 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Robust Model-Free Learning and Control without Prior Knowledge
Oct 01, 2020
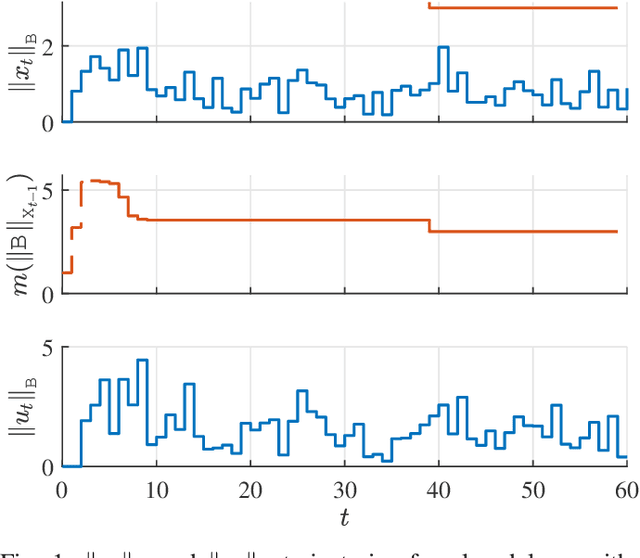
We present a simple model-free control algorithm that is able to robustly learn and stabilize an unknown discrete-time linear system with full control and state feedback subject to arbitrary bounded disturbance and noise sequences. The controller does not require any prior knowledge of the system dynamics, disturbances, or noise, yet it can guarantee robust stability and provides asymptotic and worst-case bounds on the state and input trajectories. To the best of our knowledge, this is the first model-free algorithm that comes with such robust stability guarantees without the need to make any prior assumptions about the system. We would like to highlight the new convex geometry-based approach taken towards robust stability analysis which served as a key enabler in our results. We will conclude with simulation results that show that despite the generality and simplicity, the controller demonstrates good closed-loop performance.
* 16 pages, 7 figures
Toward Adaptive Trust Calibration for Level 2 Driving Automation
Sep 24, 2020
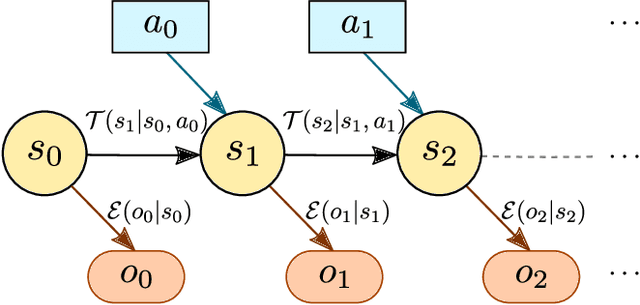
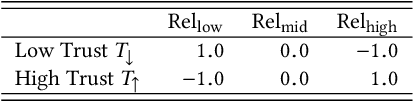
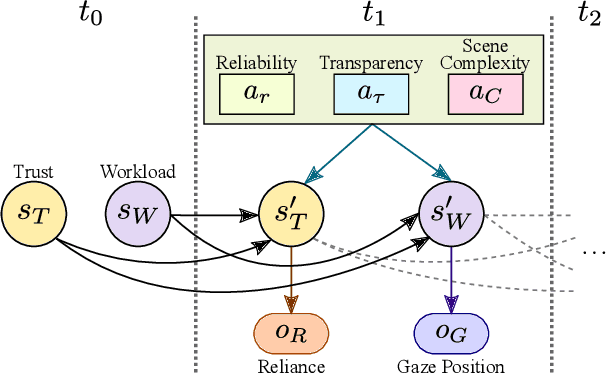
Properly calibrated human trust is essential for successful interaction between humans and automation. However, while human trust calibration can be improved by increased automation transparency, too much transparency can overwhelm human workload. To address this tradeoff, we present a probabilistic framework using a partially observable Markov decision process (POMDP) for modeling the coupled trust-workload dynamics of human behavior in an action-automation context. We specifically consider hands-off Level 2 driving automation in a city environment involving multiple intersections where the human chooses whether or not to rely on the automation. We consider automation reliability, automation transparency, and scene complexity, along with human reliance and eye-gaze behavior, to model the dynamics of human trust and workload. We demonstrate that our model framework can appropriately vary automation transparency based on real-time human trust and workload belief estimates to achieve trust calibration.
A Machine Learning-Based Migration Strategy for Virtual Network Function Instances
Jun 15, 2020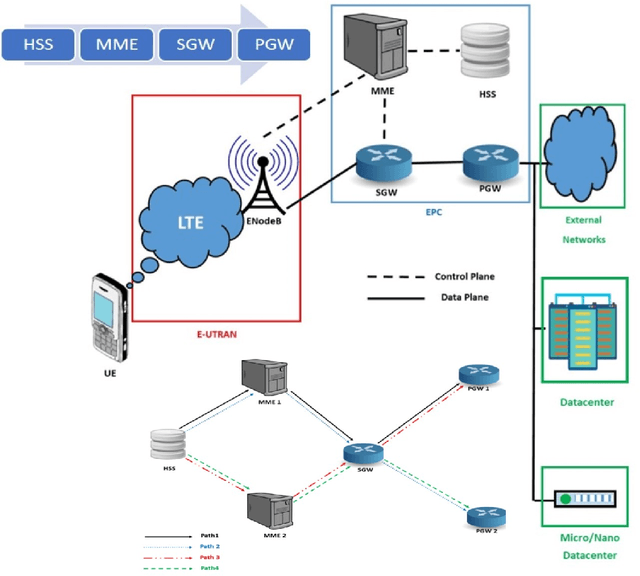
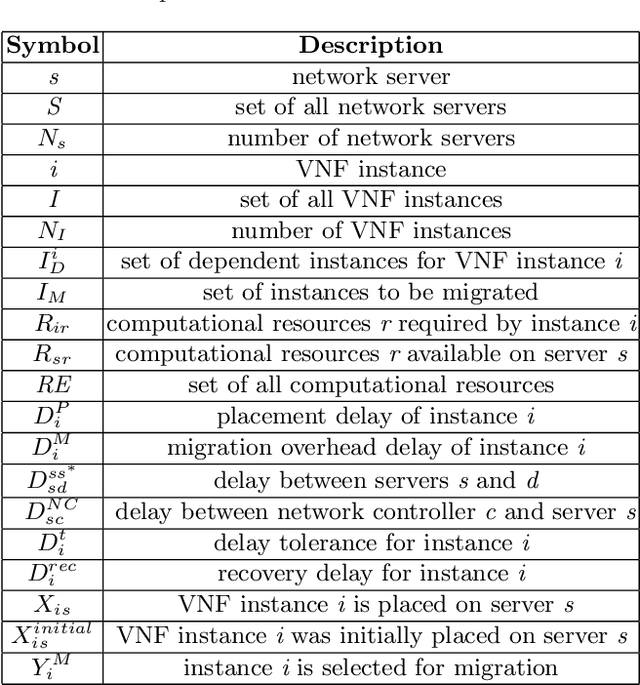


With the growing demand for data connectivity, network service providers are faced with the task of reducing their capital and operational expenses while simultaneously improving network performance and addressing the increased demand. Although Network Function Virtualization (NFV) has been identified as a promising solution, several challenges must be addressed to ensure its feasibility. In this paper, we address the Virtual Network Function (VNF) migration problem by developing the VNF Neural Network for Instance Migration (VNNIM), a migration strategy for VNF instances. The performance of VNNIM is further improved through the optimization of the learning rate hyperparameter through particle swarm optimization. Results show that the VNNIM is very effective in predicting the post-migration server exhibiting a binary accuracy of 99.07% and a delay difference distribution that is centered around a mean of zero when compared to the optimization model. The greatest advantage of VNNIM, however, is its run-time efficiency highlighted through a run-time analysis.
Benchmark Tests of Convolutional Neural Network and Graph Convolutional Network on HorovodRunner Enabled Spark Clusters
May 12, 2020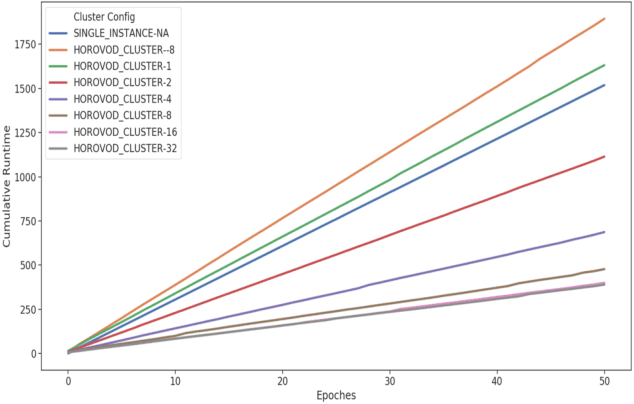
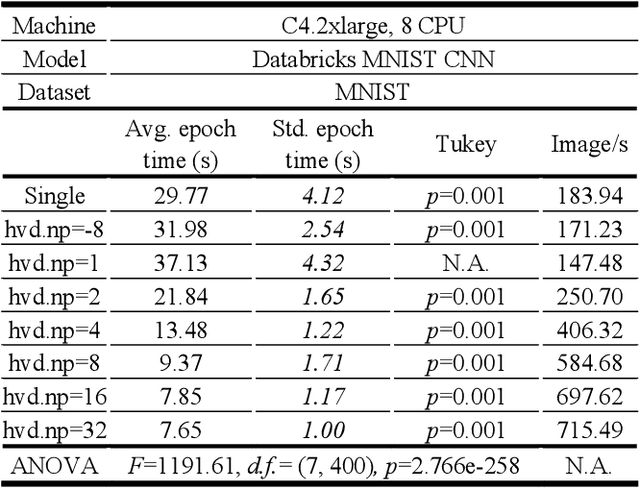
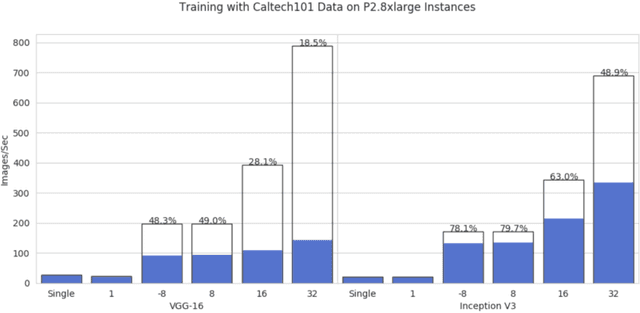
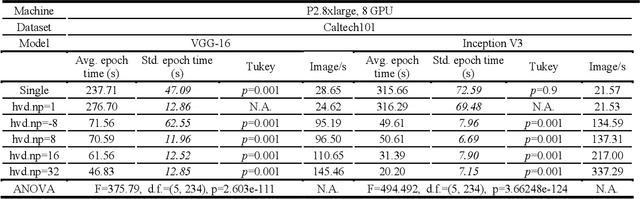
The freedom of fast iterations of distributed deep learning tasks is crucial for smaller companies to gain competitive advantages and market shares from big tech giants. HorovodRunner brings this process to relatively accessible spark clusters. There have been, however, no benchmark tests on HorovodRunner per se, nor specifically graph convolutional network (GCN, hereafter), and very limited scalability benchmark tests on Horovod, the predecessor requiring custom built GPU clusters. For the first time, we show that Databricks' HorovodRunner achieves significant lift in scaling efficiency for the convolutional neural network (CNN, hereafter) based tasks on both GPU and CPU clusters, but not the original GCN task. We also implemented the Rectified Adam optimizer for the first time in HorovodRunner.
Stability-Guaranteed Reinforcement Learning for Contact-rich Manipulation
Apr 22, 2020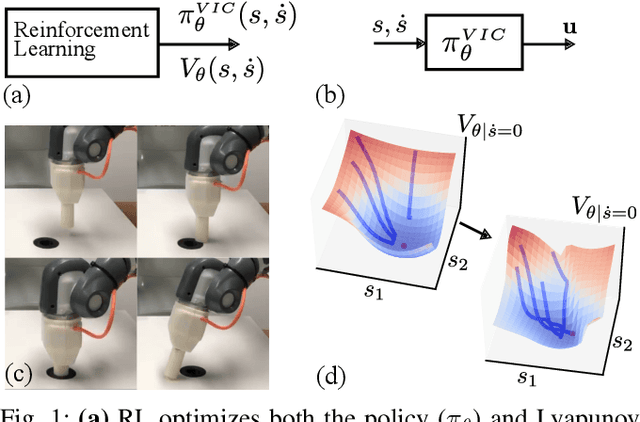
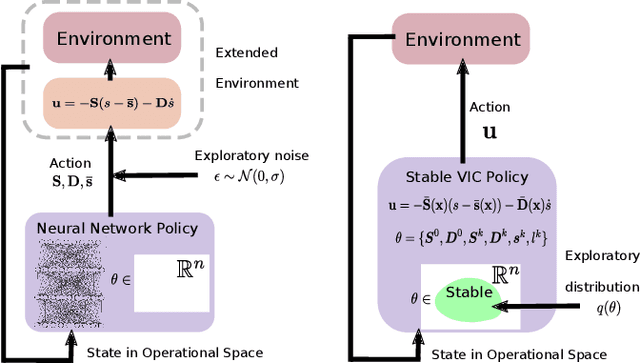
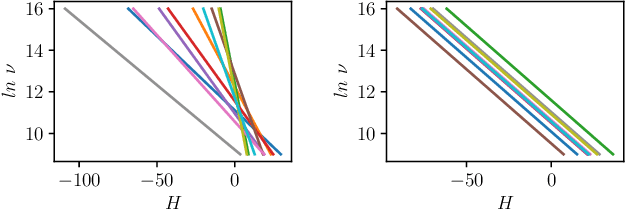
Reinforcement learning (RL) has had its fair share of success in contact-rich manipulation tasks but it still lags behind in benefiting from advances in robot control theory such as impedance control and stability guarantees. Recently, the concept of variable impedance control (VIC) was adopted into RL with encouraging results. However, the more important issue of stability remains unaddressed. To clarify the challenge in stable RL, we introduce the term all-the-time-stability that unambiguously means that every possible rollout will be stability certified. Our contribution is a model-free RL method that not only adopts VIC but also achieves all-the-time-stability. Building on a recently proposed stable VIC controller as the policy parameterization, we introduce a novel policy search algorithm that is inspired by Cross-Entropy Method and inherently guarantees stability. As a part of our extensive experimental studies, we report, to the best of our knowledge, the first successful application of RL with all-the-time-stability on the benchmark problem of peg-in-hole.
Full Quaternion Representation of Color images: A Case Study on QSVD-based Color Image Compression
Jul 19, 2020
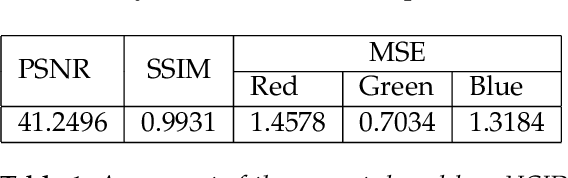
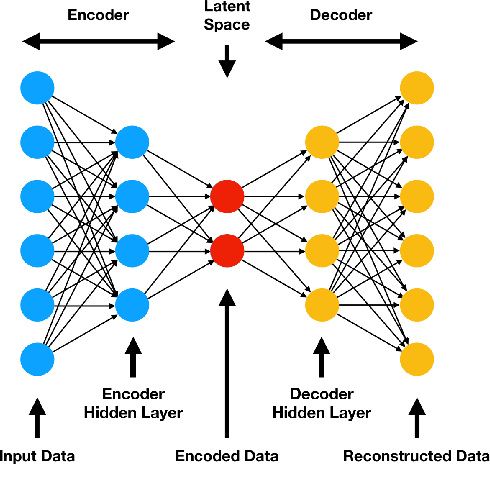
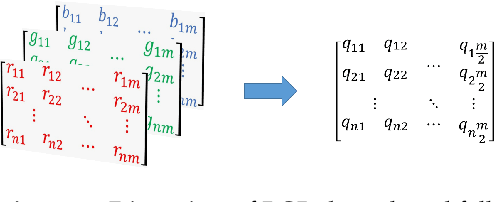
For many years, channels of a color image have been processed individually, or the image has been converted to grayscale one with respect to color image processing. Pure quaternion representation of color images solves this issue as it allows images to be processed in a holistic space. Nevertheless, it brings additional costs due to the extra fourth dimension. In this paper, we propose an approach for representing color images with full quaternion numbers that enables us to process color images holistically without additional cost in time, space and computation. With taking auto- and cross-correlation of color channels into account, an autoencoder neural network is used to generate a global model for transforming a color image into a full quaternion matrix. To evaluate the model, we use UCID dataset, and the results indicate that the model has an acceptable performance on color images. Moreover, we propose a compression method based on the generated model and QSVD as a case study. The method is compared with the same compression method using pure quaternion representation and is assessed with UCID dataset. The results demonstrate that the compression method using the proposed full quaternion representation fares better than the other in terms of time, quality, and size of compressed files.
Representation Learning for Sequence Data with Deep Autoencoding Predictive Components
Oct 07, 2020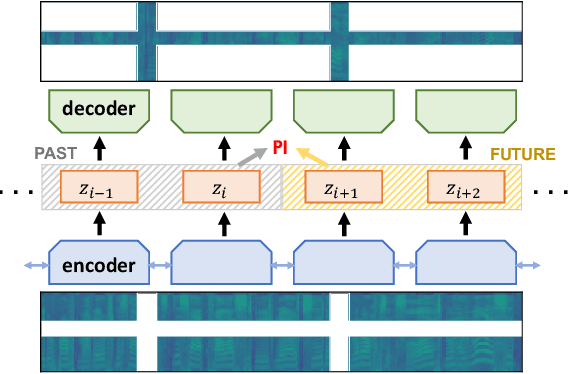
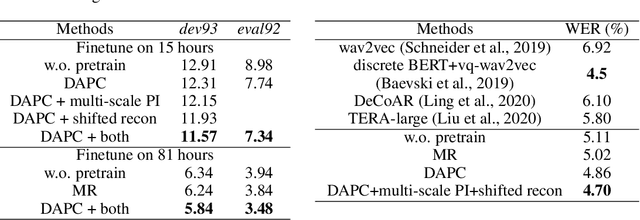
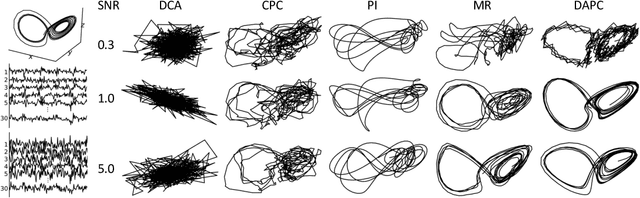
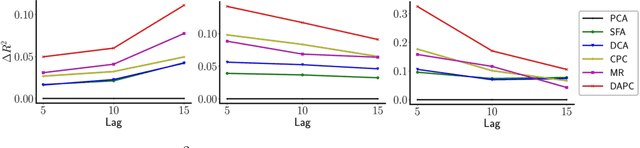
We propose Deep Autoencoding Predictive Components (DAPC) -- a self-supervised representation learning method for sequence data, based on the intuition that useful representations of sequence data should exhibit a simple structure in the latent space. We encourage this latent structure by maximizing an estimate of predictive information of latent feature sequences, which is the mutual information between past and future windows at each time step. In contrast to the mutual information lower bound commonly used by contrastive learning, the estimate of predictive information we adopt is exact under a Gaussian assumption. Additionally, it can be computed without negative sampling. To reduce the degeneracy of the latent space extracted by powerful encoders and keep useful information from the inputs, we regularize predictive information learning with a challenging masked reconstruction loss. We demonstrate that our method recovers the latent space of noisy dynamical systems, extracts predictive features for forecasting tasks, and improves automatic speech recognition when used to pretrain the encoder on large amounts of unlabeled data.
Characterizing and Predicting Repeat Food Consumption Behavior for Just-in-Time Interventions
Sep 17, 2019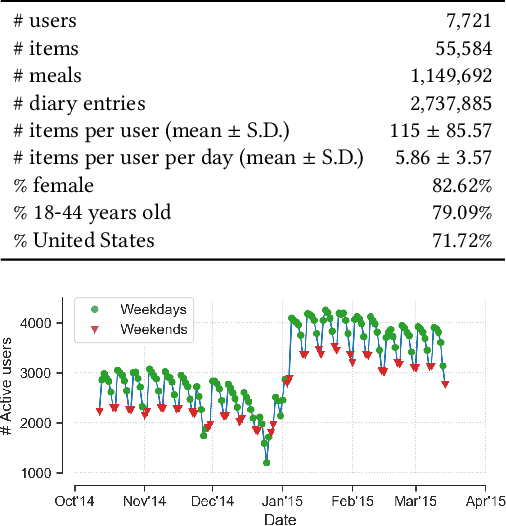
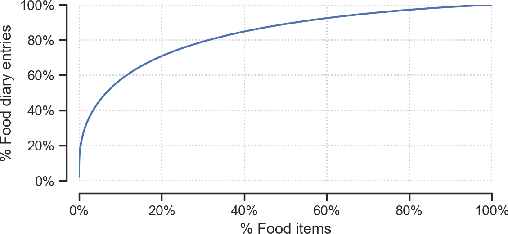

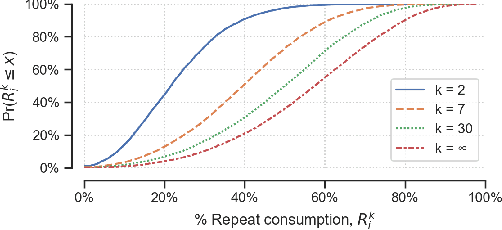
Human beings are creatures of habit. In their daily life, people tend to repeatedly consume similar types of food items over several days and occasionally switch to consuming different types of items when the consumptions become overly monotonous. However, the novel and repeat consumption behaviors have not been studied in food recommendation research. More importantly, the ability to predict daily eating habits of individuals is crucial to improve the effectiveness of food recommender systems in facilitating healthy lifestyle change. In this study, we analyze the patterns of repeat food consumptions using large-scale consumption data from a popular online fitness community called MyFitnessPal (MFP), conduct an offline evaluation of various state-of-the-art algorithms in predicting the next-day food consumption, and analyze their performance across different demographic groups and contexts. The experiment results show that algorithms incorporating the exploration-and-exploitation and temporal dynamics are more effective in the next-day recommendation task than most state-of-the-art algorithms.
IEO: Intelligent Evolutionary Optimisation for Hyperparameter Tuning
Sep 10, 2020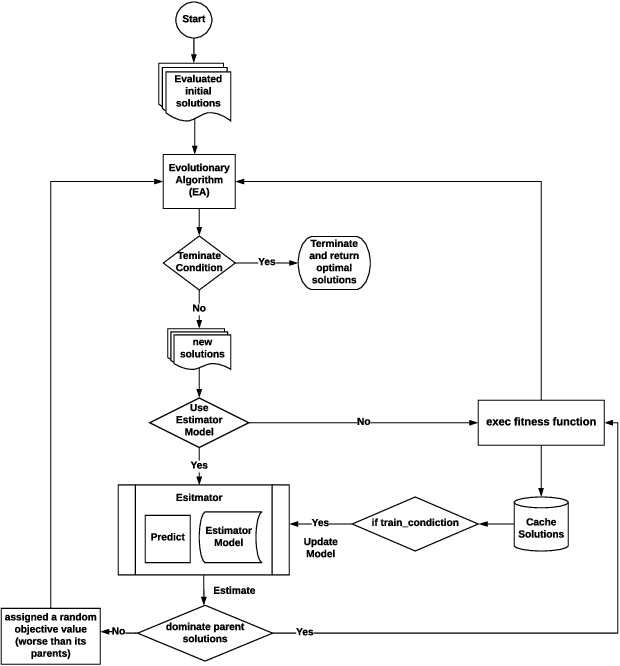
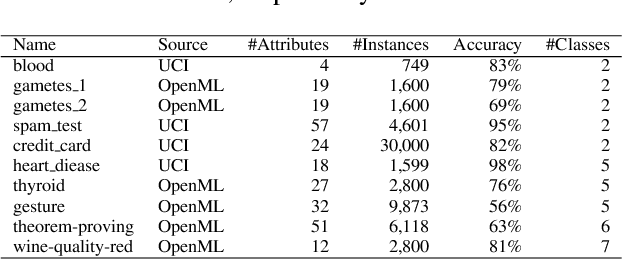
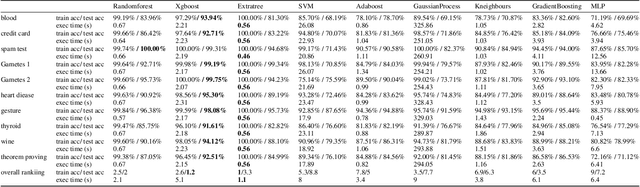
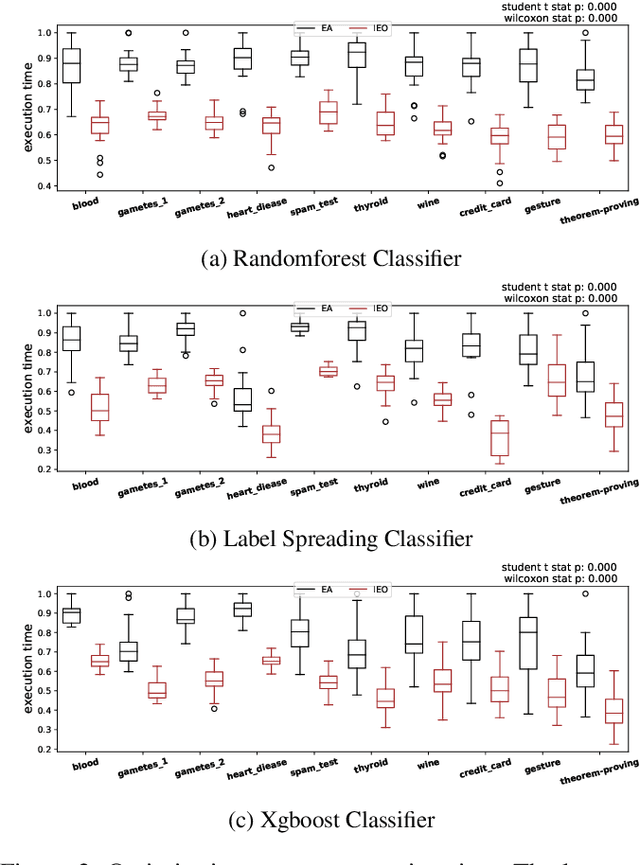
Hyperparameter optimisation is a crucial process in searching the optimal machine learning model. The efficiency of finding the optimal hyperparameter settings has been a big concern in recent researches since the optimisation process could be time-consuming, especially when the objective functions are highly expensive to evaluate. In this paper, we introduce an intelligent evolutionary optimisation algorithm which applies machine learning technique to the traditional evolutionary algorithm to accelerate the overall optimisation process of tuning machine learning models in classification problems. We demonstrate our Intelligent Evolutionary Optimisation (IEO)in a series of controlled experiments, comparing with traditional evolutionary optimisation in hyperparameter tuning. The empirical study shows that our approach accelerates the optimisation speed by 30.40% on average and up to 77.06% in the best scenarios.
DORB: Dynamically Optimizing Multiple Rewards with Bandits
Nov 15, 2020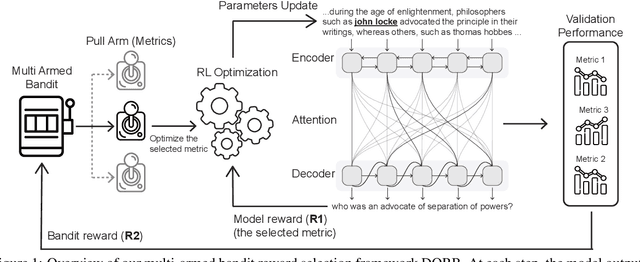
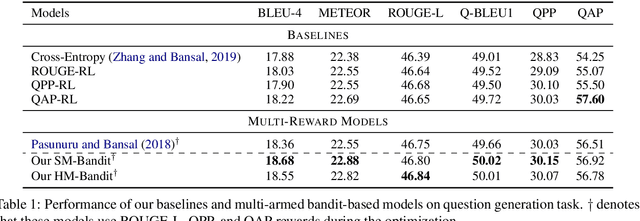
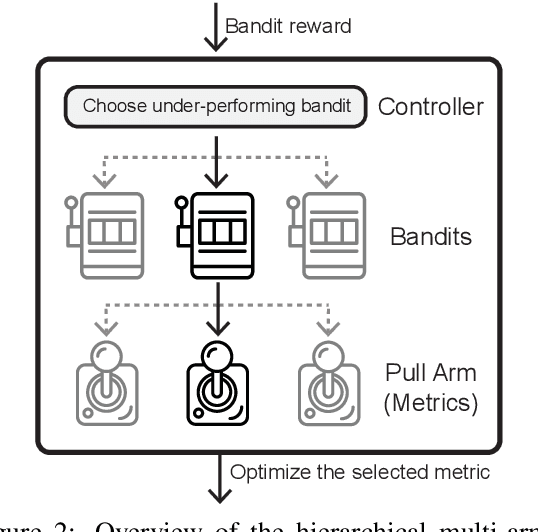
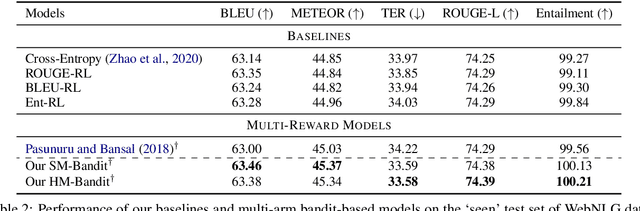
Policy gradients-based reinforcement learning has proven to be a promising approach for directly optimizing non-differentiable evaluation metrics for language generation tasks. However, optimizing for a specific metric reward leads to improvements in mostly that metric only, suggesting that the model is gaming the formulation of that metric in a particular way without often achieving real qualitative improvements. Hence, it is more beneficial to make the model optimize multiple diverse metric rewards jointly. While appealing, this is challenging because one needs to manually decide the importance and scaling weights of these metric rewards. Further, it is important to consider using a dynamic combination and curriculum of metric rewards that flexibly changes over time. Considering the above aspects, in our work, we automate the optimization of multiple metric rewards simultaneously via a multi-armed bandit approach (DORB), where at each round, the bandit chooses which metric reward to optimize next, based on expected arm gains. We use the Exp3 algorithm for bandits and formulate two approaches for bandit rewards: (1) Single Multi-reward Bandit (SM-Bandit); (2) Hierarchical Multi-reward Bandit (HM-Bandit). We empirically show the effectiveness of our approaches via various automatic metrics and human evaluation on two important NLG tasks: question generation and data-to-text generation, including on an unseen-test transfer setup. Finally, we present interpretable analyses of the learned bandit curriculum over the optimized rewards.