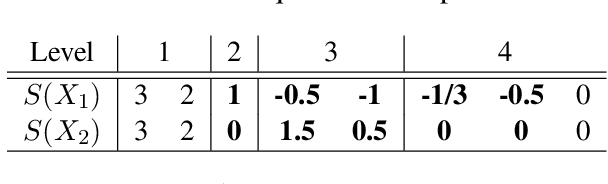

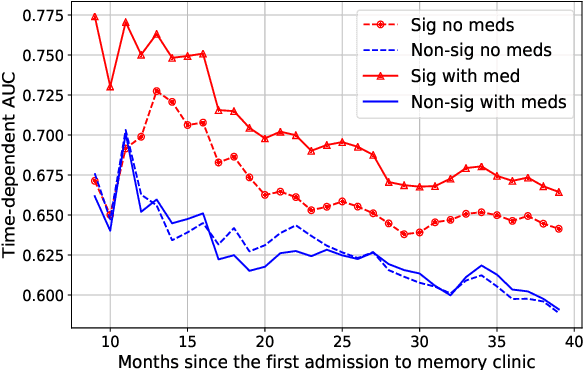
In this work we addressed the problem of capturing sequential information contained in longitudinal electronic health records (EHRs). Clinical notes, which is a particular type of EHR data, are a rich source of information and practitioners often develop clever solutions how to maximise the sequential information contained in free-texts. We proposed a systematic methodology for learning from chronological events available in clinical notes. The proposed methodological {\it path signature} framework creates a non-parametric hierarchical representation of sequential events of any type and can be used as features for downstream statistical learning tasks. The methodology was developed and externally validated using the largest in the UK secondary care mental health EHR data on a specific task of predicting survival risk of patients diagnosed with Alzheimer's disease. The signature-based model was compared to a common survival random forest model. Our results showed a 15.4$\%$ increase of risk prediction AUC at the time point of 20 months after the first admission to a specialist memory clinic and the signature method outperformed the baseline mixed-effects model by 13.2 $\%$.