 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Defense-friendly Images in Adversarial Attacks: Dataset and Metrics for Perturbation Difficulty
Nov 07, 2020
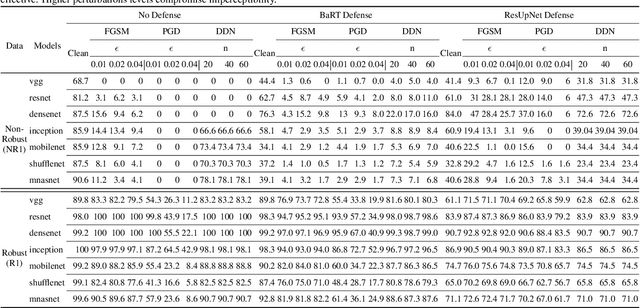
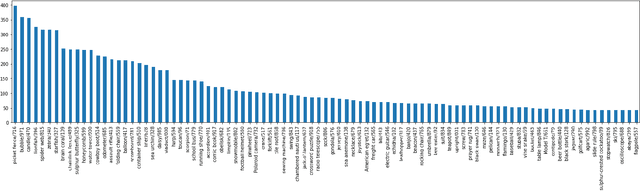
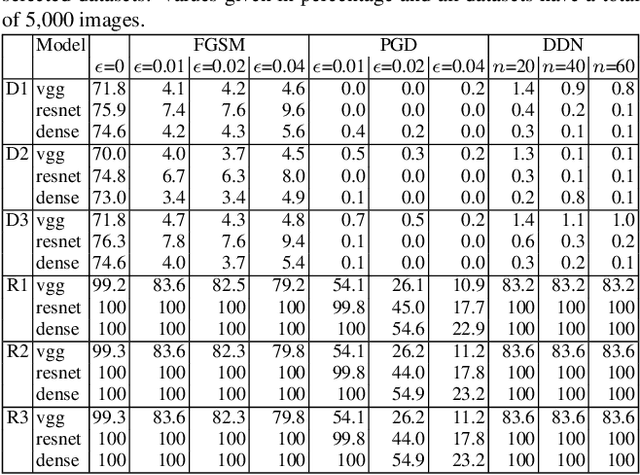

Dataset bias is a problem in adversarial machine learning, especially in the evaluation of defenses. An adversarial attack or defense algorithm may show better results on the reported dataset than can be replicated on other datasets. Even when two algorithms are compared, their relative performance can vary depending on the dataset. Deep learning offers state-of-the-art solutions for image recognition, but deep models are vulnerable even to small perturbations. Research in this area focuses primarily on adversarial attacks and defense algorithms. In this paper, we report for the first time, a class of robust images that are both resilient to attacks and that recover better than random images under adversarial attacks using simple defense techniques. Thus, a test dataset with a high proportion of robust images gives a misleading impression about the performance of an adversarial attack or defense. We propose three metrics to determine the proportion of robust images in a dataset and provide scoring to determine the dataset bias. We also provide an ImageNet-R dataset of 15000+ robust images to facilitate further research on this intriguing phenomenon of image strength under attack. Our dataset, combined with the proposed metrics, is valuable for unbiased benchmarking of adversarial attack and defense algorithms.
SipMask: Spatial Information Preservation for Fast Image and Video Instance Segmentation
Jul 29, 2020
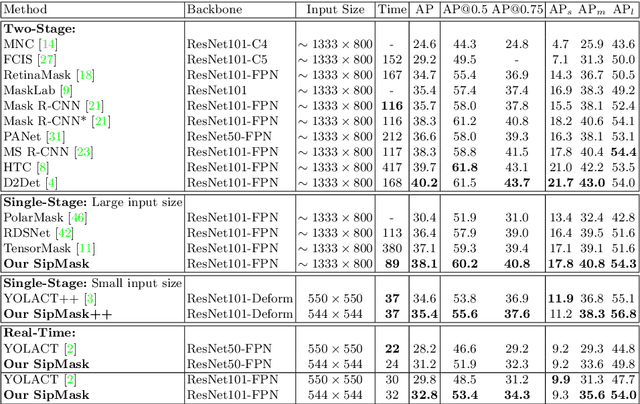
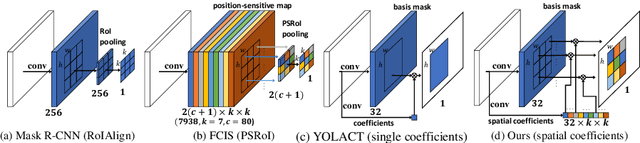
Single-stage instance segmentation approaches have recently gained popularity due to their speed and simplicity, but are still lagging behind in accuracy, compared to two-stage methods. We propose a fast single-stage instance segmentation method, called SipMask, that preserves instance-specific spatial information by separating mask prediction of an instance to different sub-regions of a detected bounding-box. Our main contribution is a novel light-weight spatial preservation (SP) module that generates a separate set of spatial coefficients for each sub-region within a bounding-box, leading to improved mask predictions. It also enables accurate delineation of spatially adjacent instances. Further, we introduce a mask alignment weighting loss and a feature alignment scheme to better correlate mask prediction with object detection. On COCO test-dev, our SipMask outperforms the existing single-stage methods. Compared to the state-of-the-art single-stage TensorMask, SipMask obtains an absolute gain of 1.0% (mask AP), while providing a four-fold speedup. In terms of real-time capabilities, SipMask outperforms YOLACT with an absolute gain of 3.0% (mask AP) under similar settings, while operating at comparable speed on a Titan Xp. We also evaluate our SipMask for real-time video instance segmentation, achieving promising results on YouTube-VIS dataset. The source code is available at https://github.com/JialeCao001/SipMask.
Unmasking Communication Partners: A Low-Cost AI Solution for Digitally Removing Head-Mounted Displays in VR-Based Telepresence
Nov 06, 2020

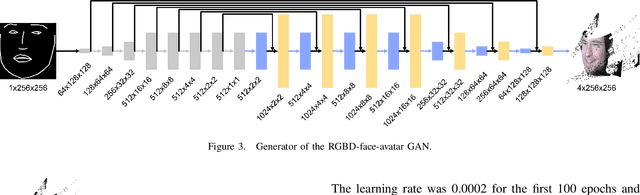
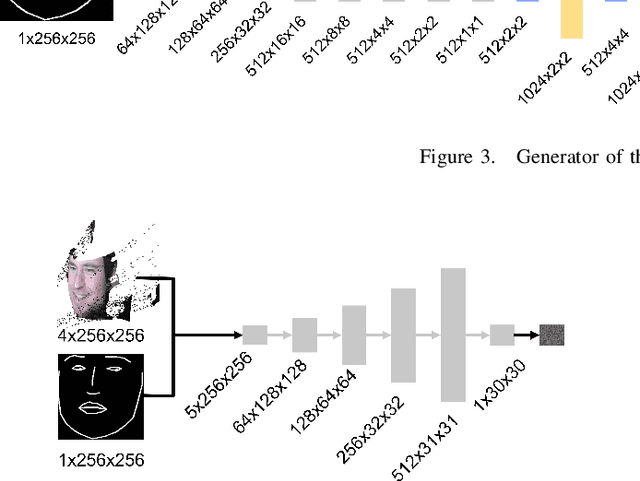
Face-to-face conversation in Virtual Reality (VR) is a challenge when participants wear head-mounted displays (HMD). A significant portion of a participant's face is hidden and facial expressions are difficult to perceive. Past research has shown that high-fidelity face reconstruction with personal avatars in VR is possible under laboratory conditions with high-cost hardware. In this paper, we propose one of the first low-cost systems for this task which uses only open source, free software and affordable hardware. Our approach is to track the user's face underneath the HMD utilizing a Convolutional Neural Network (CNN) and generate corresponding expressions with Generative Adversarial Networks (GAN) for producing RGBD images of the person's face. We use commodity hardware with low-cost extensions such as 3D-printed mounts and miniature cameras. Our approach learns end-to-end without manual intervention, runs in real time, and can be trained and executed on an ordinary gaming computer. We report evaluation results showing that our low-cost system does not achieve the same fidelity of research prototypes using high-end hardware and closed source software, but it is capable of creating individual facial avatars with person-specific characteristics in movements and expressions.
Efficient Permutation Discovery in Causal DAGs
Nov 06, 2020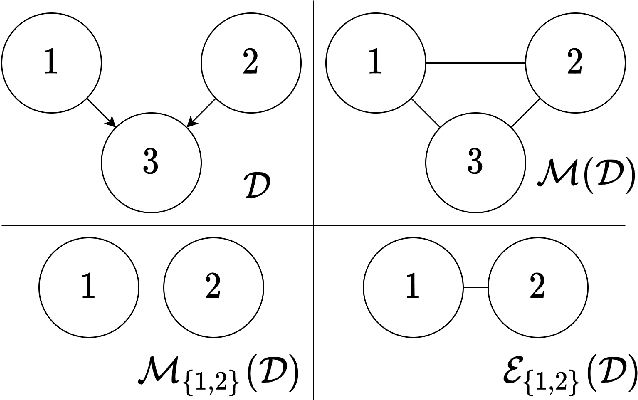
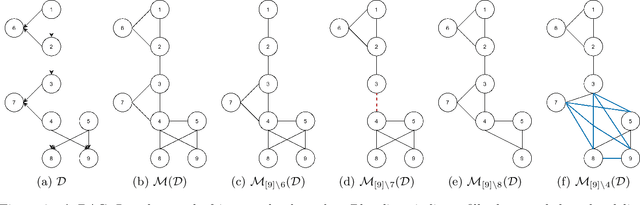
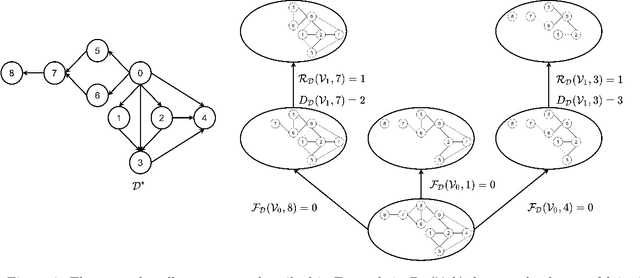
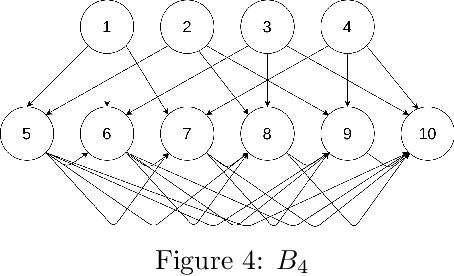
The problem of learning a directed acyclic graph (DAG) up to Markov equivalence is equivalent to the problem of finding a permutation of the variables that induces the sparsest graph. Without additional assumptions, this task is known to be NP-hard. Building on the minimum degree algorithm for sparse Cholesky decomposition, but utilizing DAG-specific problem structure, we introduce an efficient algorithm for finding such sparse permutations. We show that on jointly Gaussian distributions, our method with depth $w$ runs in $O(p^{w+3})$ time. We compare our method with $w = 1$ to algorithms for finding sparse elimination orderings of undirected graphs, and show that taking advantage of DAG-specific problem structure leads to a significant improvement in the discovered permutation. We also compare our algorithm to provably consistent causal structure learning algorithms, such as the PC algorithm, GES, and GSP, and show that our method achieves comparable performance with a shorter runtime. Thus, our method can be used on its own for causal structure discovery. Finally, we show that there exist dense graphs on which our method achieves almost perfect performance, so that unlike most existing causal structure learning algorithms, the situations in which our algorithm achieves both good performance and good runtime are not limited to sparse graphs.
Explainable Artificial Intelligence for Manufacturing Cost Estimation and Machining Feature Visualization
Oct 28, 2020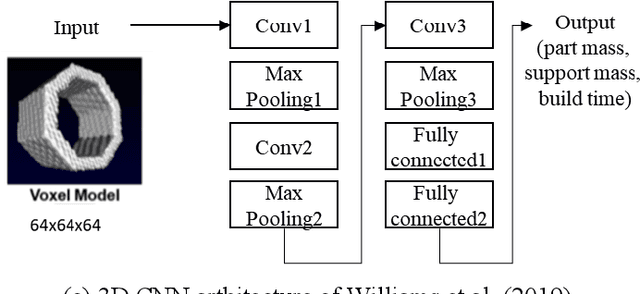
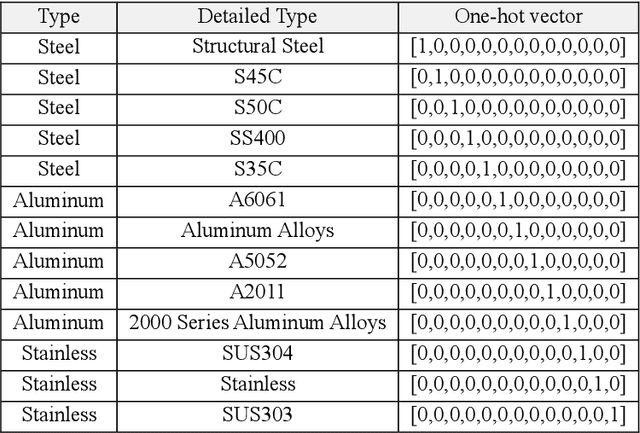
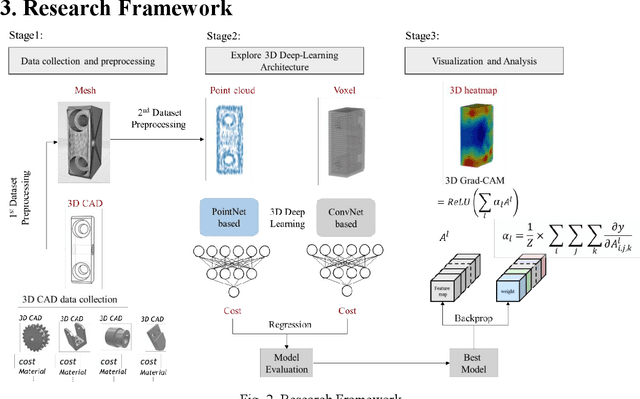
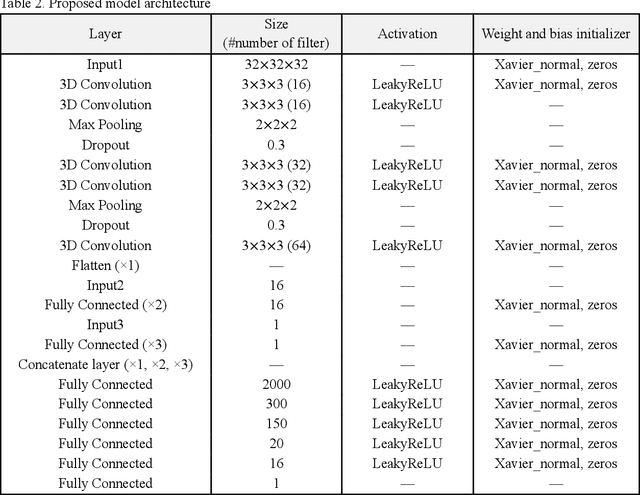
Studies on manufacturing cost prediction based on deep learning have begun in recent years, but the cost prediction rationale cannot be explained because the models are still used as a black box. This study aims to propose a manufacturing cost prediction process for 3D computer-aided design (CAD) models using explainable artificial intelligence. The proposed process can visualize the machining features of the 3D CAD model that are influencing the increase in manufacturing costs. The proposed process consists of (1) data collection and pre-processing, (2) 3D deep learning architecture exploration, and (3) visualization to explain the prediction results. The proposed deep learning model shows high predictability of manufacturing cost for the computer numerical control (CNC) machined parts. In particular, using 3D gradient-weighted class activation mapping proves that the proposed model not only can detect the CNC machining features but also can differentiate the machining difficulty for the same feature. Using the proposed process, we can provide a design guidance to engineering designers in reducing manufacturing costs during the conceptual design phase. We can also provide real-time quotations and redesign proposals to online manufacturing platform customers.
A Game AI Competition to foster Collaborative AI research and development
Oct 17, 2020
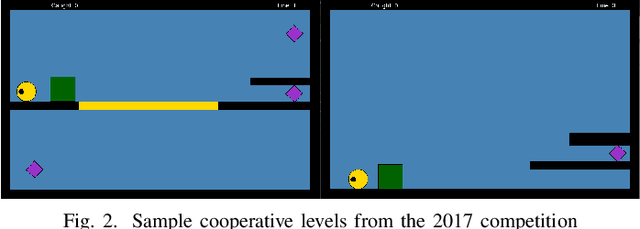
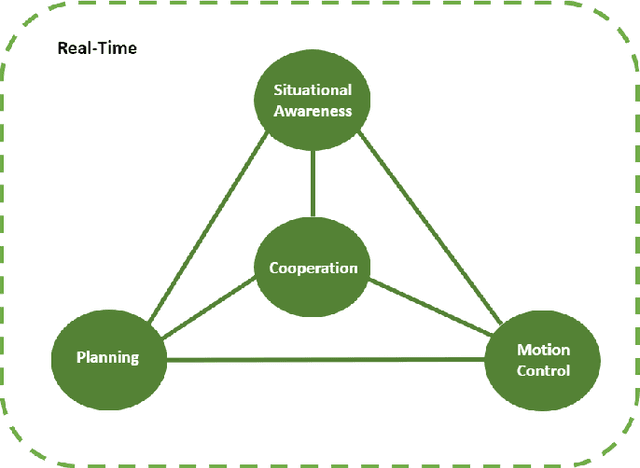
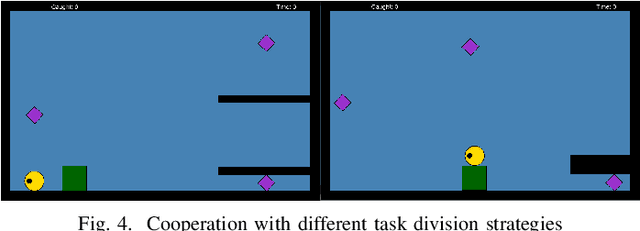
Game AI competitions are important to foster research and development on Game AI and AI in general. These competitions supply different challenging problems that can be translated into other contexts, virtual or real. They provide frameworks and tools to facilitate the research on their core topics and provide means for comparing and sharing results. A competition is also a way to motivate new researchers to study these challenges. In this document, we present the Geometry Friends Game AI Competition. Geometry Friends is a two-player cooperative physics-based puzzle platformer computer game. The concept of the game is simple, though its solving has proven to be difficult. While the main and apparent focus of the game is cooperation, it also relies on other AI-related problems such as planning, plan execution, and motion control, all connected to situational awareness. All of these must be solved in real-time. In this paper, we discuss the competition and the challenges it brings, and present an overview of the current solutions.
ECG Classification with a Convolutional Recurrent Neural Network
Oct 06, 2020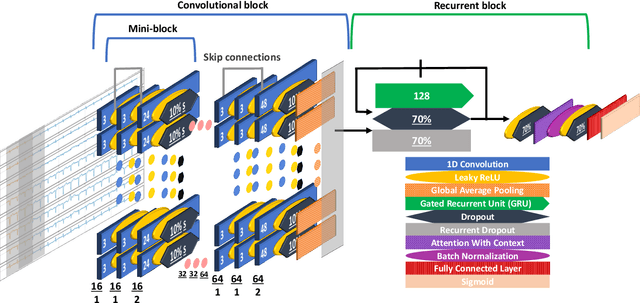
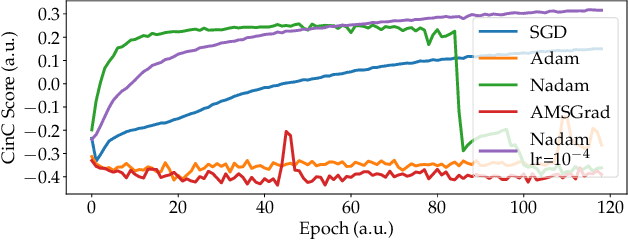
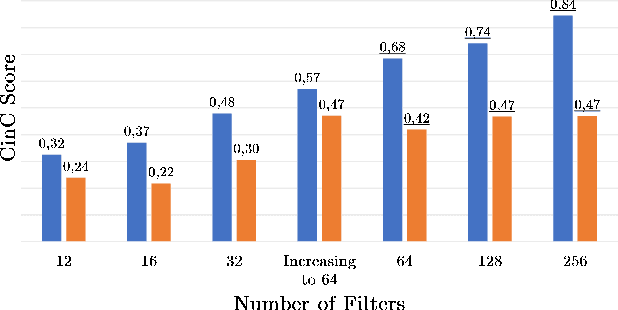
We developed a convolutional recurrent neural network to classify 12-lead ECG signals for the challenge of PhysioNet/ Computing in Cardiology 2020 as team Pink Irish Hat. The model combines convolutional and recurrent layers, takes sliding windows of ECG signals as input and yields the probability of each class as output. The convolutional part extracts features from each sliding window. The bi-directional gated recurrent unit (GRU) layer and an attention layer aggregate these features from all windows into a single feature vector. Finally, a dense layer outputs class probabilities. The final decision is made using test time augmentation (TTA) and an optimized decision threshold. Several hyperparameters of our architecture were optimized, the most important of which turned out to be the choice of optimizer and the number of filters per convolutional layer. Our network achieved a challenge score of 0.511 on the hidden validation set and 0.167 on the full hidden test set, ranking us 23rd out of 41 in the official ranking.
Leveraging TSP Solver Complementarity via Deep Learning
Jun 01, 2020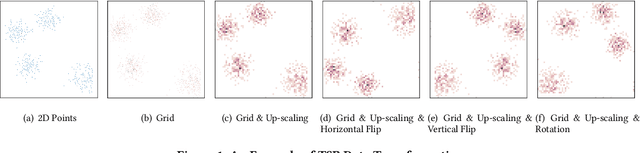
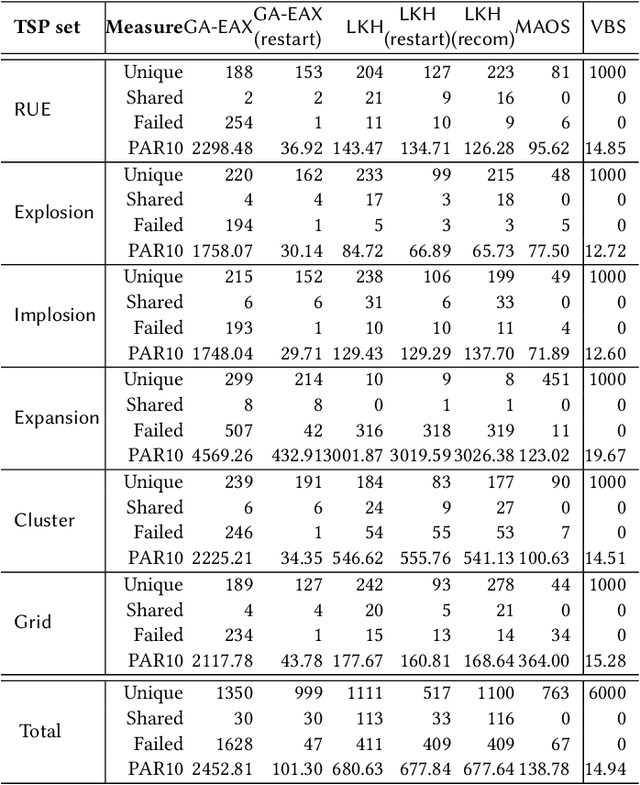

The Travelling Salesman Problem (TSP) is a classical NP-hard problem and has broad applications in many disciplines and industries. In a large scale location-based services system, users issue TSP queries concurrently, where a TSP query is a TSP instance with $n$ points. In the literature, many advanced TSP solvers are developed to find high-quality solutions. Such solvers can solve some TSP instances efficiently but may take an extremely long time for some other instances. Due to the diversity of TSP instances, it is well-known that there exists no universal best solver dominating all other solvers on all possible TSP instances. To solve TSP efficiently, in addition to developing new TSP solvers, it needs to find a per-instance solver for each TSP instance, which is known as the TSP solver selection problem. In this paper, for the first time, we propose a deep learning framework, \CTAS, for TSP solver selection in an end-to-end manner. Specifically, \CTAS exploits deep convolutional neural networks to extract informative features from TSP instances and involves data argumentation strategies to handle the scarcity of labeled TSP instances. Moreover, to support large scale TSP solver selection, we construct a challenging TSP benchmark dataset with 6,000 instances, which is known as the largest TSP benchmark. Our \CTAS achieves over 2$\times$ speedup of the average running time, comparing the single best solver, and outperforms the state-of-the-art statistical models.
Frost filtered scale-invariant feature extraction and multilayer perceptron for hyperspectral image classification
Jun 18, 2020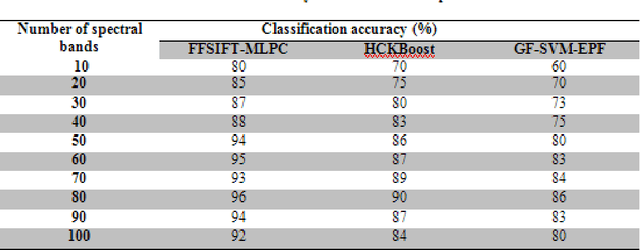
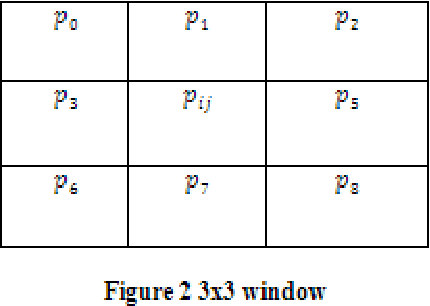
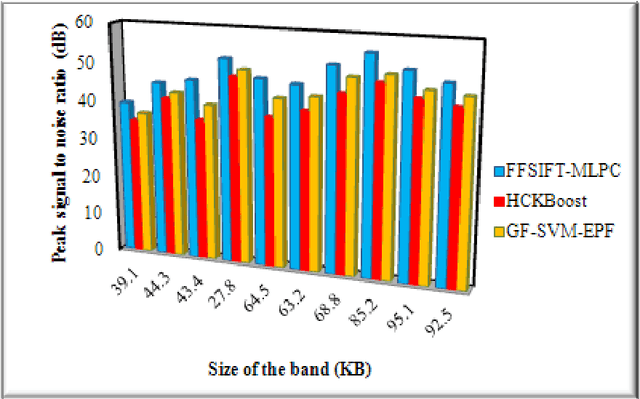
Hyperspectral image (HSI) classification plays a significant in the field of remote sensing due to its ability to provide spatial and spectral information. Due to the rapid development and increasing of hyperspectral remote sensing technology, many methods have been developed for HSI classification but still a lack of achieving the better performance. A Frost Filtered Scale-Invariant Feature Transformation based MultiLayer Perceptron Classification (FFSIFT-MLPC) technique is introduced for classifying the hyperspectral image with higher accuracy and minimum time consumption. The FFSIFT-MLPC technique performs three major processes, namely preprocessing, feature extraction and classification using multiple layers. Initially, the hyperspectral image is divided into number of spectral bands. These bands are given as input in the input layer of perceptron. Then the Frost filter is used in FFSIFT-MLPC technique for preprocessing the input bands which helps to remove the noise from hyper-spectral image at the first hidden layer. After preprocessing task, texture, color and object features of hyper-spectral image are extracted at second hidden layer using Gaussian distributive scale-invariant feature transform. At the third hidden layer, Euclidean distance is measured between the extracted features and testing features. Finally, feature matching is carried out at the output layer for hyper-spectral image classification. The classified outputs are resulted in terms of spectral bands (i.e., different colors). Experimental analysis is performed with PSNR, classification accuracy, false positive rate and classification time with number of spectral bands. The results evident that presented FFSIFT-MLPC technique improves the hyperspectral image classification accuracy, PSNR and minimizes false positive rate as well as classification time than the state-of-the-art methods.
Continuous Chaotic Nonlinear System and Lyapunov controller Optimization using Deep Learning
Oct 28, 2020
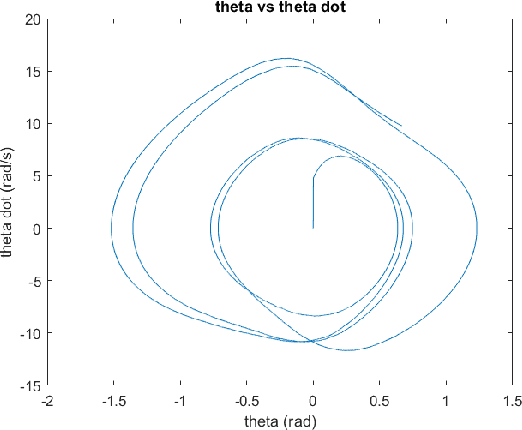

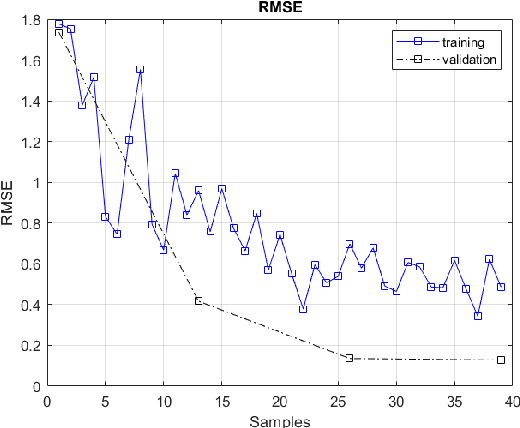
The introduction of unexpected system disturbances and new system dynamics does not allow initially selected static system and controller parameters to guarantee continued system stability and performance. In this research we present a novel approach for detecting early failure indicators of non-linear highly chaotic system and accordingly predict the best parameter calibrations to offset such instability using deep machine learning regression model. The approach proposed continuously monitors the system and controller signals. The Re-calibration of the system and controller parameters is triggered according to a set of conditions designed to maintain system stability without compromise to the system speed, intended outcome or required processing power. The deep neural model predicts the parameter values that would best counteract the expected system in-stability. To demonstrate the effectiveness of the proposed approach, it is applied to the non-linear complex combination of Duffing Van der pol oscillators. The approach is also tested under different scenarios the system and controller parameters are initially chosen incorrectly or the system parameters are changed while running or new system dynamics are introduced while running to measure effectiveness and reaction time.